is just at the beginning of the S-curve. The near-term and long-term opportunities are enormous.” Satya Nadella - Microsoft CEO “The generative AI market is poised to explode over the next 10 years, expanding at a CAGR of 42%.” Bloomberg Intelligence “We have reached the tipping point of a new computing era.” Jensen Huang “Generative AI could add $2.6 trillion to $4.4 trillion annually…” “AI inferencing hardware alone in the data center will be 2x that for AI training hardware by 2025.” McKinsey & Company “Artificial intelligence could unlock $6 trillion….” Morgan Stanley “Spending on GenAI solutions will reach $143B in 2027 with a 5-Year CAGR of 73.3%” IDC 5 LLM Demand: Proven & Growing
vs Inference Run Time Weeks or months Milliseconds or seconds Key Requirement Parallelism is enough for training Low latency inference is sequential Best Architecture Graphics Processor Groq LPU™ Accelerator Frequency Periodic Persistent Inference is Not Training What got us here, won’t move us forward.
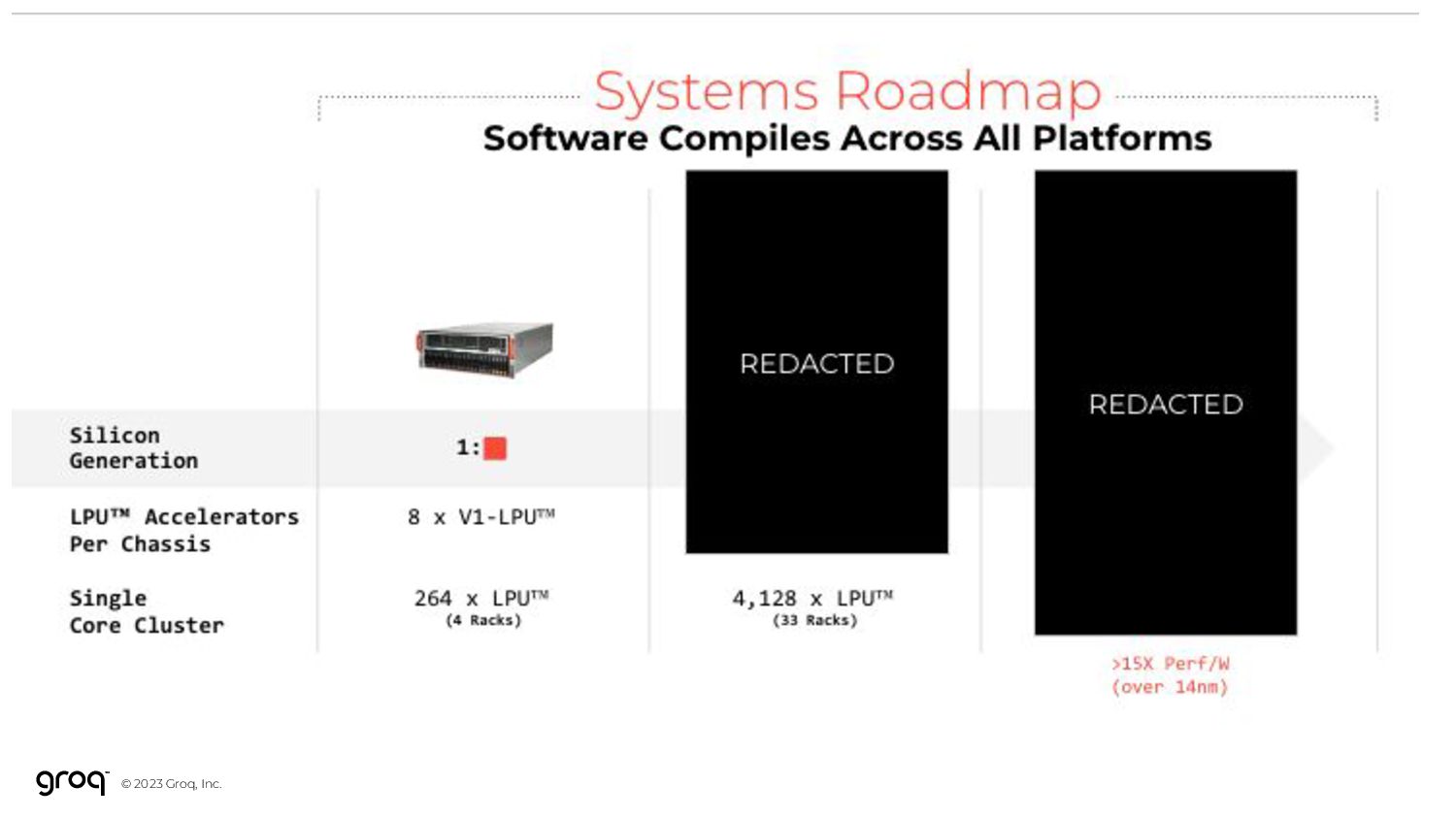
From its start, Groq understood that the most valuable AI/ML problems would require multi-rack scale Groq LPU™ Inference Engine: Scale by Design …but in volume it’s quicker and cheaper to use an assembly line You can build a car in one location… …but at scale it’s quicker and cheaper to use an LPU Inference Engine You can compute an inference with a GPU that has a lot of external memory…
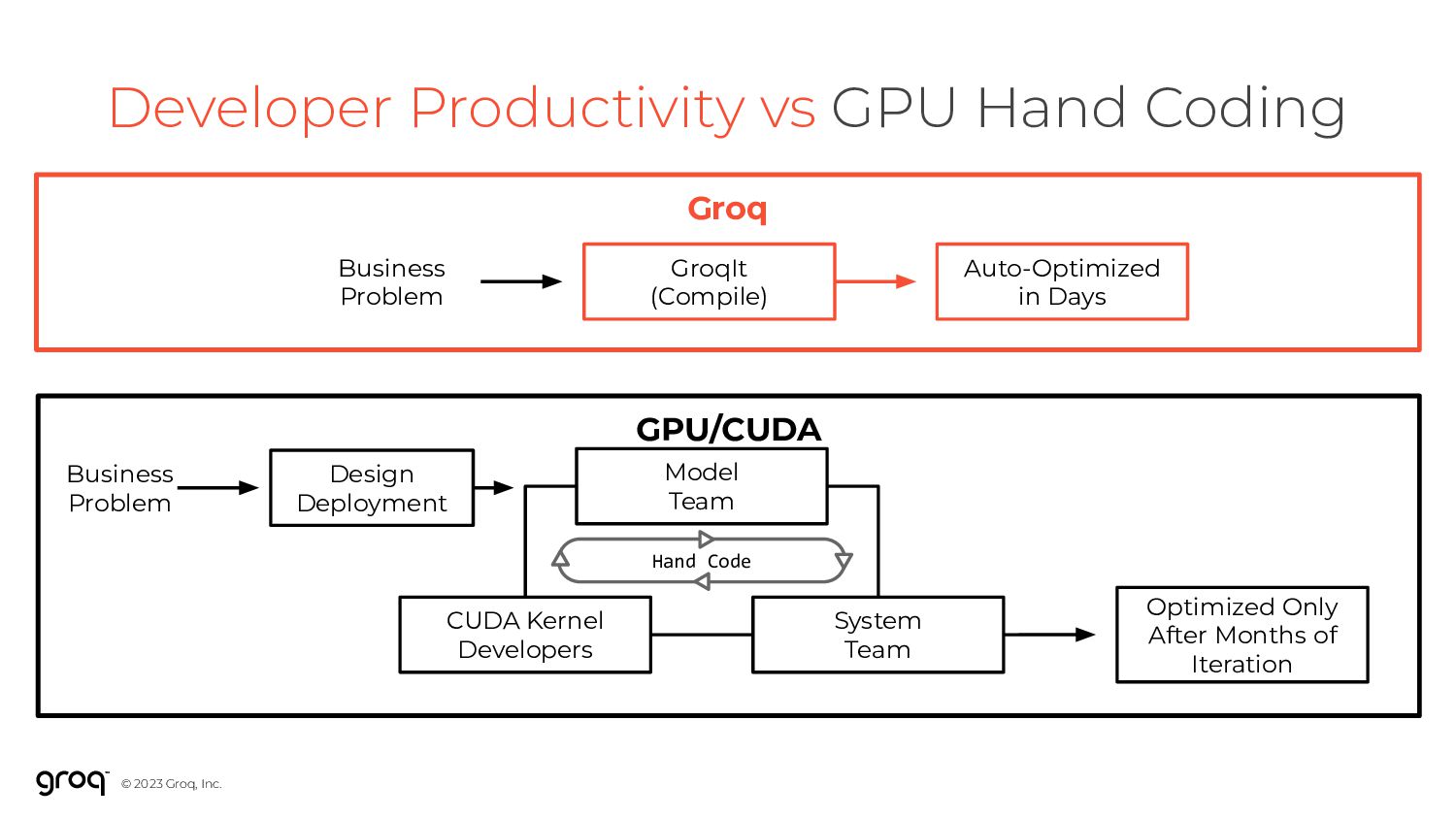
12 12 Developer Productivity vs GPU Hand Coding Auto-Optimized in Days GroqIt (Compile) Business Problem Model Team Optimized Only After Months of Iteration System Team CUDA Kernel Developers Design Deployment Business Problem Hand Code
Teams Thrive With Great Tools Groq Compiles Fast From Download to Running Llama 65B 5 days Llama 7B 5 days Llama 13B 4 days Llama-2 70B 5 days Code Llama 34B 4 days and many more ↦ 13 https://thenewstack.io/add-it-up-how-long-does-a-machine-learning-deployment-take/ https://www.scribd.com/document/616304173/Algorithmia-2020-State-of-Enterprise-ML
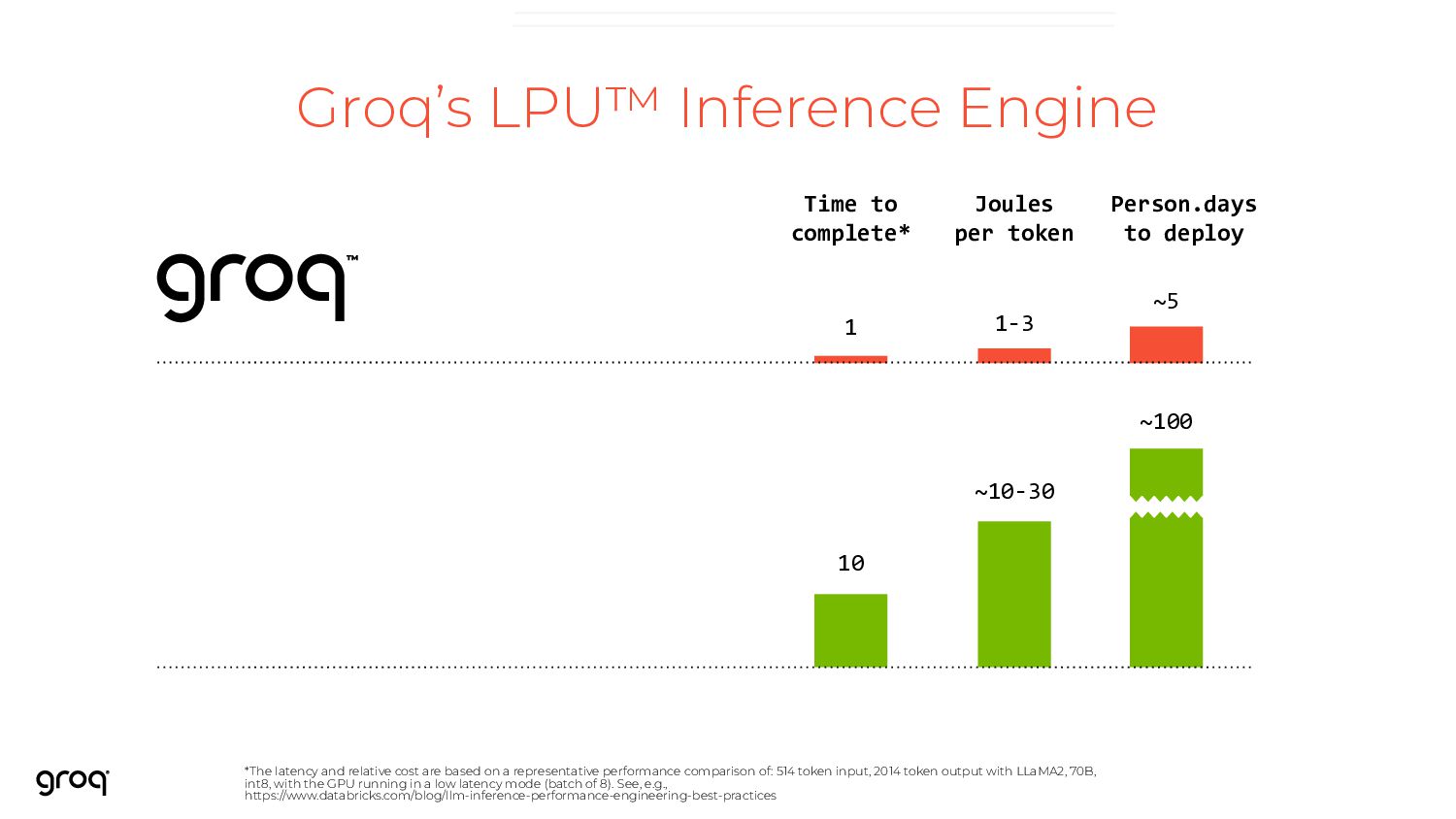
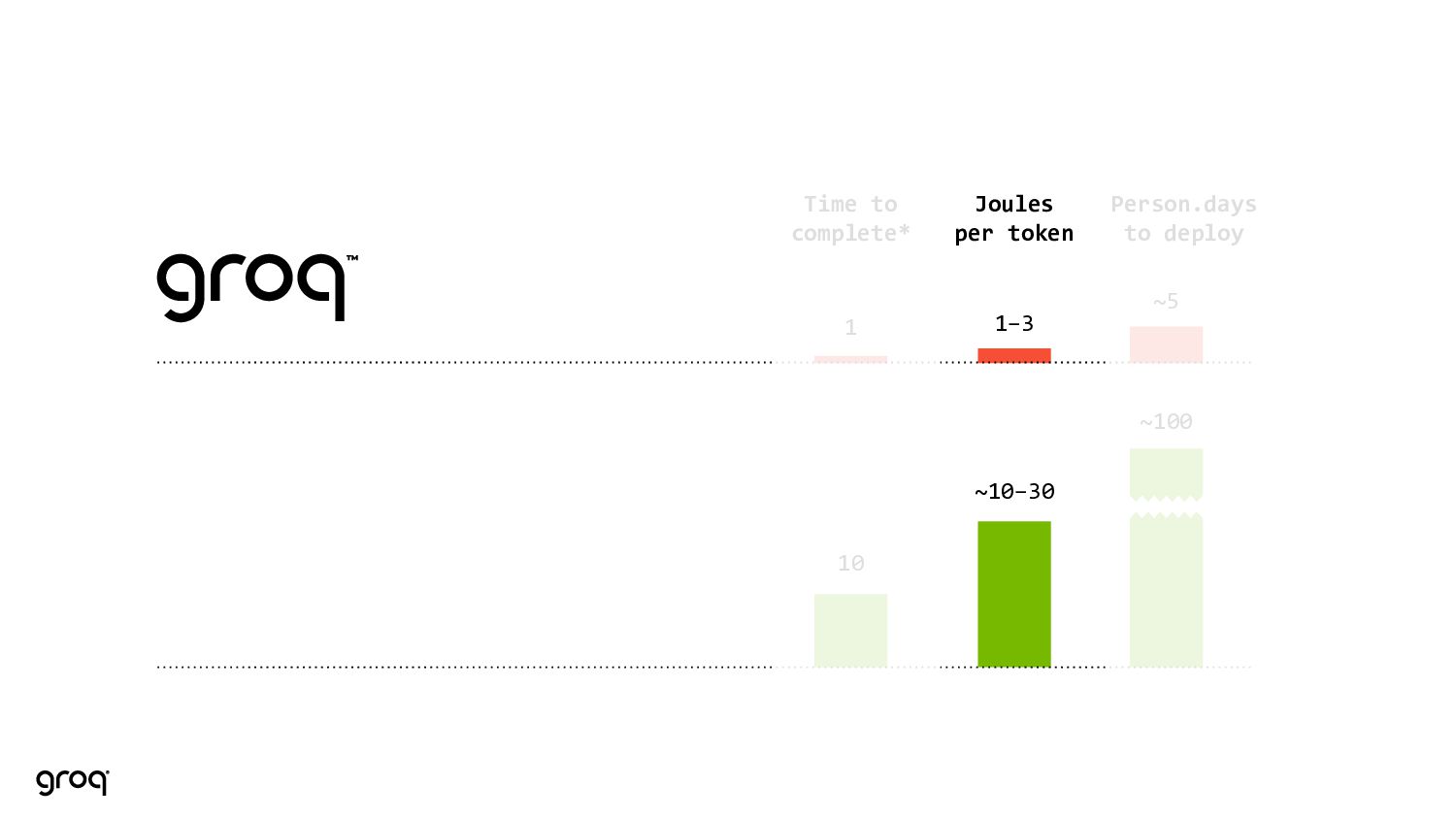
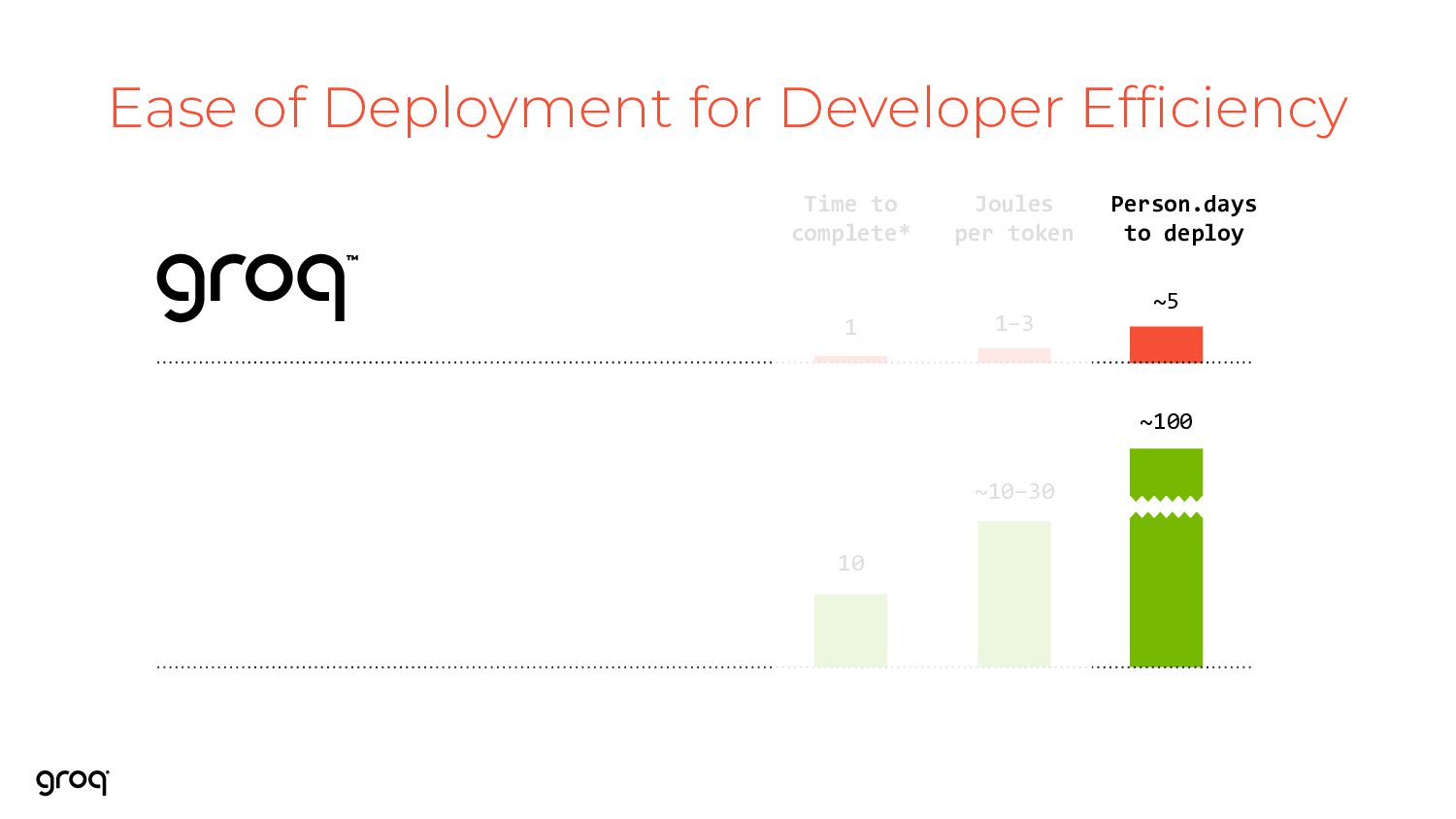
are based on a representative performance comparison of: 514 token input, 2014 token output with LLaMA2, 70B, int8, with the GPU running in a low latency mode (batch of 8). See, e.g., https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices Groq’s LPU™ Inference Engine ~100 Person.days to deploy ~10-30 Joules per token 10 Time to complete* 1-3 1 ~5
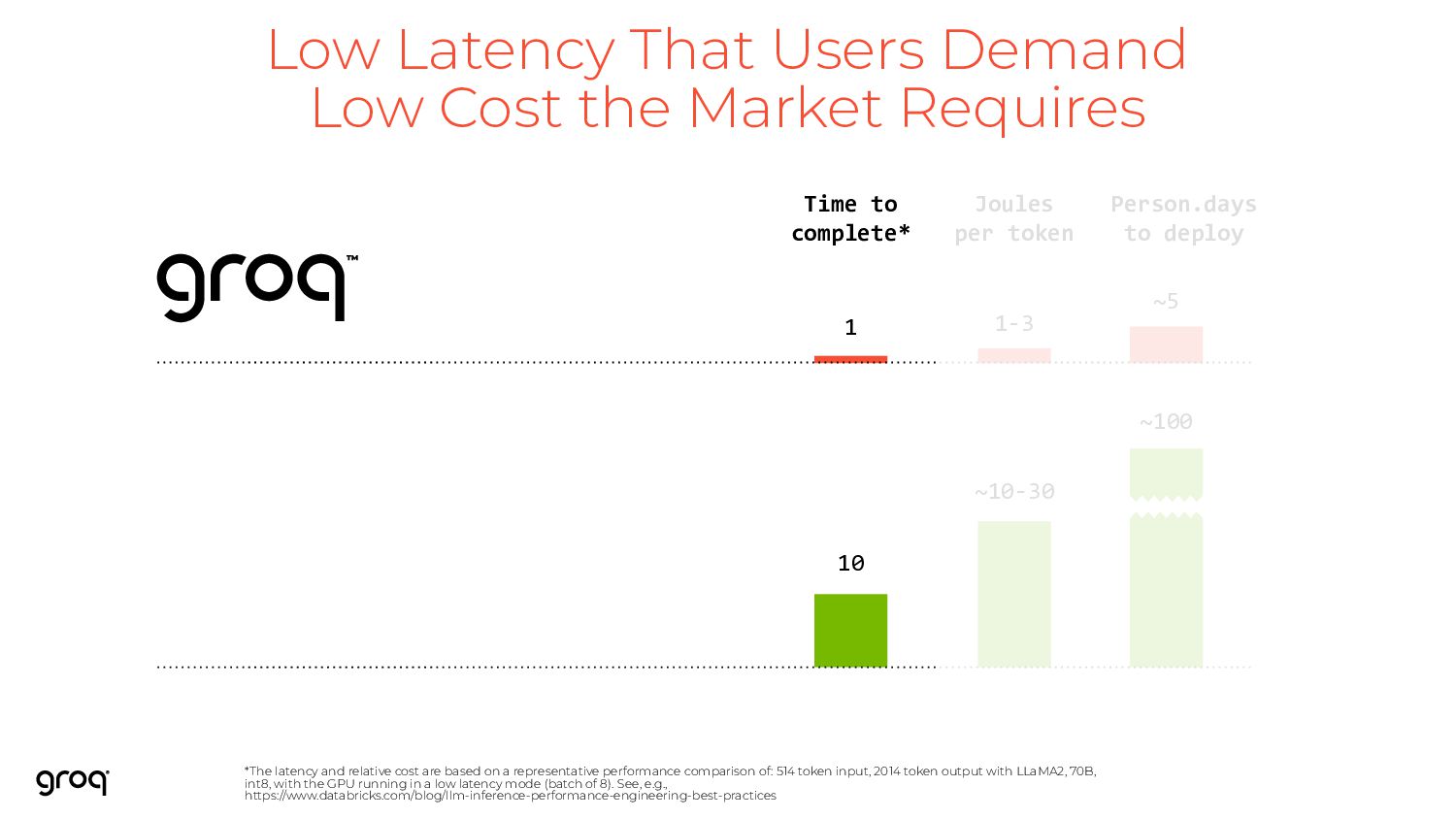
are based on a representative performance comparison of: 514 token input, 2014 token output with LLaMA2, 70B, int8, with the GPU running in a low latency mode (batch of 8). See, e.g., https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices ~100 Person.days to deploy ~10-30 Joules per token 10 Time to complete* 1-3 1 ~5 Low Latency That Users Demand Low Cost the Market Requires
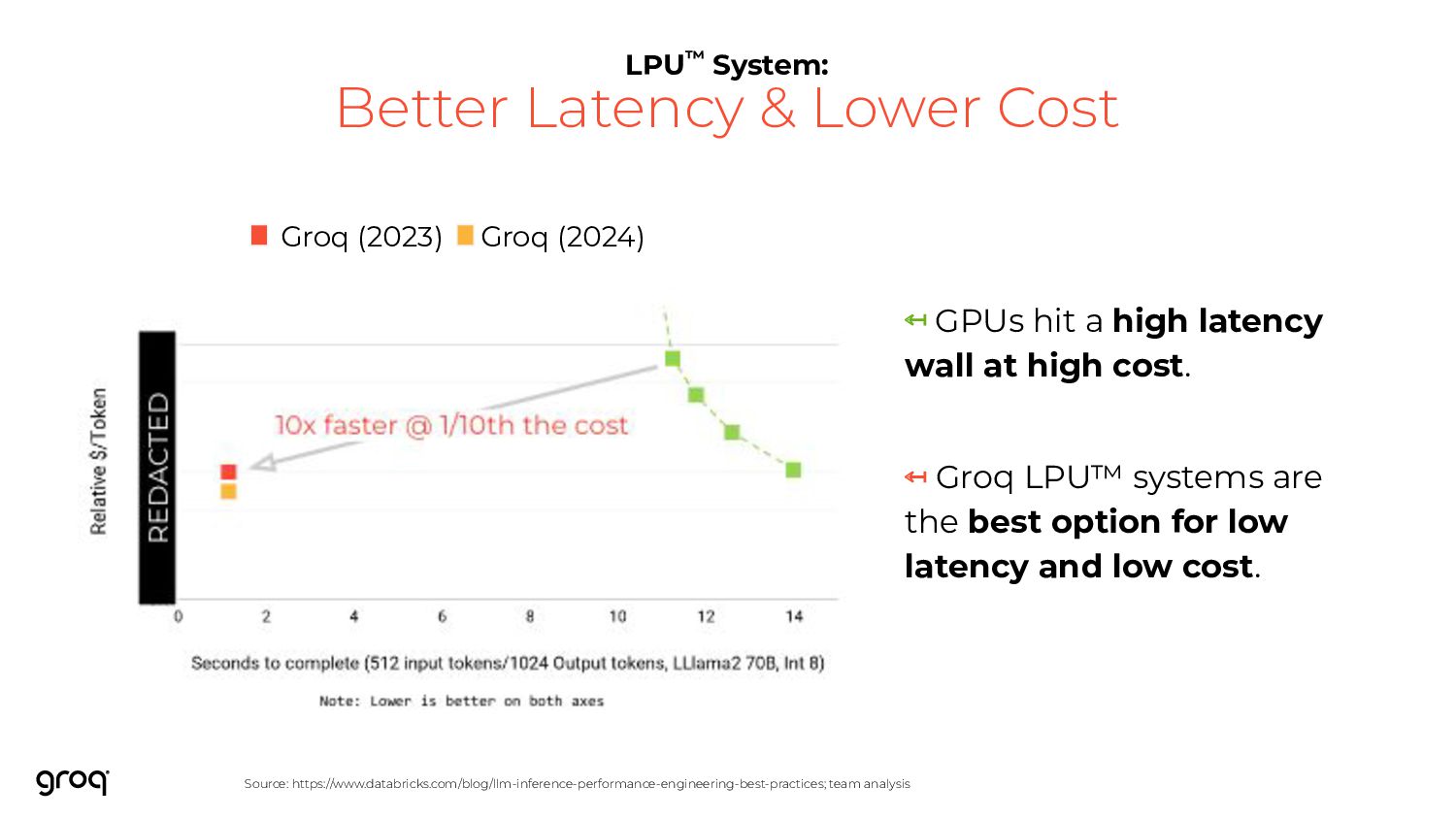
↤ GPUs hit a high latency wall at high cost. ↤ Groq LPU™ systems are the best option for low latency and low cost. LPU™ System: Better Latency & Lower Cost Groq (2023) Groq (2024)
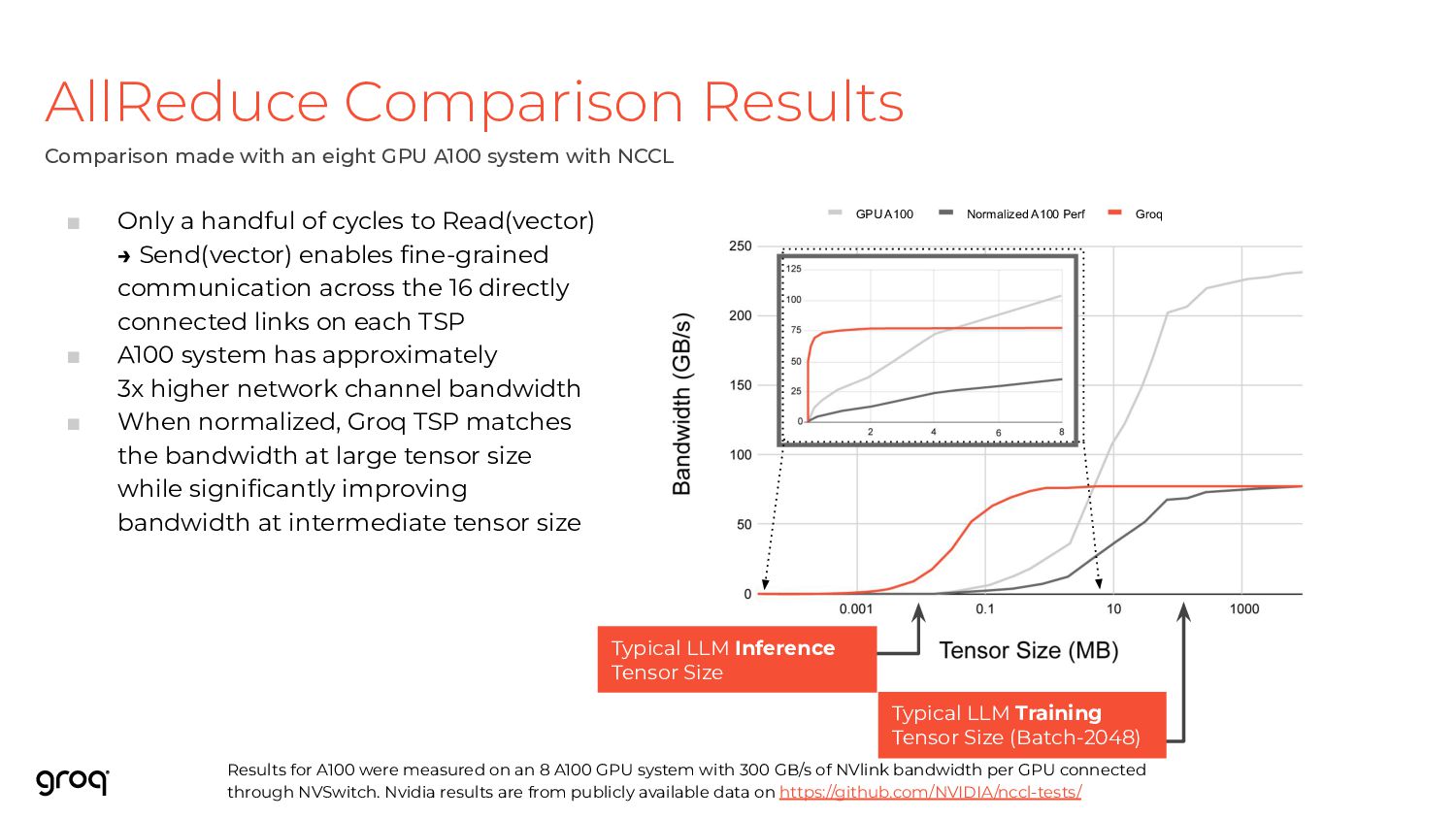
a handful of cycles to Read(vector) → Send(vector) enables fine-grained communication across the 16 directly connected links on each TSP ▪ A100 system has approximately 3x higher network channel bandwidth ▪ When normalized, Groq TSP matches the bandwidth at large tensor size while significantly improving bandwidth at intermediate tensor size Results for A100 were measured on an 8 A100 GPU system with 300 GB/s of NVlink bandwidth per GPU connected through NVSwitch. Nvidia results are from publicly available data on https://github.com/NVIDIA/nccl-tests/ Comparison made with an eight GPU A100 system with NCCL Typical LLM Inference Tensor Size Typical LLM Training Tensor Size (Batch-2048) GPU A100 Normalized A100 Perf Groq
Proposition: The Groq LPU™ Inference Engine has demonstrated that it’s better, faster, and more affordable than the GPU for generative AI language inference.
People & Talent Previously Intel 37 Michelle Donnelly Chief Revenue Officer Previously Salesforce Mark Heaps Brand & Creative Previously Apple | Google | Duarte Adam Tachner Corp Dev & CLO Previously Google | InvenSense | Qualcomm Jim Miller Engineering Previously Amazon | Qualcomm | Intel CLICK NAMES TO VIEW LINKEDIN PROFILES Estelle Hong Operations Previously Intel | US Army Leadership team prepared to navigate and maximize return on this incredible opportunity Jonathan Ross CEO, Founder Previously Google John Barrus Product Previously Google | Amazon 37 Knowledge & Experience
Black President, Groq Public Sector Previously Google | VMWare Leadership team prepared to navigate and maximize return on this incredible opportunity Andy Cunningham CMO (Advisory) Previously Apple | Regis McKenna Oskar Mencer CEO, Maxeler Previously Bell Labs | Stanford Dinesh Maheshwari Chief Technology Advisor Previously Silicon Catalyst | Cypress Igor Arsovski Head of Silicon Previously Google | Marvell | IBM Andrew Ling Compiler Lead Previously Intel Yaniv Shemesh Cloud and Systems Lead Previously Meta | F5 38 Value-Add Advisors & Outstanding Technical + Subsidiary Leads
Board of Directors Jay Zaveri Social Capital Founder of Dropbox-acquired CloudOn Jonathan Ross CEO & Founder Inventor of the Google TPU Andy Rappaport Independent Well-known technology strategist and investor Youngme Moon Independent Harvard Business School Ford Tamer Independent Sold Inphi to Marvell for $10B, current Marvell Board member
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
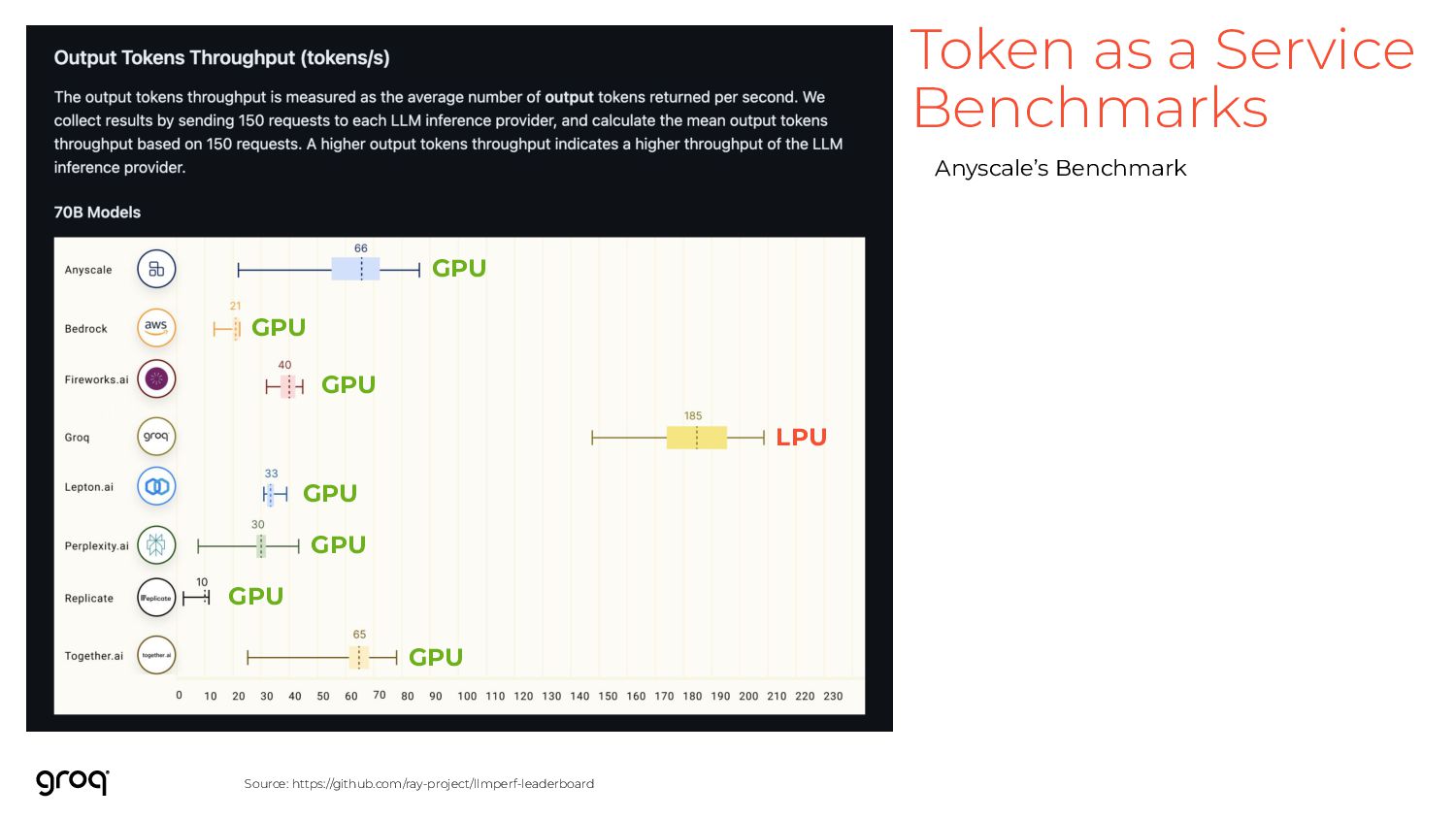{kind=link}
{kind=link}
{kind=link}
{kind=link}
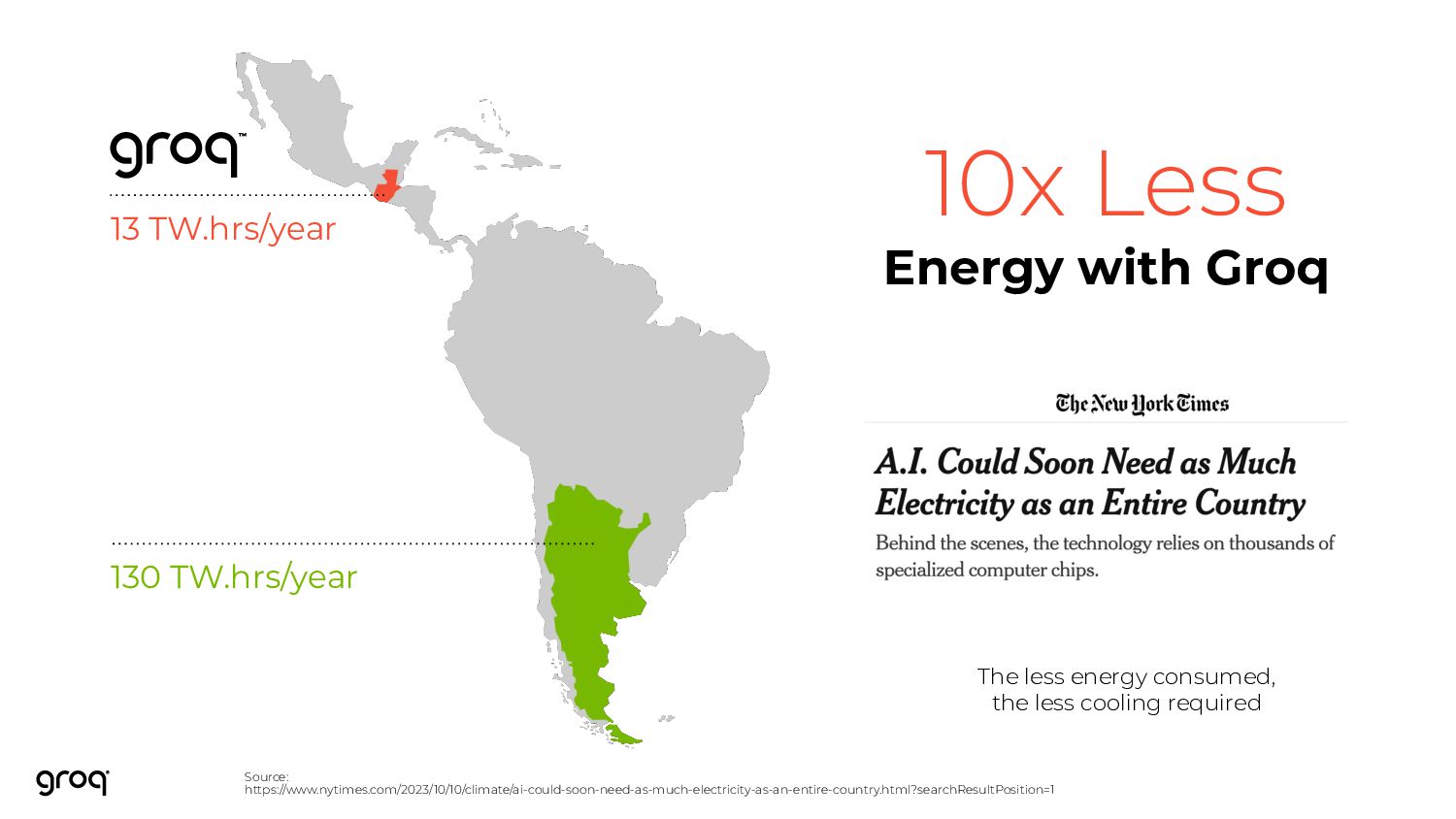{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}