Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
lambdaの連鎖で作るRecommendEngine
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
gree_tech
PRO
July 08, 2019
Technology
670
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
lambdaの連鎖で作るRecommendEngine
「Cloud Native Meetup Tokyo #8 」で発表された資料です。
https://cloudnative.connpass.com/event/130892/
gree_tech
PRO
July 08, 2019
More Decks by gree_tech
See All by gree_tech
変わるもの、変わらないもの :OSSアーキテクチャで実現する持続可能なシステム
gree_tech
PRO
0
5k
マネジメントに役立つ Google Cloud
gree_tech
PRO
0
72
今この時代に技術とどう向き合うべきか
gree_tech
PRO
3
2.8k
生成AIを開発組織にインストールするために: REALITYにおけるガバナンス・技術・文化へのアプローチ
gree_tech
PRO
0
470
安く・手軽に・現場発 既存資産を生かすSlack×AI検索Botの作り方
gree_tech
PRO
0
470
生成AIを安心して活用するために──「情報セキュリティガイドライン」策定とポイント
gree_tech
PRO
1
2.4k
あうもんと学ぶGenAIOps
gree_tech
PRO
0
580
MVP開発における生成AIの活用と導入事例
gree_tech
PRO
0
610
機械学習・生成AIが拓く事業価値創出の最前線
gree_tech
PRO
0
500
Other Decks in Technology
See All in Technology
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
140
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
270
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.4k
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
110
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
2
150
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
320
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
810
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
640
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
250
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
150
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.5k
AI時代こそ、スケールしないことをしよう -「作る人」から「なぜ作るか」を考える人へ / Do Things That Don't Scale in the AI Era — From How to Why
kaminashi
1
120
Featured
See All Featured
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
The Limits of Empathy - UXLibs8
cassininazir
1
540
Six Lessons from altMBA
skipperchong
29
4.3k
Context Engineering - Making Every Token Count
addyosmani
9
1k
Building the Perfect Custom Keyboard
takai
2
820
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
The Curse of the Amulet
leimatthew05
2
13k
Transcript
lambdaの連鎖で作る Recommend Engine
Masahiro Higuchi / 樋口雅拓 • グリーグループのリミア株式会社で、LIMIA という住まい領域のメディアを 作っています。ゲーム会社ですが、最近はメディアに力を入れています。 • 機械学習のエンジニアですが、iOS,
Android,JSなどもやっている何でも屋 です。4歳の娘のパパ。twitter: @mahiguch1 • https://limia.jp/ • https://arine.jp/ • https://aumo.jp/ • https://www.mine-3m.com/mine/
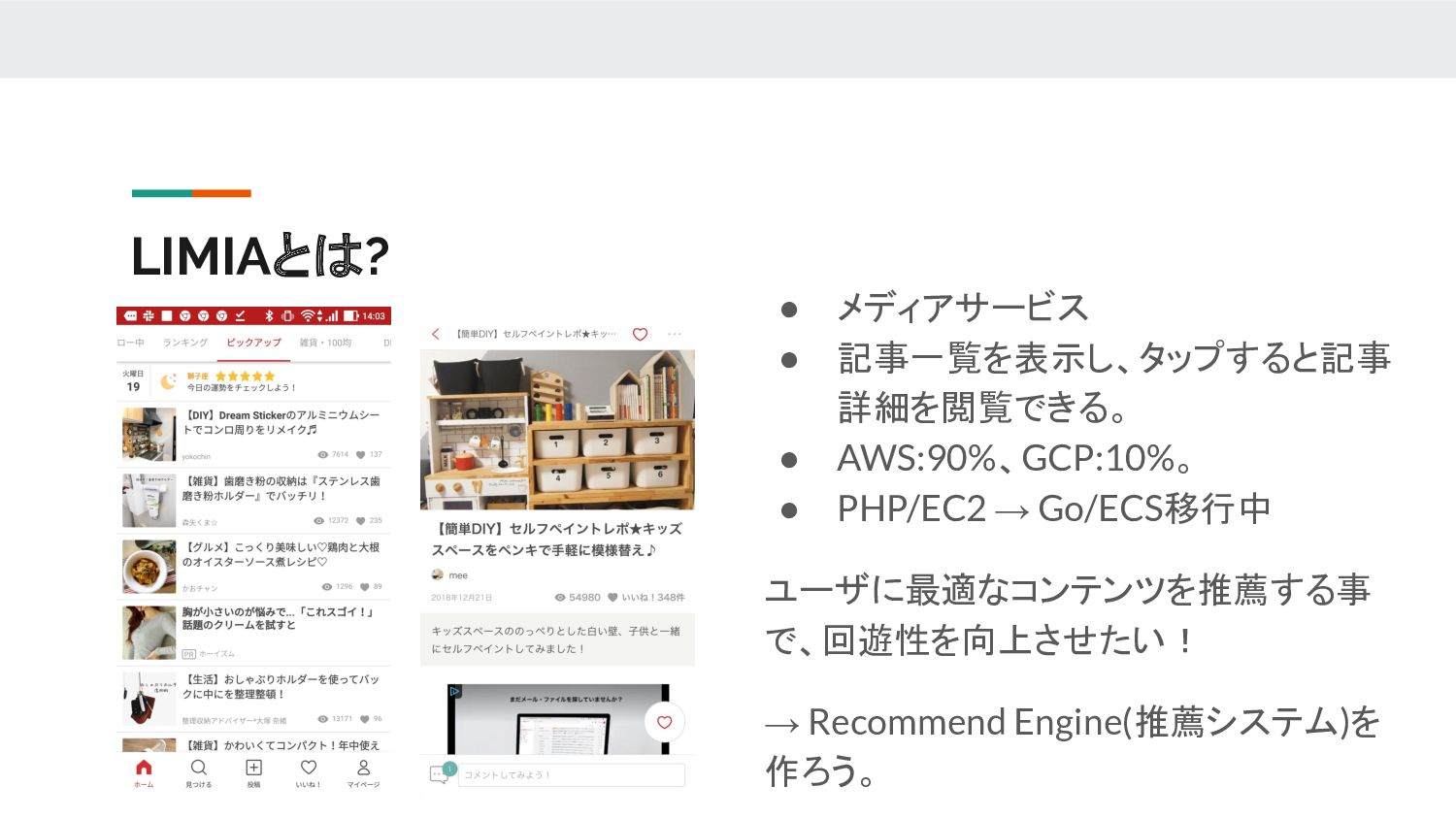
LIMIAとは? • メディアサービス • 記事一覧を表示し、タップすると記事 詳細を閲覧できる。 • AWS:90%、GCP:10%。 • PHP/EC2
→ Go/ECS移行中 ユーザに最適なコンテンツを推薦する事 で、回遊性を向上させたい! → Recommend Engine(推薦システム)を 作ろう。
どうやってRecommendするのか • ユーザを10個ぐらいのセグメントに分類 • セグメント毎にCTRを計算 • 記事の投稿日時で補正したCTRが高い順にリストに掲載 → せっかく今から作るんだから、インスタンスを立てずに行こう!
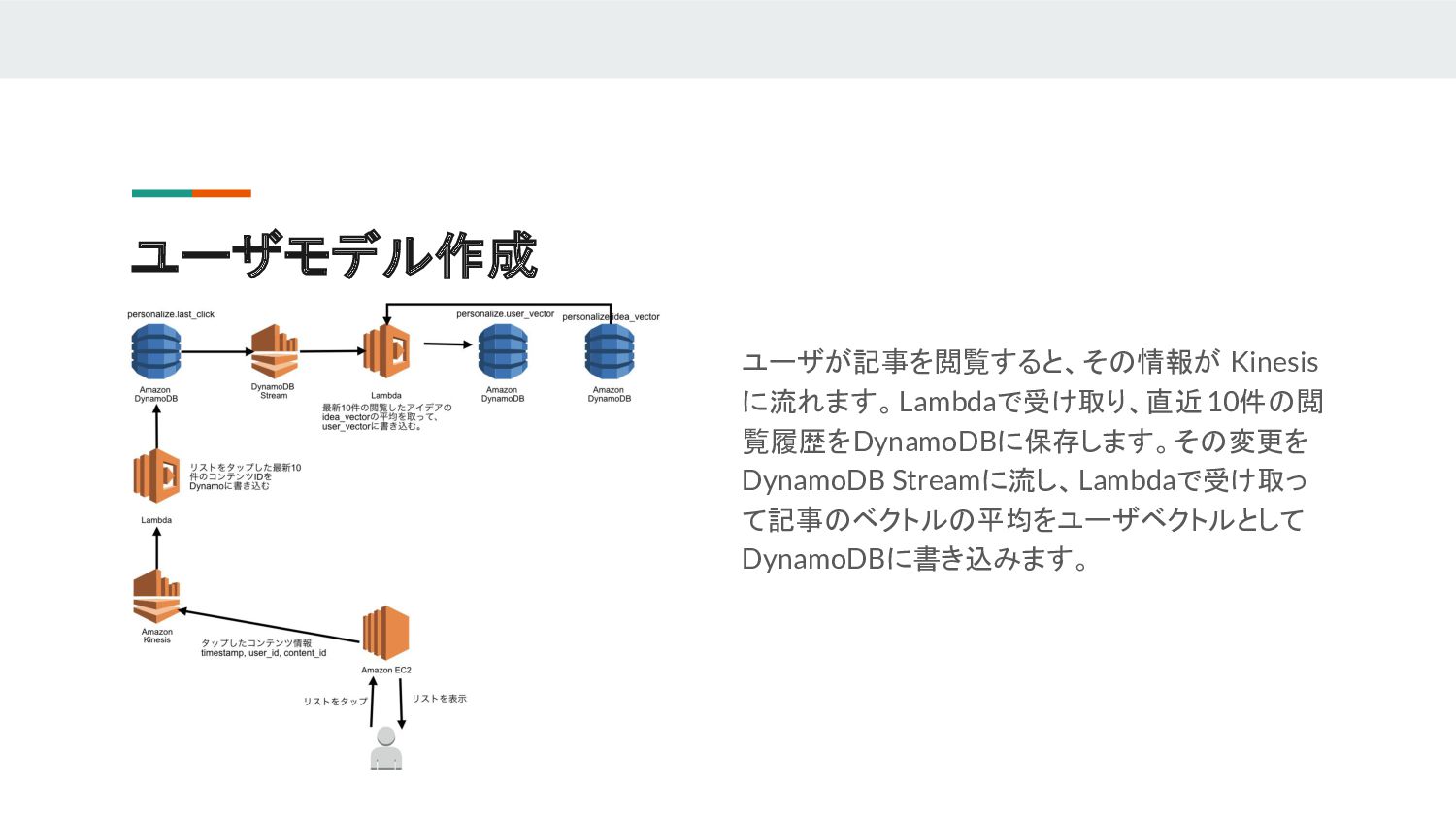
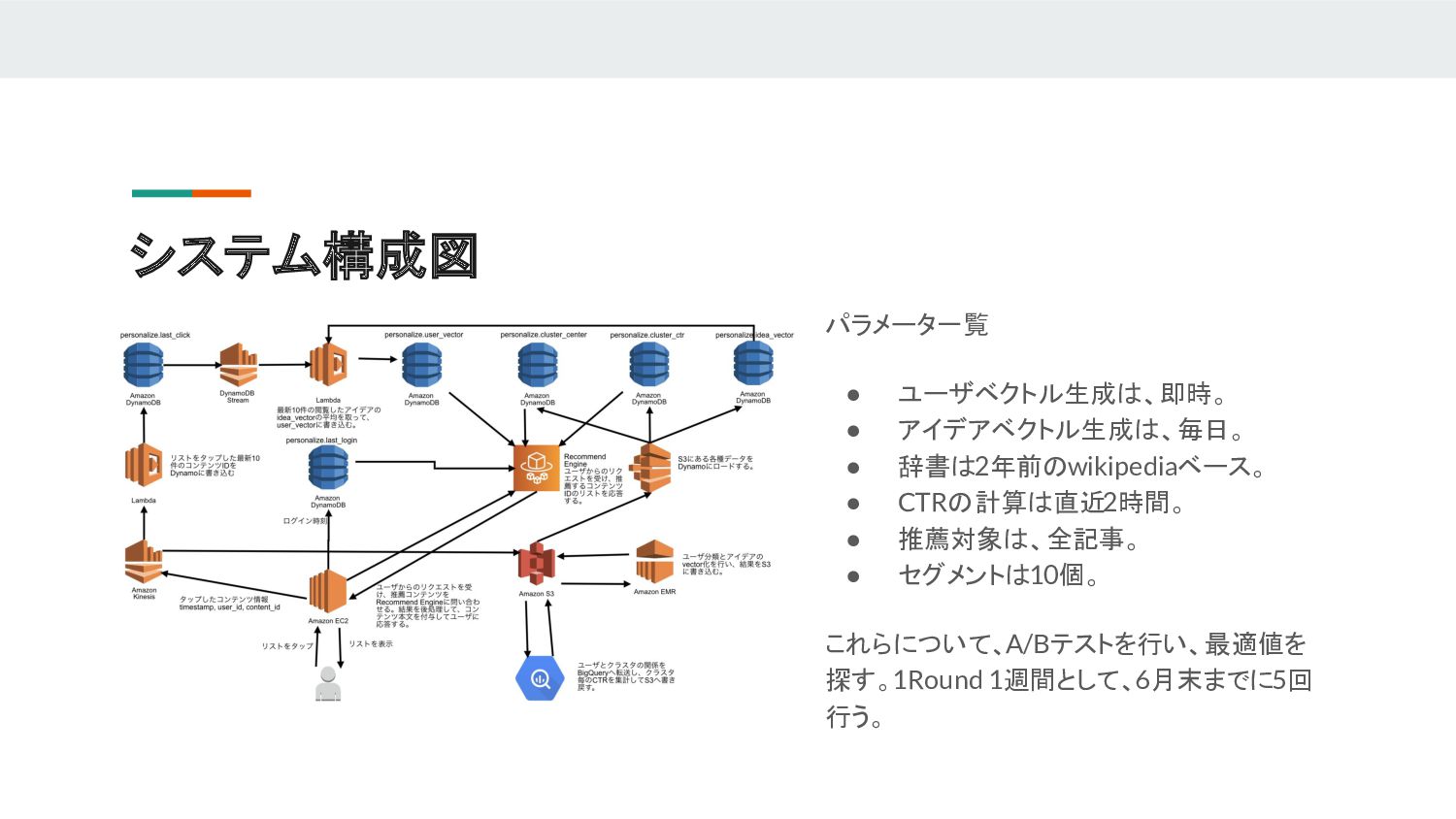
ユーザモデル作成 ユーザが記事を閲覧すると、その情報が Kinesis に流れます。Lambdaで受け取り、直近10件の閲 覧履歴をDynamoDBに保存します。その変更を DynamoDB Streamに流し、Lambdaで受け取っ て記事のベクトルの平均をユーザベクトルとして DynamoDBに書き込みます。
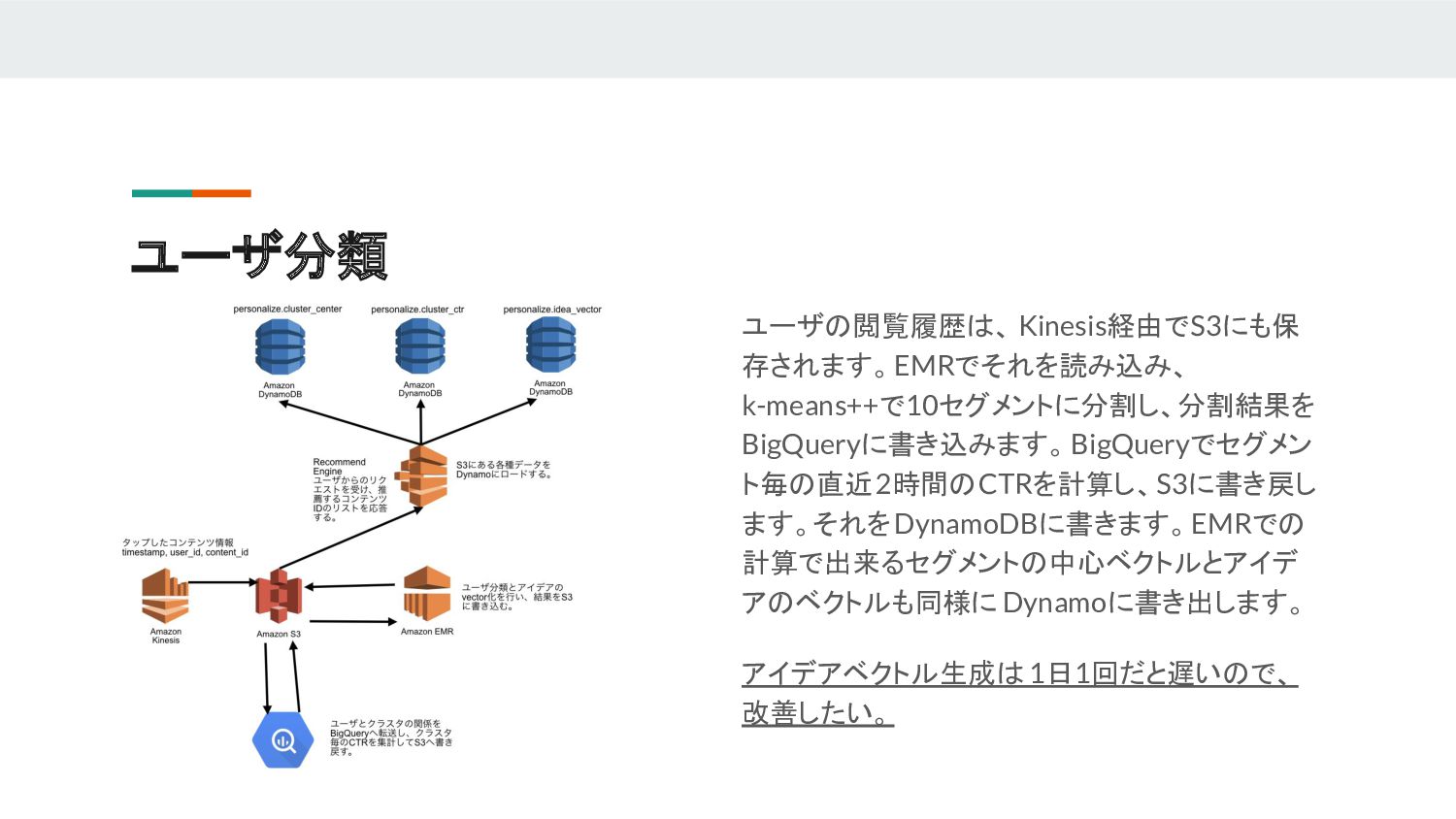
ユーザ分類 ユーザの閲覧履歴は、 Kinesis経由でS3にも保 存されます。EMRでそれを読み込み、 k-means++で10セグメントに分割し、分割結果を BigQueryに書き込みます。BigQueryでセグメン ト毎の直近2時間のCTRを計算し、S3に書き戻し ます。それをDynamoDBに書きます。EMRでの 計算で出来るセグメントの中心ベクトルとアイデ アのベクトルも同様に
Dynamoに書き出します。 アイデアベクトル生成は 1日1回だと遅いので、 改善したい。
配信 ユーザが記事一覧を表示しようとすると、 Recommend Engineに問い合わせます。 Recommend Engineはユーザの直近10件の記事閲 覧履歴から所属するセグメントを選び、そのセグメント のユーザの直近2時間のCTRが高いものを表示しま す。ただし、古い記事ほど減点し、ユーザの前回ログ イン以降に投稿された記事は加点します。
Recommend Engineはgolangで書いて、 ECS/Fargateで動かしています。
システム構成図 パラメータ一覧 • ユーザベクトル生成は、即時。 • アイデアベクトル生成は、毎日。 • 辞書は2年前のwikipediaベース。 • CTRの計算は直近2時間。
• 推薦対象は、全記事。 • セグメントは10個。 これらについて、A/Bテストを行い、最適値を 探す。1Round 1週間として、6月末までに5回 行う。
まとめ • Recommend Engineは簡単に作れる。 • 今の所は既存編成ロジックより良い結果が出ている。 • システム的にはアイデアベクトル生成をリアルタイムで行いたい。しかし、 S3にある5GBの辞書 を読み込む必要があるため、
Lambdaで実行時に読み込むとコスト的にやばい。何か良いアイ デアがあれば教えて欲しい。 ありがとうございました。懇親会でぜひ声をかけてください!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}