things easier, namely the way it aligns with the rest of the toolset used. Ability to use all the functionalities of SCM systems: merges, forks, pull requests, history, reversion, etc. Easy to automate the production and final output, from PDF documents to HTML pages, all from the same source. Integration of scripts and code For the last point Jupyter notebooks are a common choice (especially for Python); here I demonstrate the use of the official Kubernetes library to produce this prensentation and some very simple diagrams of a Kubernetes cluster with a simple application deployed (using ) Above all using this approach allows the creation of up-to-date documentation since the sections that are supposed to reflect what exists are automatically updated: this in turn reduces issues from out-of-date documentation that is always playing catch-up with changes. minikube
work kubectl should be working correctly in the desired context, e.g. kubectl config view should work. official Kubernetes client for Python In [344]: from kubernetes import client, config config.load_kube_config() v1 = client.CoreV1Api() display(v1) <kubernetes.client.api.core_v1_api.CoreV1Api at 0x7f9ae7fec470>
information on the nodes. In [345]: import collections import pandas as pd nodes = v1.list_node(watch=False) node_list = [] for i in nodes.items: node_dict = collections.OrderedDict() node_dict["Name"]= i.metadata.name node_dict["OS"]= i.status.node_info.operating_system node_dict["OS image"]= i.status.node_info.os_image node_dict["Runtime"]= i.status.node_info.container_runtime_version node_list.append(node_dict) nodes_df = pd.DataFrame(node_list) display(nodes_df) Name OS OS image Runtime 0 multinode linux Buildroot 2020.02.10 docker://20.10.4 1 multinode-m02 linux Buildroot 2020.02.10 docker://20.10.4
the code shorter in later blocks. In [347]: from diagrams import Cluster, Diagram from diagrams.k8s.clusterconfig import HPA from diagrams.k8s.compute import Deployment, Pod, ReplicaSet from diagrams.k8s.infra import Node, Master from diagrams.k8s.network import Ingress, Service from diagrams.k8s.group import Namespace from diagrams.k8s.podconfig import Secret
the diagrams; from the home page: It uses to build the graphs so that needs to be installed as well. Diagrams Diagrams lets you draw the cloud system architecture in Python code. It was born for prototyping a new system architecture without any design tools. You can also describe or visualize the existing system architecture as well. Diagram as Code allows you to track the architecture diagram changes in any version control system. Graphviz
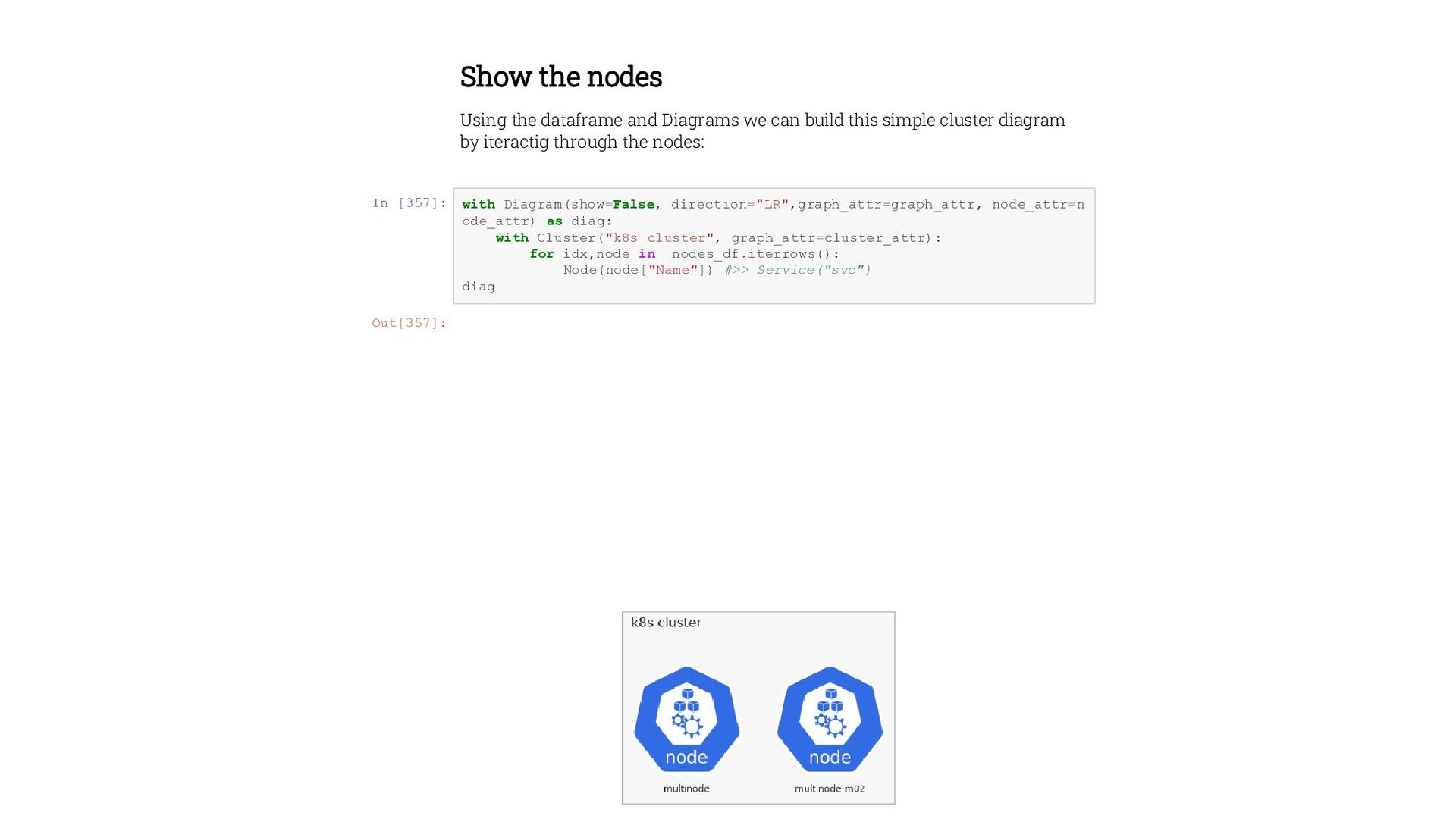
build this simple cluster diagram by iteractig through the nodes: In [357]: with Diagram(show=False, direction="LR",graph_attr=graph_attr, node_attr=n ode_attr) as diag: with Cluster("k8s cluster", graph_attr=cluster_attr): for idx,node in nodes_df.iterrows(): Node(node["Name"]) #>> Service("svc") diag Out[357]:
again, we process the dict to build a dataframe. In [358]: ns = v1.list_namespace(watch=False) ns_list = [] for i in ns.items: ns_dict = collections.OrderedDict() ns_dict["Name"]= i.metadata.name ns_dict["UID"]= i.metadata.uid ns_list.append(ns_dict) ns_df = pd.DataFrame(ns_list) display(ns_df) Name UID 0 default 0086019d-bc33-4b04-a4e3-4f63f3472621 1 kube-node-lease 6d7de7e1-02ab-4d70-9e4a- 0b9237890f73 2 kube-public 4dd3461e-726c-4595-a3dc- d2bbc0748851 3 kube-system db61c947-b684-4efc-8c45- 9a9ed915852d
[359]: with Diagram(show=False,graph_attr=graph_attr,node_attr=node_attr) as diag : with Cluster("k8s cluster", graph_attr=cluster_attr): for idx,namespace in ns_df.iterrows(): Namespace(namespace["Name"]) diag Out[359]:
building Pandas dataframes because this is useful for other purposes (namely for the production of a PDF via LaTeX), but directly using the dict is possible and would actually be simpler. I'm using a simplistic approach for the label/selector pairing, so I simply add an "App" column that contains the label.
services = v1.list_service_for_all_namespaces(watch=False) srv_list = [] for i in services.items: srv_dict = collections.OrderedDict() srv_dict["Name"]= i.metadata.name srv_dict["Type"]= i.spec.type srv_dict["IP"]= i.spec.cluster_ip if i.spec.selector is not None: if "app" in i.spec.selector: srv_dict["App"] = i.spec.selector["app"] srv_list.append(srv_dict) srv_df = pd.DataFrame(srv_list) display(srv_df) Name Type IP App 0 kubernetes ClusterIP 10.96.0.1 NaN 1 web NodePort 10.99.132.93 web 2 kube-dns ClusterIP 10.96.0.10 NaN
Cluster("ns: default", graph_attr=cluster_attr): for idx,pod in pods_df[pods_df["Namespace"] == "default"].iterrows (): p = Pod(pod["Name"]) if srv_df[srv_df["App"] == pod["App"]]["Name"].any(): p >> Service(pod["App"]) if pod["Secret"]: Secret(pod["Secret"]) >> p diag Out[362]:
, and obviously that was used to produce this presentation - on top of the HTML export and the ablity to use it interactively. Since we're in a Jupyter notebook a lot more can be done: using any of the visualisations libraries (like ) we can automatically produce plots and statistics about our cluster: this simple example uses matplotlib and Seaborn to show how many pods are running in each node. AsciiDoc LaTeX Reveal.js Seaborn In [363]: import seaborn as sns sns.set() sns.set_style("whitegrid") pods_df[["Name","Node"]].groupby('Node').count().plot(kind="bar",legend=Fa lse) Out[363]: <matplotlib.axes._subplots.AxesSubplot at 0x7f9af842dc50>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![In [360]: ret = v1.list_pod_for_all_namespaces(watch=False) pods_list = [] for i](https://files.speakerdeck.com/presentations/7c68381d42d34698a53cb37e063c4936/slide_11.jpg){kind=link}
![We also get the Services, including their selector. In [361]:](https://files.speakerdeck.com/presentations/7c68381d42d34698a53cb37e063c4936/slide_12.jpg){kind=link}
{kind=link}
![In [362]: with Diagram(show=False, graph_attr=graph_attr, node_attr=node_attr) as di ag: with](https://files.speakerdeck.com/presentations/7c68381d42d34698a53cb37e063c4936/slide_14.jpg){kind=link}
{kind=link}