In this talk I'll be introducing the concept of querying by examples. I'll cover a couple of features used for multimedia search, and some matching procedures such as kNN and Bayesian Sets. Finally, I'll conclude with Lucene internally performing a matrix multiply, and using More Like This as a online feature selection algorithm.
{kind=link}
{kind=link}
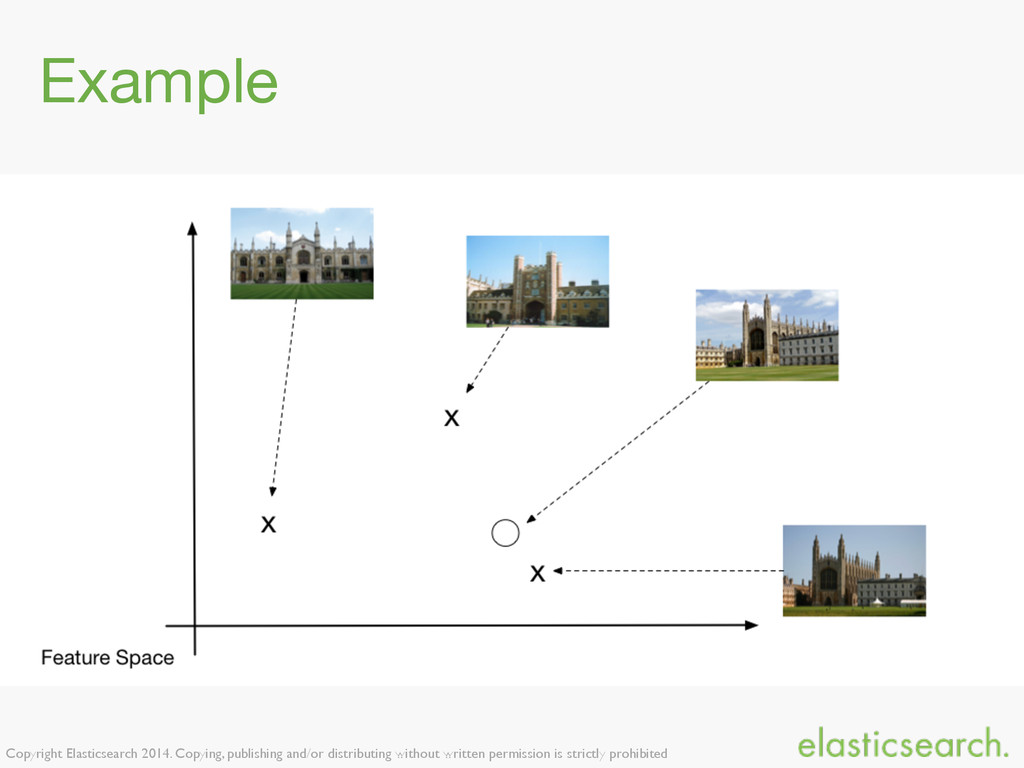{kind=link}
{kind=link}
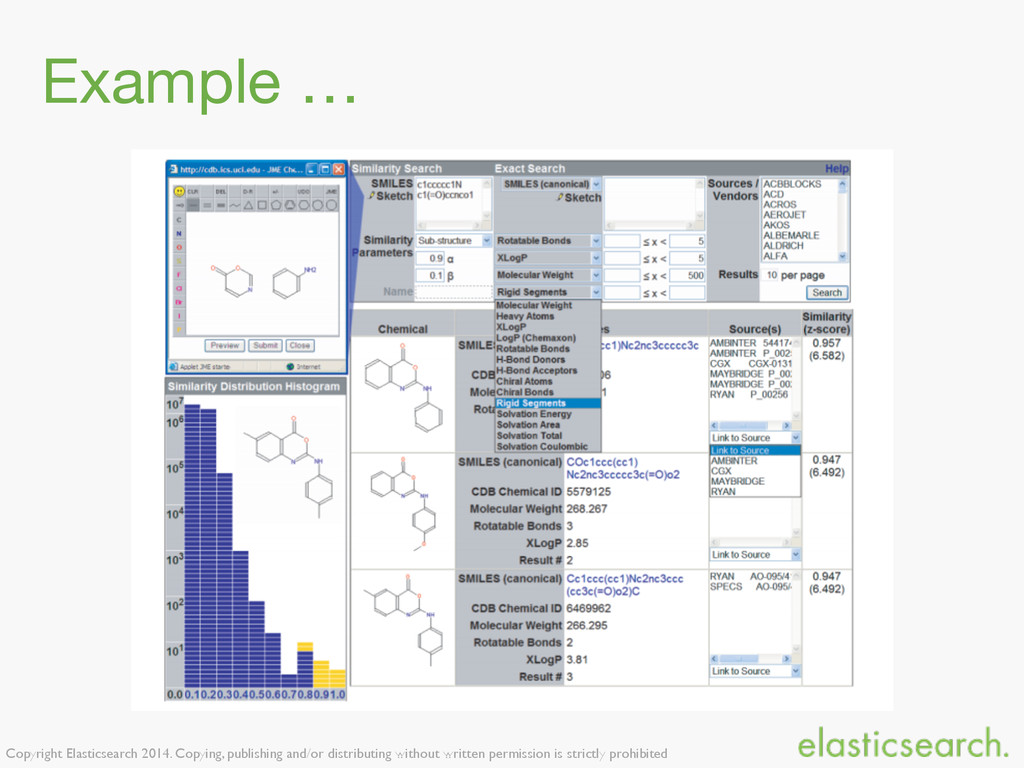{kind=link}
{kind=link}
{kind=link}
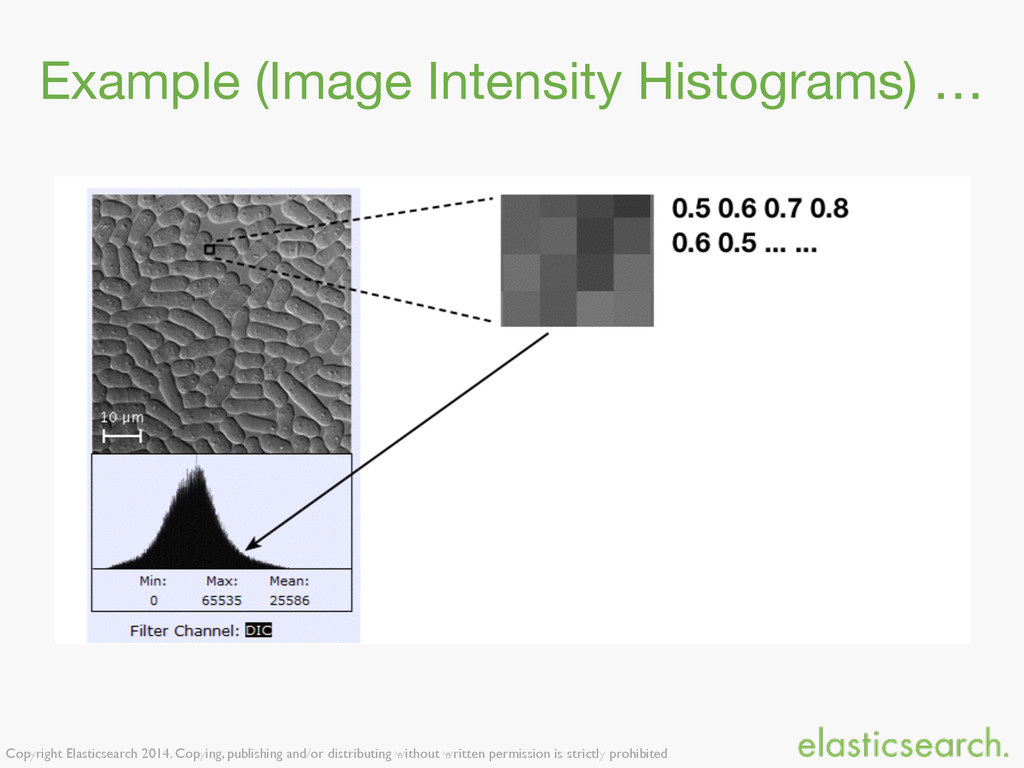{kind=link}
{kind=link}
{kind=link}
{kind=link}
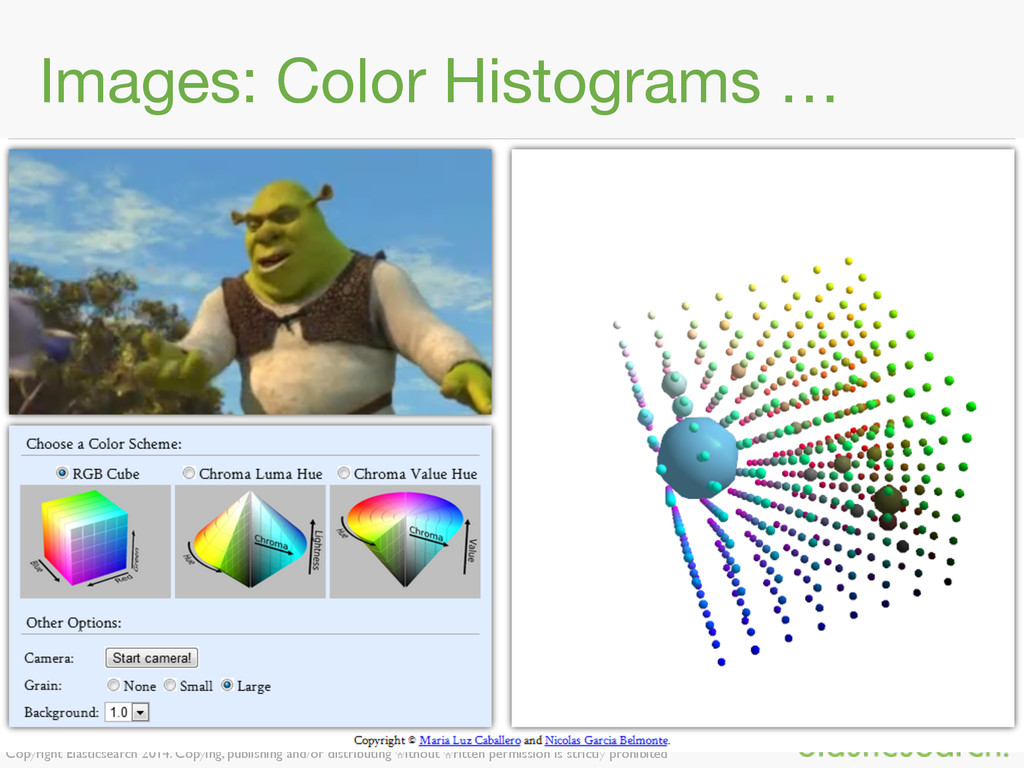{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
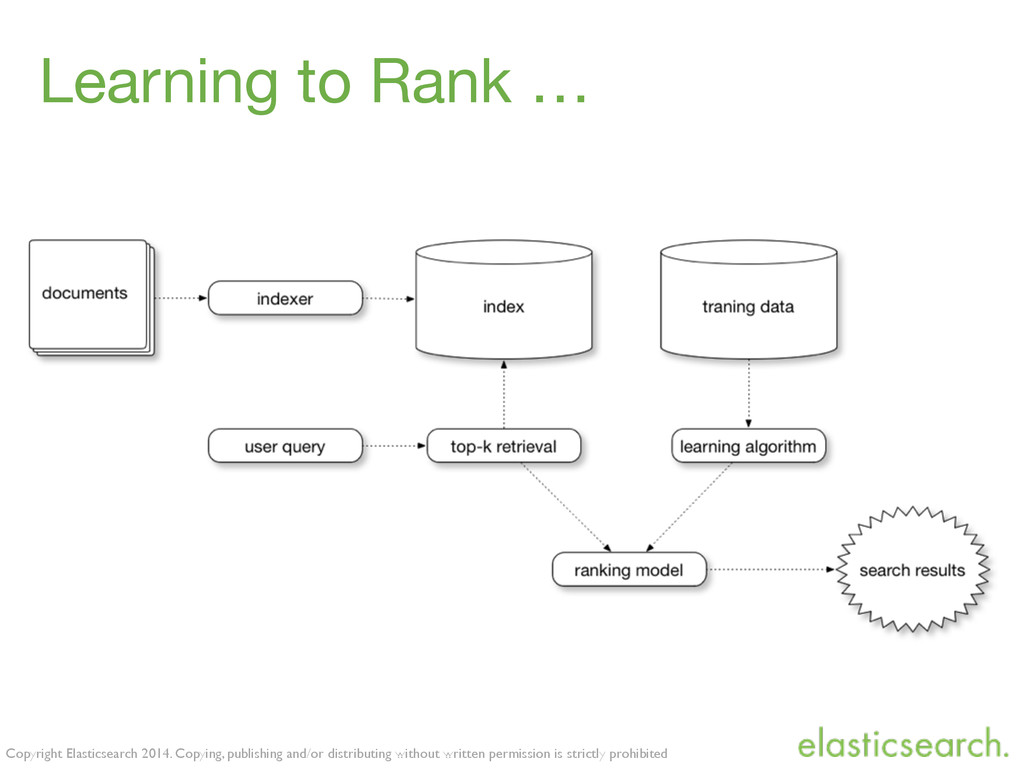{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}