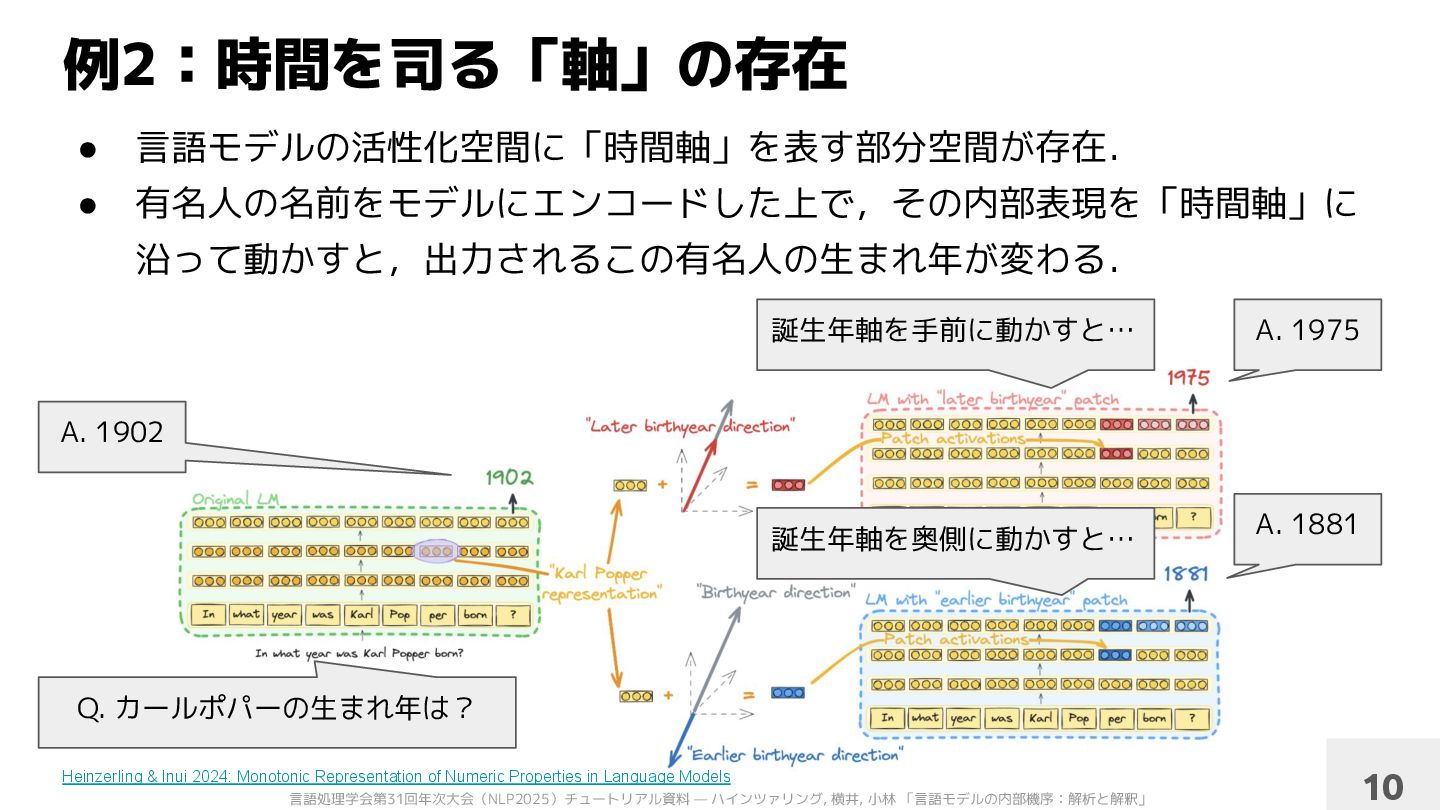
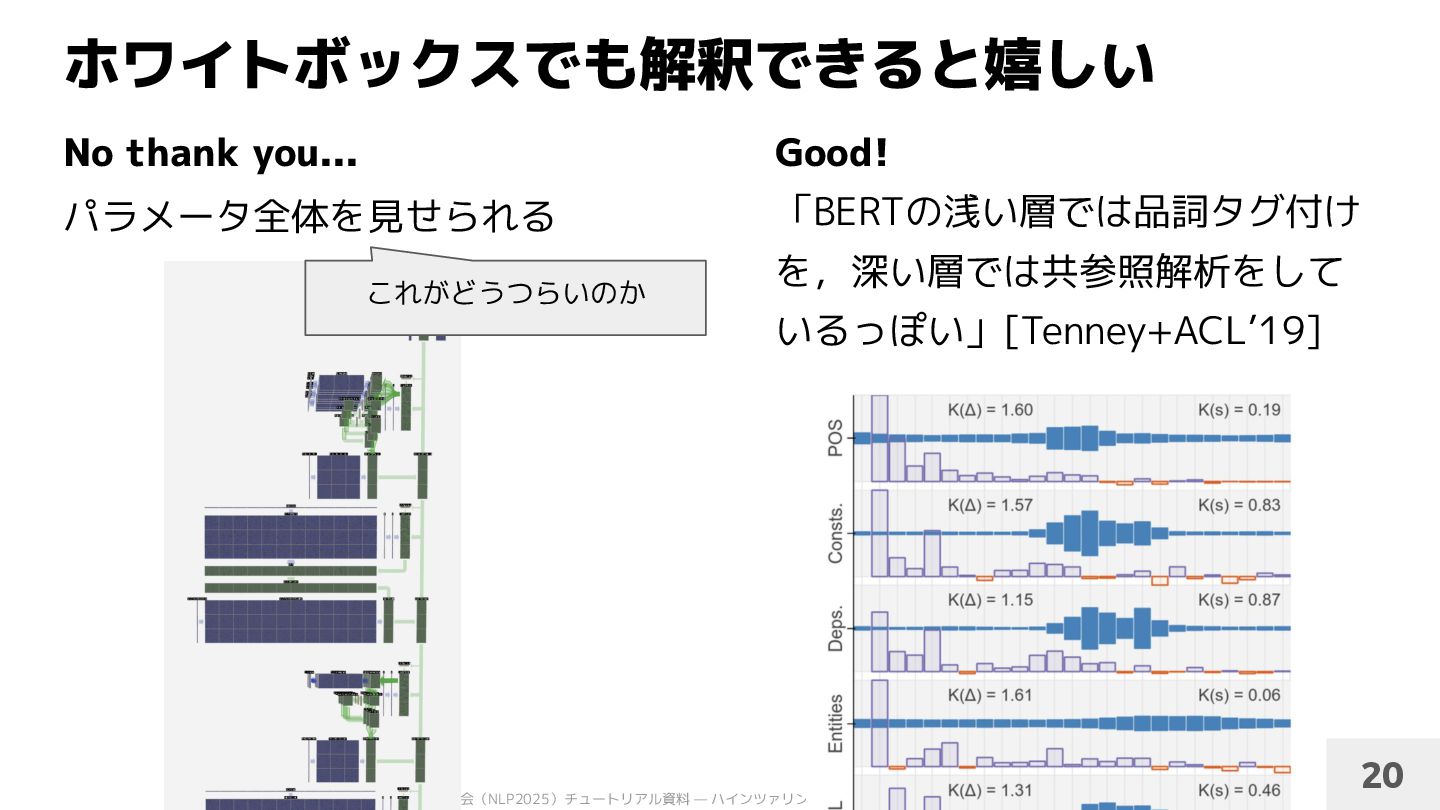
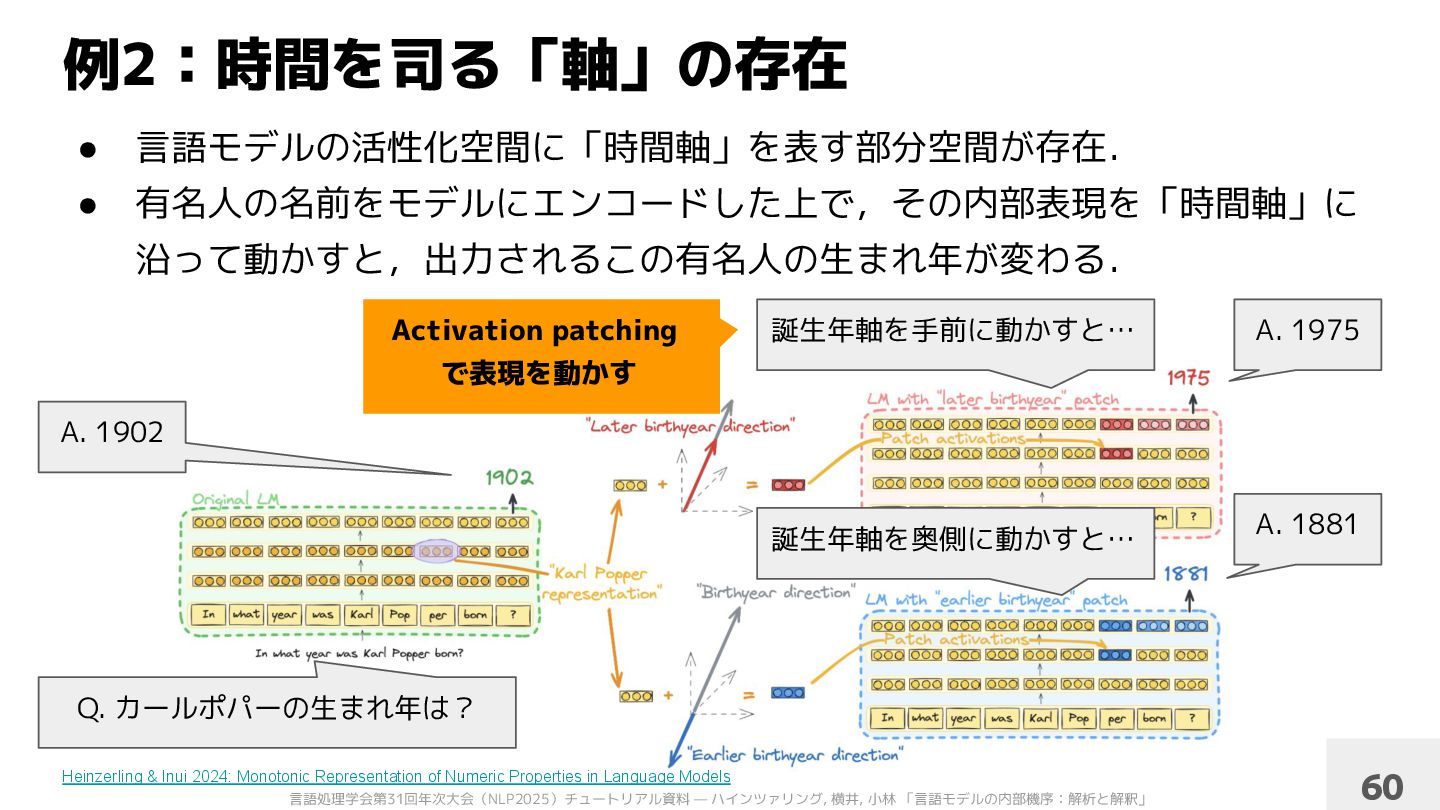
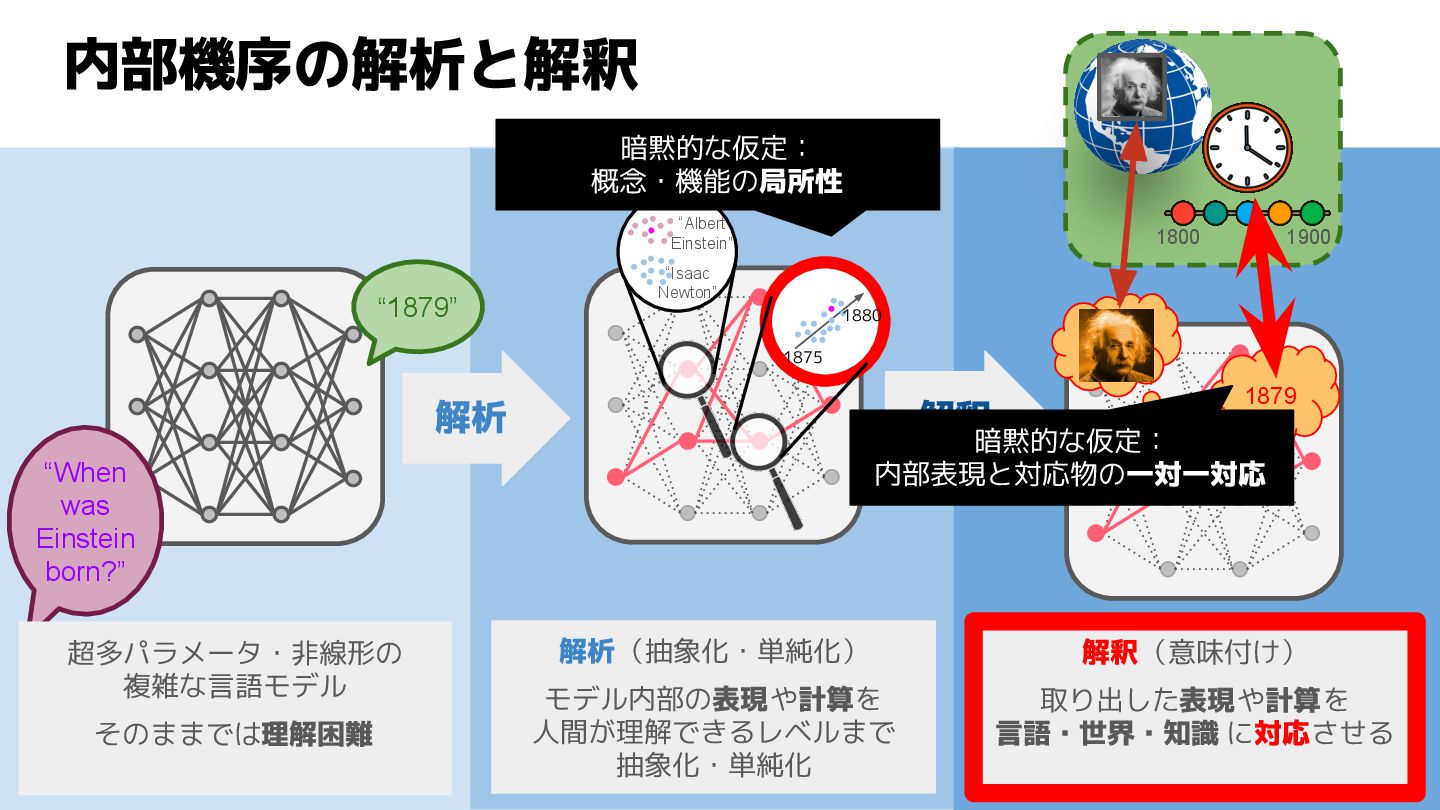
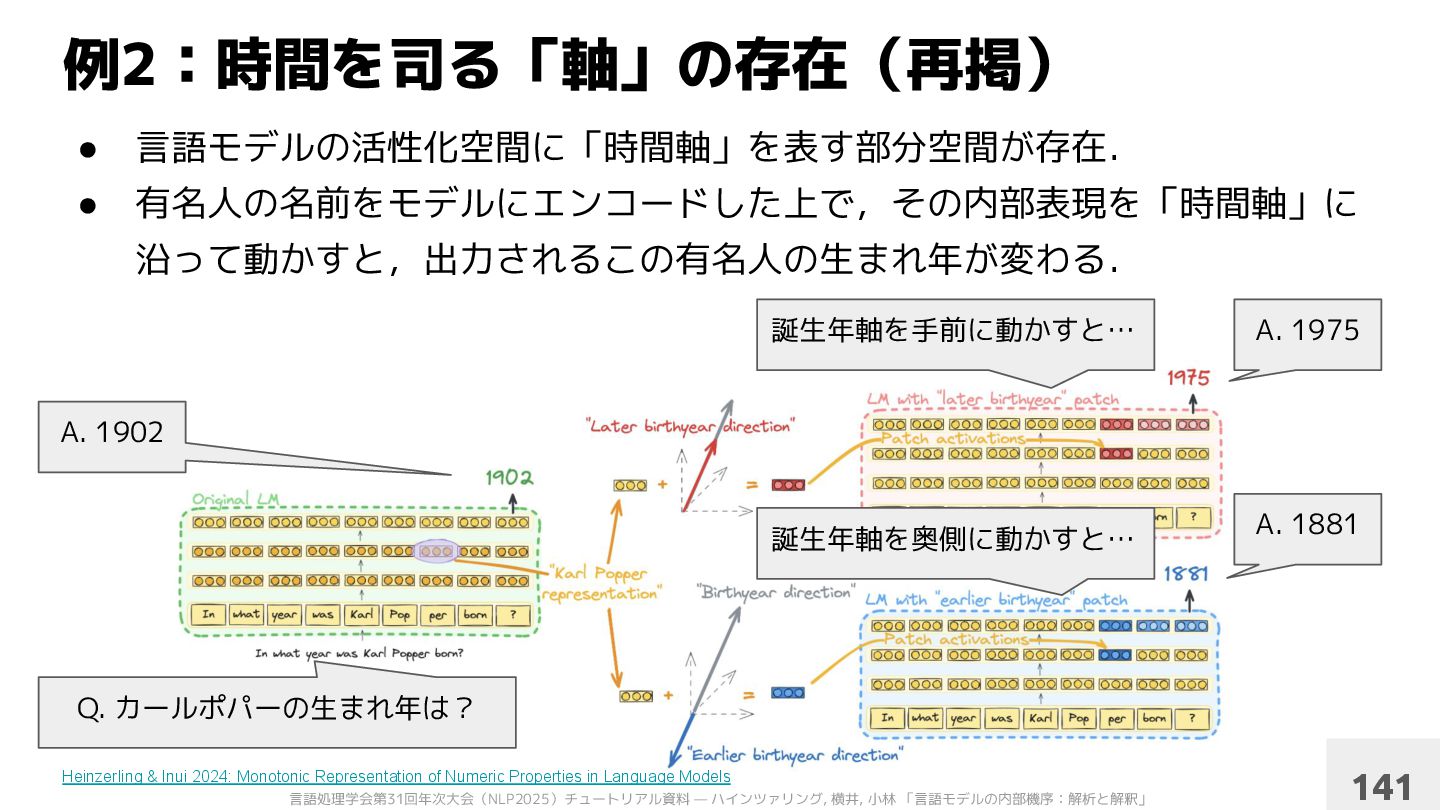
沿って動かすと,出力されるこの有名人の生まれ年が変わる. 例2:時間を司る「軸」の存在 Heinzerling & Inui 2024: Monotonic Representation of Numeric Properties in Language Models 10 Q. カールポパーの生まれ年は? A. 1902 誕生年軸を手前に動かすと… 誕生年軸を奥側に動かすと… A. 1975 A. 1881
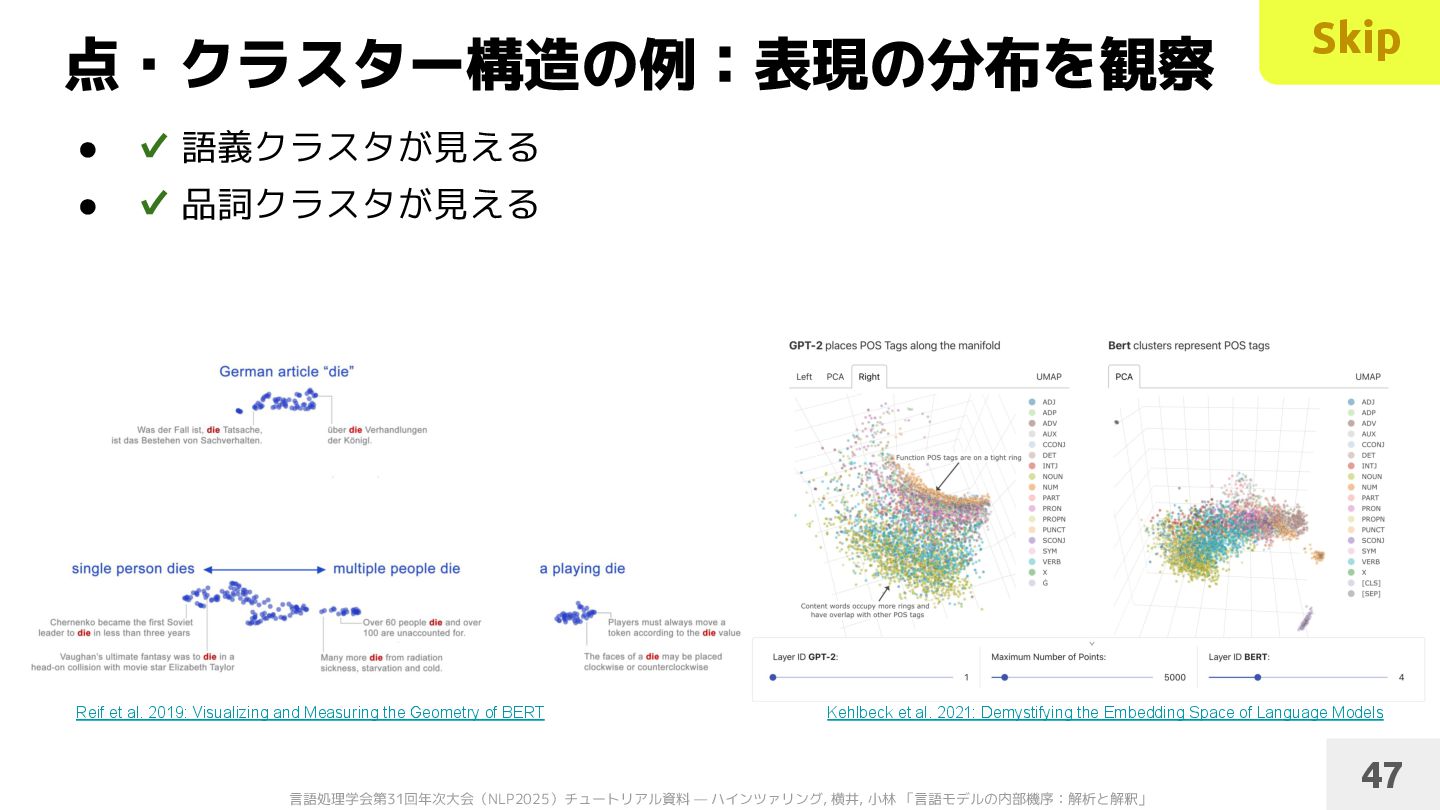
• ✔ 品詞クラスタが見える 47 Reif et al. 2019: Visualizing and Measuring the Geometry of BERT Kehlbeck et al. 2021: Demystifying the Embedding Space of Language Models Skip
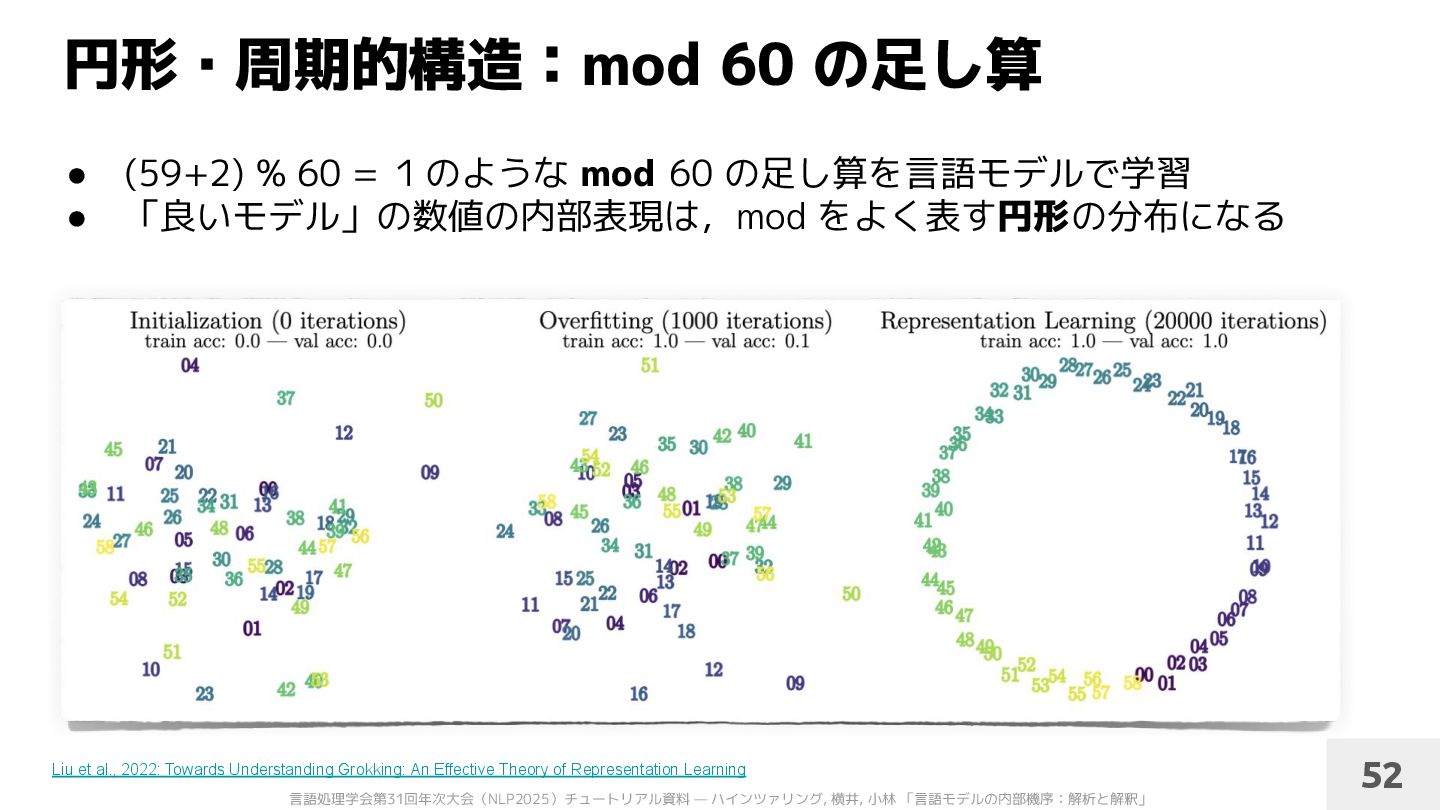
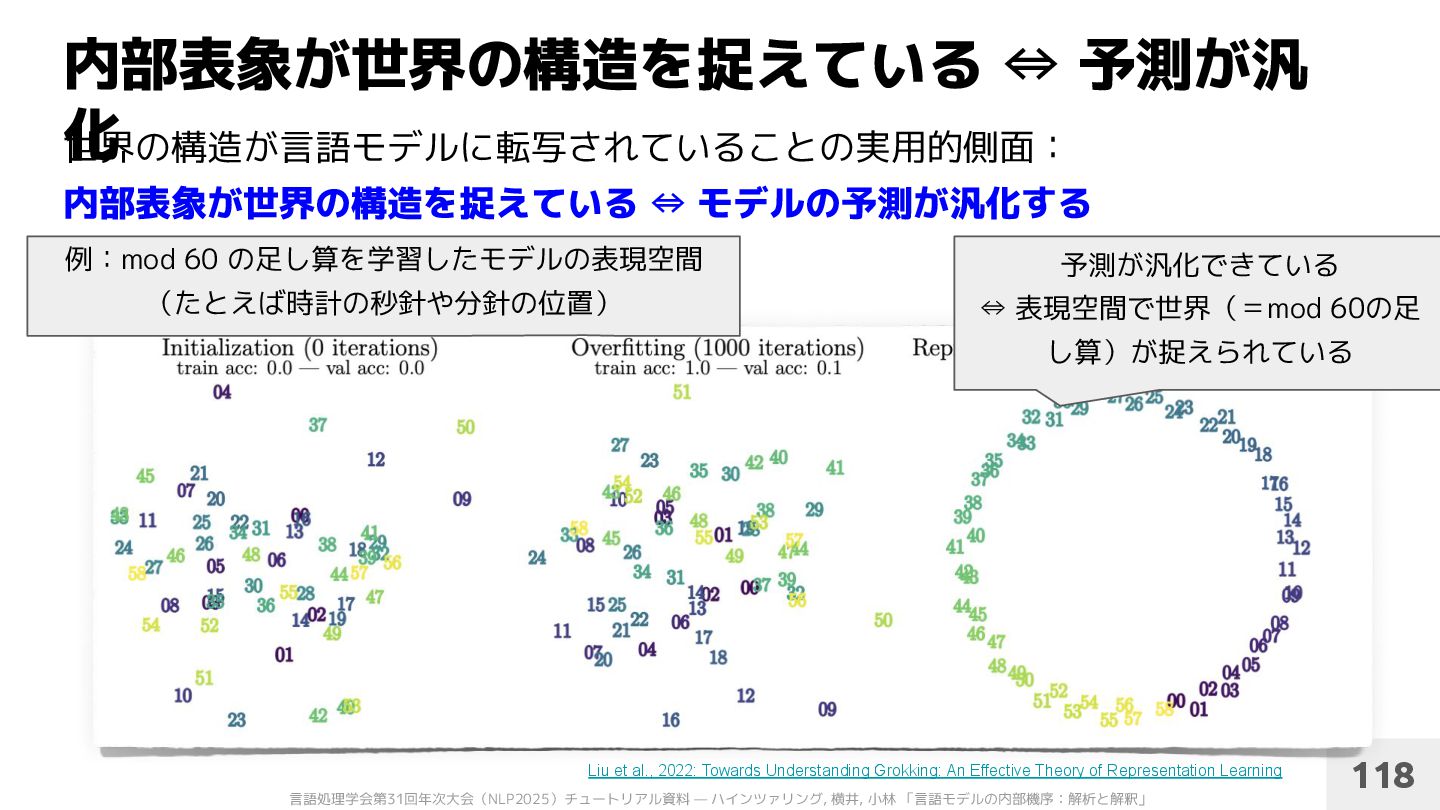
et al., 2022: Towards Understanding Grokking: An Effective Theory of Representation Learning 52 • (59+2) % 60 = 1のような mod 60 の足し算を言語モデルで学習 • 「良いモデル」の数値の内部表現は,mod をよく表す円形の分布になる
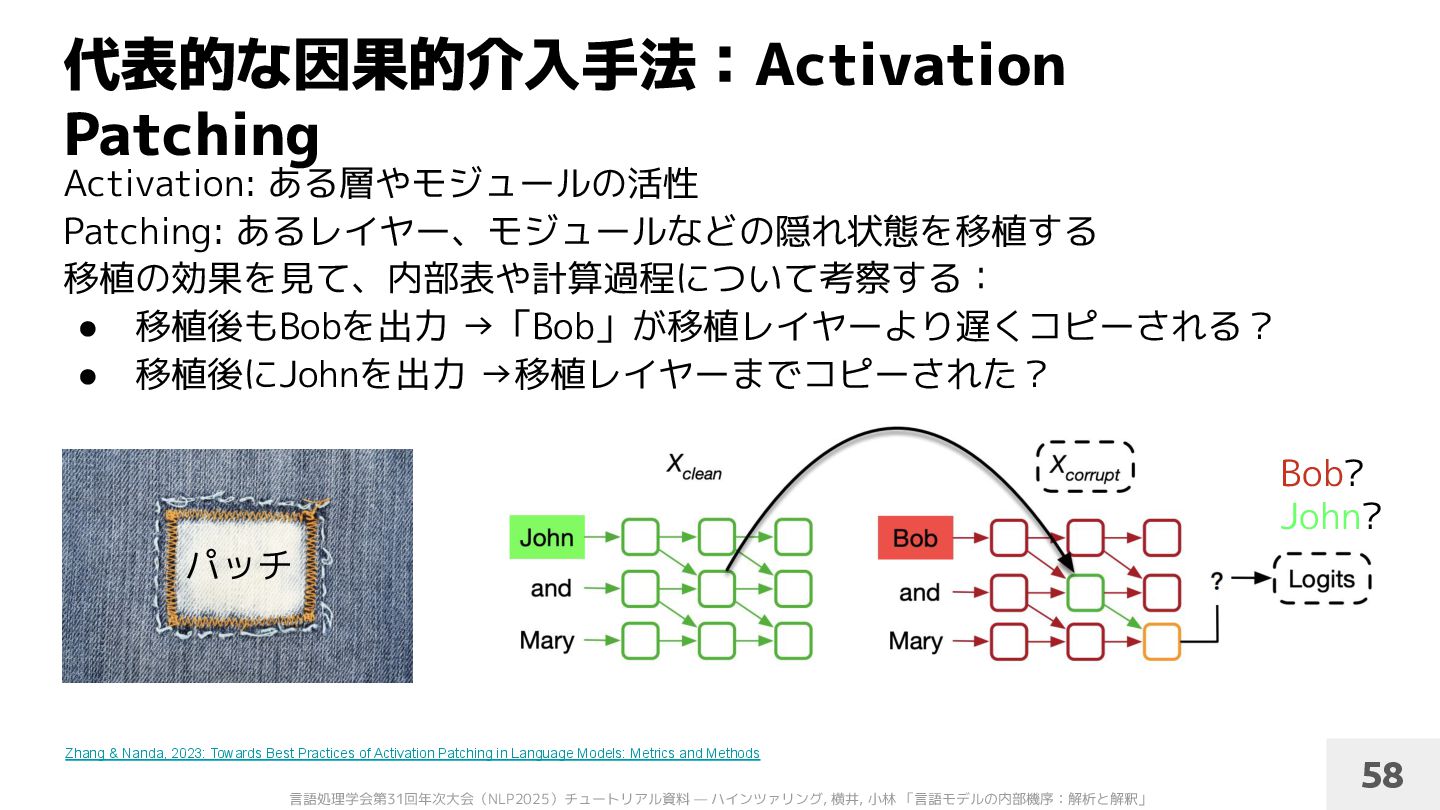
Patching: あるレイヤー、モジュールなどの隠れ状態を移植する 移植の効果を見て、内部表や計算過程について考察する: • 移植後もBobを出力 →「Bob」が移植レイヤーより遅くコピーされる? • 移植後にJohnを出力 →移植レイヤーまでコピーされた? 58 Zhang & Nanda, 2023: Towards Best Practices of Activation Patching in Language Models: Metrics and Methods パッチ Bob? John?
沿って動かすと,出力されるこの有名人の生まれ年が変わる. 例2:時間を司る「軸」の存在 Heinzerling & Inui 2024: Monotonic Representation of Numeric Properties in Language Models 60 Q. カールポパーの生まれ年は? A. 1902 誕生年軸を手前に動かすと… 誕生年軸を奥側に動かすと… A. 1975 A. 1881 Activation patching で表現を動かす
• 回答を拒否するかどうかを表現する方向が存在 [Arditi+’24] ◦ 有害な入力集合と無害な入力集合で、中間表現の平均差分ベクトル (振る舞い方向) を算出 • 推論中の中間表現に対し、この方向を伸ばしたり潰したりする介入で ◦ 有害な入力に対して拒否を回避できる (左図) ◦ 無害な入力に対して拒否を強制できる (右図) 61 Arditi+, Refusal in Language Models Is Mediated by a Single Direction (NeurIPS 2024) Skip
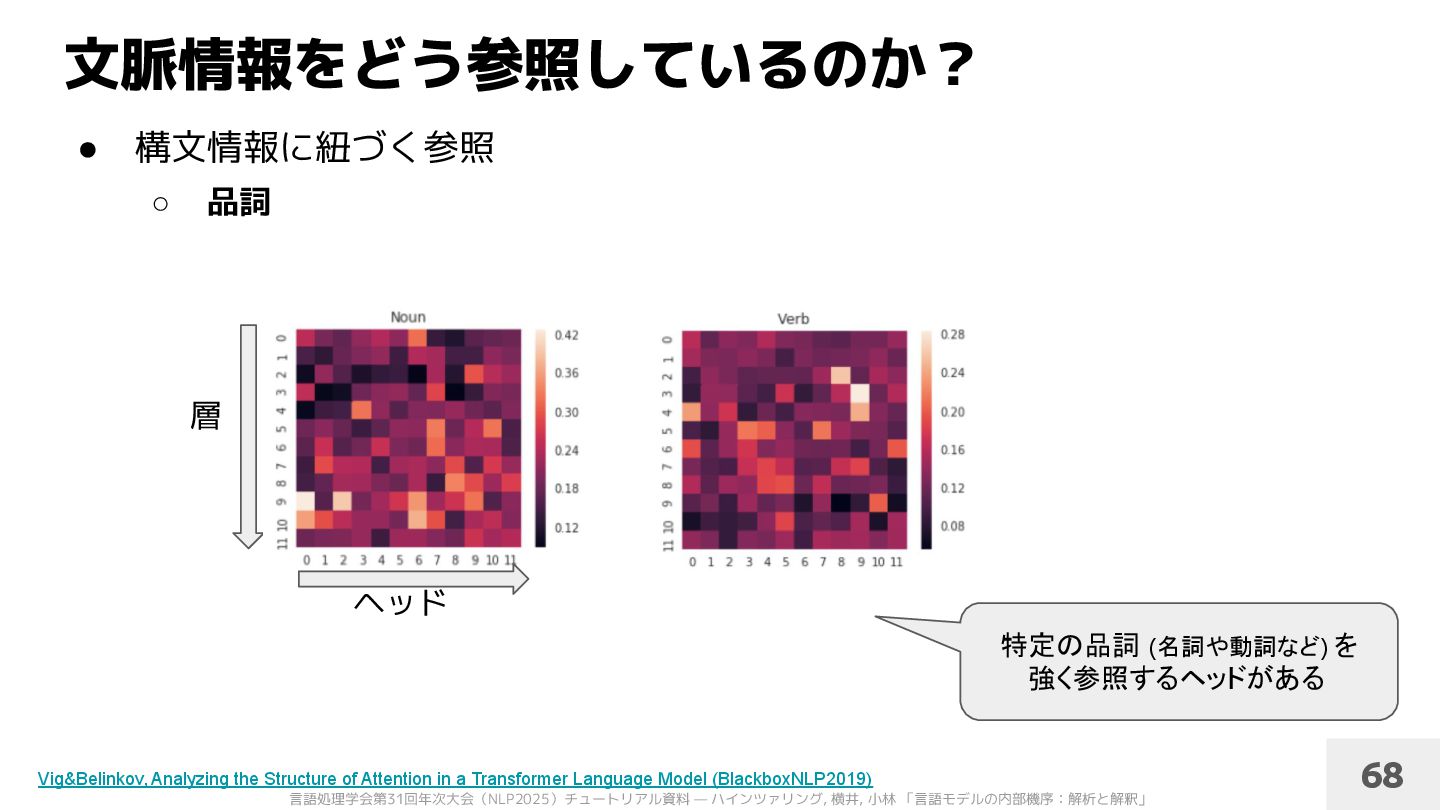
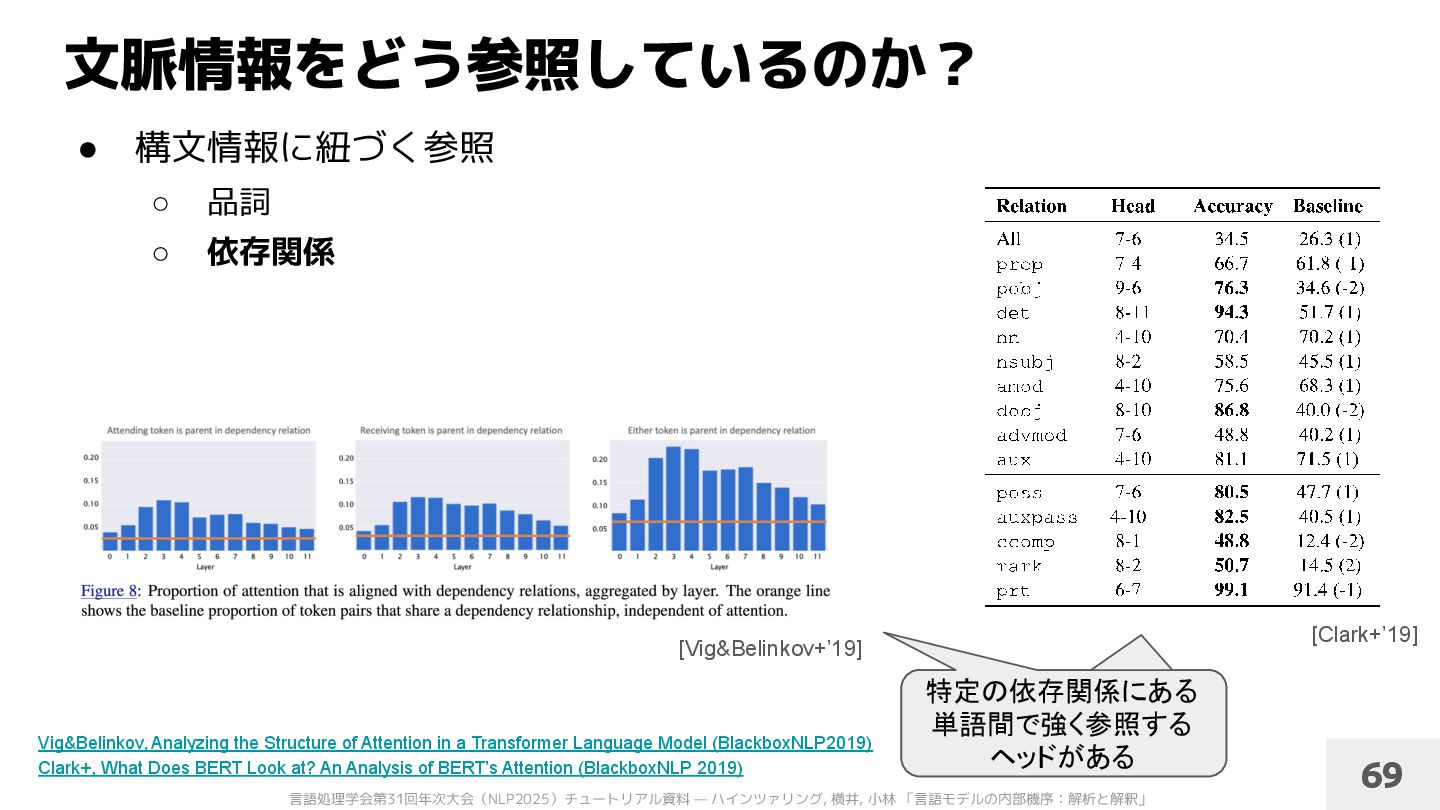
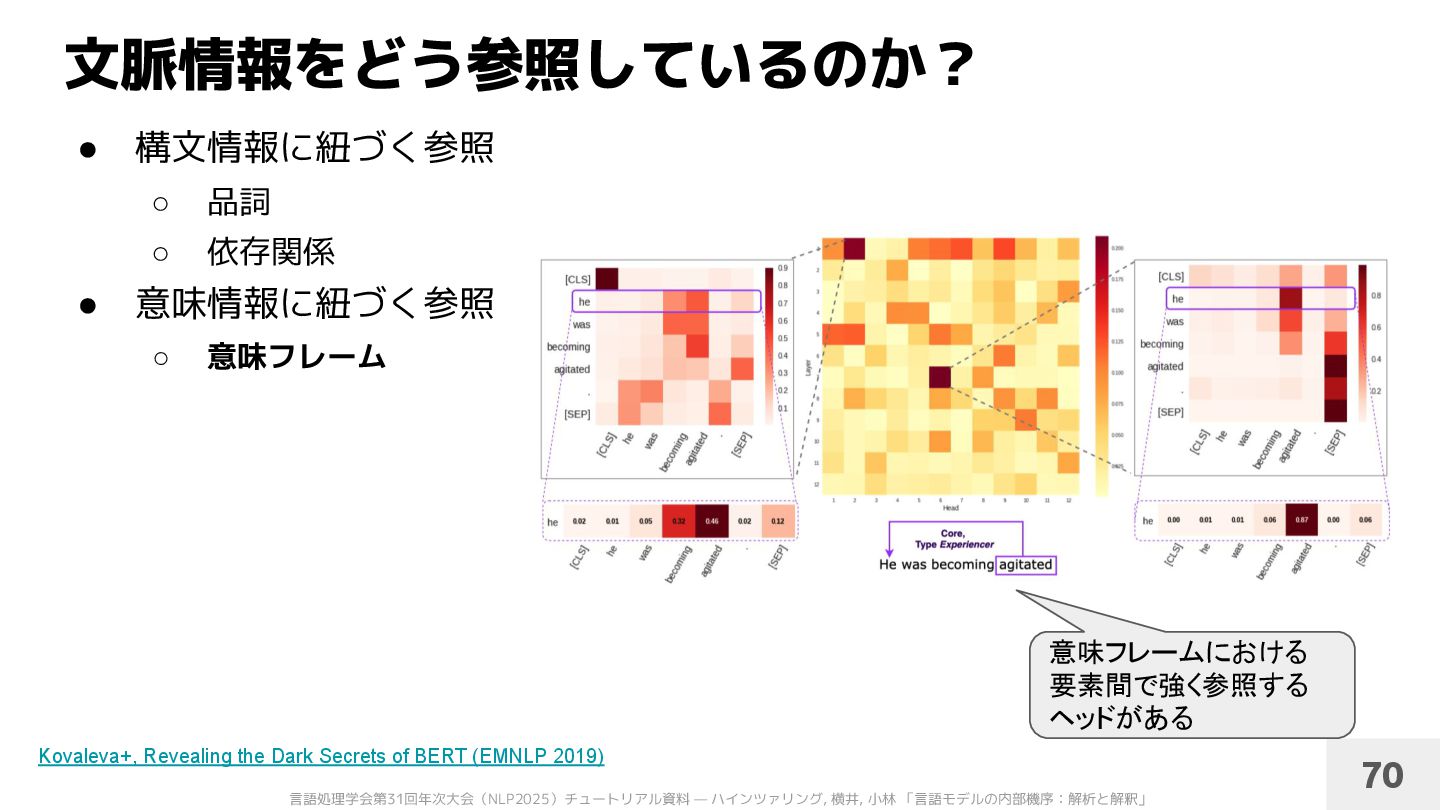
品詞 ◦ 依存関係 [Vig&Belinkov+’19] [Clark+’19] 特定の品詞へ強く注目 するヘッドがある 特定の依存関係にある 単語間で強く参照する ヘッドがある 69 Vig&Belinkov, Analyzing the Structure of Attention in a Transformer Language Model (BlackboxNLP2019) Clark+, What Does BERT Look at? An Analysis of BERT’s Attention (BlackboxNLP 2019)
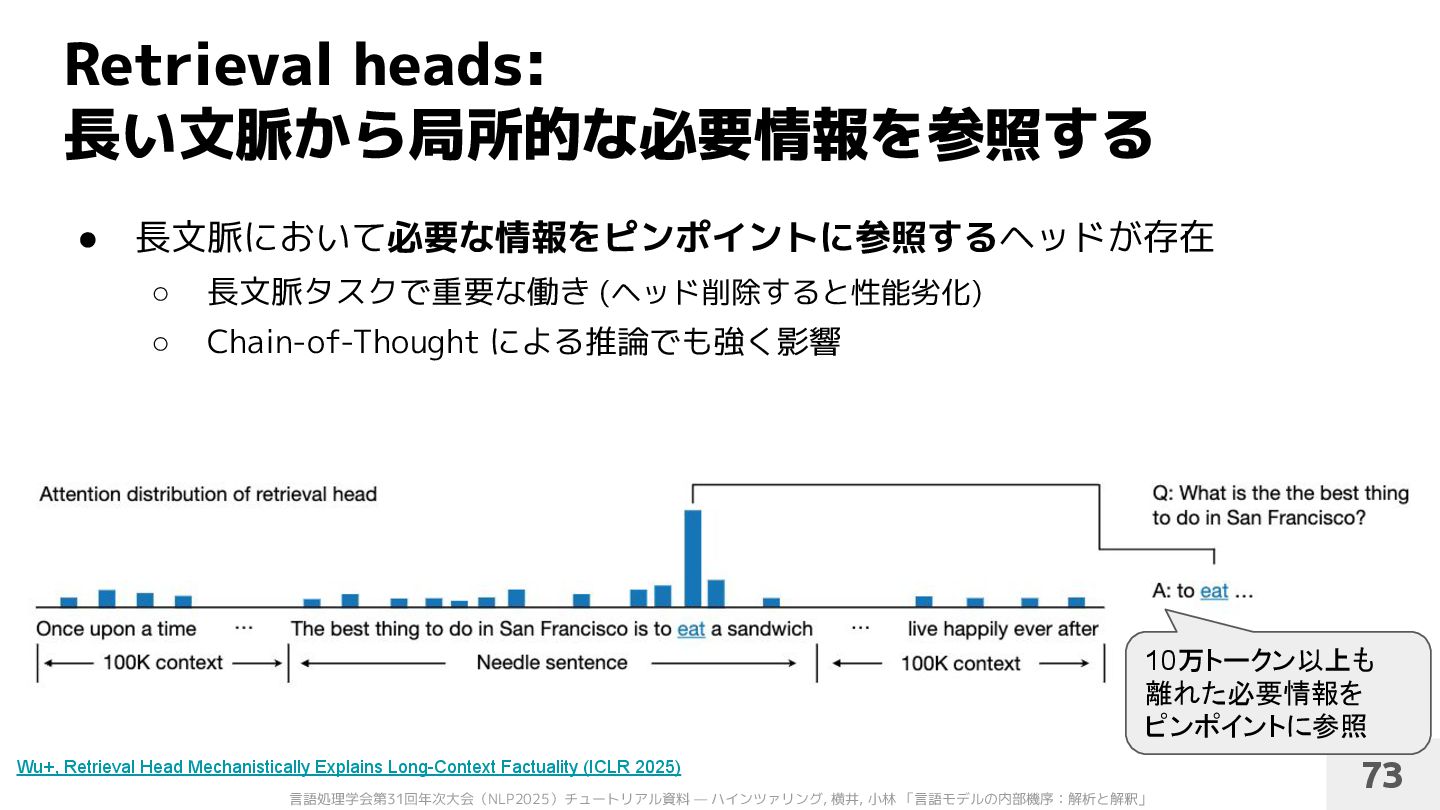
◦ 隣接する数トークンを強く参照する ヘッドが多く存在 [Clark+’19; Fu+’24] • 文脈を広く参照する (Global Attention) ◦ 入力に応じて文脈を広く参照する ヘッドも存在 [Fu+’24] 近い文脈の参照・遠い文脈の参照 [Fu+’24] 72 Clark+, What Does BERT Look at? An Analysis of BERT’s Attention (BlackboxNLP 2019) Fu+, MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression (arXiv 2024)
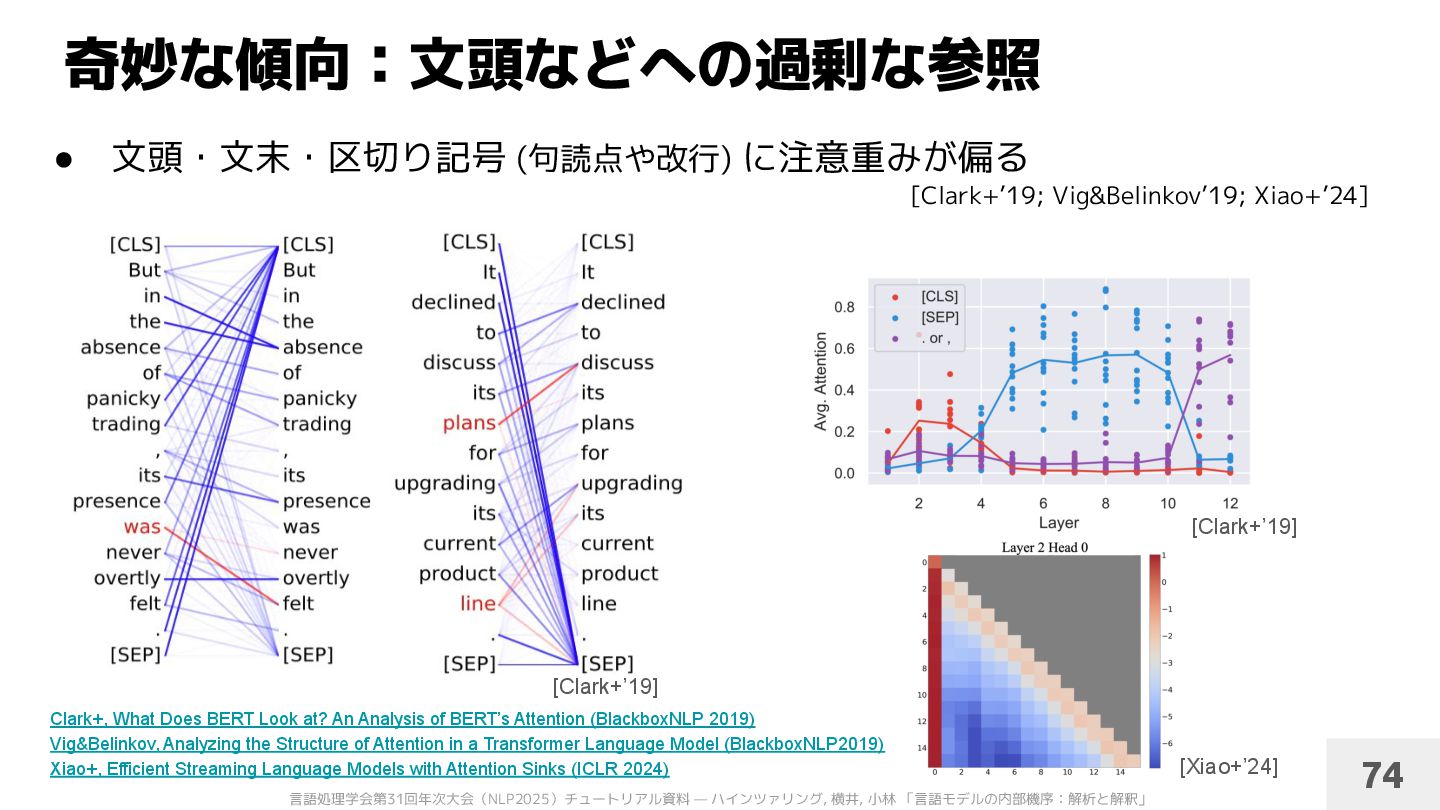
に注意重みが偏る [Clark+’19] [Clark+’19] [Xiao+’24] 74 [Clark+’19; Vig&Belinkov’19; Xiao+’24] Clark+, What Does BERT Look at? An Analysis of BERT’s Attention (BlackboxNLP 2019) Vig&Belinkov, Analyzing the Structure of Attention in a Transformer Language Model (BlackboxNLP2019) Xiao+, Efficient Streaming Language Models with Attention Sinks (ICLR 2024)
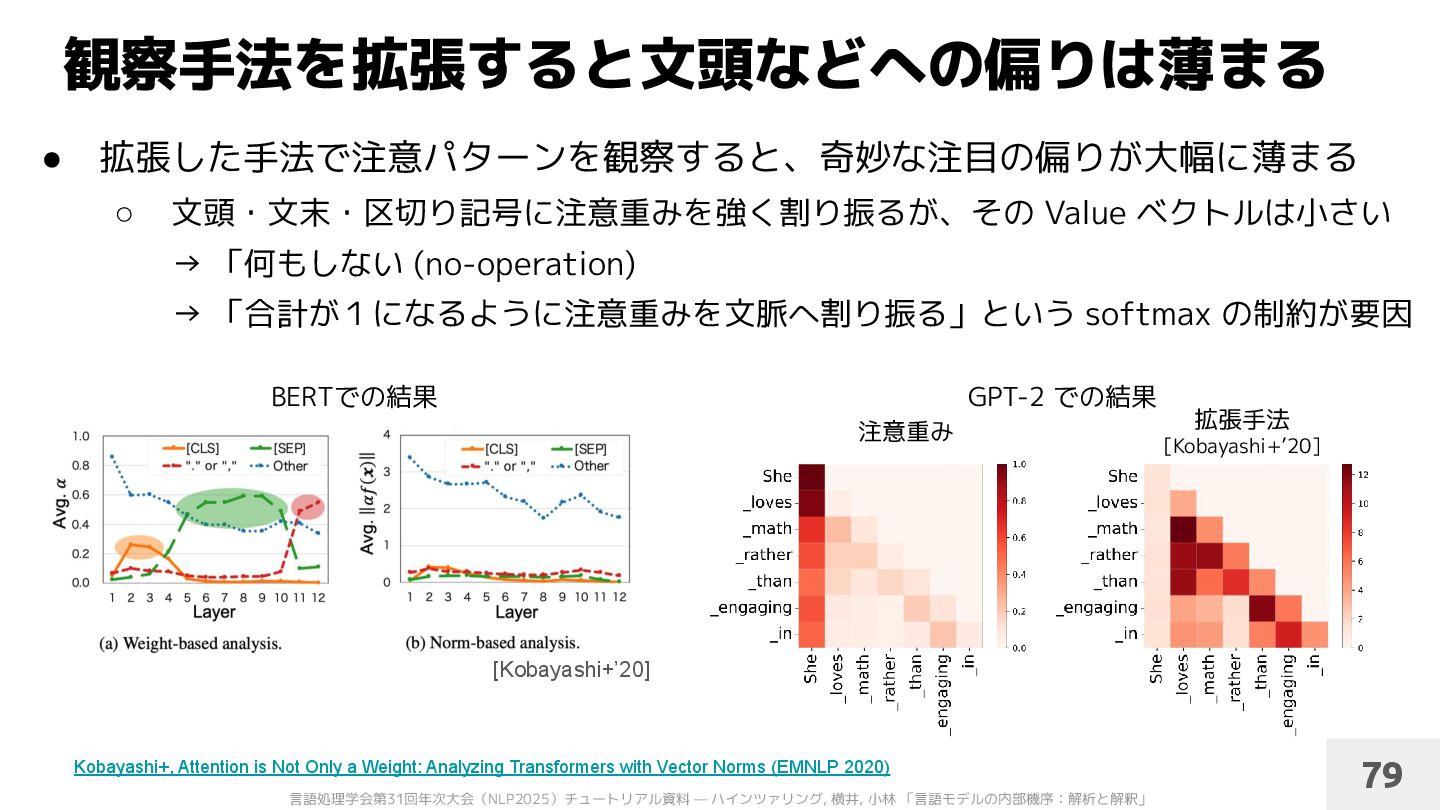
◦ 注意重みの値を置き換えても予測が大して変わらない ◦ タスクの重要情報に注意重みを割り振らない損失で学習しても、間接的に重要情報 にアクセスして十分なタスク性能を達成できる [Pruthi+’20] • 注意重みを拡張した手法が提案されている ◦ 注意重みから後段計算において本質的でない成分を除去する [Brunner+’20] ◦ Value ベクトルのノルムを考慮する [Kobayashi+’20] ◦ 注意機構以外のモジュールも考慮して注意パターンを観察する [Kobayashi+’21;’24] Kobayashi+, Attention is Not Only a Weight: Analyzing Transformers with Vector Norms (EMNLP 2020) Kobayashi+, Incorporating Residual and Normalization Layers into Analysis of Masked Language Models (EMNLP 2021) Kobayashi+, Analyzing Feed-Forward Blocks in Transformers through the Lens of Attention Maps (ICLR 2024) Jain&Wallace, Attention is not Explanation (NAACL 2019) Serrano&Smith, Is Attention Interpretable? (ACL 2019) Pruthi, Learning to Deceive with Attention-Based Explanations (ACL 2020) Brunner+, On Identifiability in Transformers (ICLR 2020) 注意重みに関する議論と拡張 78 [Jain&Wallace’19; Serrano&Smith’19]
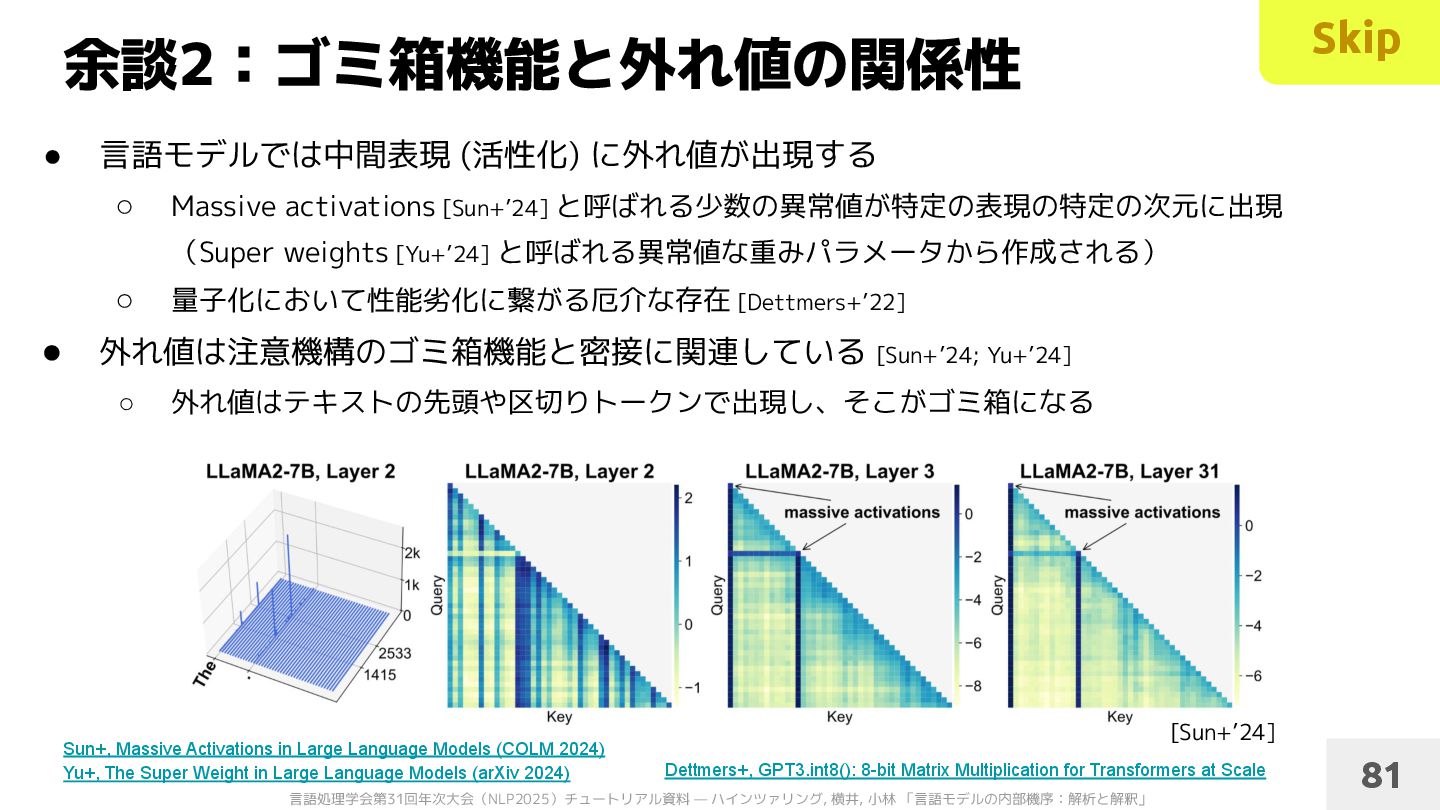
◦ Massive activations [Sun+’24] と呼ばれる少数の異常値が特定の表現の特定の次元に出現 (Super weights [Yu+’24] と呼ばれる異常値な重みパラメータから作成される) ◦ 量子化において性能劣化に繋がる厄介な存在 [Dettmers+’22] • 外れ値は注意機構のゴミ箱機能と密接に関連している [Sun+’24; Yu+’24] ◦ 外れ値はテキストの先頭や区切りトークンで出現し、そこがゴミ箱になる 余談2:ゴミ箱機能と外れ値の関係性 Sun+, Massive Activations in Large Language Models (COLM 2024) Yu+, The Super Weight in Large Language Models (arXiv 2024) [Sun+’24] 81 Dettmers+, GPT3.int8(): 8-bit Matrix Multiplication for Transformers at Scale Skip
Outliers by Helping Attention Heads Do Nothing (NeurIPS 2023) Miller+, Attention Is Off By One (blog post 2023) Sun+, Massive Activations in Large Language Models (COLM 2024) • 「注意重みの合計が1」という制約を無くすように softmax を改変 • 各注意機構で系列の先頭に学習可能な Key/Value を足すように設計する[Sun+’24] 余談4:ゴミ箱・外れ値の緩和 [Bondarenko+’23] [Miller+’23] 83 [Sun+’24] [Miller+’23; Bondarenko+’23] それぞれ小さめモデルの事前学習で外れ値が緩和 → 量子化しやすいモデル構築に期待 Skip
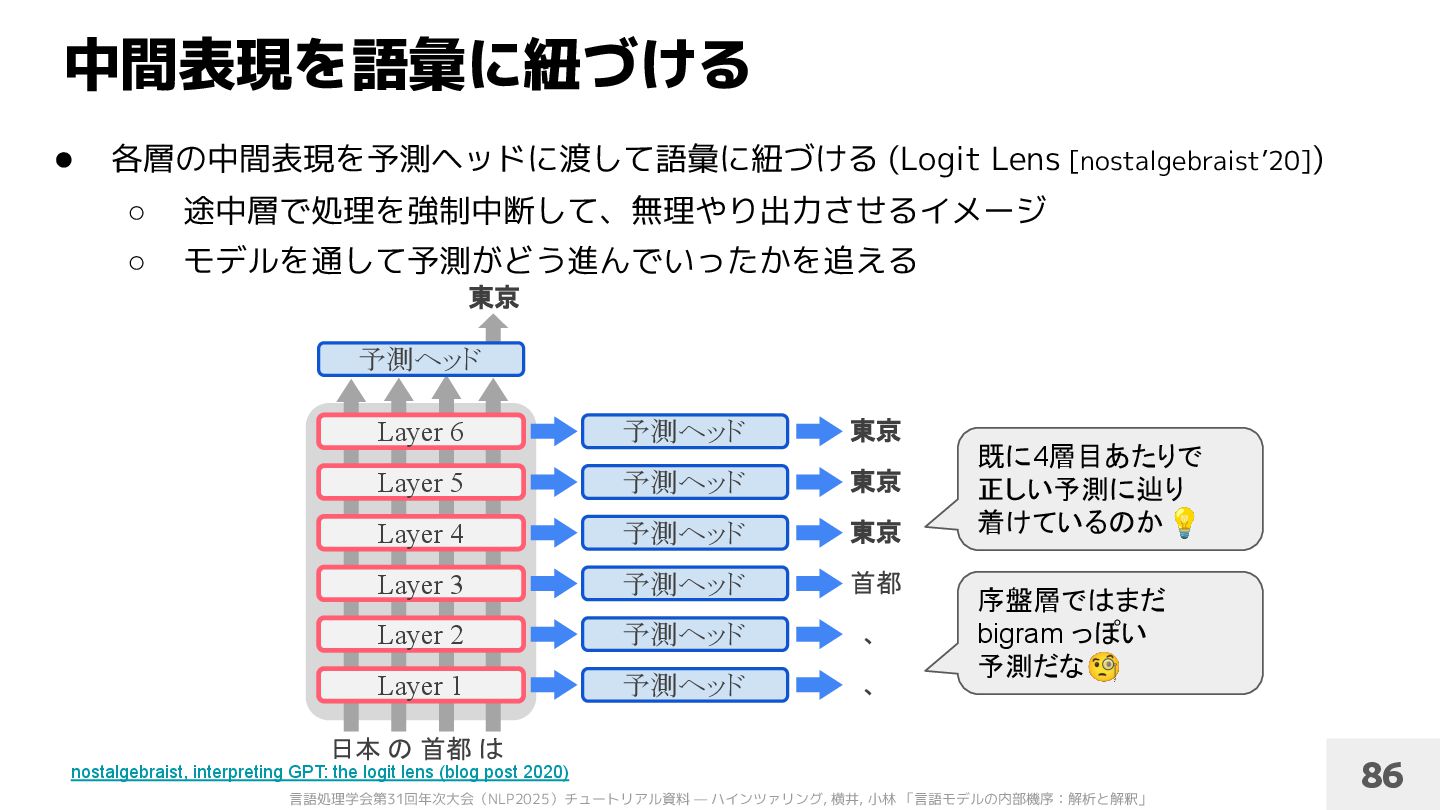
Do Llamas Work in English? On the Latent Language of Multilingual Transformers (ACL 2024) 層 88 • 各層の中間表現を予測ヘッドに渡して語彙に紐づける (Logit Lens [nostalgebraist’20]) ◦ モデルを通して予測がどう進んでいったかを追える ◦ 非英語言語を処理する際、中間層では英語 (第一言語?) で意味処理をしている? [Wendler+’24] Skip
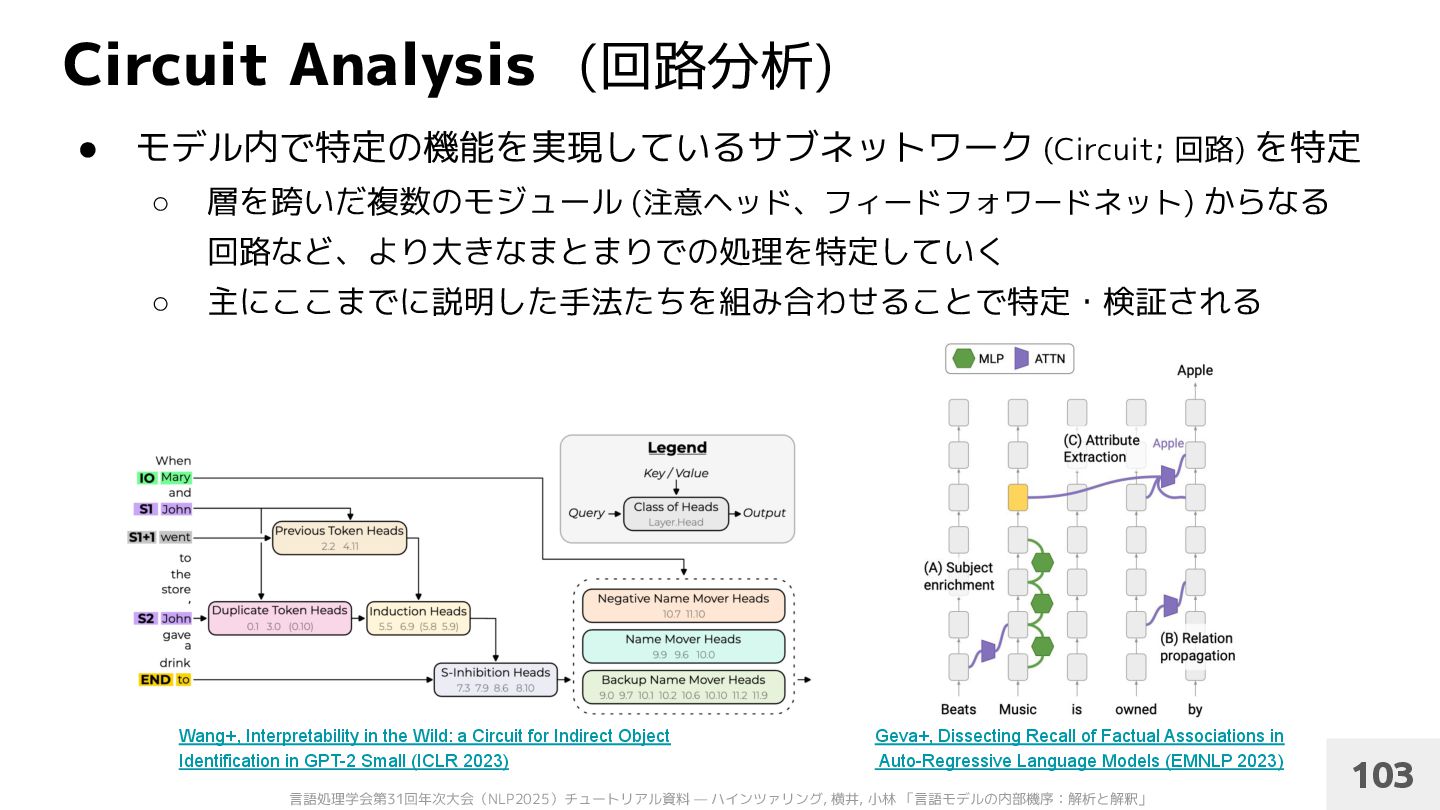
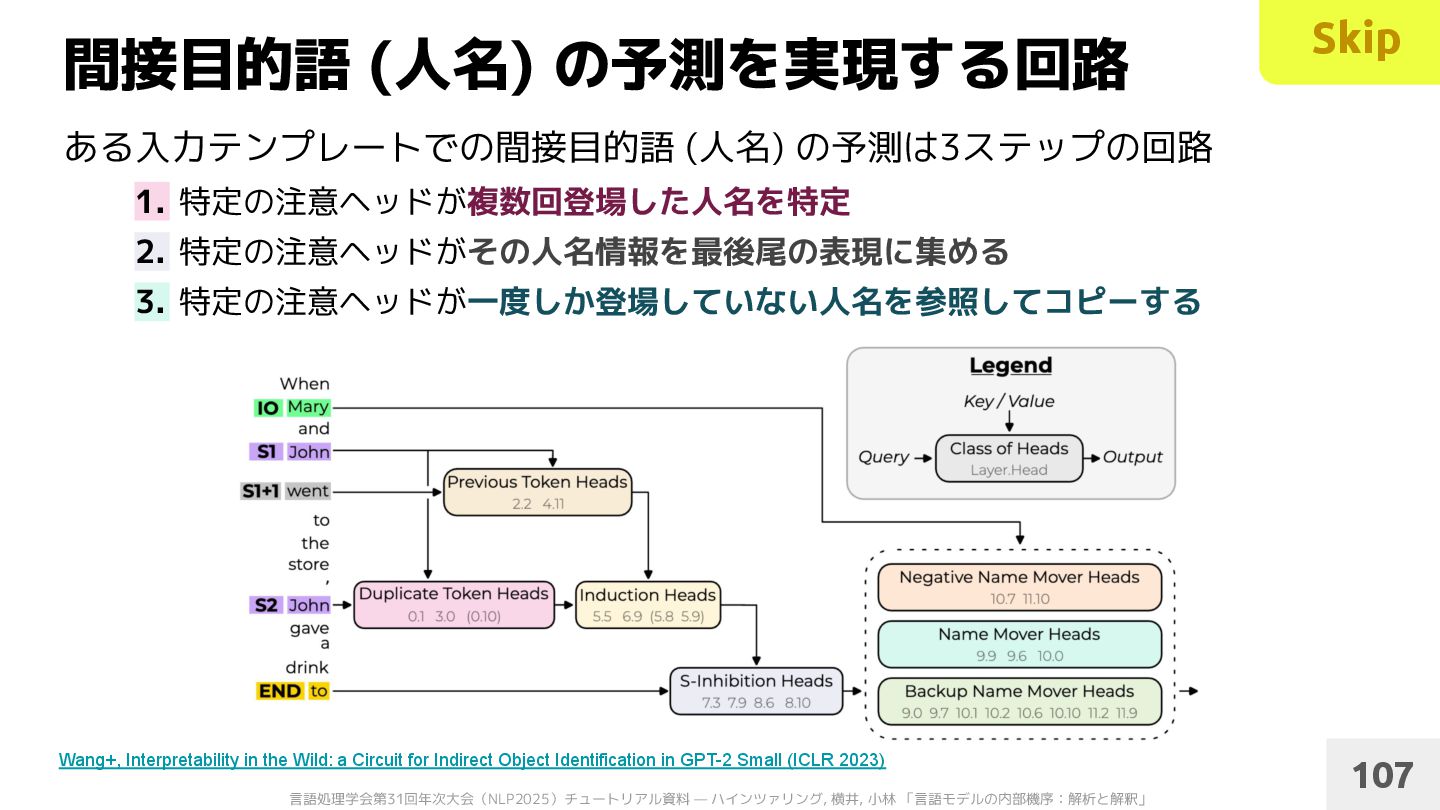
特定の注意ヘッドが複数回登場した人名を特定 2. 特定の注意ヘッドがその人名情報を最後尾の表現に集める 3. 特定の注意ヘッドが一度しか登場していない人名を参照してコピーする 間接目的語 (人名) の予測を実現する回路 107 Wang+, Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small (ICLR 2023) Skip
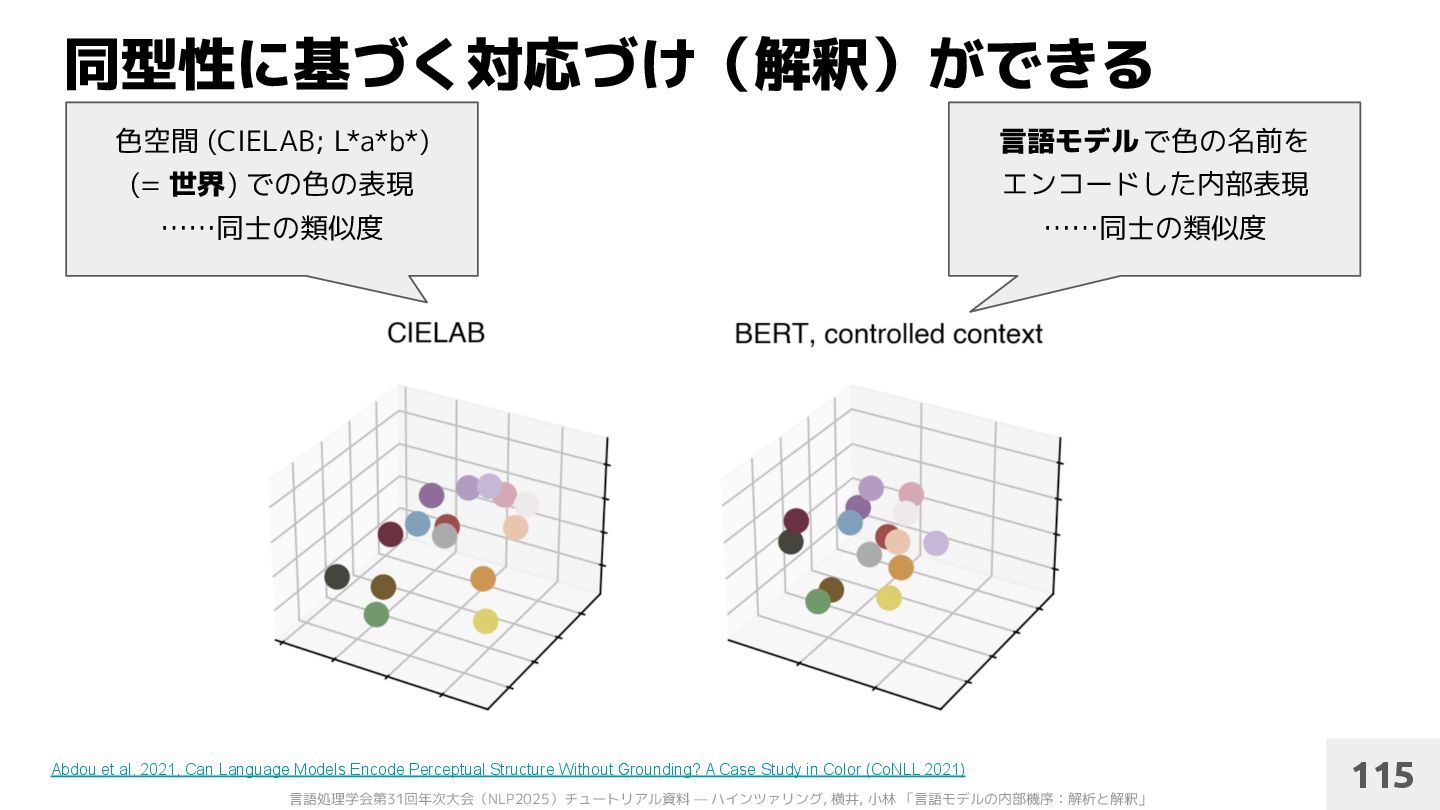
al. 2021, Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color (CoNLL 2021) 言語モデル で色の名前を エンコードした内部表現 ……同士の類似度 色空間 (CIELAB; L*a*b*) (= 世界) での色の表現 ……同士の類似度
は直接的には世界と接していないが, センサー・アクチュエータ系としてのヒトの集団は世界と接している • このヒトの集団が世界と接しながら言葉を紡いで残したのがコーパス • 映画『マトリックス』の世界のように, 巨大な脳としてのコーパス/言語モデルが, “ロープ” で繋がれた人間の集団を介して世界と接している? 116 Taniguchi+, Generative Emergent Communication: Large Language Model is a Collective World Model (arXiv 2025-01) Skip
世界の構造が言語モデルに転写されていることの実用的側面: 内部表象が世界の構造を捉えている ⇔ モデルの予測が汎化する 118 Liu et al., 2022: Towards Understanding Grokking: An Effective Theory of Representation Learning 例:mod 60 の足し算を学習したモデルの表現空間 (たとえば時計の秒針や分針の位置) 予測が汎化できている ⇔ 表現空間で世界(=mod 60の足 し算)が捉えられている
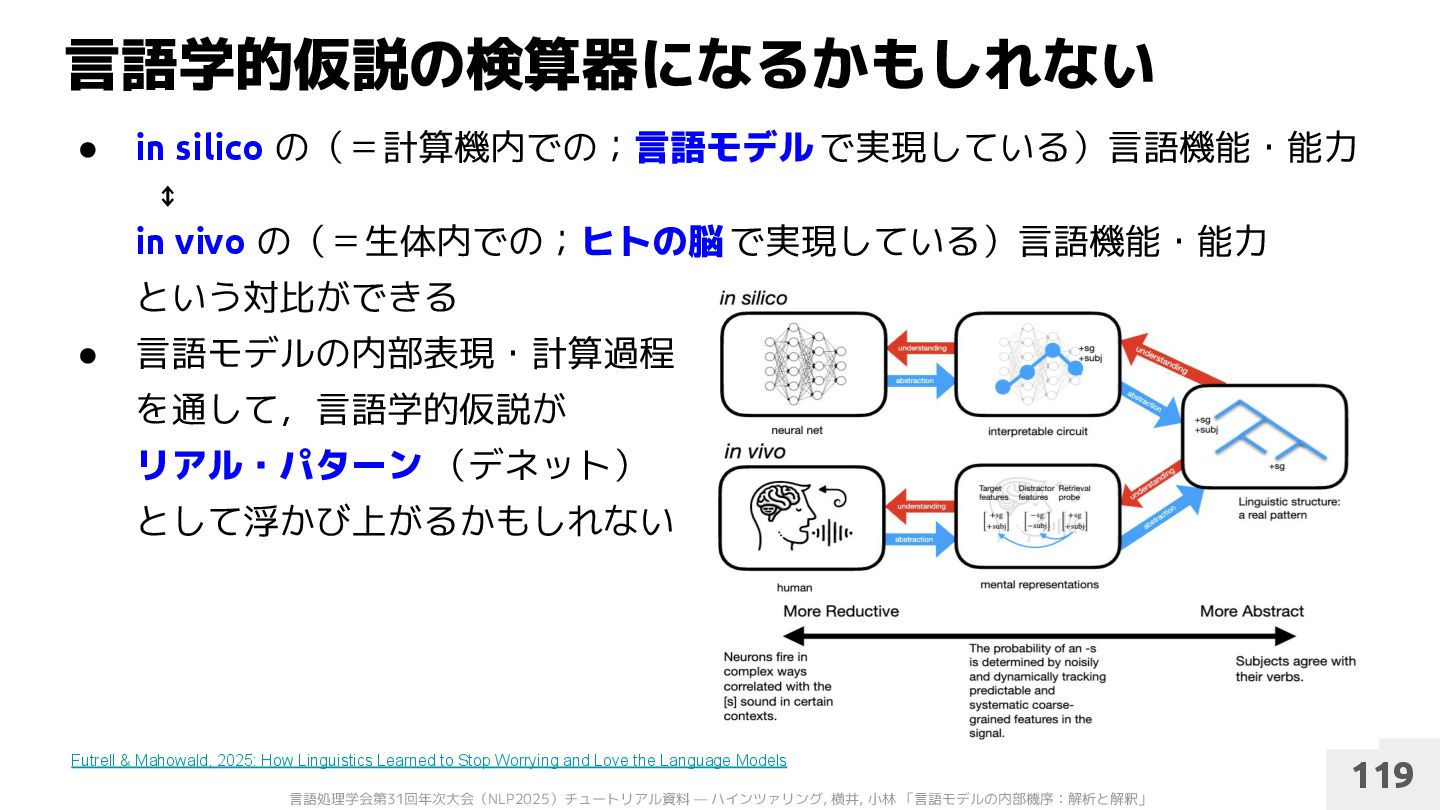
の(=計算機内での;言語モデル で実現している)言語機能・能力 ↕ in vivo の(=生体内での;ヒトの脳で実現している)言語機能・能力 という対比ができる • 言語モデルの内部表現・計算過程 を通して,言語学的仮説が リアル・パターン (デネット) として浮かび上がるかもしれない 119 Futrell & Mahowald, 2025: How Linguistics Learned to Stop Worrying and Love the Language Models
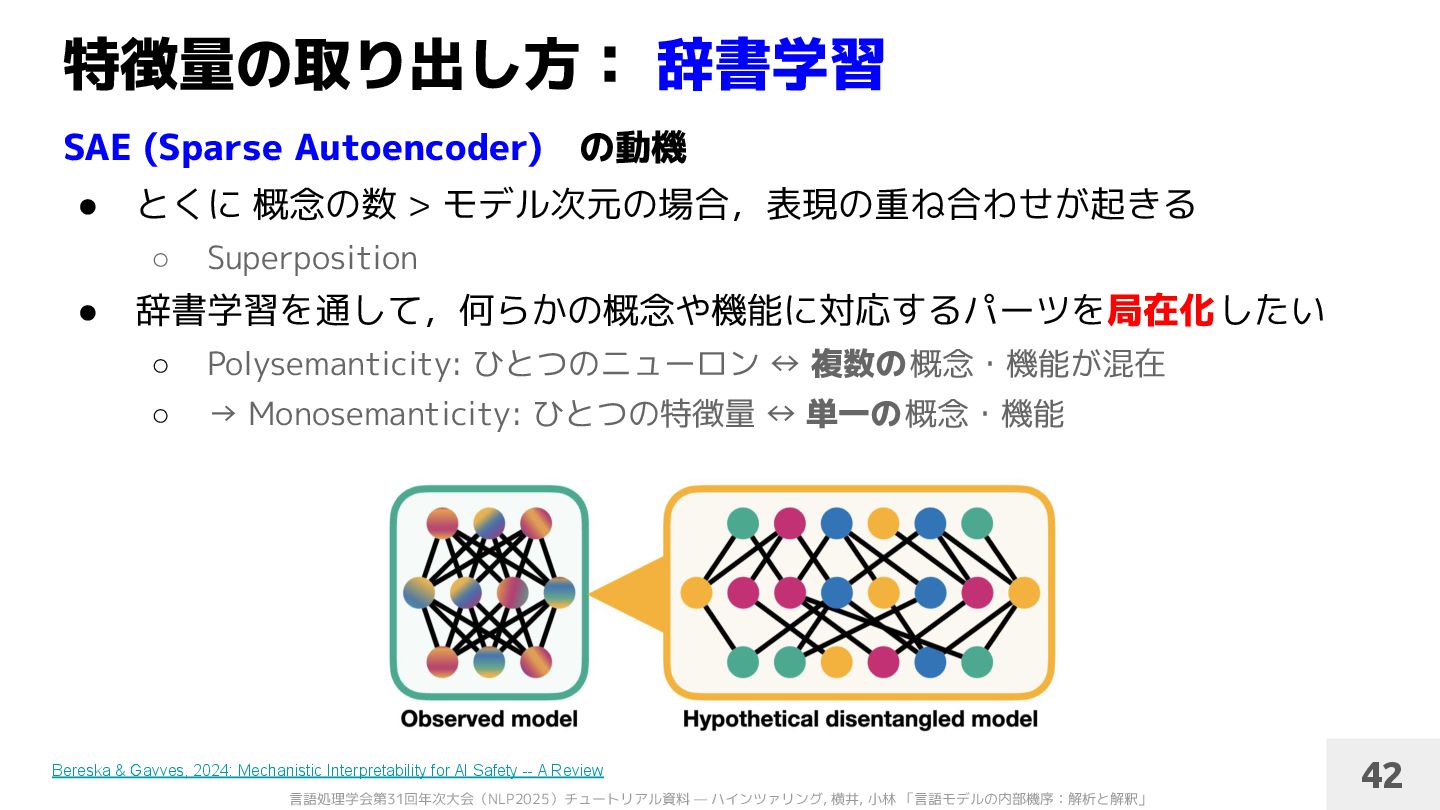
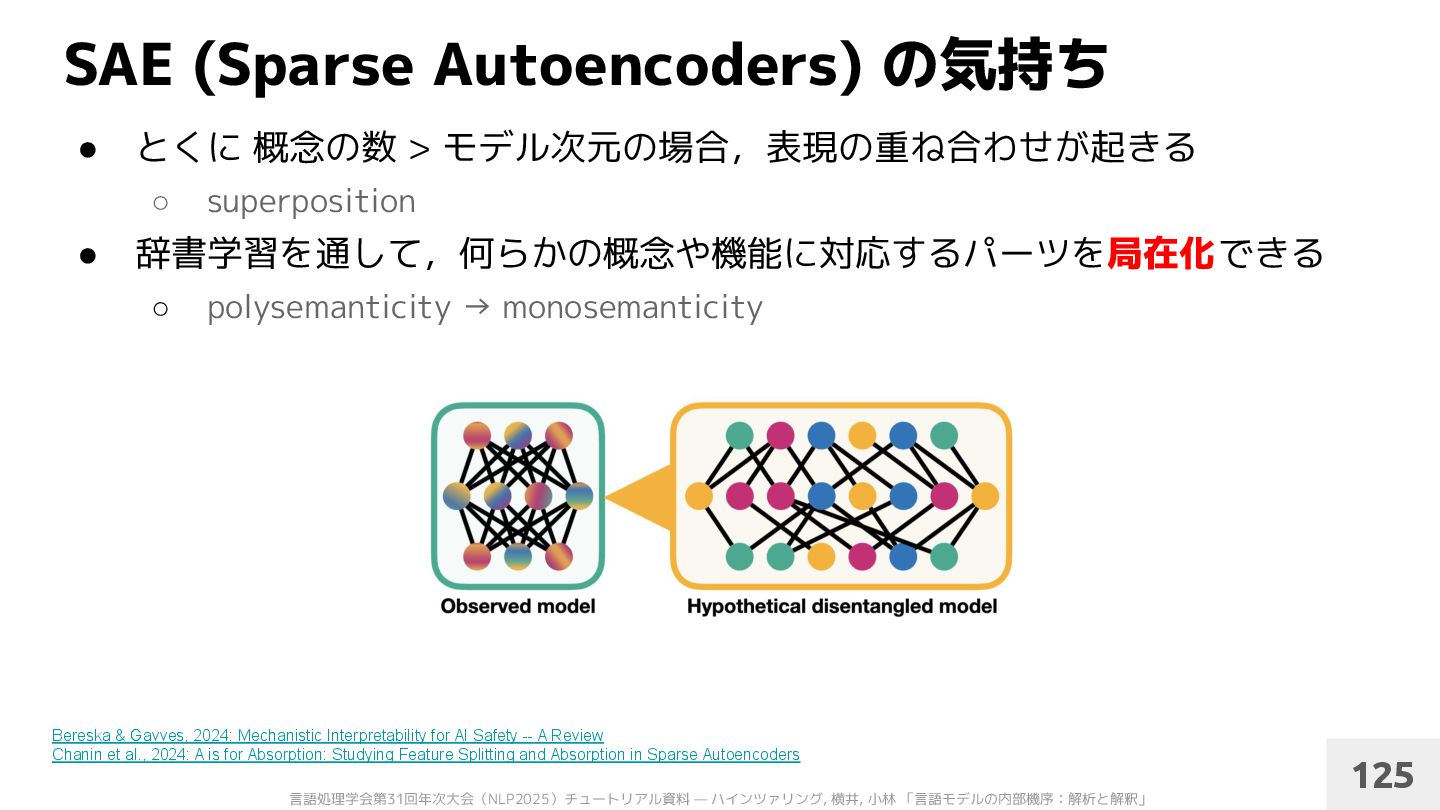
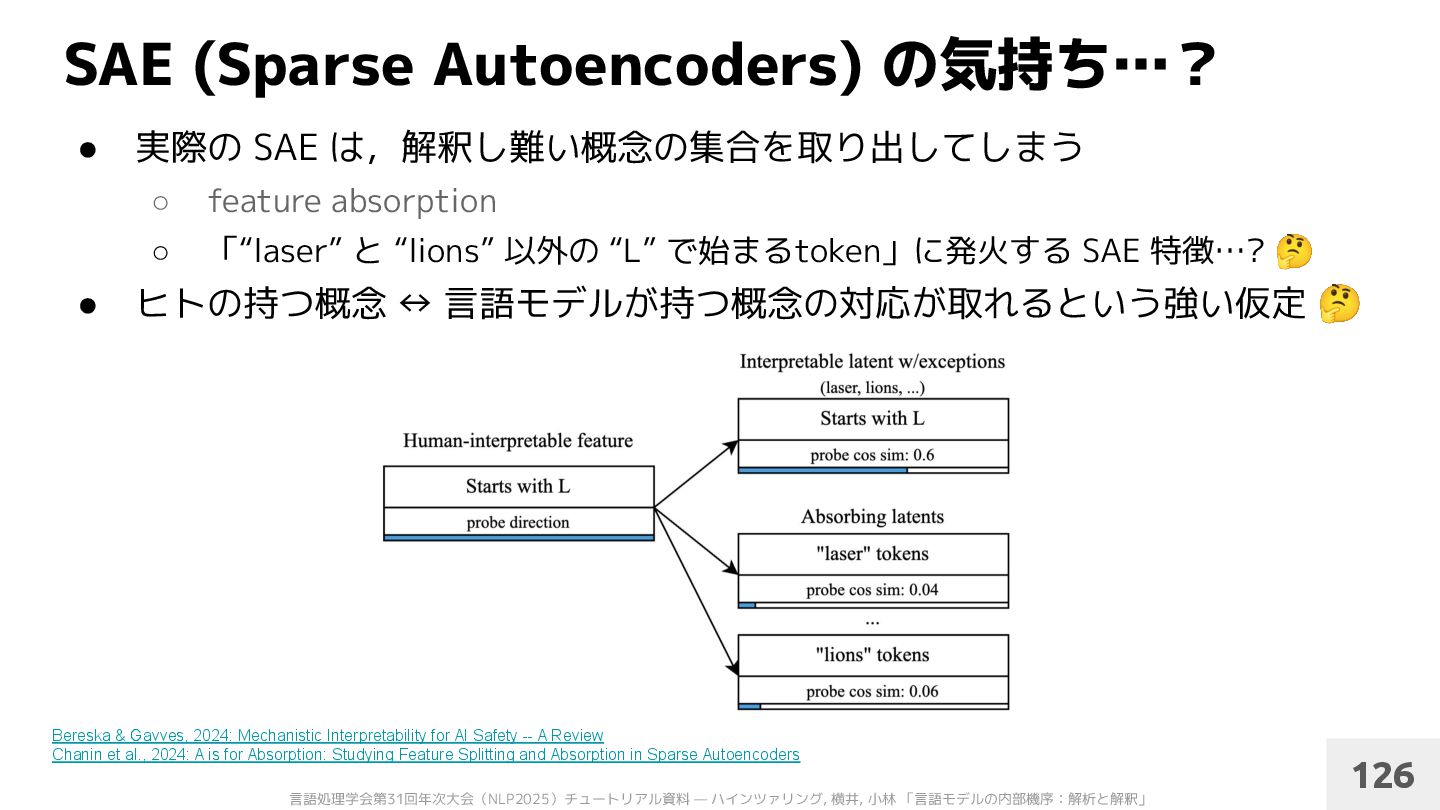
• とくに 概念の数 > モデル次元の場合,表現の重ね合わせが起きる ◦ superposition • 辞書学習を通して,何らかの概念や機能に対応するパーツを局在化できる ◦ polysemanticity → monosemanticity 125 Bereska & Gavves, 2024: Mechanistic Interpretability for AI Safety -- A Review Chanin et al., 2024: A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders
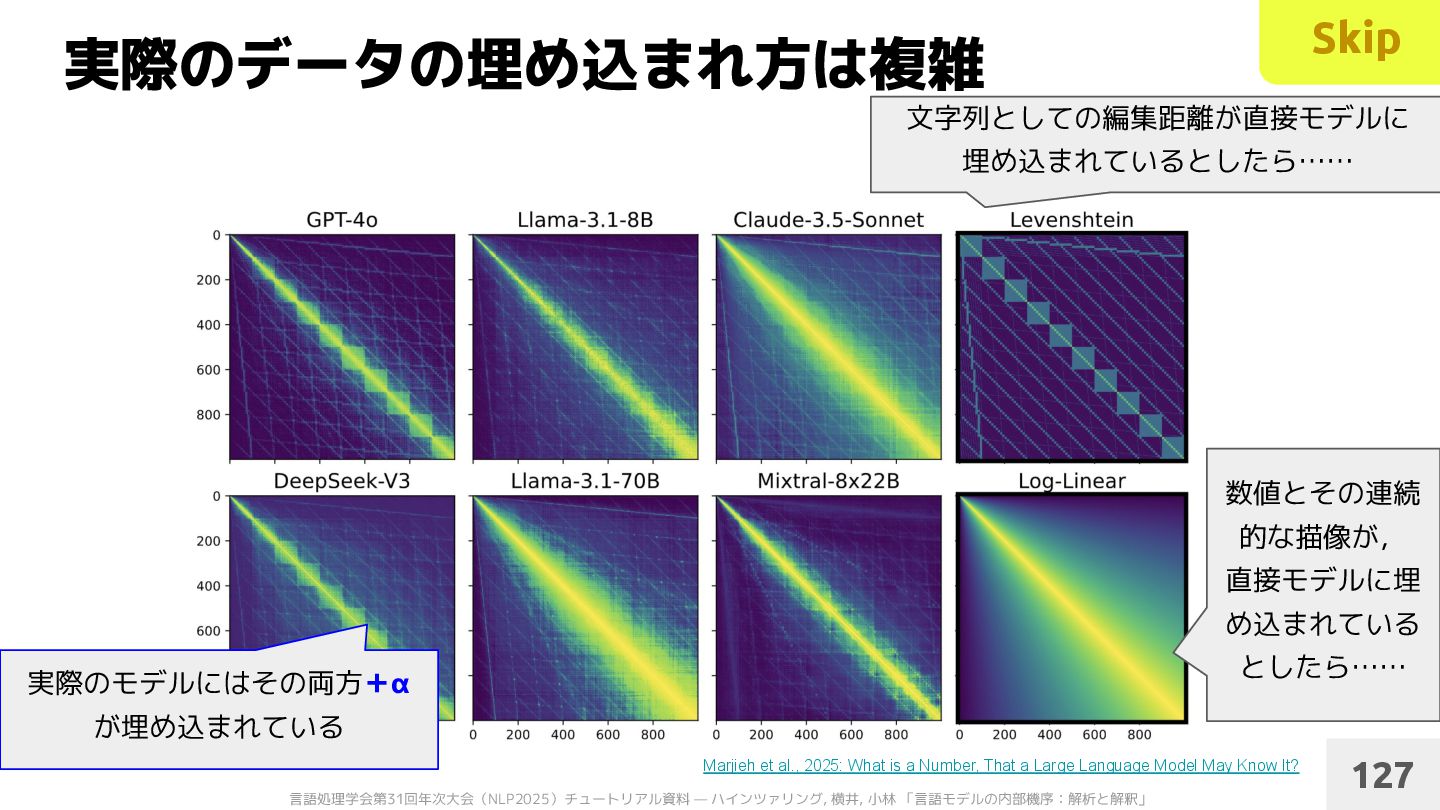
2025: What is a Number, That a Large Language Model May Know It? 127 数値とその連続 的な描像が, 直接モデルに埋 め込まれている としたら…… 文字列としての編集距離が直接モデルに 埋め込まれているとしたら…… 実際のモデルにはその両方+α が埋め込まれている Skip
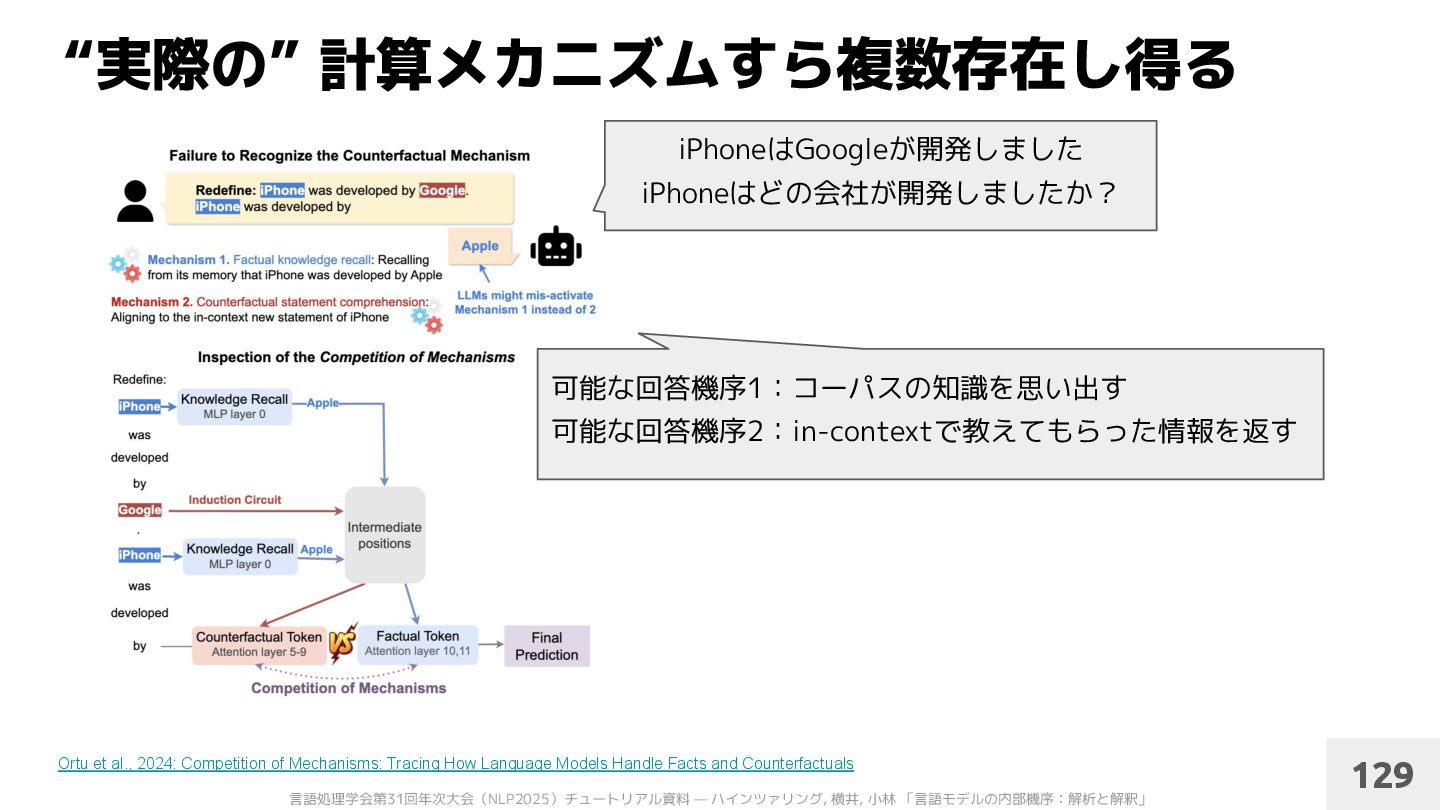
al., 2024: Competition of Mechanisms: Tracing How Language Models Handle Facts and Counterfactuals 129 iPhoneはGoogleが開発しました iPhoneはどの会社が開発しましたか? 可能な回答機序1:コーパスの知識を思い出す 可能な回答機序2:in-contextで教えてもらった情報を返す
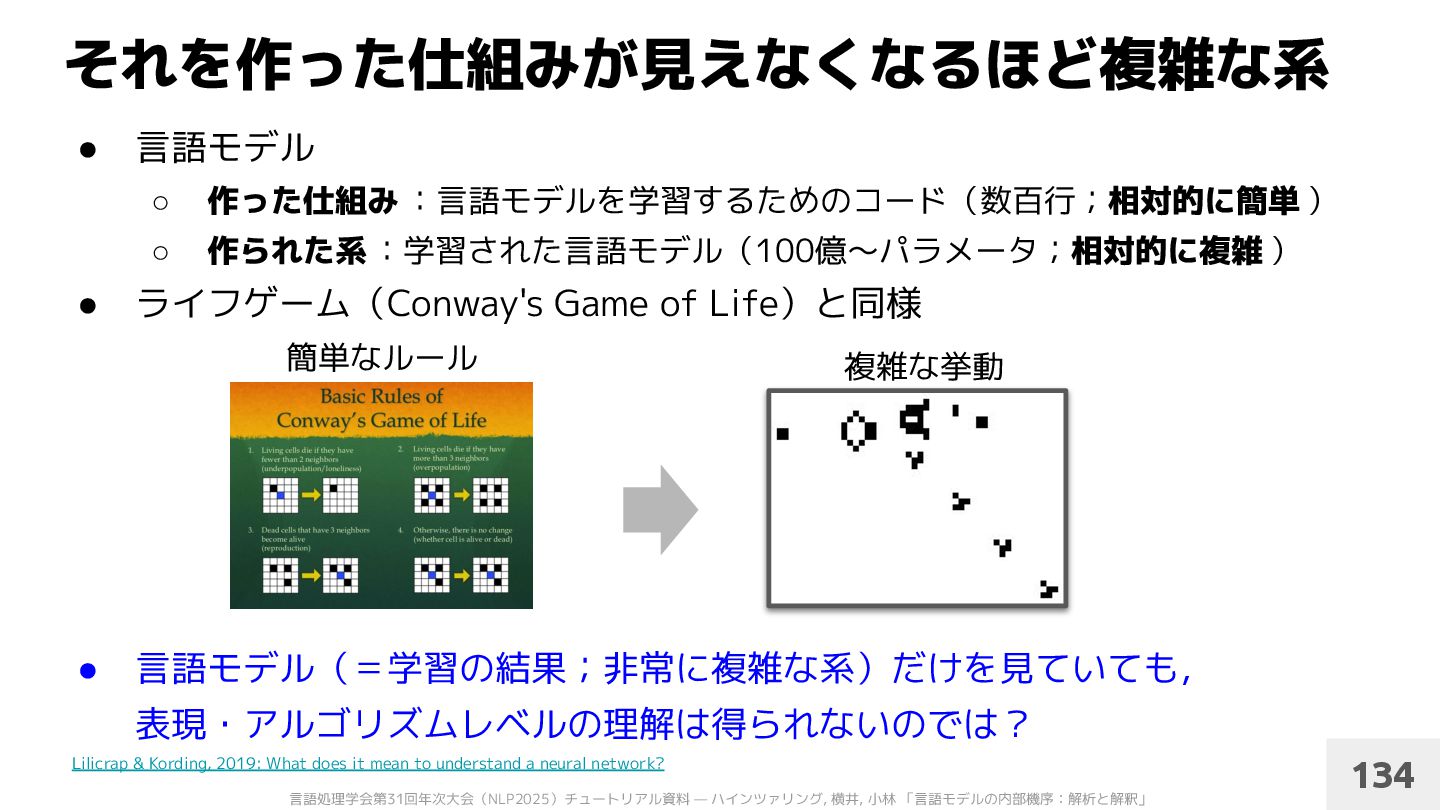
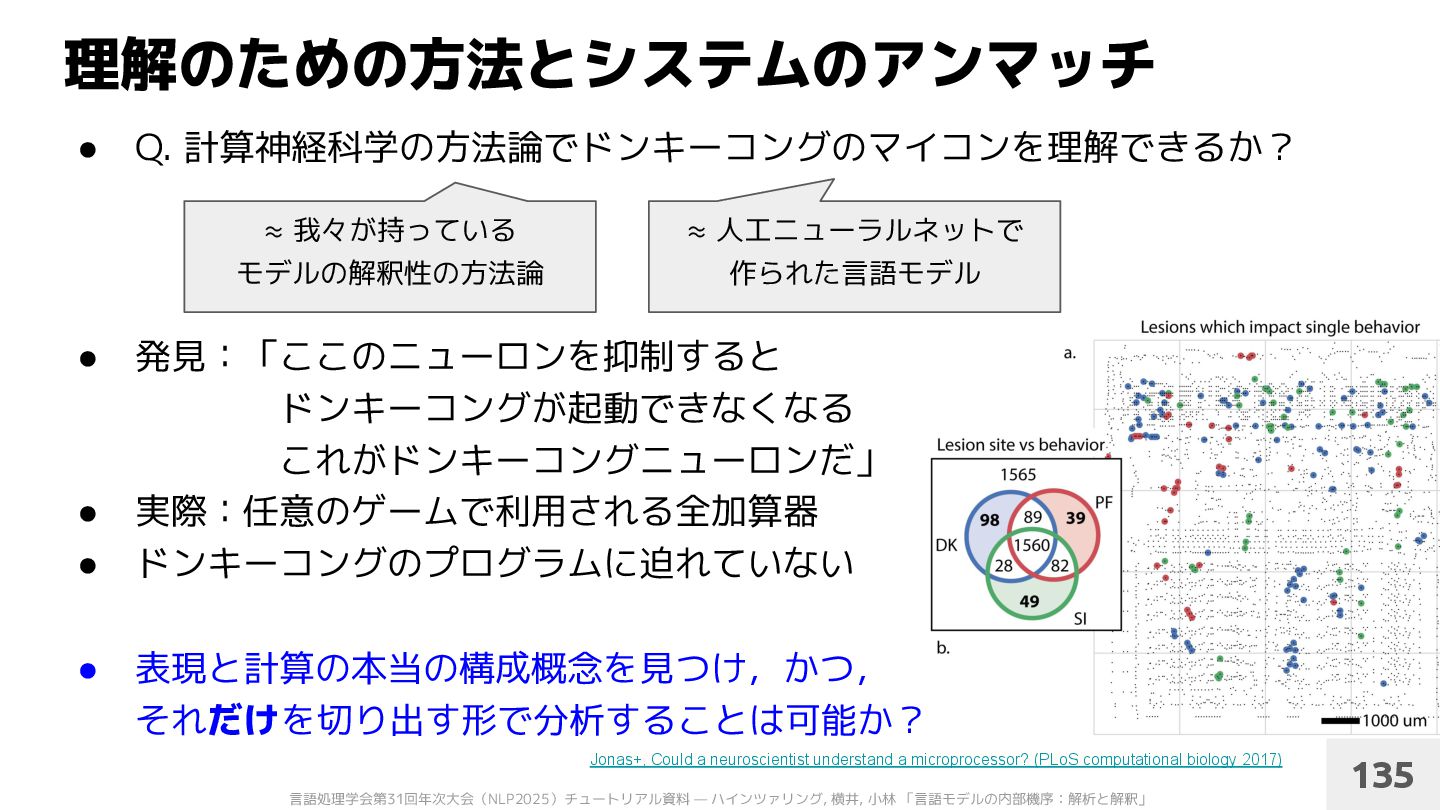
作った仕組み :言語モデルを学習するためのコード(数百行;相対的に簡単 ) ◦ 作られた系 :学習された言語モデル(100億〜パラメータ;相対的に複雑 ) • ライフゲーム(Conway's Game of Life)と同様 • 言語モデル(=学習の結果;非常に複雑な系)だけを見ていても, 表現・アルゴリズムレベルの理解は得られないのでは? 134 簡単なルール 複雑な挙動 Lilicrap & Kording, 2019: What does it mean to understand a neural network?
• 説明可能性 具体的なステークホルダーに対して彼ら彼女らがわかる形で洞察を提供 137 Calderon & Reichart, 2024: On Behalf of the Stakeholders: Trends in NLP Model Interpretability in the Era of LLMs
目的:評価,デバッグ,汎化,知識編集,… Calderon & Reichart, 2024: On Behalf of the Stakeholders: Trends in NLP Model Interpretability in the Era of LLMs ステークホルダー:“理学的” な関心を持つ人 目的:理論の整備,新発見,仮説生成,… こちらにも膨大な領域 ステークホルダー:ビジネスに関心を持つ人,社会全体 目的:意思決定,信頼性,安全性,公平性,……
沿って動かすと,出力されるこの有名人の生まれ年が変わる. 例2:時間を司る「軸」の存在(再掲) Heinzerling & Inui 2024: Monotonic Representation of Numeric Properties in Language Models 141 Q. カールポパーの生まれ年は? A. 1902 誕生年軸を手前に動かすと… 誕生年軸を奥側に動かすと… A. 1975 A. 1881
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![言語処理学会第31回年次大会(NLP2025)チュートリアル資料 — ハインツァリング, 横井, 小林 「言語モデルの内部機序:解析と解釈」 • 仮説:ゴミ箱機能のために外れ値を学習 [Bondarenko+’23] 1.](https://files.speakerdeck.com/presentations/34463d58208d4999832c40cca50e5ea1/slide_81.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}