Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データベースと応用システム:情報検索
Search
自然言語処理研究室
July 11, 2014
Education
2.7k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データベースと応用システム:情報検索
自然言語処理研究室
July 11, 2014
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Education
See All in Education
【セーフィー】テクニカルライティング&コミュニケーション実践講座(26新卒エンジニア向け研修資料)
ymzaki_m4
0
260
Gitがない時代 インターネットがない時代の 開発話
sapi_kawahara
0
320
[2026前期火5] 論理学(京都大学文学部 前期 第10回)「論理学の哲学——意味とは何か(Tonkと推論主義)」
yatabe
0
180
参加制約理論
roadofhope
0
130
「機械学習と因果推論」入門 ③ 漸近効率な推定量と二重機械学習
masakat0
0
740
Data Physicalisation - Lecture 9 - Next Generation User Interfaces (4018166FNR)
signer
PRO
1
1.1k
Lectura 1 (PIT : Python Basico)
robintux
0
380
コミュニティを通じた_キャリア設計のススメ_20260424.pdf
masakiokuda
0
350
AIには考えられないことを考えられる人になるために
iqbocchi
1
200
[2026前期火5] 論理学(京都大学文学部 前期 第9回)「正規化の停止性——ヒドラゲームによる証明」
yatabe
0
170
0513
cbtlibrary
0
210
We部コミュニティスライド2026-04-24
junhat6
0
190
Featured
See All Featured
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Utilizing Notion as your number one productivity tool
mfonobong
4
360
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
The browser strikes back
jonoalderson
0
1.4k
Transcript
(c)長岡技術科学大学 電気系 1 データベースと応用システム 情報検索 山本和英 長岡技術科学大学 電気系
(c)長岡技術科学大学 電気系 2 情報検索とは • Information Retrieval, IR • 広義では「ユーザの持つ問題(情報要求)を解決
できる情報を見つけ出すこと」 • 狭義では「ユーザの検索質問に適合する文書を (大量の)文書中から見つけ出すこと」
(c)長岡技術科学大学 電気系 3 情報検索の歴史 • 情報検索は図書館の蔵書・文書検索が起源であ り、図書館学として研究が進められてきた。 • 科学技術分野、及び特許分野で大量の論文・特 許の検索が必要となる。
• 計算機の登場により、情報学との関連が強くな り、図書館情報学と呼ばれるようになる。 • Webの登場によりページ数が爆発的に増加、検索 エンジンが登場
(c)長岡技術科学大学 電気系 4 関連分野 • データベース • 自然言語処理 – 聞いてほしいことはいっぱいありますので、興味ある人は
修士の授業を聞いてください。 • パタン認識 • 図書館情報学 • 認知心理学
(c)長岡技術科学大学 電気系 5 索引付け
(c)長岡技術科学大学 電気系 6 索引付け(indexing) • 文書から、検索対象とする用語(キーワード)を決 めること。 • 昔は、計算機性能が十分でなかったため、検索 対象語を絞り込む必要があった。このため人手で
厳選したキーワードを付与していた。 • 文書が電子化さえされていれば索引付けの自動 化は可能である。しかし、自動的に付与した索引 が必ずしも便利とは限らないため、今でも人手で 行っている場合も多い。 – 例えば学術原稿では著者にキーワードの付与を要求す る場合も多い。
(c)長岡技術科学大学 電気系 7 どんな語をキーワードにすべきか? 一言で言えば特徴的な語。 でも何がどうなっていれば「特徴的」なのか? • その文書内でよく使われている語 – 文書の内容を代表的に表現している
• 他の文書であまり(or全く)使われていない語 – 他文書との差異を表現している
(c)長岡技術科学大学 電気系 8 TF・IDF 語の重要度を計算する指標 • TF (term frequency) –
ある文書d中に出現する語tの頻度 • IDF (Inverse document frequency) – • TF・IDF – 両指標の積 – 最も有名でよく使用される。 log (全文書数 ) (tを含む文書数 ) +1
(c)長岡技術科学大学 電気系 9 不要語リスト(stop words) • 誰もこんな語で検索しないだろう、という語のリスト – 日本語の「それ」、英語の is
など • 検索の負荷(索引の規模や検索時間等)を減らす のが目的。 • 厳密な定義は困難であるが、機能語(日本語の 助詞、英語の前置詞など)や超高頻度語の中か ら選ばれる。
(c)長岡技術科学大学 電気系 10 検索質問拡張(query expansion) • 一般に、言語表現は多様性がある。 – 異表記(例:「リンゴ」と「りんご」と「林檎」) –
揺れ(例:「コンピュータ」と「コンピューター」) – 同義語(例:「コンピュータ」と「計算機」) • これらは検索結果の精度低下を招くので、精度を 高めるために入力表現の同義語等も同時に検索す る技術のこと。 • さらに、「もしかして検索」のように誤入力した検索 質問に対しても検索質問拡張を行うシステムもあ る。
(c)長岡技術科学大学 電気系 11 情報検索モデル
(c)長岡技術科学大学 電気系 12 検索結果の絞り込み 検索要求を満たす文書(ページ)は大量に適合す るかもしれない。どうやってほしい文書を見つける か? • さらに絞り込む –
ブーリアンモデル • 順位付けする – ベクトル空間モデル – テキスト外情報: PageRank、協調フィルタリングなど
(c)長岡技術科学大学 電気系 13 ブーリアンモデル(Boolean model) • 最も古典的な検索方法 • 検索質問を論理式で表現して検索する •
検索結果が多い場合はさらに検索質問を追加して (AND検索して)絞り込む
(c)長岡技術科学大学 電気系 14 ベクトル空間モデル (vector space model) • 検索質問と文書を同一軸のベクトルで表現する。 •
ベクトルの各軸は各キーワードの出現頻度などとす る場合が多い。 – つまり、ベクトルの次元数 = 単語数 • これによって、検索質問と文書の類似度をベクトル の類似度で表現できる。 – 例えば、両ベクトル間の角度(コサイン)で定義でき る。
(c)長岡技術科学大学 電気系 15 PageRank • Googleの技術。PageRank(TM) は、米Google社の登録商標です。 • 文書の内容から重要性を判断しない •
ページのリンク情報を用いて質を判断する • PR0~PR10の11段階ある。
(c)長岡技術科学大学 電気系 16 PageRank:考え方 • 多くの良質なページからリンクされているページは、 良質である。 • ページAからページBへのリンクを、「投票」と考え る。
– 多くのページからリンクされているほうが良質 – 良質なページからリンクされているほうが良質 – あまりリンクしていないページからリンクされているほうが 良質
(c)長岡技術科学大学 電気系 17 全文検索システム
(c)長岡技術科学大学 電気系 18 全文検索の分類 • 逐次検索 – 毎回全文を最初から調べていく方法 – 文書が高頻度で更新される場合に有効
• 全文索引 – 事前に何らかの形で自動的に索引を作っておく方法 – 大規模な文書に対して有効
(c)長岡技術科学大学 電気系 19 全文索引 対象となる全文を分析してあらかじめ自動で転置索 引を作成する。索引の作り方は大きく2種類ある。 • 単語索引 – 形態素解析を行って分かち書きする。
– 索引を小さくできるが、検索漏れの可能性あり • N-gram索引 – N文字のすべての部分文字を「単語」とみな す。 – 検索漏れはないが無意味な索引が大量に発生
(c)長岡技術科学大学 電気系 20 形態素解析 • 自然言語処理の基本技術 • 二つの仕事: – 形態素分割(分かち書き)
– 品詞付与 • 日本語だけの技術ではなく、例えば英語でも必 要となる – that's ==> that be – New York ==> (1単語)
(c)長岡技術科学大学 電気系 21 (文書) 文書1:「京都の寺は多い」 文書2:「東京都国分寺はテニスコートが多い」 文書3:「テニスするなら東京より京都がいい」 ... (単語転置索引) position(京都)
= {1, 3} position(寺) = {1} position(多い) = {1, 2} position(東京都) = {2} position(国分寺) = {2} position(テニスコート) = {2} position(テニス) = {3} position(東京) = {3} ... 文書2が間違って 検索されない 単語索引
(c)長岡技術科学大学 電気系 22 (文書) 文書1:「京都の寺は多い」 文書2:「東京都国分寺はテニスコートが多い」 文書3:「テニスするなら東京より京都がいい」 ... (転置索引) position(京都)
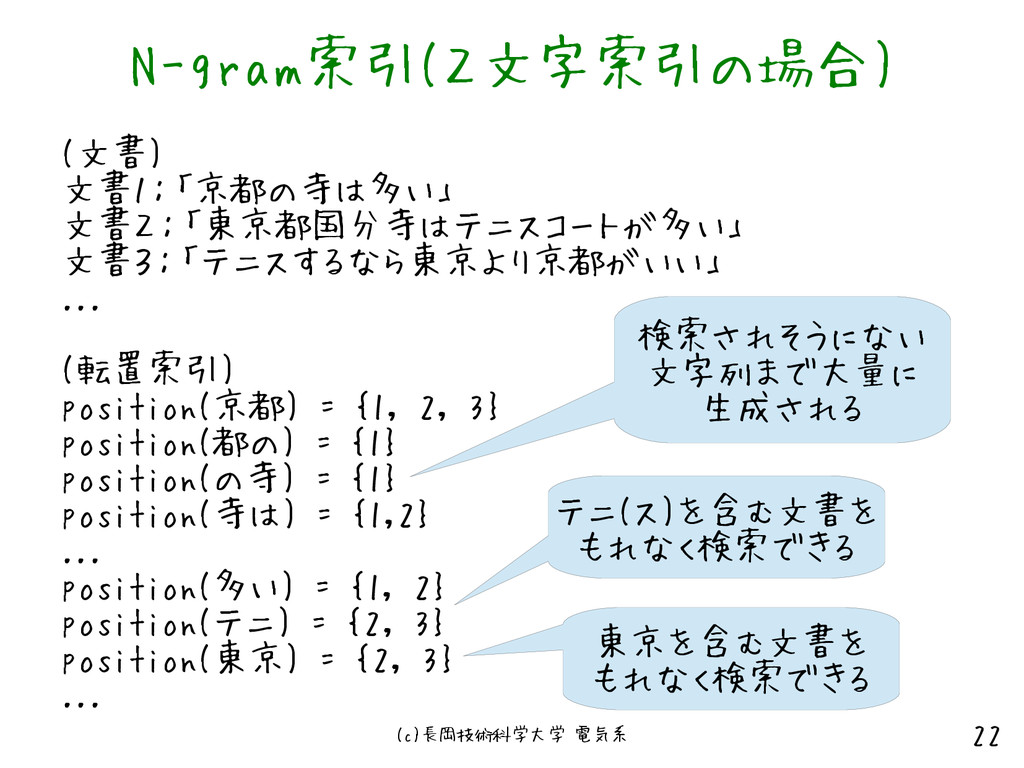
= {1, 2, 3} position(都の) = {1} position(の寺) = {1} position(寺は) = {1,2} ... position(多い) = {1, 2} position(テニ) = {2, 3} position(東京) = {2, 3} ... テニ(ス)を含む文書を もれなく検索できる 東京を含む文書を もれなく検索できる 検索されそうにない 文字列まで大量に 生成される N-gram索引(2文字索引の場合)
(c)長岡技術科学大学 電気系 23 情報検索システムの評価
(c)長岡技術科学大学 電気系 24 検索システムの評価 • 検索結果の有効性 – 検索の正確さ • 検索作業の作業効率
– 検索時間 • 使いやすさ – 初心者にとっての使いやすさ – 熟練者にとっての使いやすさ
(c)長岡技術科学大学 電気系 25 再現率と適合率 • 再現率(recall):どの程度正解を検索できたか – R = (v∩w)÷v
• 適合率(精度)(precision):検索したものがどの 程度正しかったか – P = (v∩w)÷w • 正解数のみを出力 させると両指標は 常に同一になる。 正解 検索結果 v w v∩w
(c)長岡技術科学大学 電気系 26 F値 (F-measure) • 再現率と適合率を一つの尺度にまとめたもの。 • Rを再現率、Pを適合率とした時、両者の調和平 均を計算する。
• これを変形して、 1 F = 1 2 ( 1 R + 1 P ) F= 2PR P+R
(c)長岡技術科学大学 電気系 27 情報検索の今後
(c)長岡技術科学大学 電気系 28 協調フィルタリング • ユーザに似た人の意見を参考にする、という考え 方。 – 行動履歴によって検索要求を推測しようとする試み •
1992年にXerox PARCが発表(tapestry)、Amazon が1997年に「おすすめ商品」を導入。 • 現在では、レコメンデーションサービスで一般的に 利用されている
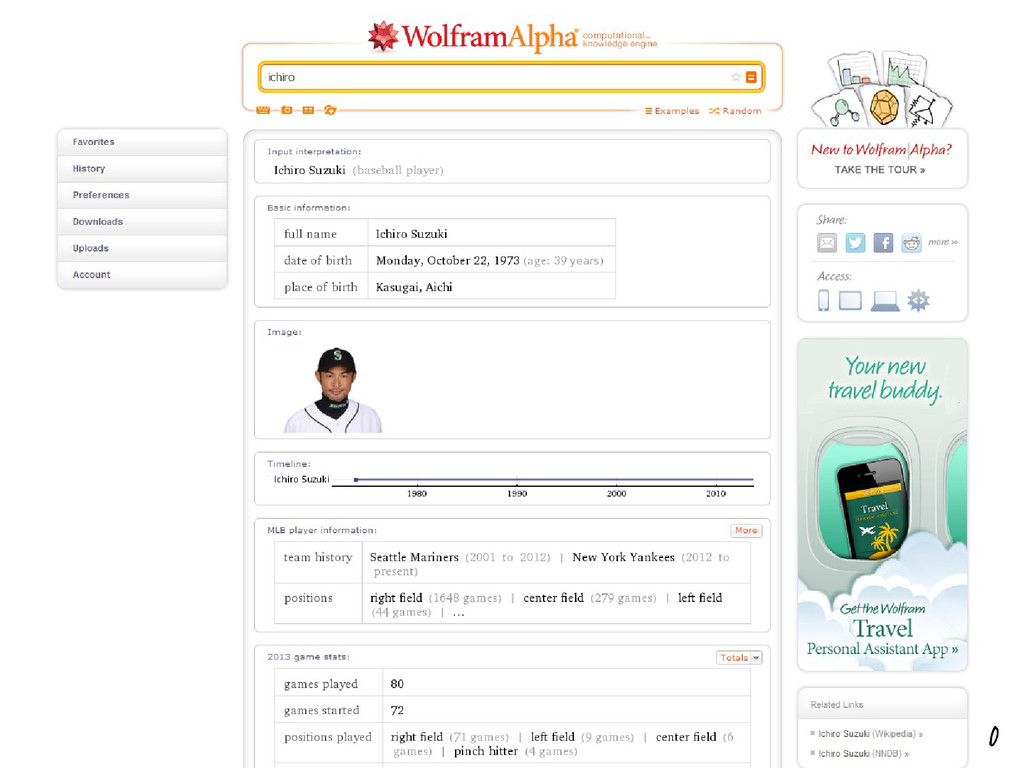
(c)長岡技術科学大学 電気系 29 質問応答(Question Answering) • ユーザが知りたい情報を含む文書(ページ)を出力 するのではなく、知りたい情報に対して回答を探す 技術。 •
Wolfram Alpha • しゃべってコンシェル・Siri • IBM Watson
(c)長岡技術科学大学 電気系 30
(c)長岡技術科学大学 電気系 31 画像検索 • 画像検索は各画像に予め索引を付与しておき、そ れを検索するのが一般的。 – つまり索引を付与してしまえば後は文書検索と全く同 じ。
• 画像を入力して類似画像を検索する技術もある。 – 例:Google検索 – ただし、類似画像を検索しているのではなく、入力画像 をキーワードに自動変換した上で画像検索している。
(c)長岡技術科学大学 電気系 32 音声検索 • 「音声で検索」するためには音声認識を行えばよ く、すでに実用的 • 「音声を検索」する場合も、事前に音声認識を 行っておけばよい。
• 音声以外の情報も含めて検索するのはまだ実験段 階か? – 似た曲の検索
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}