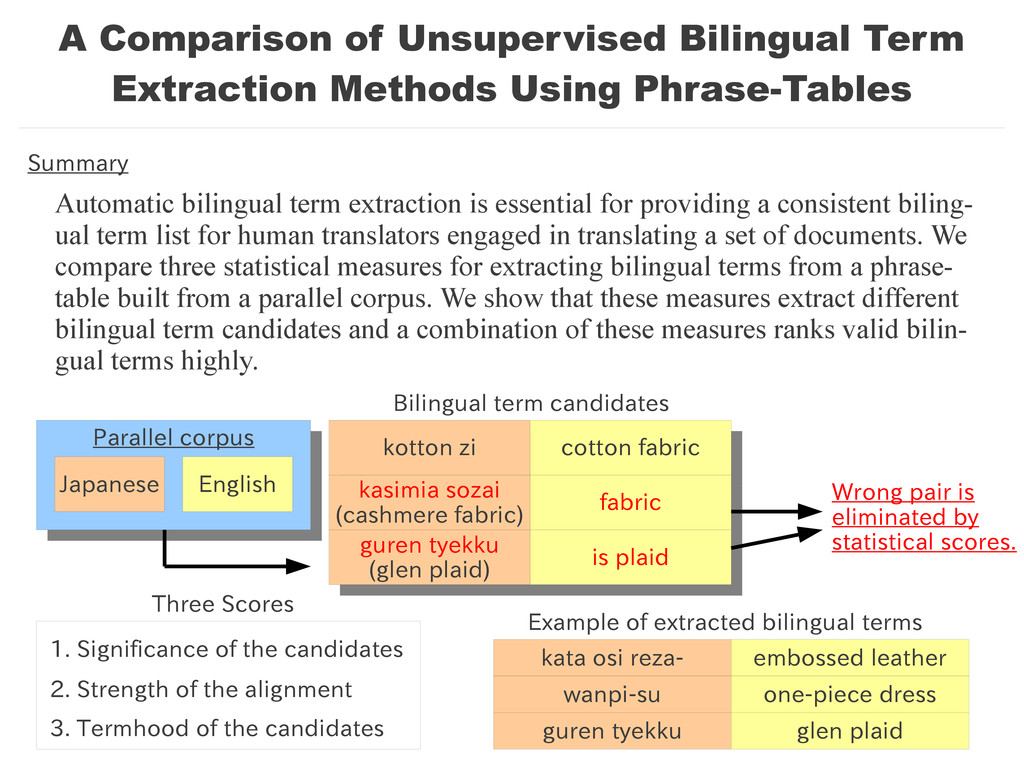
Automatic bilingual term extraction is essential for providing a consistent biling- ual term list for human translators engaged in translating a set of documents. We compare three statistical measures for extracting bilingual terms from a phrase- table built from a parallel corpus. We show that these measures extract different bilingual term candidates and a combination of these measures ranks valid bilin- gual terms highly. Summary Parallel corpus Parallel corpus Japanese English kotton zi kotton zi cotton fabric cotton fabric kasimia sozai (cashmere fabric) kasimia sozai (cashmere fabric) fabric fabric guren tyekku (glen plaid) guren tyekku (glen plaid) is plaid is plaid Wrong pair is eliminated by statistical scores. Three Scores 1. Significance of the candidates 2. Strength of the alignment 3. Termhood of the candidates Bilingual term candidates kata osi reza- embossed leather Example of extracted bilingual terms wanpi-su one-piece dress guren tyekku glen plaid
Western Asia, where its wild ancestor, the Alma, is still found today. There are more than 7,500 known cultivars of apples, resulting in a range of desired characteristics… Apple What contents about apple are in the text? • Originate • Tree • Cultivar Descriptive Elements The main purpose here is identification factors that affect the relationship between query and text. Purpose We challenge to assign Descriptive Elements to text. Descriptive Elements are contents of the text. As a result, we find few points to assign Descriptive Elements. Experiments and Results
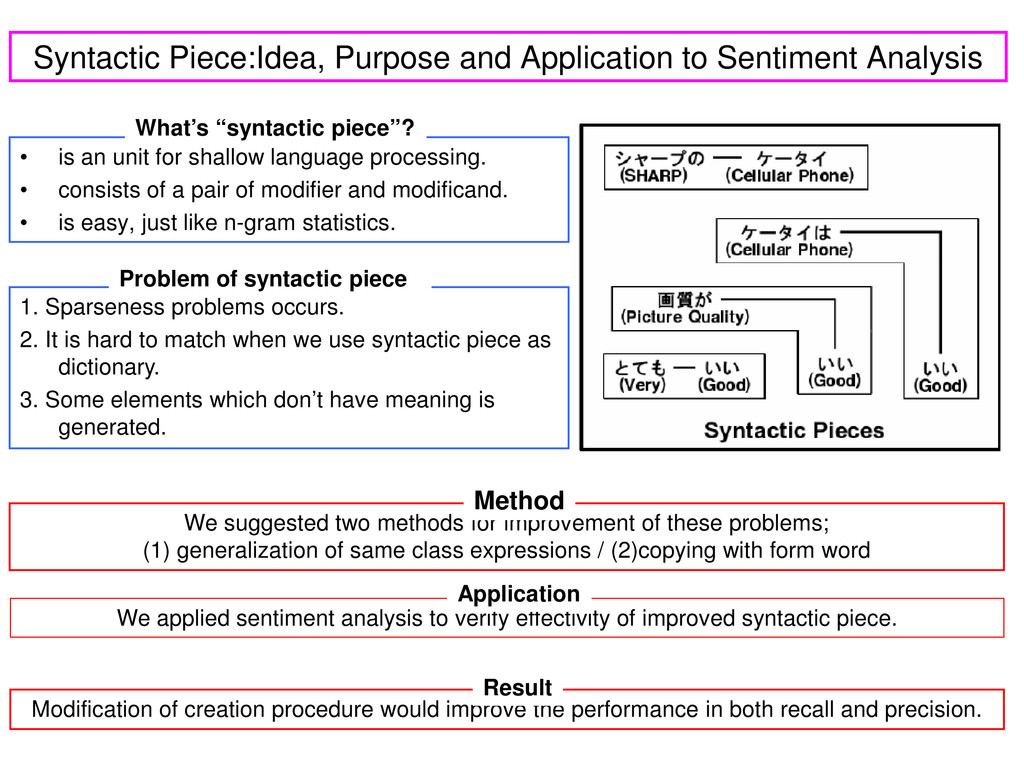
an unit for shallow language processing. • consists of a pair of modifier and modificand. • is easy, just like n-gram statistics. 1. Sparseness problems occurs. 2. It is hard to match when we use syntactic piece as dictionary. 3. Some elements which don’t have meaning is generated. Problem of syntactic piece We suggested two methods for improvement of these problems; (1) generalization of same class expressions / (2)copying with form word Method We applied sentiment analysis to verify effectivity of improved syntactic piece. Application Modification of creation procedure would improve the performance in both recall and precision. Result What’s “syntactic piece”?
特徴語抽出手法を比較した。 入力文: サーカスと動物園、どっちに行こうか (疑問) ベースライン:Let's go to the circus and, the zoo? (肯定・不正解) 提案手法: Which one shall we go to the circus and Zoo? (疑問・正解)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}