構築、運用化、保護、モニタリングを行う能力が必要です。 また、既存の機械学習モデルの活用、デプロイ、継続的なトレーニングができなければなりません。 https://cloud.google.com/certification/guides/data-engineer?hl=ja Google Cloud Professional Data Enginner の説明 “
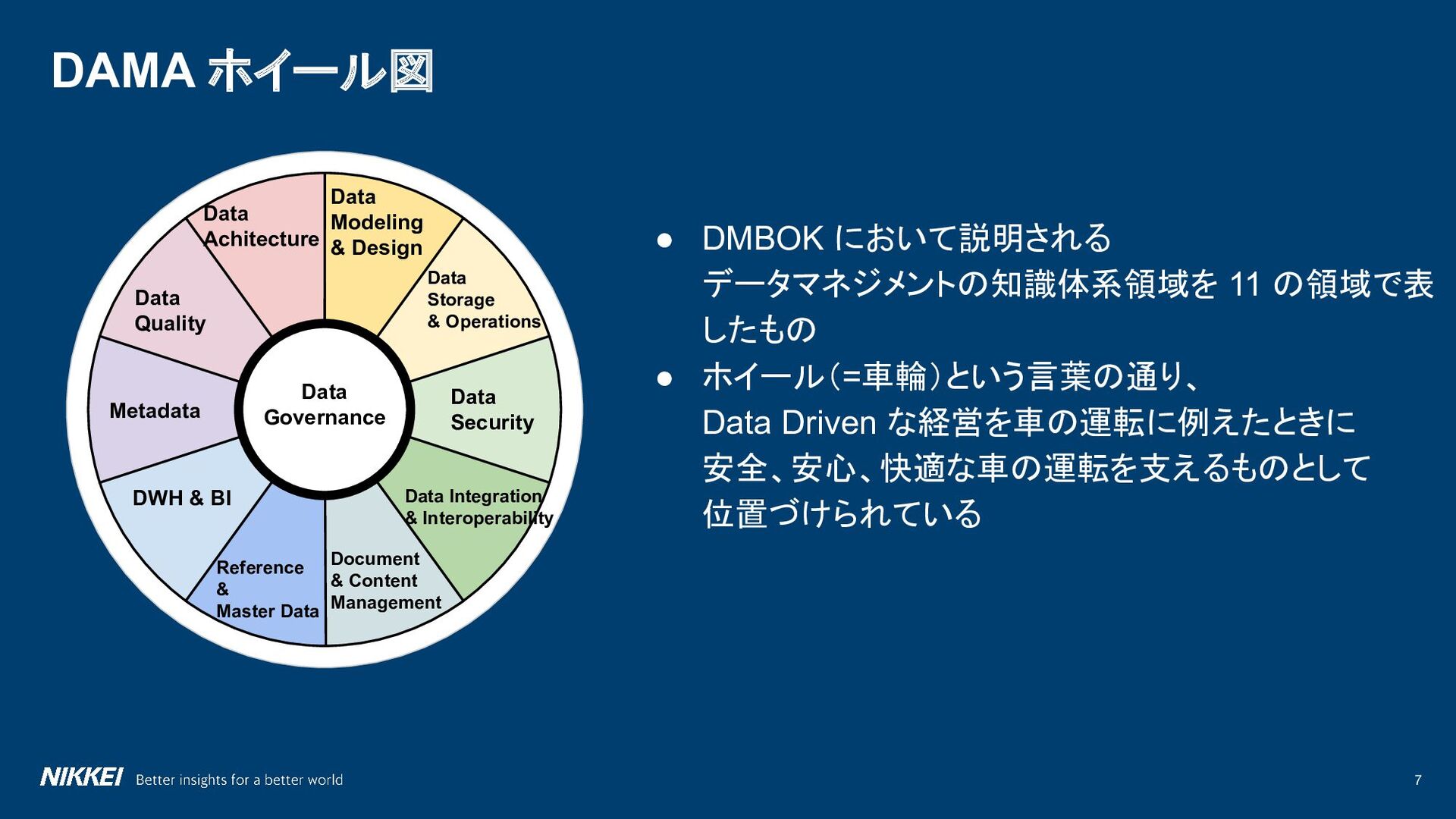
• ホイール(=車輪)という言葉の通り、 Data Driven な経営を車の運転に例えたときに 安全、安心、快適な車の運転を支えるものとして 位置づけられている Data Modeling & Design Data Storage & Operations Data Security Data Integration & Interoperability Document & Content Management Reference & Master Data DWH & BI Metadata Data Governance Data Quality Data Achitecture
Design Data Storage & Operations Data Security Data Integration & Interoperability Document & Content Management Reference & Master Data DWH & BI Metadata Data Governance Data Quality Data Achitecture セキュリティ データ処理システムの 設計、構築、運用 モニタリング コンプライアンス スケーラビリティ、 効率性、信頼性 柔軟性、ポータビリティ
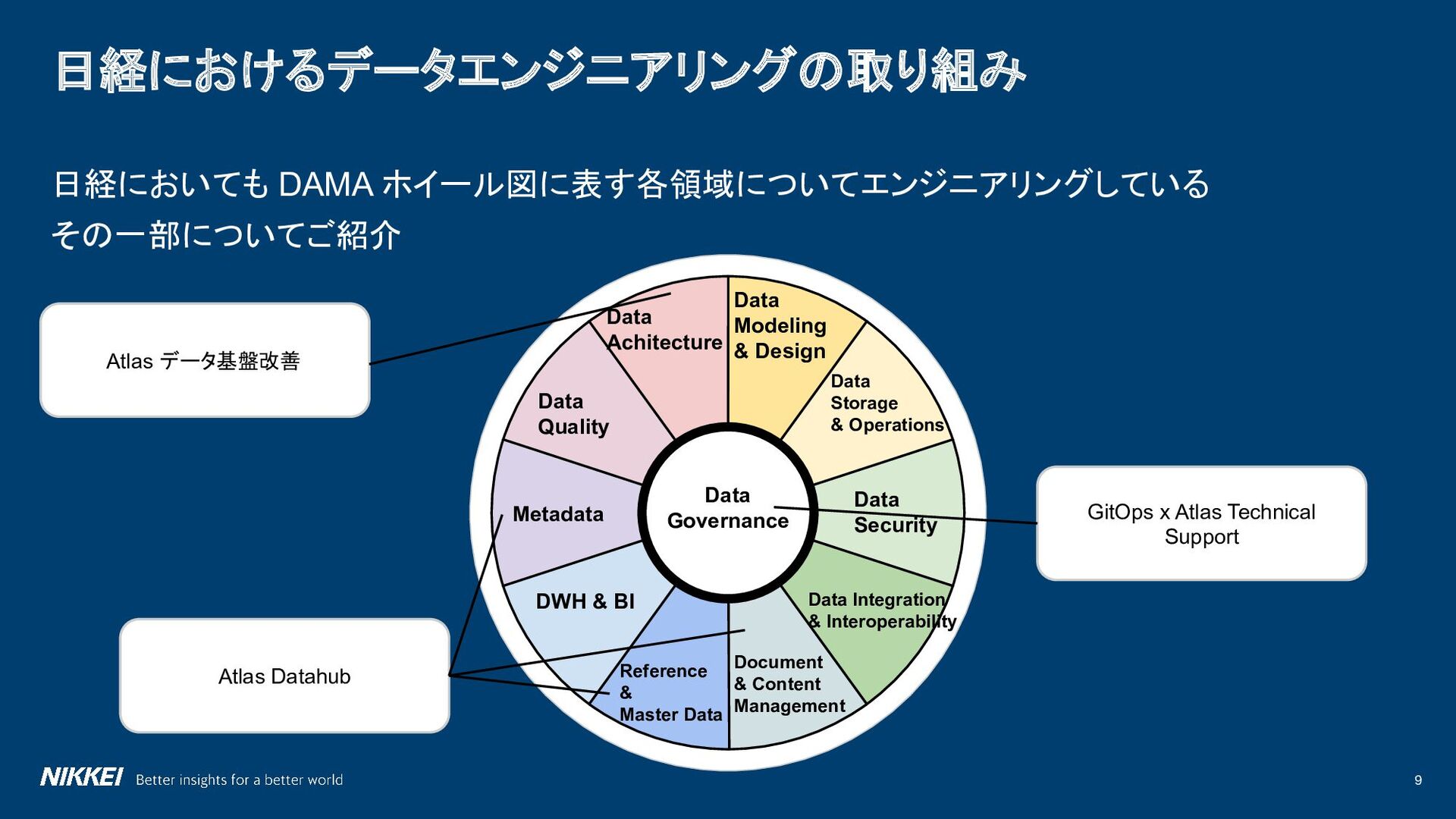
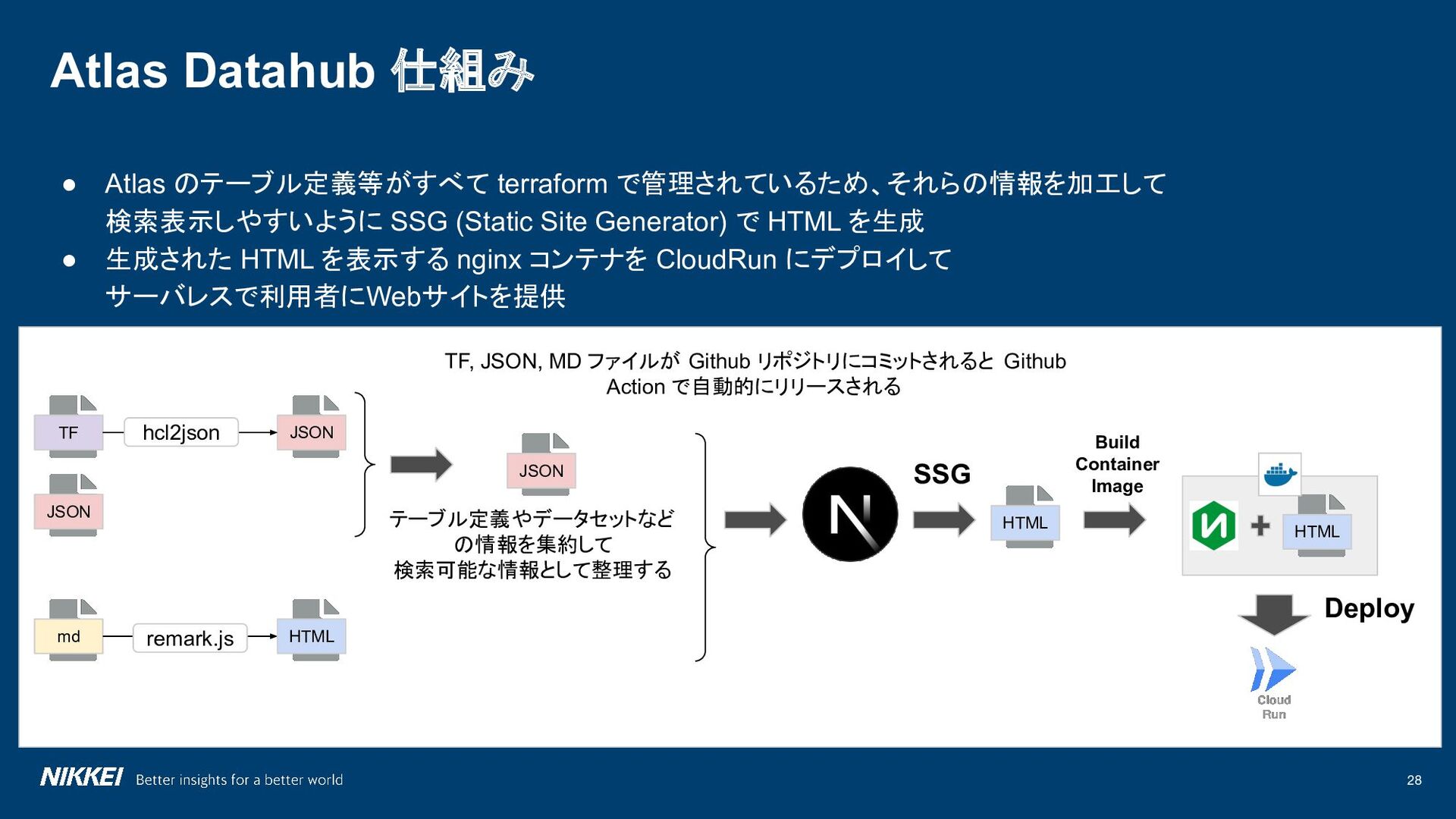
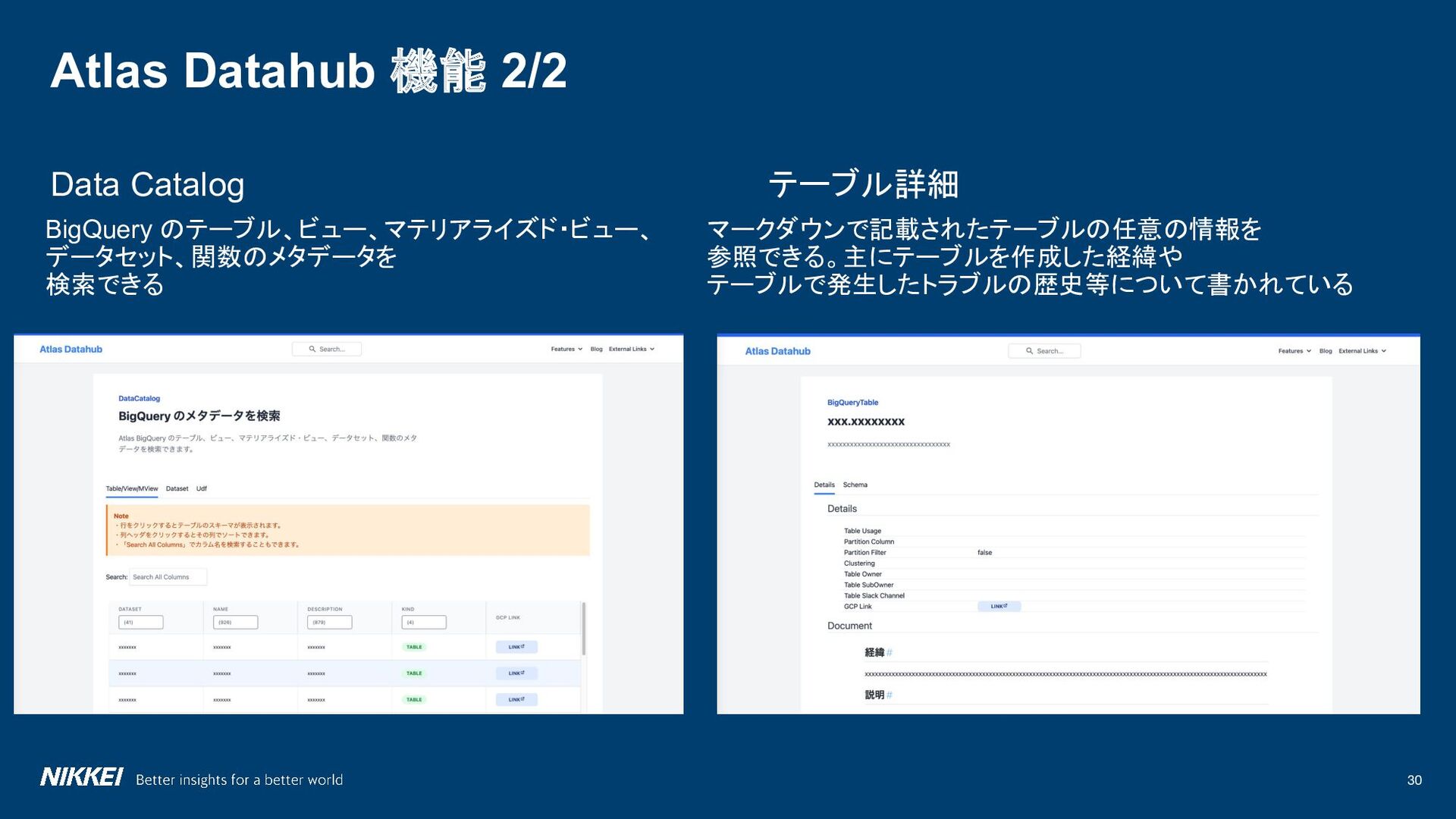
Data Storage & Operations Data Security Data Integration & Interoperability Document & Content Management Reference & Master Data DWH & BI Metadata Data Governance Data Quality Data Achitecture Atlas データ基盤改善 Atlas Datahub GitOps x Atlas Technical Support
& Operations Data Security Data Integration & Interoperability Document & Content Management Reference & Master Data DWH & BI Metadata Data Governance Data Quality Data Achitecture
Data Storage & Operations Data Security Data Integration & Interoperability Document & Content Management Reference & Master Data DWH & BI Metadata Data Governance Data Quality Data Achitecture
Operations Data Security Data Integration & Interoperability Document & Content Management Reference & Master Data DWH & BI Metadata Data Governance Data Quality Data Achitecture
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
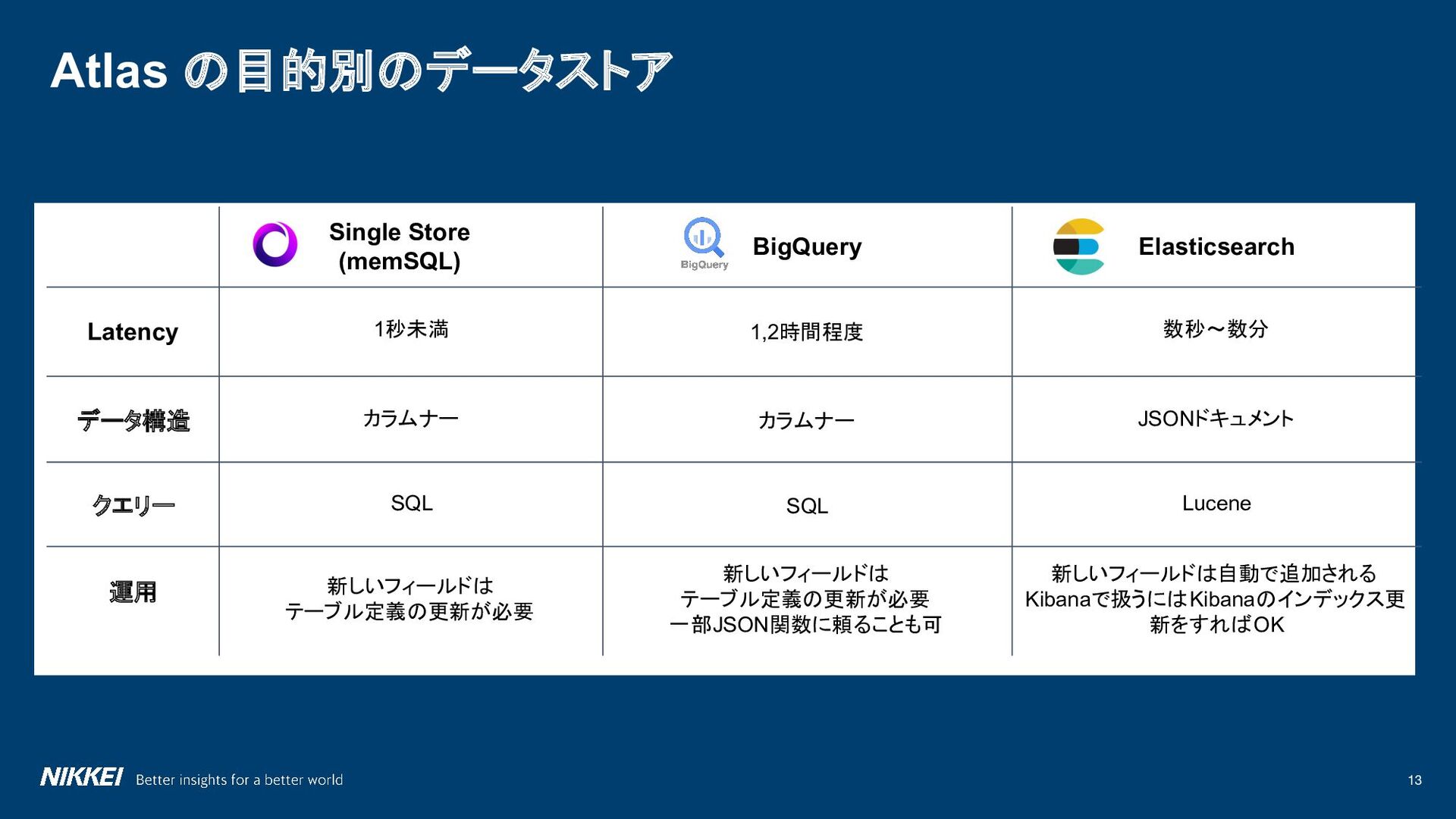{kind=link}
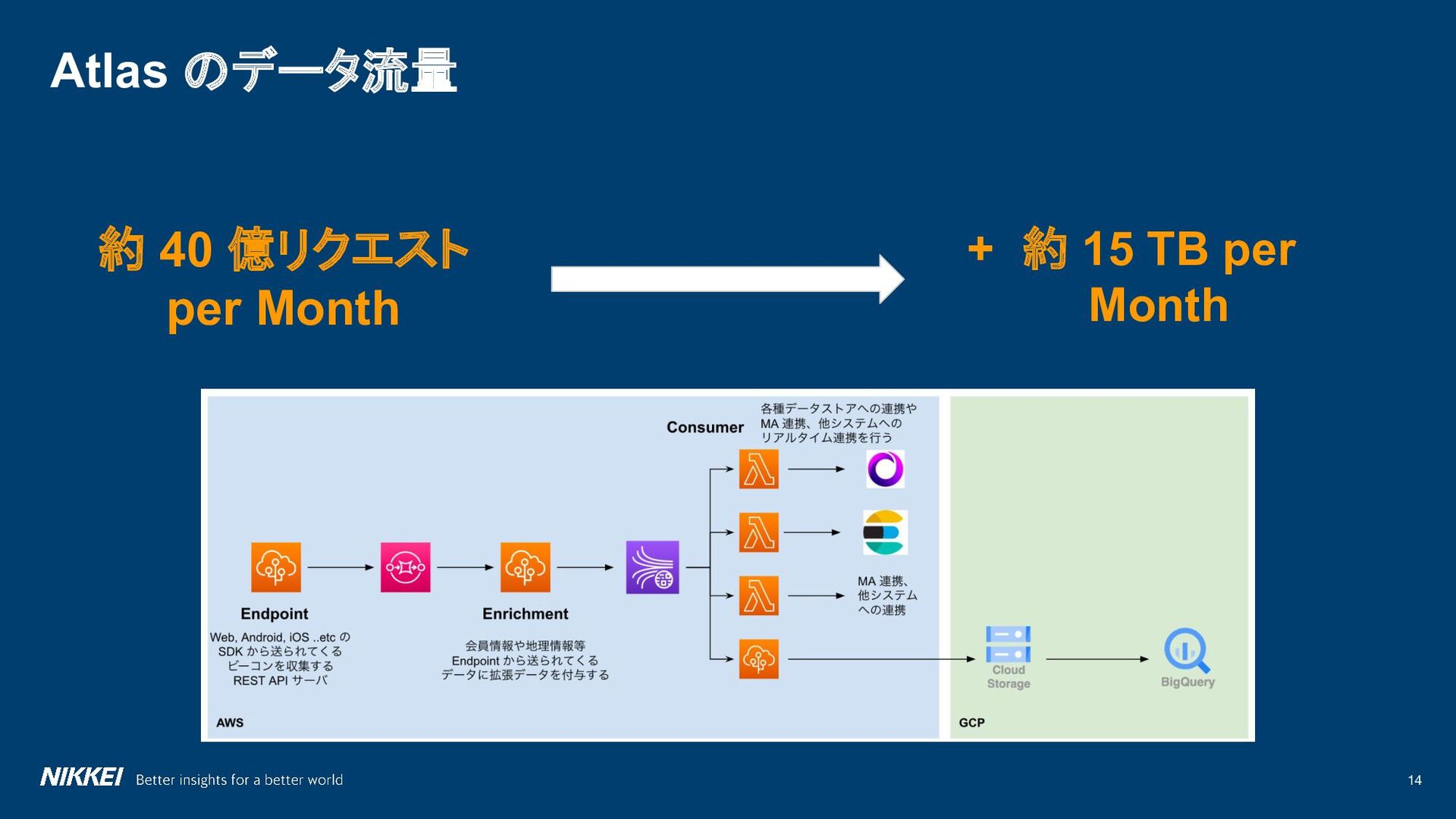{kind=link}
{kind=link}
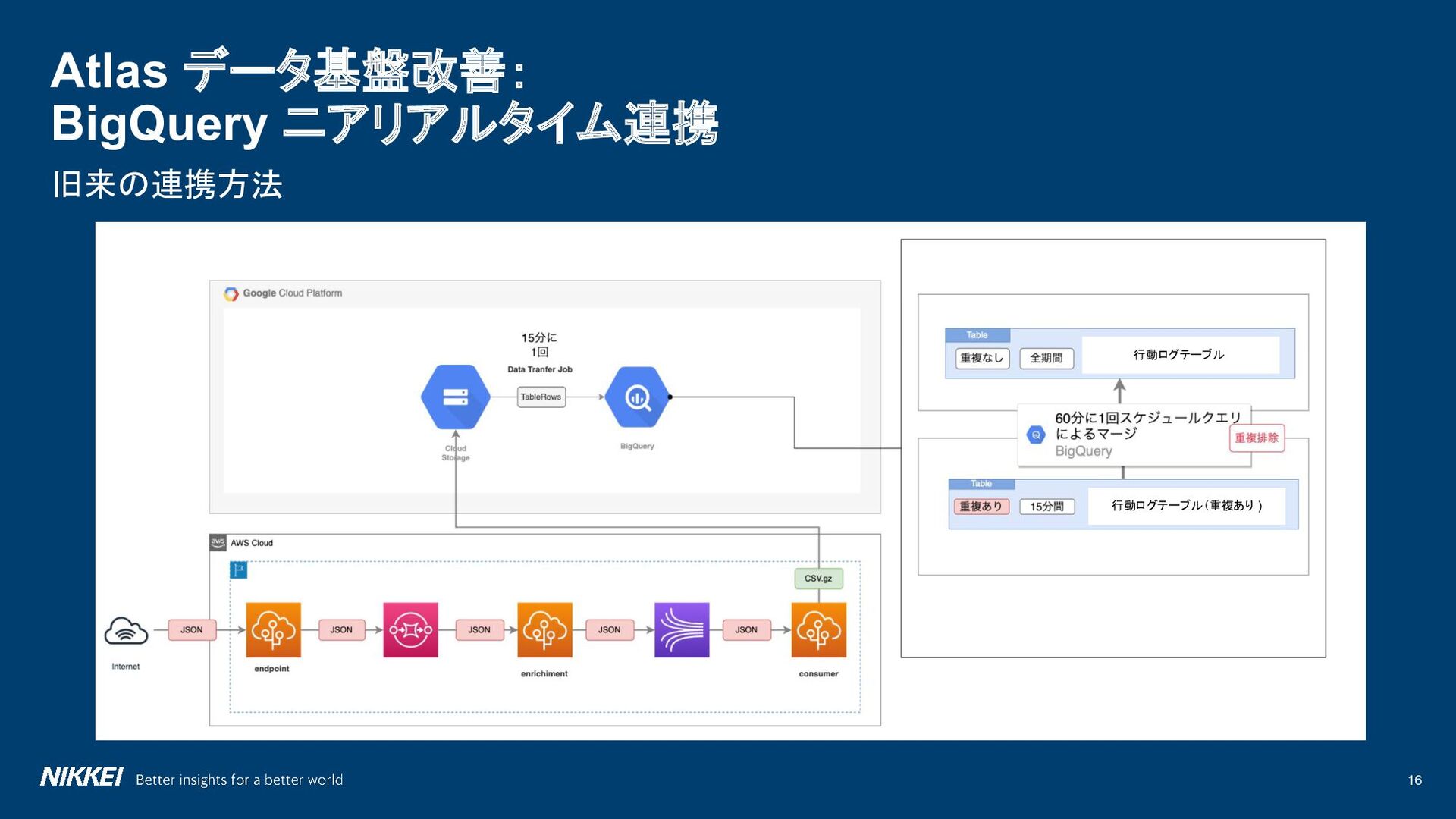{kind=link}
{kind=link}
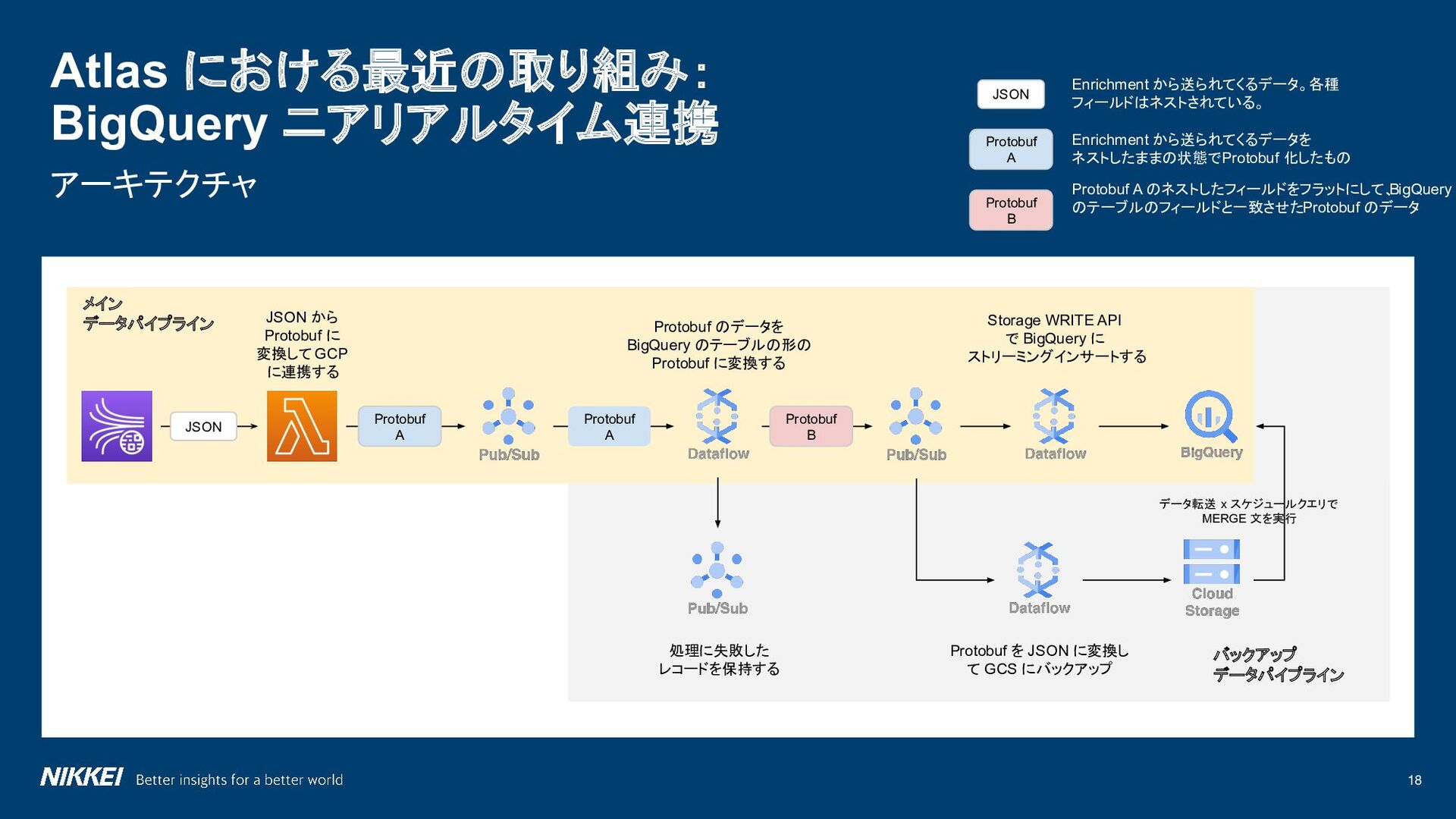{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}