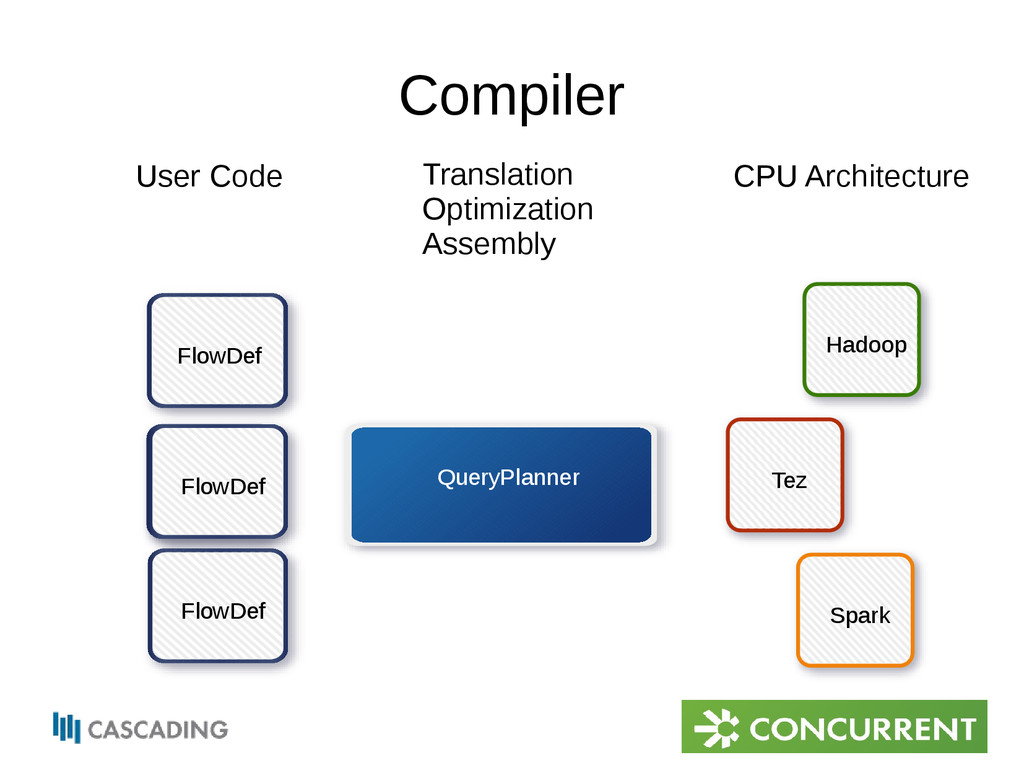
the Tuples • Operations are executed on Tuples in TupleStreams • FlowConnector uses QueryPlanner to translate FlowDef into Flow to run on computational fabric
the "document" text lines into a token stream Fields token = new Fields( "token" ); Fields text = new Fields( "text" ); RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ \\[\\]\\(\\),.]" ); // only returns "token" Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS ); // determine the word counts Pipe wcPipe = new Pipe( "wc", docPipe ); wcPipe = new GroupBy( wcPipe, token ); wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL ); ...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Counting words // configuration String docPath = args[ 0 ];](https://files.speakerdeck.com/presentations/d23dc29056fe0132daa3426e07da56ad/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? [email protected]](https://files.speakerdeck.com/presentations/d23dc29056fe0132daa3426e07da56ad/slide_18.jpg){kind=link}
{kind=link}
{kind=link}