Cloud Native Database Meetup #4 登壇資料
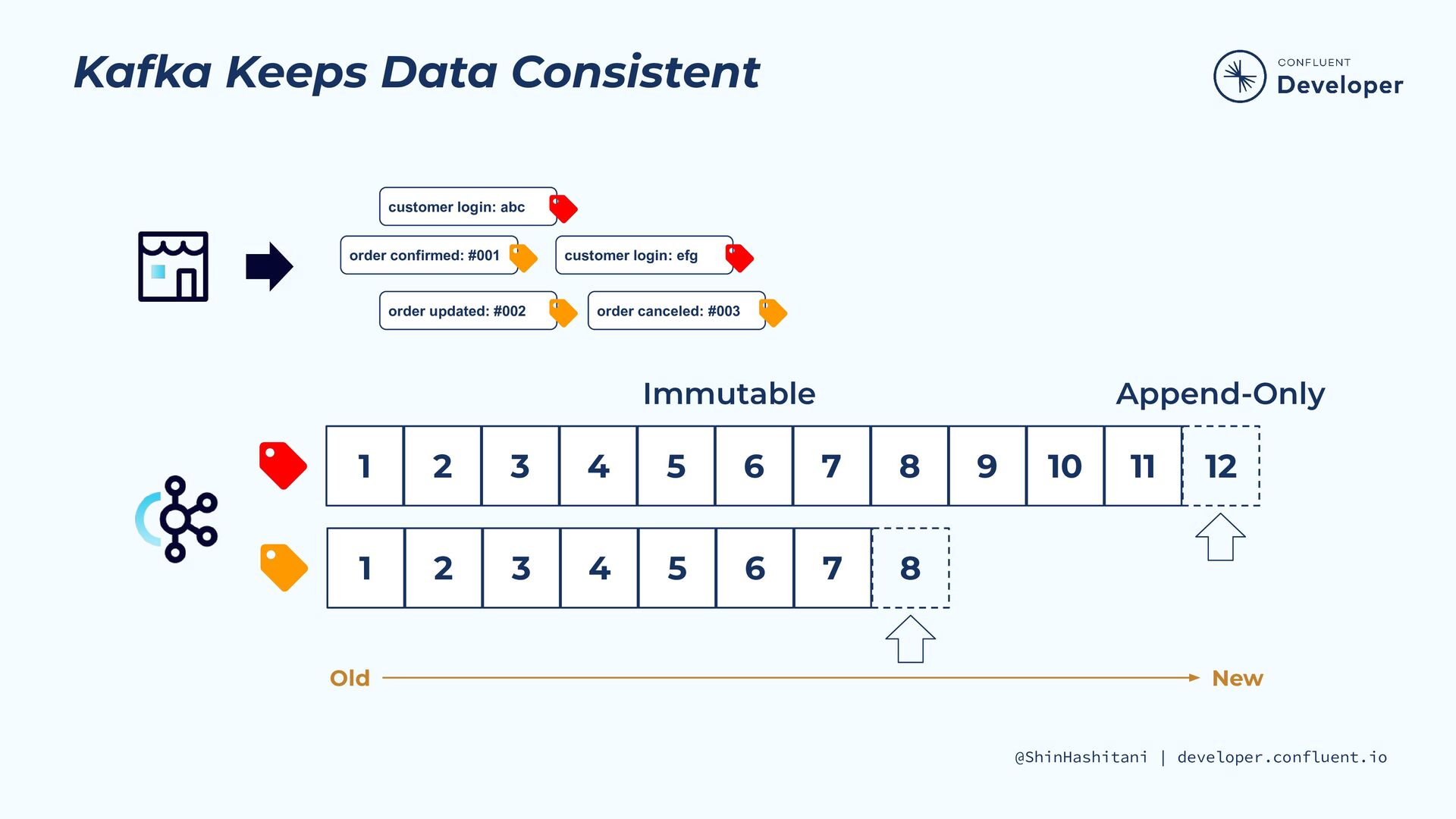
ksqlDBはKafkaを利用する事を前提としたストリーム処理エンジンです。 『DB』という名前が付いてはいますが、DBでありながらストリーム処理エンジンでもある少し変わった個性を持つ技術です。Kafkaエコシステムの中でKafka Streamsと共に育った技術ですが、ストリーム処理の枠を超えてDBとしての道を歩み始めています。
KafkaとKafka Streamsと強いつながりを持つksqlDBは、その特性を理解することで長所を生かした活用が可能です。
本セッションではksqlDBの概要、Kafka StreamsとksqlDBの関わりと、合わせてksqlDBの仕組みについてもご紹介いたします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}