EBPF is getting popular and popular. In this talk I will reintroduce it, and will describe what is the state of the art and how we can leverage it to solve problems related to performance, security and networking.
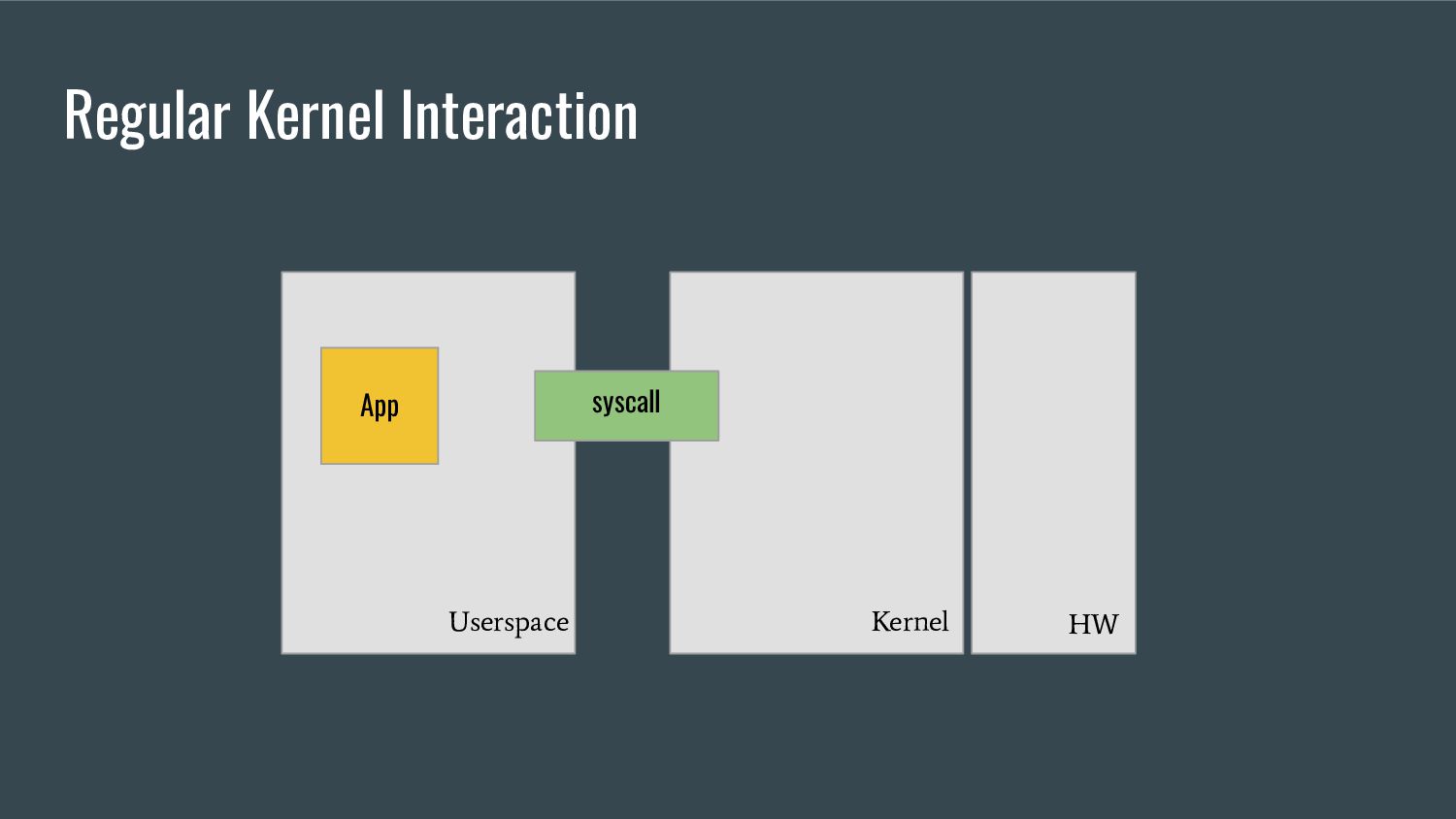
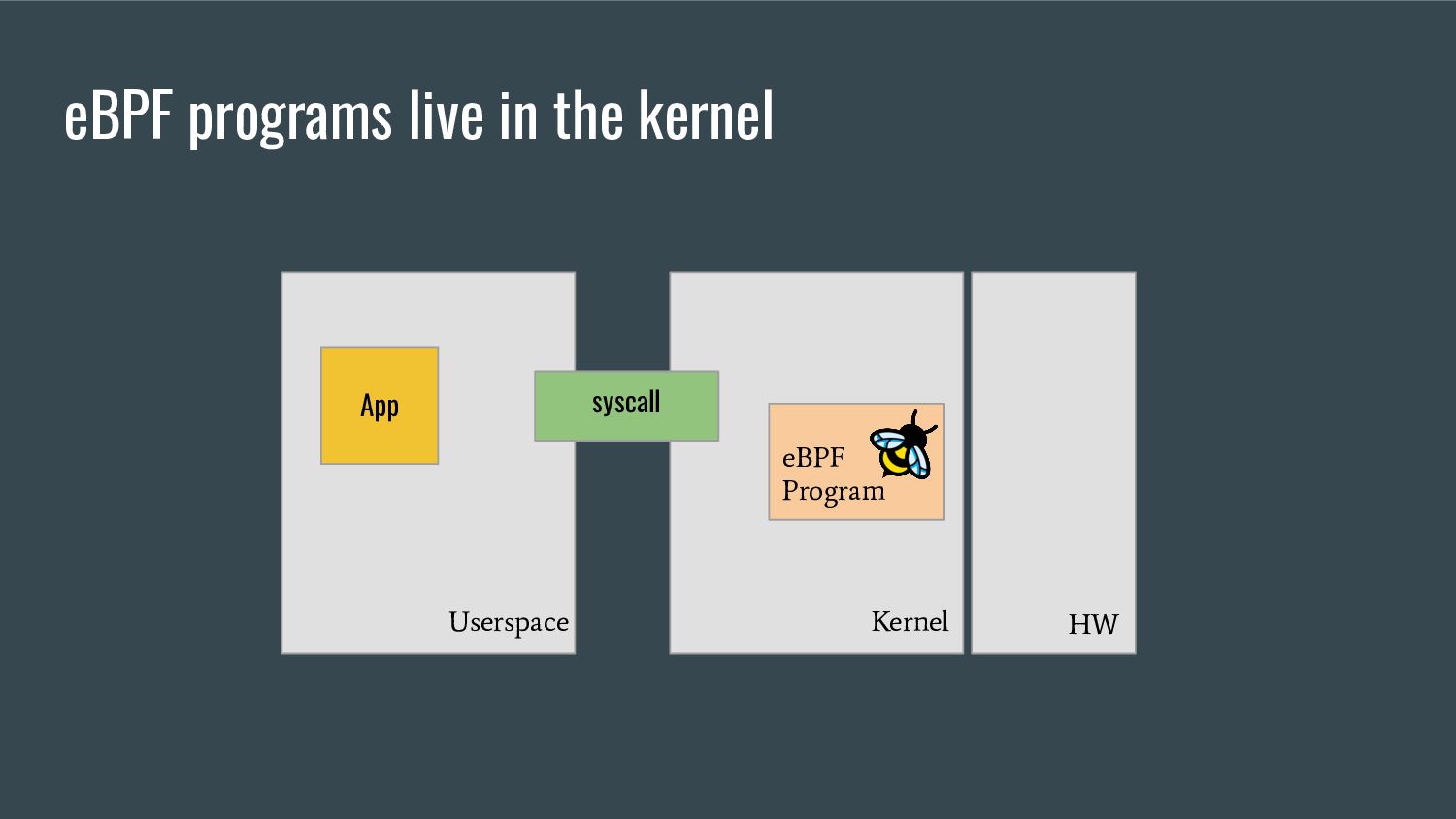
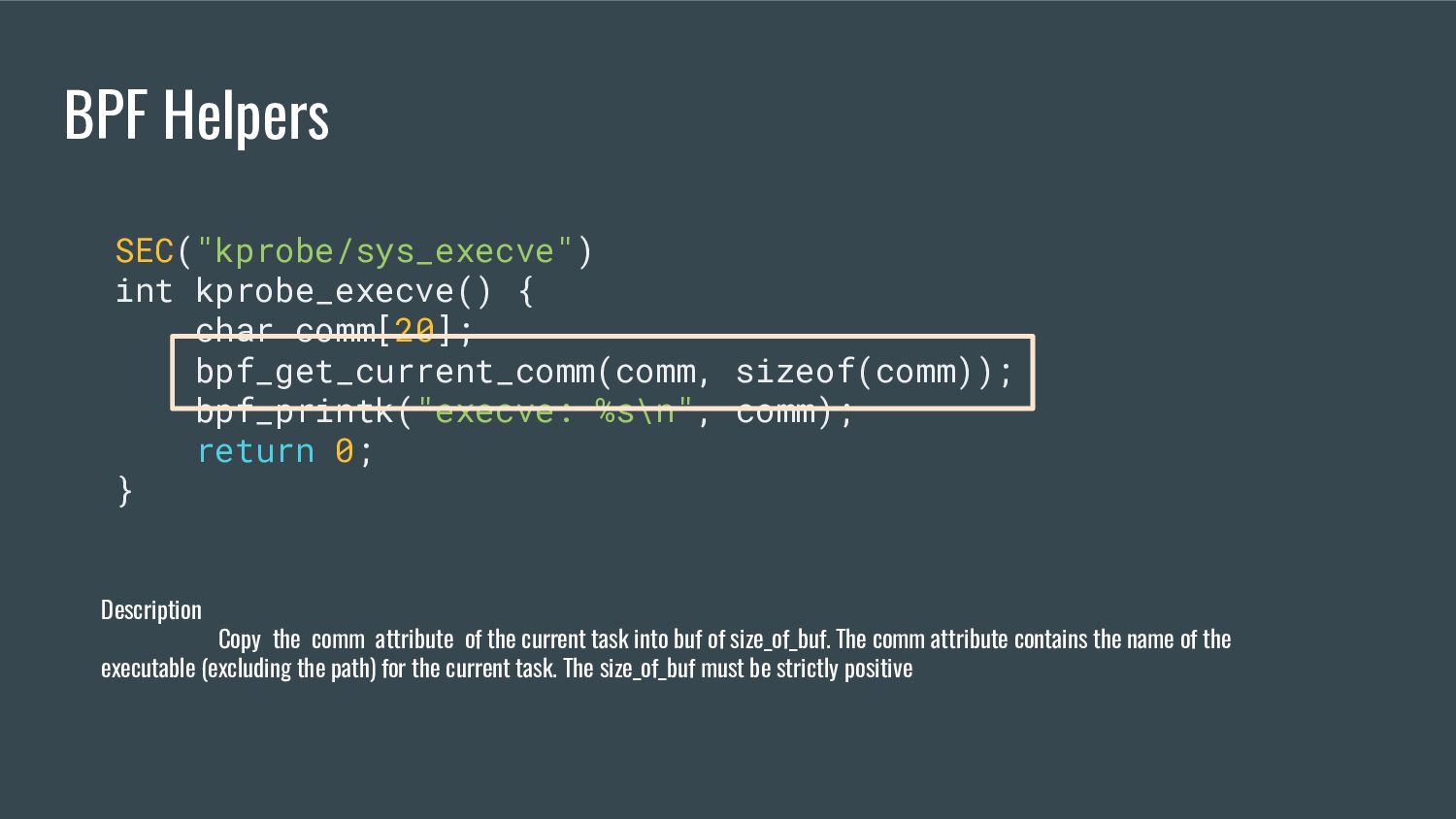
"cBPF") in several aspects, one of them being the ability to call special functions (or "helpers") from within a program - These helpers are used by eBPF programs to interact with the system, or with the context in which they work - each program type can only call a subset of those helpers from man bpf-helpers
task into buf of size_of_buf. The comm attribute contains the name of the executable (excluding the path) for the current task. The size_of_buf must be strictly positive SEC("kprobe/sys_execve") int kprobe_execve() { char comm[20]; bpf_get_current_comm(comm, sizeof(comm)); bpf_printk("execve: %s\n", comm); return 0; }
task into buf of size_of_buf. The comm attribute contains the name of the executable (excluding the path) for the current task. The size_of_buf must be strictly positive SEC("kprobe/sys_execve") int kprobe_execve() { char comm[20]; bpf_get_current_comm(comm, sizeof(comm)); bpf_printk("execve: %s\n", comm); return 0; }
buf of size_of_buf. The comm attribute contains the name of the executable (excluding the path) for the current task. The size_of_buf must be strictly positive
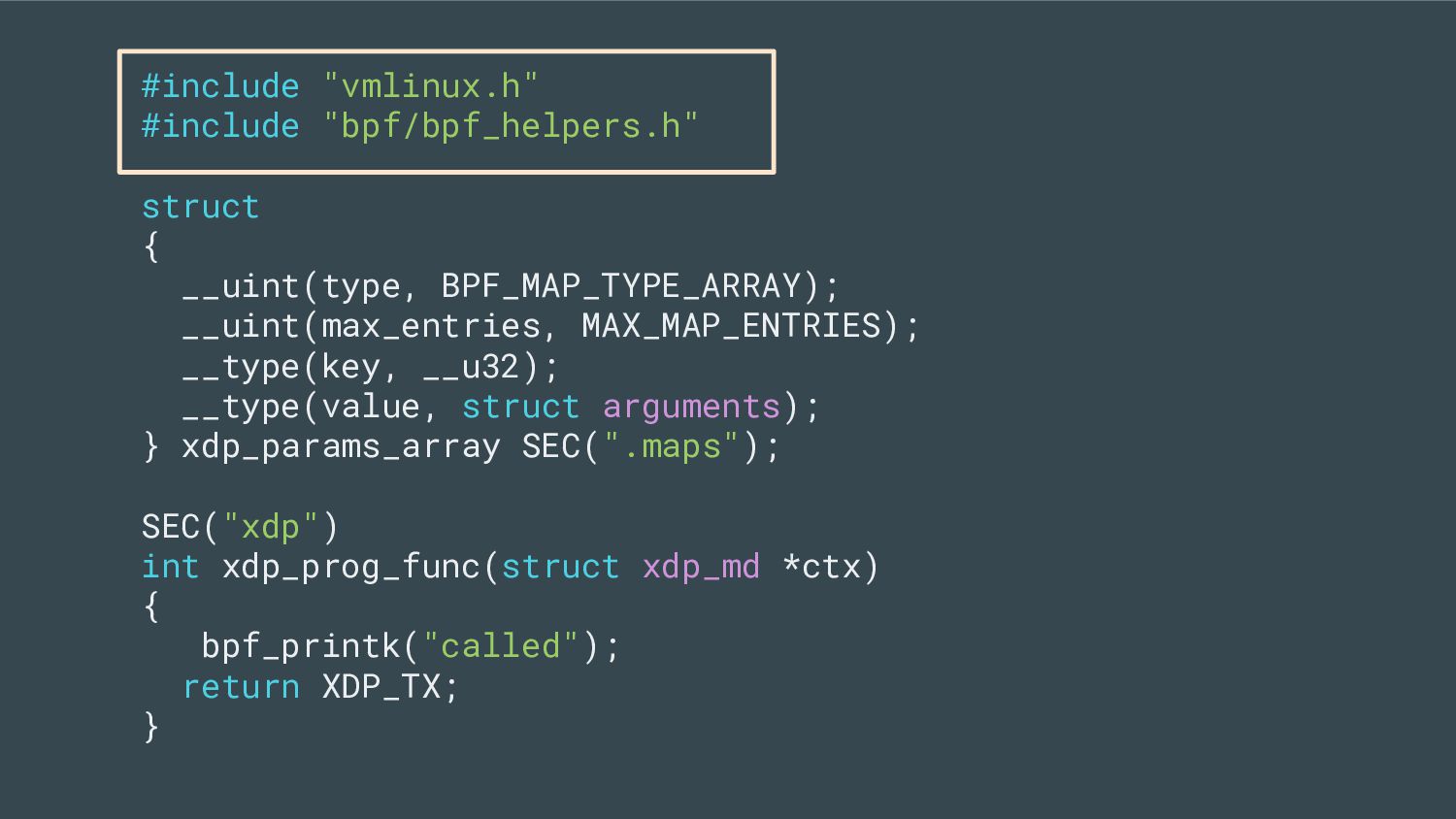
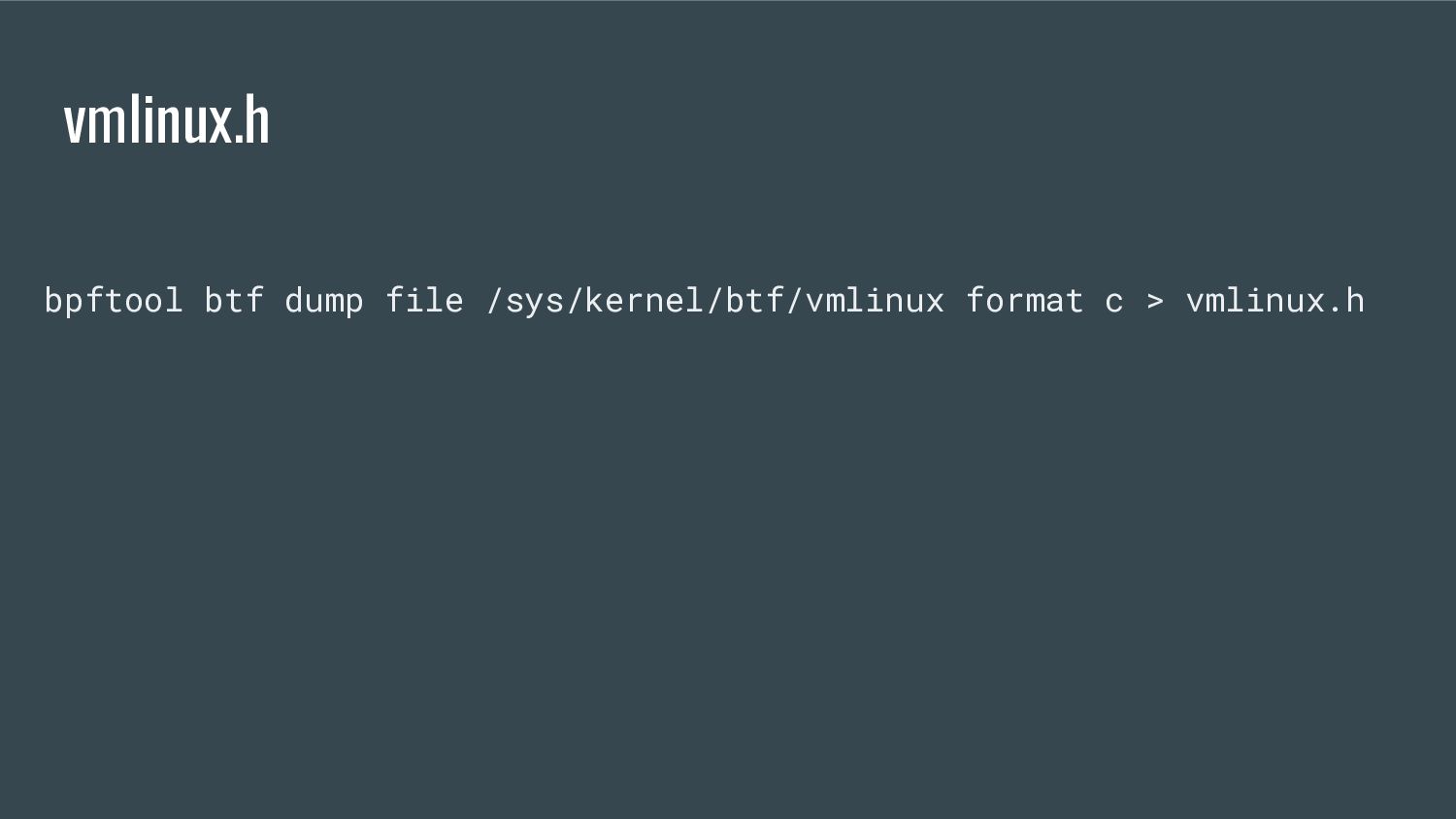
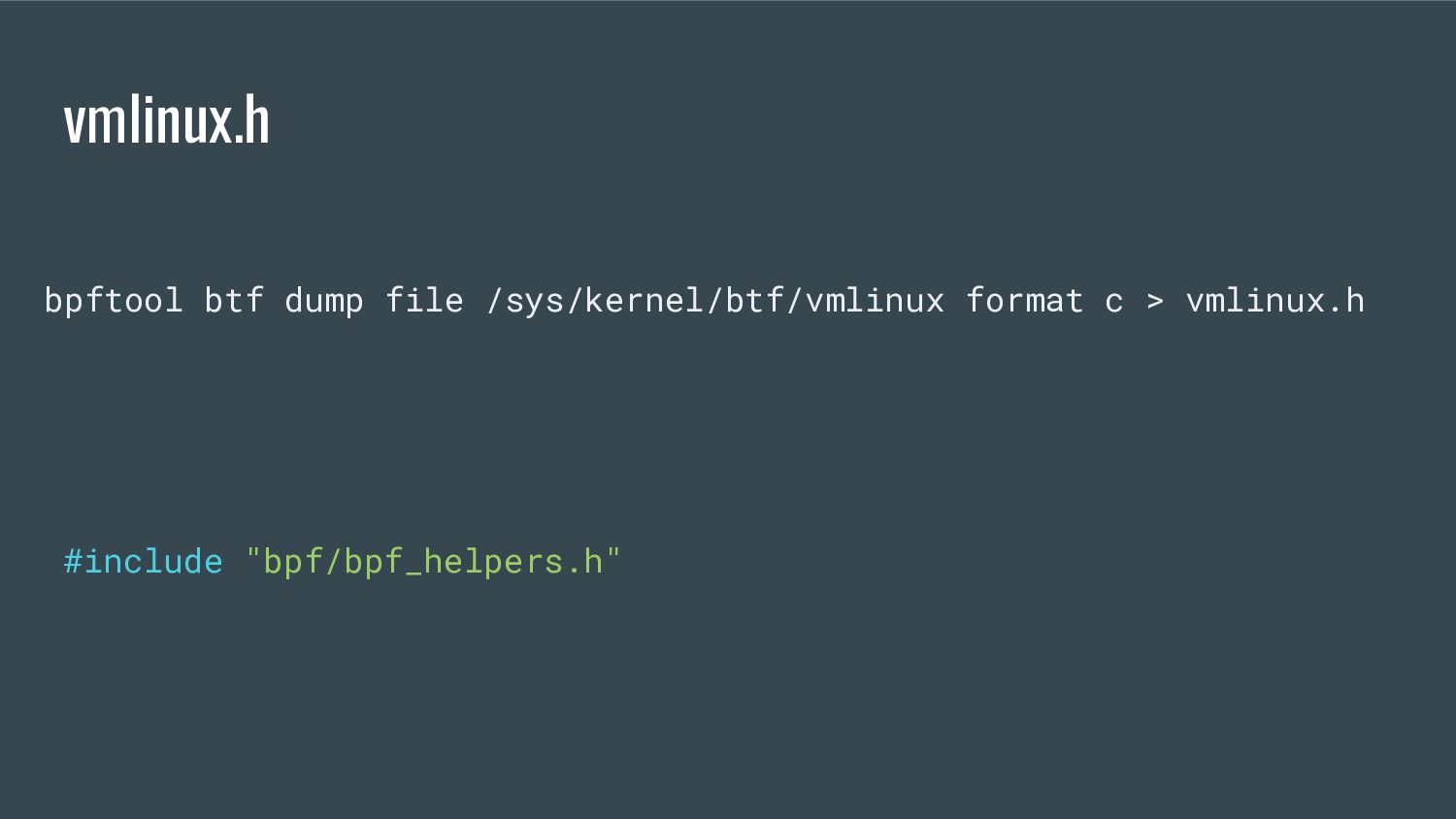
modern approach to writing portable BPF applications that can run on multiple kernel versions and configurations without modifications and runtime source code compilation on the target machine. from nakryiko.com/posts/bpf-core-reference-guide/
the program - A program has BTF information associated to it (i.e. which fields it wants to read) - The kernel comes with BTF information (i.e. where each field is)
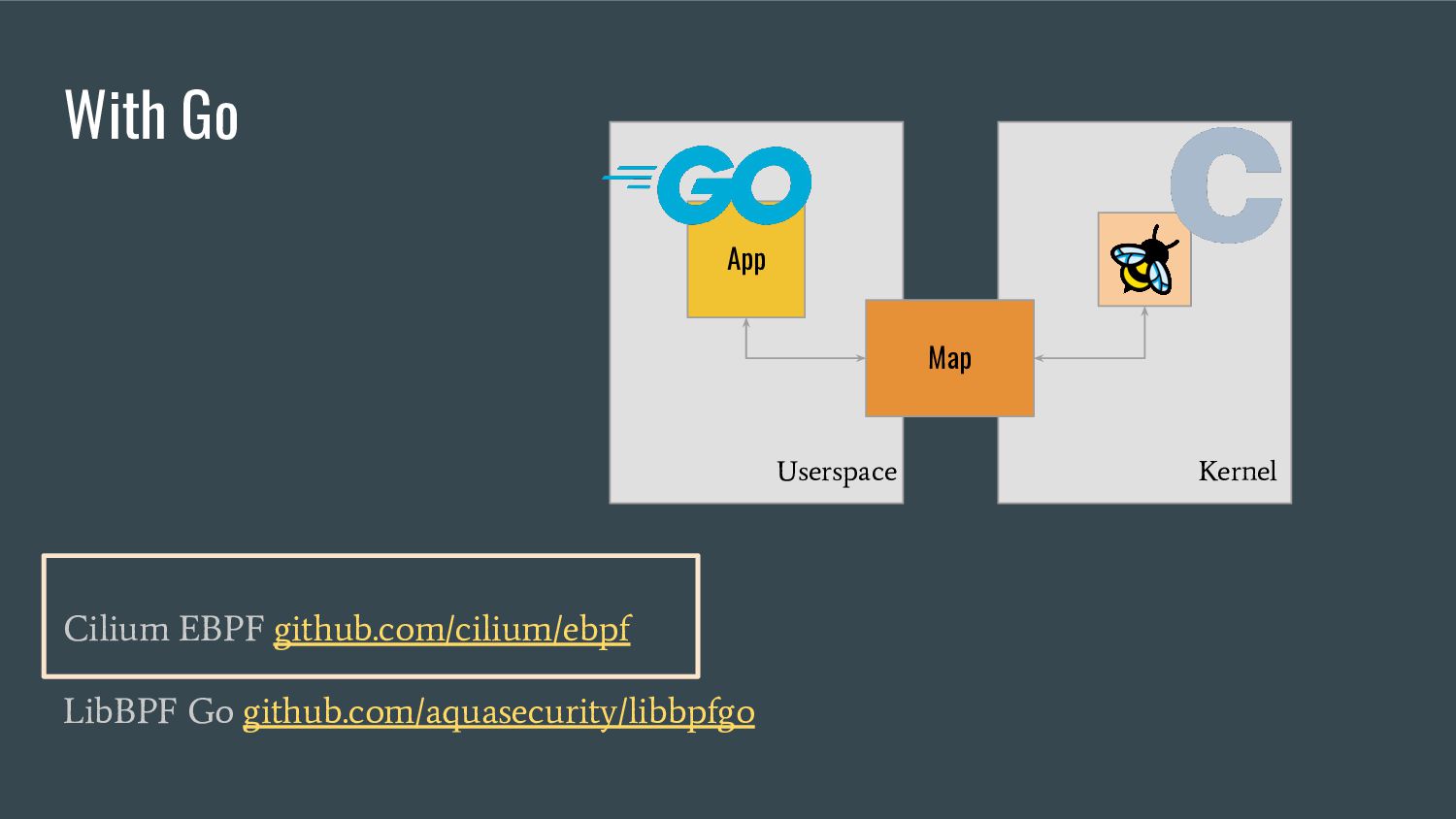
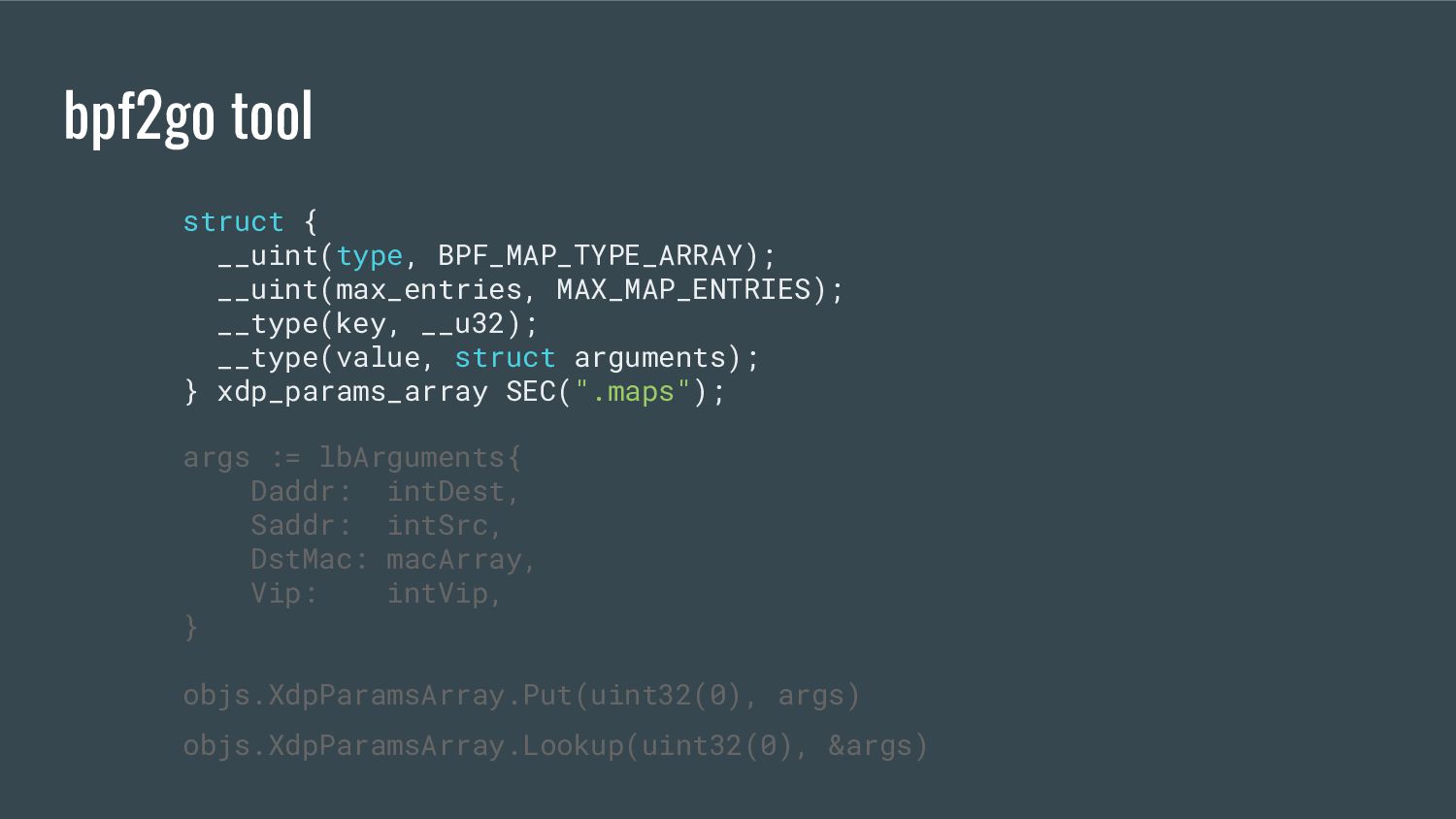
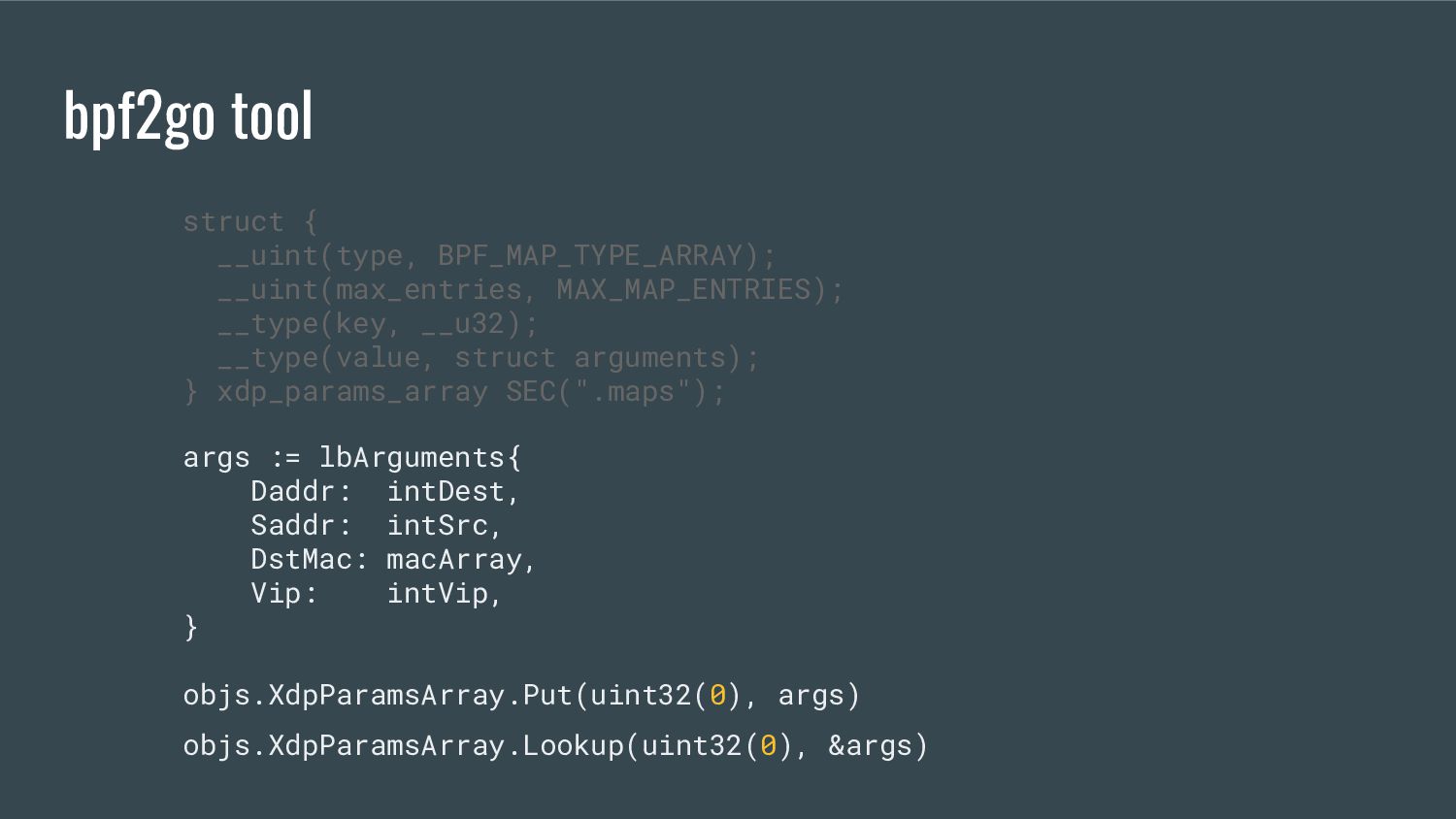
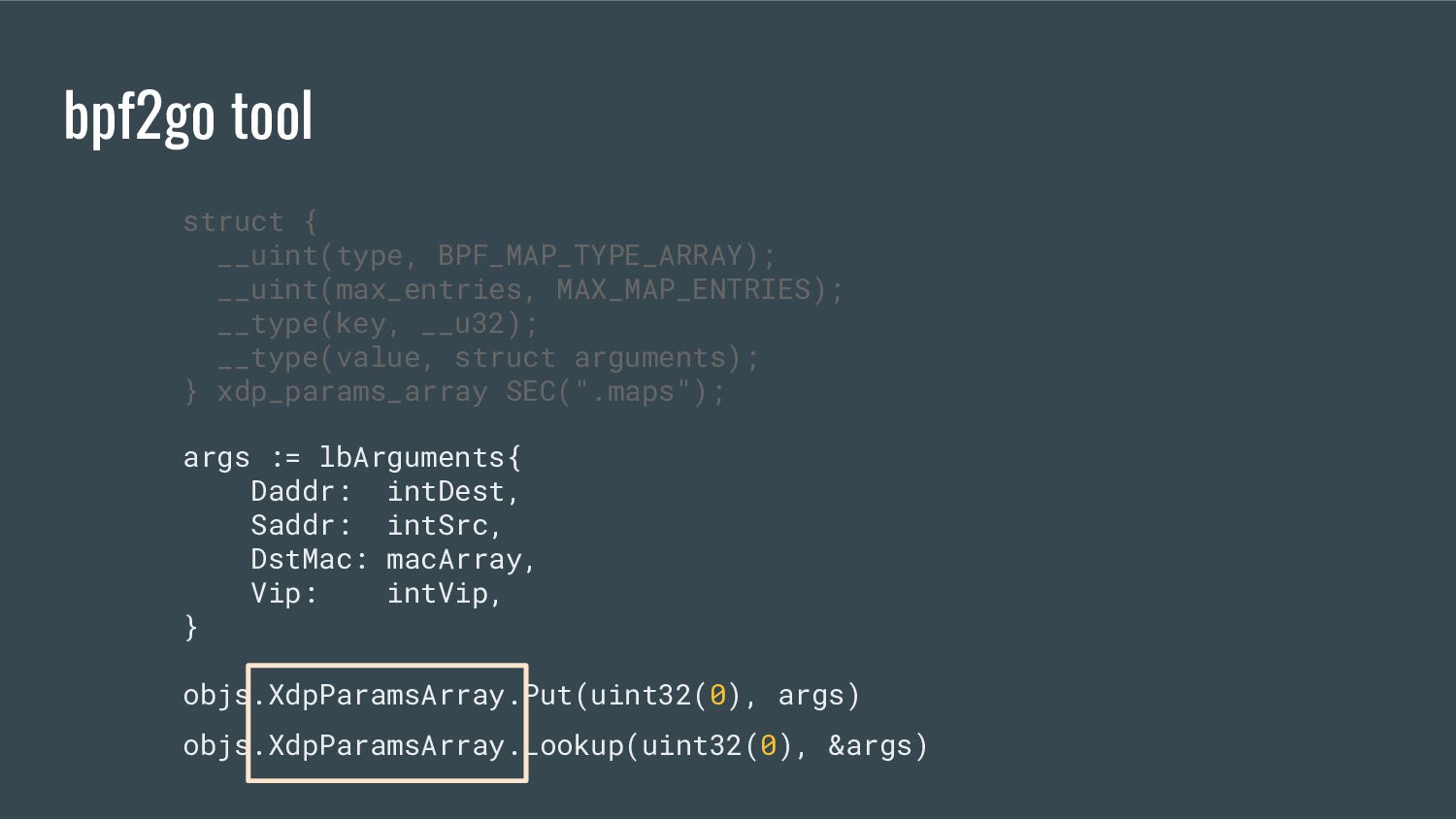
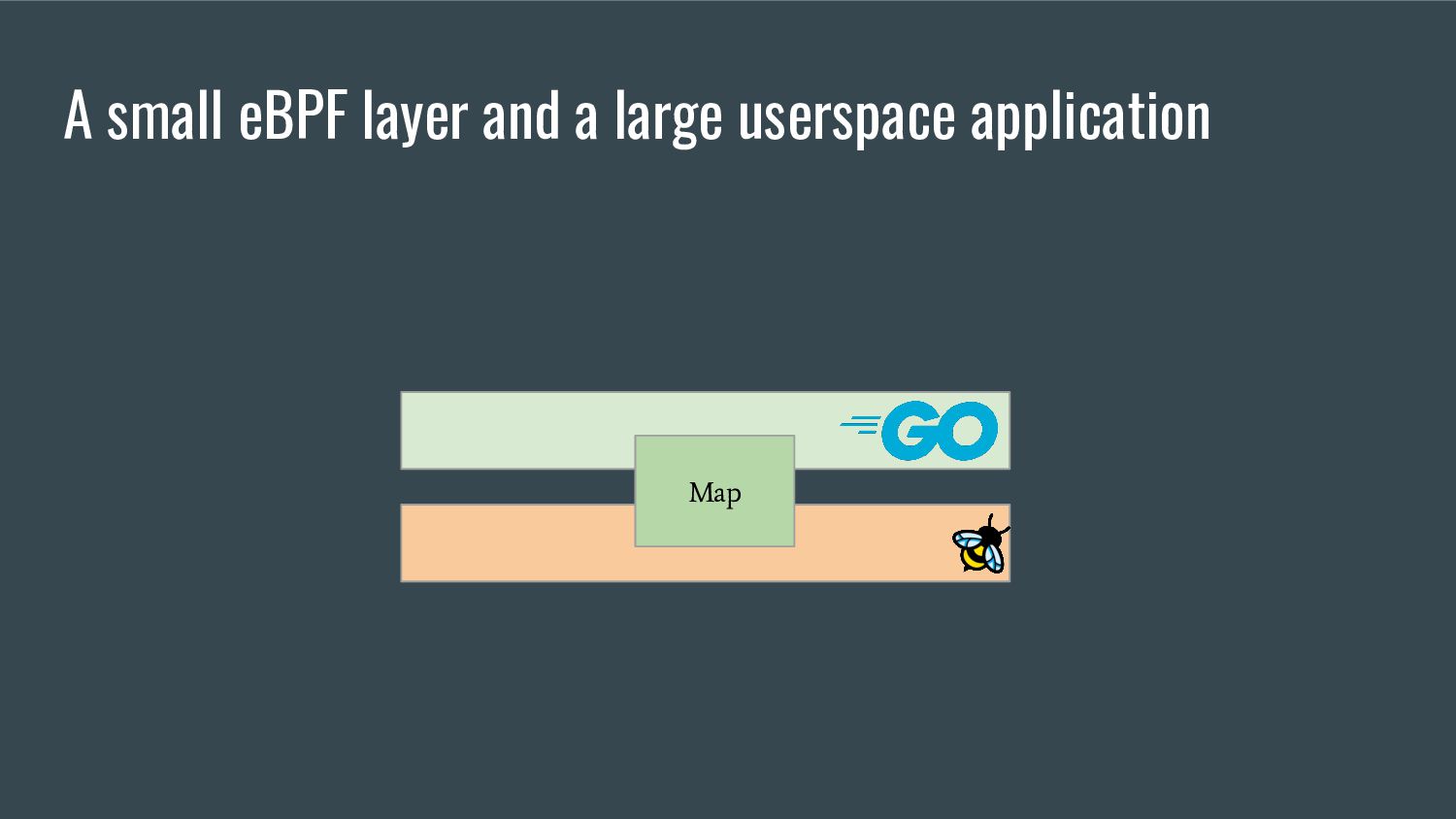
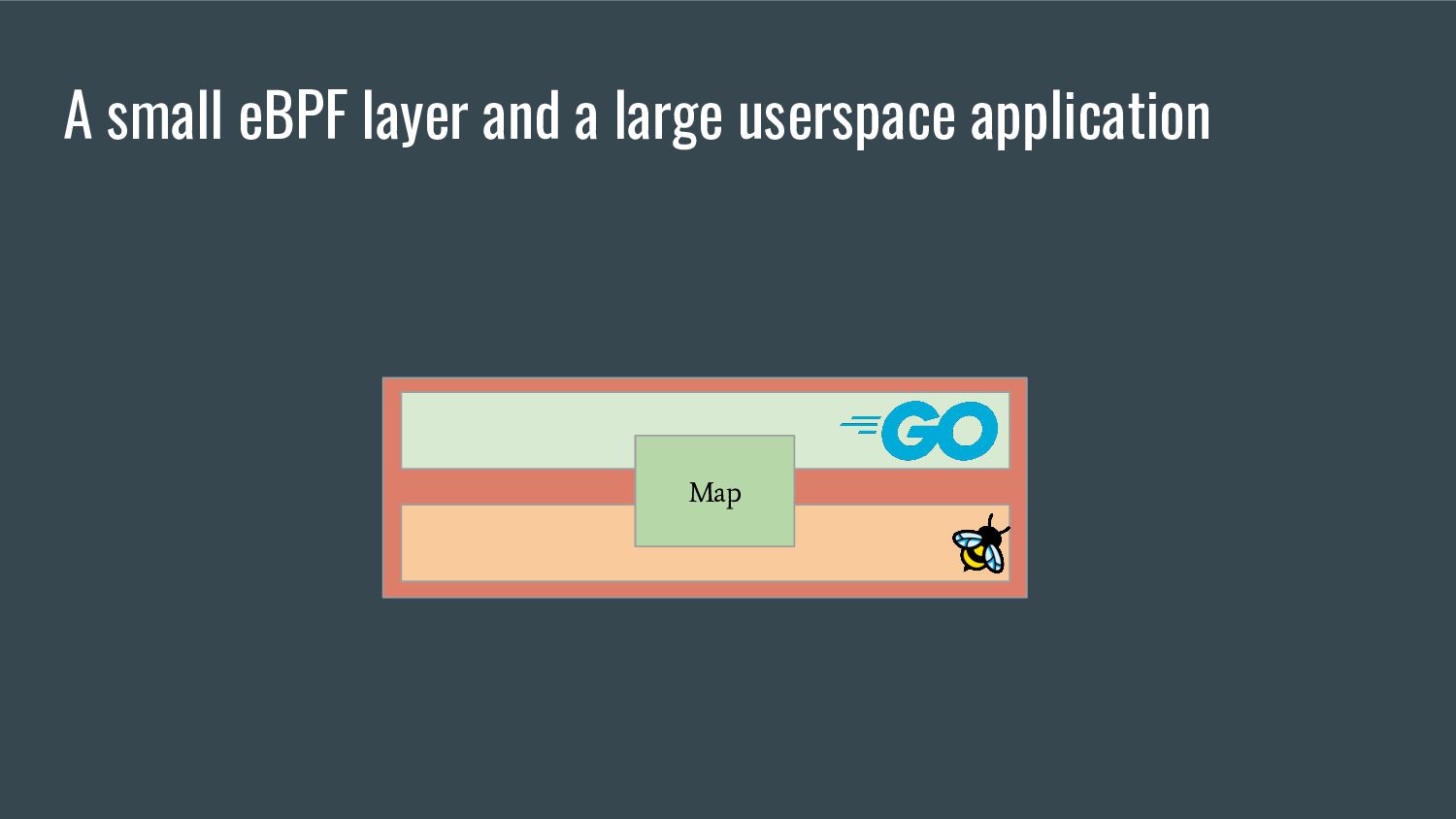
embeds the eBPF elf file in the single go binary - provides references to the eBPF maps / programs that are accessible from Go - generates Go equivalent objects of C structs bpf2go tool
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![git-9348 [000] ...21 2534.887840: bpf_trace_printk: called! git-9351 [000] ...21 2534.891143:](https://files.speakerdeck.com/presentations/f76af7f3712a42f584d82f753c6f1c45/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Maps - Hash Map struct command { u8 cmd[64]; };](https://files.speakerdeck.com/presentations/f76af7f3712a42f584d82f753c6f1c45/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![bpf2go tool struct arguments { __u8 dst_mac[6]; __u32 daddr; __u32](https://files.speakerdeck.com/presentations/f76af7f3712a42f584d82f753c6f1c45/slide_71.jpg){kind=link}
![bpf2go tool struct arguments { __u8 dst_mac[6]; __u32 daddr; __u32](https://files.speakerdeck.com/presentations/f76af7f3712a42f584d82f753c6f1c45/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Check for tracepoints sudo bpftrace -e 'tracepoint:xdp:* { @cnt[probe] =](https://files.speakerdeck.com/presentations/f76af7f3712a42f584d82f753c6f1c45/slide_133.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Any questions? @fedepaol hachyderm.io/@fedepaol [email protected] Slides at: speakerdeck.com/fedepaol [email protected]](https://files.speakerdeck.com/presentations/f76af7f3712a42f584d82f753c6f1c45/slide_151.jpg){kind=link}