undirected graph G(V, E) : We want to identify the partition B(V) of V(G) which opti- mizes an objective function f : B, G → R over the set of all partitions B(V).
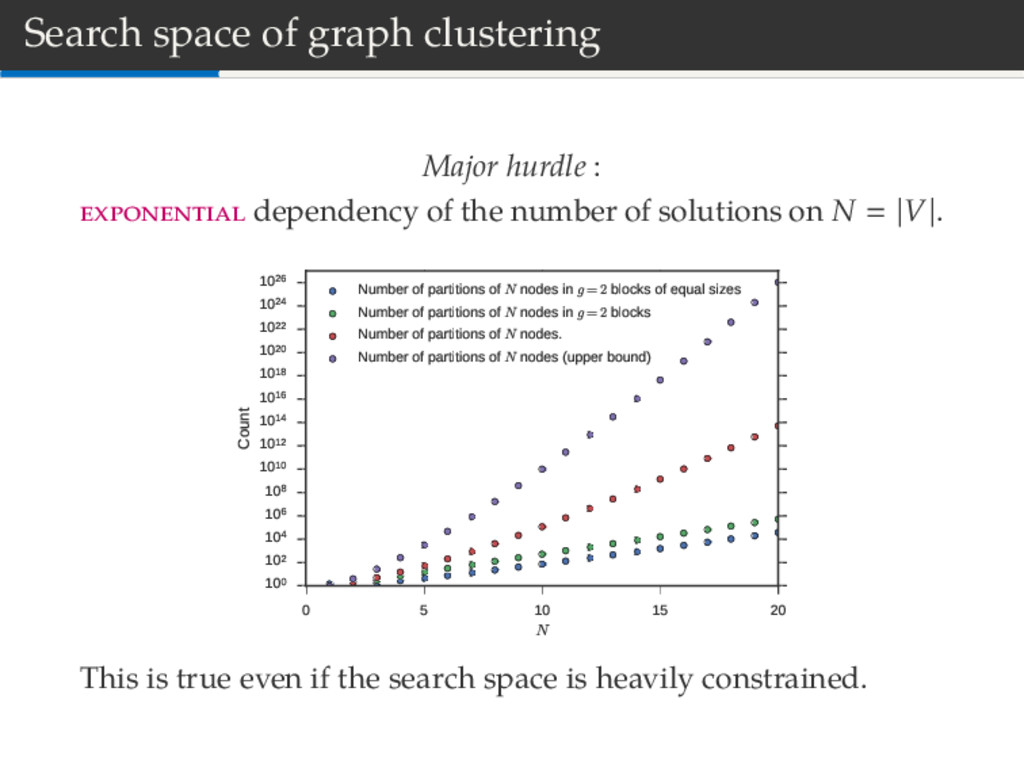
the number of solutions on N |V|. 0 5 10 15 20 N 100 102 104 106 108 1010 1012 1014 1016 1018 1020 1022 1024 1026 Count Number of partitions of N nodes in g=2 blocks of equal sizes Number of partitions of N nodes in g=2 blocks Number of partitions of N nodes. Number of partitions of N nodes (upper bound) This is true even if the search space is heavily constrained.
in polynomial time (easy) NP : Problems solvable in non-deterministic polynomial time (hard) NP-C : Equivalence class of NP (hard) NP-H : Problems which are at least as hard as the hardest problem in NP-C (hardest)
consider objective functions of the form f ({σi }, G) ij h(in) ij (G)δσi σj + ij h(out) ij (G) ¯ δσi σj ij [h(in) ij (G) − h(out) ij (G)]δσi σj . D δij : Kronecker delta. σi : index of the block of vertex vi ∈ V. h(in) ij : cost associated to putting vi, vj in the same block. h(out) ij : cost associated to putting vi, vj in different blocks.
either vi ∈ B or vi ∈ B . We denote this with indicator variables si ± . Then si sj if σi σj − otherwise . and δσi σj ≡ (si sj + )/ . Defining the indicator vector s and objective matrix H, we rewrite the objective function as the f ({σi }, G) ≡ sT Hs + C .
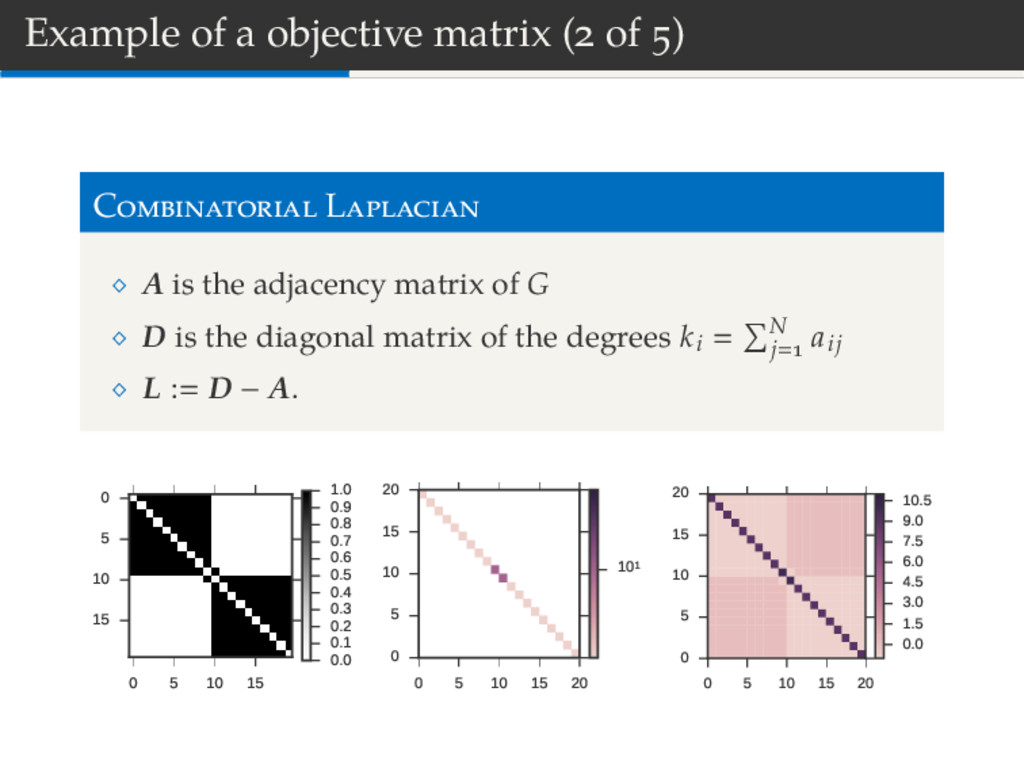
A is the adjacency matrix of G D is the diagonal matrix of the degrees ki N j aij L : D − A. 0 5 10 15 0 5 10 15 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 0 5 10 15 20 0 5 10 15 20 101 0 5 10 15 20 0 5 10 15 20 0.0 1.5 3.0 4.5 6.0 7.5 9.0 10.5
Laplacian counts the number of edges between blocks. fLap sT Ls sT Ds − sTAs Define m(B , B ) as the number of edges between blocks B , B : sT Ds N i ki s i m , sTAs m(B , B ) + m(B , B ) − m(B , B ) .
G) sT Hs subject to s ∈ {− , }N . B partitions are often desirable. Unconstrained bisection does not ask for balance. ∃ two methods to constrains B {B , B } : . Modify f . . Reject bad solutions explicitly.
Suppose that xi ∈ RN is a normalized eigenvector of H with eigenvalue λi. Then f xT i Hxi λi xT i xi λi If we have ordered eigenvectors (accounting for multiplicities), λ ≤ λ ≤ ... ≤ λN ⇒ the optima of f correspond to extremal eigenvalues.
optimization perspective f xT i Hxi ij hij xi xj of f are found by setting {∂xi [ f ]} to zero. We avoid trivial solutions xi ∀i, by asking i x i ∆, ∆ > ∂ ∂xr ij hij xi xj − λ i xi − ∆ (∆ > ) Using ∂xr [xi ] δir, we find that j Hij xj λxi ⇔ Hx λx
relaxed s → x. How do we recover s ? In the , we can show that the sign of xi ∈ x is a good predictor of the nearest s. In general, we can use K-Means to minimize argminB K r i∈Br ||xi − µr || I : Reject solutions that do not satisfy xT ≤ .
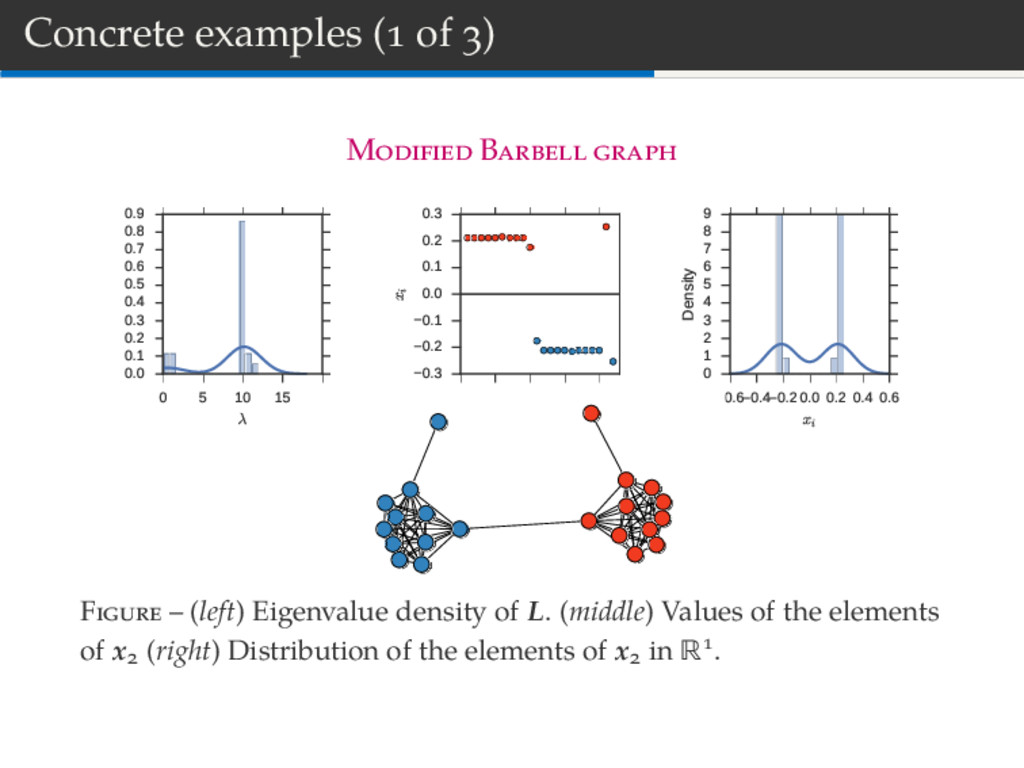
15 20 λ 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0 5 10 15 20 i 0.3 0.2 0.1 0.0 0.1 0.2 0.3 xi 0.6 0.4 0.20.0 0.2 0.4 0.6 xi 0 1 2 3 4 5 6 7 8 9 Density F – (left) Eigenvalue density of L. (middle) Values of the elements of x (right) Distribution of the elements of x in R .
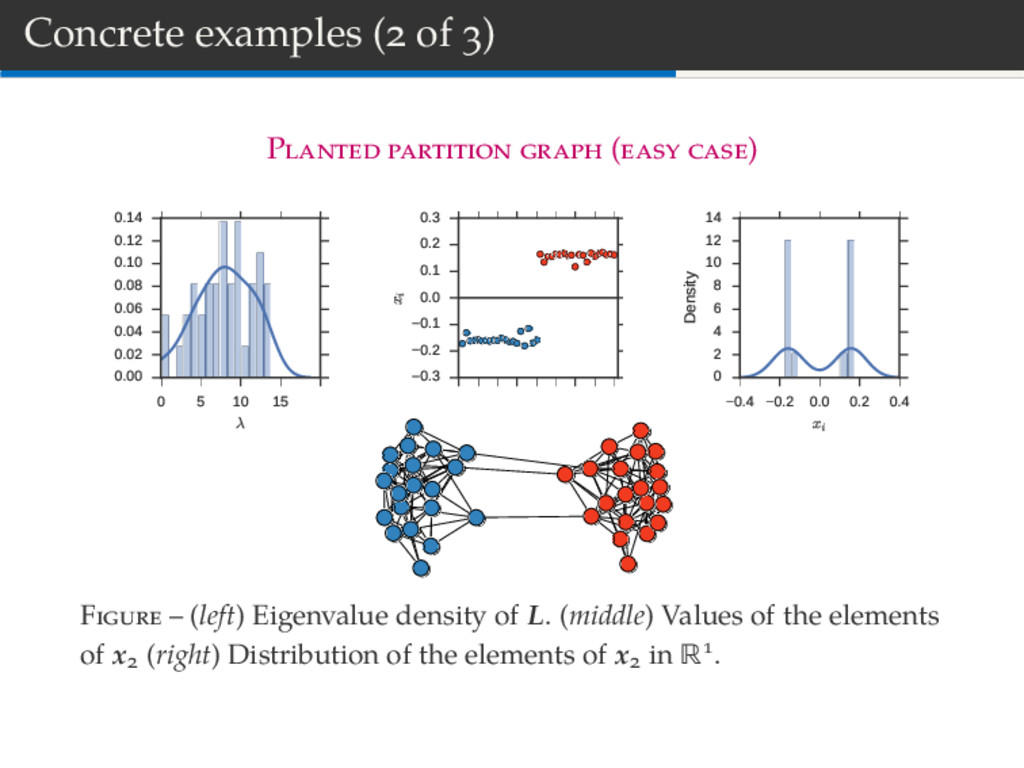
10 15 20 λ 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0 5 10 15 20 25 30 35 40 i 0.3 0.2 0.1 0.0 0.1 0.2 0.3 xi 0.4 0.2 0.0 0.2 0.4 xi 0 2 4 6 8 10 12 14 Density F – (left) Eigenvalue density of L. (middle) Values of the elements of x (right) Distribution of the elements of x in R .
10 15 20 25 λ 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0 5 10 15 20 25 30 35 40 i 0.4 0.2 0.0 0.2 0.4 0.6 xi 0.4 0.2 0.0 0.2 0.4 xi 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 Density F – (left) Eigenvalue density of L. (middle) Values of the elements of x (right) Distribution of the elements of x in R .
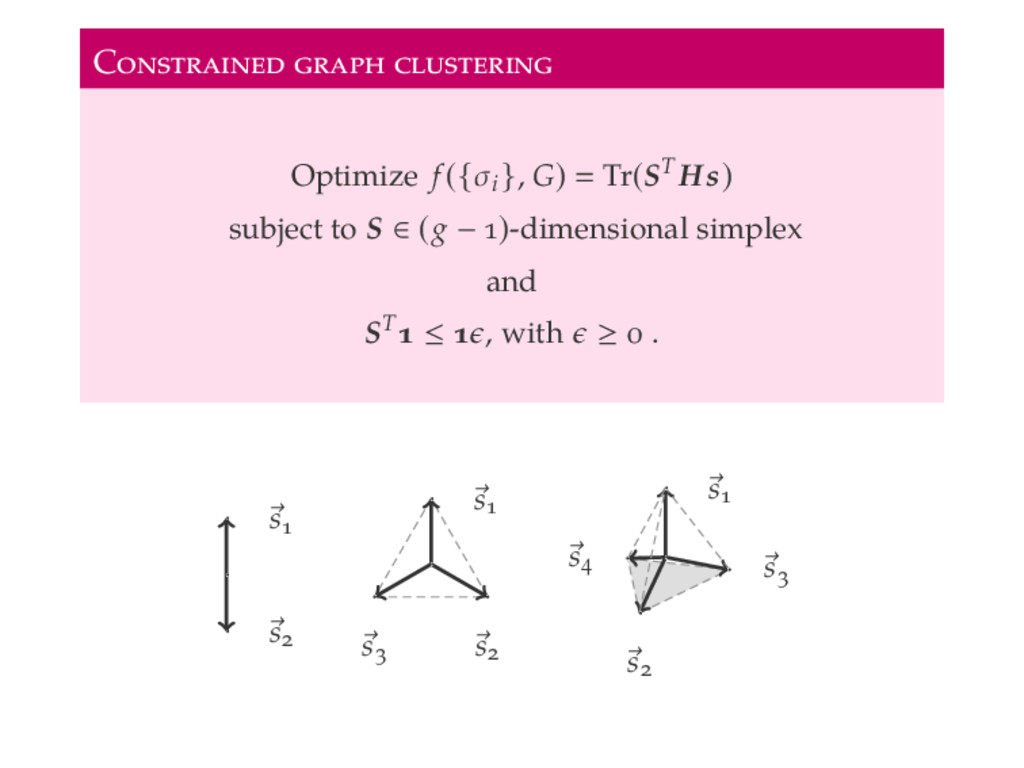
we optimize objective functions of the form f ({σi }, G) ij [h(in) ij (G) − h(out) ij (G)]δσi σj . If the partition has g ≥ block B, we must use indicator to represent δσi σj . s s s s s s s s s F – Corners of regular (g − )-simplices.
vectors satisfy sT i si − g if σi σj − g otherwise . ( ) f ({σi }, G) ij [h(in) ij (G) − h(out) ij (G)]δσi σj Tr ST HS + C S is the N × g − matrix with vector si on row i.
eigenvectors of H such that HX XΛ where Λ is the diagonal matrix of eigenvalues. We see f Tr XT HX Tr XT XΛ g− i λi ⇒ the optima of f are given by sums of extremal eigenvalues.
[ f ]} to zero. f Tr XT HX We avoid trivial solutions Xrs ∀i, by asking XT X ∆I ∂ ∂X Tr XT HX − Tr X(Λ + ∆I)XT (∆ > ) This leads to HX XΛ Because we have the identities ∂ ∂X Tr(XTAX) (A + AT)X ∂ ∂X Tr(XAXT) X A + AT
matrix H, tolerance . Compute the g largest (smallest) eigenvalues of H . Construct the N × (g − ) matrix of eigenvectors X . Verify that XT ≤ (element-wise). If not, replace the faulty eigenvector. . Cluster the elements of X in Rg− with K-Means (K g − ). Return : The clusters in Rg− .
12 14 16 λ 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.3 0.2 0.1 0.0 0.1 0.2 0.3 x(1) i 0.2 0.1 0.0 0.1 0.2 0.3 x(2) i F – (left) Eigenvalue density of L. (right) Elements of x versus the element of x in R .
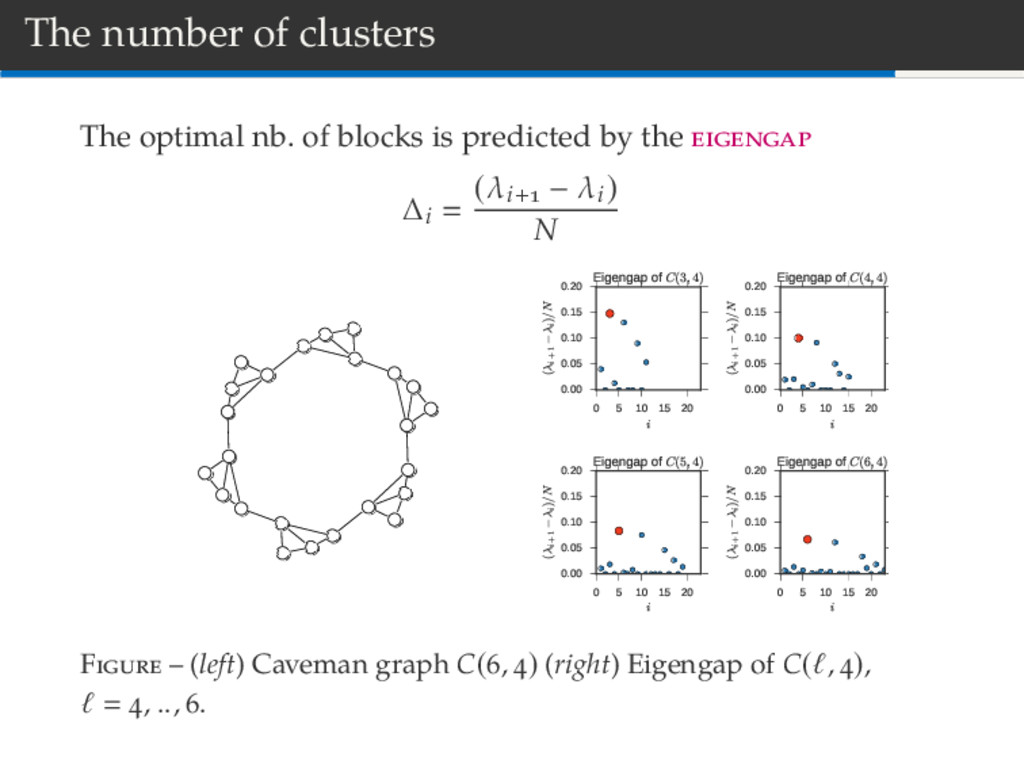
0.000 0.005 0.010 0.015 0.020 0.025 0.030 (λi+1 − λi)/N Eigengap of Zachary's Karate Club F – (left) Graph of interactions (right) Statistics of the eigengap [Laplacian matrix].
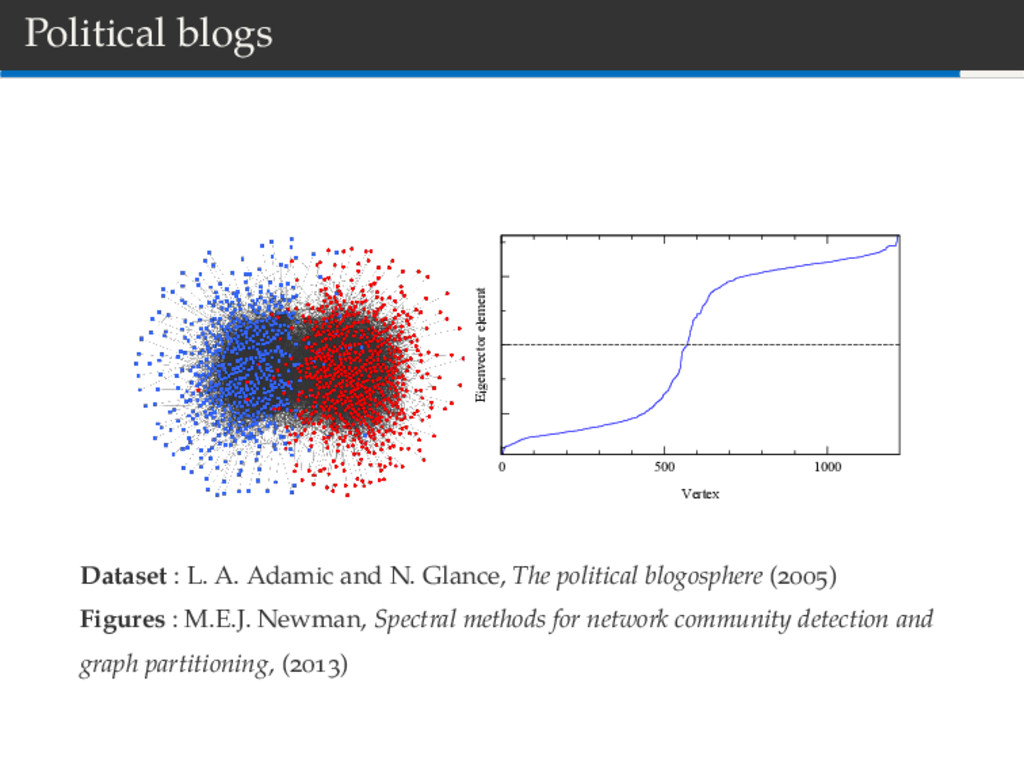
L. A. Adamic and N. Glance, The political blogosphere ( ) Figures : M.E.J. Newman, Spectral methods for network community detection and graph partitioning, ( )
the discrete constraint ⇒ spectral algorithm The spectral approach arises from the continuous optimization perspective The framework is general, arbitrary H.
online at www.jgyoung.ca/crm2016/ Recommended reading E : U. Von Luxburg, A tutorial on spectral clustering, Statistics and computing, ( ), pp. – . C : M. A. Riolo and M. E. J. Newman, First-principles multiway spectral partitioning of graphs, J. Complex Netw., ( ), pp. – .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}