Potter's Wheel: An Interactive Data Cleaning System
Interactive data cleaning system including type induction, discrepancy induction, scalable spreadsheet interaction, a formal transformation algebra and optimizations.
Early work that led to Wrangler, Trifacta, and the Data Preparation market.
n Inter-organizational differences in data representation n Home Depot: 60,000 suppliers! n Data often scraped off web pages, etc. n E.g. in centralized systems n Data entry “errors”, poor integrity constraints Cleansing a prereq for analysis, xactions Cleansing done by “content managers” n Ease of use critical! n Standards can help a bit (e.g. UDDI) n But graphical tools are the name of the game
a spreadsheet n data auditing tools n domain-specific algorithms Code up transforms to fix errors n “ETL” (extract/transform/load) tools from warehousing world n string together domain-specific cleansing rules n scripting languages, custom code, etc. Apply transforms on data Iterate n special cases n nested discrepancies, e.g. 19997/10/31 Code Apply Detect
transforms n regular expressions, grammars, custom scripts, etc. n Discrepancy detection n notion of discrepancy domain-dependent n want a mix of custom and standard techniques n want to apply on parts of the data values Rebecca by Daphne du Maurier (Mass Market Paperback) $6.29 **** Sonnet 19. Craig W.J., ed. 1914. The Oxford Shakespeare The Big Four Agatha Christie, Mass market paperback 5.39 10% (from bartleby.com, bn.com)
n Even on big data! Use Online Reordering (VLDB ‘99), sampling n Ensure transform results can be seen/undone instantly n Compile/optimize sequence of transforms when happy Eliminate programming, but keep user “in the loop” n Semi-automatic, “direct manipulation” GUI n Support & leverage “eyeball” detection, verification (human input) n Point-and-click transformation “by example” Unify detection and transformation n Detection always runs online in the background n Detection always runs on transformed “view” of data Extensibility n Domain experts (vendors) should be able to plug in detectors/transforms A mixed (“Systems!”) design challenge: n Query Processing, HCI, Learning Limited appreciation for this kind of systems work
n Given: n A set of (possibly composite) data items, including discrepancies n A set of user-defined “domains” (atomic types) n Choose a “structure” for the set n A string of domains (w/repetition) that best fits the data n E.g. for “March 17, 2000”: n S* n alpha* digit*, digit* n [Machr]* 17, int Report rows that do not fit chosen domain PS: Must be an online algorithm!
{ // Required inclusion function boolean match(char *value); // Helps in structure extraction int cardinality(int length); // For probabilistic discrepancy checking float matchWithConfidence(char *value, int dataSetSize); void updateState(char *value); // Helps in parsing boolean isRedundantAfter(Domain d); } e.g. integer, ispell word, money, standard part names
as many values as possible n Precision n flag as many real discrepancies as possible n e.g. Month day, day over alpha* digit*, digit* n Conciseness n avoid over-fitting examples, make use of the domains n e.g. alpha* digit*, digit* over March 17, 2000
…dp , string vi , how good is S? Minimum Description Length (MDL) principle n Rissanen, ‘78, etc. n DL(vi ,S) = length of theory for S + length to encode string vi with S Computing DL(v,S) 1) Length of theory = p log (number of domains known) 2) If vi doesn’t match S, encode it explicitly 3) Else encode vi = wi,1 wi,2 …wi,p where wi,j Î dj n Encode length of each wi,j n Encode each wi,j among all dj ’s of length j n use cardinality function n DL = AVGi ((1) + (2) + (3)) = AVGi (UnConciseness + UnPrecision + UnRecall) Choose structure with minimum DL(v,S) n Hard search problem; heuristics in paper
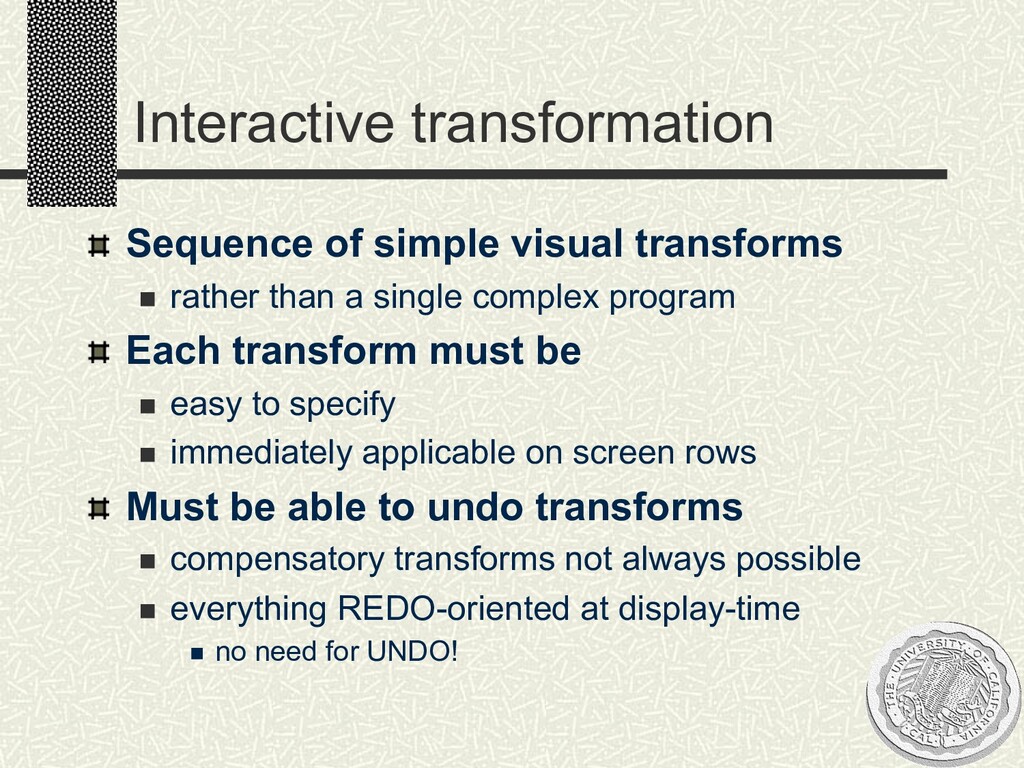
a single complex program Each transform must be n easy to specify n immediately applicable on screen rows Must be able to undo transforms n compensatory transforms not always possible n everything REDO-oriented at display-time n no need for UNDO!
expr. substitution, arithmetic ops, … One-to-one row mappings n Add/Drop/Copy columns n Merge,Split columns n Divide column by predicate One-to-many row mappings n Fold columns n adapted from Fold of SchemaSQL[LSS’96] n Resolve some higher-order differences
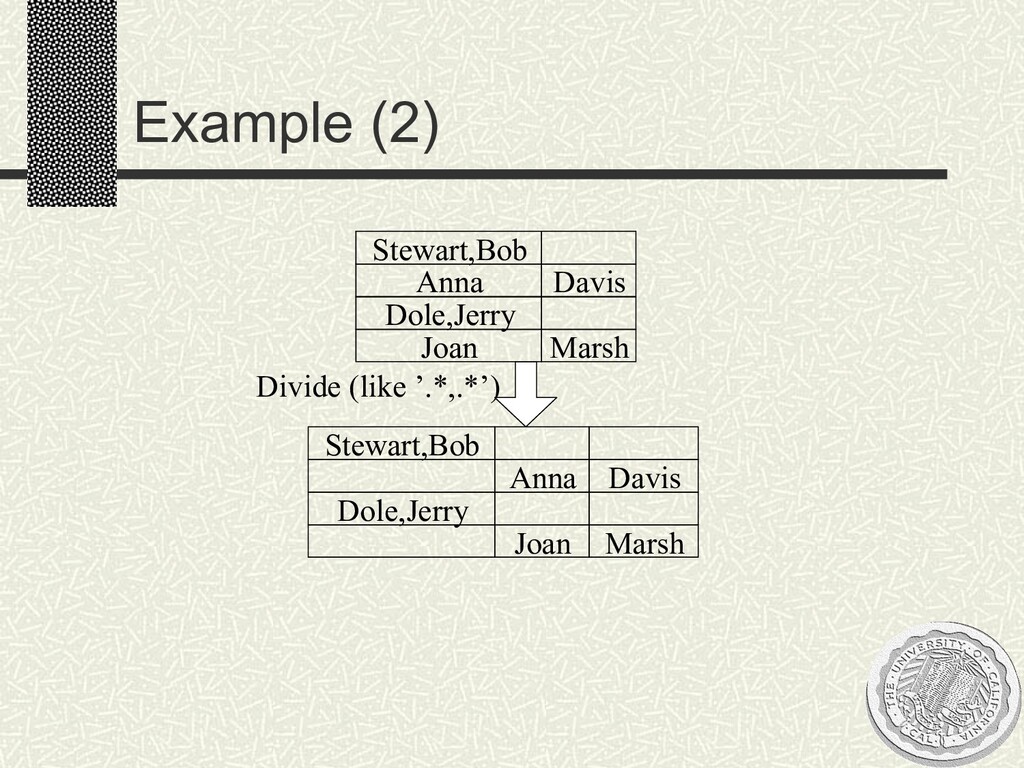
Stewart,Bob Dole,Jerry Davis Marsh Anna Joan Stewart Anna Davis Dole Joan Marsh Jerry Bob Bob Jerry Stewart Dole Anna Joan Davis Marsh Split at ' ' Anna Joan Davis Marsh Bob Stewart Jerry Dole
Math:96 Bio:78 Bio:54 Name Math 43 96 Ann Bob 78 54 Bio Ann Bob Bob Ann Name Math:96 Bio:54 Math:43 Bio:78 Math Bio Math Bio Ann Ann Bob Bob Name 43 78 96 54 Name
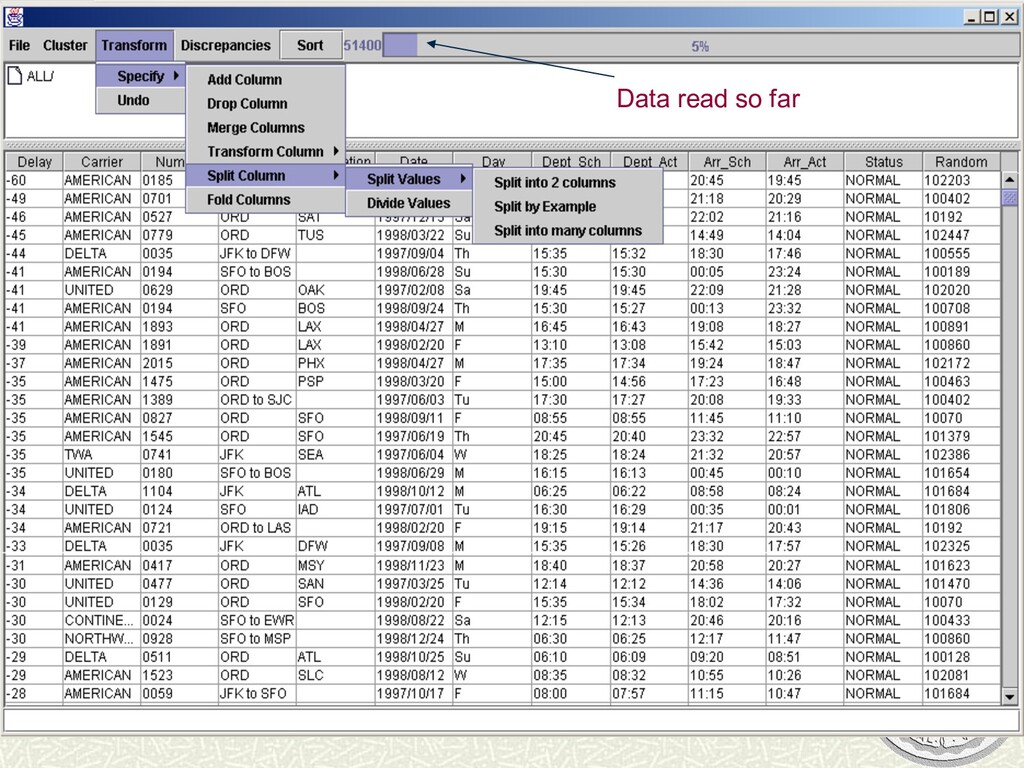
hard to do interactively n must find/display companion rows for each row to transform n higher-order transforms Specification n click on appropriate columns and choose transform n but, Split is hard n important transform in screen-scraping/wrapping n need to enter regular expressions n not always unambiguous n e.g. n want to leverage domains Taylor, Jane, $52,072 Tony Smith, 1,00,533 Transforms summary
infers structure, then parses rest Parsing n must identify matching substrings for structures n multiple alternate parses could work n search heuristics explored in paper n DecreasingSpecificity seems good Taylor, Jane|, $52,072 Tony Smith|, 1,00,533 infer structures <S * >, <‘,’ Money>
tools n commercial -- ETL and auditing tools n research -- e.g. AJAX, Lee/Lu/Ling/Ko ’99 Custom auditing algorithms n de-duplication (e.g. Hernandez/Stolfo ’97) n outlier detection (e.g. Ramaswamy/Rastogi/Shim ’00) n dependency inference (e.g. Kivinen/Manilla ’95) Structure extraction techniques n e.g. XTRACT, DataMold, Brazma ‘94 Transformation tools n text-processing tools – e.g. perl/awk/sed, LAPIS n screen-scraping -- e.g. NoDoSE, XWRAP, OnDisplay, Cohera Connect, Telegraph Screen Scraper (TeSS) Middleware, schema mapping
n Perform both interactively n short, immediately applied steps n specify visually, undo if needed n contrast with declarative language n Parse values before discrepancy detection n user-defined domains helpful Software online (http://control.cs.berkeley.edu/abc)
HTML) More complex domain-expressions Extend to generalized query processor client in Telegraph n specify initial query n refine by specifying transforms as results stream in n dynamically choose transforms to be pushed into server n See Shankar’s upcoming thesis, Telegraph papers
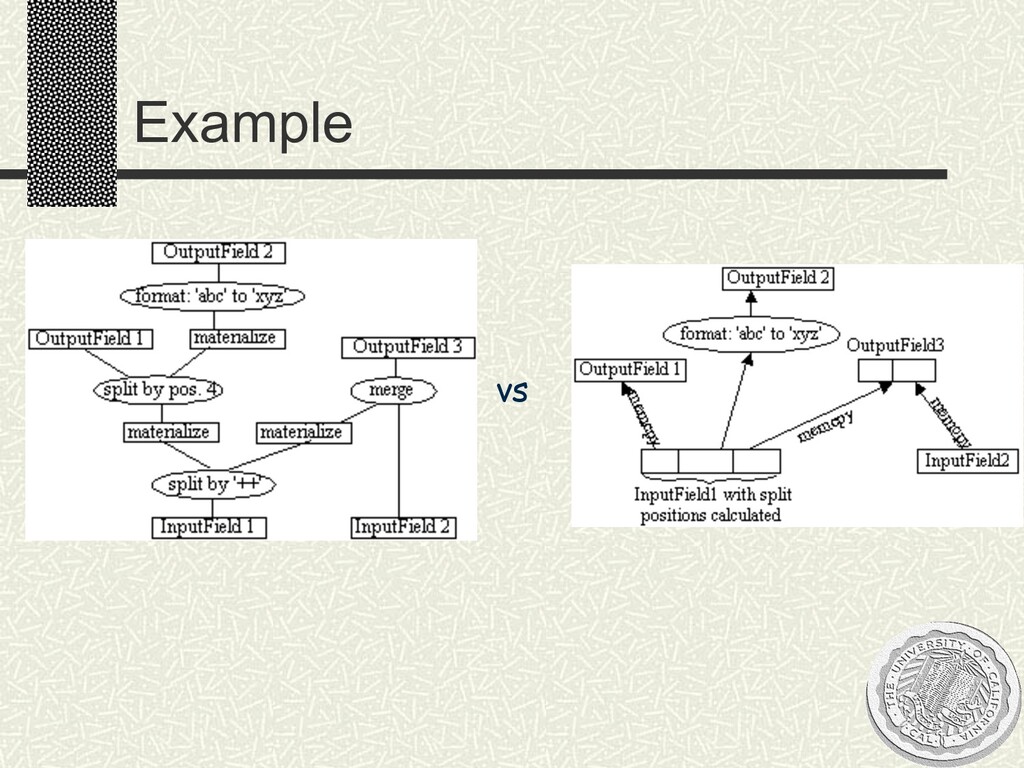
at end n hence opportunities for optimization remove redundant operations avoid expensive memory copies/allocations/deallocations by careful pipelining materialize intermediate strings only when necessary up to 110% speedup for C programs n C programs 10x faster than Perl scripts
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}