Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
個人適応による英日翻訳での訳語候補の順位付け
Search
自然言語処理研究室
March 31, 2006
Research
170
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
個人適応による英日翻訳での訳語候補の順位付け
青木 優、山本 和英. 個人適応による英日翻訳での訳語候補の順位付け. 言語処理学会第12回年次大会, pp.260-263 (2006.3)
自然言語処理研究室
March 31, 2006
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
480
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
240
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
200
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
Fukui Shibiten 39 - AI Art
butchi
0
140
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
1k
正規分布と最適化について
koide3
1
280
人間中心の意思決定支援AI
yukinobaba
PRO
6
3.2k
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
270
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
460
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
150
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
240
Featured
See All Featured
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Unsuck your backbone
ammeep
672
58k
Amusing Abliteration
ianozsvald
1
220
Tell your own story through comics
letsgokoyo
1
980
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
240
AI: The stuff that nobody shows you
jnunemaker
PRO
8
760
How GitHub (no longer) Works
holman
316
150k
Chasing Engaging Ingredients in Design
codingconduct
0
230
First, design no harm
axbom
PRO
2
1.2k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
180
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Transcript
個人適応による英日翻訳での 訳語候補の順位付け 長岡技術科学大学 電気系 青木 優 山本 和英
はじめに 背景 個人の興味や知識を学習する個人適応 システムは、ユーザが大量の情報を選 別するタスクに有効である。 問題設定
複数の選択肢が提示されたとき、ユー ザにとって必要な情報の取捨選択。 →英日翻訳における訳語選択
ユーザプロファイル 以下の情報を訳語選択に利用 頻出単語:よく使用する単語 分野情報:ユーザを分類する指標 訳語履歴:選択された訳語
共起単語:使われやすいと思われる単語
処理の流れ 1. ユーザプロファイルの作成 2. 訳語候補スコアの計算 3. ランキングで表示 4. ユーザは尤もらしい候補を選択 5.
ユーザプロファイルの更新
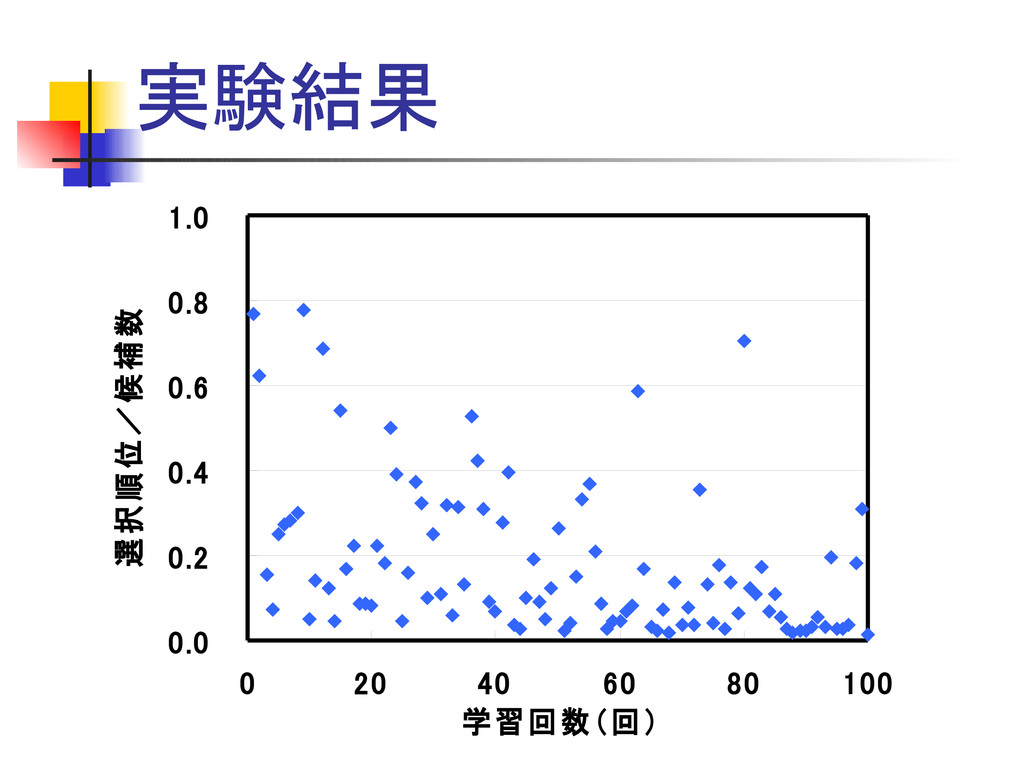
まとめ ユーザプロファイルを作成、利用 訳語候補をランキングで提示 ユーザの個人性を学習させた その結果、学習回数の増加に伴い、 選択された訳語の順位が上位である 割合が高くなくなる傾向が見られた。
辞書の作成 属性付き対訳辞書 クロスランゲージ専門語辞書を使用 共起単語辞書 一文中で共起する2語の共起頻度
毎日新聞2000年版を使用 [circuit:回路:電気・電子]
プロファイルの作成 頻出単語プロファイル Blogなど個人の特徴が現れやすい文書 中の単語頻度 分野情報プロファイル 単語頻度を属性情報に変換したときの
属性値頻度 回路 = 5 接続 = 4 電気・電子 = 8 機械工学 = 4
訳語候補スコア λ(n)各プロファイルスコアの重み 頻出単語 = 3 分野情報 = 2 、 訳語履歴
= 2 共起単語 = 1 ( ) ( ) ( ) ( ) ∑ × + = n i P i F n w n S w S λ , 初期値 各プロファイルから求めた スコアの総和
初期値の計算 コーパス中の単語単位の頻度情報 毎日新聞2000年版を使用 ( ) 訳語候補 全単語の出現頻度の和
の出現頻度 = 初期値 : i i i F w w w S
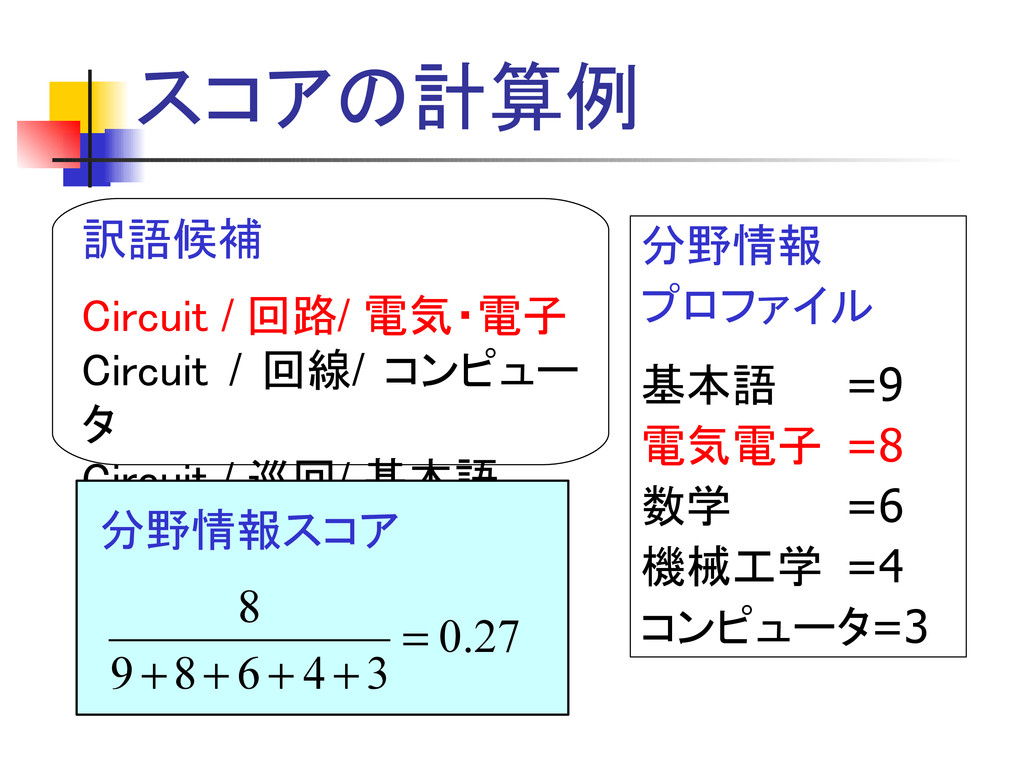
スコアの計算例 分野情報 プロファイル 基本語 =9 電気電子 =8 数学 =6 機械工学
=4 コンピュータ=3 訳語候補 Circuit / 回路/ 電気・電子 Circuit / 回線/ コンピュー タ Circuit / 巡回/ 基本語 27 . 0 3 4 6 8 9 8 = + + + + 分野情報スコア
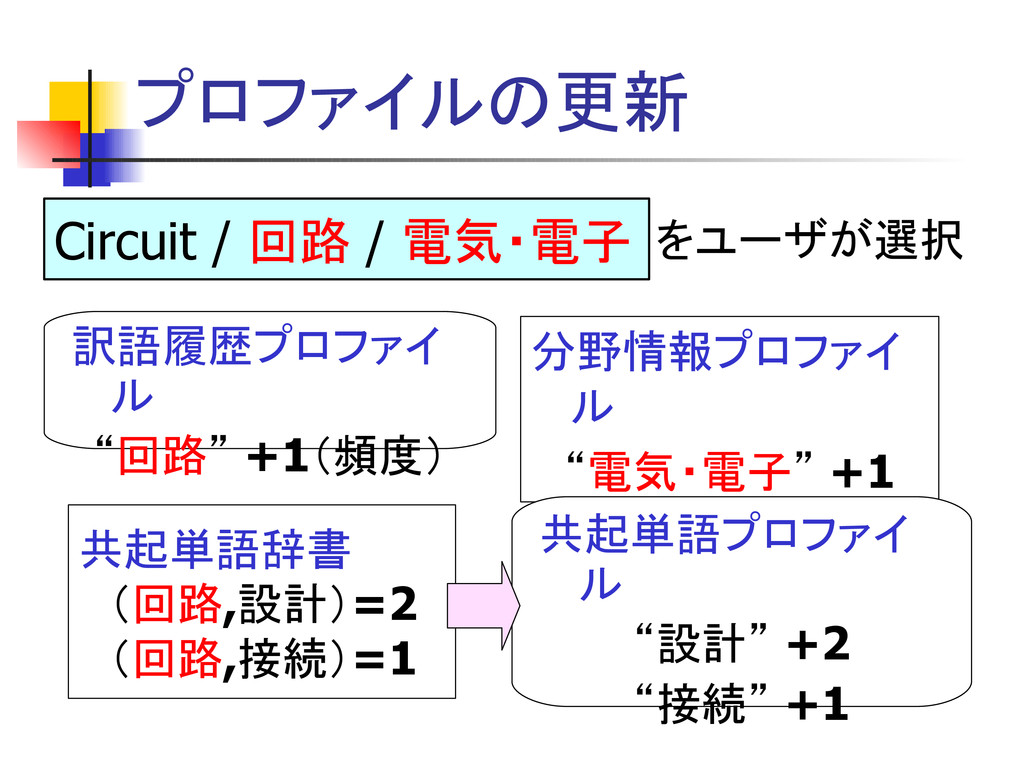
プロファイルの更新 Circuit / 回路 / 電気・電子 分野情報プロファイ ル “電気・電子” +1
訳語履歴プロファイ ル “回路” +1(頻度) 共起単語プロファイ ル “設計” +2 “接続” +1 共起単語辞書 (回路,設計)=2 (回路,接続)=1 をユーザが選択
評価実験 ランダムで選んだ英単語100語を入力 ユーザは尤もらしいと思う訳語を選択 システムに学習させる 選ばれた訳語の順位の推移を評価 プロファイルを更新し、システムに学習さ
せることで、ユーザに選ばれる訳語候補 が上位に出力されることを確認する。
実験結果 0.0 0.2 0.4 0.6 0.8 1.0 0 20 40
60 80 100 学習回数(回) 選択順位/候補数
考察 頻出単語 一般的に使用頻度の高い訳語候補が 上位に出現してしまう 表記揺れの対応 訳語候補数が増加してしまう
lack:欠ける、不足、欠如、ない break:こわす、壊す、こわれる、壊れる
課題 ユーザプロファイルの作成 個人の特徴が現れるような文書の 収集方法の検討 初期でのプロファイルの作成 効率的な学習
重み付け方法の検討
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}