Co-presenter: Mark Heckler
Different database technologies optimize for different uses. Graph databases excel in discovering relationships, known or unknown, within vast sets of data and can help unlock value from overlooked or underutilized sources. Join the presenters in this session to discover what consideration make a dataset a candidate for graph storage and analysis. You'll also learn tips and tricks for data ingestion and structuring while gaining insights on how to build APIs that optimize for meaningful analysis of data relationships. Likewise, you'll learn how to delegate tasks to tools, automate essential but non-critical path functions, and dominate your domain with actionable insights that unlock your data's full value.
![Jennifer Reif Email: [email protected] Twitter: @JMHReif LinkedIn: linkedin.com/in/jmhreif Github: github.com/JMHReif](https://files.speakerdeck.com/presentations/cd4442195bd941b3b84ecaa1a4184747/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
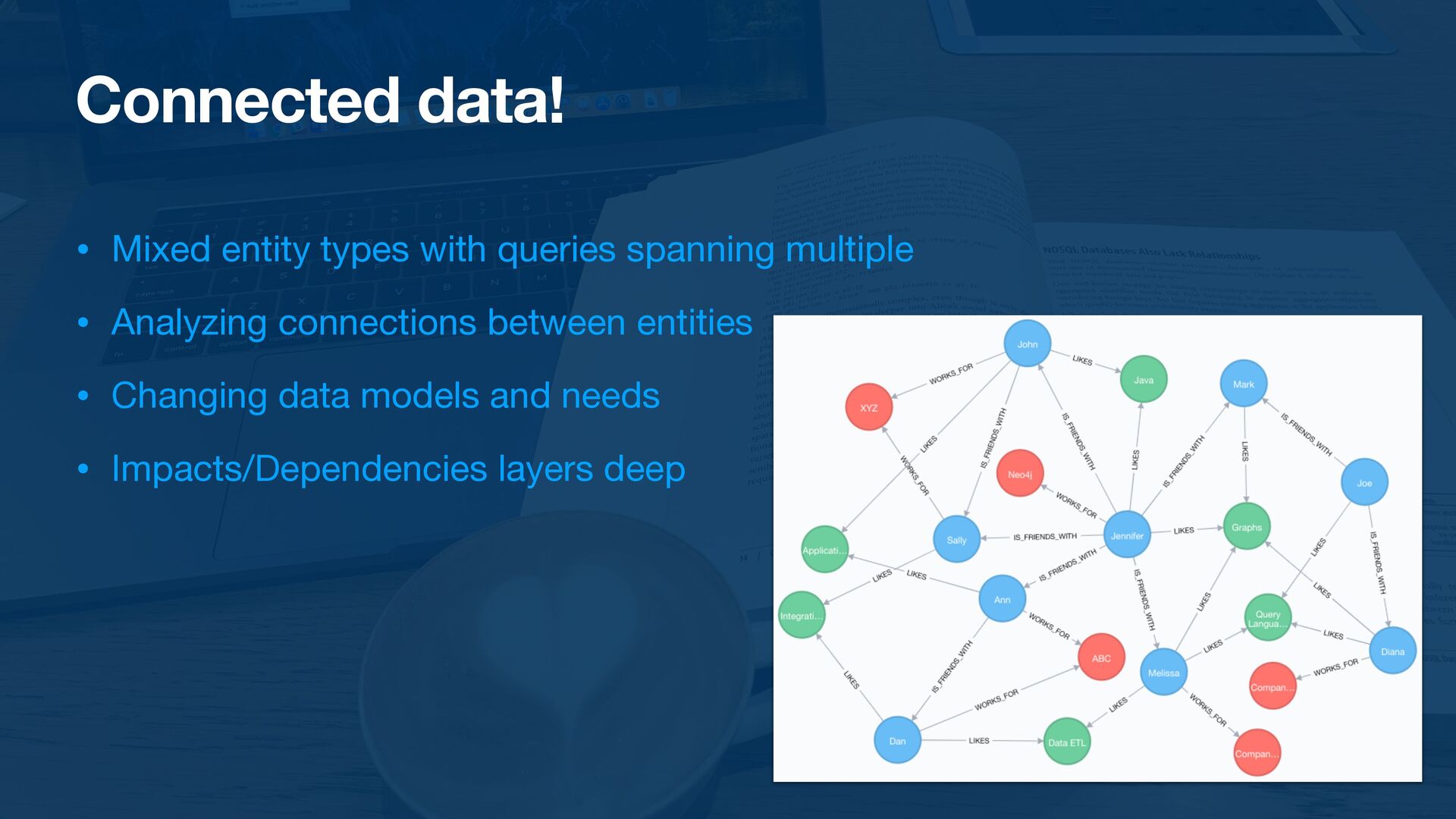{kind=link}
{kind=link}
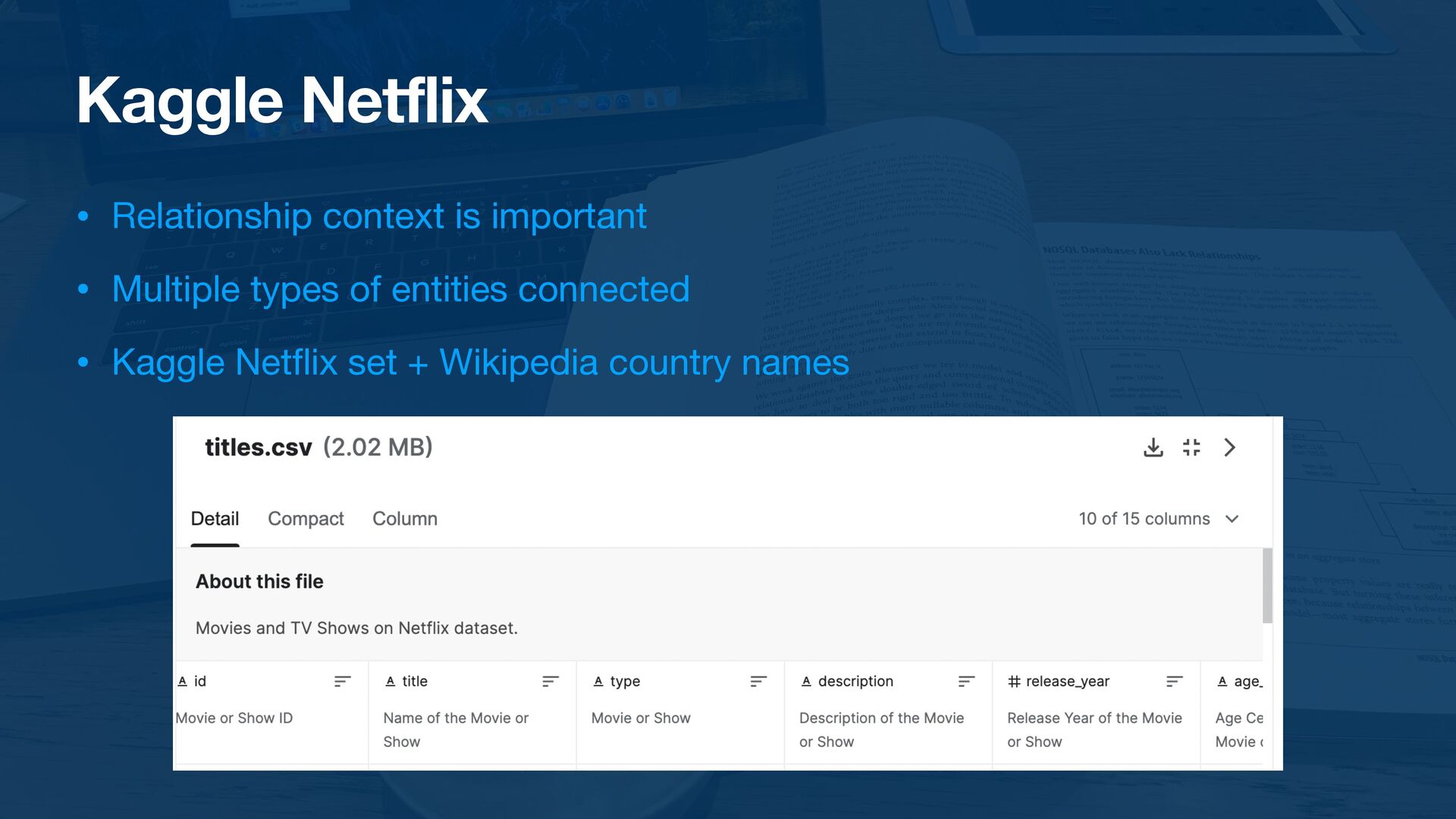{kind=link}
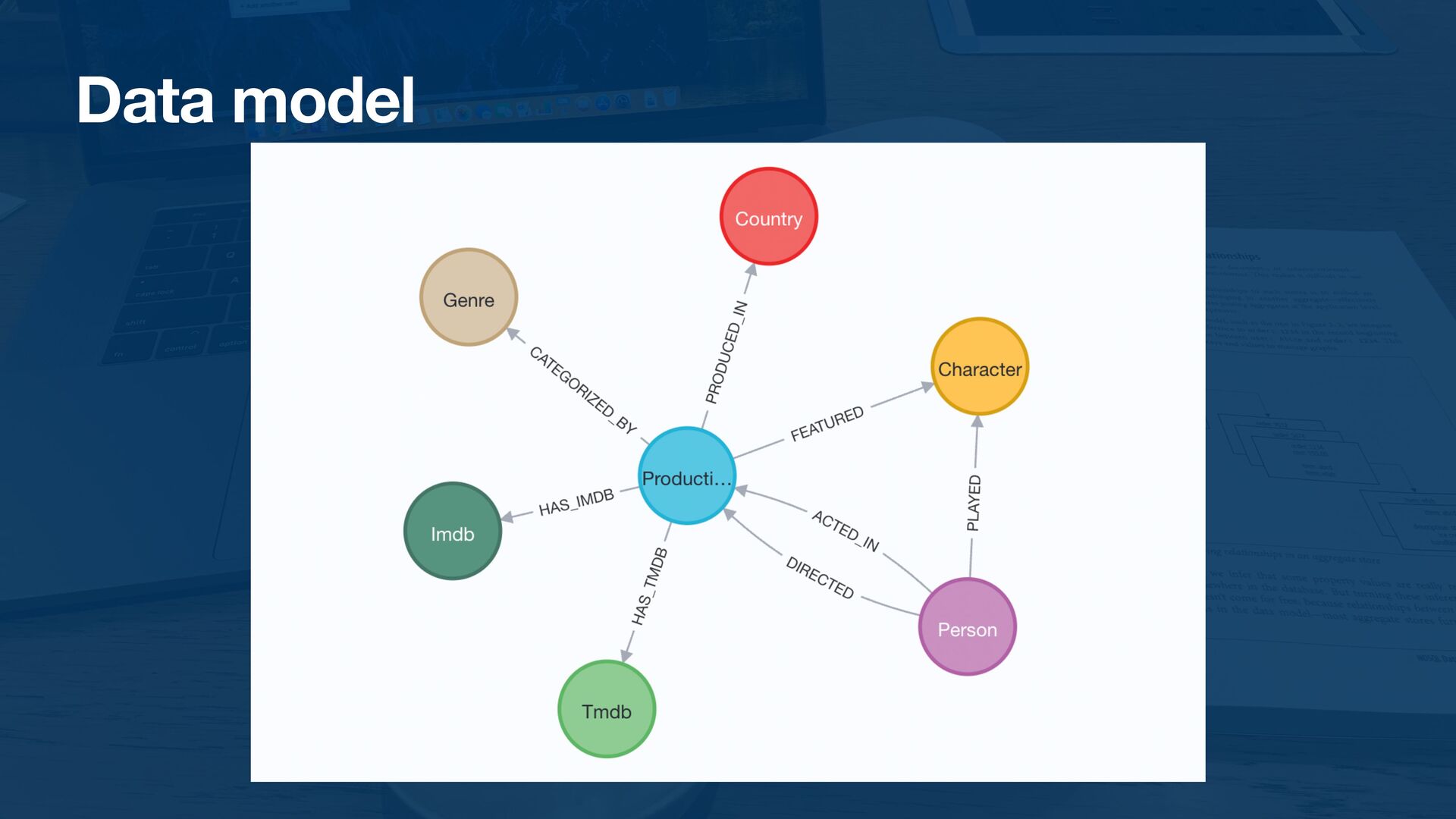{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}