Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2ちゃんねるを対象とした悪口表現の抽出
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
March 31, 2010
Research
480
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2ちゃんねるを対象とした悪口表現の抽出
石坂 達也, 山本 和英. 2ちゃんねるを対象とした悪口表現の抽出. 言語処理学会第16回年次大会, pp.178-181 (2010.3)
自然言語処理研究室
March 31, 2010
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
410
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
120
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.3k
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
2
310
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
200
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
3.8k
Harness Engineering and Al Agent
kzinmr
3
1.7k
正規分布と最適化について
koide3
1
260
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
350
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
320
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
410
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
380
LLM Compute Infrastructure Overview
karakurist
2
1.4k
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
200
Featured
See All Featured
Joys of Absence: A Defence of Solitary Play
codingconduct
1
400
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
160
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Marketing to machines
jonoalderson
1
5.5k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
420
Building the Perfect Custom Keyboard
takai
2
800
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
540
Raft: Consensus for Rubyists
vanstee
141
7.5k
Transcript
1 2ちゃんねるを対象とした 悪口表現の抽出 長岡技術科学大学 石坂達也 山本和英
2 背景 z Web上には他者を誹謗中傷する書き込みが存在 z 最悪の場合, 自殺のきっかけとなる 悪口書き込みはより厳重に管理されるべき 辞書を使用したフィルタリング 堅実な方法として…
3 悪口表現辞書の構築 今回 悪口表現抽出の手法を検討 目的 悪口表現の抽出が必須
4 z 他の情報を必要としない侮辱や誹謗中傷し ている単語,句 (例) ・あの政治家死ね ・奴らはバカな暇人野郎 悪口表現の定義
5 z 他の情報を必要としない侮辱や誹謗中傷し ている単語,句 (例) ・あの政治家死ね ・奴らはバカな暇人野郎 悪口表現の定義 皮肉は対象外
6 z 他の情報を必要としない侮辱や誹謗中傷し ている単語,句 (例) ・あの政治家死ね ・奴らはバカな暇人野郎 悪口表現の定義 「バカ」は悪口ではない場合がある (例)バカうまい
7 z 2ちゃんねるは多くの人が利用している z さらに, 悪口書き込みが多い 仮説 Web全体と2ちゃんねるでは 悪口表現の種類数 に大きな差はない
なぜ 「2ちゃんねる」なのか
8 問題点 と 基本方針 z 2ちゃんねるを対象にすることで生じる問題点 z 形態素解析器の解析ミス(単語の区切り、品詞情報) z 文の区切りが句点とは限らない
z 造語, 隠語が多い z 基本方針 z 品詞情報を無視 z 単語の過分割にも対応可能
9 手法の流れ 1. 悪口表現種辞書の構築 2. 悪口文の収集 3. 悪口n-gram モデルの作成 4.
悪口表現抽出
10 悪口表現種辞書の構築 z 人手で2ちゃんねるから悪口表現を抽出 z 103件 (例) z みんなまとめて逝け z
うざい z キモイ z ヲタは地獄に落ちろ
11 悪口文の収集 z 種辞書の登録表現を含む文(悪口文)を収集 z 毎日 約2000スレッドを解析 z 約20万文を収集できた (例)
z つか,官僚死ねや z 泥棒ゴミクズ団体はさっさと吊ってこい! z こんなんでイチイチ騒ぐなボケカス。
12 悪口n-gram モデルの作成 1/2 z 悪口文と非悪口文からモデルを作成 z 悪口文を約20万文, 非悪口文を約50万文 z
単語n-gram z 1~5-gram z 前向きと後ろ向きn-gramの2パターン z SRILMを使用 z 悪口表現を持つn-gramを抽出
13 悪口n-gram モデルの作成 2/2 - 前処理 - z 悪口表現は1語に合成、汎化 (例)
男 って バカ な 暇人 野郎 ばっか 男 って <悪口> ばっか z 単語は原形にして扱う
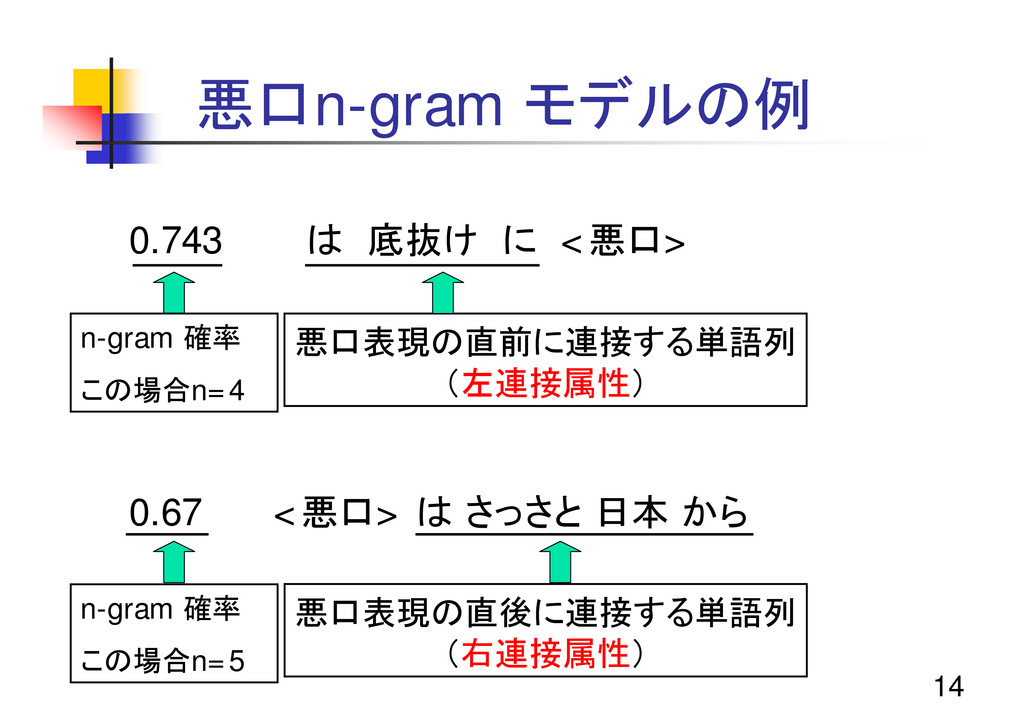
14 悪口n-gram モデルの例 0.743 は 底抜け に <悪口> 0.67 <悪口>
は さっさと 日本 から n-gram 確率 この場合n=4 悪口表現の直前に連接する単語列 (左連接属性) n-gram 確率 この場合n=5 悪口表現の直後に連接する単語列 (右連接属性)
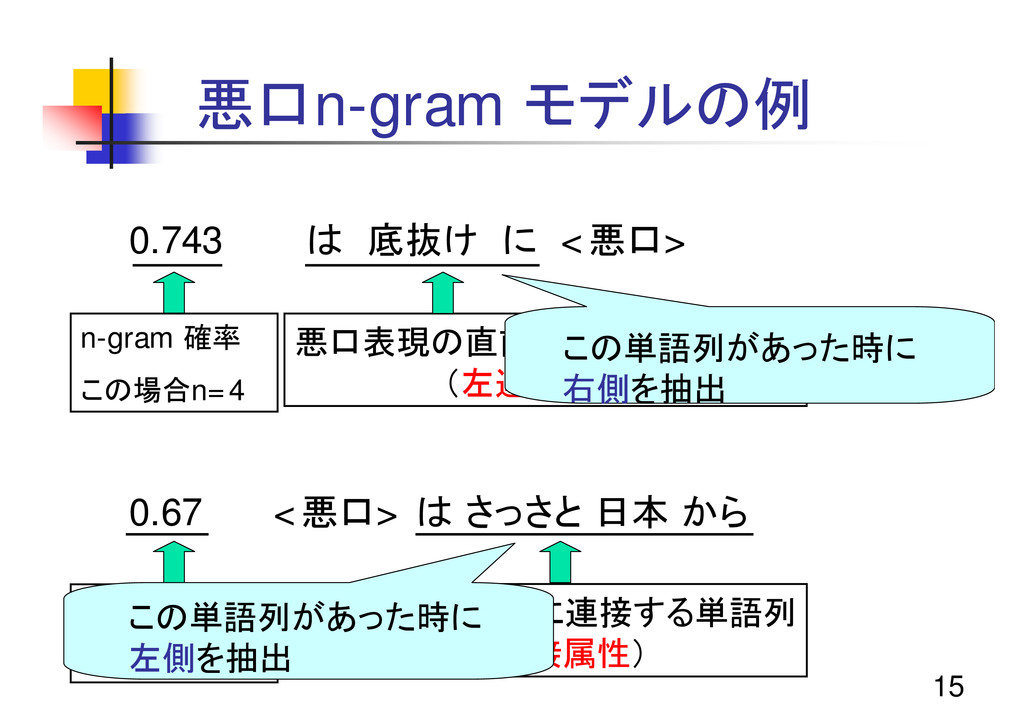
15 悪口n-gram モデルの例 0.743 は 底抜け に <悪口> 0.67 <悪口>
は さっさと 日本 から n-gram 確率 この場合n=4 悪口表現の直前に連接する単語列 (左連接属性) n-gram 確率 この場合n=5 悪口表現の直後に連接する単語列 (右連接属性) この単語列があった時に 右側を抽出 この単語列があった時に 左側を抽出
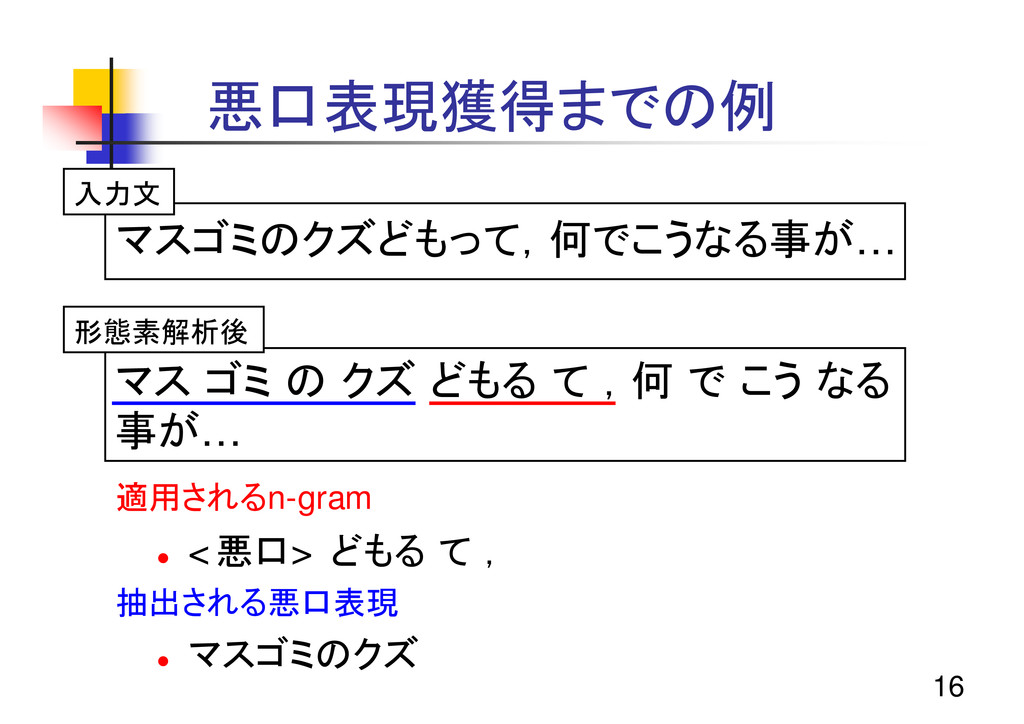
16 マス ゴミ の クズ どもる て ,何 で こう
なる 事が… 悪口表現獲得までの例 マスゴミのクズどもって,何でこうなる事が… 適用されるn-gram z <悪口> どもる て , 抽出される悪口表現 z マスゴミのクズ 入力文 形態素解析後
17 評価実験 z 評価セット z 悪口文378文, 非悪口文382文 z 評価方法 z
抽出された文字列を人手で悪口表現か評価 z 実験条件 z n-gram確率を閾値
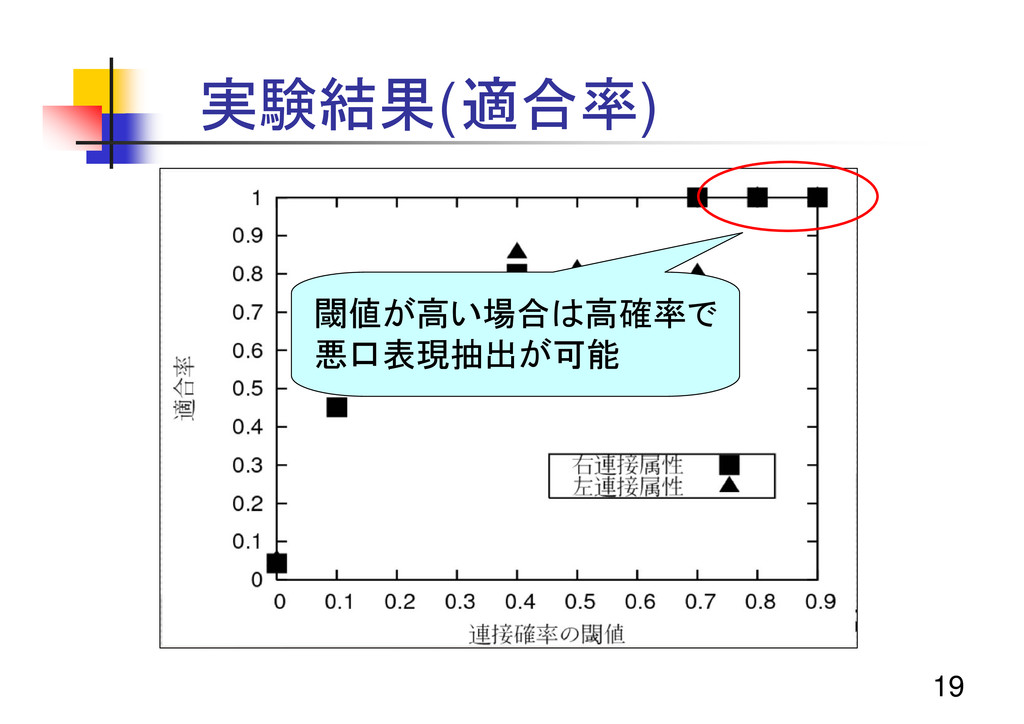
18 実験結果(適合率)
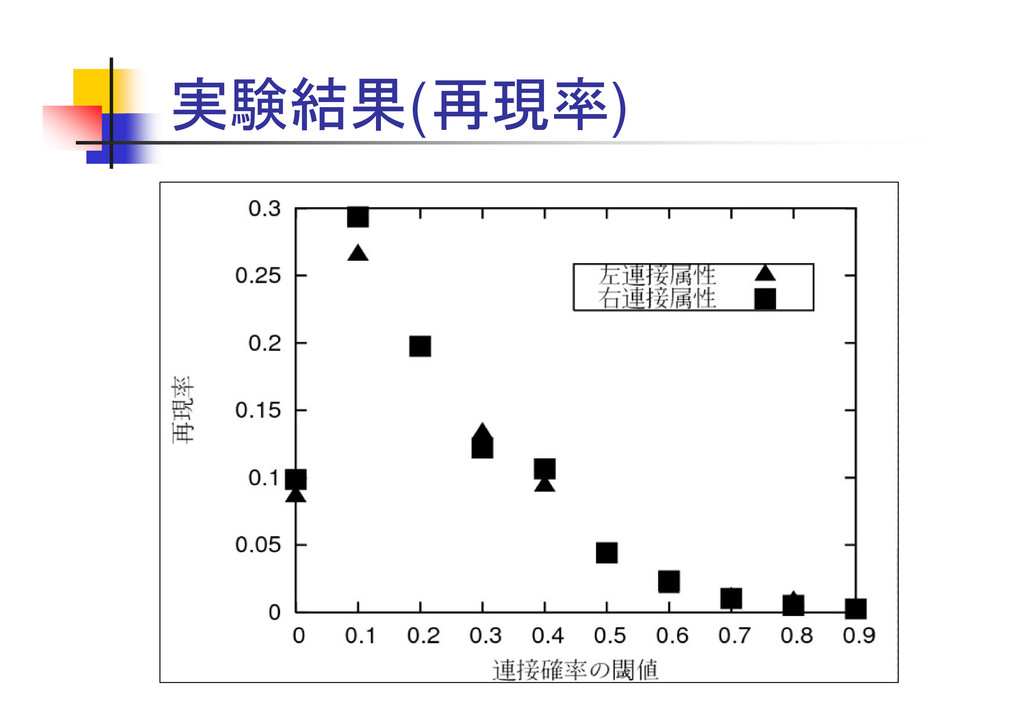
19 実験結果(適合率) 閾値が高い場合は高確率で 悪口表現抽出が可能
20 実験結果(適合率) 閾値が高い場合は高確率で 悪口表現抽出が可能 しかし、3件 閾値を下げても再現率は最高で0.3
21 考察:適合率と再現率 z 悪口表現のみに連接しやすい単語列は少ない (定型的に存在するわけではない) より悪口表現の特徴に適した指標も必要
22 新しい悪口表現の獲得数 辞書の拡張のためには新しい悪口表現の 獲得が必要 今回の手法でいくつ獲得できているか 予備実験
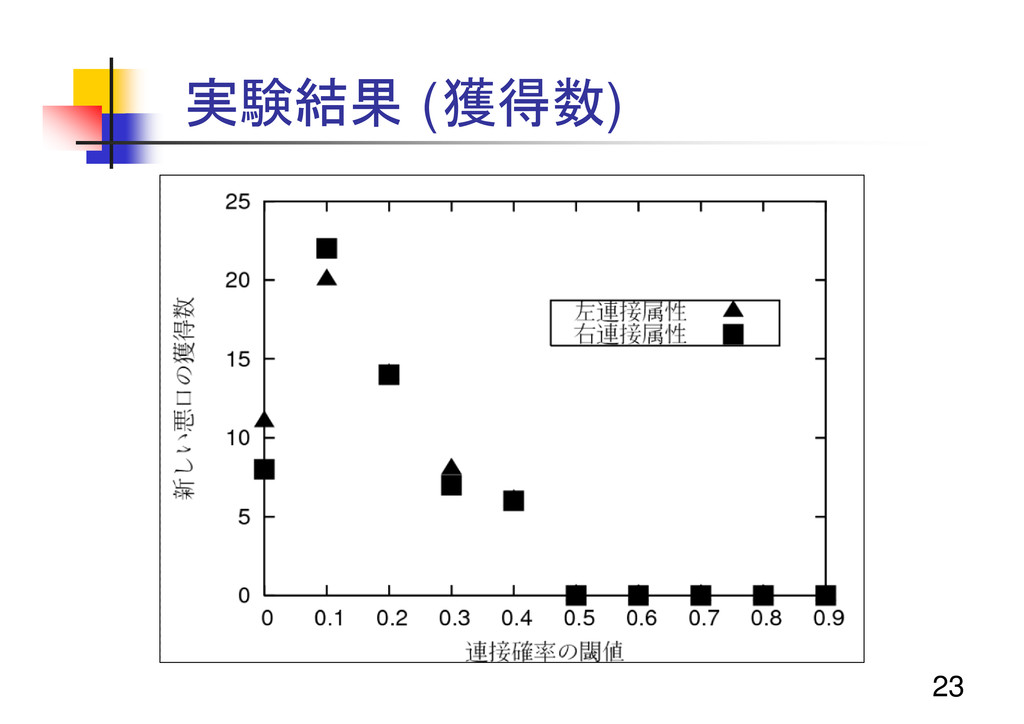
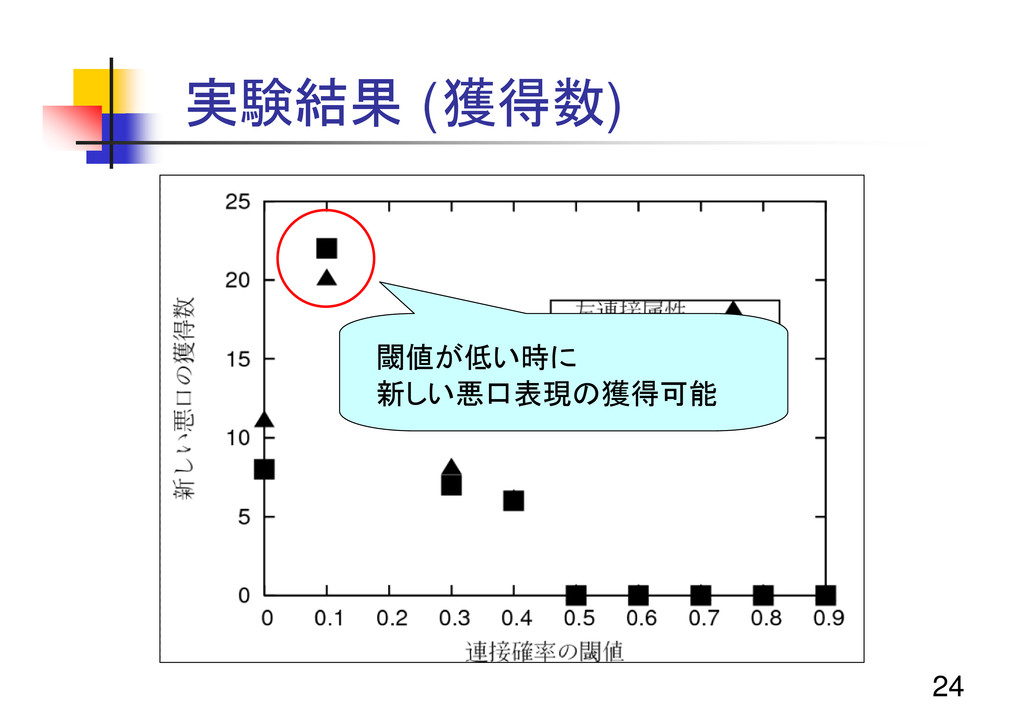
23 実験結果 (獲得数)
24 実験結果 (獲得数) 閾値が低い時に 新しい悪口表現の獲得可能
25 獲得した悪口表現 z キモオタロリコン z 消えてしまえ,馬鹿 z デブ婆ァ z スタイル悪い
z カス芸人 z 馬鹿男女
26 考察:新しい悪口表現の獲得 z 閾値が低い場合に, 新しい悪口表現の獲得 z 閾値が低い場合は非悪口表現も多く獲得 z 同じ単語を使用する悪口表現を多く獲得 (例)
糞◦◦ 糞ガキ, 糞ゲー 同じ単語を使用する造語の獲得には有効
27 まとめ z n-gram確率で悪口表現を抽出する手法を検討 z 閾値が高い場合に高確率で抽出可能 z 種辞書にない表現も獲得可能
28 ご清聴有難うございました
実験結果(再現率)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}