Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CVPR2026論文紹介:Efficiently Reconstructing Dynamic...
Search
hinako0123
June 20, 2026
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CVPR2026論文紹介:Efficiently Reconstructing Dynamic Scenes One D4RT at a Time
hinako0123
June 20, 2026
More Decks by hinako0123
See All by hinako0123
CVPR2026現地参加報告
hinako0123
0
130
ICCV2025論文紹介:FlowEdit
hinako0123
0
170
ICCV2025現地参加報告
hinako0123
0
190
ICCV2025論文紹介:SAM2Long
hinako0123
0
200
ECCV2024現地参加報告
hinako0123
0
32
CVPR2025現地参加報告
hinako0123
0
160
CVPR2025論文紹介:動画像分類
hinako0123
0
110
CVPR2025論文紹介:Segmentation
hinako0123
0
200
ECCV2024論文紹介:Vision & Language
hinako0123
0
170
Featured
See All Featured
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Making the Leap to Tech Lead
cromwellryan
135
10k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
The Language of Interfaces
destraynor
162
27k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
The World Runs on Bad Software
bkeepers
PRO
72
12k
Code Reviewing Like a Champion
maltzj
528
40k
Music & Morning Musume
bryan
47
7.3k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
320
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
Transcript
CVPR2026 Best paper award Efficiently Reconstructing Dynamic Scenes One D4RT
at a Time 中京大学 工学研究科 工学専攻 博士2年 村上 尚生 名古屋CV・PRML勉強会 June 20, 2026 プロジェクトページ: https://d4rt-paper.github.io/
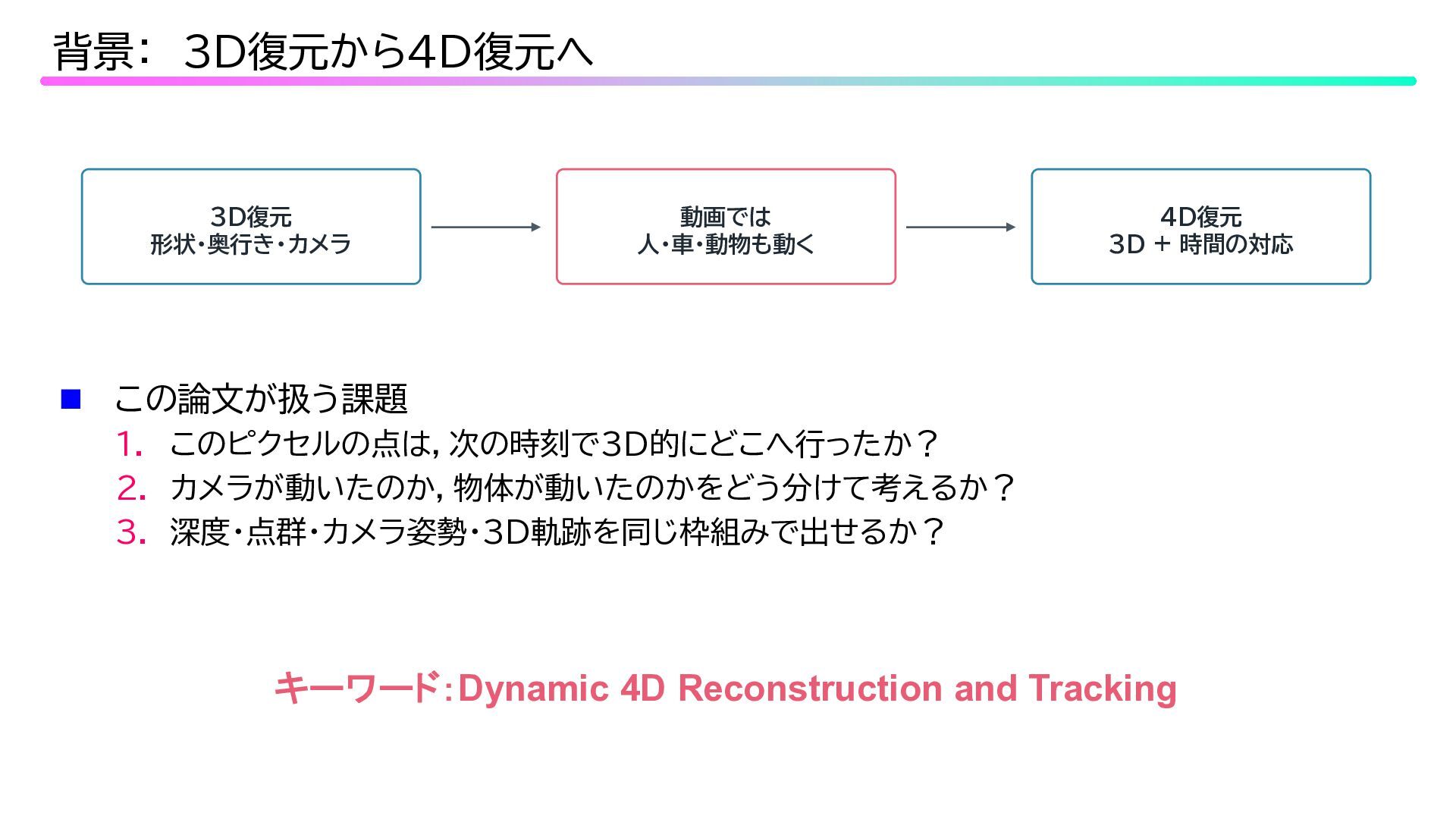
この論文が扱う課題 1. このピクセルの点は,次の時刻で3D的にどこへ行ったか? 2. カメラが動いたのか,物体が動いたのかをどう分けて考えるか? 3. 深度・点群・カメラ姿勢・3D軌跡を同じ枠組みで出せるか? 背景: 3D復元から4D復元へ
3D復元 形状・奥行き・カメラ 動画では 人・車・動物も動く 4D復元 3D + 時間の対応 キーワード:Dynamic 4D Reconstruction and Tracking
1. タスクごとに処理が分かれている D復元・深度推定・カメラ推定・点追跡を別々のモジュールで処理 2. 動く物体の対応づけが苦手 生き物や車などな動的物体は,フレームごとの点群を重ねるだけだと残像や穴が出る 3. 後処理や最適化が重い
複数のモデルから出た結果を統合するため計算コストが高くなる 従来手法の課題
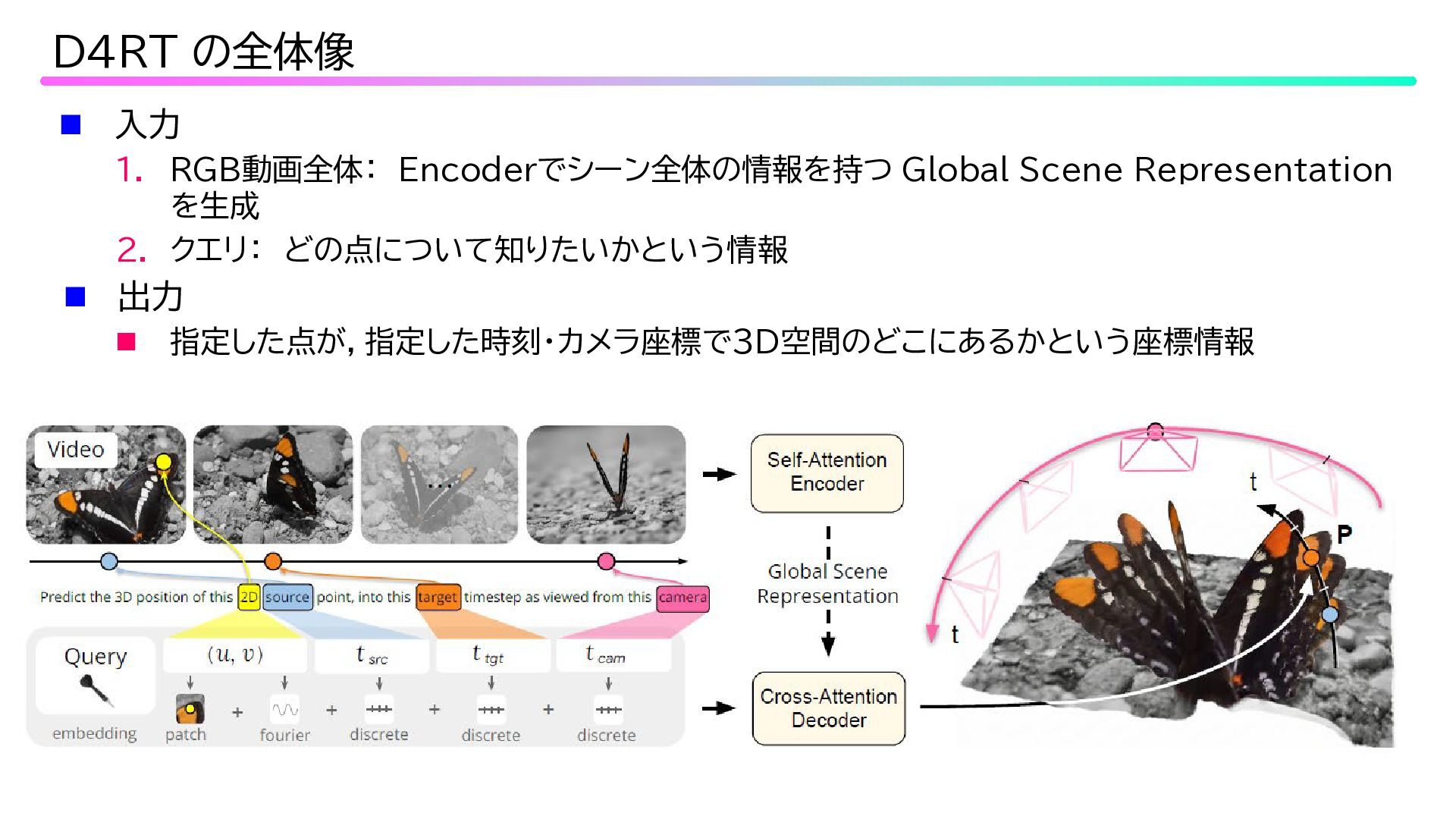
入力 1. RGB動画全体: Encoderでシーン全体の情報を持つ Global Scene Representation を生成 2.
クエリ: どの点について知りたいかという情報 出力 指定した点が,指定した時刻・カメラ座標で3D空間のどこにあるかという座標情報 D4RT の全体像
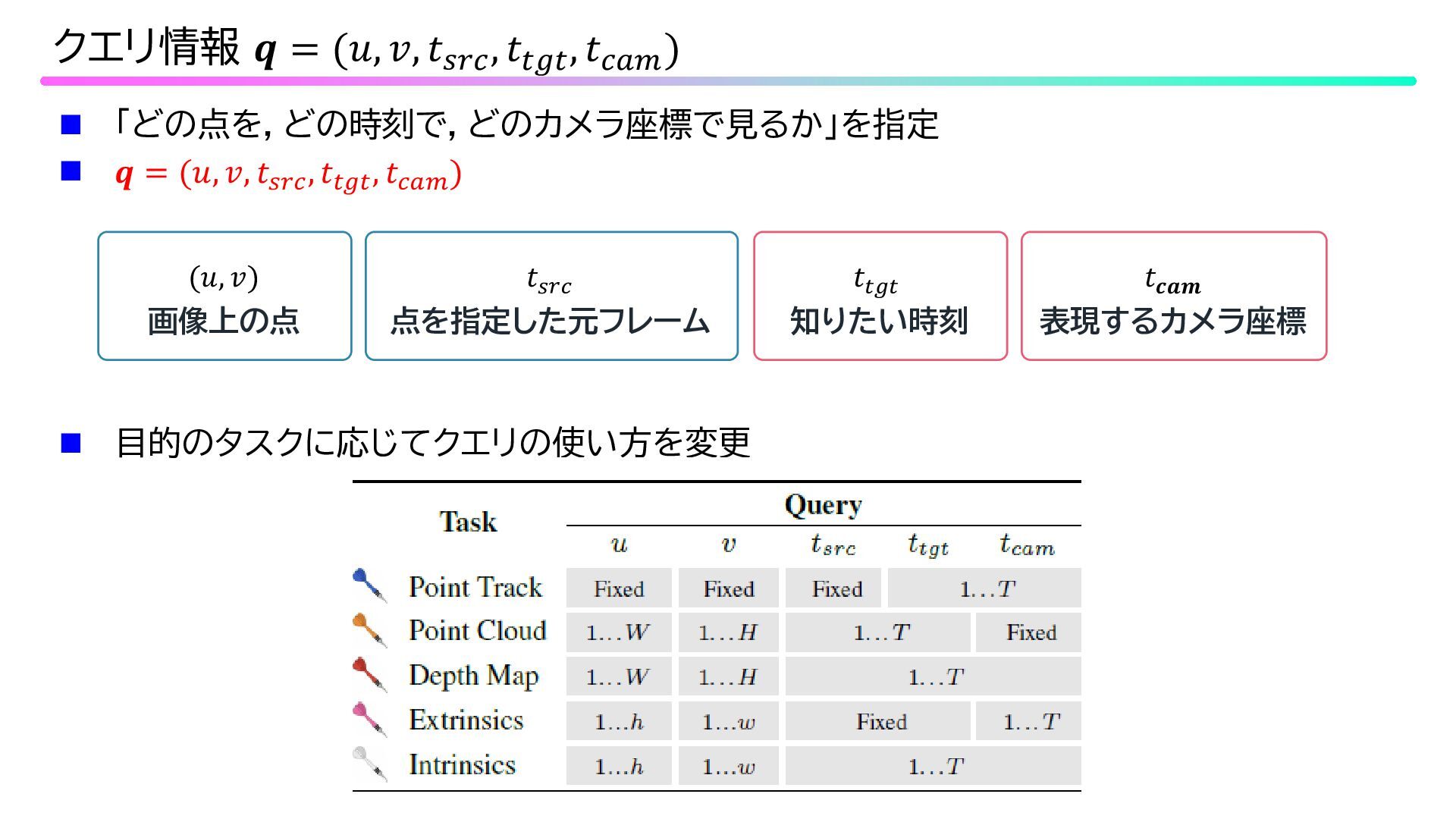
「どの点を,どの時刻で,どのカメラ座標で見るか」を指定 𝒒𝒒 = (𝑢𝑢, 𝑣𝑣, 𝑡𝑡𝑠𝑠𝑠𝑠𝑠𝑠 , 𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡
, 𝑡𝑡𝑐𝑐𝑐𝑐𝑐𝑐 ) クエリ情報 𝒒𝒒 = (𝑢𝑢, 𝑣𝑣, 𝑡𝑡𝑠𝑠𝑠𝑠𝑠𝑠 , 𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡 , 𝑡𝑡𝑐𝑐𝑐𝑐𝑐𝑐 ) (𝑢𝑢, 𝑣𝑣) 画像上の点 𝑡𝑡𝑠𝑠𝑠𝑠𝑠𝑠 点を指定した元フレーム 𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡 知りたい時刻 𝑡𝑡𝒄𝒄𝒄𝒄𝒄𝒄 表現するカメラ座標 目的のタスクに応じてクエリの使い方を変更
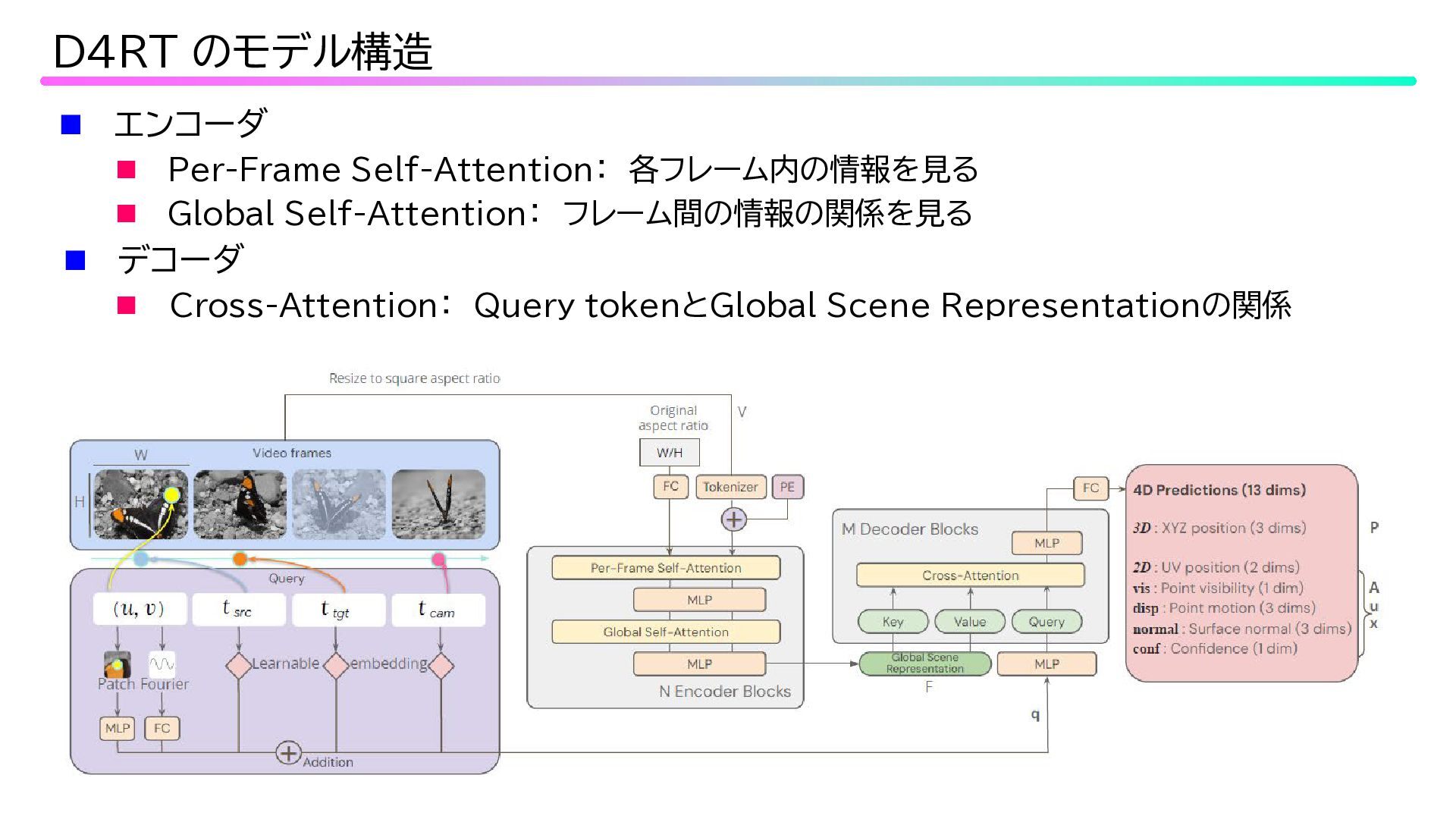
エンコーダ Per-Frame Self-Attention: 各フレーム内の情報を見る Global Self-Attention: フレーム間の情報の関係を見る
デコーダ Cross-Attention: Query tokenとGlobal Scene Representationの関係 D4RT のモデル構造
全ピクセルを追跡するための工夫 従来: 全ピクセルの全時刻を推定 O(T²HW) D4RT: 未調査ピクセルからだけ新しい追跡を開始
Occupancy Grid 動画中のどのピクセルが既に推定済みかを記録する表を利用 D4RT の工夫
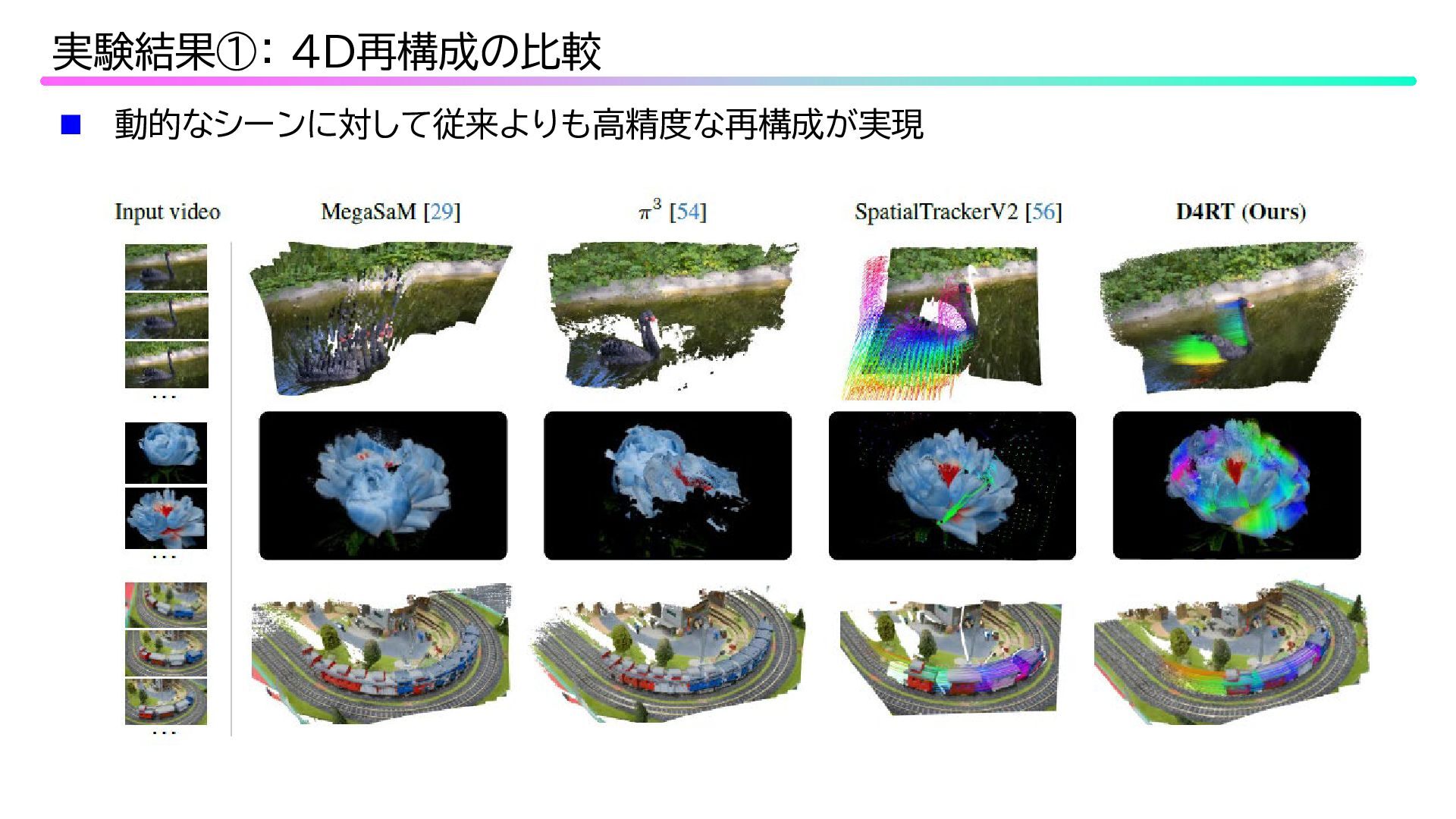
動的なシーンに対して従来よりも高精度な再構成が実現 実験結果①: 4D再構成の比較
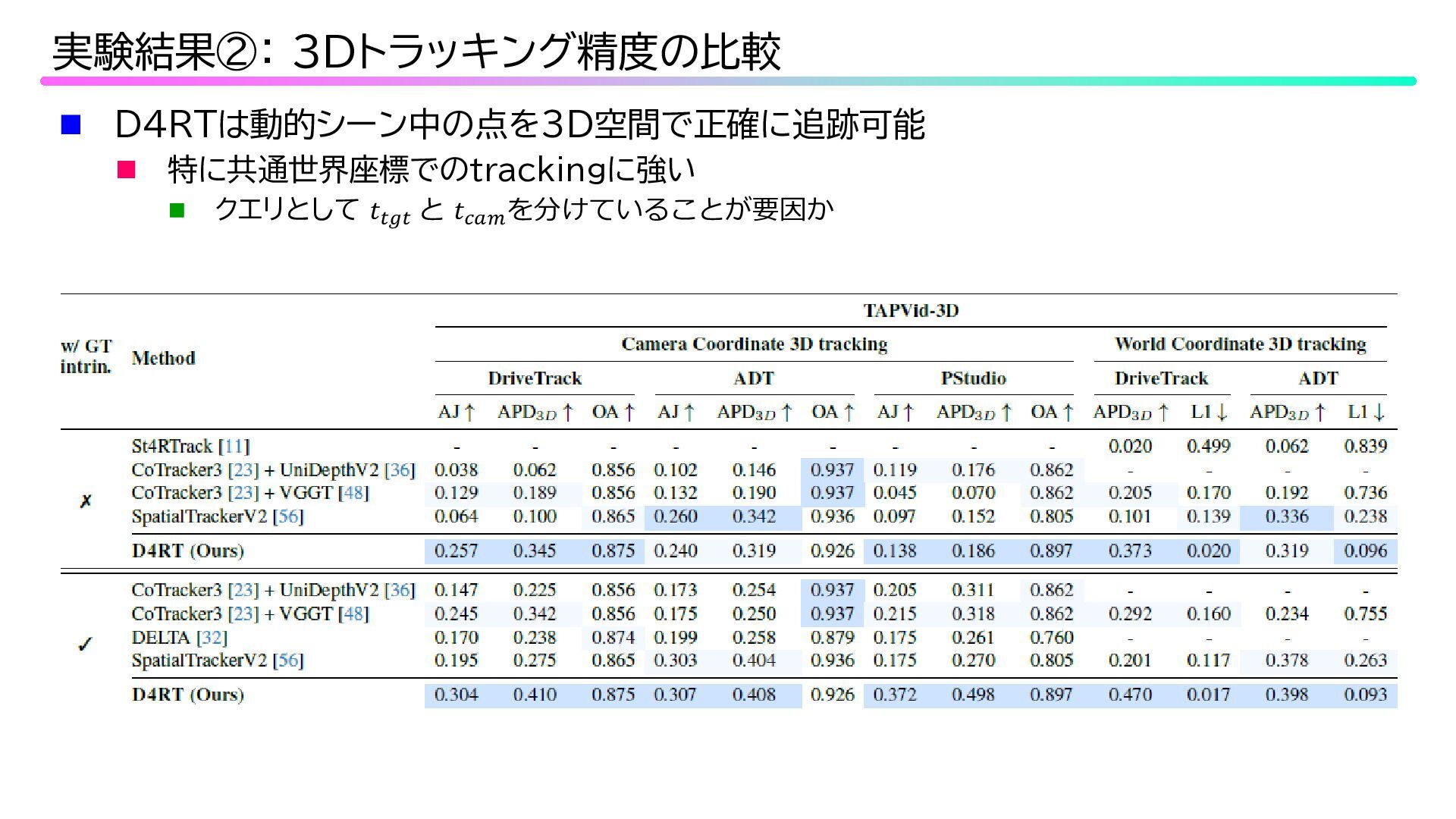
D4RTは動的シーン中の点を3D空間で正確に追跡可能 特に共通世界座標でのtrackingに強い クエリとして 𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡 と 𝑡𝑡𝑐𝑐𝑐𝑐𝑐𝑐 を分けていることが要因か
実験結果②: 3Dトラッキング精度の比較
クエリでは座標情報だけでなく局所的な見た目情報も利用 目的 点の局所的な見た目を与える 物体境界や細部の復元を改善 結果
Depth推定,Camera Pose推定の両方で性能向上 特に物体境界がシャープになる アブレーション実験: Local RGB patchの効果
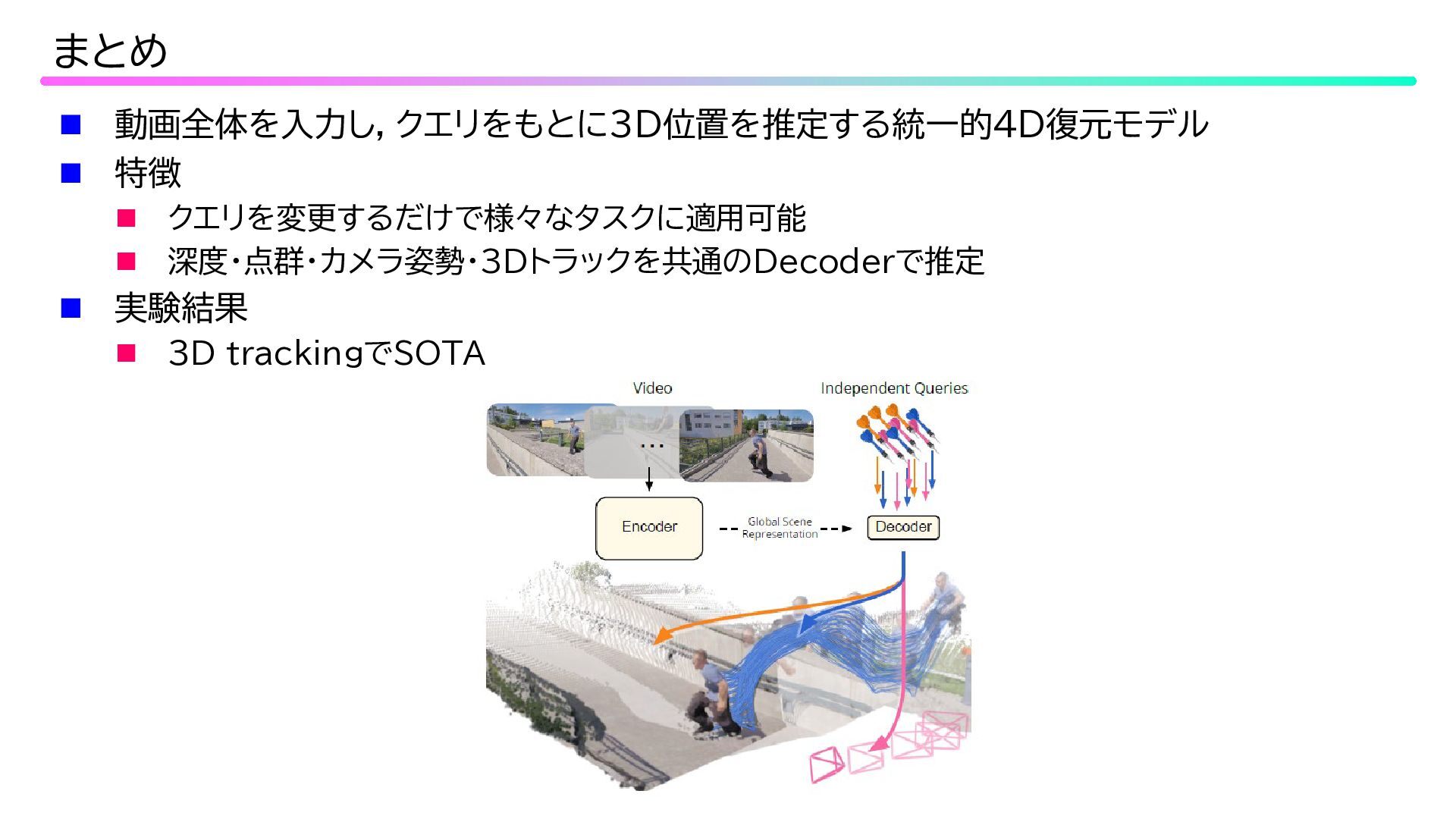
動画全体を入力し,クエリをもとに3D位置を推定する統一的4D復元モデル 特徴 クエリを変更するだけで様々なタスクに適用可能 深度・点群・カメラ姿勢・3Dトラックを共通のDecoderで推定 実験結果
3D trackingでSOTA まとめ
Thank you for your attention!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}