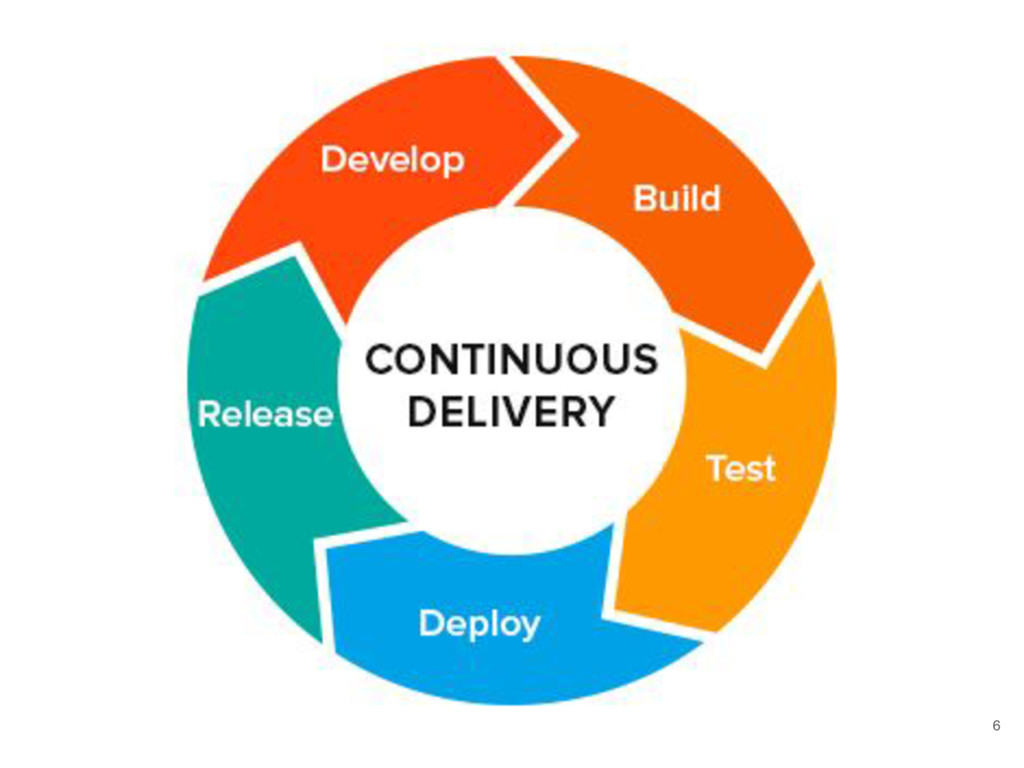
engineering approach in which teams produce software in short cycles, ensuring that the software can be reliably released at any time. It aims at building, testing, and releasing software faster and more frequently. The approach helps reduce the cost, time, and risk of delivering changes by allowing for more incremental updates to applications in production.” https://en.wikipedia.org/wiki/Continuous_delivery 5
high ◦ Write tests until nausea to avoid regressions ◦ Don’t Repeat Yourself ◦ Keep It Simple Stupid ◦ Don’t reinvent the wheel • Automate (almost) everything ◦ Time spent writing code is never lost ◦ Project building must be automated ◦ Test phase must be automated ◦ Deploy/Release should be automated • Team awareness (no working in silos) ◦ Everyone should know what is going on ◦ Monitoring ◦ Metrics 7
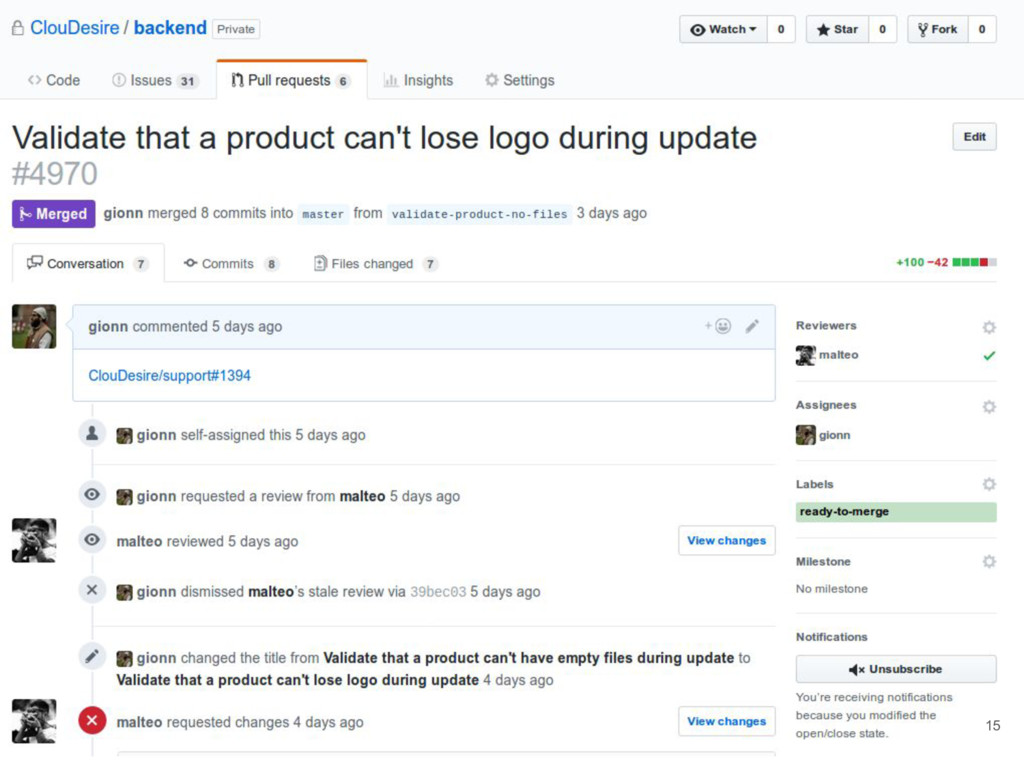
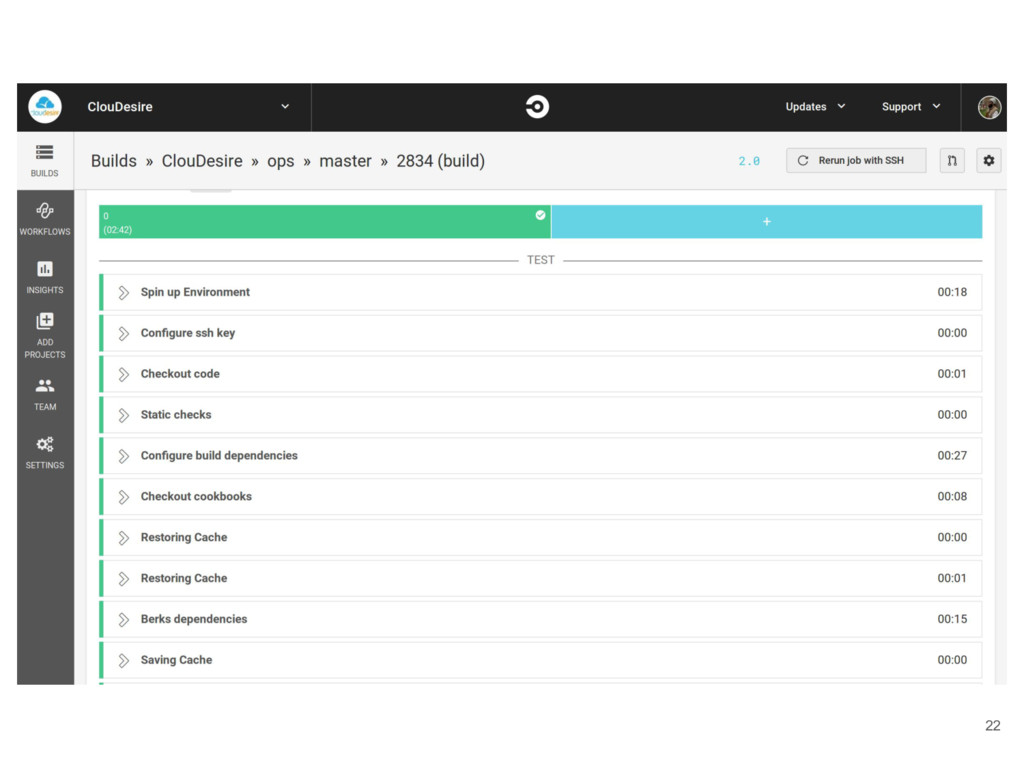
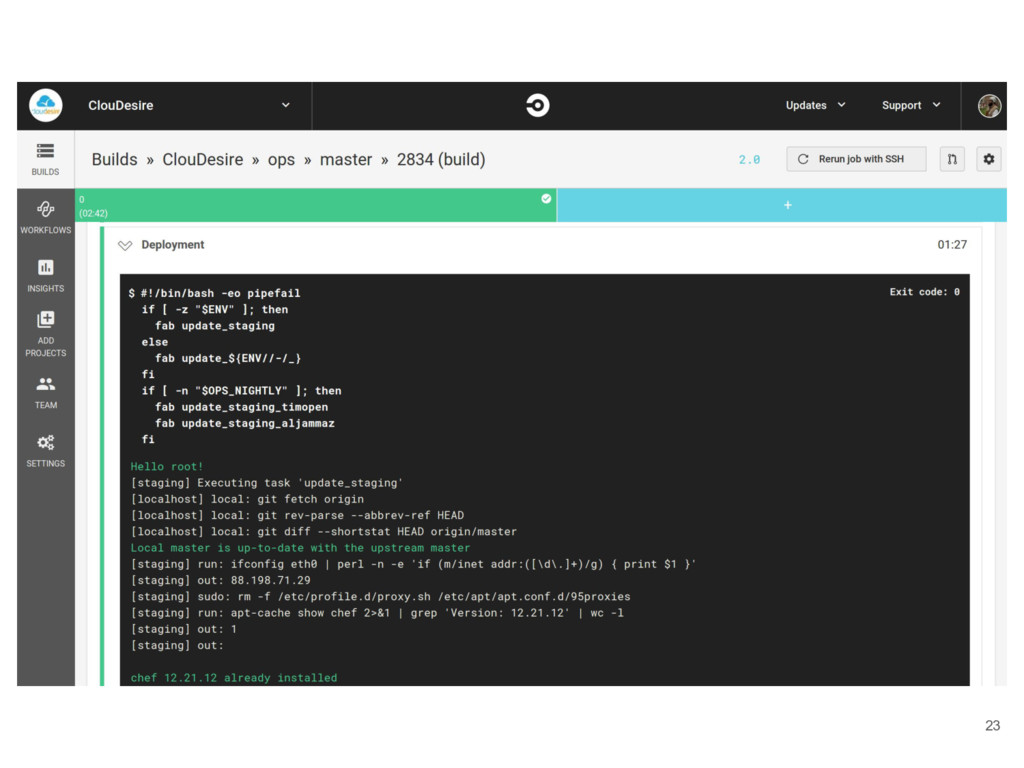
code and tests in a new branch 3. Open a pull request 4. Wait for the first green build 5. Ask for a code review 6. Handle received feedback 7. Merge code into master branch 8. Have green builds on dependant projects 9. Eventually test on staging environment (especially the UX) 10. Release to end-users 8
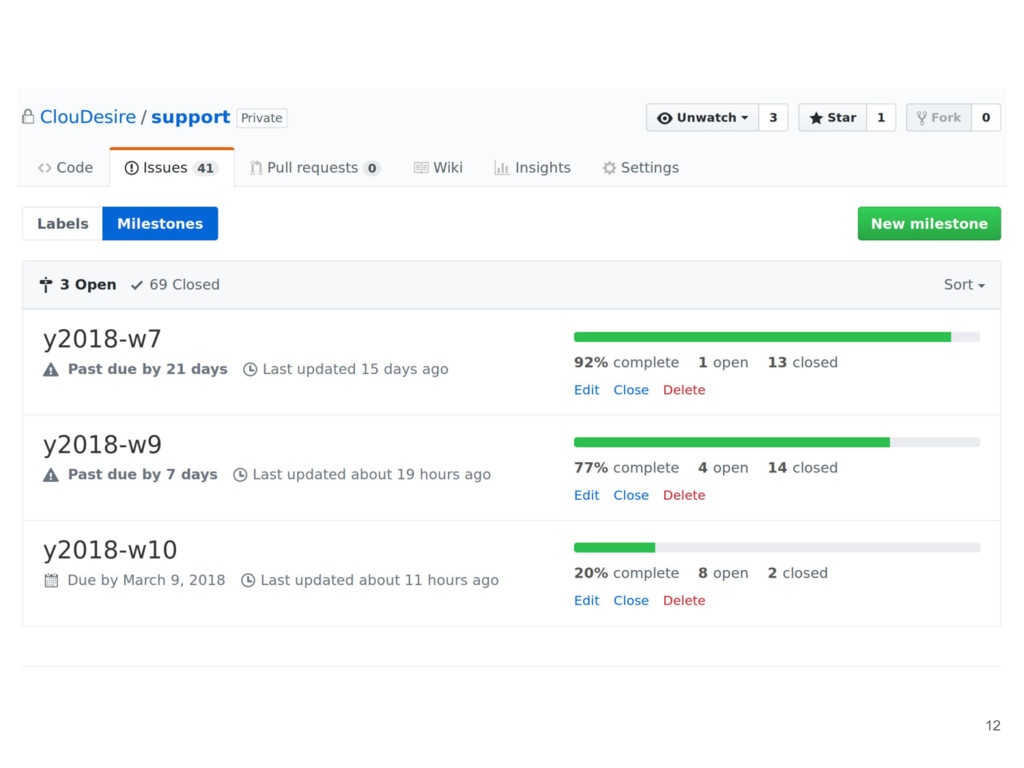
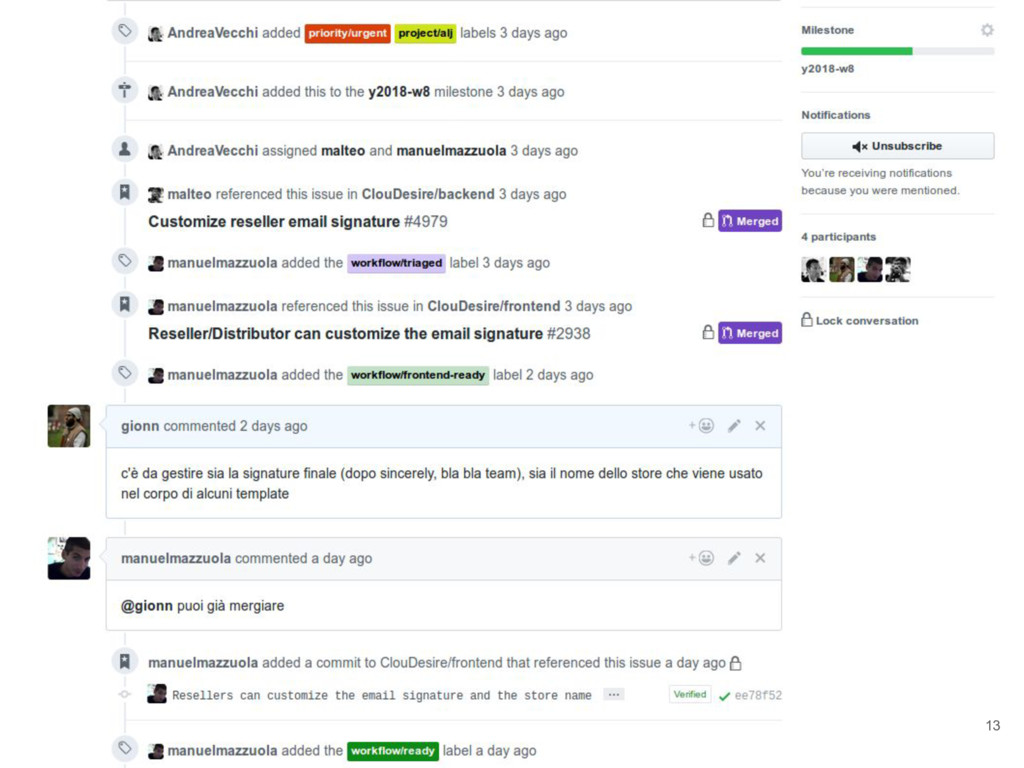
new issues and treat them as priorities (github milestones) • Technical details are discussed on project repository • Workflow labels: ◦ Triaged: someone has looked to the issue and defined impact ◦ Awaiting-feedback: more upstream information is required to proceed ◦ Backend-ready: backend code is merged into master ◦ Frontend-ready: frontend code is merged into master ◦ Ready: issue will be into the next release 11
for code quality and team awareness • Different eyes catch different bugs • Push code laziness away • Knowledge sharing • Code changes awareness • Asynchronous interaction between developers 14
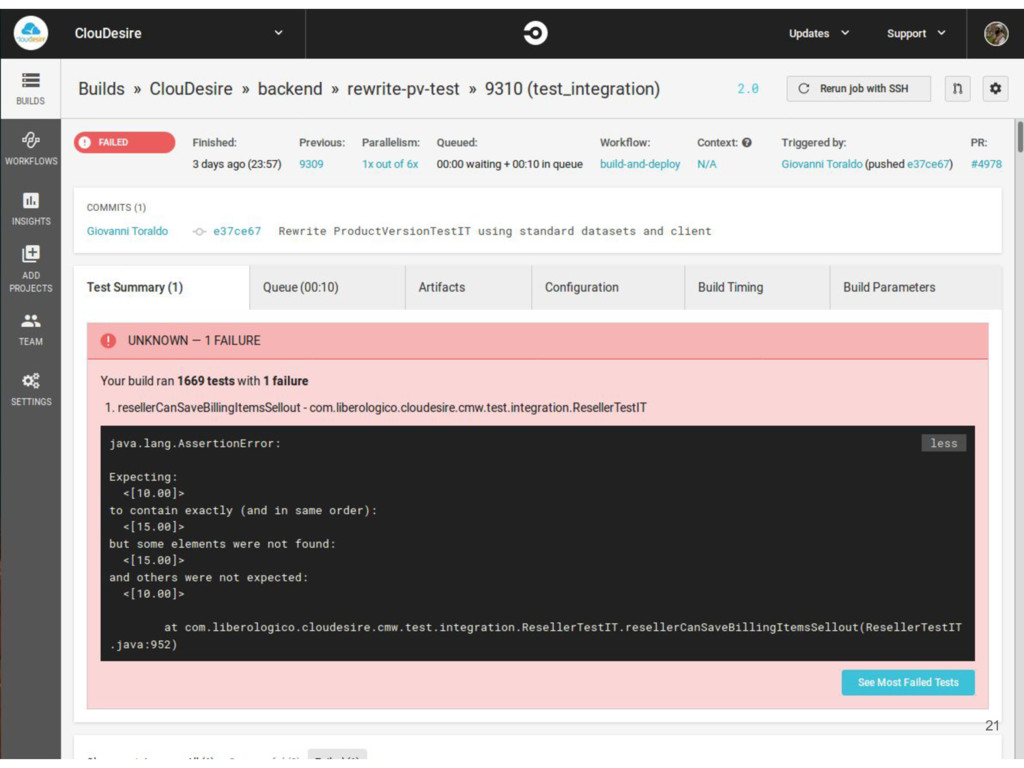
Build parallelization bound to number of nodes ◦ More nodes to increase parallelization of a single project • Isolation across projects fragile ◦ Hack to use different ports for each project • Failed builds may interferes with next builds ◦ Hack to ensure everything get cleaned properly • Toolchains needs to coexist together and maintained ◦ Beefy node configuration recipes ◦ Rbenv, nvm, pyenv and similar is a must • Github PR plugin integration broke multiple times ◦ Leaving us in panic 16
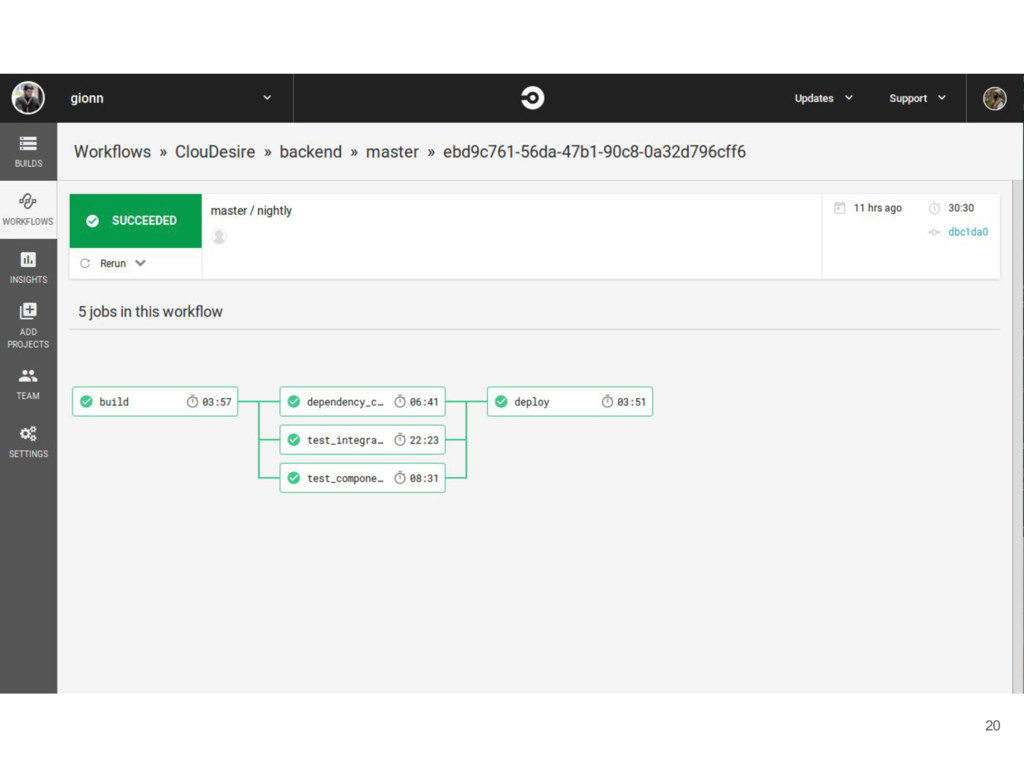
github builds broke, we decided to migrate CI to a paid service and keep headaches only for the code we write Enhancements of CircleCI over Jenkins: • Build isolation guaranteed by the platform • Parallelization bound to the bought plan • No infrastructure to manage • Project build configuration versioned into repository • Finally a decent UI 17
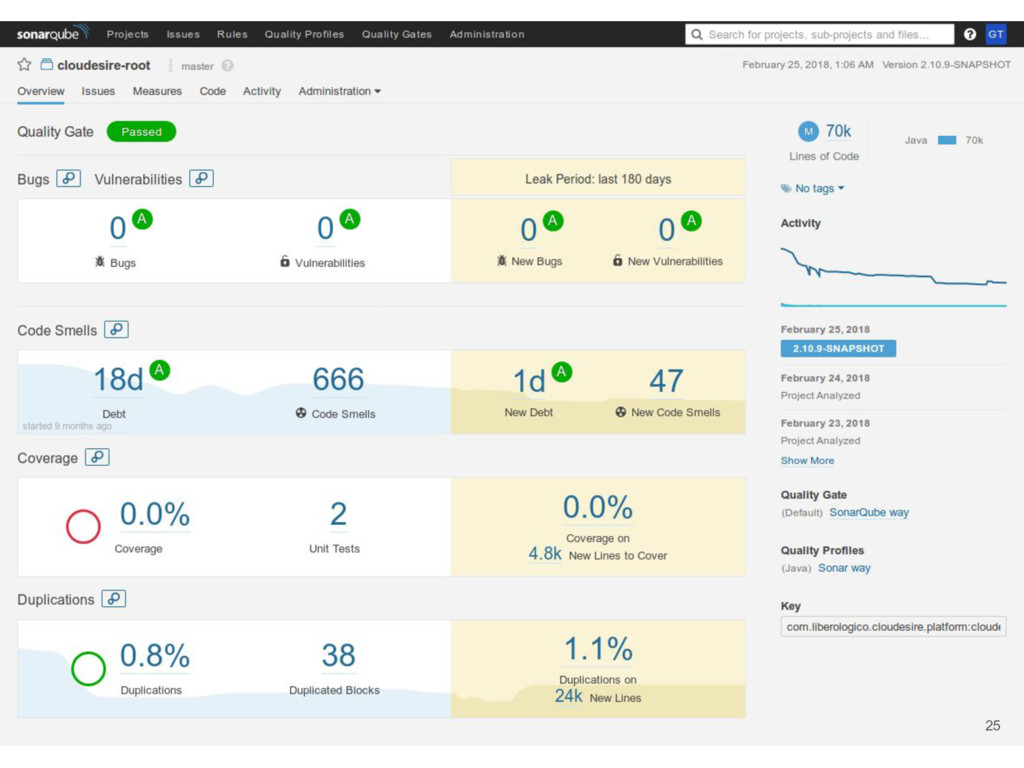
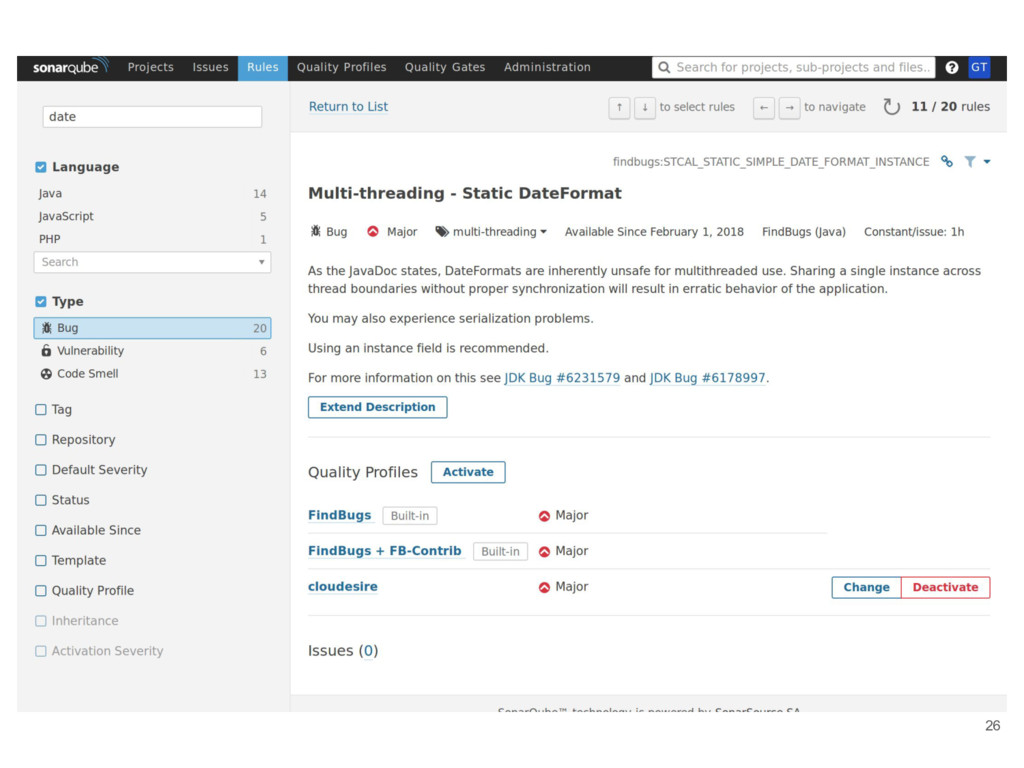
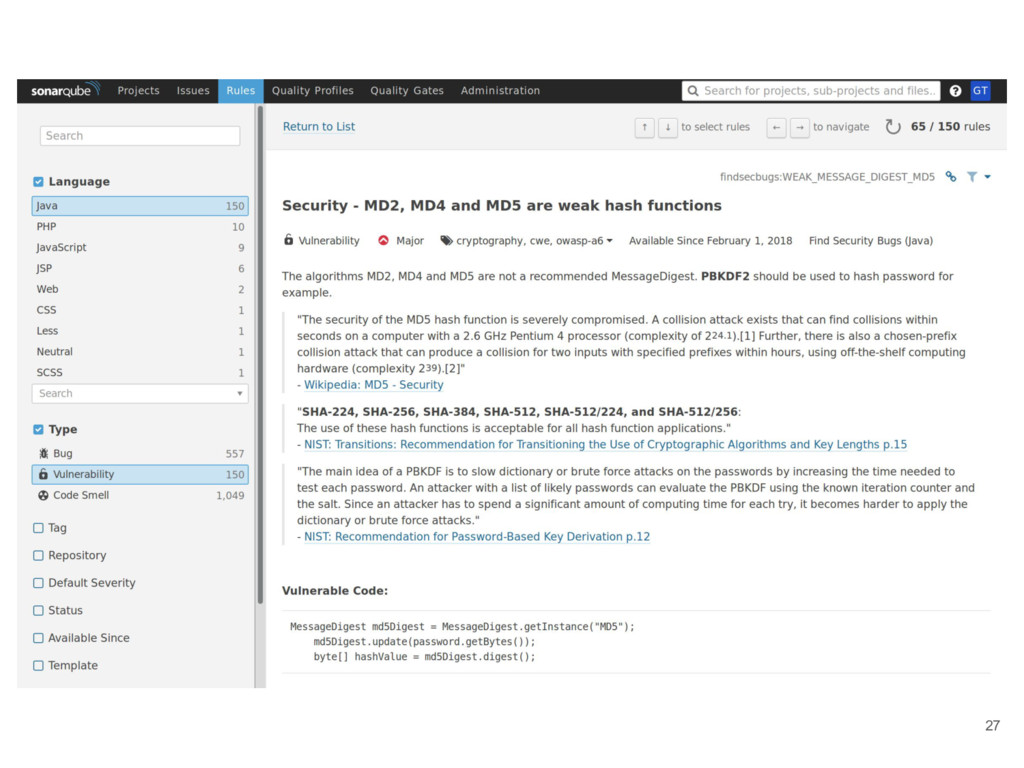
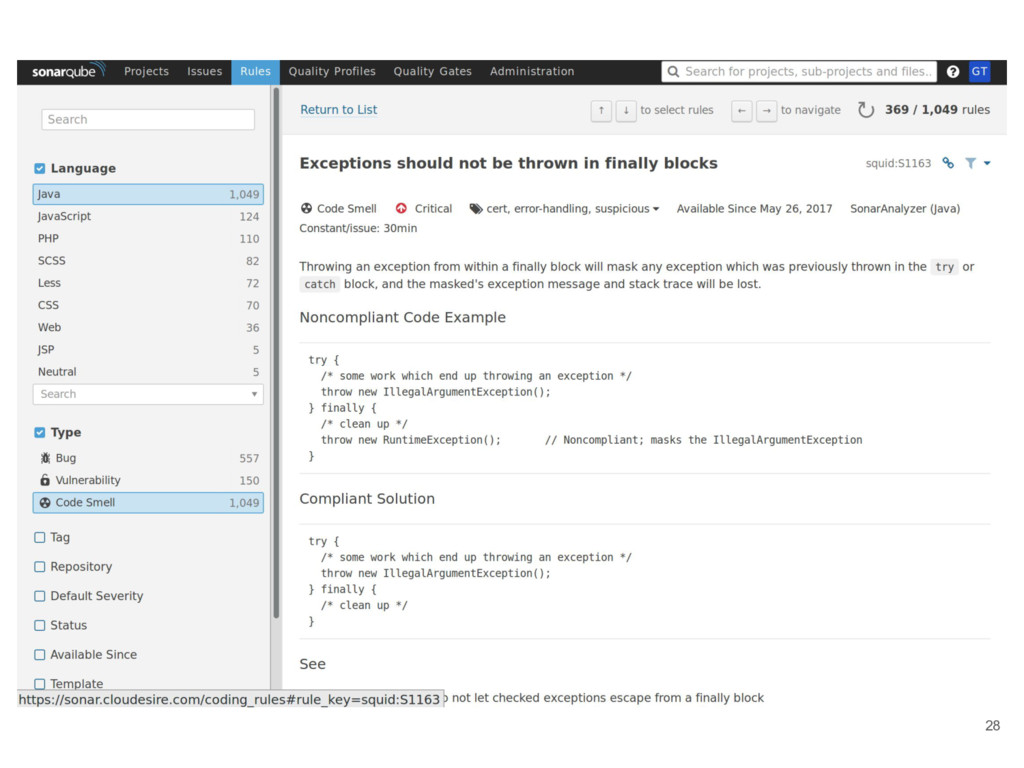
• Catch bugs automatically • Learn new things • Enforce standards With SonarQube is possible to: • Run on every build for every project • New warnings added on PR as comments • Generate reports about current projects status 24
(2014) Nowadays, every project: • Have a docker-compose.yml launched via autoenv • Build a docker image and runs integration tests against it • Push image to the registry as final build step ◦ Build number is the image tag • Get released via chef recipes 30
0. • Chef-zero (serverless) • Provision via fabric script ◦ Sourcing node ssh details from ssh-config ◦ Copy packaged cookbooks via rsync ◦ Run chef-zero • Platform modules deployed as docker containers ◦ Consul + registrator to access containers running on different hosts ◦ Consul-template to autoregister upstream on nginx • All cookbooks tested via test-kitchen + serverspec (migrating to inspec) 31
with known software best practices: • Code versioning • Code reuse (modularization/abstraction) • Code sharing In order to achieve: • Repeatability • Speed • Reliability 32
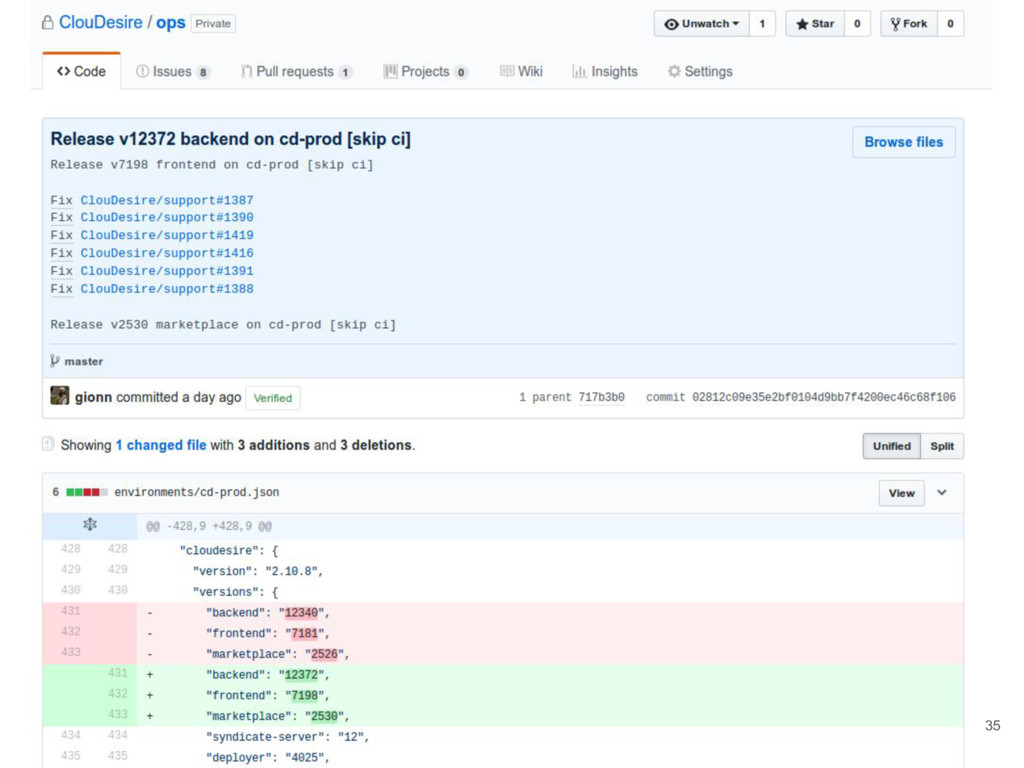
restart containers with updated images: image versions are stored inside chef environment json, modified with a hand-made script that: • Iterate over circleci projects looking for last successful build • Ensure that latest master dependencies are green (no regressions) • Retrieve commit list via Github API between current version and next release ◦ Print which new commits are going into this release ◦ Reference support ticket for automatic closing • Commit version change and run deploy job (parametrized for different envs) 34
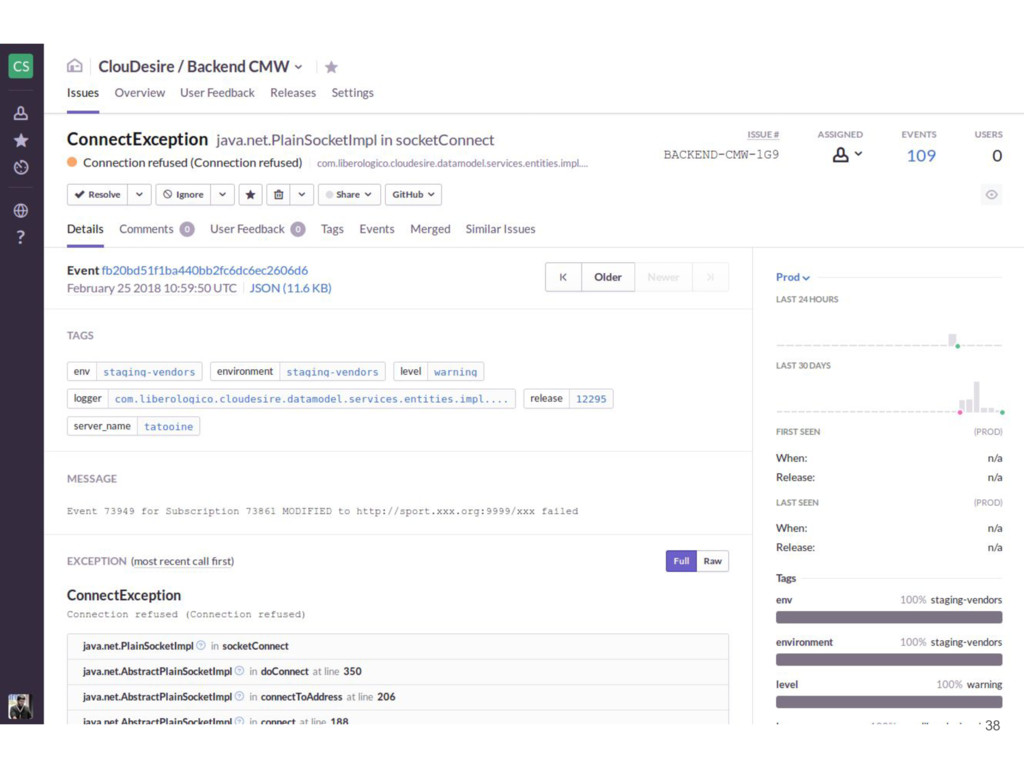
aggregation • Full-text search on error message, function names, stacktraces • Link GitHub issue • Remember if an error was already marked as fixed (regression) 36
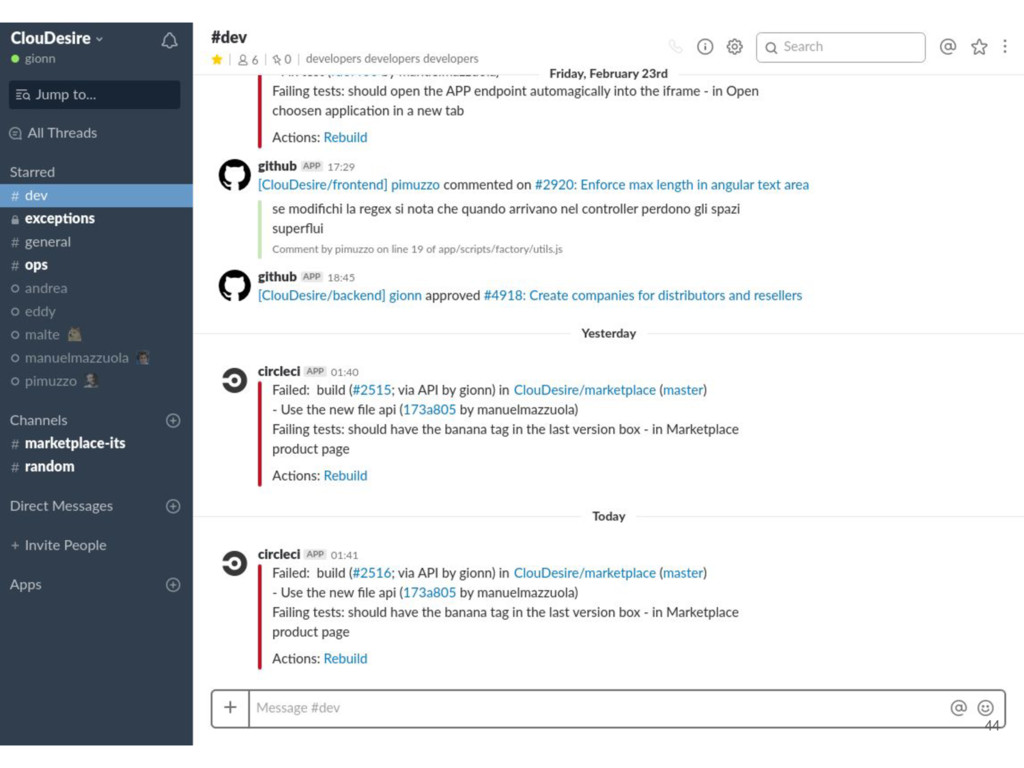
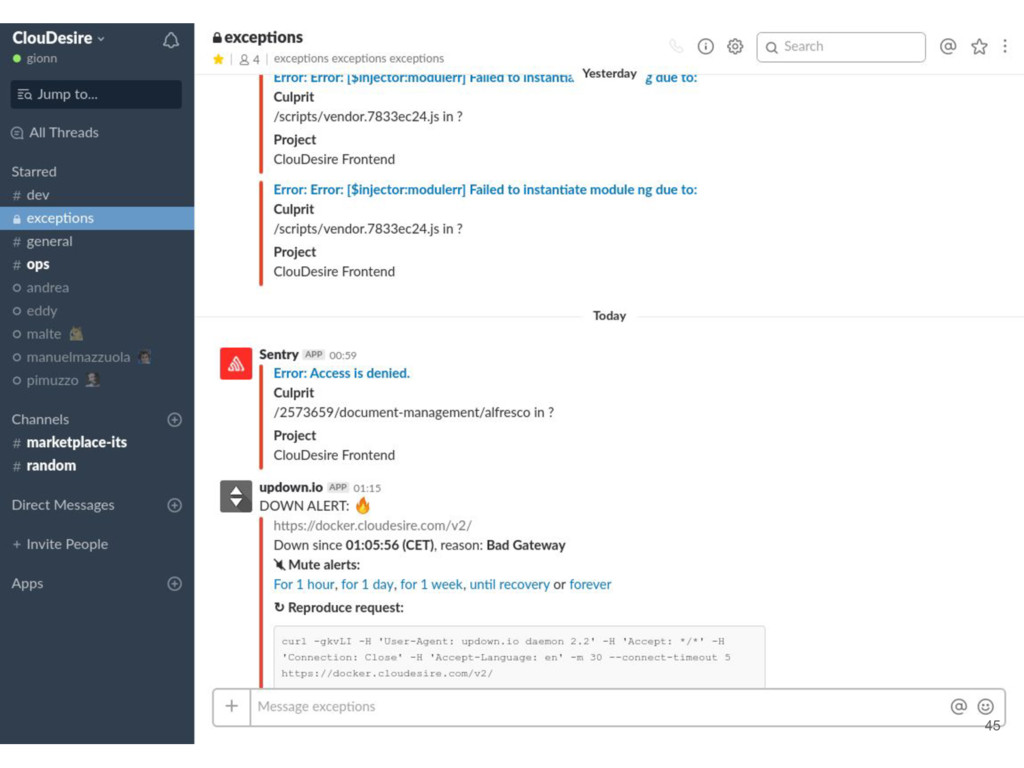
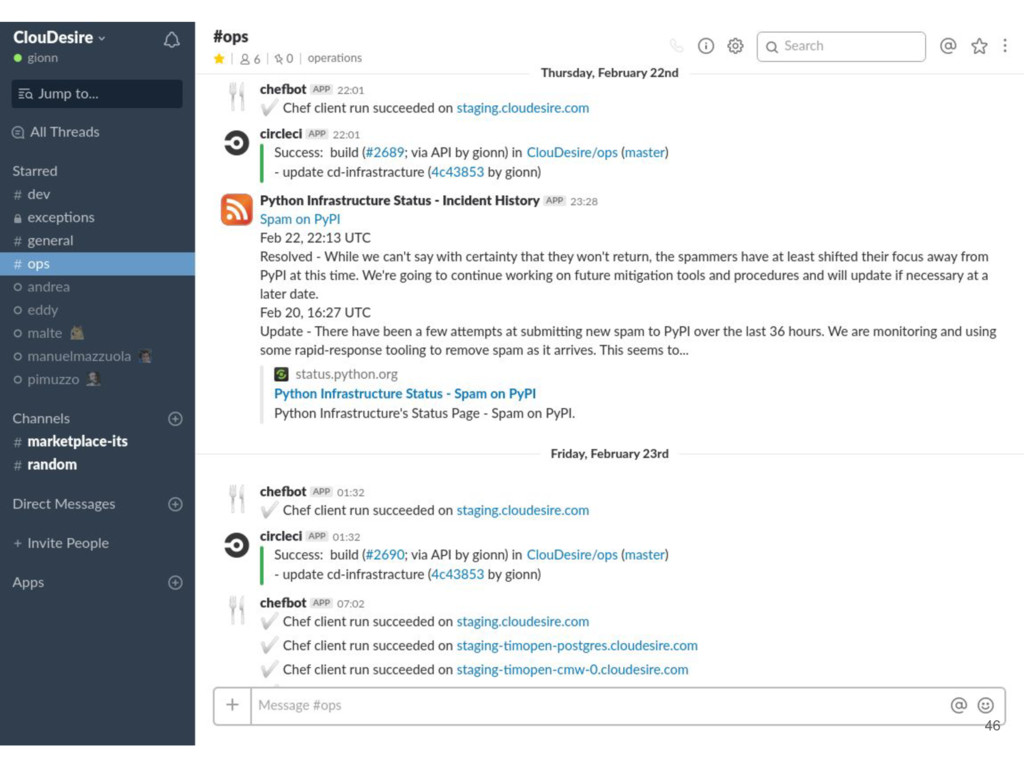
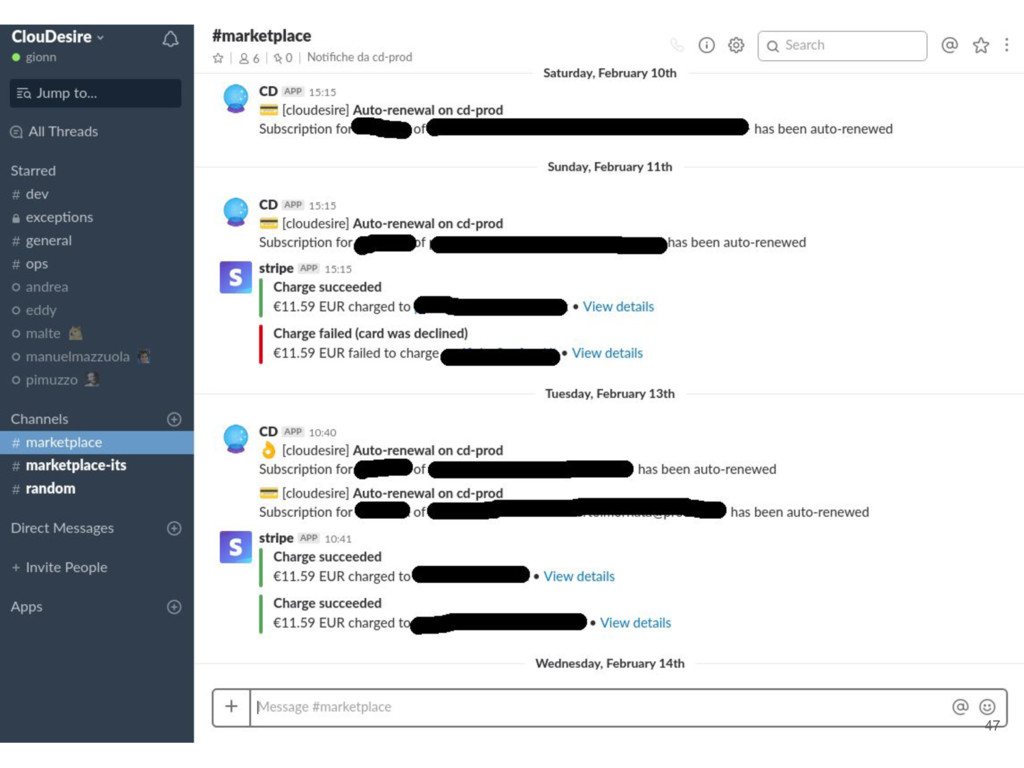
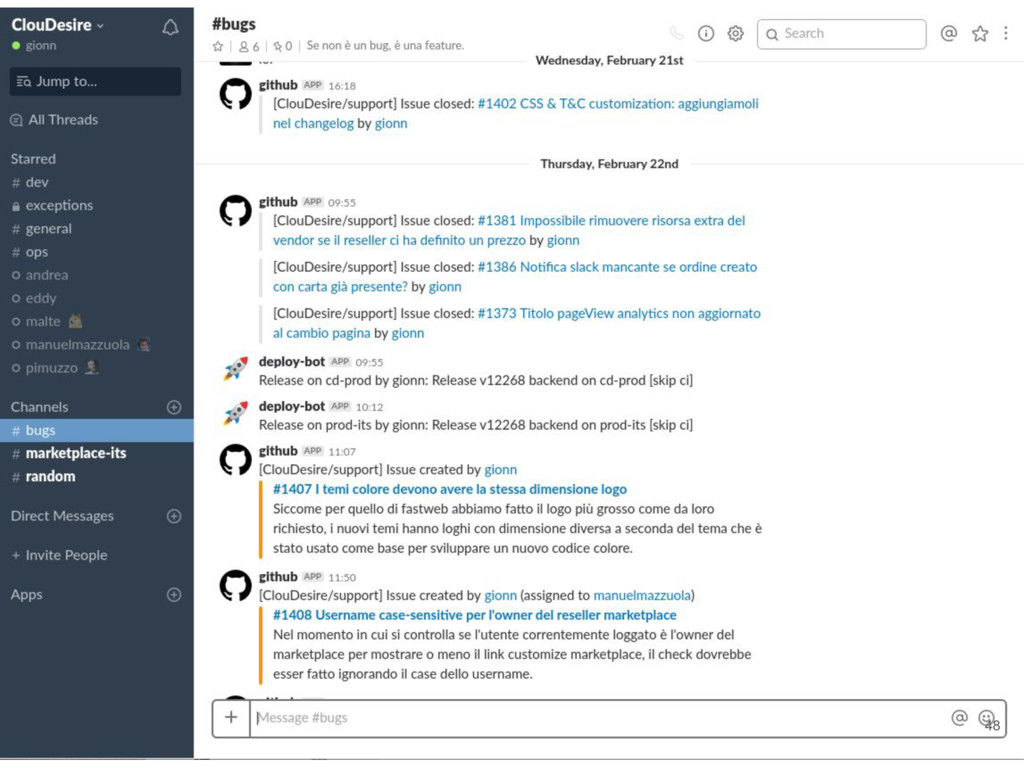
and notification system • #dev: developers communication, notification from github and circleci • #exceptions: high priority notification from sentry and updown.io • #ops: notification from chef runs, rss from external system status • #marketplace: notifications generated by cloudesire platform for a specific environment • #bugs: issue creation/closing and deployment to production environments notifications 43
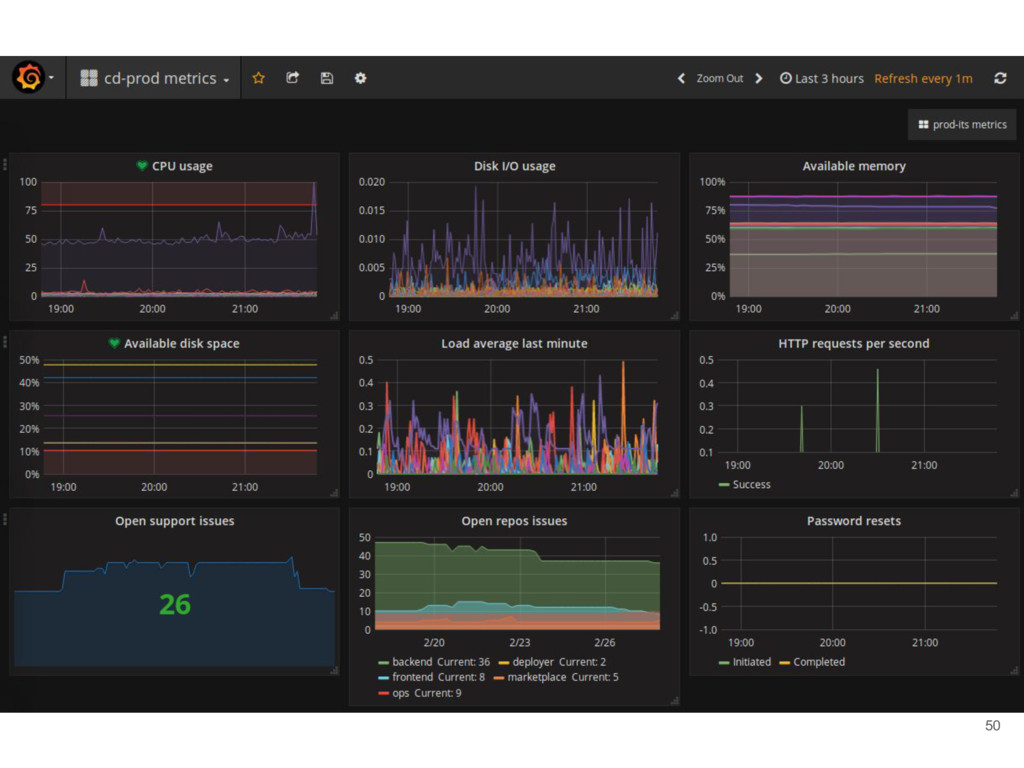
/ time-series database • Server scrape and store time series data • Metrics exporter for nodes and applications (nginx, mysql, etc) • Client libraries to instrument code • Alert manager to send notifications • Node autodiscovery via consul 49
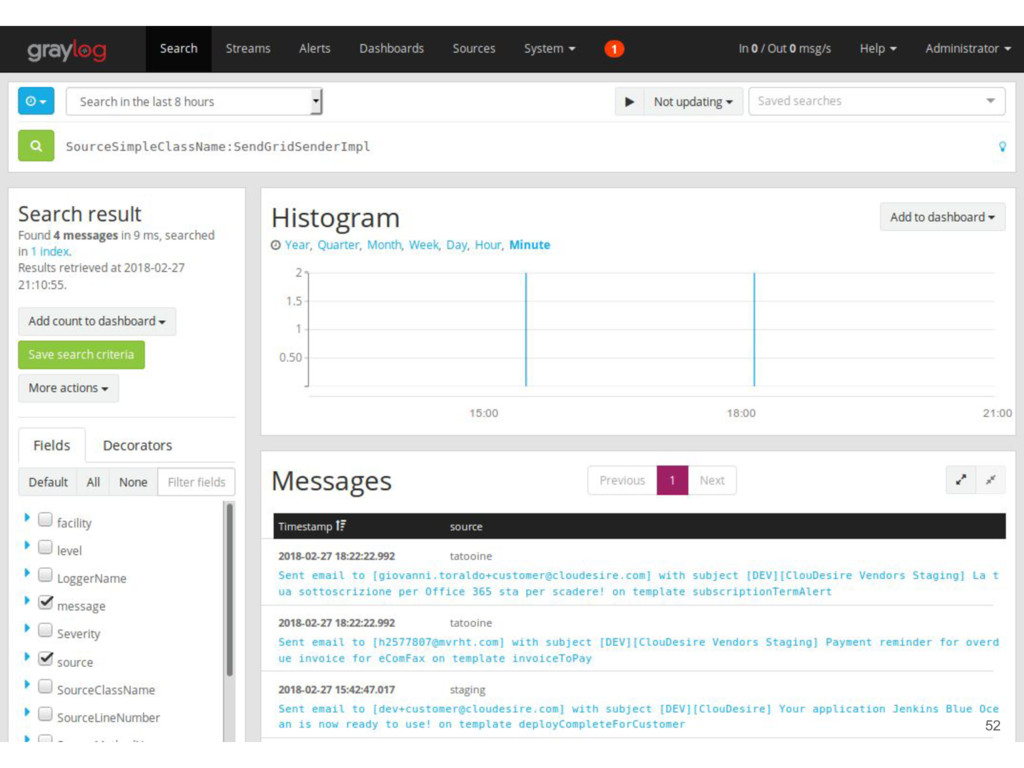
avoid when having multiple backends Graylog is an open source log management platform • ElasticSearch backend for logs storage/indexing • MongoDB backend for webapp persistence • Rsyslog TCP+SSL input • GELF input for application logs 51
chef orchestration ◦ Avoid complexity in chef recipes ◦ Scalable/fault-tolerant infrastructure • Kotlin to replace Java for backend modules ◦ Concise code ◦ Backward-compatibility • Full-remote developers ◦ Currently working 2 days a week from home 53
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}