Talk from SF Scala / Bay Area Machine Learning Meetup on 9-22-2014.
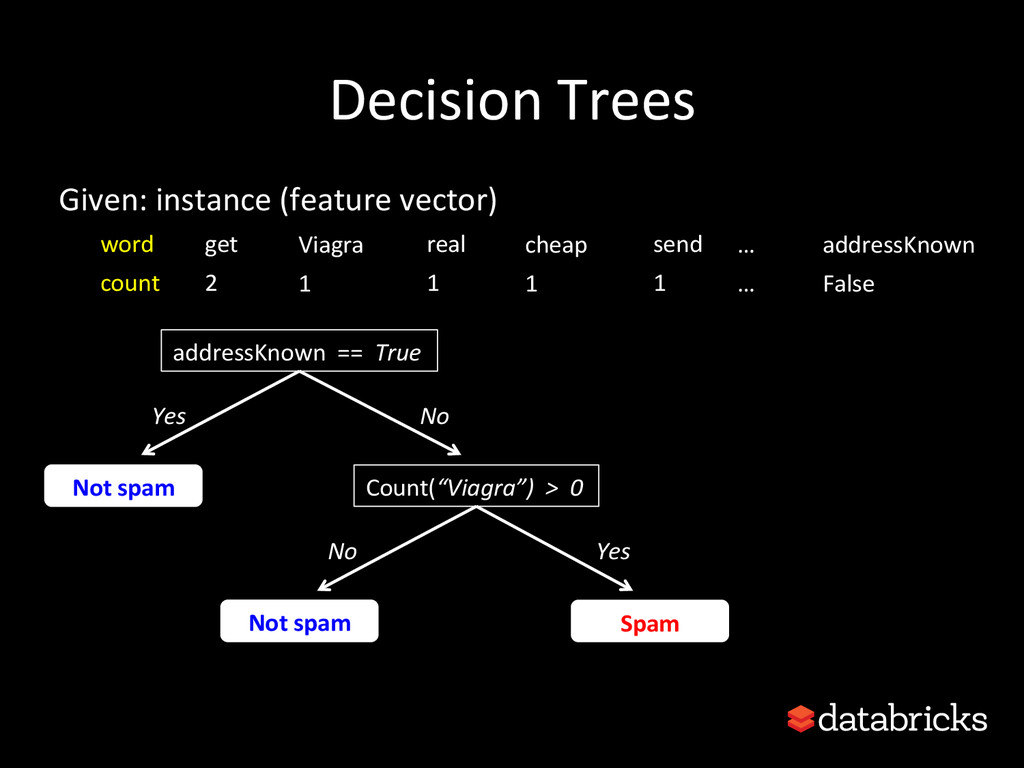
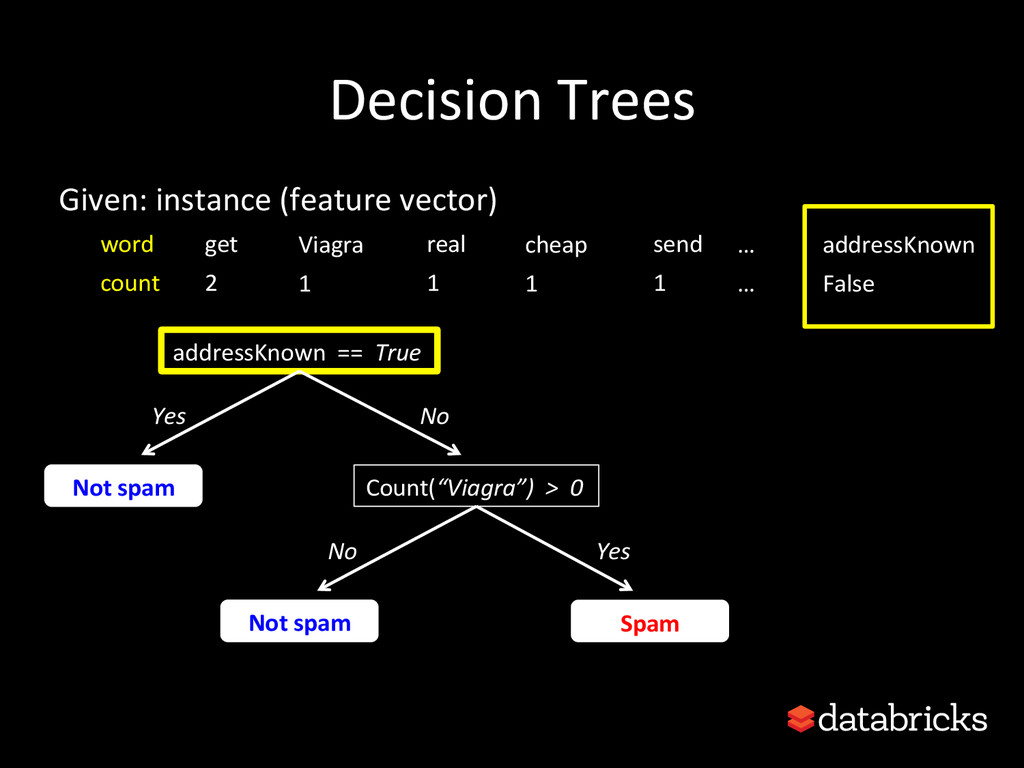
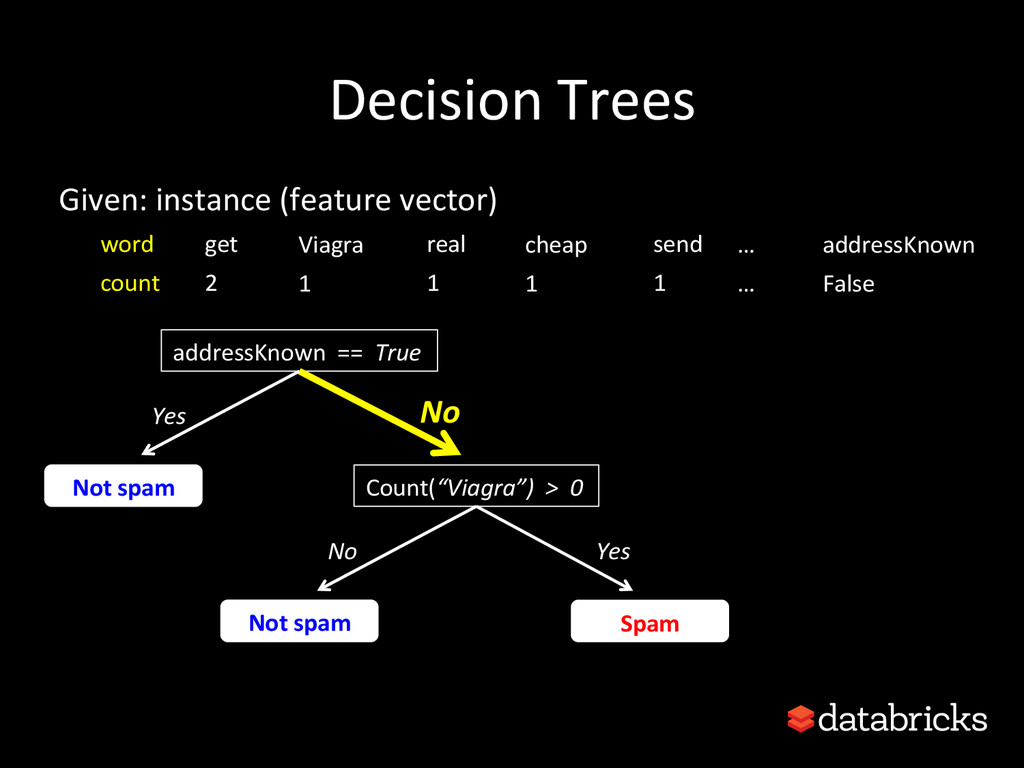
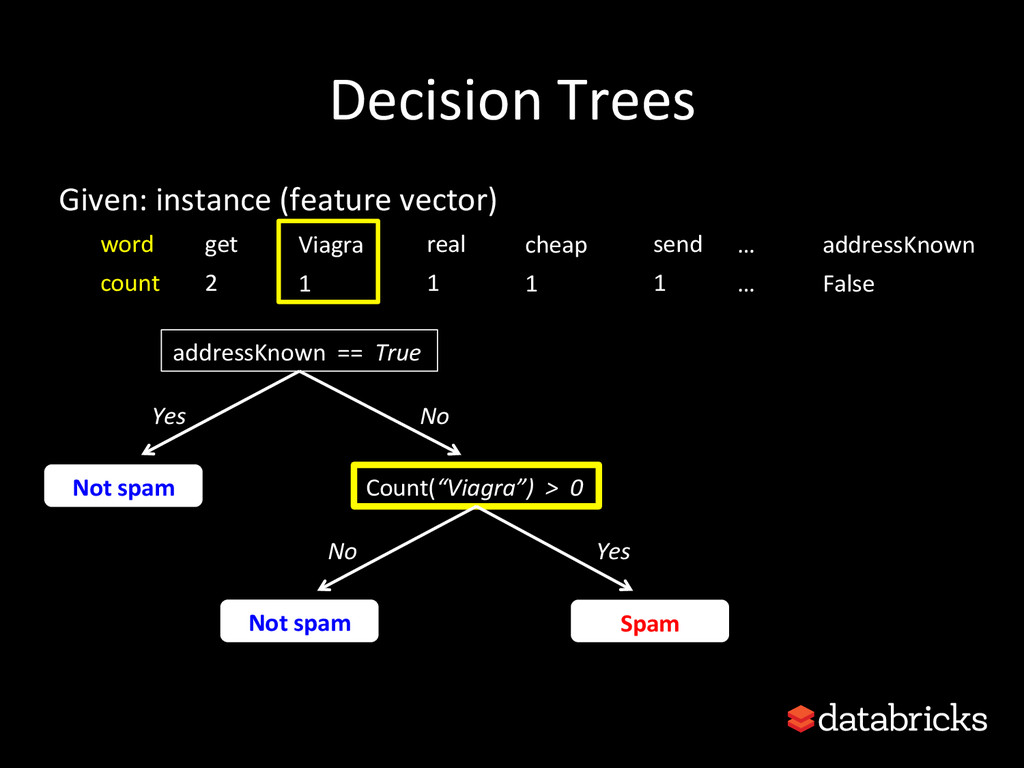
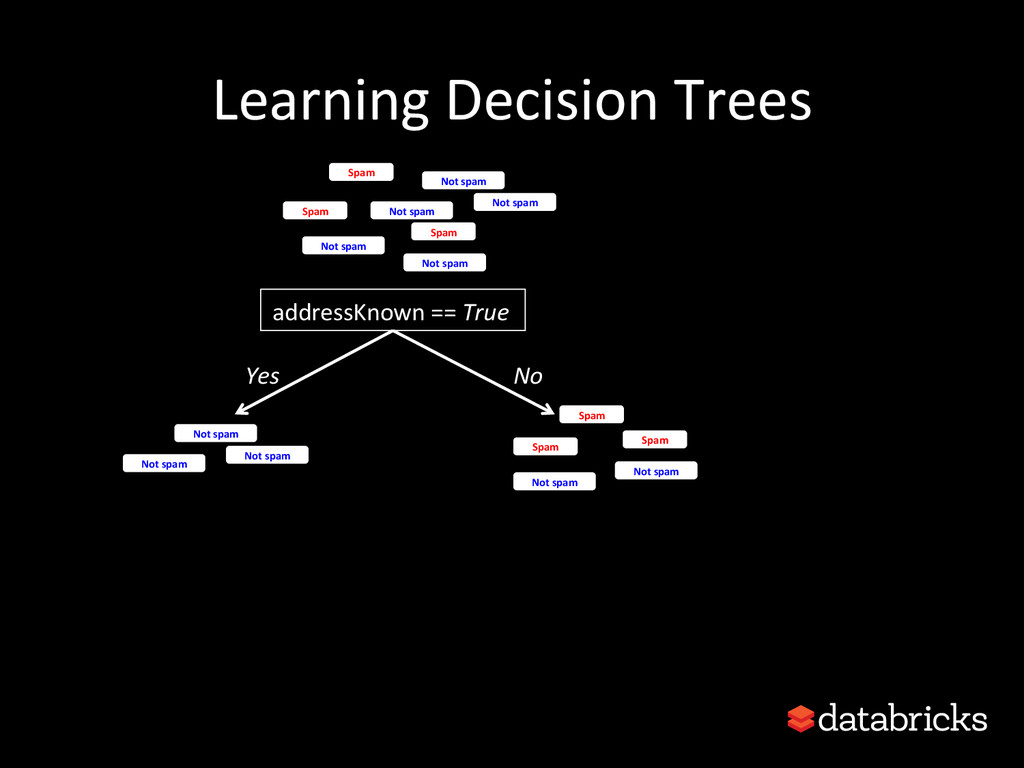
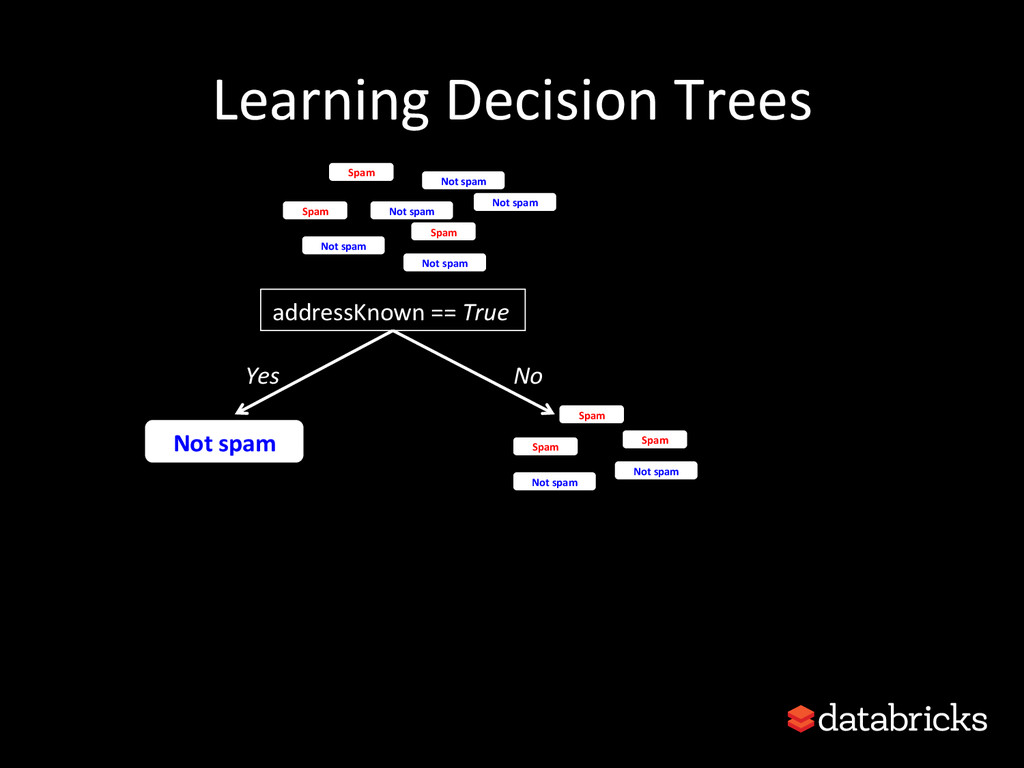
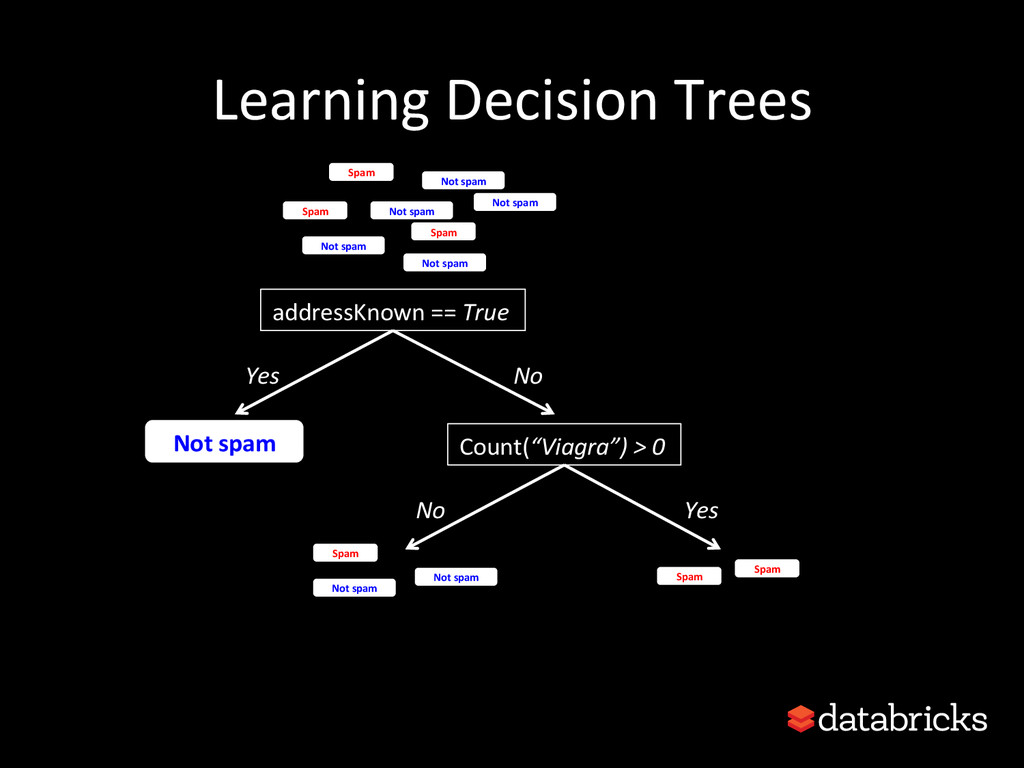
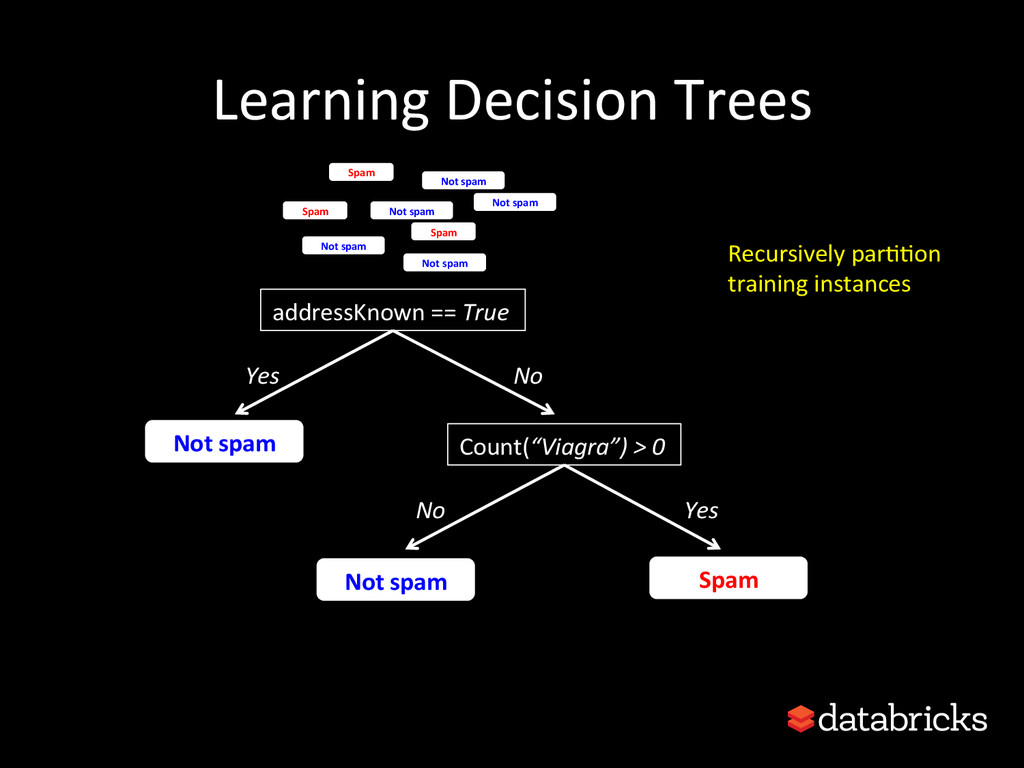
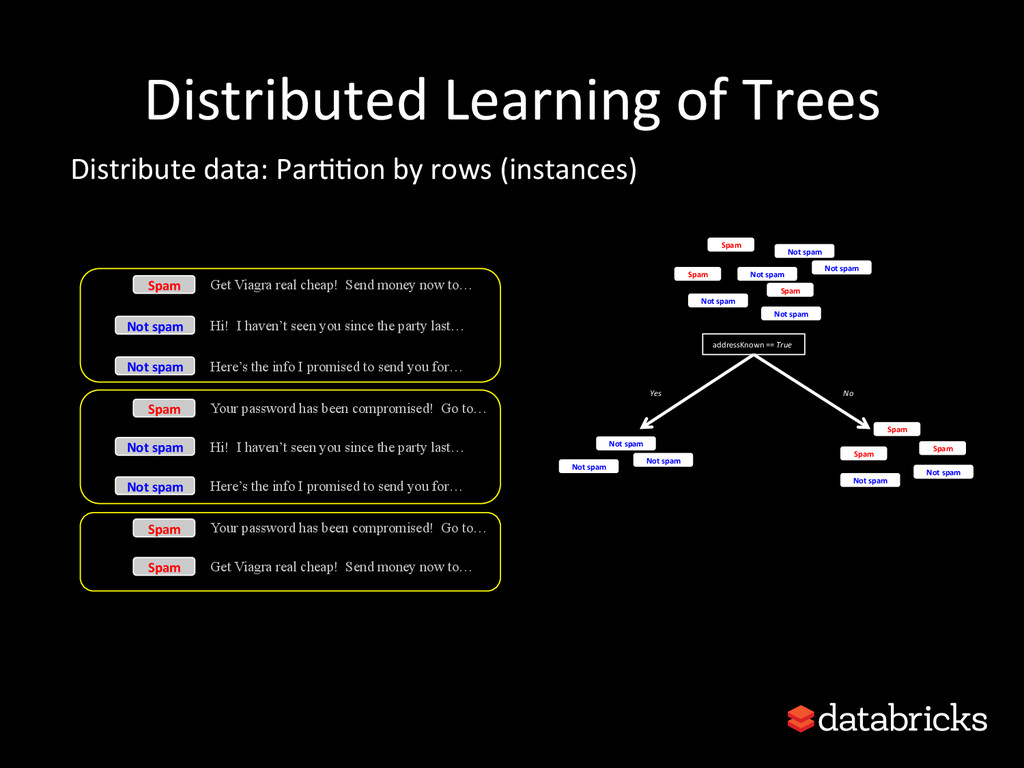
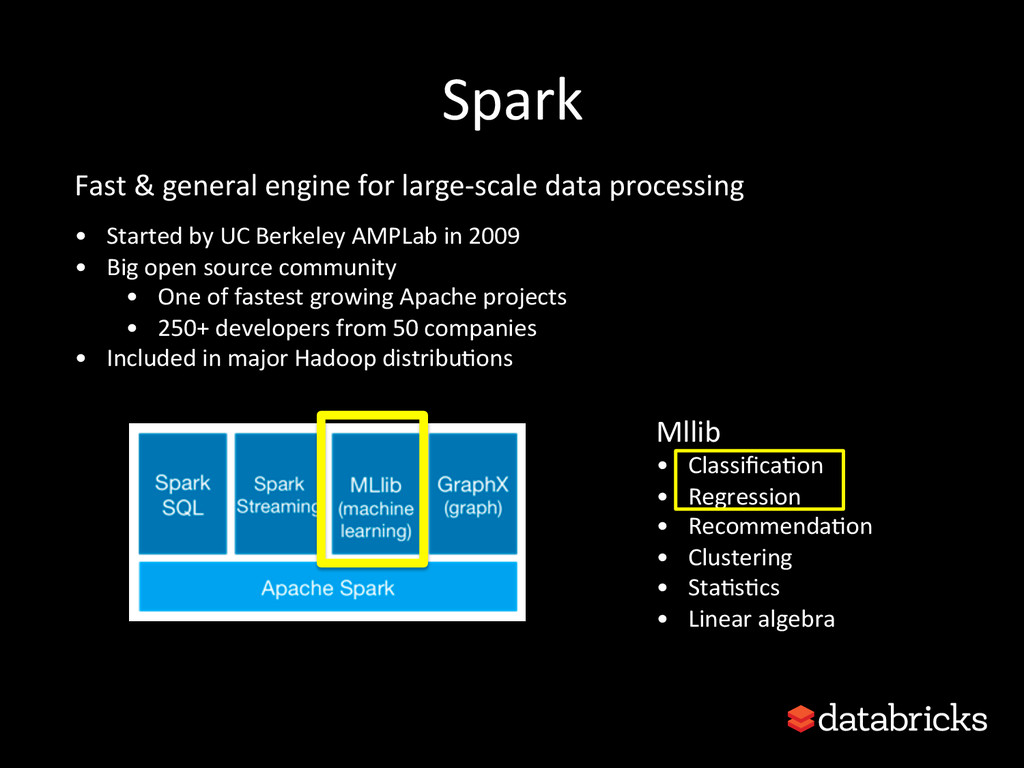
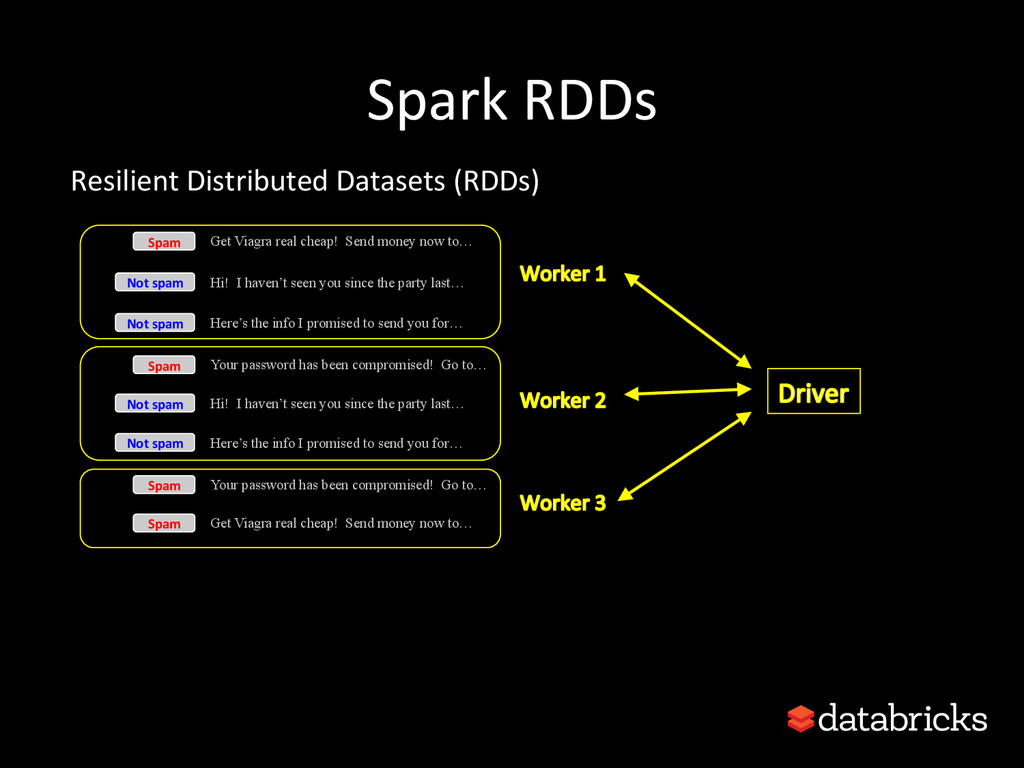
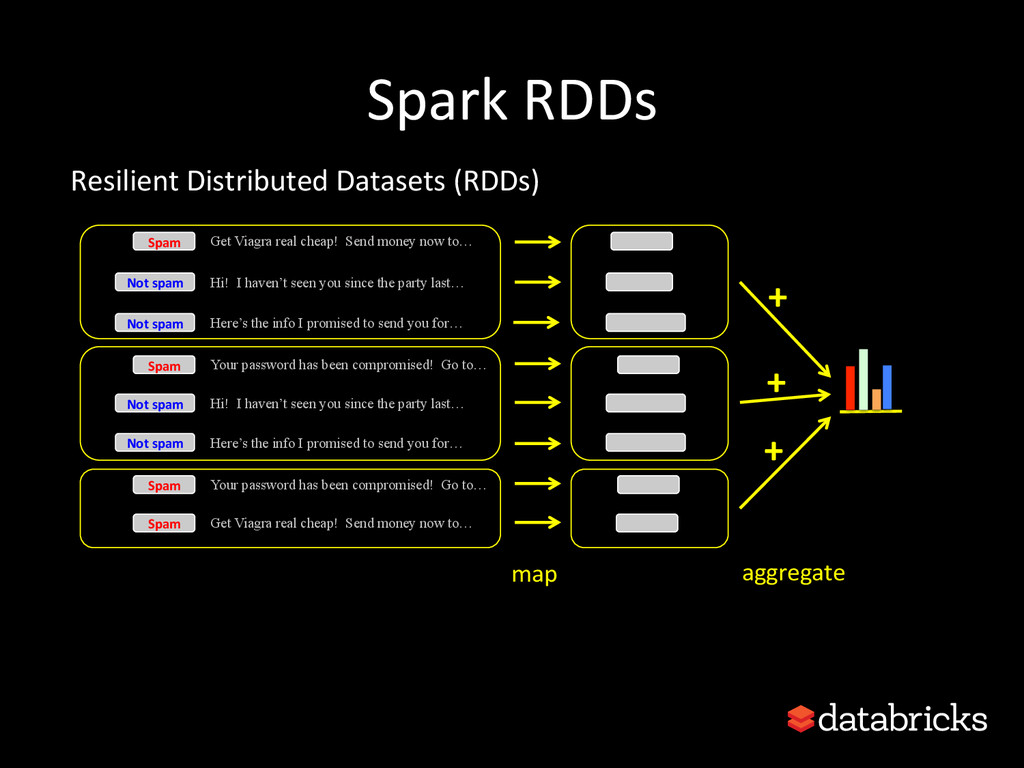
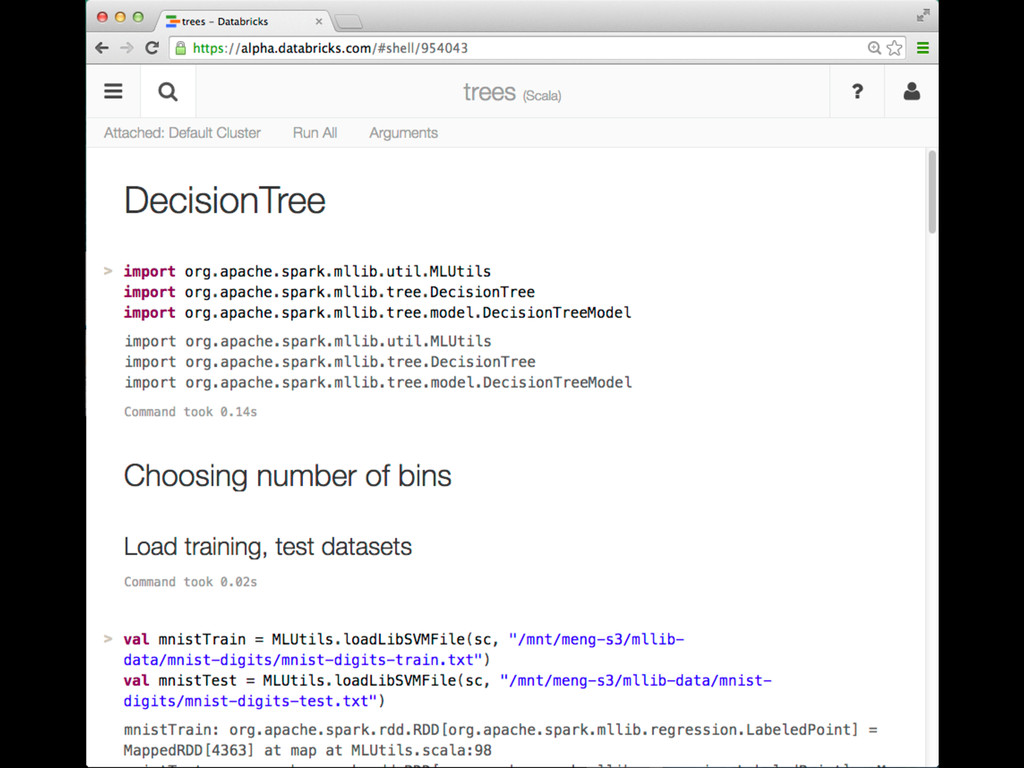
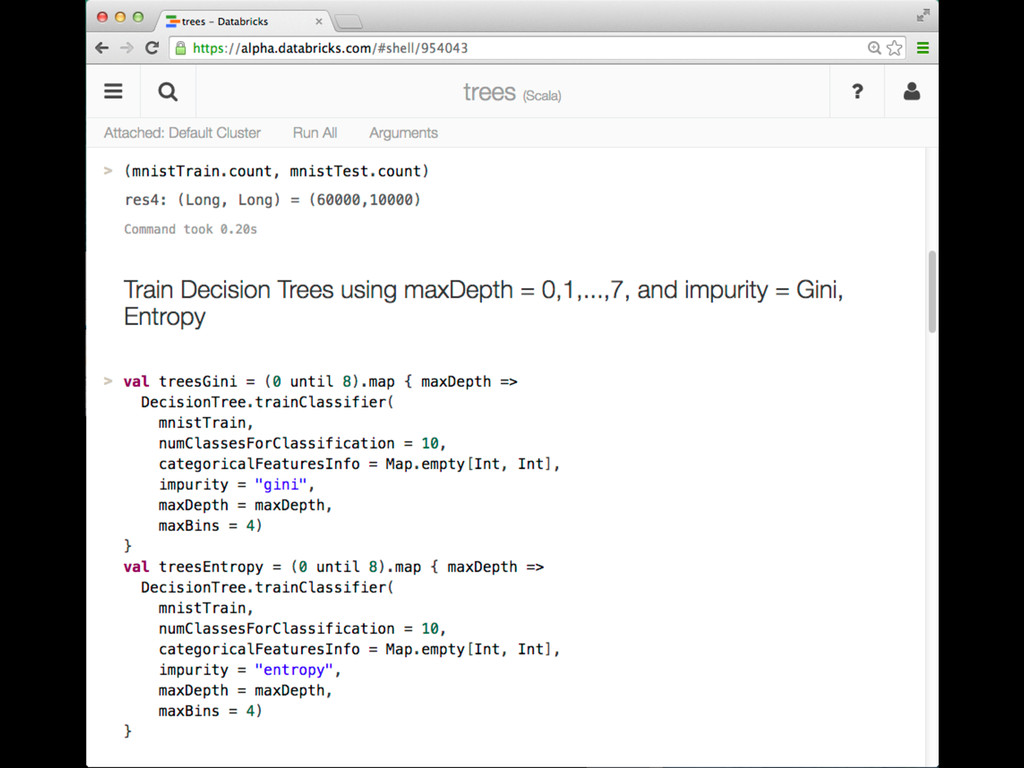
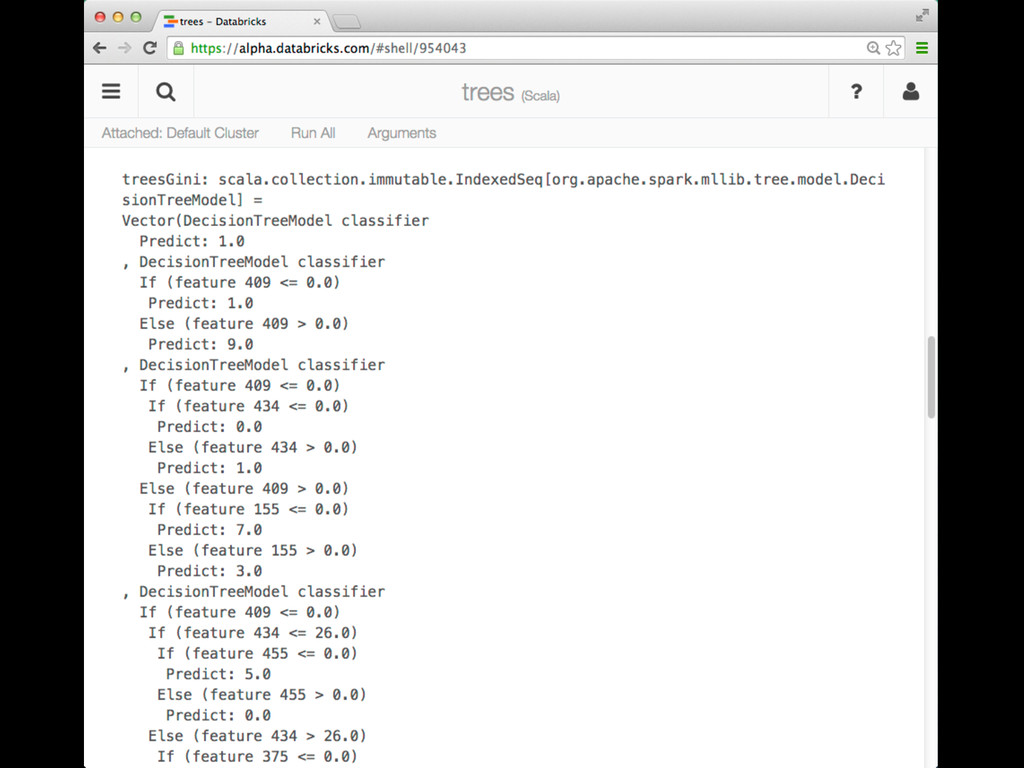
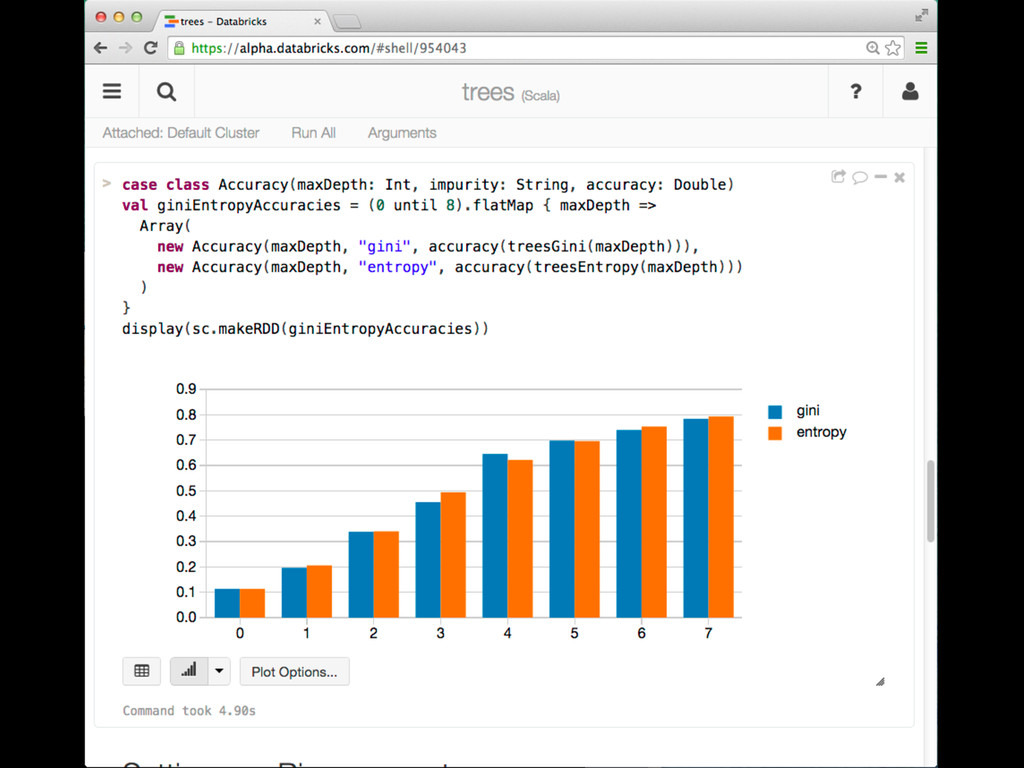
This talk discusses learning Decision Trees in a distributed computing cluster using MLlib, the machine learning library built on top of Spark. Decision trees are a powerful machine learning algorithm which are used in many applications. Spark is an open-source project for large-scale data analytics. This talk explains how trees are implemented on Spark, discusses how best to use MLlib trees in practice, and gives a number of examples.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
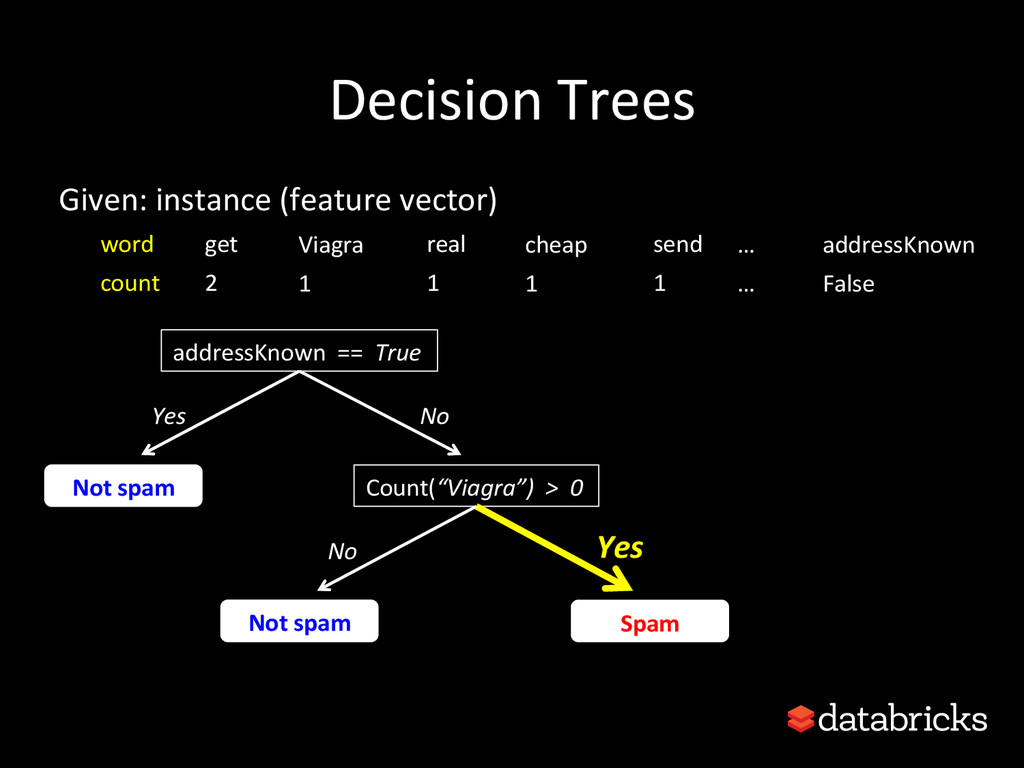{kind=link}
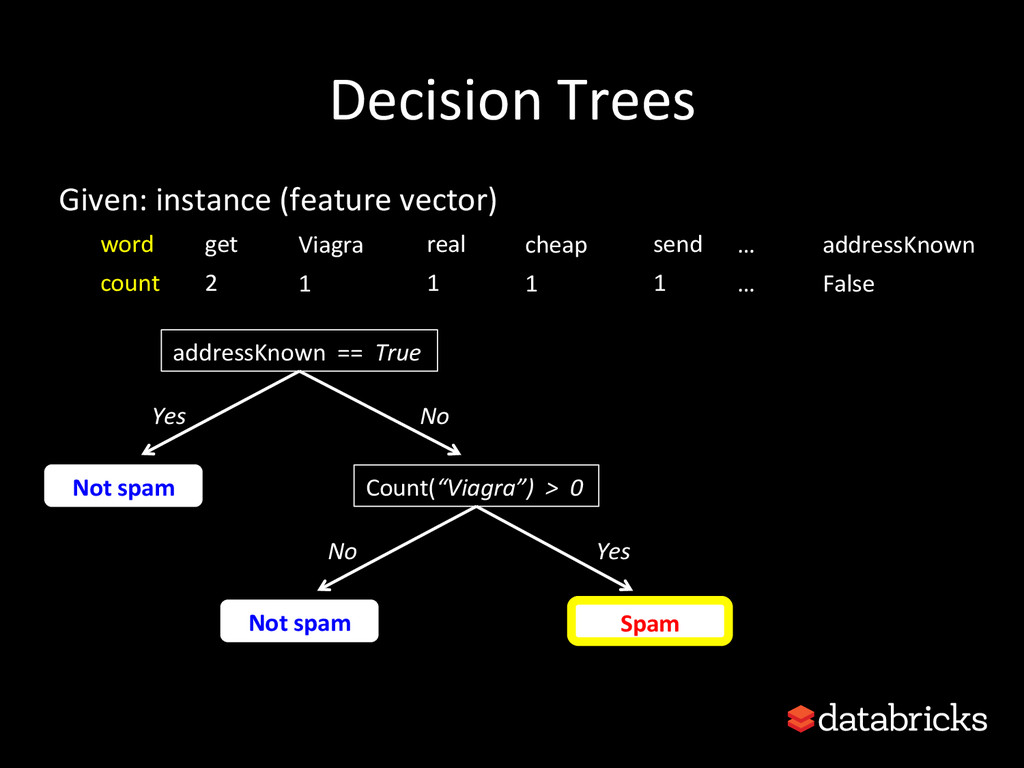{kind=link}
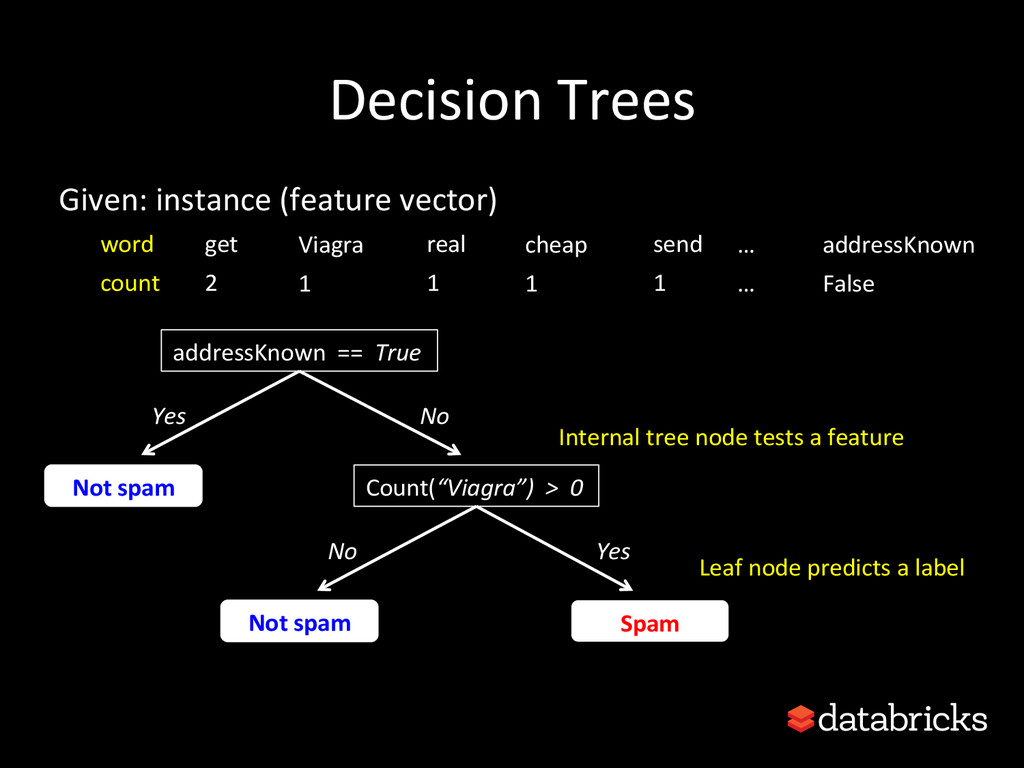{kind=link}
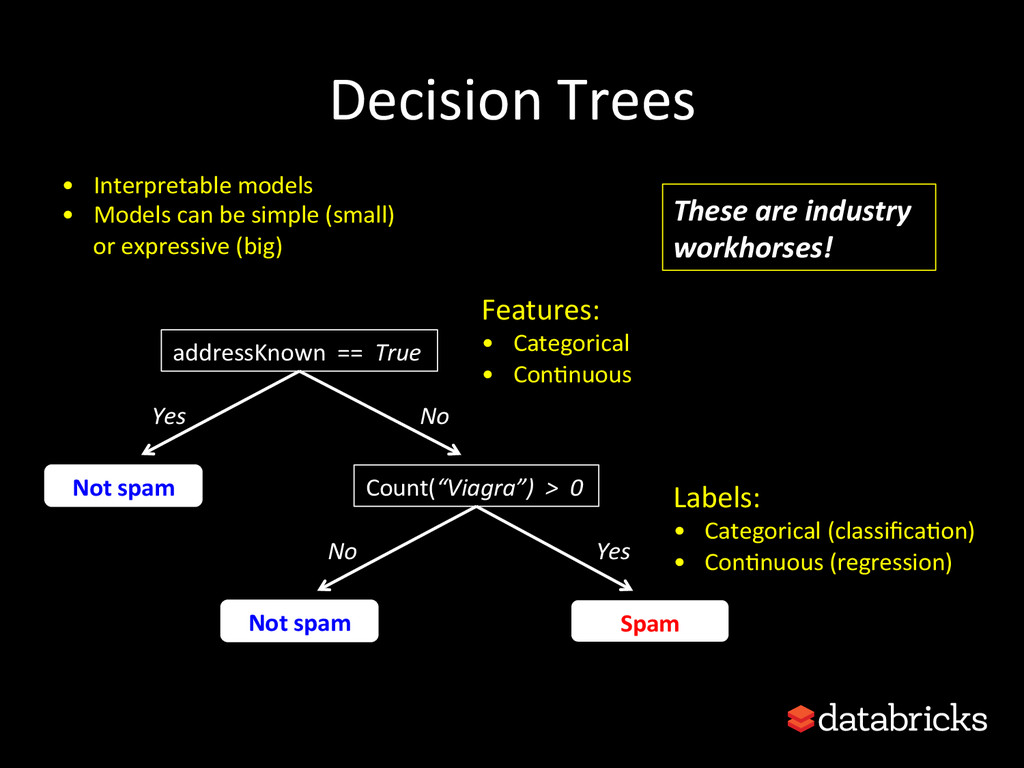{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
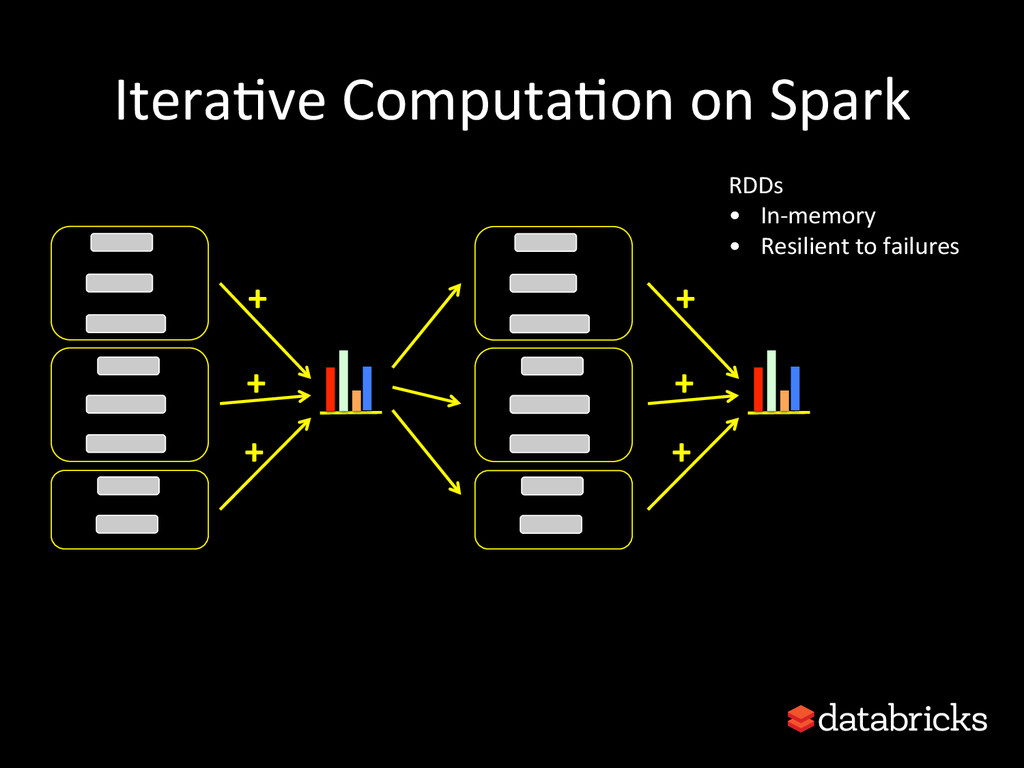{kind=link}
{kind=link}
{kind=link}
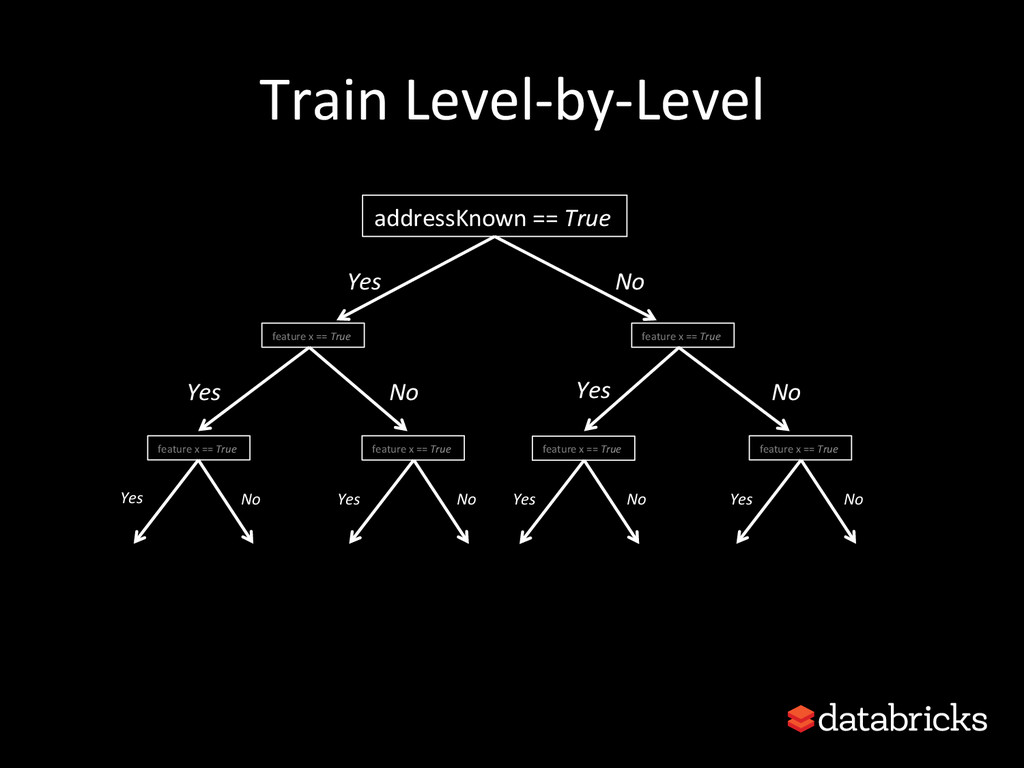{kind=link}
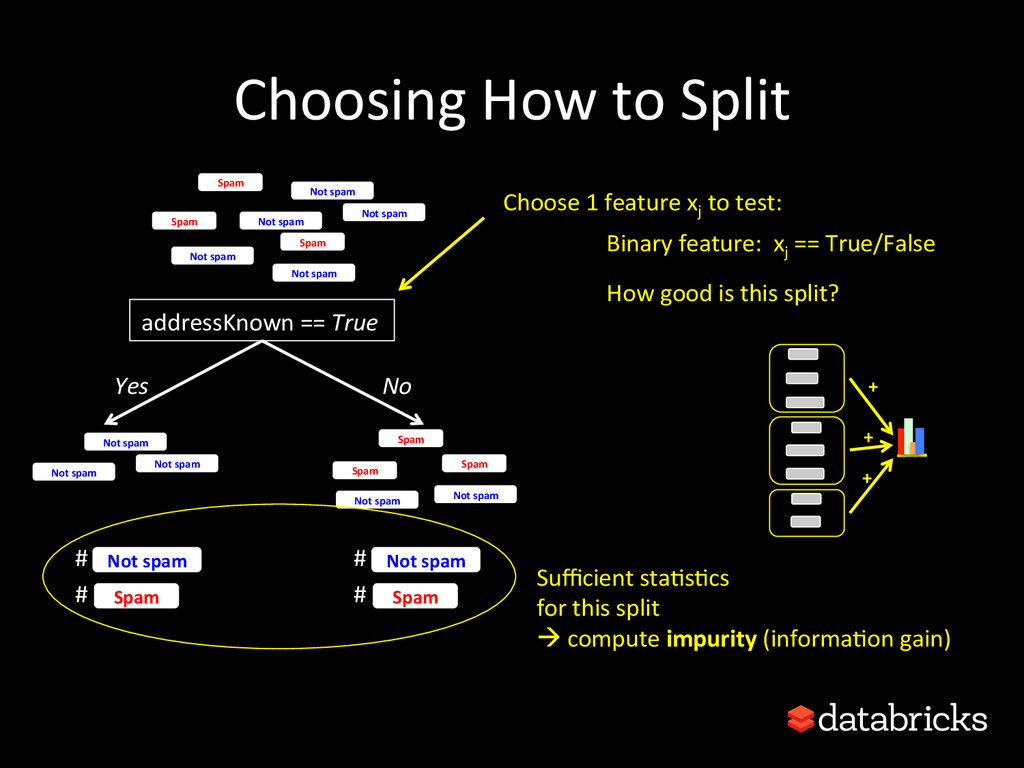{kind=link}
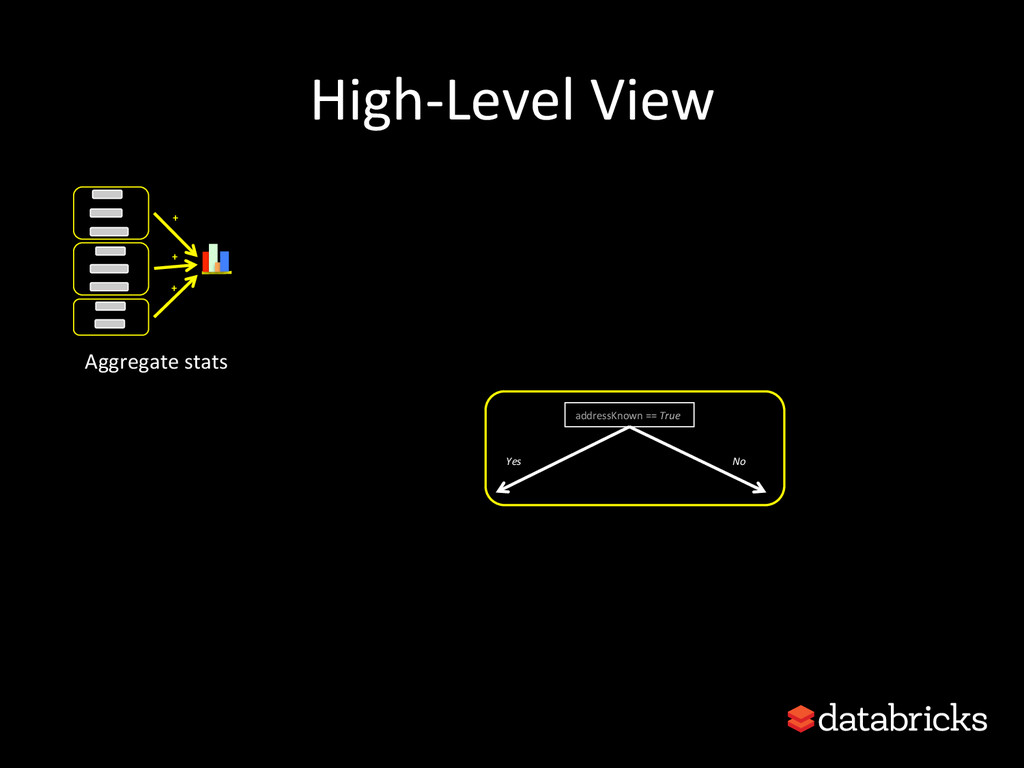{kind=link}
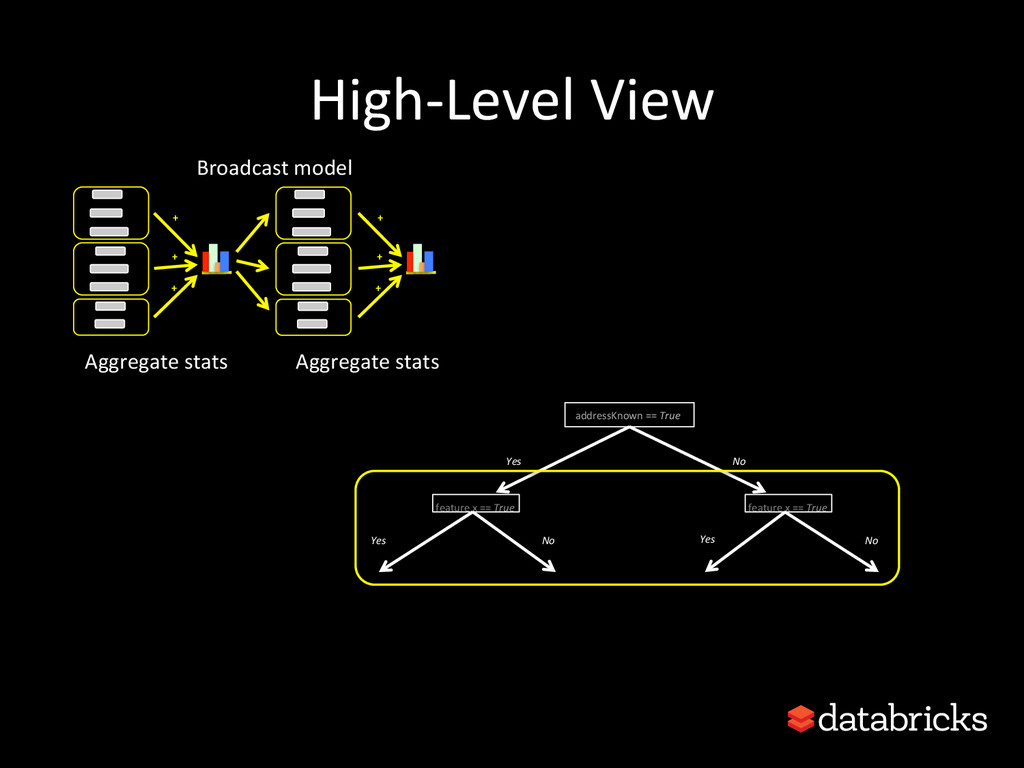{kind=link}
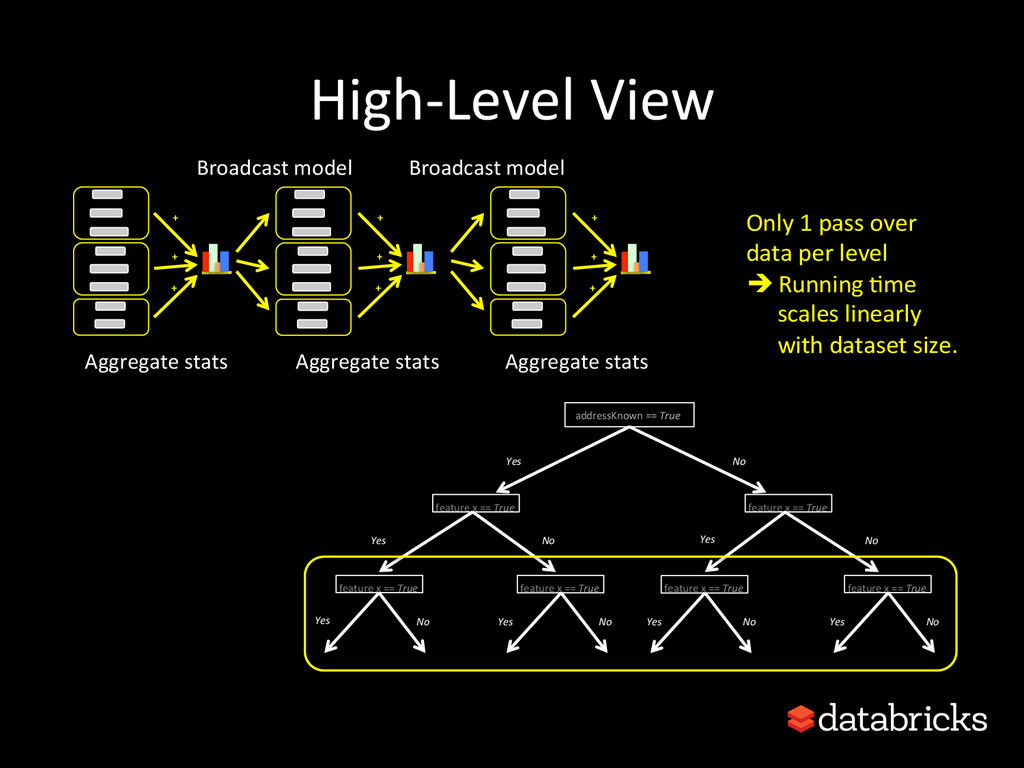{kind=link}
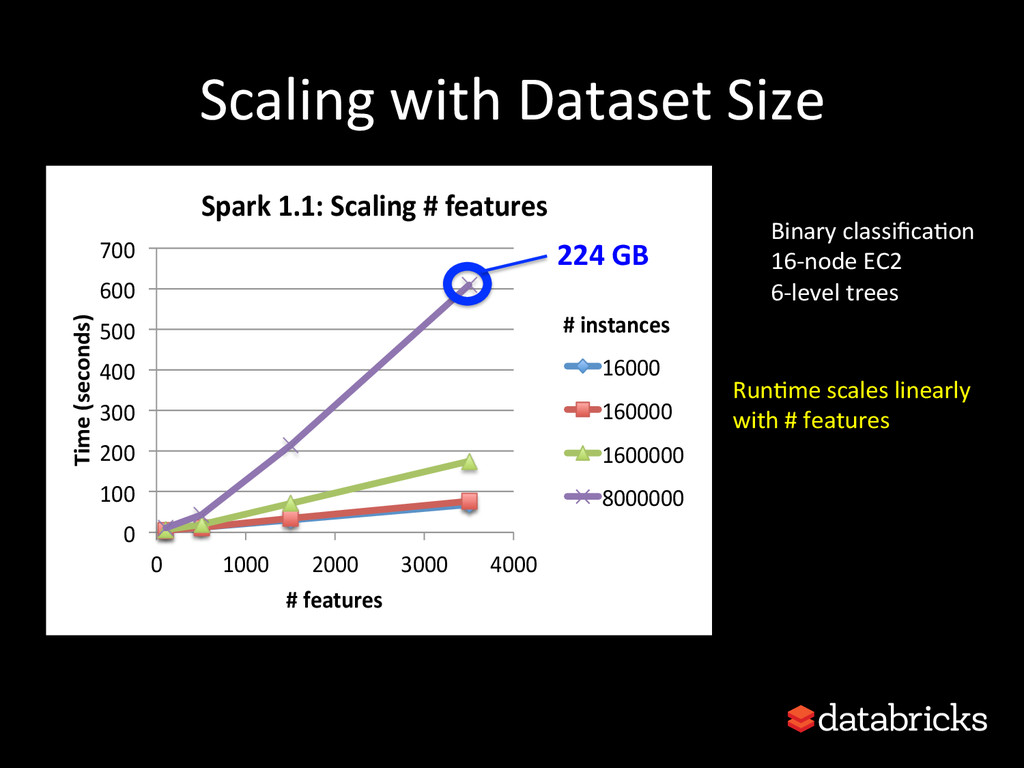{kind=link}
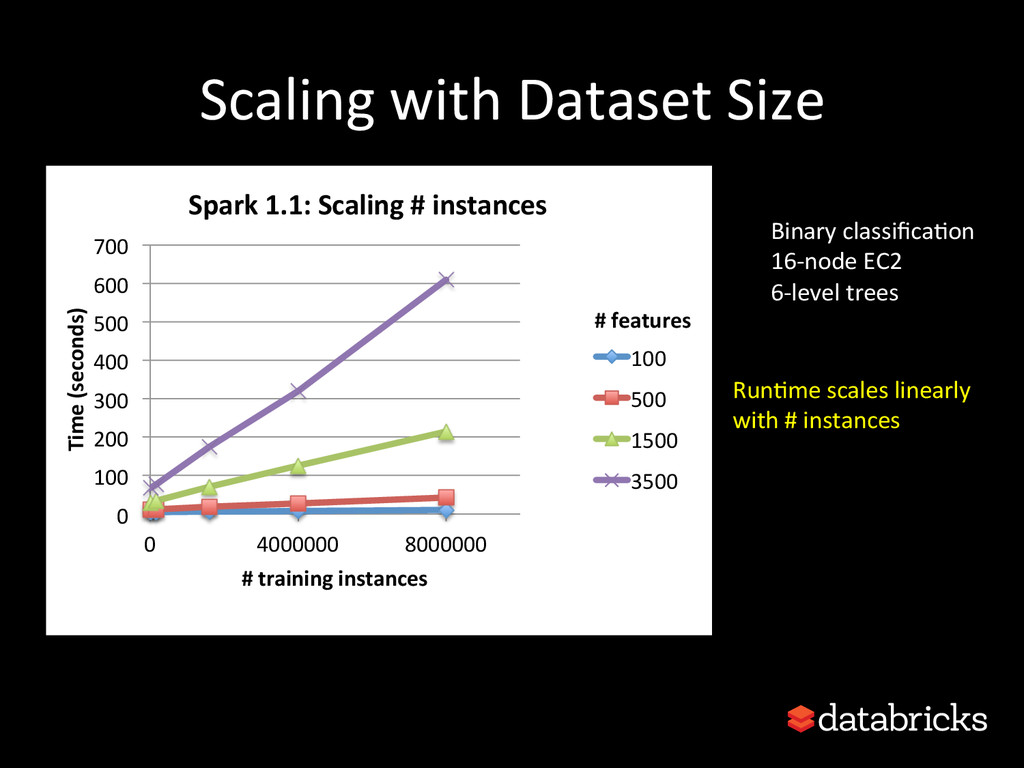{kind=link}
{kind=link}
{kind=link}
![MLlib Trees in Prac<ce def trainClassifier( input: RDD[LabeledPoint], numClassesForClassification:](https://files.speakerdeck.com/presentations/10644f30258c0132c818261770be6abf/slide_35.jpg){kind=link}
![MLlib Trees in Prac<ce def trainClassifier( input: RDD[LabeledPoint], numClassesForClassification:](https://files.speakerdeck.com/presentations/10644f30258c0132c818261770be6abf/slide_36.jpg){kind=link}
![MLlib Trees in Prac<ce def trainClassifier( input: RDD[LabeledPoint], numClassesForClassification:](https://files.speakerdeck.com/presentations/10644f30258c0132c818261770be6abf/slide_37.jpg){kind=link}
![MLlib Trees in Prac<ce def trainClassifier( input: RDD[LabeledPoint], numClassesForClassification:](https://files.speakerdeck.com/presentations/10644f30258c0132c818261770be6abf/slide_38.jpg){kind=link}
![MLlib Trees in Prac<ce def trainClassifier( input: RDD[LabeledPoint], numClassesForClassification:](https://files.speakerdeck.com/presentations/10644f30258c0132c818261770be6abf/slide_39.jpg){kind=link}
![MLlib Trees in Prac<ce def trainClassifier( input: RDD[LabeledPoint], numClassesForClassification:](https://files.speakerdeck.com/presentations/10644f30258c0132c818261770be6abf/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MLlib Trees in Prac<ce def trainClassifier( input: RDD[LabeledPoint], numClassesForClassification:](https://files.speakerdeck.com/presentations/10644f30258c0132c818261770be6abf/slide_46.jpg){kind=link}
![MLlib Trees in Prac<ce def trainClassifier( input: RDD[LabeledPoint], numClassesForClassification:](https://files.speakerdeck.com/presentations/10644f30258c0132c818261770be6abf/slide_47.jpg){kind=link}
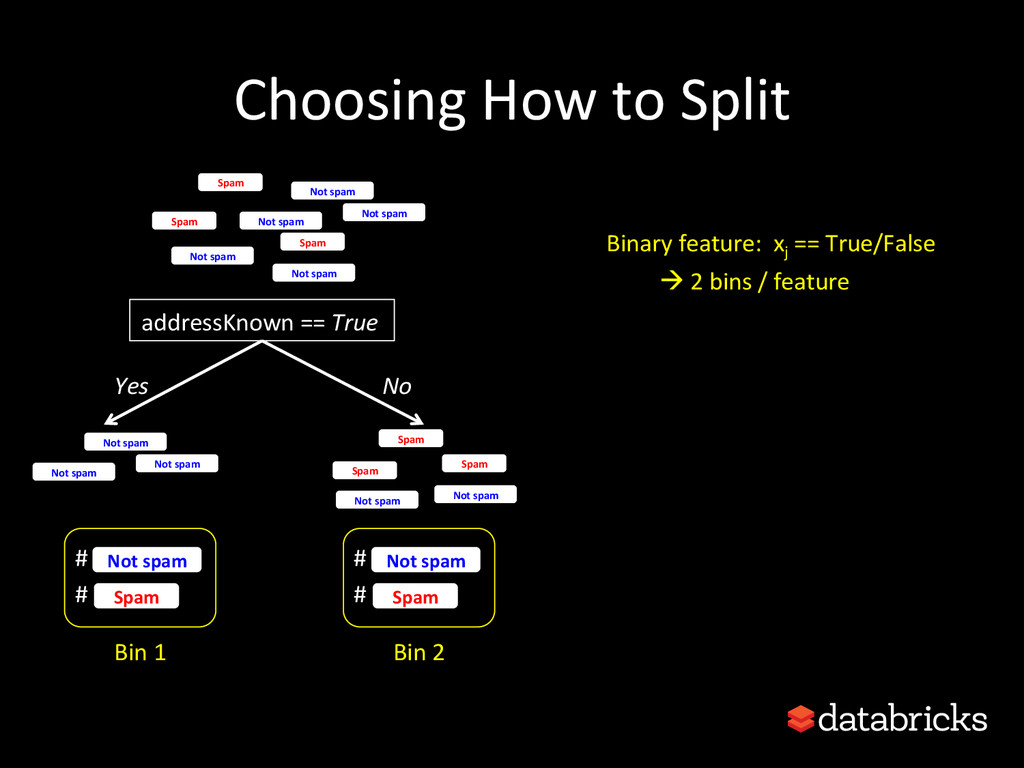{kind=link}
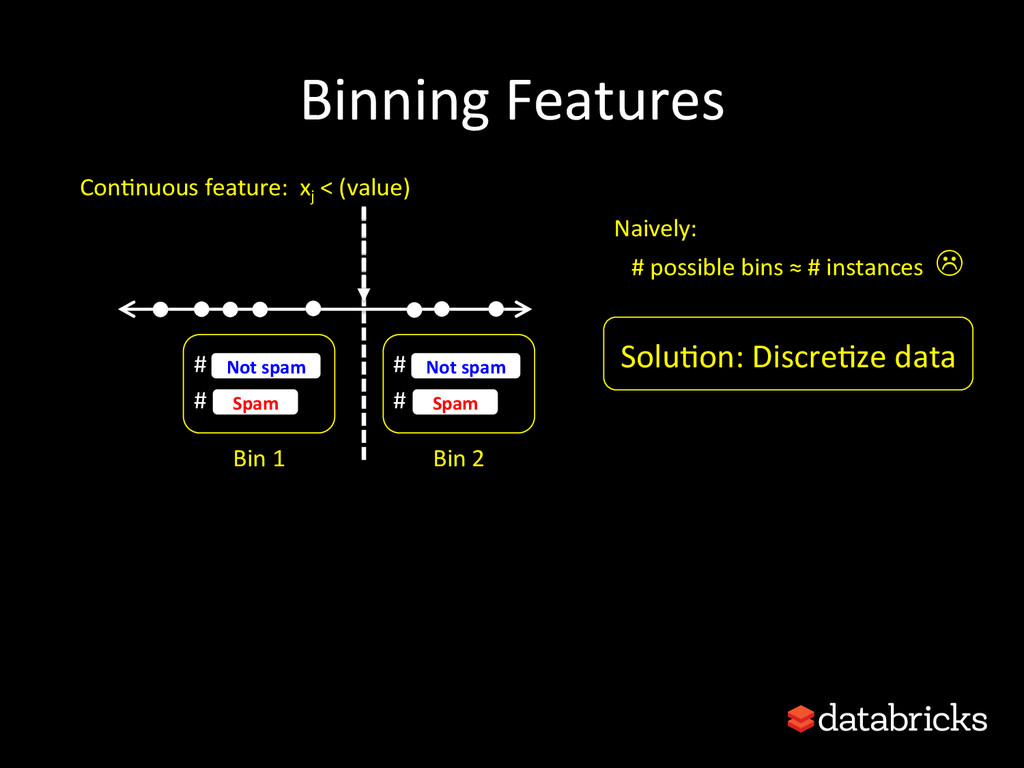{kind=link}
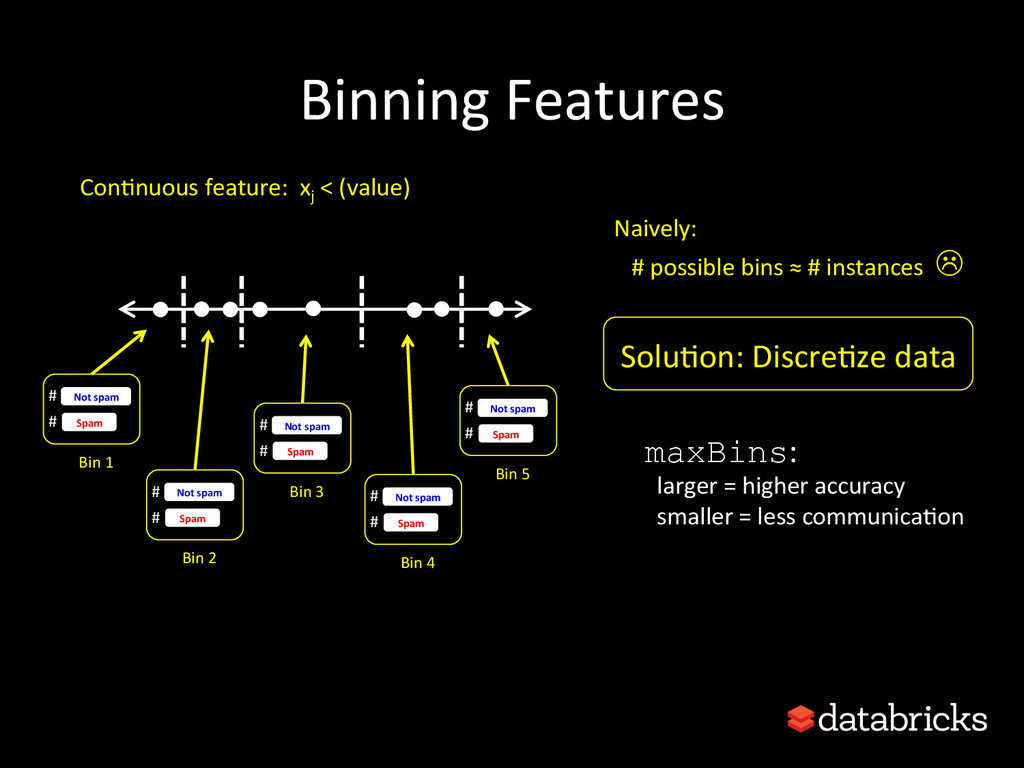{kind=link}
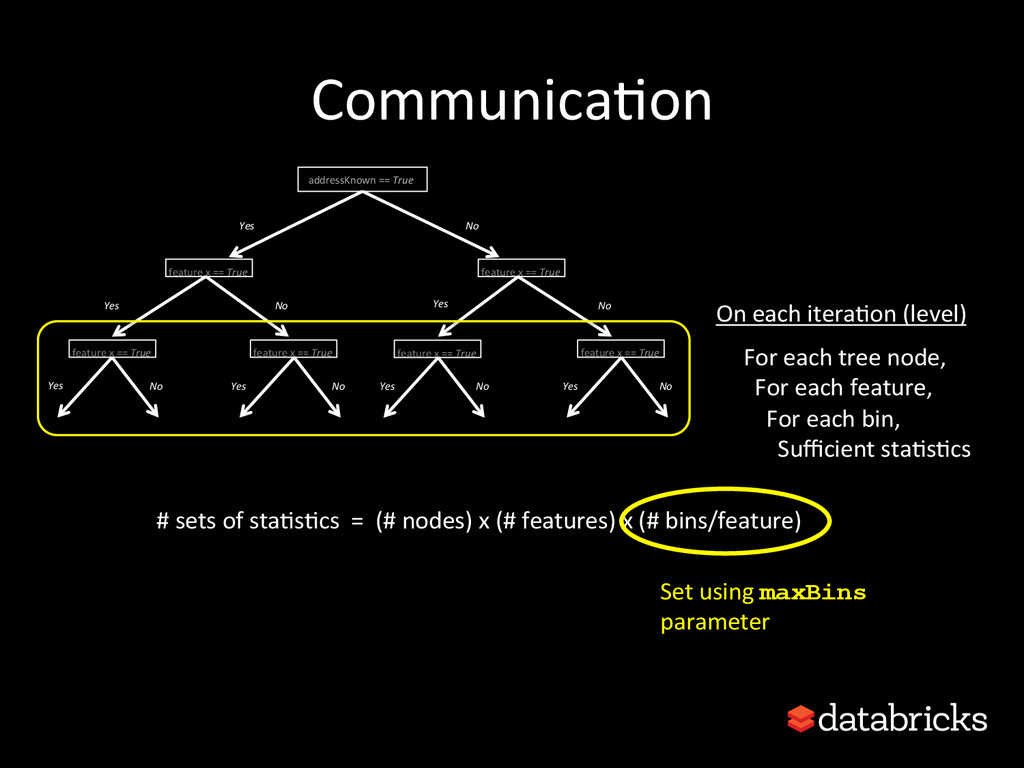{kind=link}
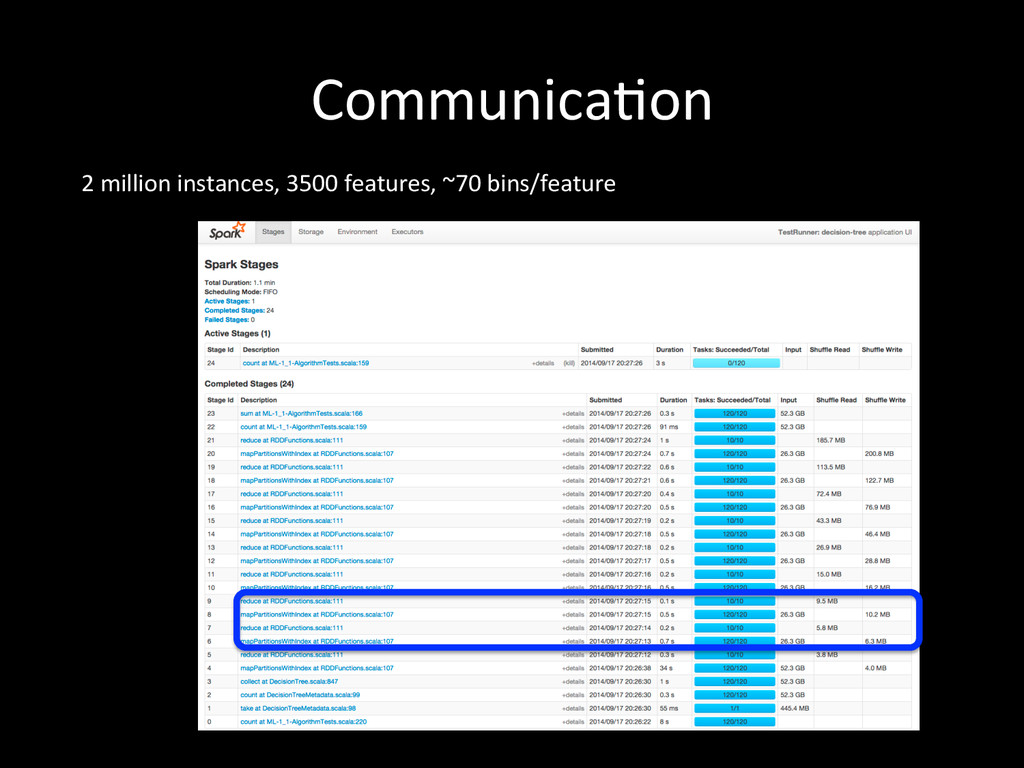{kind=link}
{kind=link}
{kind=link}
{kind=link}
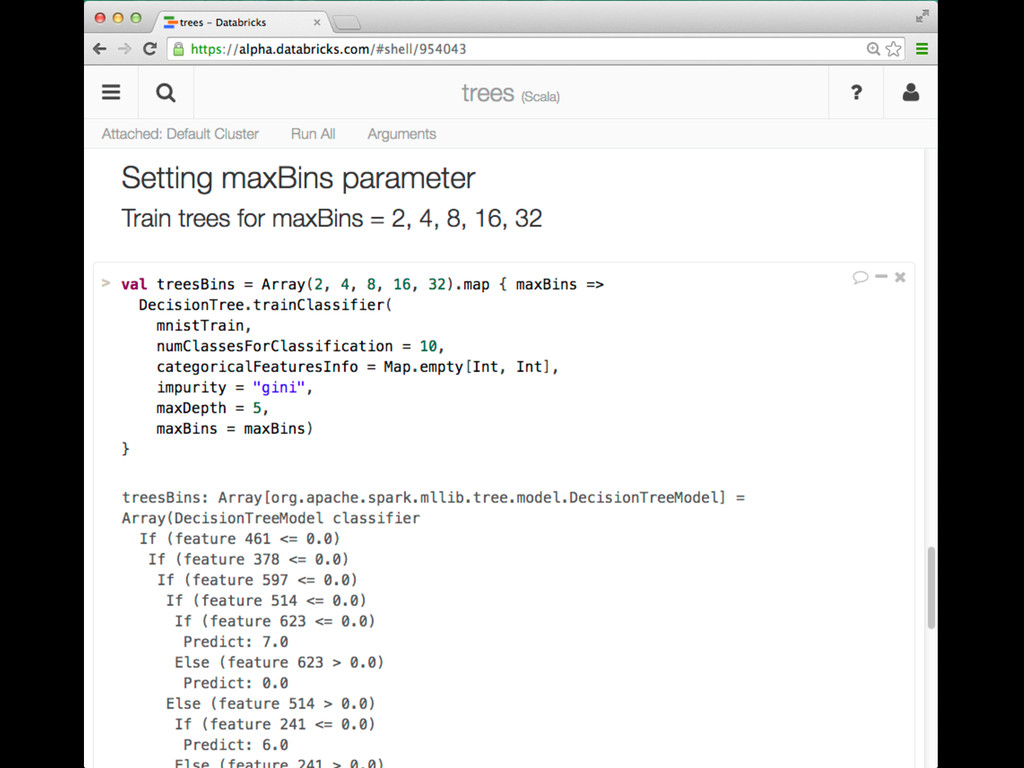{kind=link}
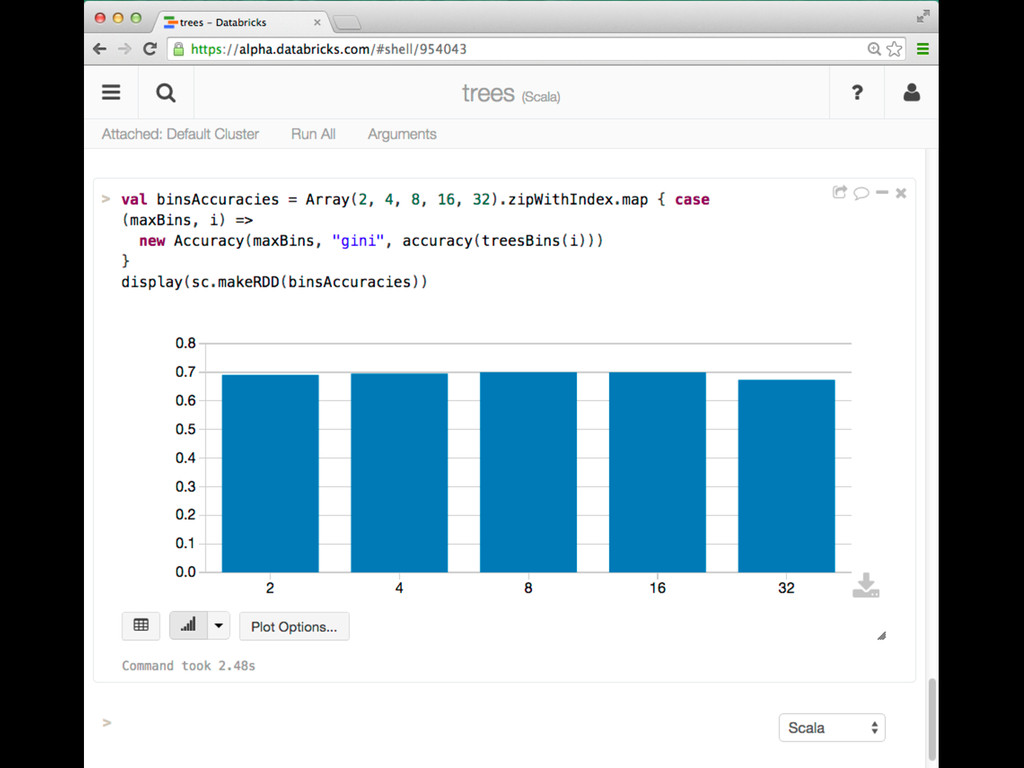{kind=link}
![MLlib Trees in Prac<ce def trainClassifier( input: RDD[LabeledPoint], numClassesForClassification:](https://files.speakerdeck.com/presentations/10644f30258c0132c818261770be6abf/slide_58.jpg){kind=link}
{kind=link}
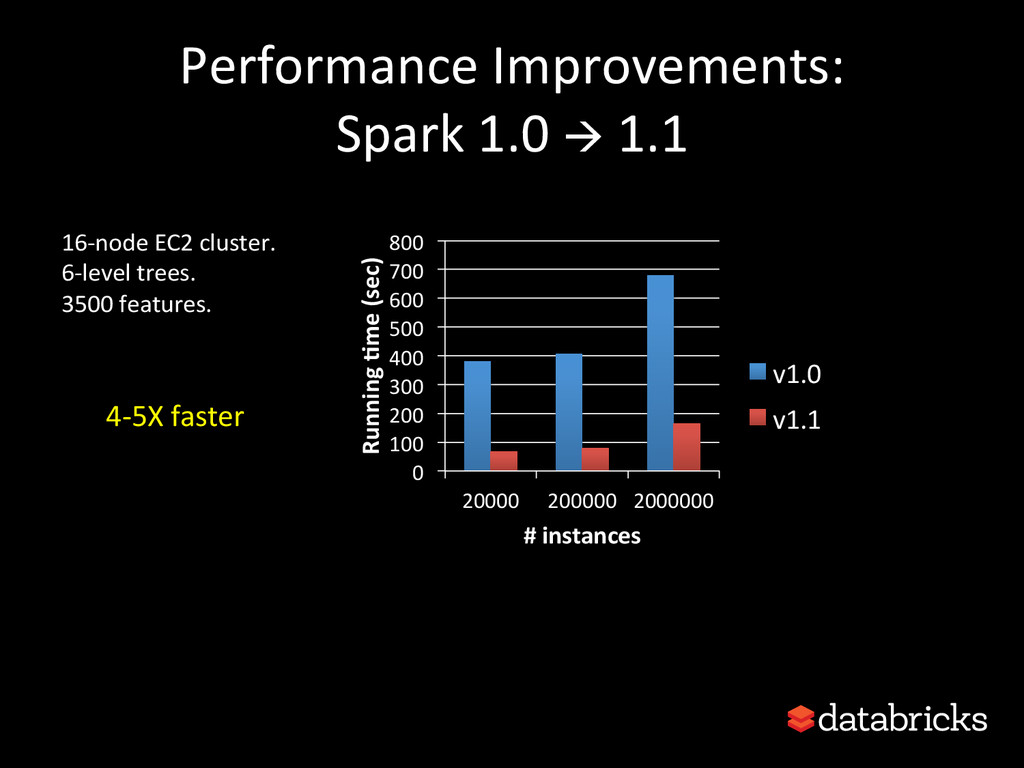{kind=link}
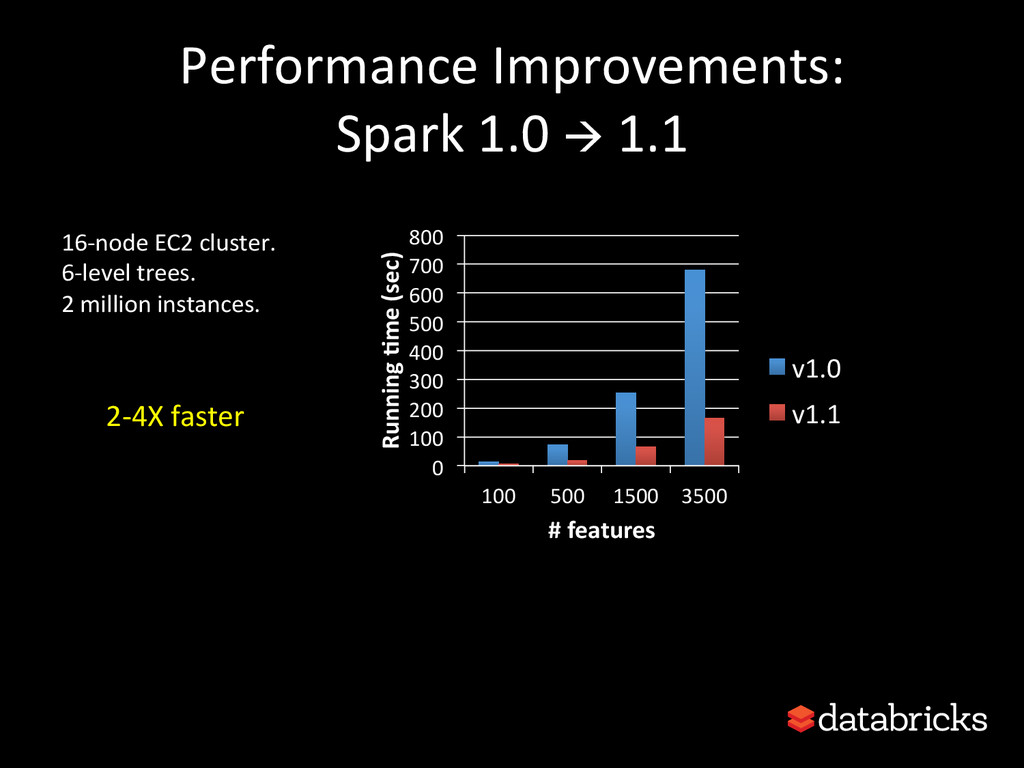{kind=link}
{kind=link}
{kind=link}
{kind=link}