Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
巨大モノリスを乗り越えろ! GREE Platform 20周年を支える「無停止クラウド移行」...
Search
gree_tech
PRO
October 17, 2025
Technology
460
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
巨大モノリスを乗り越えろ! GREE Platform 20周年を支える「無停止クラウド移行」実践事例
GREE Tech Conference 2025で発表された資料です。
https://techcon.gree.jp/2025/session/TrackB-6
gree_tech
PRO
October 17, 2025
More Decks by gree_tech
See All by gree_tech
我々はどう生きるか
gree_tech
PRO
0
2
変わるもの、変わらないもの :OSSアーキテクチャで実現する持続可能なシステム
gree_tech
PRO
0
5.1k
マネジメントに役立つ Google Cloud
gree_tech
PRO
0
72
今この時代に技術とどう向き合うべきか
gree_tech
PRO
3
2.8k
生成AIを開発組織にインストールするために: REALITYにおけるガバナンス・技術・文化へのアプローチ
gree_tech
PRO
0
470
安く・手軽に・現場発 既存資産を生かすSlack×AI検索Botの作り方
gree_tech
PRO
0
470
生成AIを安心して活用するために──「情報セキュリティガイドライン」策定とポイント
gree_tech
PRO
1
2.4k
あうもんと学ぶGenAIOps
gree_tech
PRO
0
590
MVP開発における生成AIの活用と導入事例
gree_tech
PRO
0
620
Other Decks in Technology
See All in Technology
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
700
AI驚き屋発見器
yama3133
1
380
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
310
人とエージェントが高め合う協業設計
kintotechdev
0
1.1k
BigQuery を検索ソースとした AI Agent の作り方って 〇〇 通りあんねん
satohjohn
0
140
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
290
AI エージェント時代のデジタルアイデンティティ
fujie
1
1.1k
VPCセキュリティ対応の最新事情
nagisa53
1
340
コンポーネント名には何を含めるべきなのか? / what-should-be-included-in-component-names
airrnot1106
0
180
QAタスクをスキル化したいときに考えること
aomoriringo
0
120
ウォーターフォール開発案件のPMとしてAI活用を模索している話
hatahata021
2
190
なぜMIXIはゼロトラスト基盤として クラウドフレアを選んだのか - Cloudflare Peer Point SASE User Voices
mixi_engineers
PRO
2
130
Featured
See All Featured
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Everyday Curiosity
cassininazir
0
260
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Documentation Writing (for coders)
carmenintech
77
5.4k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
380
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
750
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
640
We Are The Robots
honzajavorek
0
290
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Transcript
株式会社グリー エンジニア 高峰健志 巨大モノリスを乗り越えろ! GREE Platform 20周年を支える 「無停止クラウド移行」実践事例
総合旅行情報サイトにて、サーバーエンジニアに従事。 2011年にグリー株式会社(現:グリーホールディングス株式会社)へ GREE Developer Center 担当として入社。 複数チームへの合流を経る中で業務範囲を広げ、基盤開発以外にもデベロッ パーおよびユーザー向けのテクニカルサポート業務やNativeアプリ開発マネー ジメントなどを兼務。 現在、GREE
Platform部/PF開発グループのシニアマネージャーとして従事。 株式会社グリー エンジニア Takeshi Takamine (高峰 健志) 2
• 本セッションについて • 「GREE」について 事業サービスについて • 幻のクラウド移行計画 • 巨大モノリスシステムの正体 •
移行プロジェクトの課題 ◦ 課題1:モノリスを無停止で移行せよ! ◦ 課題2:ときに計画は裏切られる! ◦ 課題3:石橋は作って渡ろう! • まとめ 目次 3
本セッションについて 本セッションでは GREE Platformのオンプレ・クラウド移行の対応実績を元に、 現場で起きた課題への取り組みを 一緒に考えながら追体験することで、 皆さんの今後のシステム運用業務に お役立ちできるであろう経験・知識を 持ち帰っていただきたいと考えております。 今回は、プロダクト側のシステム担当者目線になります。
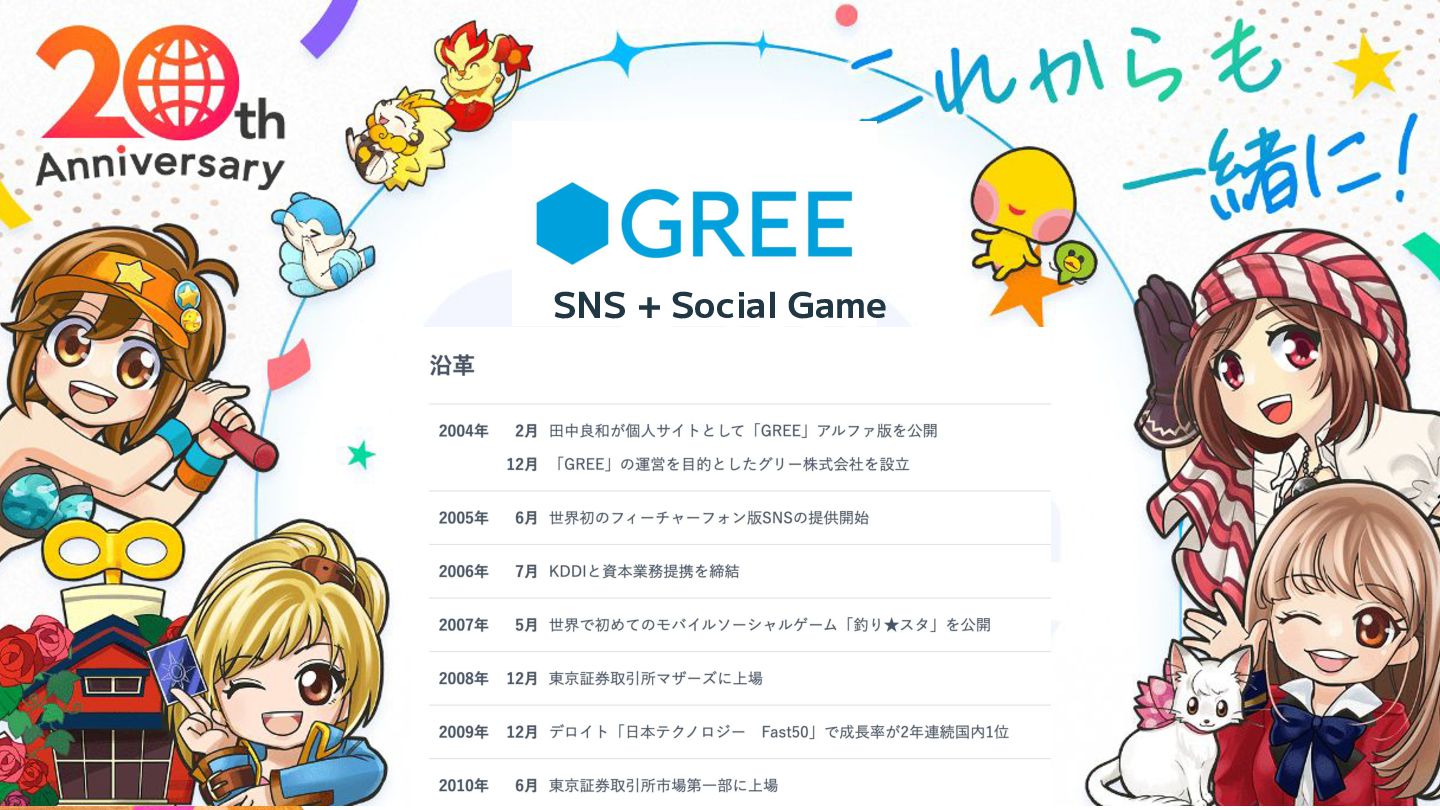
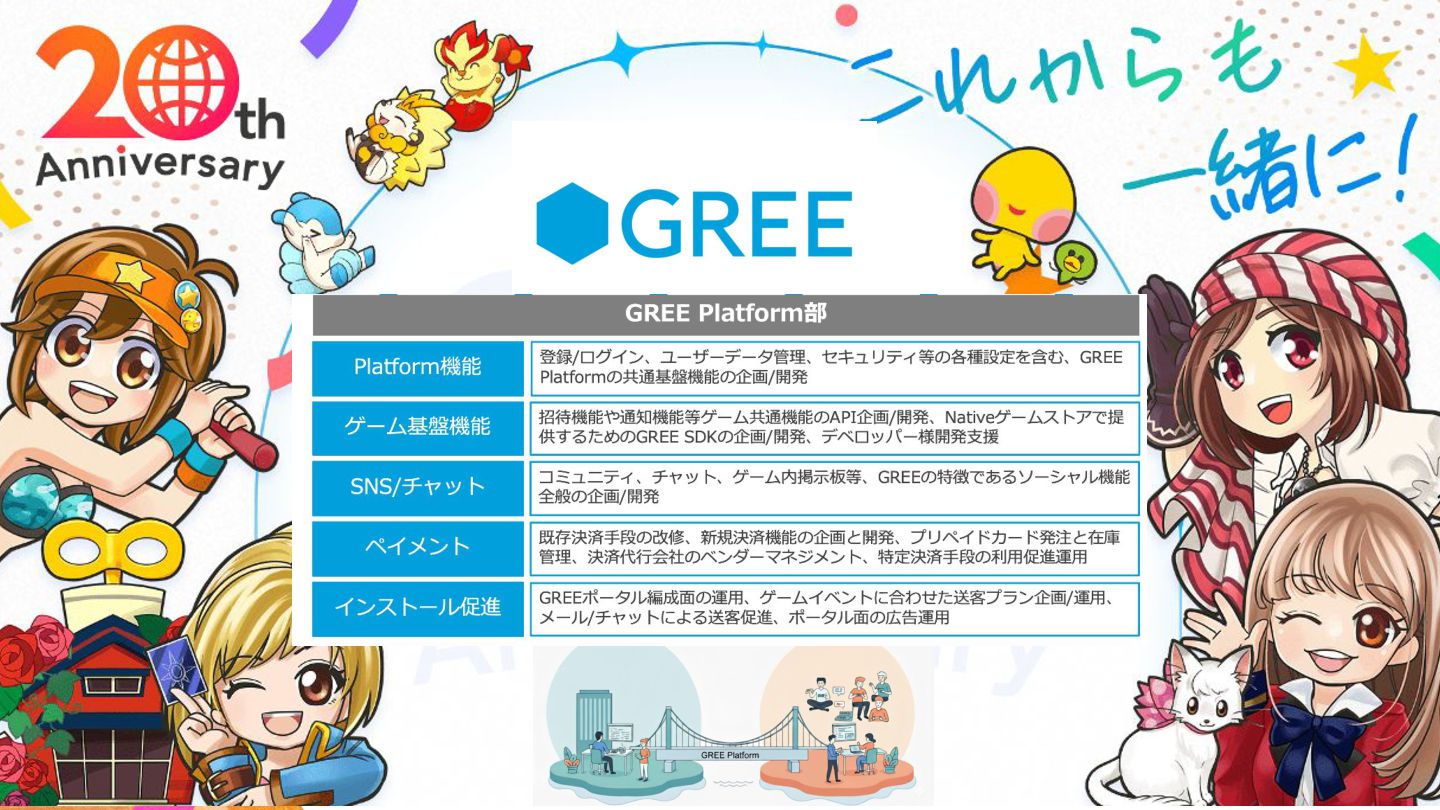
「GREE」事業サービスについて 5
6 SNS + Social Game
7
幻のクラウド移行計画 8
9 実は。。。 GREE のクラウド(AWS)移行対応は、2015年頃まで遡ります 2016- 2017年に、弊社の内製WEB Gameサービスは、 クラウド移行が完了しておりました。 では、なぜPlatformはクラウド移行しなかったのか 2011年:AWS
アジアパシフィック(東京)リージョンが開設
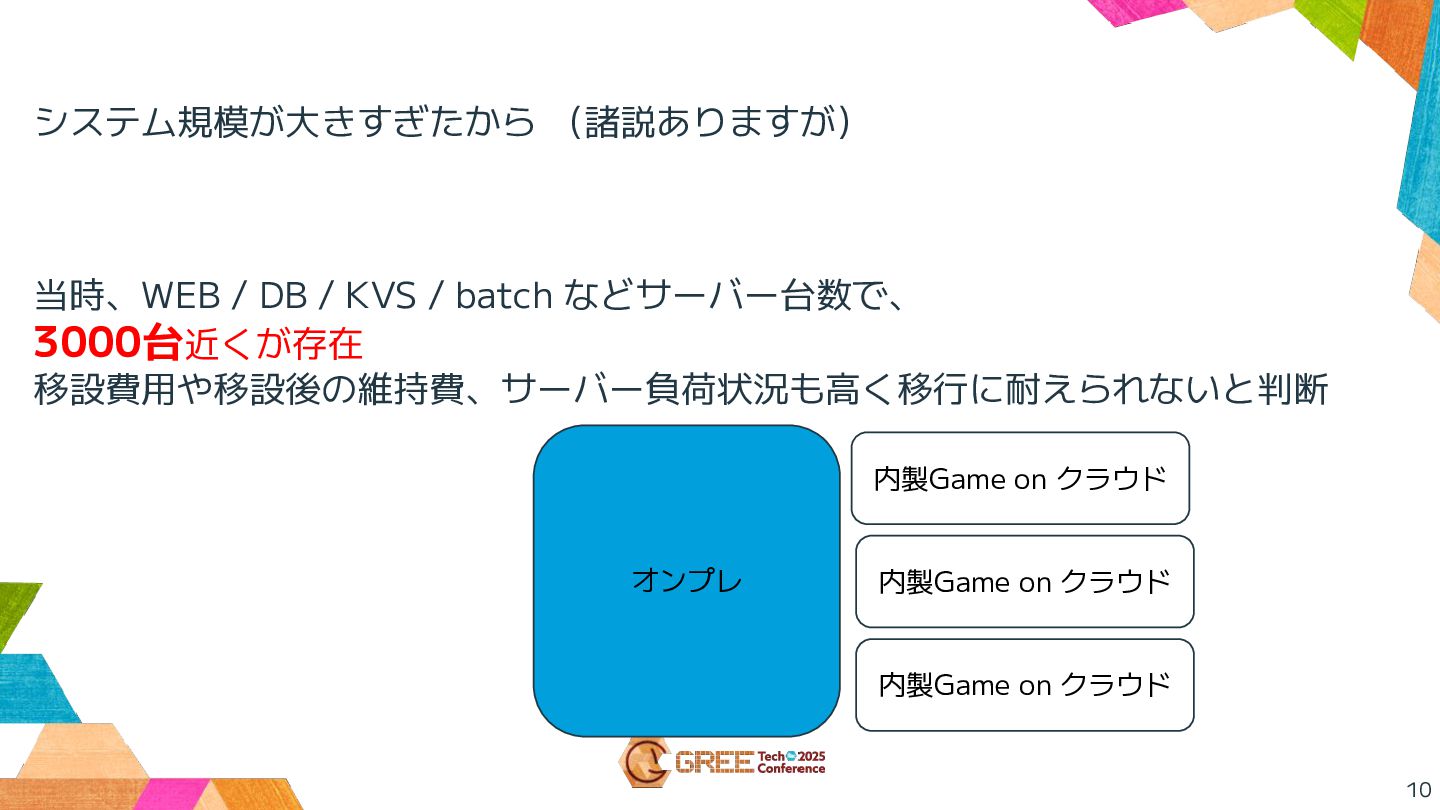
10 システム規模が大きすぎたから (諸説ありますが) 当時、WEB / DB / KVS / batch
などサーバー台数で、 3000台近くが存在 移設費用や移設後の維持費、サーバー負荷状況も高く移行に耐えられないと判断 オンプレ 内製Game on クラウド 内製Game on クラウド 内製Game on クラウド
巨大モノリスシステムの正体 11
「モノリス」設計とは 特徴 • 単一のコードベース : アプリケーション全体が1つのまとまったコード(プログラム)として書かれています。 • 単一のデプロイメント : アプリケーション全体が1つの実行ファイルやパッケージとしてサーバーにデプロイ(配置)されます。
• 密結合: アプリケーション内の様々な機能(例:ユーザー認証、商品管理、決済処理など)が強く結びついており、互いに依存しています。 メリット(初期段階や小規模なシステム) • 開発がシンプル: 小規模なプロジェクトや初期段階では、構造がシンプルで開発しやすいです。 • デバッグしやすい: 全体が一つなので、問題の特定が比較的容易な場合があります。 • 管理が容易: デプロイやテストが一度に行えます。 デメリット(大規模化や変化への対応) • 保守が困難: 特定の機能だけを修正しようとしても、他の部分に影響が出やすいため、慎重な作業が必要です。 • 拡張性の問題: アクセスが増えて負荷が高まった場合、アプリケーション全体をスケールアップ(より高性能なサーバーに載せ替える)する必要があ り、コストがかかります。特定の機能だけを増強することが難しいです。 • 技術選択の制限: 一度採用した技術スタック(プログラミング言語、フレームワークなど)を後から変更するのが非常に困難です。 • 開発チームのボトルネック : 大規模なチームで開発する場合、同じコードベースを触ることで衝突が起きやすくなります。 12
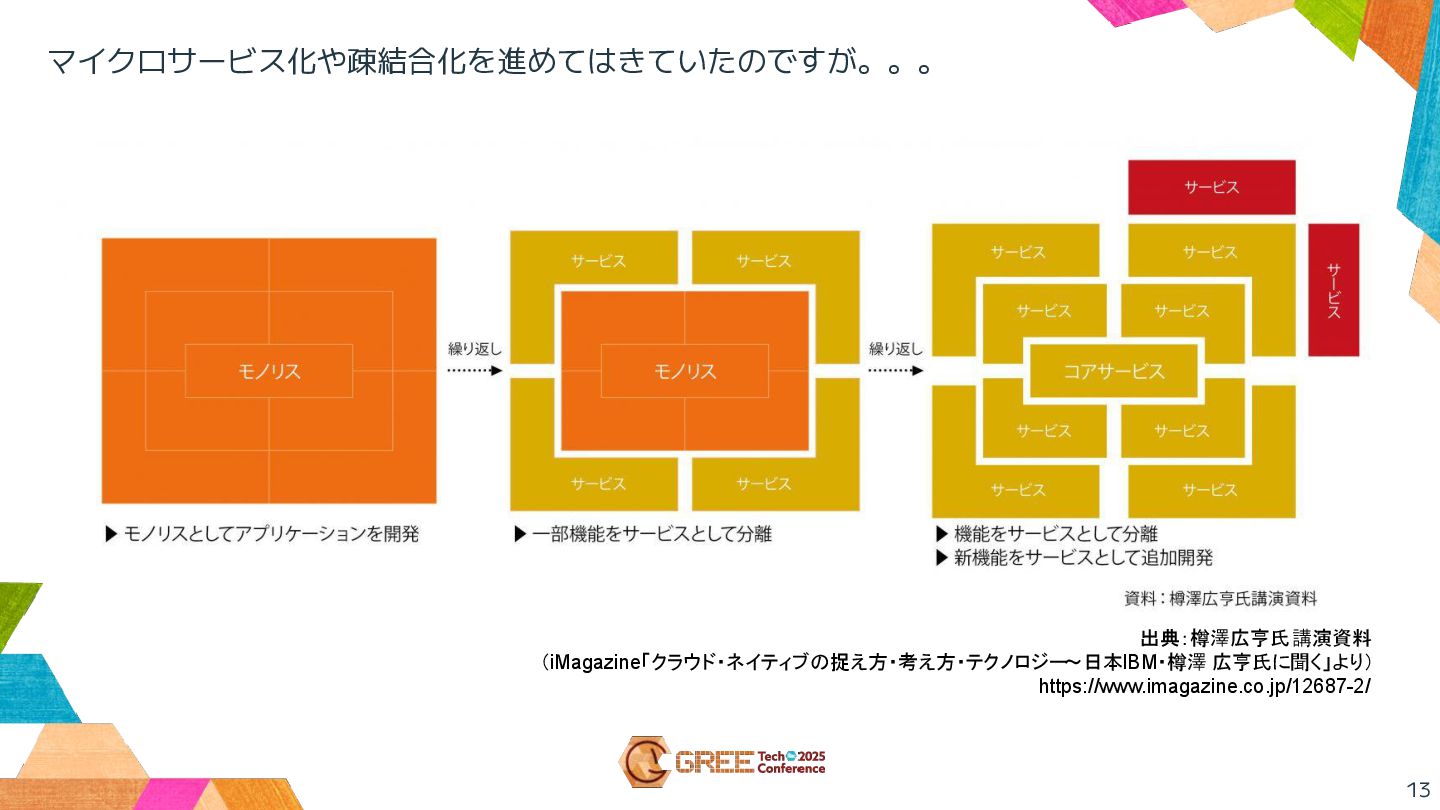
13 マイクロサービス化や疎結合化を進めてはきていたのですが。。。 出典:樽澤広亨氏 講演資料 (iMagazine「クラウド・ネイティブの捉え方・考え方・テクノロジー ~日本IBM・樽澤 広亨氏に聞く」より) https://www.imagazine.co.jp/12687-2/
14 運用コスト圧縮 クラウド移行再稼働への準備として推進 ・対策例 ・提供端末のクローズ (FP-ガラケー / PC) ・一部コンテンツのクローズ ・コンテンツのサーバー相乗り/統合
WEB / DB / KVS / batch などサーバー台数で、 1000台近くまで圧縮 移行費用や移行後の必要費用も大きく軽減化 いよいよ、GREE 本体のクラウド移行対応
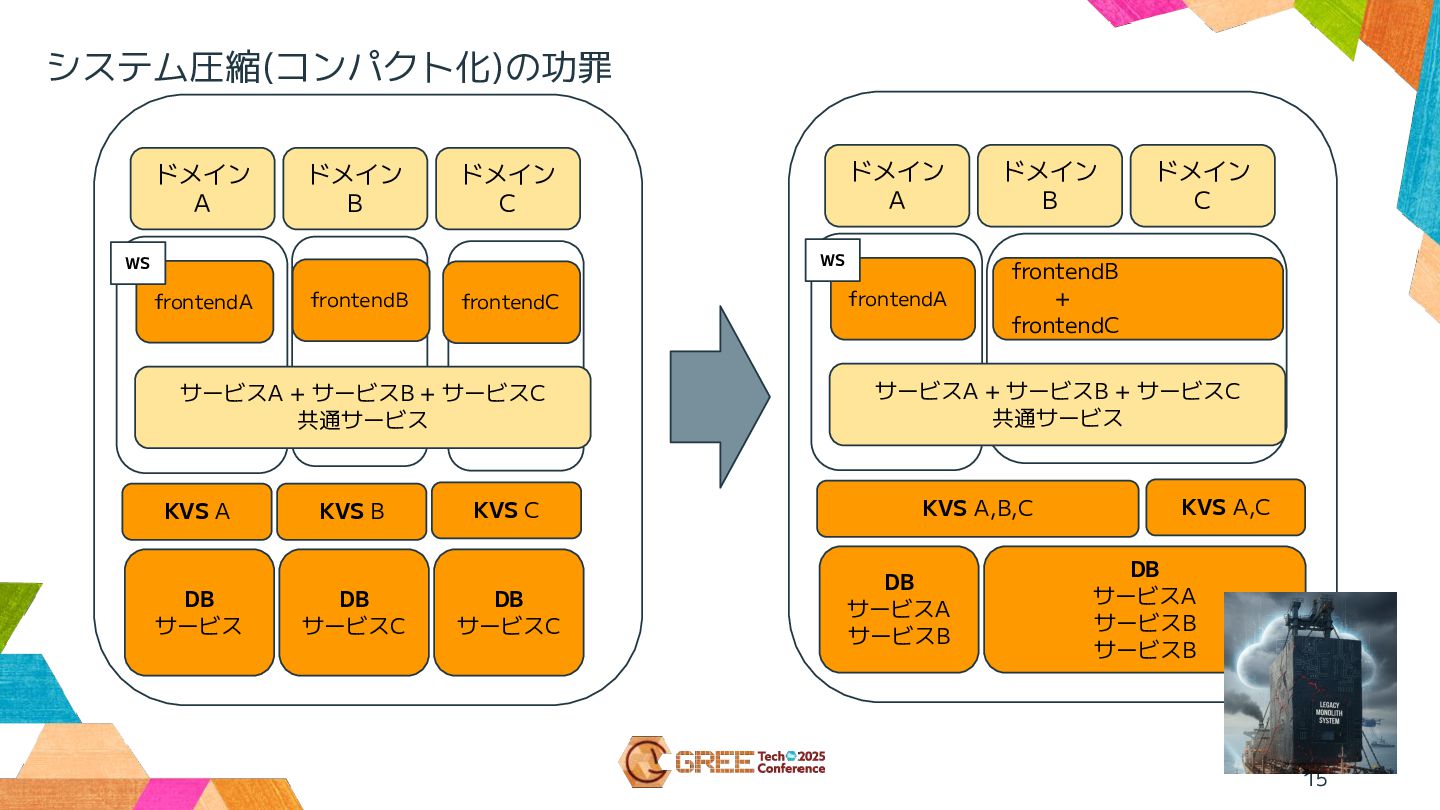
15 ドメイン A ドメイン B ドメイン C frontendA サービスA +
サービスB + サービスC 共通サービス frontendB + frontendC KVS A,B,C KVS A,C DB サービスA サービスB DB サービスA サービスB サービスB WS ドメイン A ドメイン B ドメイン C frontendA KVS A KVS B KVS C DB サービス DB サービスC DB サービスC WS frontendB frontendC サービスA + サービスB + サービスC 共通サービス システム圧縮(コンパクト化)の功罪
移行プロジェクトの課題 16
課題1:モノリスを無停止で移行せよ! 17
Thinking Time 下記のことに気をつけながらクラウド移行を行いましょう 各リソースをどんな順番で移行していきますか? WEB/DB/KVS(Flare:弊社独自redisのようなもの) ・機能・サービスは止めないでください。 ・移行コストや期限は、最小限に ・移行期間中もサービス影響が出ないことを前提 いろんな方法が考えられると思います。 18
ちなみに Gemini(生成AI) の検討結果 19 順位 移行順序 遅延リスクの特性 優先すべき事業目標 第1優先 KVS
→ DB → WEB 遅延解消の最適な順序:最も低遅延な KVSから解消するため、性能回 復のカーブが最もスムーズ。遅延影響期間は最短。 パフォーマンス回復の確実性 第2優先 DB → KVS → WEB データ整合性優先: DBを先に安定させることで、 KVS移行のリスクを 軽減。性能回復はC案に僅差で次ぐ。 データリスク管理と性能回復 の両立 第3優先 DB → WEB → KVS KVS遅延の放置:DBは早く解消されるが、最も低遅延が求められる KVSの遅延が最後まで残り、 Web移行後も性能ボトルネックが続く。 DB遅延の早期解消 (限定 的) 第4優先 WEB → DB → KVS 性能影響期間が最長: DB/KVSがオンプレに残る限り、 Web ↔ データ ストア間で遅延が発生し続け、サービス品質の低下が最も長く続く。 可用性・ロールバックの容易 さ 今回の発表資料作成時に、振り返りとともに聞いてみました。 弊社の当時の全情報を入れることはできないので、簡単なプロンプトにて
Answer 今回の移行計画は 下記の順番、粒度で移行を行なっていくことを決定 • DB -> WEB -> KVS —--(判断理由)
• DB先行 ◦ データ損出失敗時の影響抑制 ◦ オンプレ・クラウド間のレプリケーション遅延事前検証 ◦ 失敗して切り戻しがしやすいものを先行 • WEB先行 ◦ 通信遅延を最大限に広げることなく最小限の影響にする効果期待 20
課題2:ときに計画は裏切られる! 21
22 Thinking Time さすが、弊社インフラ担当者の考える計画は素晴らしいなと 「お願い致します♪」 お任せの波に乗っていたのですが。 1. DBを先行移行 2. WEBサーバーを移行
3. KVSを後追いで移行 このあと、計画通り進んでいた計画に問題が生じます どのフェーズで、どんな問題が生じたでしょうか。
Answer 1. DBを先行移行 2. WEBサーバーを移行 3. KVSを後追いで移行 なんと!WEBサーバーの構築・検証が間に合わない との報告が上がってきました。 23
Thinking Time インフラ担当者から下記の提案を受けます。 移行提案を変更 案1 DB → WEB → KVS
↓ 案2 DB → KVS→ WEB 1. 案1のままWEBサーバーの納品を待つ (移行計画:1-2ヶ月、数千万円の遅延が発生か?) 2. 案2を選択、KVSを先行で移行 (DBの通信遅延に加えて、KVSの通信遅延も追加.果たして耐えられる?) 24
課題3:石橋は叩いて割れても渡り切る! (反面教師的な事例) 25
「1通信あたりの許容遅延時間はどれくらいですか?」 潜在的課題: SLAの「見えない溝」事実 : • 通信遅延のSLAをインフラ担当者にて定義 /管理を行い、アプリ開発チームではその情報を元にコンテンツ 表示時間のSLAを定義管理して開発を行なっている。 • 安定状況の環境では、定義が揺るがないので問題はない(はず)。
• 問題/必要な情報 : 両者を繋ぐ最も重要な情報「 アプリの通信回数 (N)」の設計情報が欠落している。 ◦ 例)X 機能は、DB通信が3回、KVSの通信を2回行なっている機能である ◦ 例)DBへの通信は5回まで、KVSの通信は10回までに収める基準が構築ルール 2. 課題の深刻度: ワーストケースの存在 : 検証機投入での結果にて、表示時間の SLA越えをしている時間帯の存在が確認された。 リクエスト処理時間 のP90 外ではあるが顧客離脱に影響する可能性がある 。 【緊急課題】サービス信頼性を脅かす「SLAの見えない溝」と性 能ボトルネックの可視化 26
それでも 突き進みましょう。 処理時間が極端に遅い処理は 緊急に見直し修正を実施したものの すぐになんでも直せるものではなく不安は消えず 鳴かないカナリア(監視閾値越え)を飼い慣らすことを決意 CS担当及び営業部署へ情報共有を行い 運用変化・影響異変の検知能力を高めつつ実行へ 27
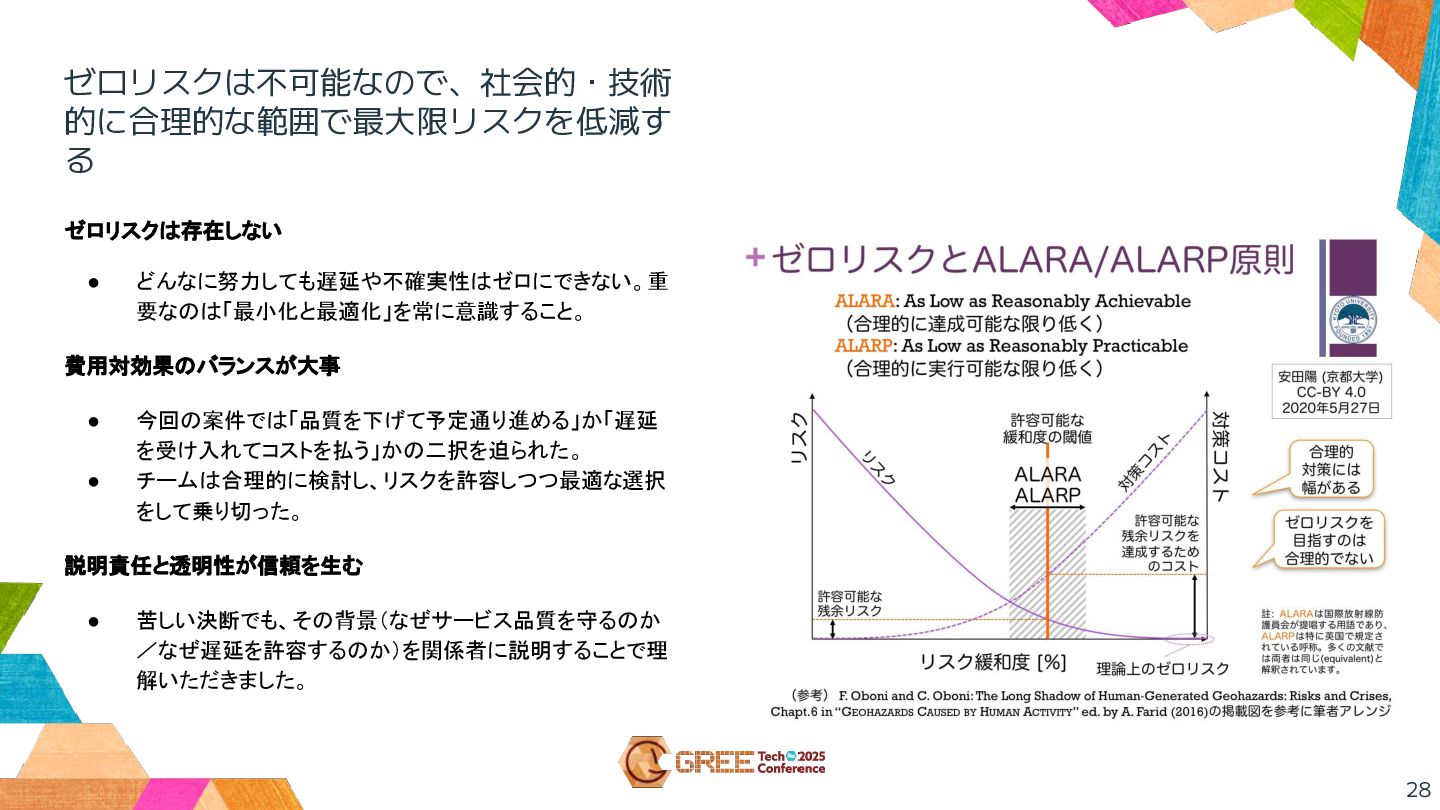
ゼロリスクは不可能なので、社会的・技術 的に合理的な範囲で最大限リスクを低減す る ゼロリスクは存在しない • どんなに努力しても遅延や不確実性はゼロにできない。重 要なのは「最小化と最適化」を常に意識すること。 費用対効果のバランスが大事 • 今回の案件では「品質を下げて予定通り進める」か「遅延
を受け入れてコストを払う」かの二択を迫られた。 • チームは合理的に検討し、リスクを許容しつつ最適な選択 をして乗り切った。 説明責任と透明性が信頼を生む • 苦しい決断でも、その背景(なぜサービス品質を守るのか /なぜ遅延を許容するのか)を関係者に説明することで理 解いただきました。 28
Answer この時、私は 1. 案1のままWEBサーバーの納品を待つ 2. 案2を選択、KVSを先行で移行 => 不要コスト発生抑制と、実施可能な可能性を選択 不安を抱えながら、KVS担当の方に ダメだったら切り戻しする対応工数は気にしないで良いよ
と後押しをもらいこの判断に 29
移行完了 ここでは語れないら話は沢山ありつつも、 無事クラウド上で稼働するサービスとなりました。 関係各所の皆様 ご協力ありがとうございました。 30
まとめ 31
32 大事なポイント: ・運用システムの管理規模の適用化 (マイクロサービス化) ・自分たちで制御できるシステム規模の見極め ・日々の運用コンテンツ・通信状態の管理把握の大切さ ・SLA/SLOの設定と許容範囲の把握 ・安全確保が確保されていない道でも、順次安全ポイントを作り前に進む勇気を持つ のと必ず後退判断できる領域を確保する
本セッションでの追憶から 皆さんの管理運営しているシステム運営も 長期かつ安定的に稼働いただけるヒントになればと思います。 33
ご清聴ありがとうございました 34
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}