Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
日報を対象とした障害予知システムの構築
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
March 31, 2009
Research
77
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
日報を対象とした障害予知システムの構築
柿元 芳文. 日報を対象とした障害予知システムの構築. 長岡技術科学大学修士論文 (2009.3)
自然言語処理研究室
March 31, 2009
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
540
データサイエンス12_分類.pdf
jnlp
0
380
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
180
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
HAKARI-Bench - 実運用視点での情報検索モデル評価ベンチマーク
hotchpotch
0
120
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
350
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
140
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
570
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.6k
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
410
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
140
LLM Compute Infrastructure Overview
karakurist
2
1.5k
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
490
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
490
IA for theory
gpeyre
0
290
Featured
See All Featured
Agile that works and the tools we love
rasmusluckow
331
22k
Tell your own story through comics
letsgokoyo
1
1k
WCS-LA-2024
lcolladotor
0
760
Six Lessons from altMBA
skipperchong
29
4.4k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Faster Mobile Websites
deanohume
310
32k
Become a Pro
speakerdeck
PRO
31
6k
My Coaching Mixtape
mlcsv
0
180
It's Worth the Effort
3n
188
29k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
How to Ace a Technical Interview
jacobian
281
24k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Transcript
日報を対象とした 障害予知システムの構築 電気電子情報工学専攻 山本研究室 07511584 柿元 芳文
2 背景 企業内文書の電子化 s ネットワークの普及 s WebやE-mailによる業務日報 業務日報の重要性 s 上司による業務の良悪の判断
s 業務に関する障害の把握 明示されている障害 明示されていない障害 未発生であるが、起こり得る障害
3 背景 企業内文書の電子化 s ネットワークの普及 s WebやE-mailによる業務日報 業務日報の重要性 s 上司による業務の良悪の判断
s 業務に関する障害の把握 明示されている障害 明示されていない障害 未発生であるが、起こり得る障害 業務日報から障害を予知する技術
4 目的 障害予知システムの構築 s 入力日報から、隠れた障害、 又は起こり得る障害を発見する s 障害の早期発見 s 障害の発生防止
テキスト情報から障害を予知する 研究は行われていない!
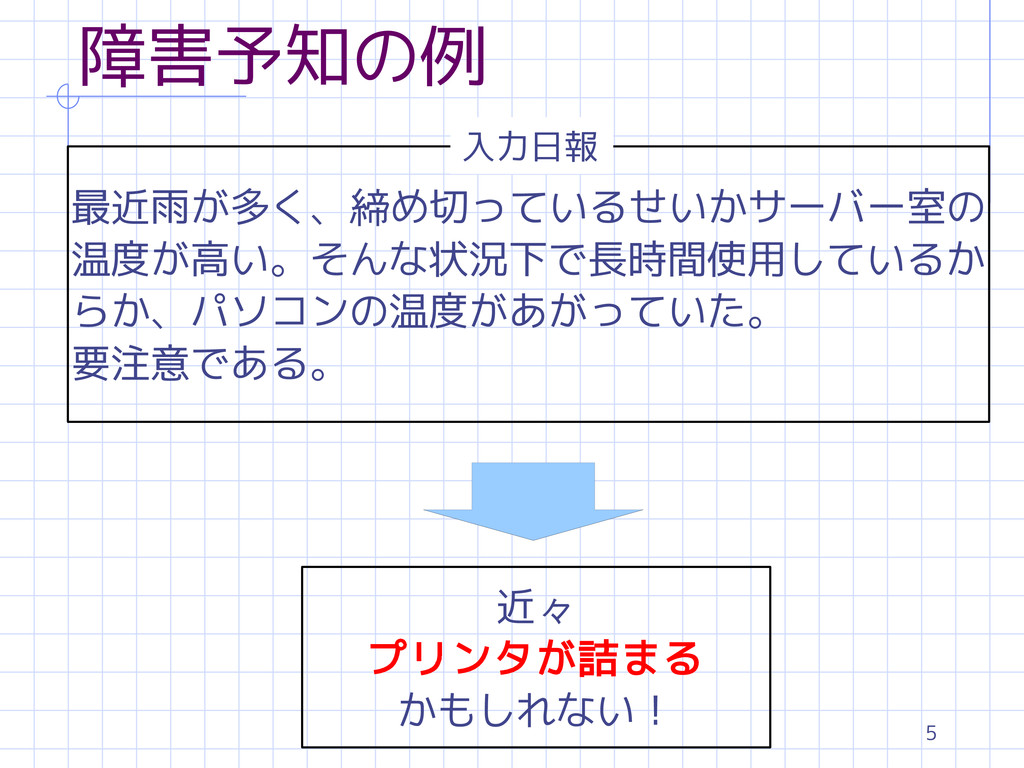
5 障害予知の例 最近雨が多く、締め切っているせいかサーバー室の 温度が高い。そんな状況下で長時間使用しているか らか、パソコンの温度があがっていた。 要注意である。 入力日報 近々 プリンタが詰まる かもしれない!
6 用いた日報データ 第三者に報告する形で記述 書き手の主観情報を多く含む ドメインが固定されている Web上のデータ「価格.com」の 1つの書き込みを「日報」として用いる 企業の日報は大量に手に入れることが難しい 企業の日報の特徴 扱ったドメイン
: 電話 , カメラ , 車 , ゲーム
7 提案手法の流れ 障害情報の抽出 s 予知すべき情報の収集 s 構文パタンと統計的情報を用いる 日報と障害情報の対応付け s 文書分類のタスクとして処理
s 独自の確率モデルを用いる 入力日報からの障害の予知 s 予知の必要/不要の判断 s 対応付け手法を用いた障害の予知
8 提案手法の流れ 障害情報の抽出 s 予知すべき情報の収集 s 構文パタンと統計的情報を用いる 日報と障害情報の対応付け s 文書分類のタスクとして処理
s 独自の確率モデルを用いる 入力日報からの障害の予知 s 予知の必要/不要の判断 s 対応付け手法を用いた障害の予知
9 関連研究:障害情報抽出部 人手による辞書を用いる手法 [市村ら 2001] s 日報から「製品名」「要因概念」「結果概念」 を抽出 構文パタンを用いる手法 [斎藤ら
2007] s 議事録からプロジェクトリスクを抽出 統計的情報を用いる手法 [De Seager et al 2008] s 日報からトラブル表現を抽出 構文パタンと 統計的情報を用いて障害情報を抽出
10 障害情報の定義 ある日報の中で 何らかの障害を報告している表現 生じた障害の内容が推察できる単位 単語では不十分である s 障害の内容が推察できない 壊れる、遅延、エラー、失敗
s 対象によって対処法が変わる 「椅子が壊れる」「サーバーが壊れる」 障害情報の単位として
11 障害情報の定義 ある日報の中で 何らかの障害を報告している表現 生じた障害の内容が推察できる単位 単語では不十分である 障害情報の単位として 障害情報には少なくとも 障害の対象と状態の対が必要である
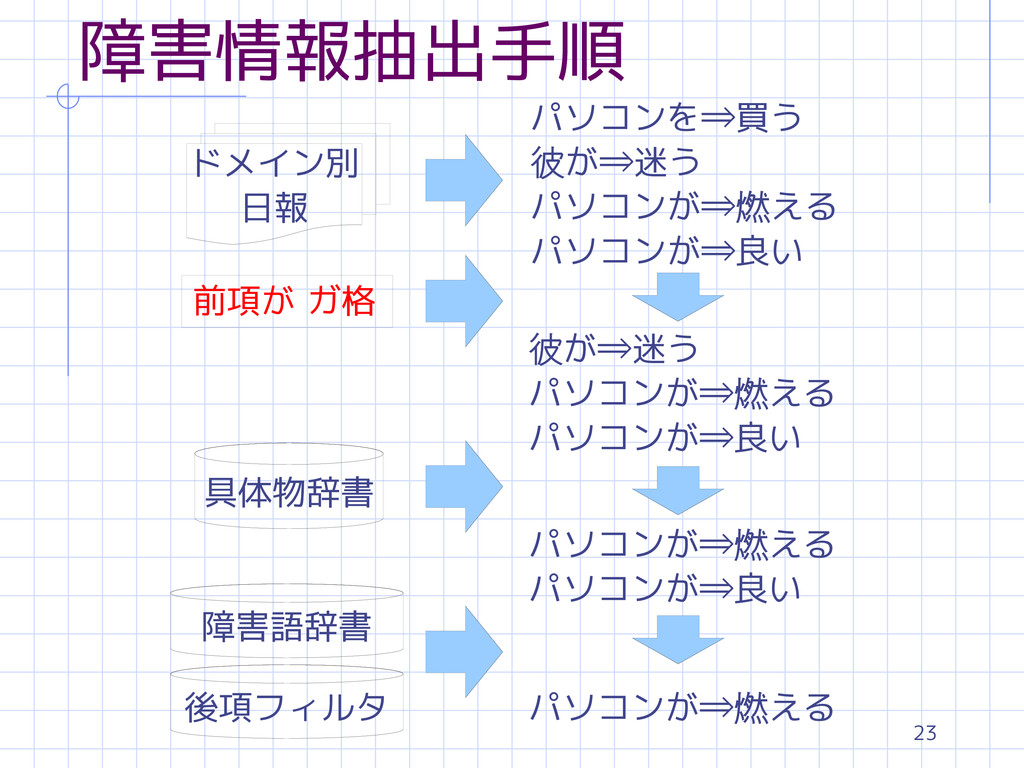
12 構文パタン 具体物名 + 格助詞「が」 ⇒ 障害を示す単語を含む文節 具体物名 s 具体物辞書を用いて判定
障害を表す単語を含む文節 s 障害語辞書を用いて判定 s 後項フィルタを用いて判定 障害情報の例 パソコンが⇒壊れる , 液晶が⇒割れる
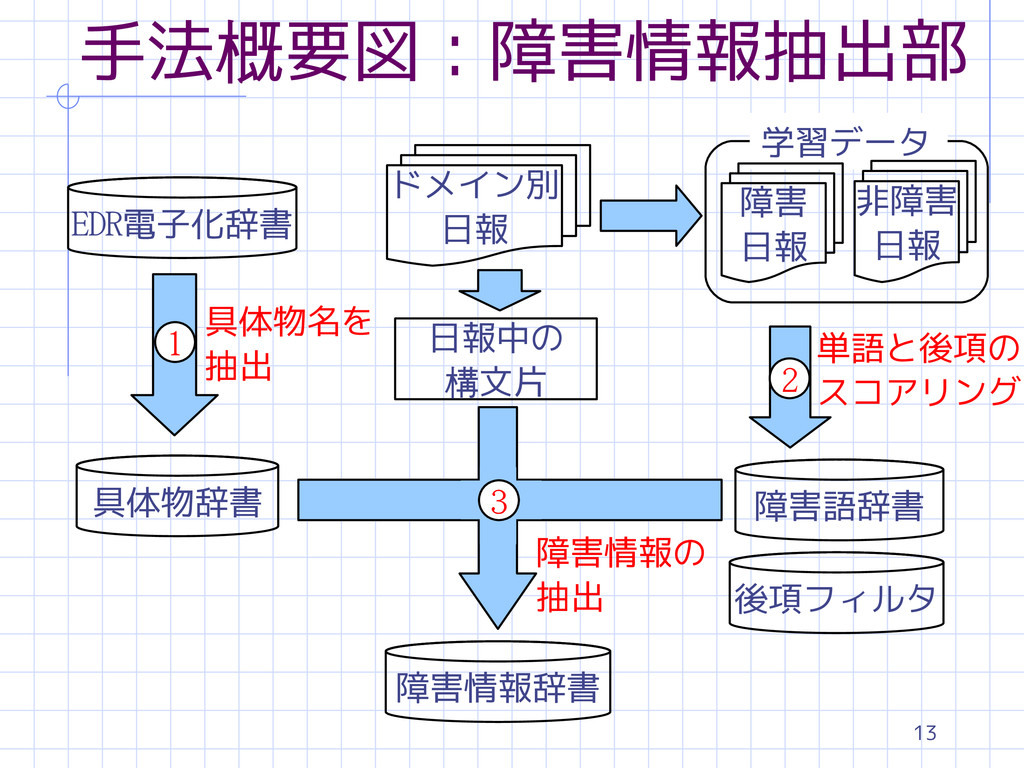
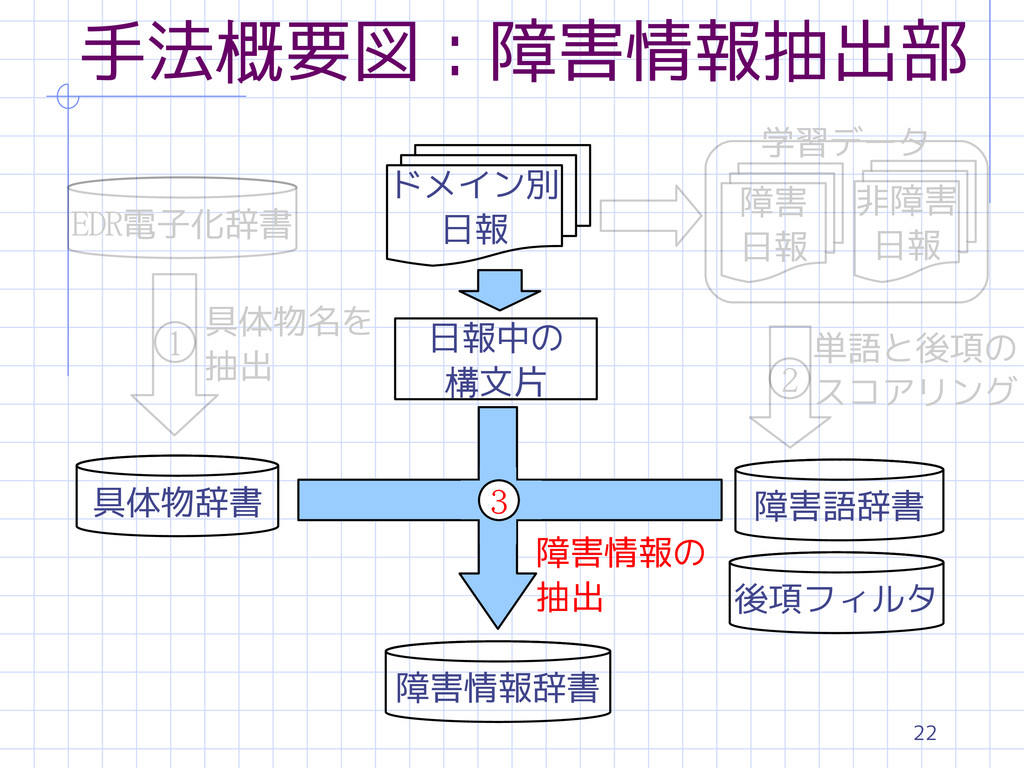
13 EDR電子化辞書 具体物辞書 学習データ 障害語辞書 ドメイン別 日報 障害 日報 非障害
日報 日報中の 構文片 障害情報辞書 具体物名を 抽出 1 2 3 単語と後項の スコアリング 障害情報の 抽出 手法概要図:障害情報抽出部 後項フィルタ
14 EDR電子化辞書 具体物辞書 学習データ 障害語辞書 ドメイン別 日報 障害 日報 非障害
日報 日報中の 構文片 障害情報辞書 具体物名を 抽出 1 2 3 単語と後項の スコアリング 障害情報の 抽出 手法概要図:障害情報抽出部 後項フィルタ
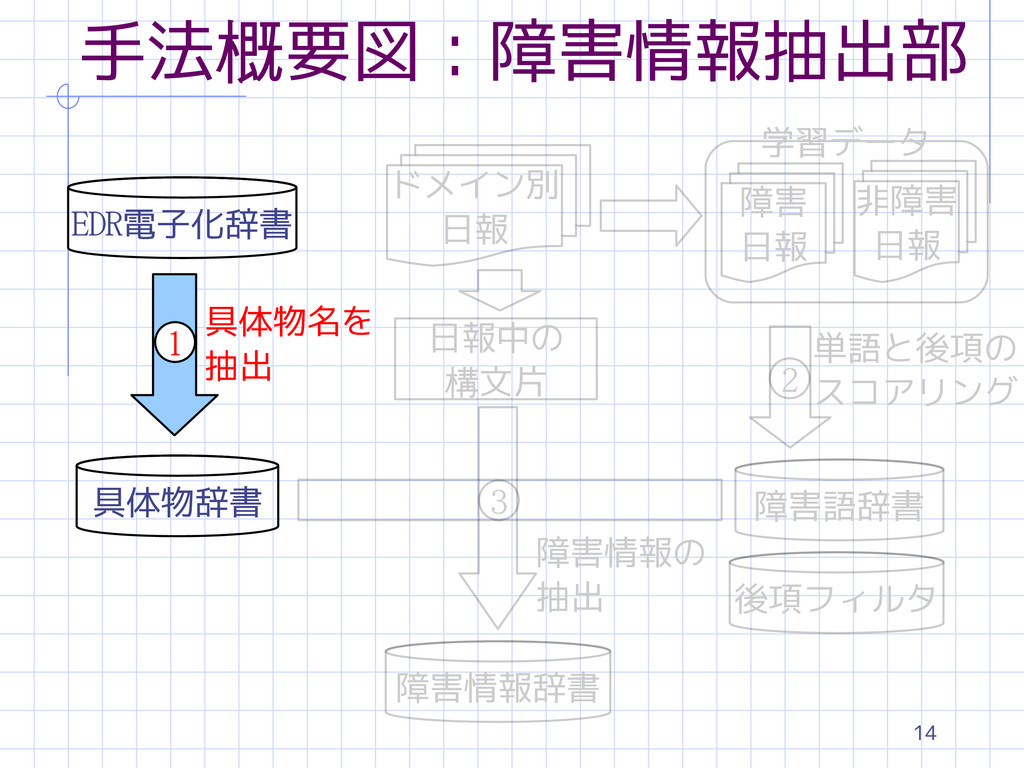
15 具体物辞書の構築 EDR電子化辞書を用いる 具体物名として用いた概念 具体物(例:カメラ) 自然現象によって出来る物(例:電波) 上記概念から除いた概念 事象(例:業者) 抽象物(例:科学) 人間または人間と似た振舞をする主体
(例:子供)
16 EDR電子化辞書 具体物辞書 学習データ 障害語辞書 ドメイン別 日報 障害 日報 非障害
日報 日報中の 構文片 障害情報辞書 具体物名を 抽出 1 2 3 単語と後項の スコアリング 障害情報の 抽出 手法概要図:障害情報抽出部 後項フィルタ
17 学習データの作成 すべての日報にはタグが存在する s 良い s 悪い s 質問 s
特価情報 s その他 「悪い」日報を障害日報 「良い」日報を非障害日報
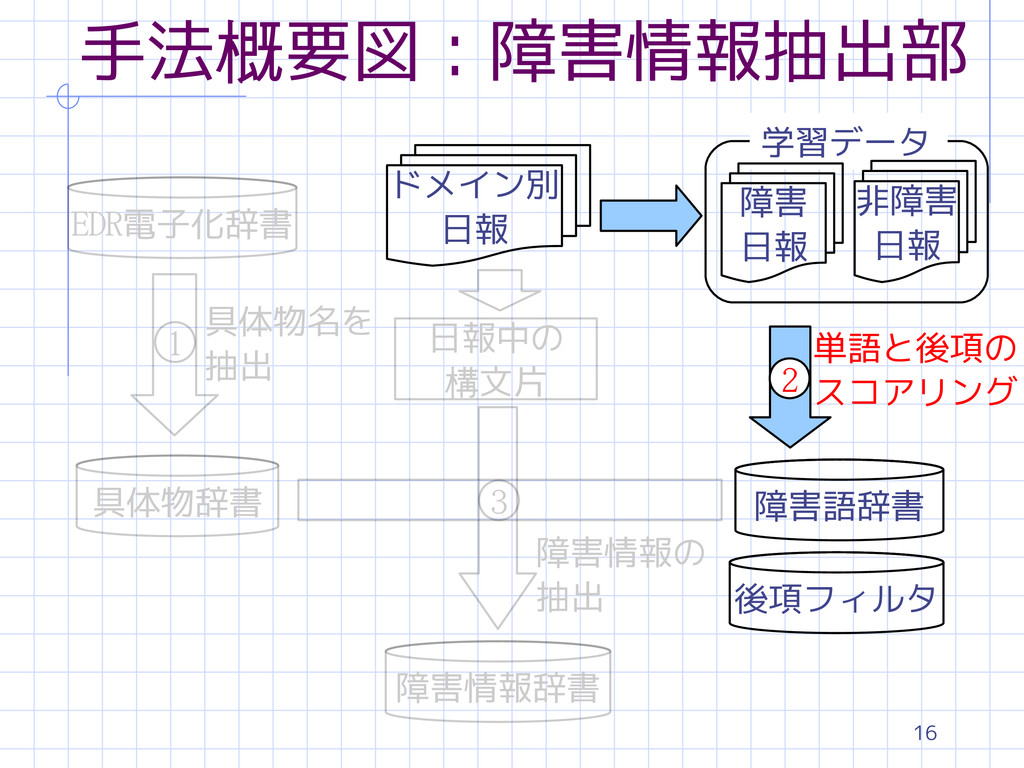
18 障害語辞書の構築 統計的情報を用いる 藤村らの手法を参考とした [藤村ら 2005] 単語の出現の偏り:-1 ~ +1 s
wi :ある単語 s P(wi) : wi が出現した非障害日報の数 s N(wi) : wi が出現した障害日報の数 s Pdoc,Ndoc : 非障害日報と障害日報の総数
19 出現頻度による差異の考慮 出現頻度:100 スコア:-0.9 出現頻度:10000 スコア:-0.9 出現頻度が高い方がスコアの信頼性が高い 信頼区間推定法を用いた [Agresti et
al 1998]
20 信頼区間推定法の適用 内容語をスコアStcと共に障害語辞書に登録 s 正のスコアの単語例: 感動 , 面白い s 負のスコアの単語例:
おかしい , 欠陥 信頼区間の考慮により極性が反転した内容語は 登録しない
21 後項フィルタの構築 文節を単位として構築 複数ドメインの非障害日報に頻出する文 節は障害を示さない s 例: 発売される 購入できる 「各ドメインの非障害日報での 出現確率の積」を算出
降順でランキング 上位となった後項を後項フィルタとして用いる
22 EDR電子化辞書 具体物辞書 学習データ 障害語辞書 ドメイン別 日報 障害 日報 非障害
日報 日報中の 構文片 障害情報辞書 具体物名を 抽出 1 2 3 単語と後項の スコアリング 障害情報の 抽出 手法概要図:障害情報抽出部 後項フィルタ
23 障害情報抽出手順 ドメイン別 日報 パソコンを⇒買う 彼が⇒迷う パソコンが⇒燃える パソコンが⇒良い 彼が⇒迷う パソコンが⇒燃える
パソコンが⇒良い パソコンが⇒燃える パソコンが⇒良い パソコンが⇒燃える 前項が ガ格 具体物辞書 障害語辞書 後項フィルタ
24 閾値の設定 設定対象 障害語辞書 後項フィルタ 設定方法 ドメイン「電話」を基準 障害語辞書と後項フィルタの閾値を変化 させ、設定条件を超えた閾値の組合せ 設定条件:抽出精度
0.9 以上 抽出数が 最多
25 否定語の考慮 障害語辞書は2種類の単語を含む 正のスコアの単語 : 間に合う , 動く 否定語の考慮 :
間に合わない , 動かない 負のスコアの単語 : 壊れる , 割れる 否定語の考慮 : 壊れない , 割れない 否定語「ない」によって極性が反転する 文節内で「ない」と共起した場合、 スコアを反転する
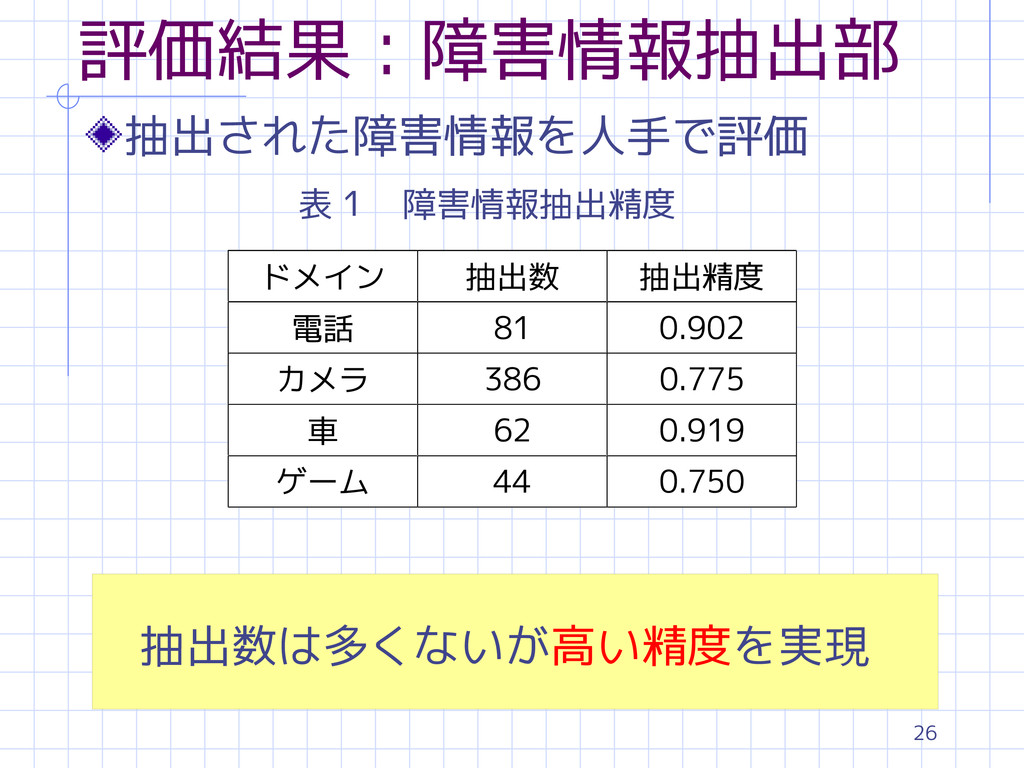
26 評価結果:障害情報抽出部 表1 障害情報抽出精度 抽出された障害情報を人手で評価 抽出数は多くないが高い精度を実現 ドメイン 抽出数 抽出精度 電話 81
0.902 カメラ 386 0.775 車 62 0.919 ゲーム 44 0.750
27 考察:誤抽出について 誤抽出数は s 全抽出数 : 573 s 語抽出数 :
109 誤抽出は障害語辞書によるものが最多 前項によって障害/非障害と変化するもの s ノイズが⇒発生する , 飛行機雲が⇒発生する 否定語の不足によるもの s 液晶が⇒壊れる , 液晶が⇒壊れにくい
28 まとめ:障害情報抽出部 構文パタンと統計的情報を用いた障害情 報抽出手法を提案 EDR電子化辞書から具体物辞書を構築 統計的情報から障害語辞書、 後項フィルタを構築 ドメイン「電話」「車」で精度0.9以上 「カメラ」「ゲーム」で精度0.8弱 高精度を実現
29 提案手法の流れ 障害情報の抽出 s 予知すべき情報の収集 s 構文パタンと統計的情報を用いる 日報と障害情報の対応付け s 文書分類のタスクとして処理
s 独自の確率モデルを用いる 入力日報からの障害の予知 s 予知の必要/不要の判断 s 対応付け手法を用いた障害の予知
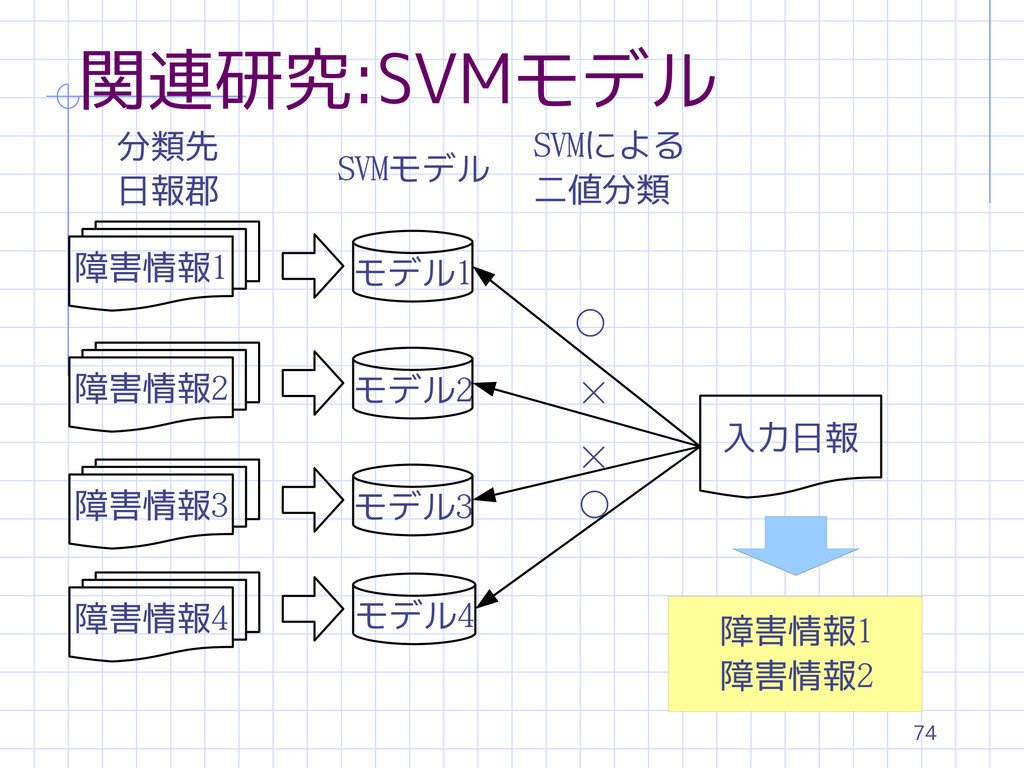
30 関連研究:対応付け部 文書分類手法 確率モデルを用いる手法 s 分類先と分類元での単語の出現確率 ベクトル空間モデルを用いる手法 s 分類先と分類元からベクトルを作成 s
コサイン距離を用いる 機械学習を用いる手法 s 単語を素性として分類モデルを構築 s SVMを使用
31 文書分類タスクで解く 文書分類は 同じテーマを持っている文書対は、共通 の単語が出やすい s 単語を特徴量として用いている s 分類先は同じテーマを持つ文書群 日報と障害の対応付けは
同じ障害は同じ状況で起こりやすい s 状況は内容語が表す s 内容語を特徴量として用いる s 分類先は同じ障害情報を持つ日報群
32 文書分類タスクで解く 文書分類は 同じテーマを持っている文書対は、共通 の単語が出やすい s 単語を特徴量として用いている s 分類先は同じテーマを持つ文書群 日報と障害の対応付けは
同じ障害は同じ状況で起こりやすい s 状況は内容語が表す s 内容語を特徴量として用いる s 分類先は同じ障害情報を持つ日報群
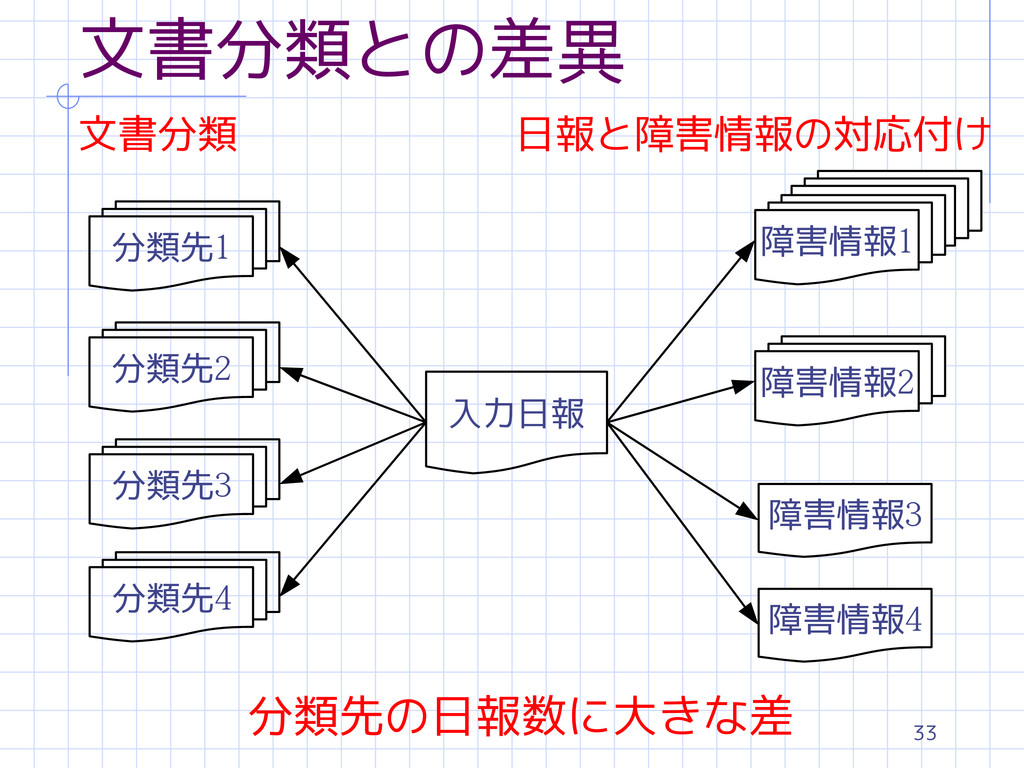
33 文書分類との差異 分類先1 入力日報 分類先2 分類先3 分類先4 障害情報1 障害情報2 障害情報3
障害情報4 文書分類 日報と障害情報の対応付け 分類先の日報数に大きな差
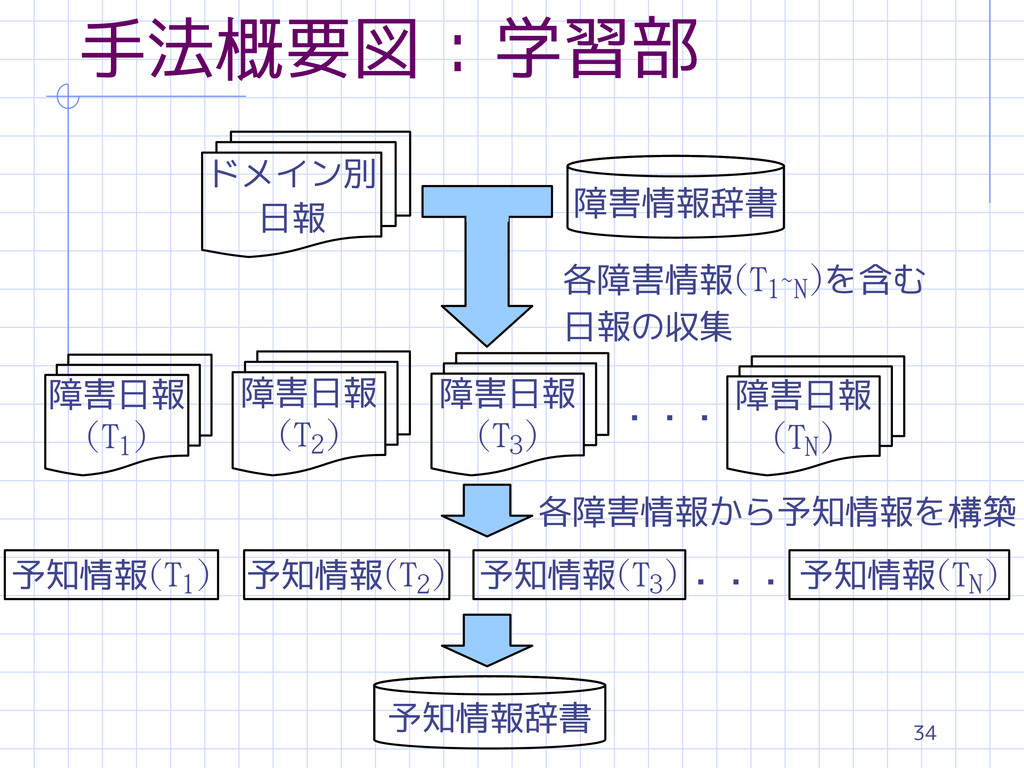
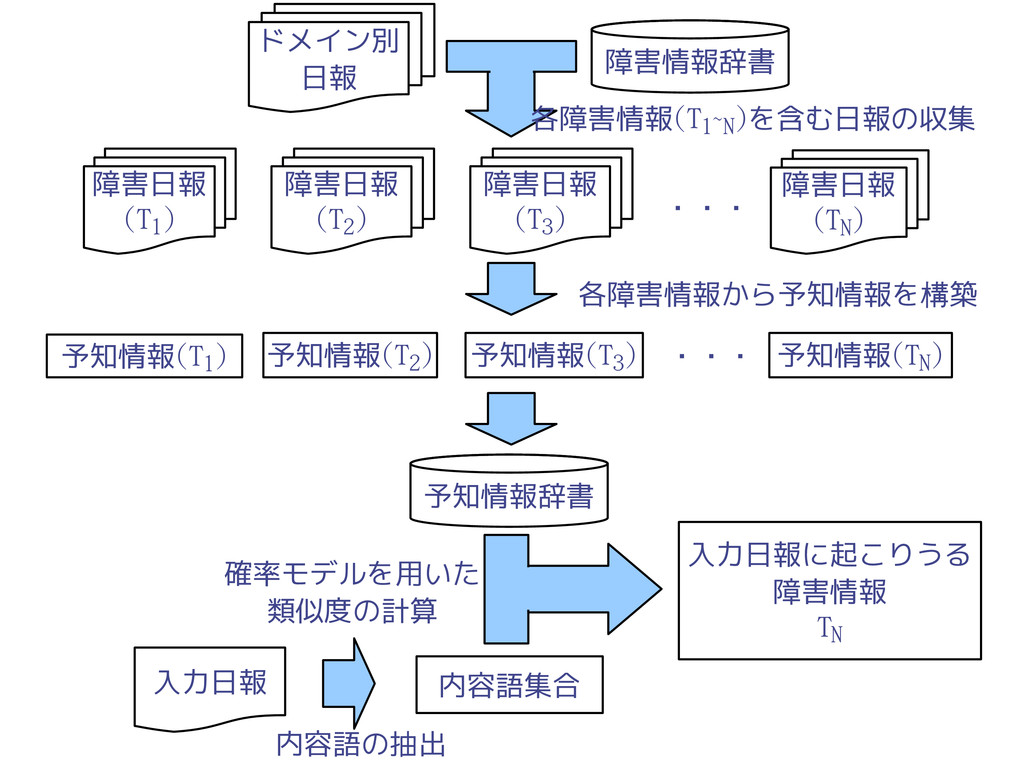
34 手法概要図 : 学習部 ドメイン別 日報 障害情報辞書 障害日報 (T1) 障害日報
(T2) 障害日報 (T3) ・・・ 障害日報 (TN) 予知情報(T1) 予知情報(T2) 予知情報(T3) 予知情報(TN) ・・・ 予知情報辞書 各障害情報から予知情報を構築 各障害情報(T1~N)を含む 日報の収集
35 予知情報辞書の構築 予知情報は各障害情報ごとに作成 内容語を要素 内容語と障害情報の共起頻度を付与 障害情報を構成している内容語は 要素から除く 予知情報の例 液晶が⇒割れる {落とす.6
, 指.6 , 衝撃.2 , ポケット.2 , 当たる.2}
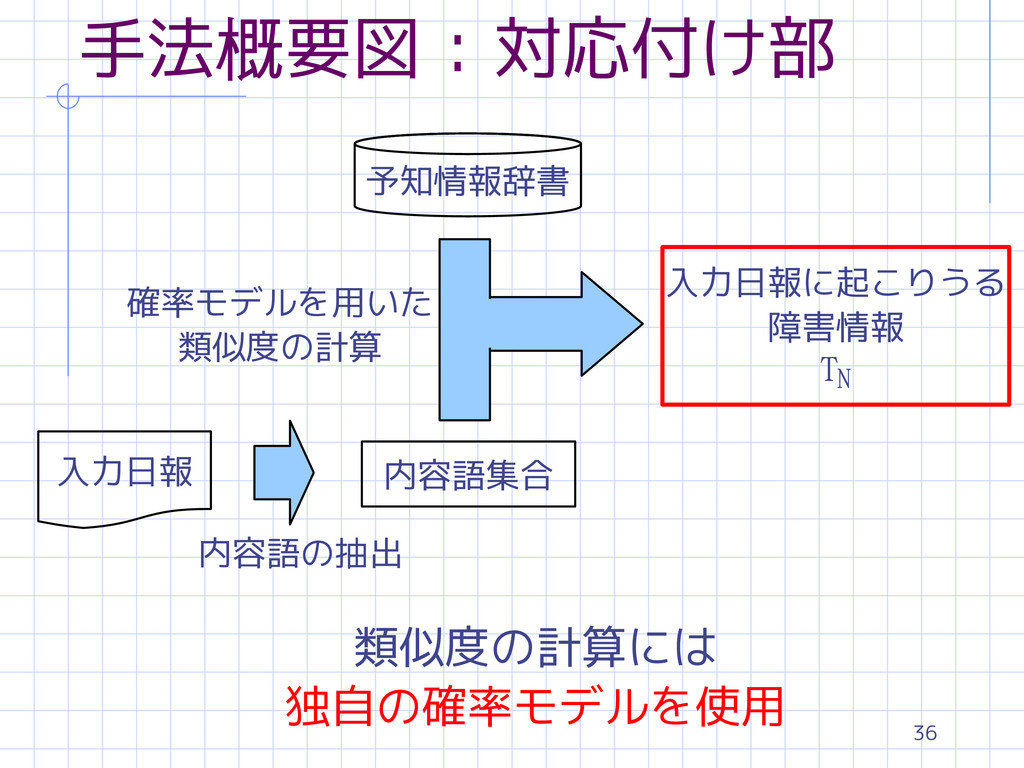
36 手法概要図 : 対応付け部 予知情報辞書 入力日報 内容語集合 入力日報に起こりうる 障害情報 TN
内容語の抽出 確率モデルを用いた 類似度の計算 類似度の計算には 独自の確率モデルを使用
37 対応付けスコアの計算 各予知情報と入力日報間で計算 独自の確率モデルを用いる 対応付けスコアに求める項目 予知情報と入力日報の内容語の一致率 s 状況が一致するほどいい 障害情報の出現しやすさ s
出現しやすい障害情報の考慮 対応付けスコアの上位3件を対応付ける
38 対応付けスコア算出式 s f : 予知情報 s d : 入力日報
s WF : 集合F に含まれ、集合D にも含まれる要素集合 s WD : 集合D に含まれ、集合F にも含まれる要素集合 s F : 予知情報f の要素集合 s D : 入力日報d の要素集合
39 評価実験:対応付け部 評価用日報の収集 s 学習用日報に含まれない日報 s 障害情報を含む日報 s 対応付け手法が、日報が持っている障害情報を 出力できたら正解
比較手法 s ベースライン s 確率モデル s ベクトル空間モデル (コサイン距離) s 機械学習モデル (SVM)
40 比較手法 ベースライン s 学習用日報中での出現確率上位の障害情報を常 に出力する 確率モデル [Iwayama et al
1994] s 入力日報と予知情報の単語の出現確率 s 障害情報の出現確率の考慮
41 比較手法 ベクトル空間モデル s 入力日報と予知情報の内容語集合をベクトル として扱う s コサイン距離を用いる s 両ベクトルの要素の和集合を取る
機械学習 s SVMを用いる s 各障害情報に分類モデルを構築 s 複数対応付けられた場合は、出現確率の高い 障害情報を優先
42 評価結果:対応付け部 表2 対応付け精度 手法 上位3位出力時の精度 電話 カメラ 車 ゲーム
ベースライン 0.731 0.266 0.667 0.667 確率モデル 0.769 0.348 0.533 0.417 ベクトル空間モデル 0.679 0.332 0.533 0.250 機械学習 0.692 0.305 0.467 0.250 本手法 0.769 0.375 0.733 0.417 すべてのドメインで比較手法と同等又は 比較手法を越えることが出来ている
43 考察:確率モデルとの比較(1/2) 精度が確率モデルと同等のドメインあり 確率モデルの出力には 出現確率上位3位の障害情報が多い 上位3位の障害情報が正解である日報は ほとんど正解している 上位ではない障害情報も対応付けたい 出現確率上位3位の障害情報が正解である評 価用日報を除いて再評価
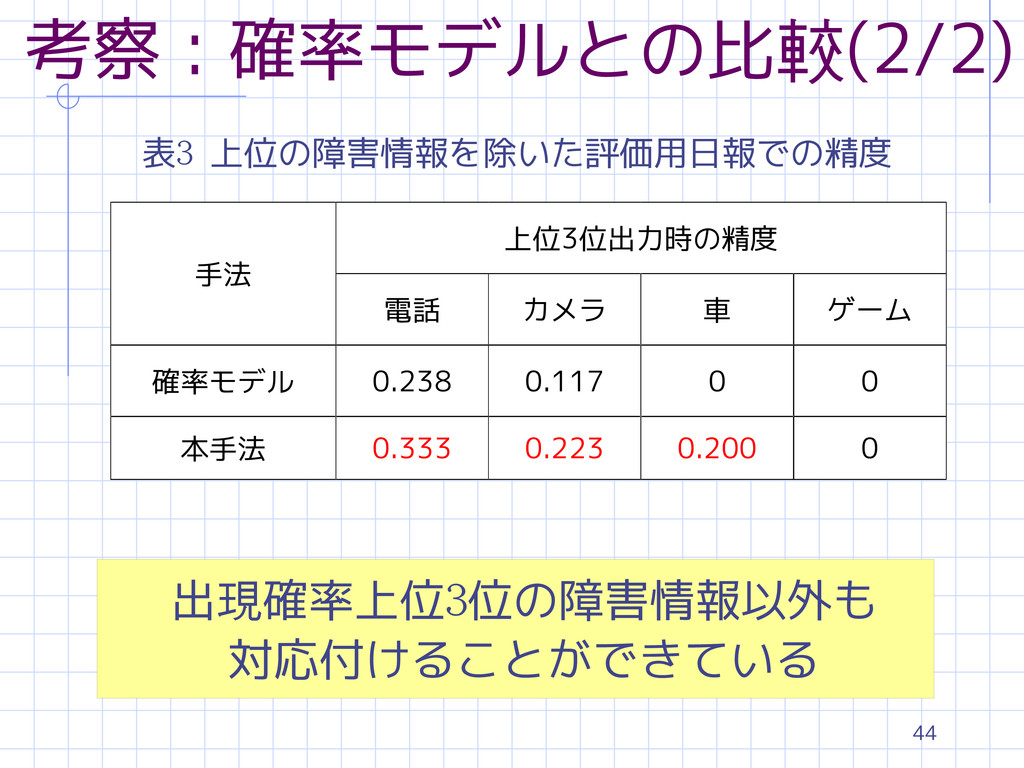
44 考察:確率モデルとの比較(2/2) 表3 上位の障害情報を除いた評価用日報での精度 手法 上位3位出力時の精度 電話 カメラ 車 ゲーム
確率モデル 0.238 0.117 0 0 本手法 0.333 0.223 0.200 0 出現確率上位3位の障害情報以外も 対応付けることができている
45 まとめ:対応付け部 日報と障害情報の対応付けを 文書分類のタスクとして処理 独自の確率モデルを提案 s 内容語の一致率 s 障害情報の出現しやすさ 比較手法よりも優れた対応付け精度を実現
s 出現確率の低い障害情報も対応付け可能
46 提案手法の流れ 障害情報の抽出 s 予知すべき情報の収集 s 構文パタンと統計的情報を用いる 日報と障害情報の対応付け s 文書分類のタスクとして処理
s 独自の確率モデルを用いる 入力日報からの障害の予知 s 予知の必要/不要の判断 s 対応付け手法を用いた障害の予知
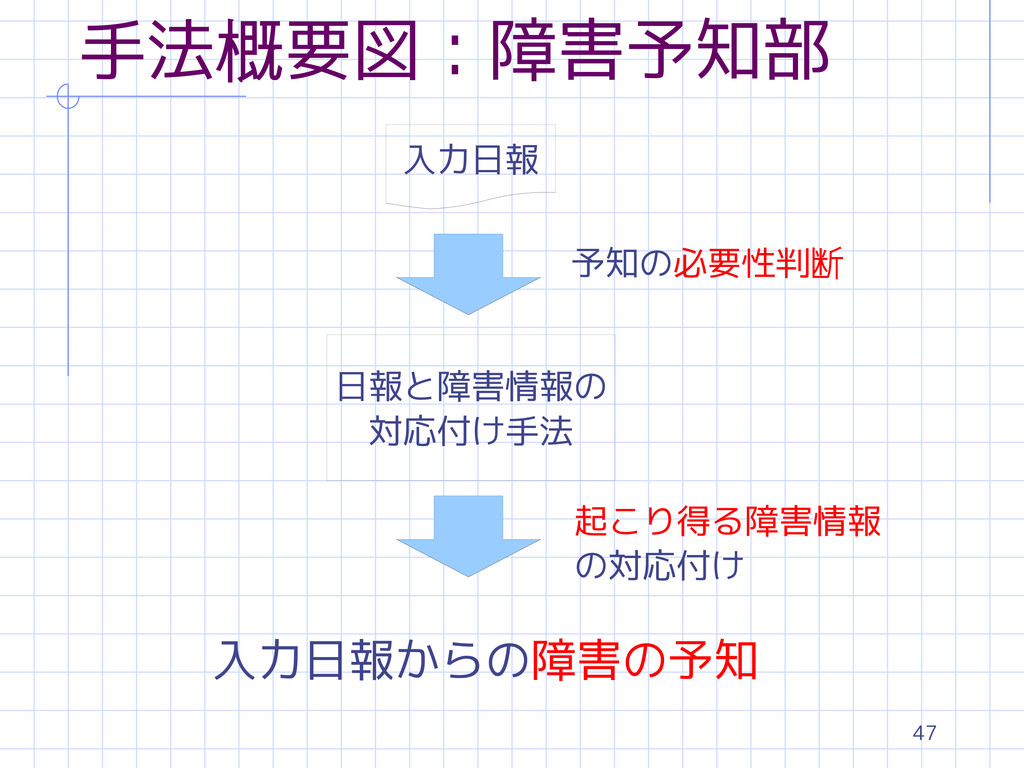
47 手法概要図:障害予知部 入力日報 予知の必要性判断 日報と障害情報の 対応付け手法 起こり得る障害情報 の対応付け 入力日報からの障害の予知
48 要予知日報判定 入力日報の予知の必要性判断 障害は悪い状況の集まりから発生 障害語辞書を用いて判定スコアSp を算出 負のスコアの日報を要予知日報とする s wi :入力日報に出現した単語
s D : 入力日報の内容語集合 s Stc : 障害語らしさのスコア
49 要予知日報判定 入力日報の予知の必要性判断 障害は悪い状況の集まりから発生 障害語辞書を用いて判定スコアSp を算出 負のスコアの日報を要予知日報とする 負のスコアとなった日報に対して 対応付け手法による予知を行う
50 評価実験概要:障害予知部 評価用日報 s 要予知日報と判断された日報 s 200件 : 各ドメイン 50
件 被験者は3名 人間による予知 s 「人間でも可能な予知」を収集 s 要予知日報判定の評価 システムの予知の評価 s 障害予知の精度を評価
51 評価実験1:人間による予知 障害が予知できる s 障害を3つまで記述 障害が起こり得るが予知はできない 障害は起こり得ない 人間でも可能な予知を収集 要予知日報判定の精度を算出 入力日報のみを提示
52 評価実験2:システムによる予知 システムの出力した予知3件 s 被験者が「起こり得る」と選択したら正解 ランダムで出力した予知3件 s 障害情報辞書からランダムで選択 障害は起こり得るが出力の中にはない 障害は起こり得ない
システムの障害予知部のみの精度を算出 入力日報とシステムの出力を提示
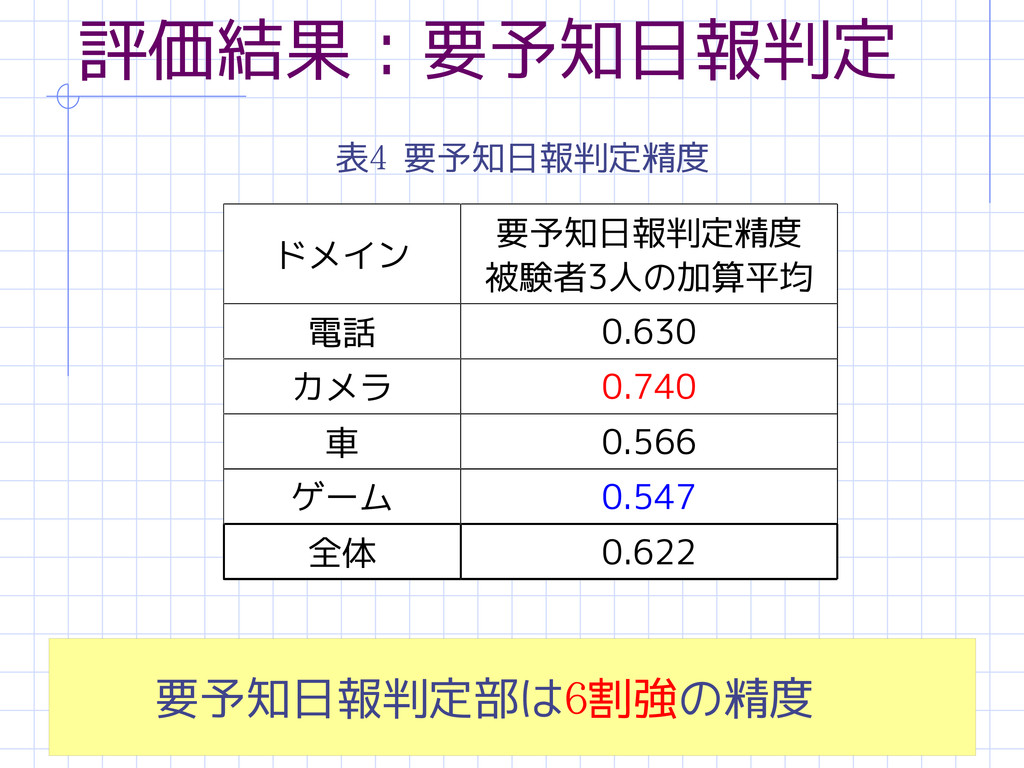
53 評価結果:要予知日報判定 表4 要予知日報判定精度 要予知日報判定部は6割強の精度 ドメイン 要予知日報判定精度 被験者3人の加算平均 電話 0.630
カメラ 0.740 車 0.566 ゲーム 0.547 全体 0.622
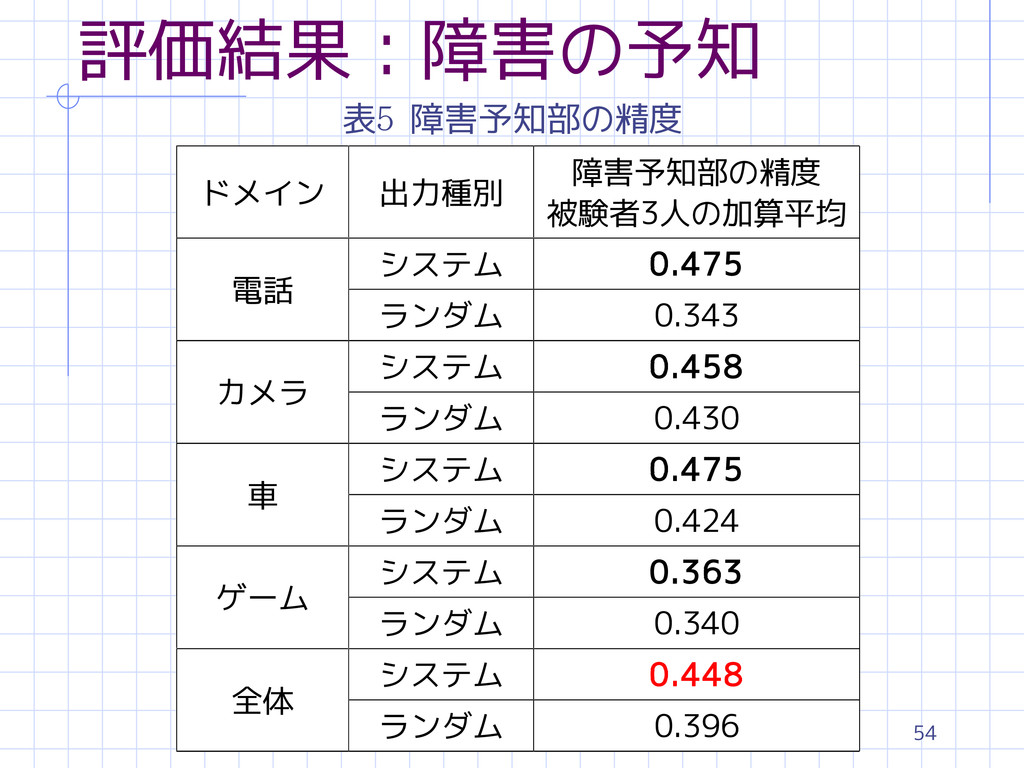
54 評価結果:障害の予知 表5 障害予知部の精度 ドメイン 出力種別 障害予知部の精度 被験者3人の加算平均 電話 システム
0.475 ランダム 0.343 カメラ システム 0.458 ランダム 0.430 車 システム 0.475 ランダム 0.424 ゲーム システム 0.363 ランダム 0.340 全体 システム 0.448 ランダム 0.396
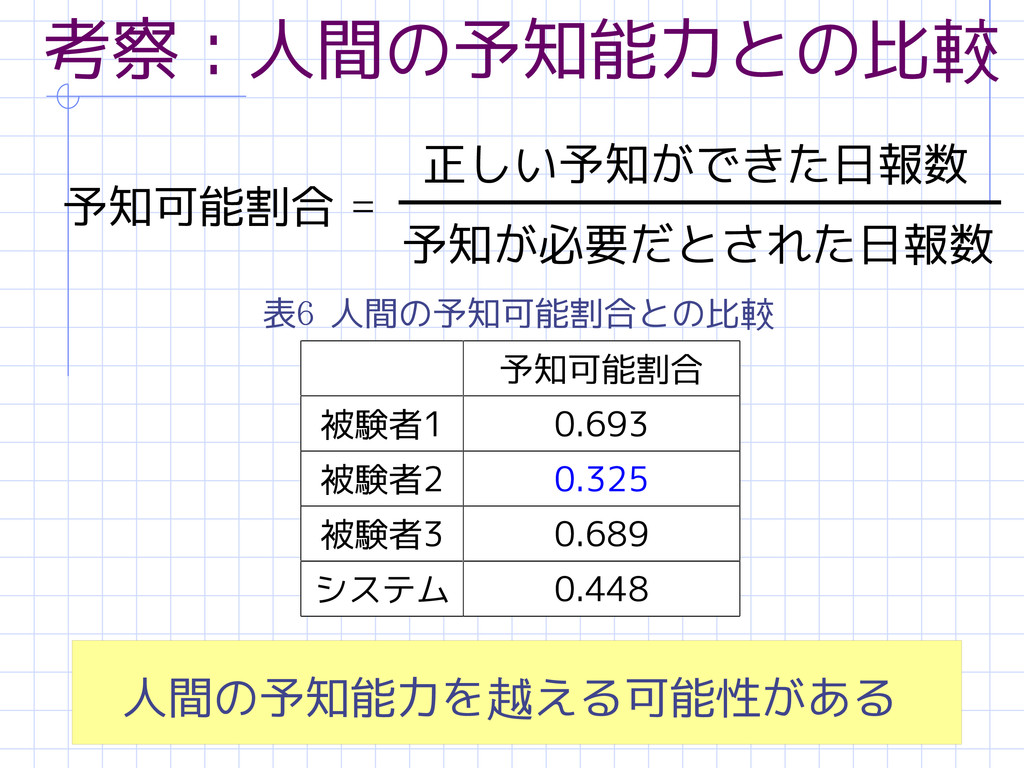
55 考察:人間の予知能力との比較 予知可能割合 = 予知が必要だとされた日報数 正しい予知ができた日報数 予知可能割合 被験者1 0.693 被験者2
0.325 被験者3 0.689 システム 0.448 人間の予知能力を越える可能性がある 表6 人間の予知可能割合との比較
56 考察:人間の予知との相違 人間が気付きにくい予知ほどいい予知 評価実験1で得た「人間による予知」と 「システムの出力した予知」を比較 比較した結果、 一致した予知は すべての被験者において一割程度 人間が気付きにくい予知を多く出力できた
57 まとめ:障害予知部 障害語辞書を用いた要予知日報判定 s 障害は悪い状況の集まりから生じる 対応付け手法を用いた障害の予知 要予知日報判定部の精度は0.622 障害予知部の精度は0.448 人間の予知能力を越える可能性 人間が気付きにくい予知を多く出力
58 まとめ:システム全体 障害予知システムを構築 s 障害情報の抽出 s 日報と障害情報の対応付け s 障害の予知 対応付け手法、障害予知手法共に
比較手法を越える精度 人間が気付きにくい予知を多く出力
59 発表おわり
60 岩山らの確率モデル s wi : ある単語 s P(f) : 予知情報辞書内の予知情報を取り出した時、
f となる確率 s P(wi ) : 予知情報辞書から要素を取り出した時、 wi となる確率 s P(wi |f) : 予知情報f から要素を取り出した時、 wi となる確率 s P(wi |d) : 予知情報d から要素を取り出した時、 w となる確率
61 ベクトル空間モデル
62 各ドメインの学習用日報数 ドメイン 学習用日報数 電話 41,917 カメラ 218,481 車 42,822
ゲーム 28,778 表7 各ドメインの学習用日報数
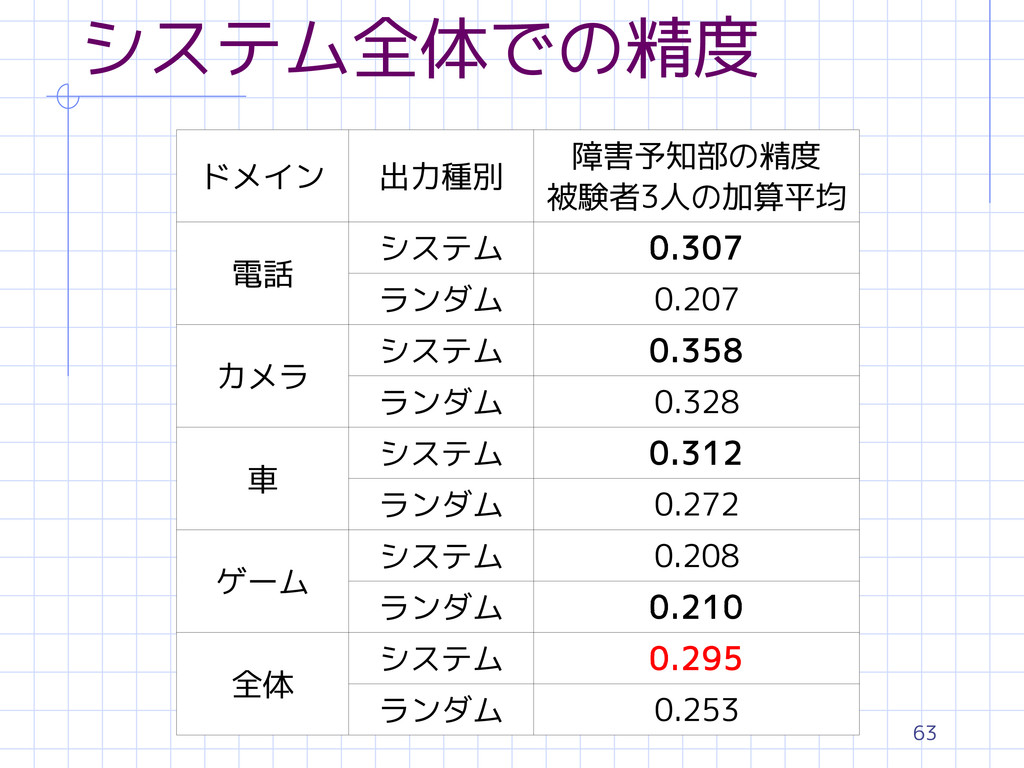
63 システム全体での精度 ドメイン 出力種別 障害予知部の精度 被験者3人の加算平均 電話 システム 0.307 ランダム
0.207 カメラ システム 0.358 ランダム 0.328 車 システム 0.312 ランダム 0.272 ゲーム システム 0.208 ランダム 0.210 全体 システム 0.295 ランダム 0.253
64 予知可能割合(各ドメイン) 予知可能割合 被験者3人の加算平均 電話 0.594 カメラ 0.595 車 0.551
ゲーム 0.520 「ゲーム」は日報に記載されている状況からは 障害を予知しにくい システムによる予知の精度も低かった
65 障害発生の喚起 「障害は起こり得ない」 とされた日報数 被験者3人の平均 評価実験1 75.7 評価実験2 66.7 予知の出力と一緒に提示することで
「障害は起こり得ない」日報数が減少 障害を喚起することができた
66 障害予知例 FMトランスミッタを使用する場合、雑音(ザー という音)が入り聞こえ方も悪くなります。た だ、手を本体に近づけると雑音がなくなり受信 状態も良くなります。このような症状で困って る方、改善方法、原因などお判りの方いらっし ゃいましたらアドバイスお願いします。 ノイズが ⇒
発生する オーディオが ⇒ 壊れる
67 障害予知例 D300を買って1ヶ月くらい経ちました。今日はじめてCF8G にフルになるまで撮影してきました。うまくとれてるかなぁ〜と撮 ったものをみてるとなんか白く点になってるところがある、これも これもこれも!!で昔撮ったものにも白い点が・・・2カ所ありま した。とりあえずキタムラさんに持って行って相談してニコン行き 決定しました。なおるのかなぁ〜なんか心配ですが新品交換よりも プロにみてもらって修理?した方が安心だよと店長さんが言ってく れたんでそれを信用することにします。皆さんのD300は大丈夫
ですか?また2週間後に使う予定なので間に合うように送るって言 ってくれました。間に合うかなぁ〜ううう。 人間 s 修理が2週間後に間に合わない システム s 液晶が ⇒ 割れる
68 構文片の利用[青木ら 2007] 係受け関係にある2文節を基としている 対象と状態の対を含むことができる 入力文: 古いパソコンのバッテリーがいきなり爆発した。 構文片: 古い ⇒
パソコン バッテリーが ⇒ 爆発する いきなり ⇒ 爆発する
69 構文片の利用[青木ら 2007] 係受け関係にある2文節を基としている 対象と状態の対を含むことができる 入力文: 古いパソコンのバッテリーがいきなり爆発した。 構文片: 古い ⇒
パソコン バッテリーが ⇒ 爆発する いきなり ⇒ 爆発する すべての構文片が 対象と状態の対を含むわけではない
70 関連研究:障害予知部 文書から障害を予知する研究はない 2つの出来事間の因果関係を推定する手法 入力文 : 私は、熱が出たため病院へ行った。 因果関係: 熱が出る(原因) ,
病院へ行く(結果) 因果関係を用いれば予知が可能となる可能性 しかし 人間にとって想像が容易な予知しかできない
71 文書分類による予知 文書分類を応用した予知によって 人間に障害を気付かせる役割 人間が容易に想像できる予知をしても 意味がない 人間が気付きにくい予知も可能
72 障害情報抽出手順 ドメイン別の大規模な日報データを与える 構文片を抽出する 前項がガ格を持たない場合、棄却する 前項が具体物を含むか判定する 後項が障害を示す単語を含むか判定する 後項が後項フィルタに含まれる場合、棄却する 障害情報辞書へ登録
73 ドメイン別 日報 障害情報辞書 障害日報 (T1) 障害日報 (T2) 障害日報 (T3)
・・・ 障害日報 (TN) 予知情報(T1) 予知情報(T2) 予知情報(T3) 予知情報(TN) ・・・ 予知情報辞書 入力日報 内容語集合 入力日報に起こりうる 障害情報 TN 各障害情報から予知情報を構築 内容語の抽出 確率モデルを用いた 類似度の計算 各障害情報(T1~N)を含む日報の収集
74 関連研究:SVMモデル 障害情報1 モデル1 モデル2 モデル3 モデル4 入力日報 分類先 日報郡
SVMモデル ◦ × × ◦ SVMによる 二値分類 障害情報2 障害情報3 障害情報4 障害情報1 障害情報2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![9 関連研究:障害情報抽出部 人手による辞書を用いる手法 [市村ら 2001] s 日報から「製品名」「要因概念」「結果概念」 を抽出 構文パタンを用いる手法 [斎藤ら](https://files.speakerdeck.com/presentations/d2ec0700c5e701304cb54a53e4d87d3a/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![18 障害語辞書の構築 統計的情報を用いる 藤村らの手法を参考とした [藤村ら 2005] 単語の出現の偏り:-1 ~ +1 s](https://files.speakerdeck.com/presentations/d2ec0700c5e701304cb54a53e4d87d3a/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
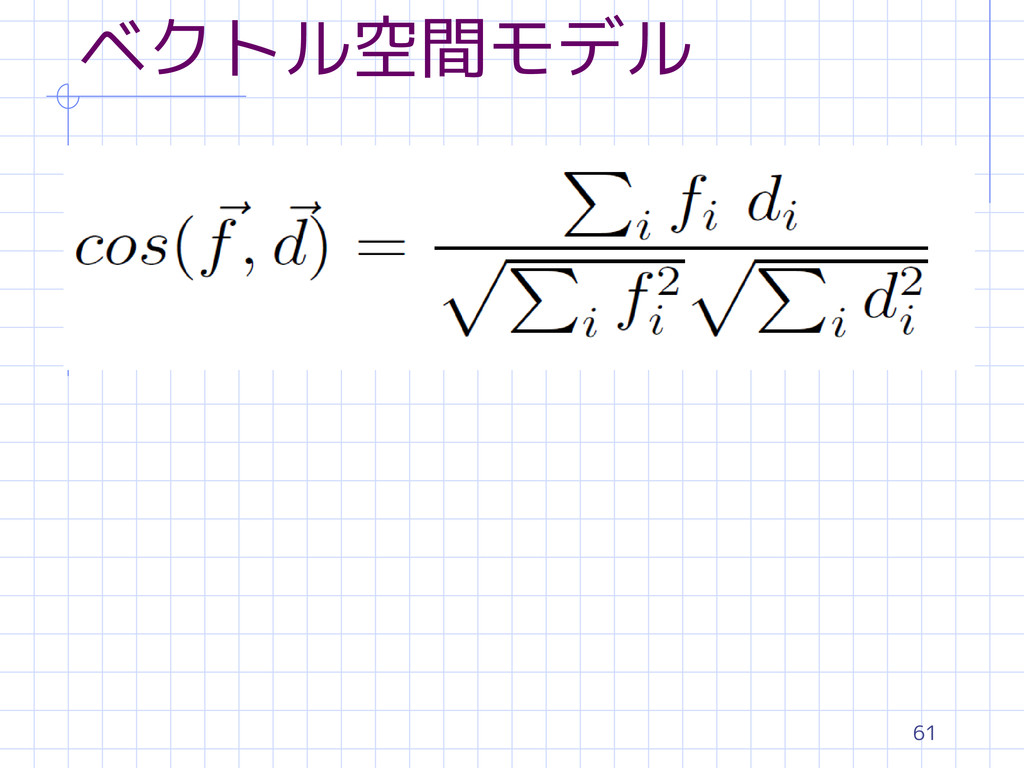{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![68 構文片の利用[青木ら 2007] 係受け関係にある2文節を基としている 対象と状態の対を含むことができる 入力文: 古いパソコンのバッテリーがいきなり爆発した。 構文片: 古い ⇒](https://files.speakerdeck.com/presentations/d2ec0700c5e701304cb54a53e4d87d3a/slide_67.jpg){kind=link}
![69 構文片の利用[青木ら 2007] 係受け関係にある2文節を基としている 対象と状態の対を含むことができる 入力文: 古いパソコンのバッテリーがいきなり爆発した。 構文片: 古い ⇒](https://files.speakerdeck.com/presentations/d2ec0700c5e701304cb54a53e4d87d3a/slide_68.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}