Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
統計的機械翻訳における地名の汎化の影響
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
March 31, 2009
Research
91
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
統計的機械翻訳における地名の汎化の影響
関 拓也. 統計的機械翻訳における地名の汎化の影響. 長岡技術科学大学課題研究報告書 (2009.3)
自然言語処理研究室
March 31, 2009
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
410
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
第66回コンピュータビジョン勉強会@関東 Epona: Autoregressive Diffusion World Model for Autonomous Driving
kentosasaki
0
630
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
290
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
3.8k
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
620
Harness Engineering and Al Agent
kzinmr
3
1.7k
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.7k
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
330
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
370
AIで最適化を解けるか?
mickey_kubo
0
120
羽田新ルート運用6年の検証
1manken
0
160
The mathematics of transformers
gpeyre
0
340
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
290
Featured
See All Featured
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.3k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Raft: Consensus for Rubyists
vanstee
141
7.5k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
400
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Site-Speed That Sticks
csswizardry
13
1.2k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
240
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
220
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
630
For a Future-Friendly Web
brad_frost
183
10k
The SEO identity crisis: Don't let AI make you average
varn
0
490
Transcript
1 統計的機械翻訳における 地名の汎化の影響 長岡技術科学大学 電気系 山本研究室 05131586 関 拓也
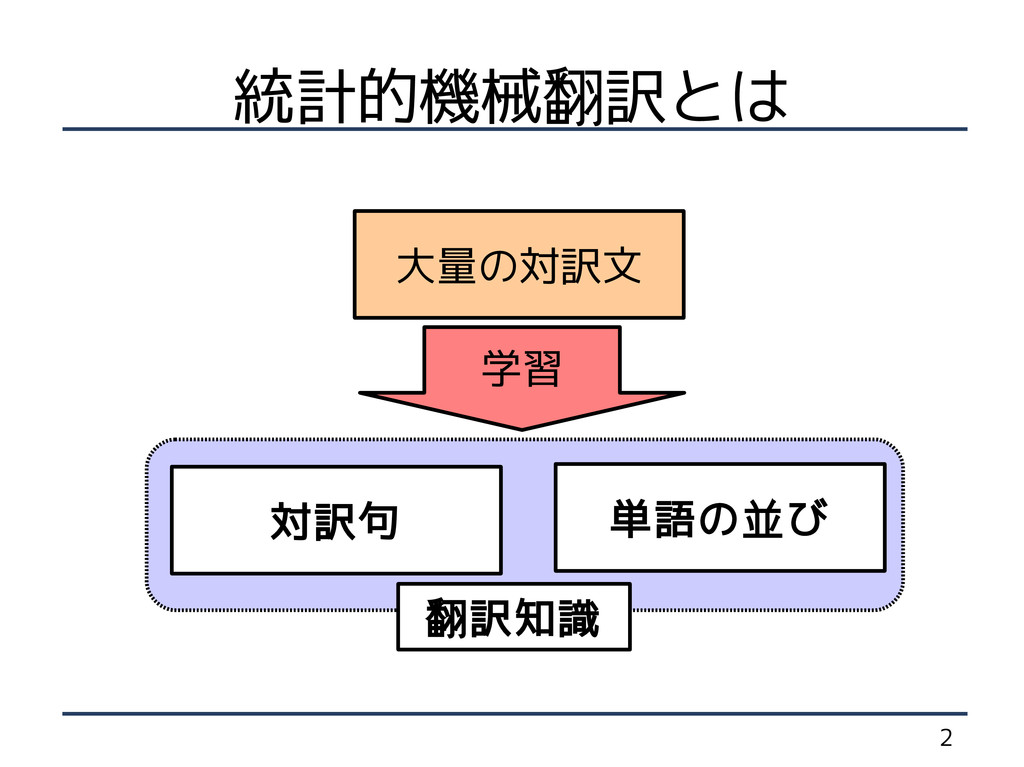
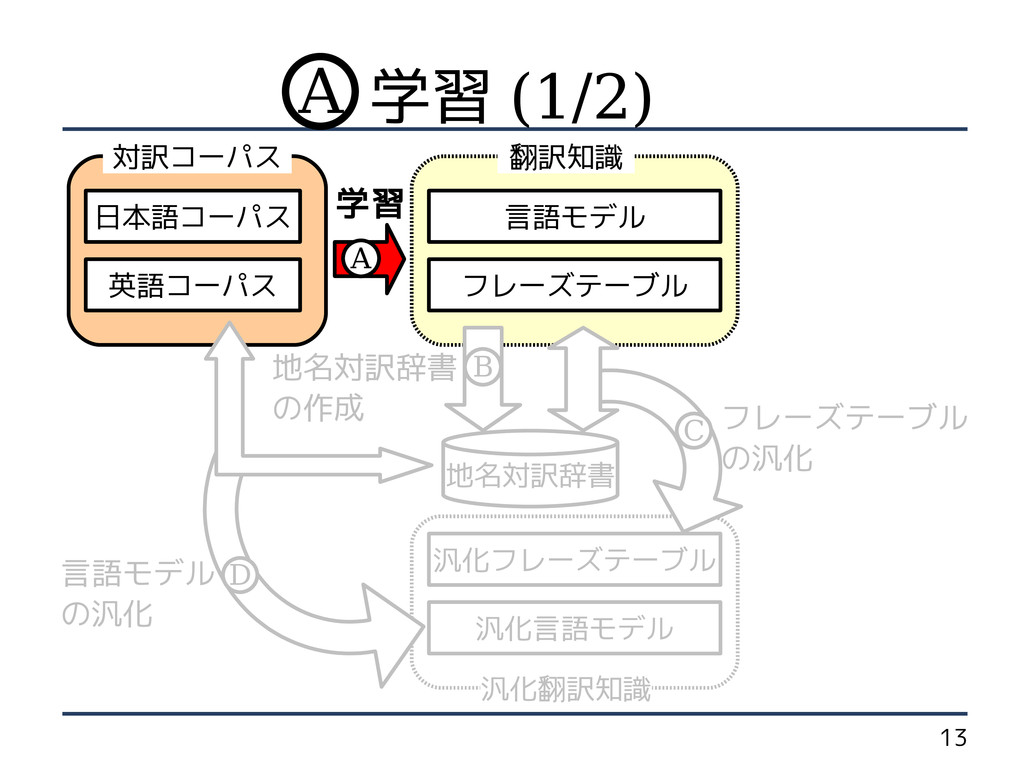
2 統計的機械翻訳とは 大量の対訳文 対訳句 単語の並び 学習 翻訳知識
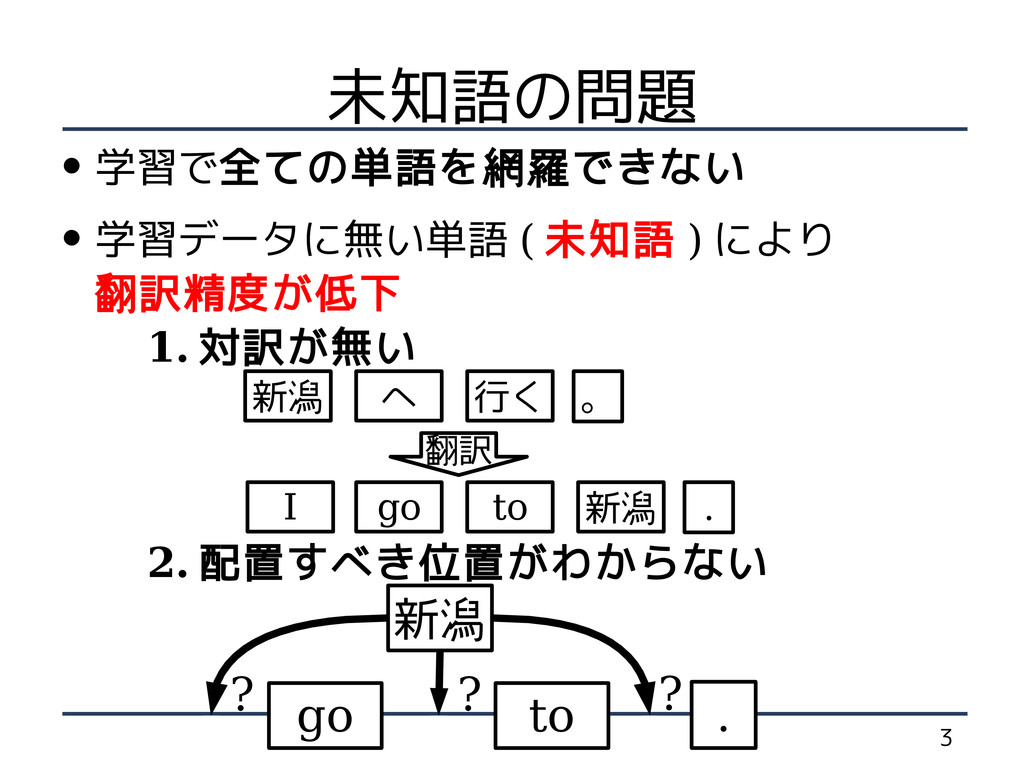
3 未知語の問題 • 学習で全ての単語を網羅できない • 学習データに無い単語 ( 未知語 ) により
翻訳精度が低下 1. 対訳が無い 2. 配置すべき位置がわからない 新潟 go to ? ? ? . go to . 新潟 新潟 へ 。 行く I 翻訳
4 目的及び既存手法 • 目的 未知の地名を含む文の翻訳精度改善 • 既存手法 ( 大熊ら [2007])
1) 未知の地名を学習データに 頻出する地名に置き換えて翻訳 2) 置き換えた地名を目的の地名に 置き換える
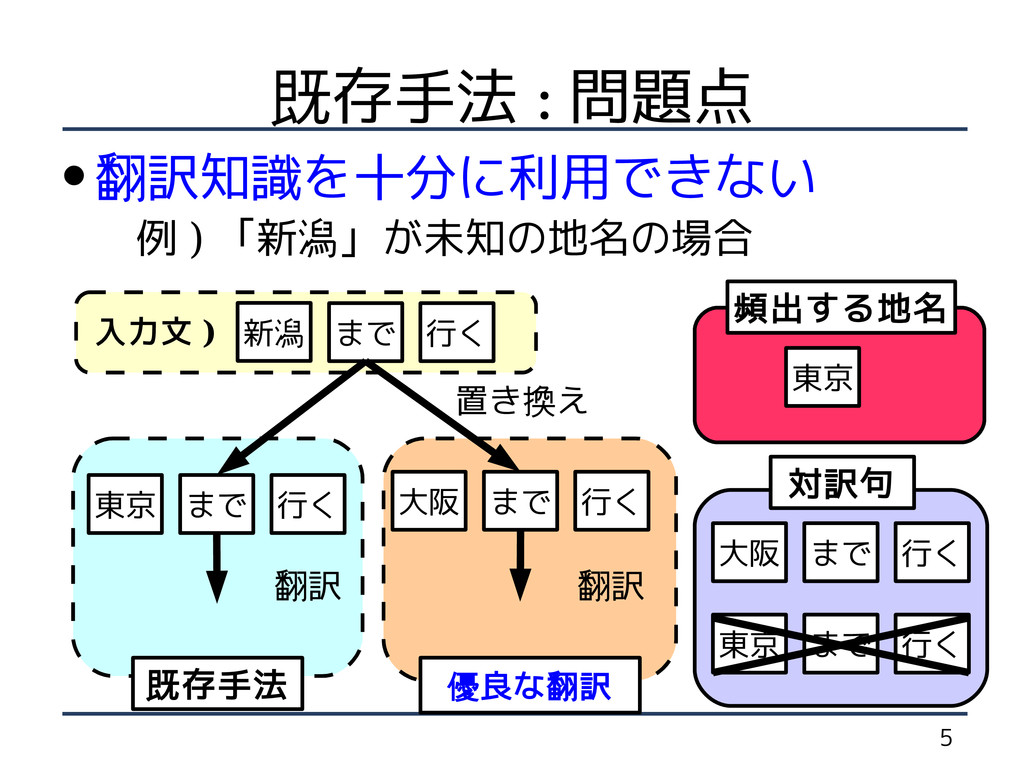
5 既存手法 : 問題点 • 翻訳知識を十分に利用できない 例 ) 「新潟」が未知の地名の場合
新潟 まで 行く 大阪 まで 行く 対訳句 置き換え 東京 頻出する地名 東京 まで 行く 翻訳 既存手法 大阪 まで 行く 翻訳 優良な翻訳 東京 まで 行く 入力文 )
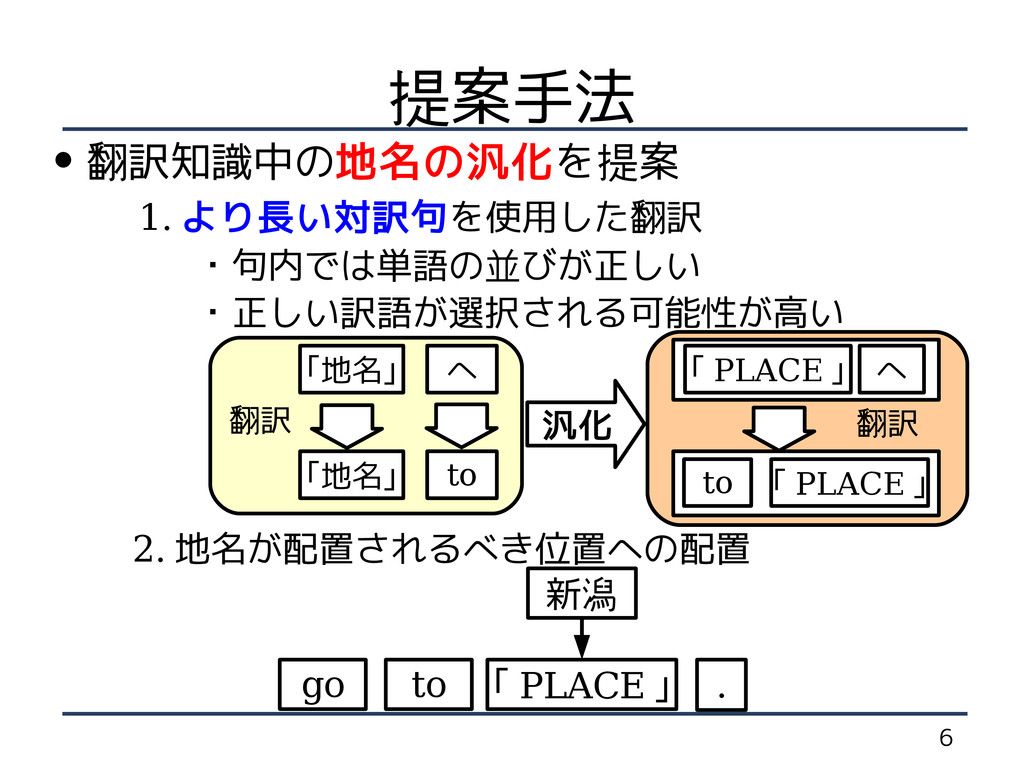
6 提案手法 • 翻訳知識中の地名の汎化を提案 1. より長い対訳句を使用した翻訳 ・句内では単語の並びが正しい ・正しい訳語が選択される可能性が高い
2. 地名が配置されるべき位置への配置 「 PLACE 」 go to . 新潟 「地名」 へ 汎化 「 PLACE 」 へ 翻訳 翻訳 「地名」 to 「 PLACE 」 to
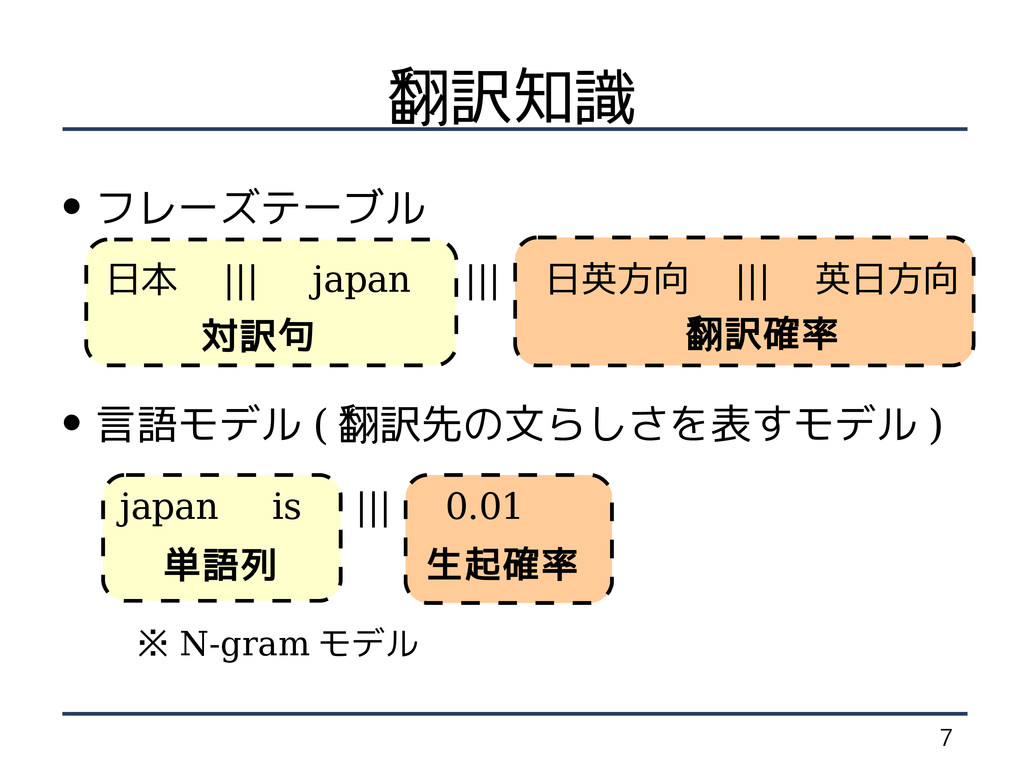
7 • フレーズテーブル • 言語モデル ( 翻訳先の文らしさを表すモデル ) ※ N-gram
モデル 翻訳知識 日本 ||| japan ||| 日英方向 ||| 英日方向 対訳句 翻訳確率 japan is ||| 0.01 単語列 生起確率
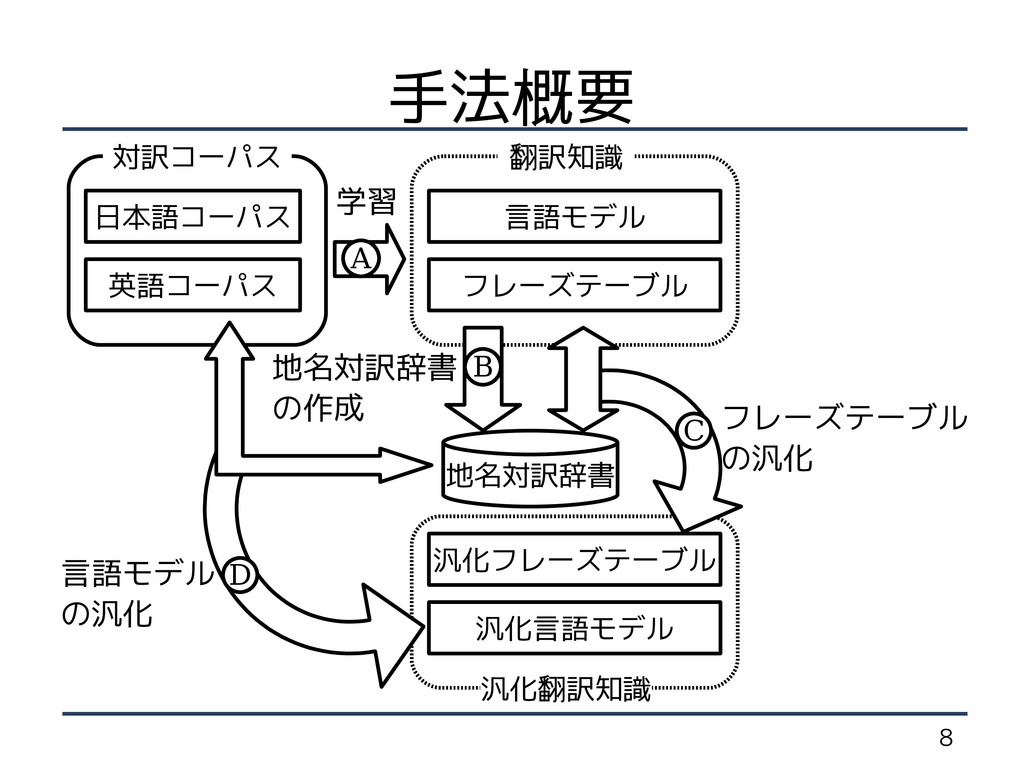
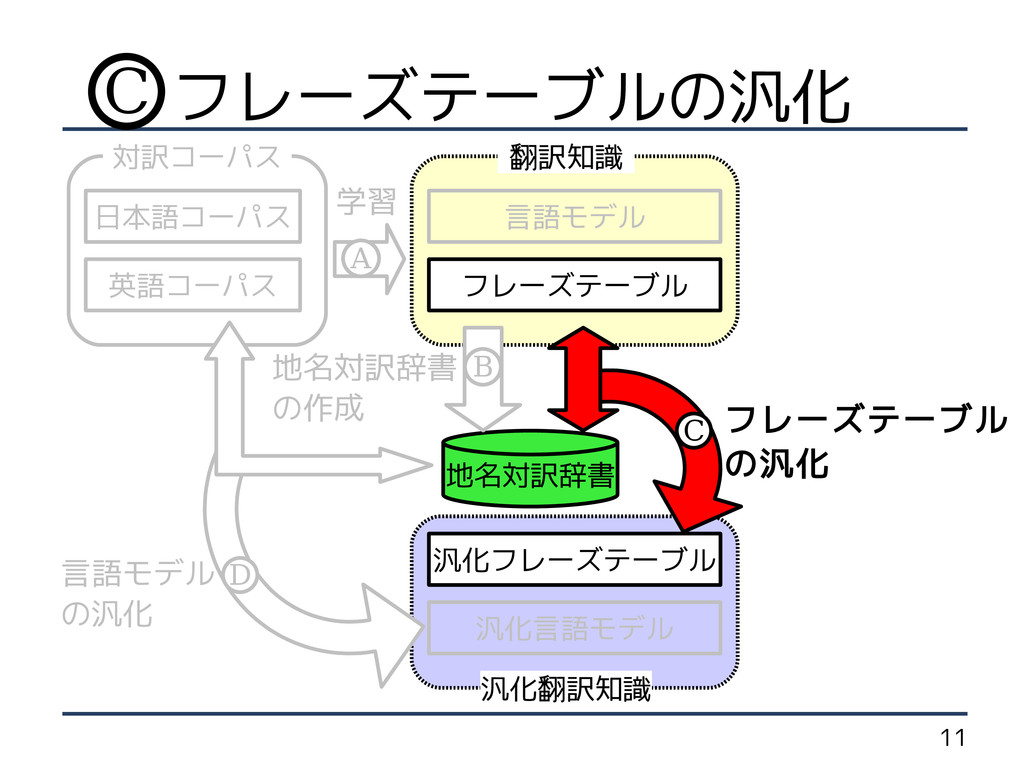
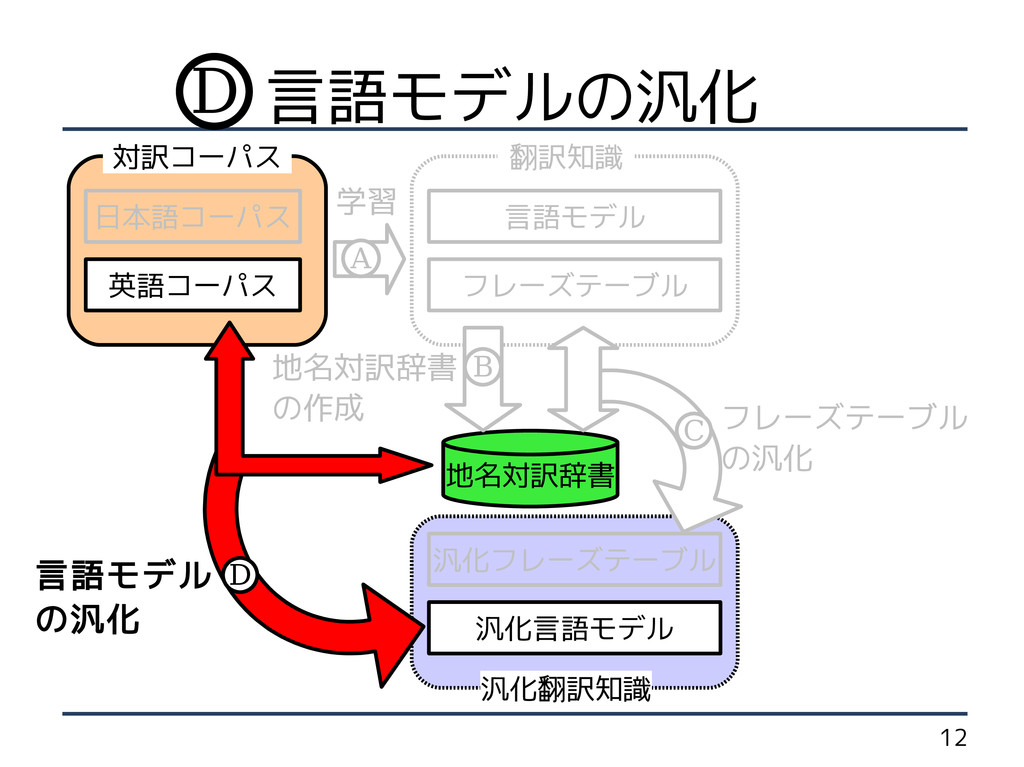
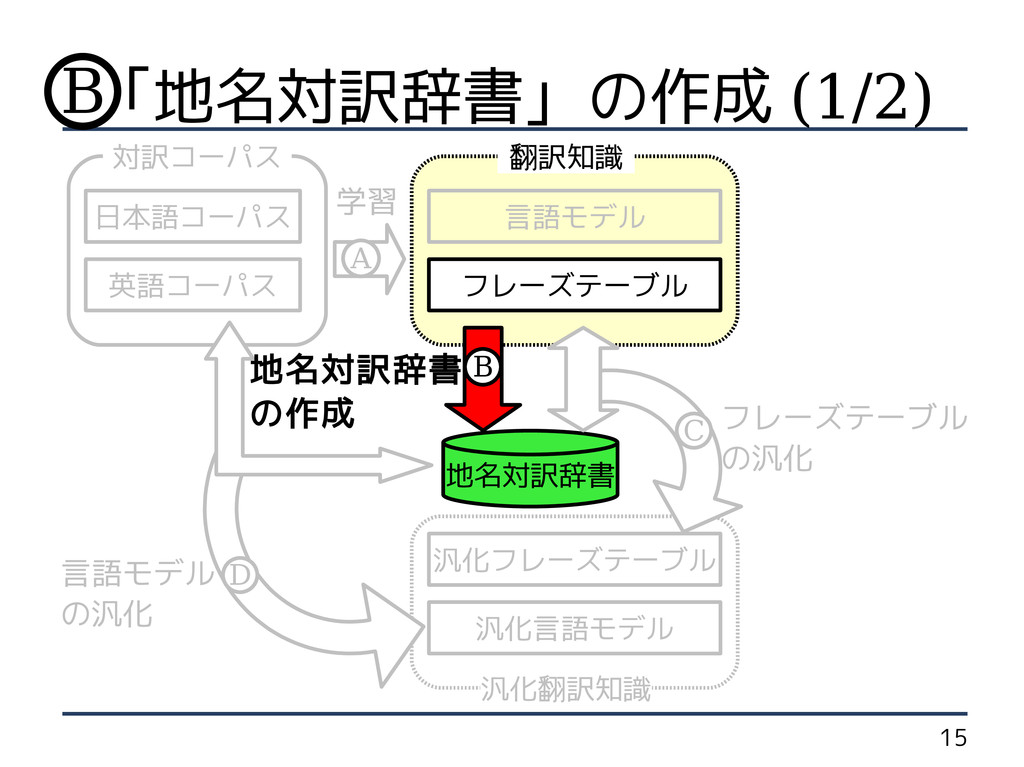
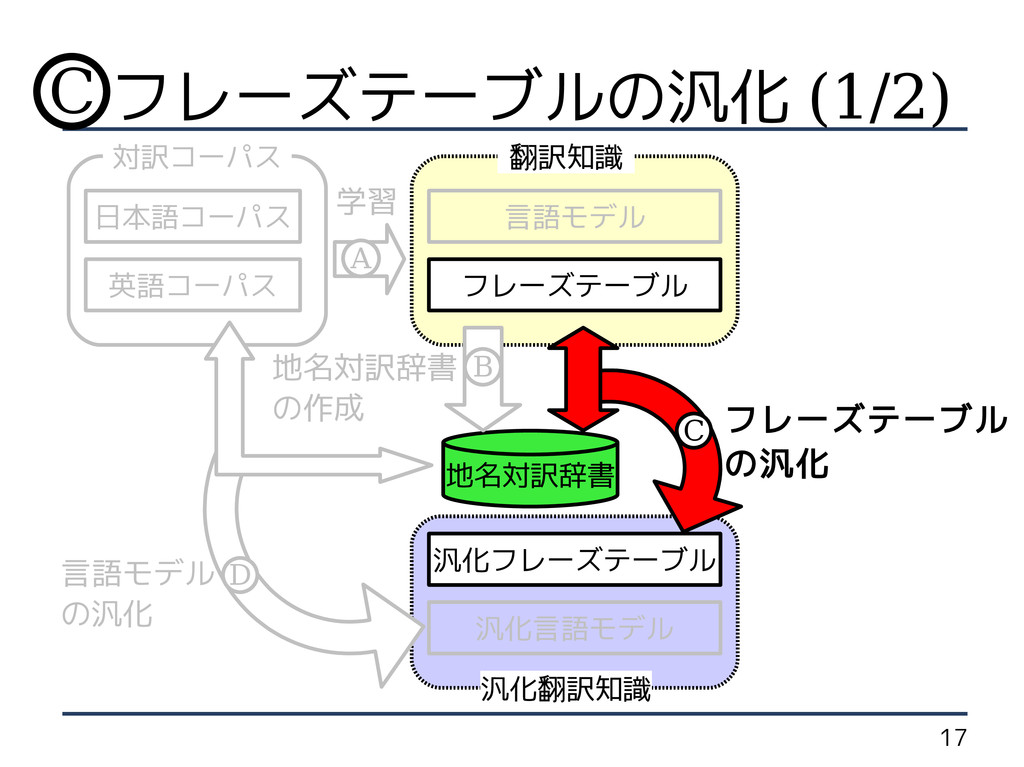
8 手法概要 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス
地名対訳辞書 の作成 英語コーパス フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス B C D 学習 A
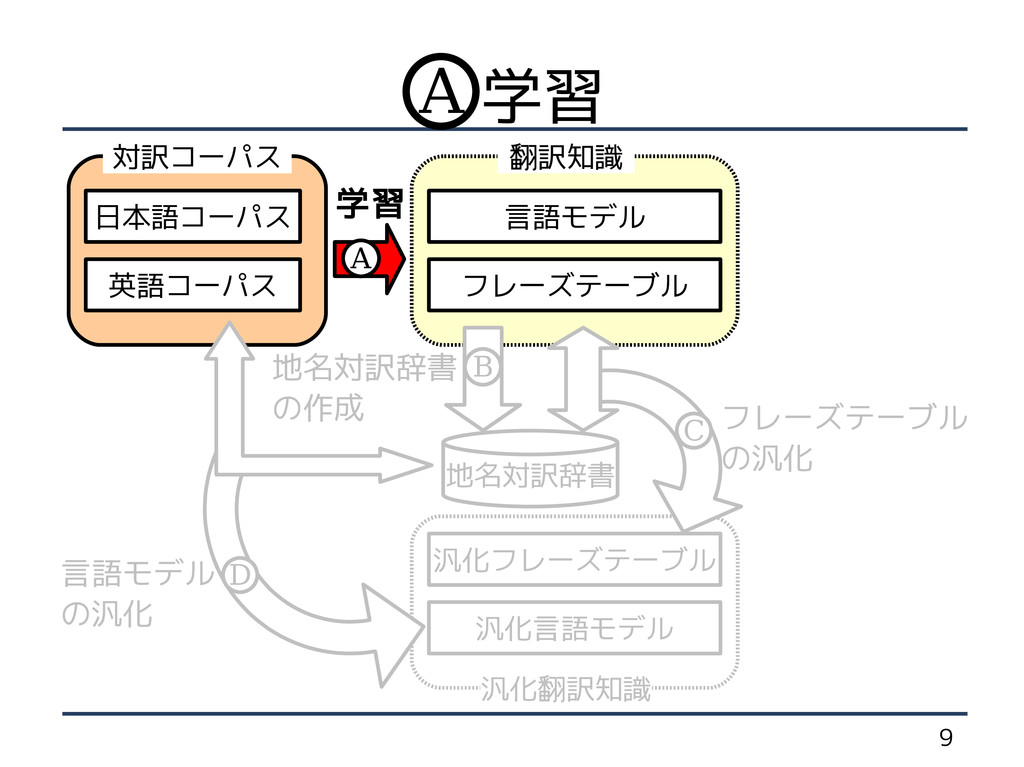
9 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス 地名対訳辞書
の作成 英語コーパス フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス B C D 学習 A 学習 A
10 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス 英語コーパス
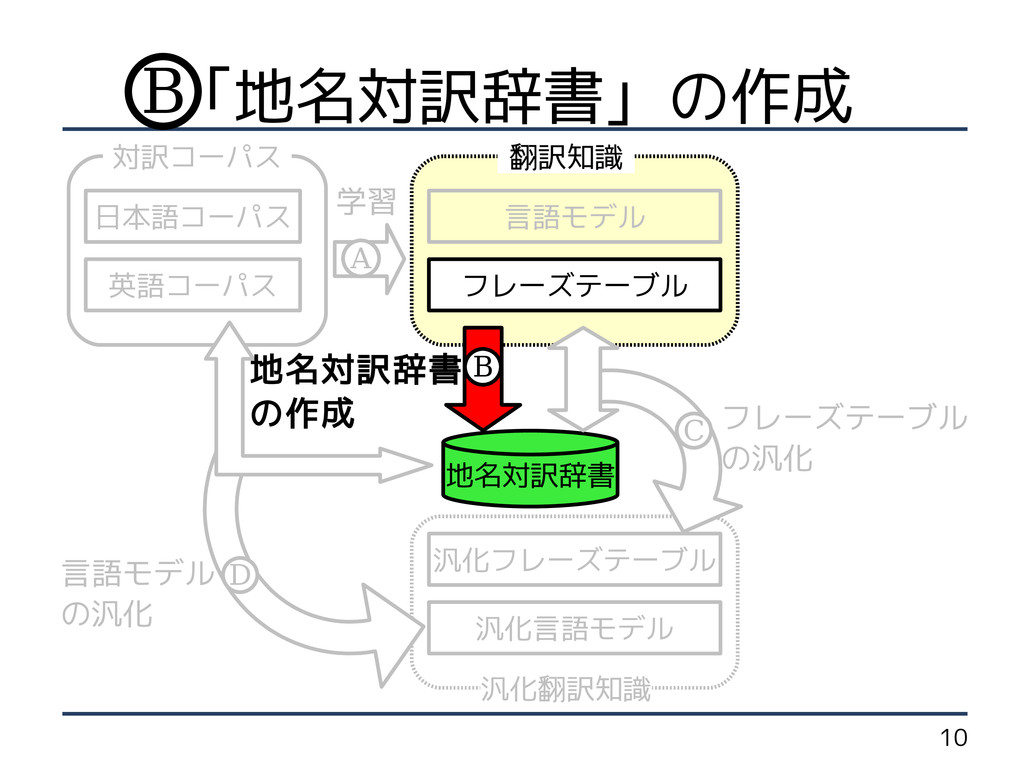
フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス B C D 学習 A 「地名対訳辞書」の作成 B 地名対訳辞書 の作成
11 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス 地名対訳辞書
の作成 英語コーパス フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス B C D 学習 A フレーズテーブルの汎化 C
12 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス 地名対訳辞書
の作成 英語コーパス フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス B C D 学習 A 言語モデルの汎化 D
13 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス 地名対訳辞書
の作成 英語コーパス フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス B C D 学習 A 学習 (1/2) A
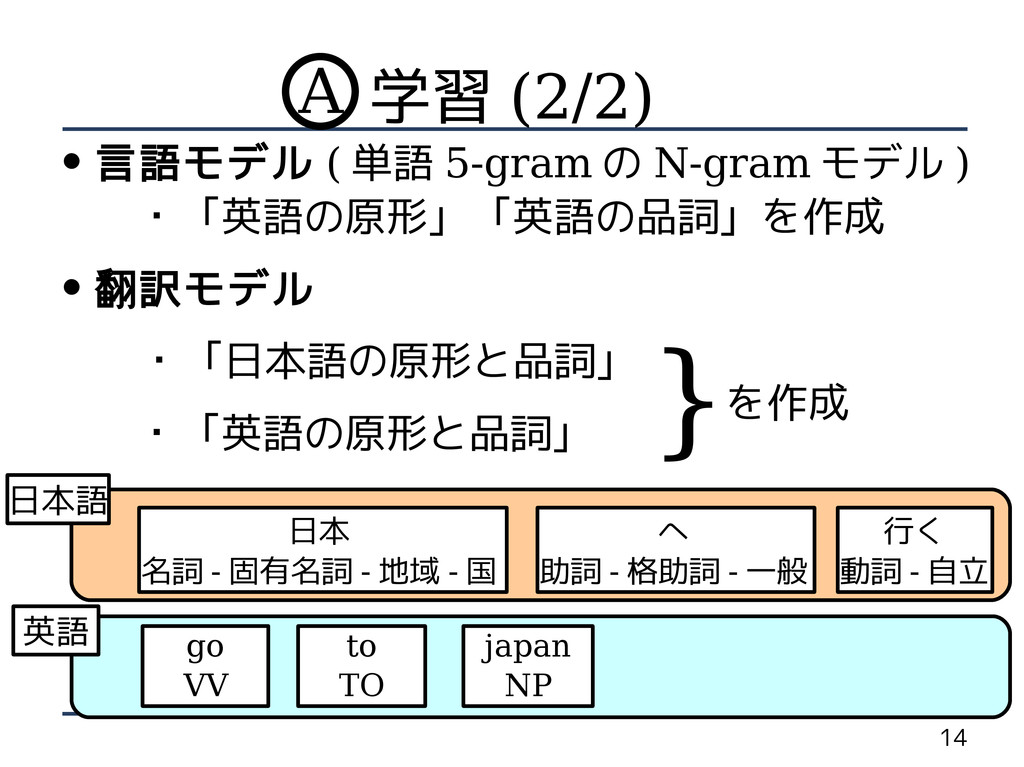
14 学習 (2/2) • 言語モデル ( 単語 5-gram の N-gram
モデル ) ・「英語の原形」「英語の品詞」を作成 • 翻訳モデル ・「日本語の原形と品詞」 ・「英語の原形と品詞」 日本 名詞 - 固有名詞 - 地域 - 国 へ 助詞 - 格助詞 - 一般 行く 動詞 - 自立 go VV to TO japan NP 英語 日本語 }を作成 A
15 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス 英語コーパス
フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス B C D 学習 A 「地名対訳辞書」の作成 (1/2) B 地名対訳辞書 の作成
16 「地名対訳辞書」の作成 (2/2) • フレーズテーブルを用いて作成 1. 「日本語 1 単語」−「英語
1 単語」対応の句 2. 日本語の品詞が ・「名詞 - 固有名詞 - 地域 - 一般」 ・「名詞 - 固有名詞 - 地域 - 国」 3. 英語の品詞が ・「 N( 名詞 ) 」 ・「 J( 形容詞 ) 」 4. 「日英方向」と「英日方向」の 翻訳確率の積が 0.01 以上 B
17 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス 地名対訳辞書
の作成 英語コーパス フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス B C D 学習 A フレーズテーブルの汎化 (1/2) C
18 フレーズテーブルの汎化 (2/2) • 「地名対訳辞書」を用いて汎化 ・日本語句内の地名を「 PLACE|PLACE 」 ・英語句内の地名を ・「
PLACE|N 」 ・「 PLACE| J 」 日本 | 名詞 - 固有名詞 - 地域 - 国 japan|NP PLACE|PLACE PLACE|N 日本語 英語 汎化 C
19 汎化言語モデル 汎化フレーズテーブル フレーズテーブル 汎化翻訳知識 言語モデル 地名対訳辞書 翻訳知識 対訳コーパス 地名対訳辞書
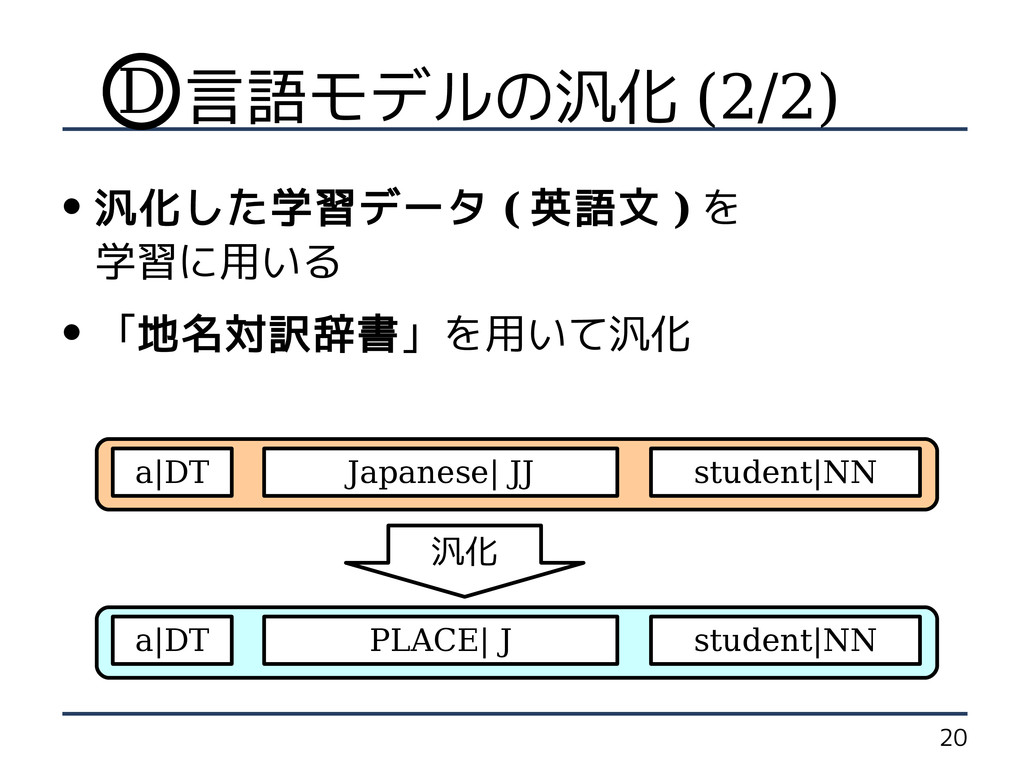
の作成 英語コーパス フレーズテーブル の汎化 言語モデル の汎化 日本語コーパス B C D 学習 A 言語モデルの汎化 (1/2) D
20 言語モデルの汎化 (2/2) • 汎化した学習データ ( 英語文 ) を 学習に用いる
• 「地名対訳辞書」を用いて汎化 Japanese| JJ student|NN a|DT 汎化 PLACE| J student|NN a|DT D D
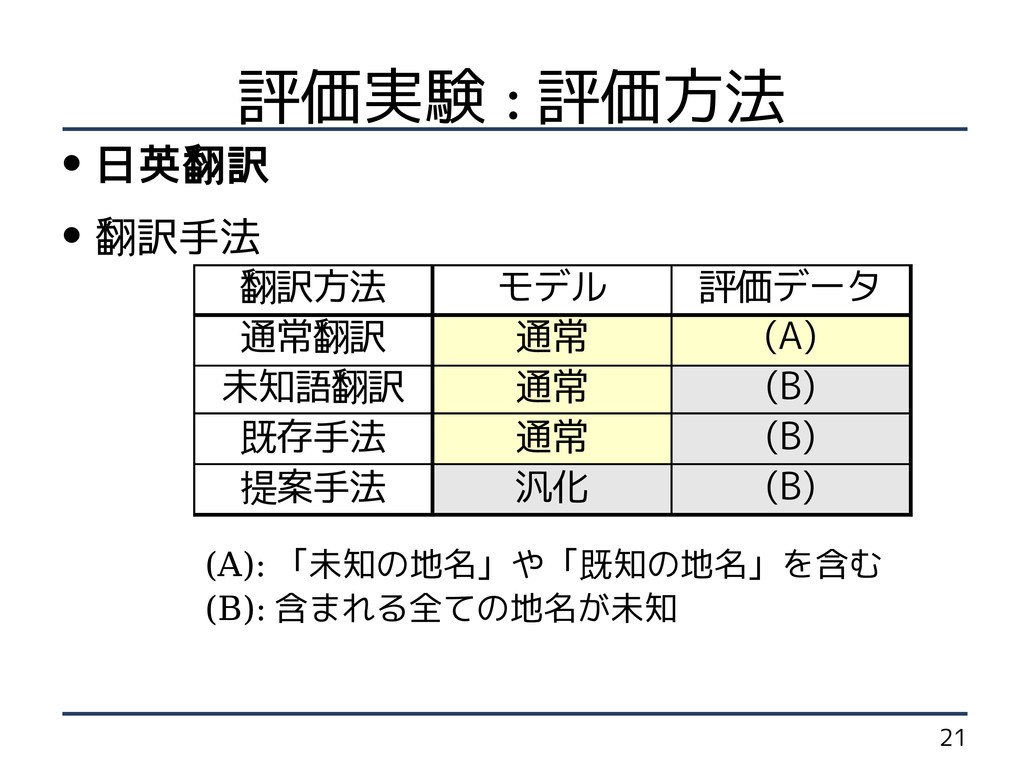
21 評価実験 : 評価方法 • 日英翻訳 • 翻訳手法
(A): 「未知の地名」や「既知の地名」を含む (B): 含まれる全ての地名が未知 翻訳方法 モデル 評価データ 通常翻訳 通常 (A) 未知語翻訳 通常 (B) 既存手法 通常 (B) 提案手法 汎化 (B)
22 評価実験 : 使用データ • 学習データ ( 対訳文 )
・ CREST コーパス: 372,985 文対 • 評価データ ( 地名を含む対訳文 ) ・学習に含まれない (open) 対訳文 1000 対 • 評価方法 ・ BLEU による翻訳精度の自動評価 ※ BLEU 値が高い方が翻訳精度は高い。
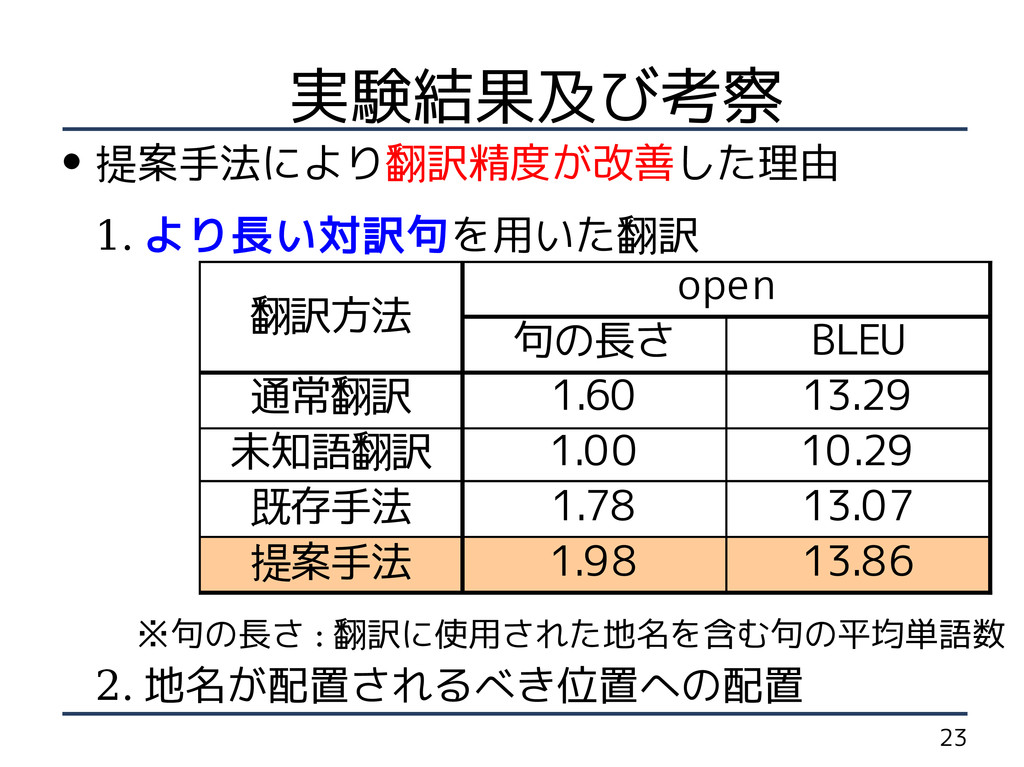
23 実験結果及び考察 • 提案手法により翻訳精度が改善した理由 1. より長い対訳句を用いた翻訳 ※句の長さ :
翻訳に使用された地名を含む句の平均単語数 2. 地名が配置されるべき位置への配置 翻訳方法 open 句の長さ BLEU 通常翻訳 1.60 13.29 未知語翻訳 1.00 10.29 既存手法 1.78 13.07 提案手法 1.98 13.86
24 考察:「地名対訳辞書」の問題 • 地名を含む対訳句の内 45.0% しか汎化できていない • 原因 ・学習データに頻出する
1 対多対訳の「地名」が未登録 例 ) 「ニューヨーク」 | 「 new york 」
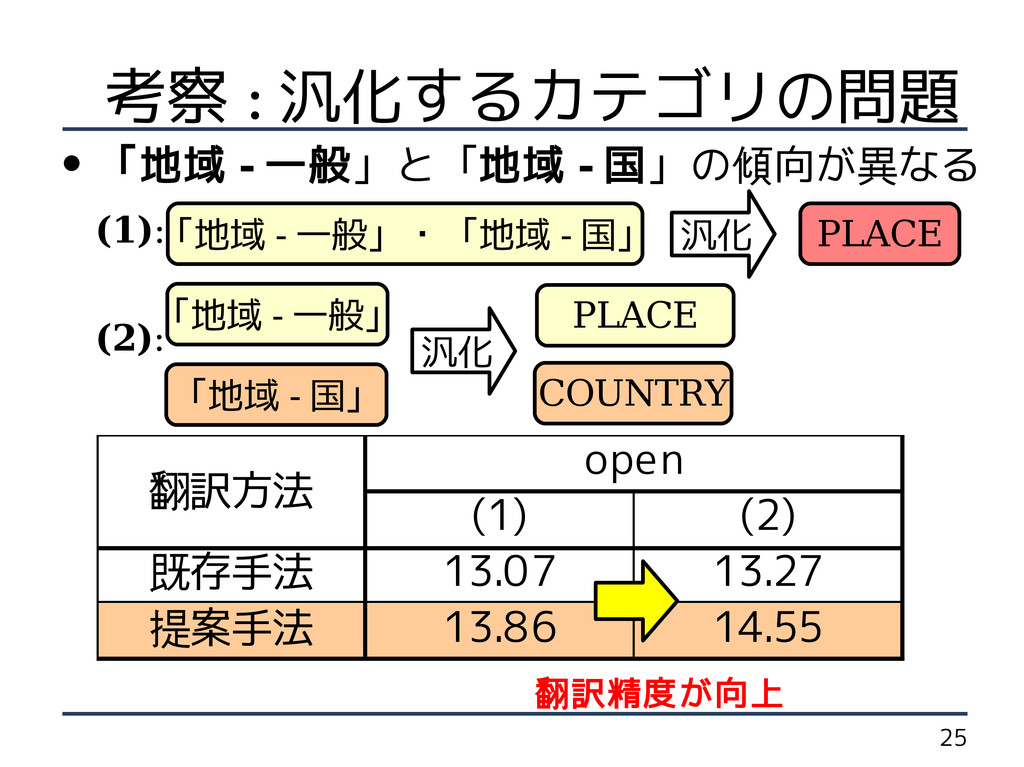
25 翻訳方法 open (1) (2) 既存手法 13.07 13.27 提案手法 13.86
14.55 • 「地域 - 一般」と「地域 - 国」の傾向が異なる (1): (2): 翻訳精度が向上 「地域 - 一般」・「地域 - 国」 「地域 - 一般」 汎化 PLACE 「地域 - 国」 汎化 COUNTRY PLACE 考察 : 汎化するカテゴリの問題
26 • 未知の地名を含む文の翻訳精度改善に有効 ・より長い句を用いた翻訳 ・地名が配置されるべき位置への配置 • 提案手法の改善のために ・「地名対訳辞書」の網羅性を上げる
・適切なカテゴリに単語を分け、 別々に汎化を行う まとめ
27 終わり
28 使用ツール及び言語資源 • デコーダ :Moses • 単語アライメント :GIZA++ • 言語モデル
:IRST LM • 日本語形態素解析 :ChaSen • 英語形態素解析 :TreeTagger • 対訳コーパス :CREST コーパス 372,985 文対 • 対訳辞書 : 英辞郎
{kind=link}
{kind=link}
{kind=link}
![4 目的及び既存手法 • 目的 未知の地名を含む文の翻訳精度改善 • 既存手法 ( 大熊ら [2007])](https://files.speakerdeck.com/presentations/e9e3b610c5e70130e9bc52af6d195c7e/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}