by: Liang Gong Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 1 Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller
Neural Networks • What is Q-learning? • Q-Learning (a simple example) • Q-Learning on Atari Games • Why use it with Neural Networks? Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 2
Neural Networks • What is Q-learning? • Q-Learning (a simple example) • Q-Learning on Atari Games • Why use it with Neural Networks? Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 3
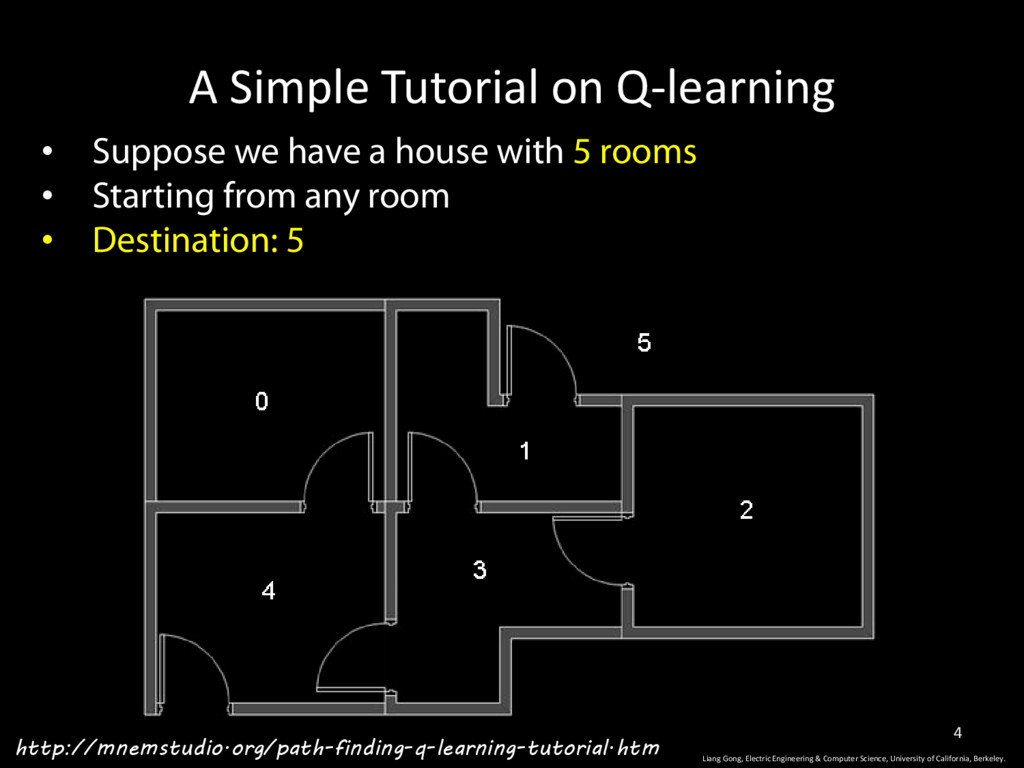
house with 5 rooms • Starting from any room • Destination: 5 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 4 http://mnemstudio.org/path-finding-q-learning-tutorial.htm
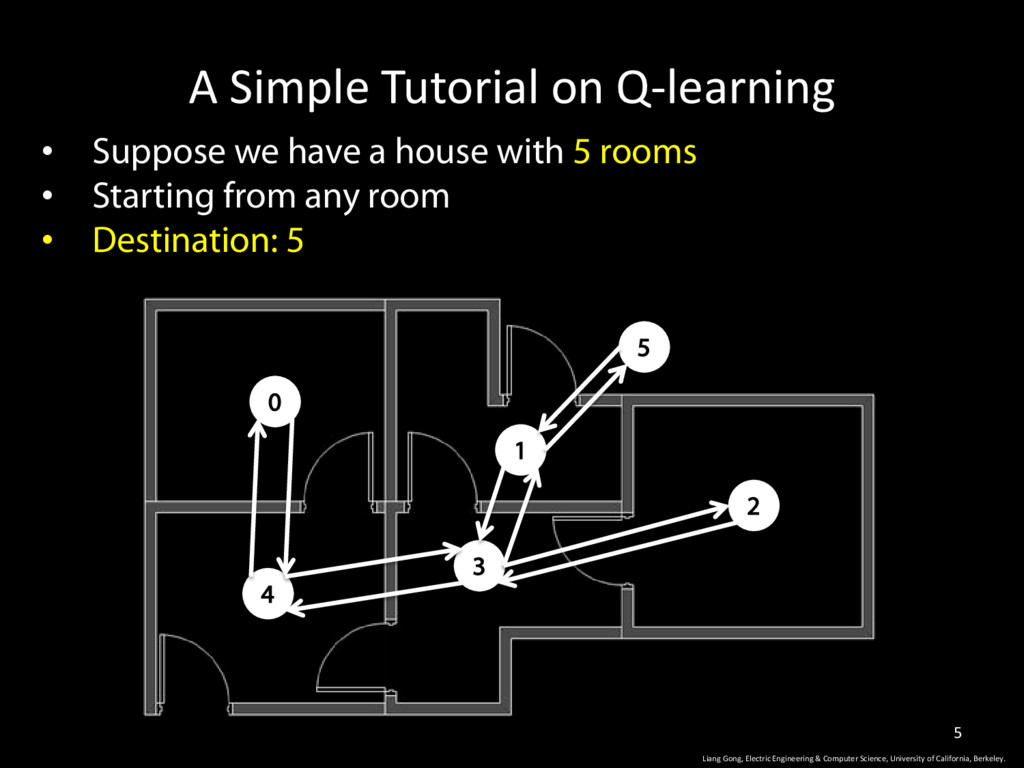
house with 5 rooms • Starting from any room • Destination: 5 0 1 2 3 4 5 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 5
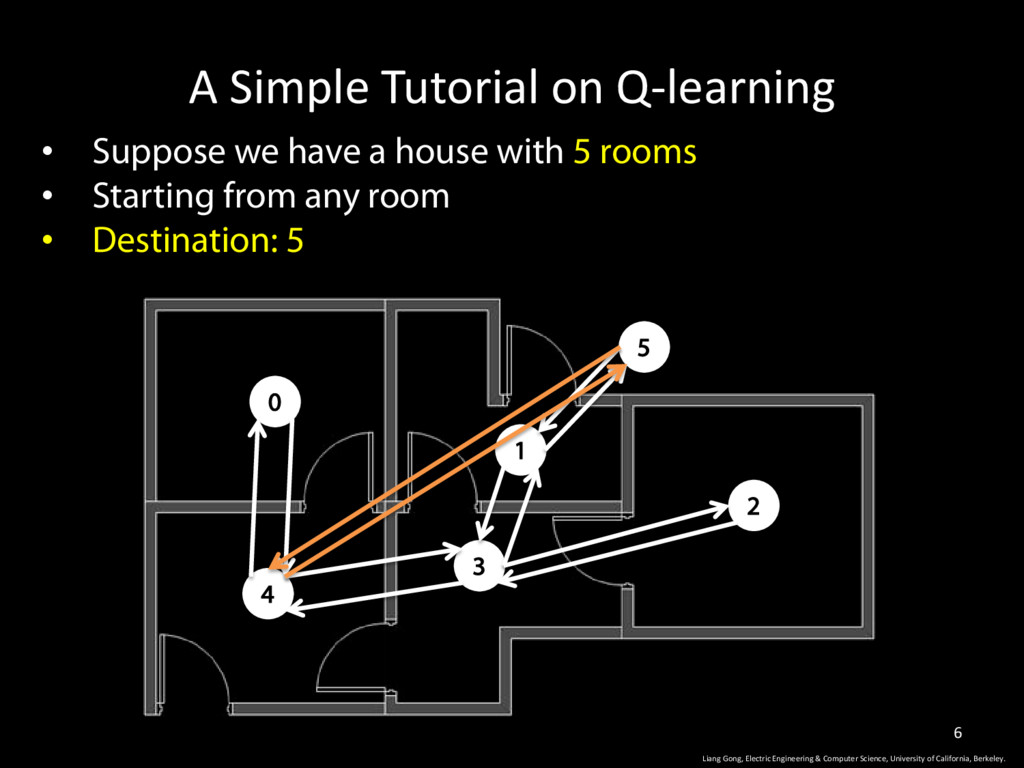
house with 5 rooms • Starting from any room • Destination: 5 0 1 2 3 4 5 Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 6
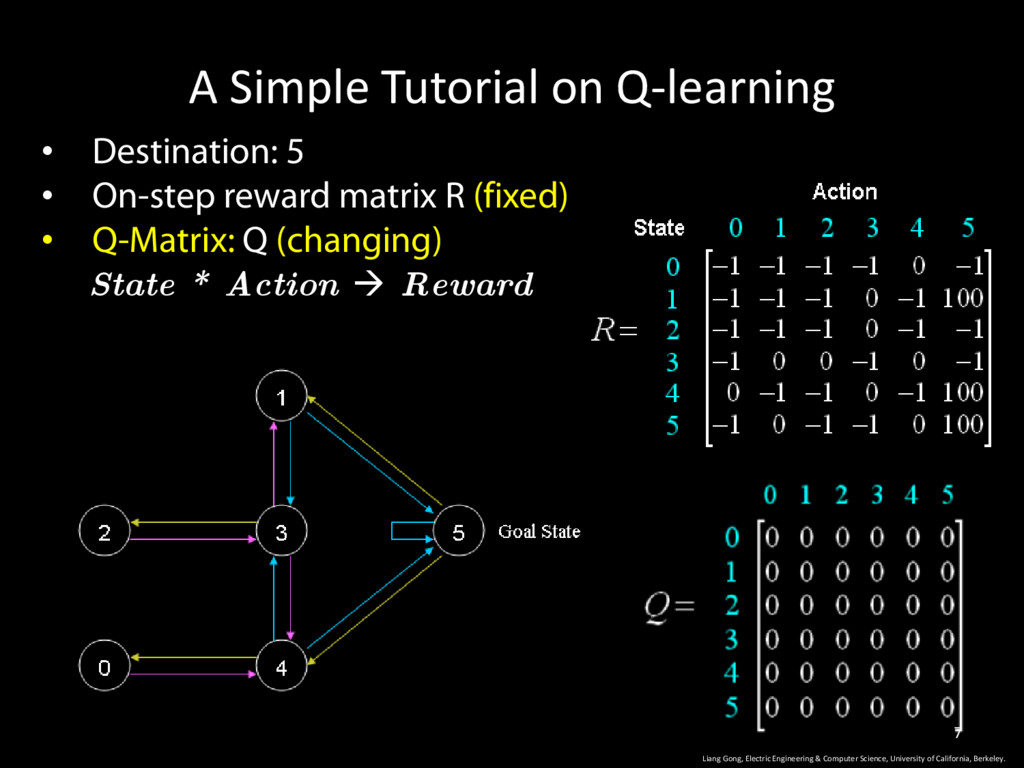
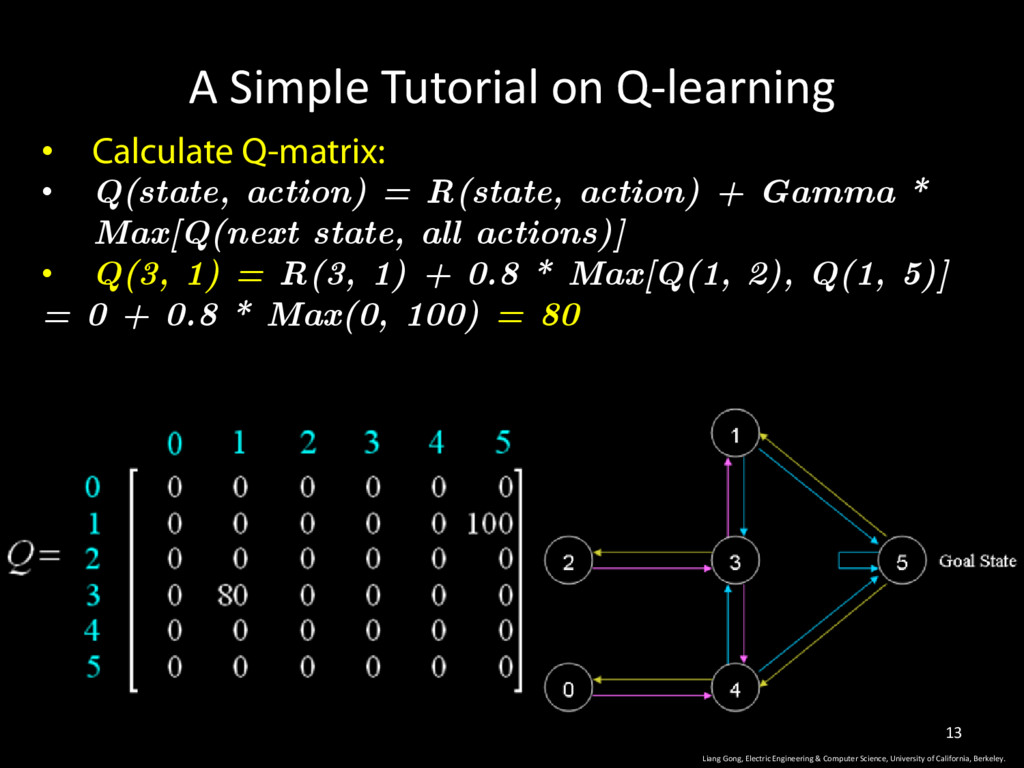
reward matrix R (fixed) • Q-Matrix: Q (changing) State * Action Reward Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 7
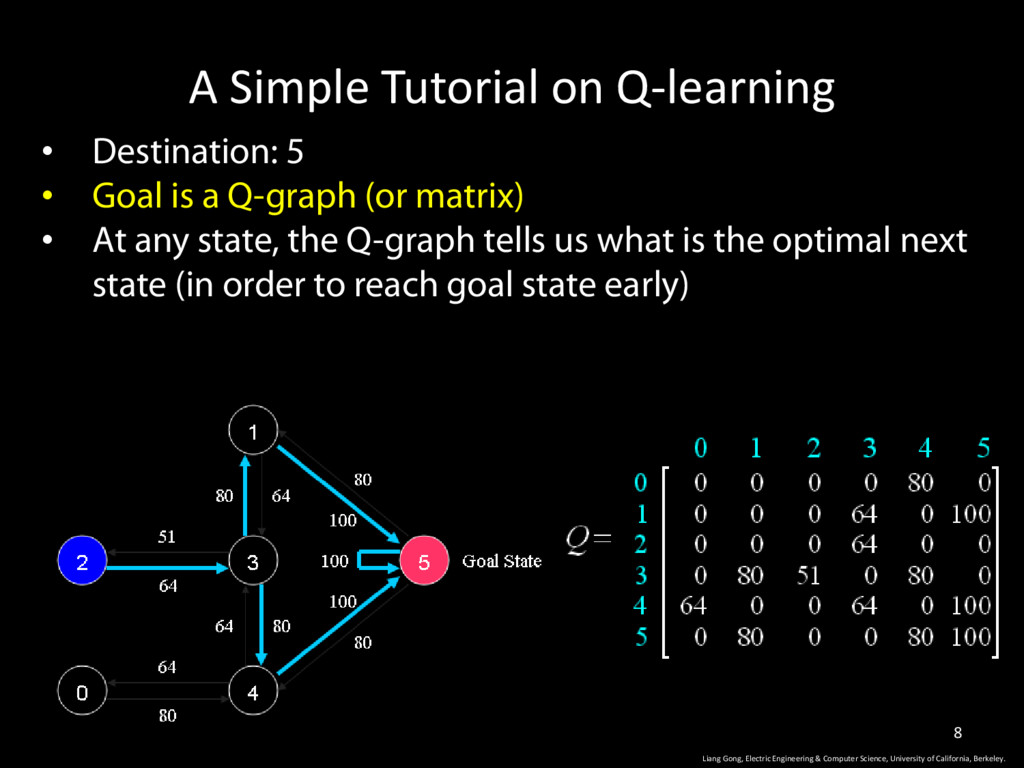
is a Q-graph (or matrix) • At any state, the Q-graph tells us what is the optimal next state (in order to reach goal state early) Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 8
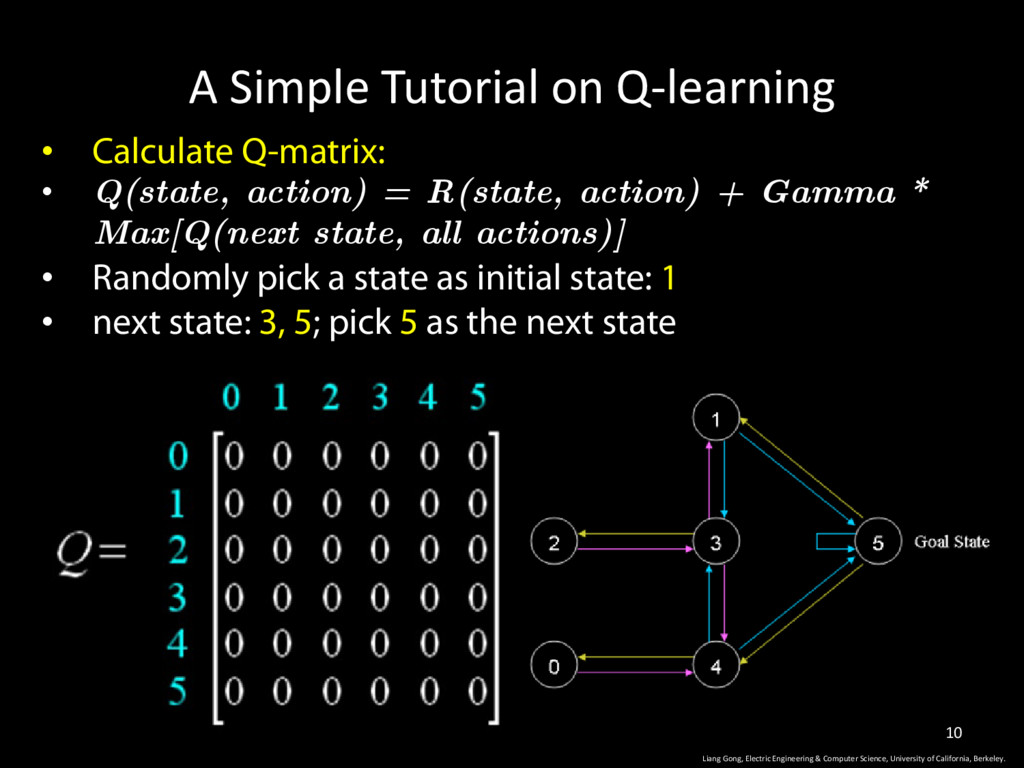
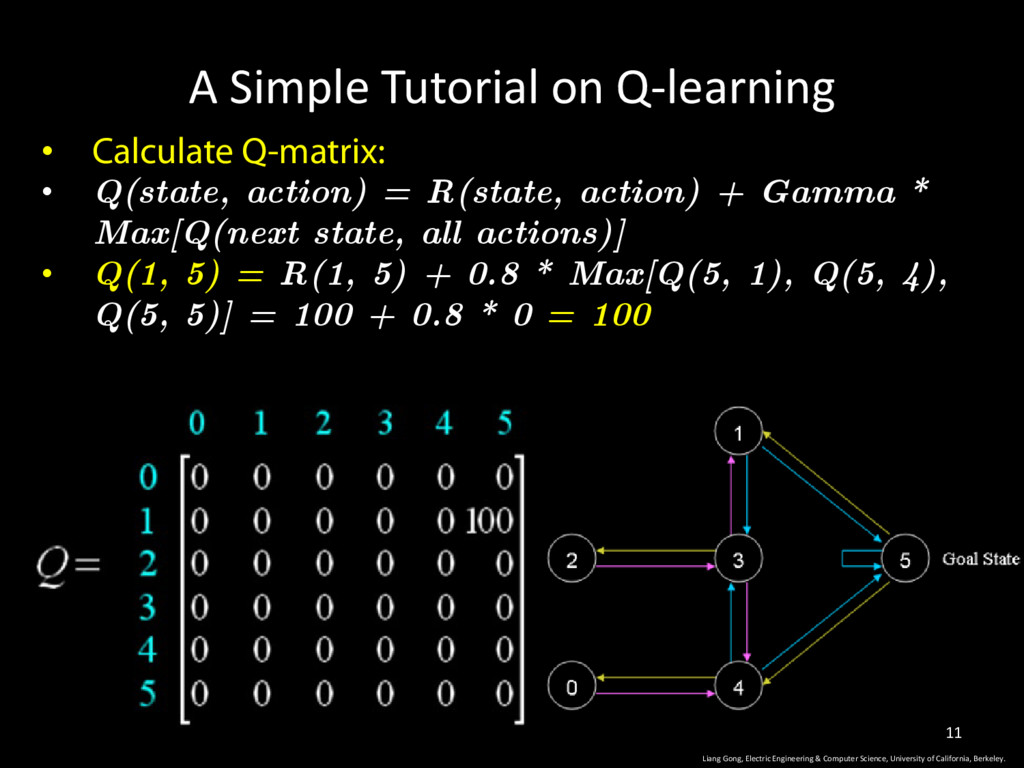
action) = R(state, action) + Gamma * Max[Q(next state, all actions)] • Randomly pick a state as initial state: 1 • next state: 3, 5; pick 5 as the next state Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 10
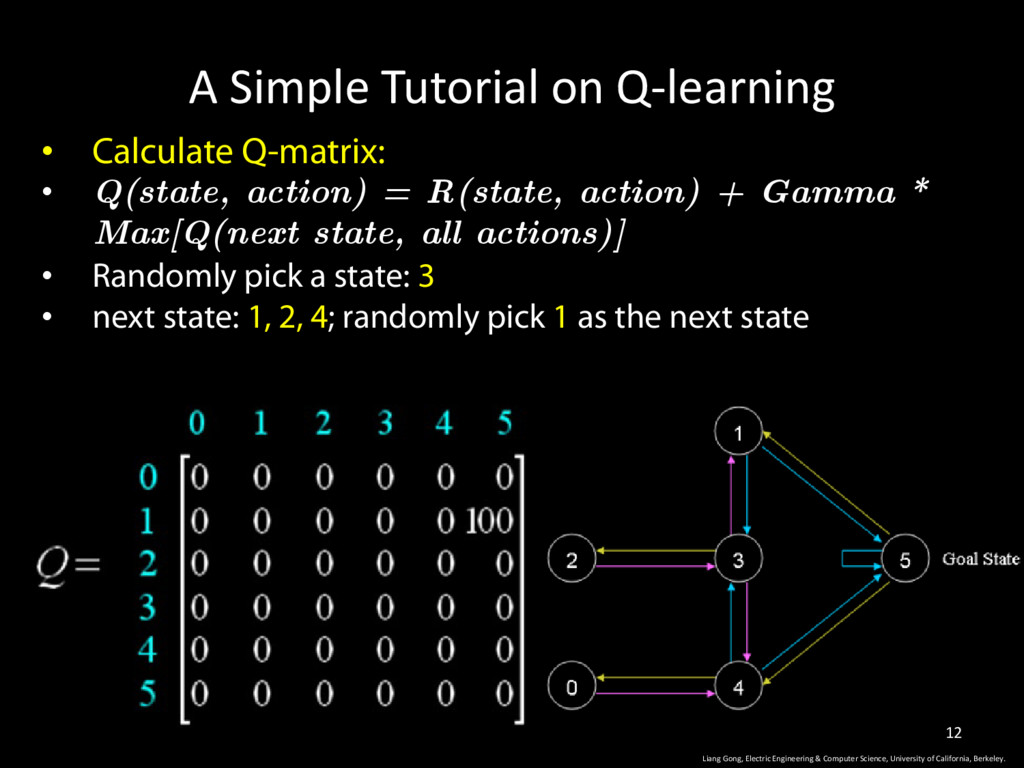
action) = R(state, action) + Gamma * Max[Q(next state, all actions)] • Randomly pick a state: 3 • next state: 1, 2, 4; randomly pick 1 as the next state Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 12
action) = R(state, action) + Gamma * Max[Q(next state, all actions)] • Repeat the process over and over -> convergence Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 14
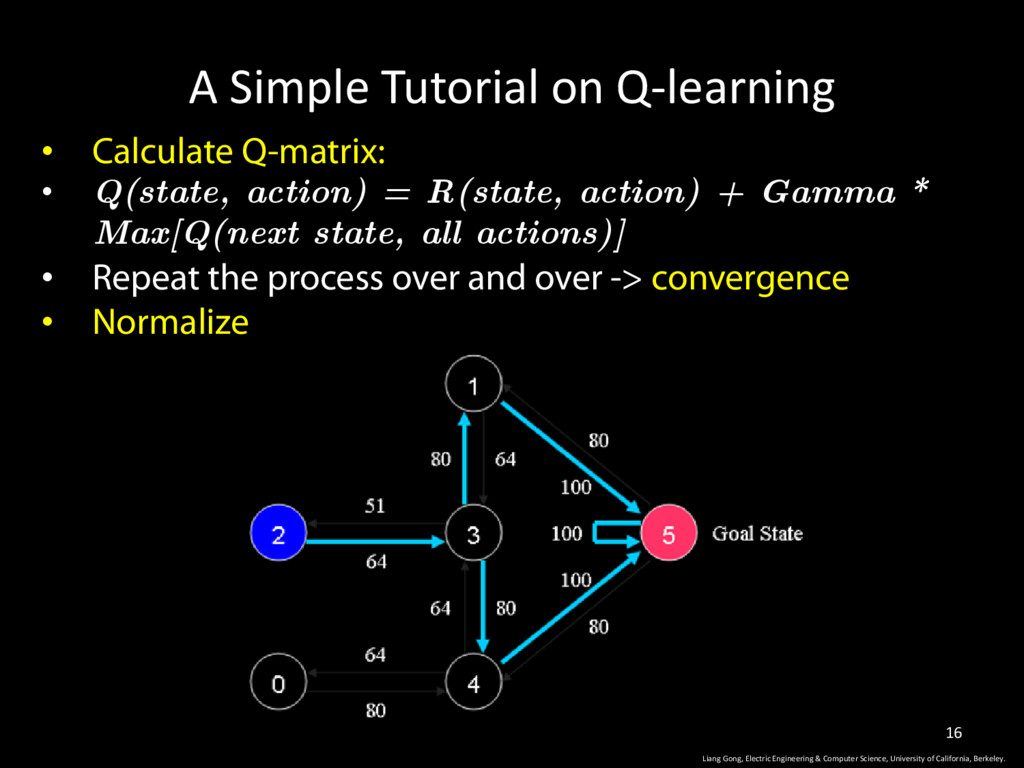
action) = R(state, action) + Gamma * Max[Q(next state, all actions)] • Repeat the process over and over -> convergence • Normalize Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 15
action) = R(state, action) + Gamma * Max[Q(next state, all actions)] • Repeat the process over and over -> convergence • Normalize Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 16
Neural Networks • What is Q-learning? • Q-Learning (a simple example) • Q-Learning on Atari Games • Why use it with Neural Networks? Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 17
Neural Networks • What is Q-learning? • Q-Learning (a simple example) • Q-Learning on Atari Games • Why use it with Neural Networks? Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 18
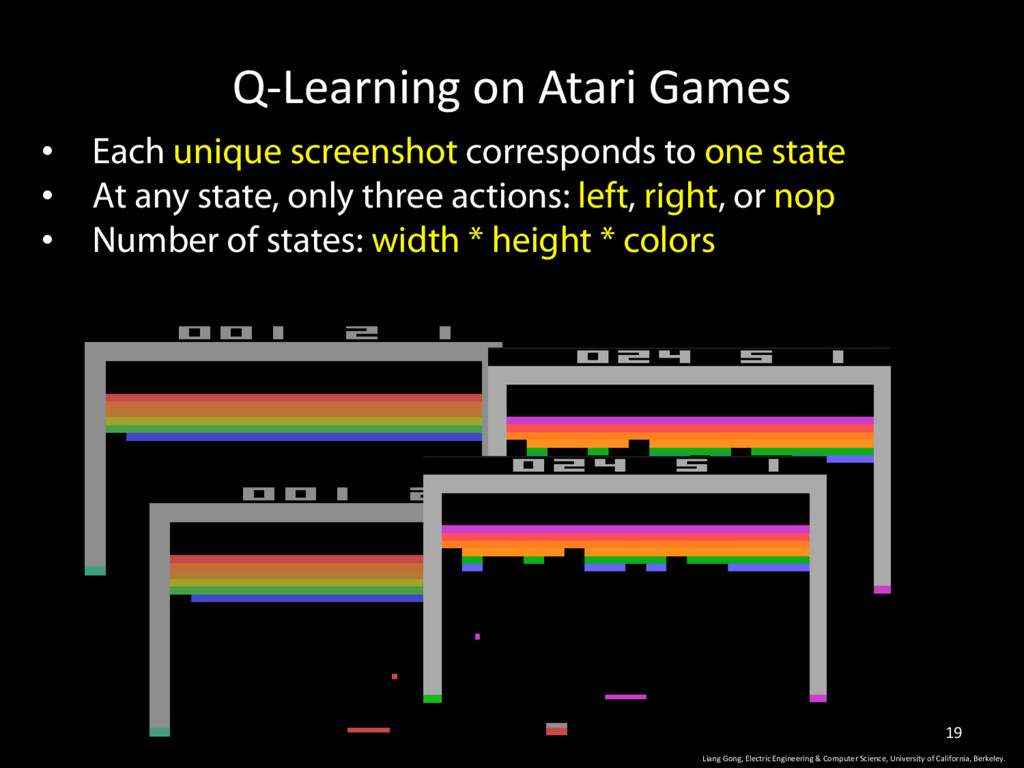
one state • At any state, only three actions: left, right, or nop • Number of states: width * height * colors Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 19
Neural Networks • What is Q-learning? • Q-Learning (a simple example) • Q-Learning on Atari Games • Why use it with Neural Networks? Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 20
one state • At any state, only three actions: left, right, or nop • Number of states: width * height * colors Problem: • Can not start from a random state • Impractical: iterating over all possible states and actions Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 21
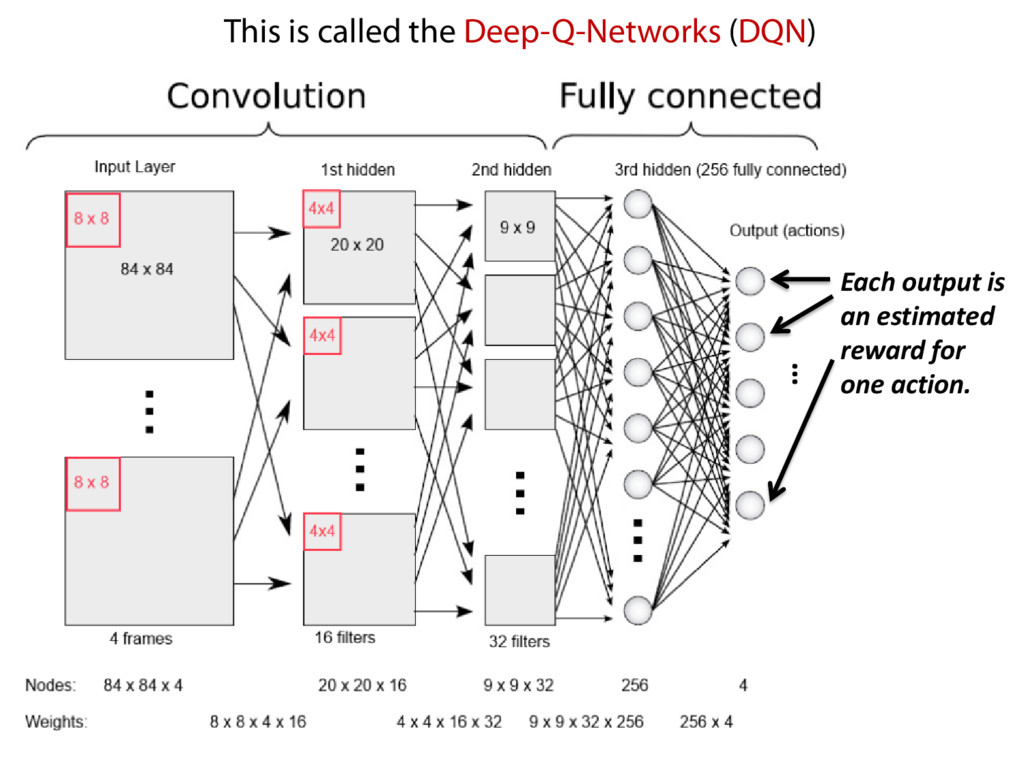
one state • At any state, only three actions: left, right, or nop • Number of states: width * height * colors Problem: • Can not start from a random state • Impractical: iterating over all possible states and actions Solution: • Use a predictor to estimate (or approximate) the converged Q-matrix • Neural Network seems to work well! Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 22
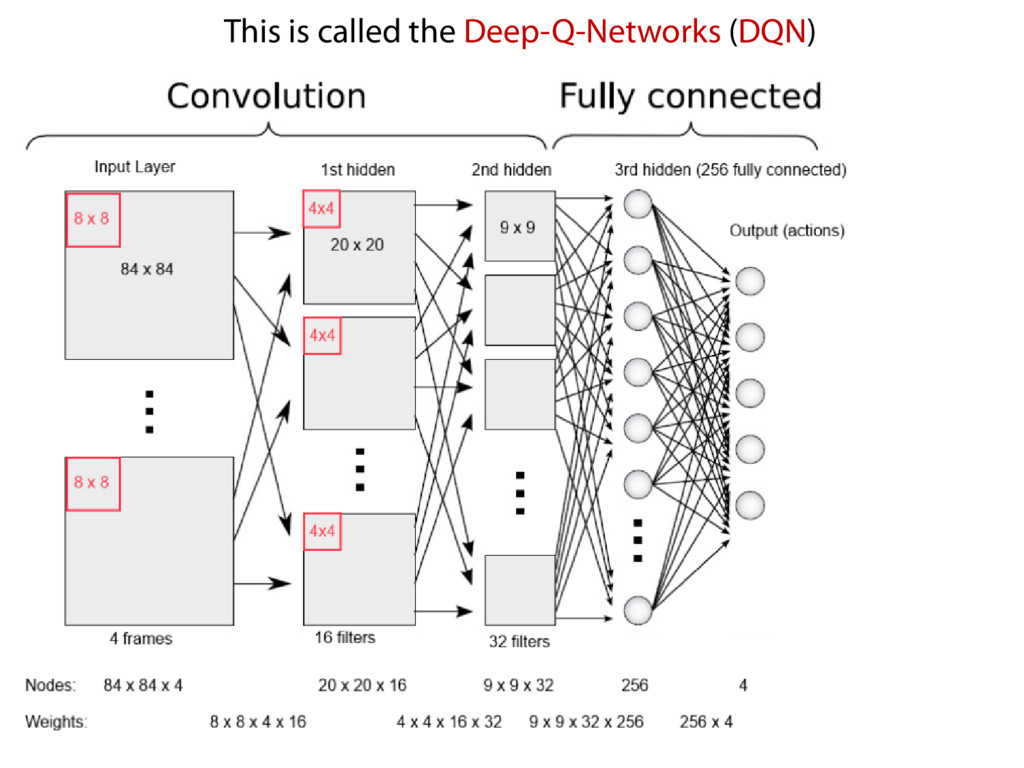
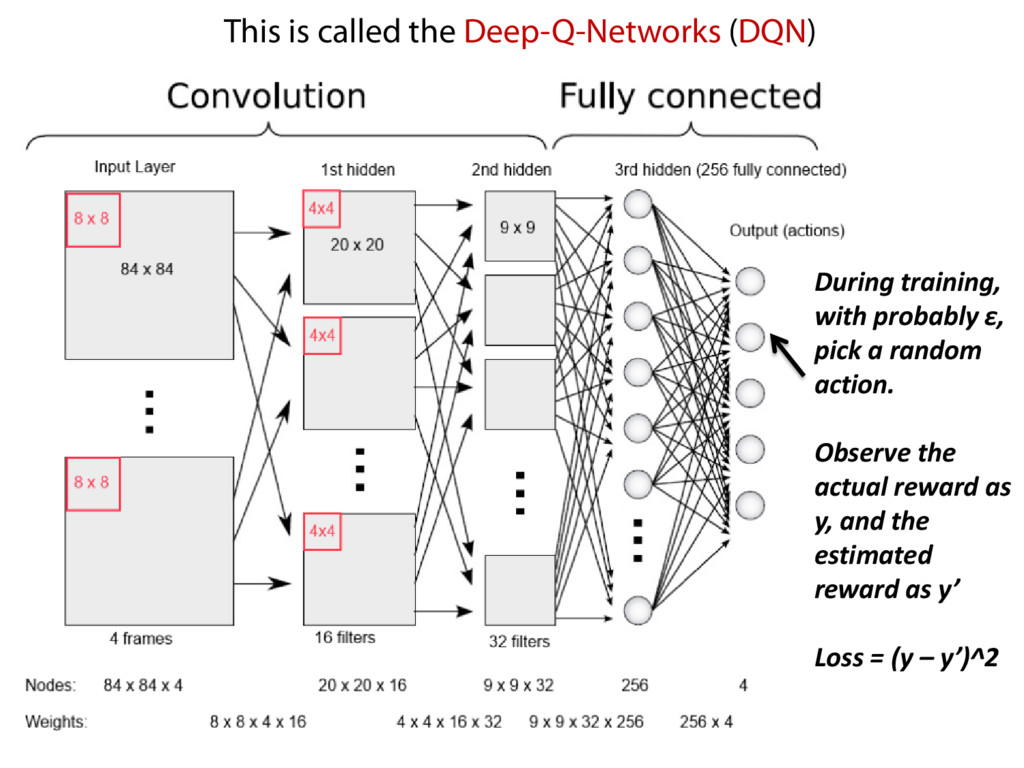
California, Berkeley. This is called the Deep-Q-Networks (DQN) During training, with probably ε, pick a random action. Observe the actual reward as y, and the estimated reward as y’ Loss = (y – y’)^2
action a under state s future discount after action a, the maximal reward for the next possible action The original Q-Learning Formula (Impractical): Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 27
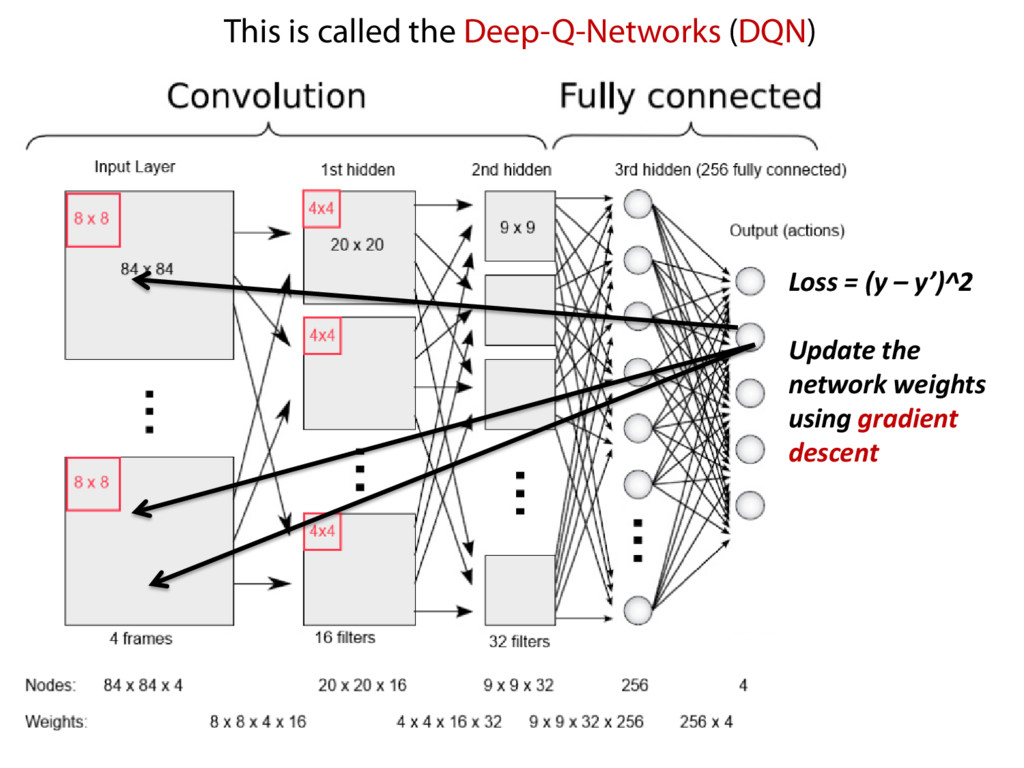
actual reward from Atari game NN predicted reward under state s, action a, and weights Calculate the loss function NN weights in step i Liang Gong, Electric Engineering & Computer Science, University of California, Berkeley. 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}