https://www.meetup.com/BristolJS/events/242690371/
Node.js apps can run on a multitude of platforms. But when you ship code to production, how can you be sure that it will behave in the same way it did on your local dev machine? Containerisation is one way to mitigate this risk: by building a virtual 'image' which includes the OS, software and source code that your application needs to run, you can ensure a reproducible build you can trust, which runs in the same way in every environment.
But containerisation isn't the whole picture. Take the concept of reproducible, declarative builds to its natural conclusion and you get 'container orchestration': a representation of all of your applications and servers and how they relate together.
This talk will introduce containerisation with Docker; how you can use it to make your workflows more predictable and your servers more reliable; and using Kubernetes to spin up your applications in the cloud using nothing but YAML files, with monitoring, logging, scaling and networking all taken care of. We'll be looking at some real-world examples, some tips and tricks, advice on developing on your local machine, and some of the more painful discoveries from a few months of deploying to production.
SPEAKER NOTES:
hands up if you write JavaScript for your job
keep them up if you write server-side applications in Node.js
keep them up if you've ever done any 'ops' or dev-ops': CI or server configuration, etc.
keep them up if you have been known to FTP files onto a server
keep them up if you have ever live-edited a file on a server in production
Who's ever used Docker?
Who's ever used Heroku?
who's ever used kubernetes?
talk is: "An introduction to Docker and Kubernetes for Node.js developers"
but I'm a developer
not a deep dive where you'll learn everything
a more personal story of how my relationship with servers has changed over the years
FTP code onto a server. Wordpress, etc.
I discovered rsync and mounted SFTP drives, so could work 'on the server'
First real job
Suite of servers
herbs and spices: Tarragon, Ginger
fond memory: Turmeric was upgraded to Saffron
in a datacentre which we sometimes needed to drive to to install a new rack box
Server configuration was managed by Puppet
code was deployed via rsync by Jenkins CI jobs
production was terrifying
had to keep it up at all costs
although Puppet helps keep servers up-to-date, it doesn't give a verifiable environment
occasionally live-edited code on prod, which 'sometimes' made it back into our version control
for local dev: a 'sandbox' server
hosted in a server room a few meters from our desks to be fast
everyone on the team had a different way of getting code onto the server:
- some SSH'd in and used Vim
- some mounted the drive and worked locally, with hiccoughs
- some developed complicated 2-way rsync solutions (mention Kornel?)
We then migrated to a Vagrant setup
a full virtual machine on our laptops with the services we needed
mounting folders into it from the host
running same servers on Mac, Windows and Linux
not a bad workflow
still loads of compromises:
1. simplified versions of things for local dev
2. everything in the same VM rather than isolated as it would be in prod
3. all localhost networking
4. no load balancing
Most worryingly:
dev, ci and prod could easily get out of sync
we had no easy way to verify new versions of software
Even with Puppet, how can you be sure that everything on the server has been documented?
who's heard of this term?
what's wrong with the process I've described?
the longer a server lives, the more likely you are to treat it like a pet
servers are nurtured, but the changes don't make it back into version control
dev, ci, staging and production are architected differently
Vagrant uses virtualization
each virtual machine runs its own entire operating system inside a simulated hardware environment
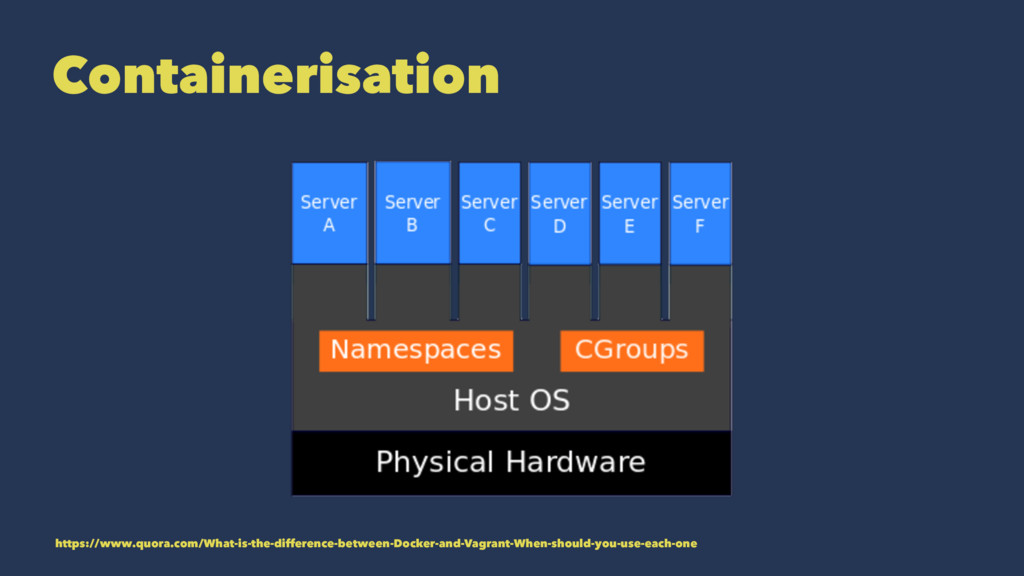
Docker uses containerization
allows multiple applications to run in isolated partitions of the kernel directly on the physical hardware
let's take a look at how we can improve confidence
be sure that that the process you run locally in development behaves the same as in production
similar to the goals for good software design in general
Docker is a way to package code into consistent units of work
the units can then be deployed to testing, QA and production environments
Docker needs to only to express the configuration for a single process
so unlike Puppet, Chef, etc., which need to manage a whole virtual machine
the problem becomes far easier
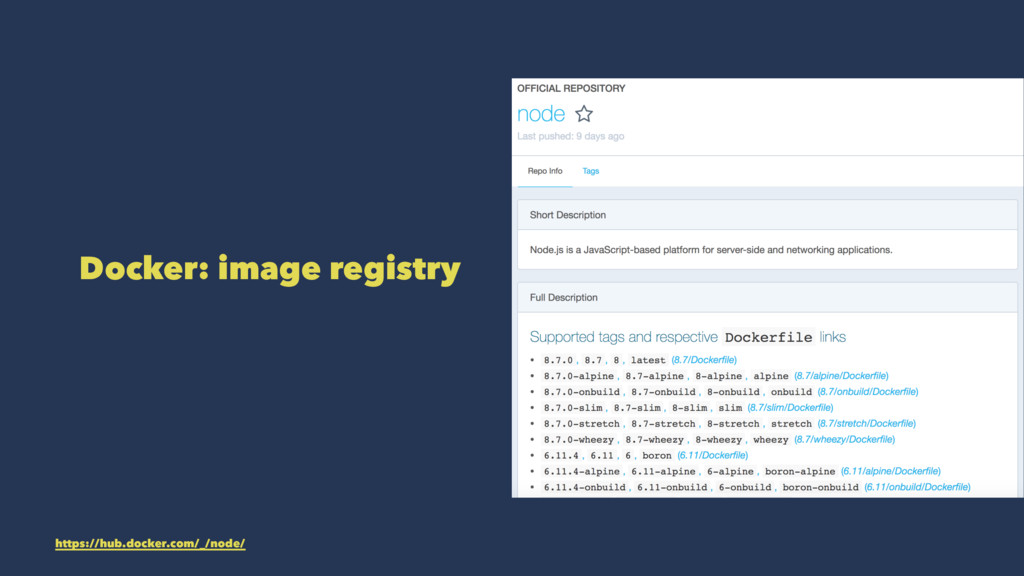
Most docker commands relate to an image. An image is built from a manifest file, called a 'Dockerfile'. You're building up a bundle of resources which can run a single process
Docker images inherit from other images - eventually down to a base image. For node, there are many varieties of tag on the 'Docker Hub' registry:
each line in the file is an instruction (inherit from another image, add files, run commands, set permissions, etc.)
First we'll build an image from our manifest
**demo: build**: https://asciinema.org/a/144295
Building an image gives us a checksum. We can make a container out of an image using `docker run`, and we have a Node 8 container.
**demo: run**: https://asciinema.org/a/144296
each instruction in the Dockerfile creates a new layer, with a checksum to verify its integrity
**demo: build, new layer**: https://asciinema.org/a/144297
first layer is cached
each line creates a cached image layer
you will often see multiple commands chained together: ensures dependencies are all cached in a single layer
So how can you even upgrade a package when it's always cached?
Bust the cache in an earlier layer with environment variables
**demo: Node.js image**: https://asciinema.org/a/144303
docker is designed to work best when there is only one process running in the container
it should be well-behaved, so should respond correctly to signals to shutdown, etc
pm2 and forever wrap Node.js processes so they behave
If you're not sure, use Yelp's dumb-init, which will wrap your command so it's correctly terminated
the application in a container is only a small part of the picture
components (front-end server, API server, database server, etc.) are now well-described with Docker images, but not how they communicate together
how can you be sure that the right number of containers are always running?
how can you make the best use of resources (CPU, memory)?
still a huge differences between dev, ci, staging and production
production has multiple redundant replicas of each server process, and a loadbalancer running across them. Perhaps also autoscaling
staging is often a low-powered, stripped down imitation of production
local dev setup uses localhost, incorrect ports, different filesystems, etc.
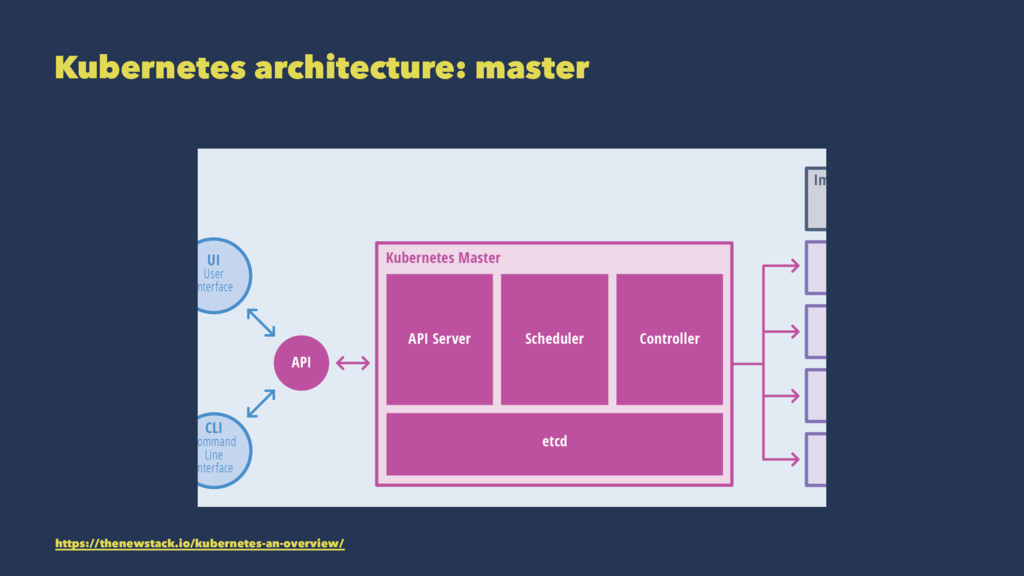
in particular, I'm going to talk about an orchestration platform called Kubernetes
For this demo, we need our Docker image to be in an accessible location.
Possible to use a private location
for easy demo, using main Docker Hub
The basic unit in k8s is the pod
This is the simplest of pods: it has a name, a label, and a single container
Let's create it
**demo: pods**: https://asciinema.org/a/144299
If we were to SSH onto the virtual machine running kubernetes, we could cURL the pod using its IP address
Services take care of routing local network traffic to pods
The pod selector identifies the set of pods to load-balance traffic to
The ports section is the same as the `docker run` command from earlier: map host port to container port
**demo: services**: https://asciinema.org/a/144300
Then, from another pod somewhere in the cluster, we can cURL the pod using a hostname (service.namespace)
This is where the benefit of a 'container orchestrator' really becomes obvious
A replica set declares a desired number of replicas of a pod.
Kubernetes will try to achieve that, following other rules like correctly waiting for startup and shutdown
Delete a pod, k8s detects it and will recreate
Like the service, this rs has labels on the pods, and a selector which matches those labels
**demo: replica sets**: https://asciinema.org/a/144301
A deployment wraps a replicaset
adds scaling, versioning, rollout and roll-back
the unit of currency for CI
**demo: deployments**: https://asciinema.org/a/144302
the final piece of the puzzle
we have a resiliant, scalable group of pods which works with CI
we have an internal hostname, with loadbalancing across the pods
we now need a way to route traffic into the cluster from the outside world
this ingress will direct requests for `demo.local` which hit the cluster IP to the nodejs service, where the request will be loadbalanced across the pods
**demo: ingresses**: https://asciinema.org/a/144304
Local development will, I hope, be getting much nicer
Docker have just announced future support for Kubernetes in their free Community Edition
meaning you can run complete k8s setups locally, for free
using your OS's hypervisor rather than a virtual machine
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Docker: introduction FROM [IMAGE] /Dockerfile](https://files.speakerdeck.com/presentations/37b8d8be961c4e7f876869cabc4c897b/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}