Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
音声翻訳において音声認識出力の詳細度は最終結果にどう影響するか?
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
March 31, 2005
Research
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
音声翻訳において音声認識出力の詳細度は最終結果にどう影響するか?
音声翻訳において音声認識出力の詳細度は最終結果にどう影響するか?
自然言語処理研究室
March 31, 2005
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
LLM Compute Infrastructure Overview
karakurist
2
1.5k
コーディングエージェントとABNを再考
hf149
2
730
Language and AI
ayaniwa
0
140
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.2k
2026年1月の生成AI領域の重要リリース&トピック解説
kajikent
0
1k
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
580
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
240
「AIとWhyを深堀る」をAIと深堀る
iflection
0
500
typst の使い方:言語学を研究する学生のために
gitomochang
0
460
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
200
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.7k
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
640
Featured
See All Featured
Music & Morning Musume
bryan
47
7.2k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
260
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
370
How GitHub (no longer) Works
holman
316
150k
The Cost Of JavaScript in 2023
addyosmani
55
10k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
260
Abbi's Birthday
coloredviolet
3
8.2k
A Soul's Torment
seathinner
6
3k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
610
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.5k
30 Presentation Tips
portentint
PRO
1
330
GitHub's CSS Performance
jonrohan
1033
470k
Transcript
音声翻訳において 音声認識出力の詳細度は 最終結果にどう影響するか? 沢井 康孝 長岡技術科学大学 電気系 菊井 玄一郎 山本
博史 ATR 音声言語コミュニケーション研究所
音声翻訳システム • ATR 音声翻訳システムの構成 音声認識 自動翻訳 音声合成 認識結果 ( 橋
, ハシ , 橋 , 普通名詞 ,- ...) 翻訳結果 音声 音声 音響モデル: HMM 言語モデル: N グラム 統計翻訳( IBM モデル4)
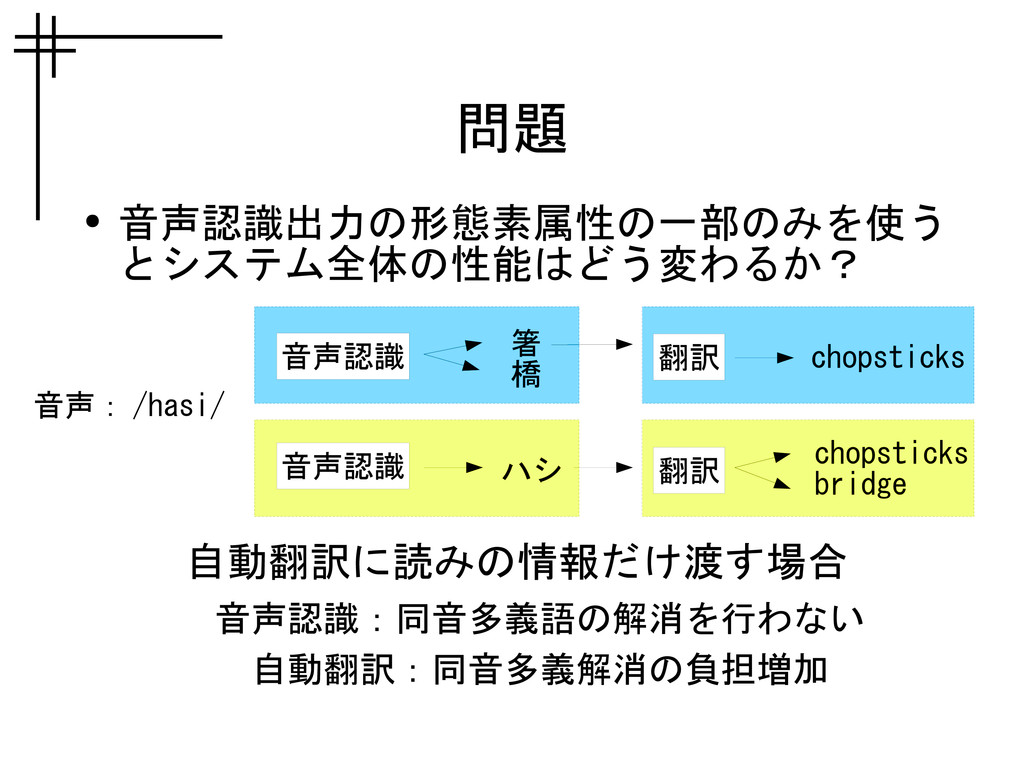
問題 • 音声認識出力の形態素属性の一部のみを使う とシステム全体の性能はどう変わるか? 自動翻訳に読みの情報だけ渡す場合 音声認識:同音多義語の解消を行わない 自動翻訳:同音多義解消の負担増加 音声: /hasi/ 箸
橋 chopsticks 音声認識 翻訳 ハシ chopsticks bridge 翻訳 音声認識
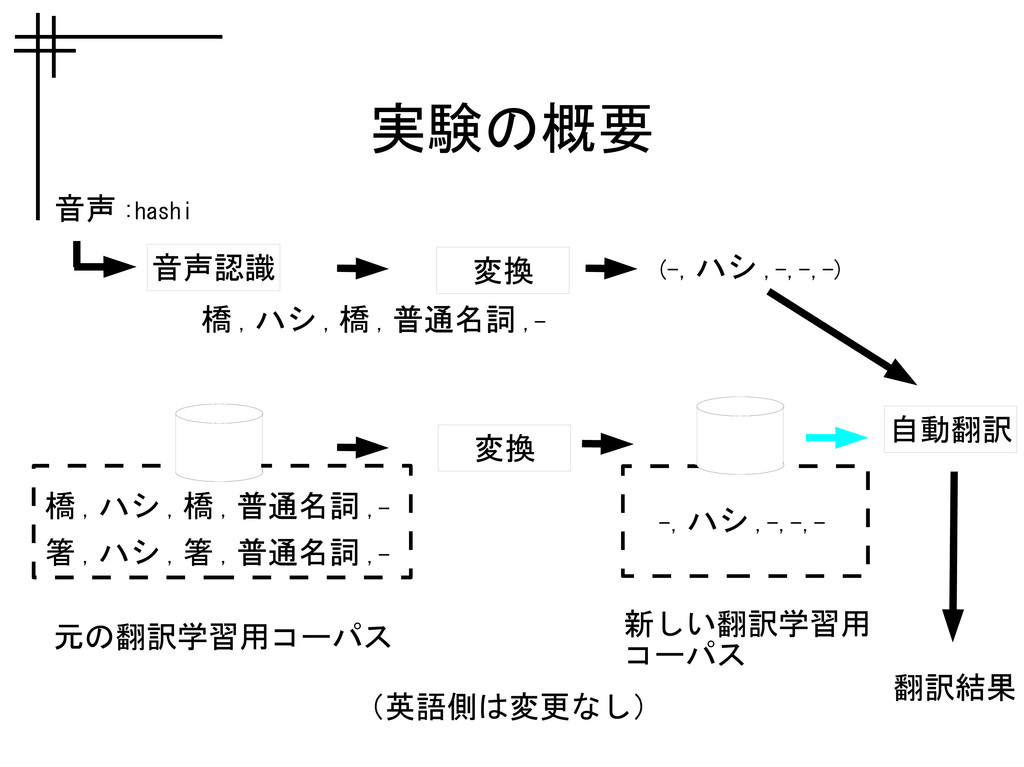
実験の概要 橋 , ハシ , 橋 , 普通名詞 ,- 箸
, ハシ , 箸 , 普通名詞 ,- 音声認識 変換 (-, ハシ ,-,-,-) 音声 :hashi 元の翻訳学習用コーパス 変換 新しい翻訳学習用 コーパス 自動翻訳 -, ハシ ,-,-,- 翻訳結果 橋 , ハシ , 橋 , 普通名詞 ,- (英語側は変更なし)
実験条件 • 形態素属性の組み合わせ • 分析対象(訓練セット、評価セット) • 翻訳方法 • 評価方法
形態素属性の組み合わせ – 表層形、読み、正規形、品詞、品詞補助情報 • 見る、ミル、見る、本動詞、一段 _ 基本 – 表層形、読み、正規形、品詞 •
見る、ミル、見る、本動詞 – 読み、正規形 • ミル、見る – 読み、品詞 • ミル、本動詞 – 読み • ミル
条件:分析対象 • 旅行会話基本表現集 – BTEC(日英対訳コーパス) 評価セット – 話者8人分の音声認識結果 • 音声認識から翻訳まで合わせた性能
– 正解認識データ • 自動翻訳単体性能 訓練セット 評価セット 152170文(発話) 1018文
評価指標 • BLEU • WER (1文に対して16文の正解を使用)
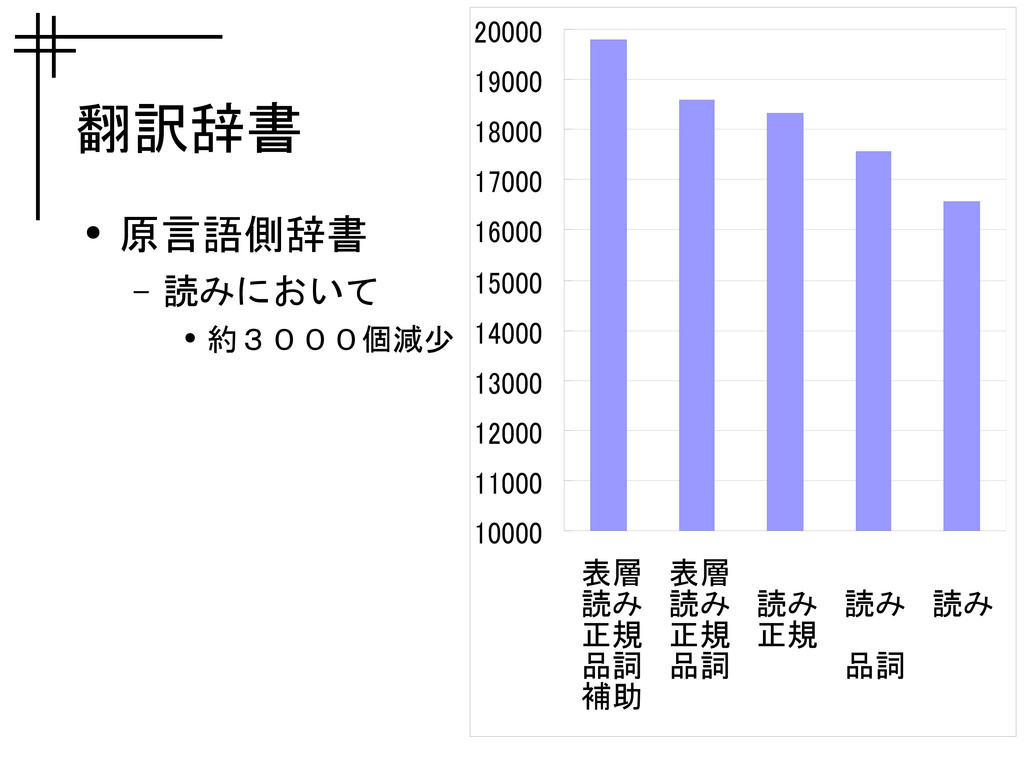
実験結果 • 学習された翻訳辞書の状態 – 原言語側単語数 – 日英翻訳候補 • 音声認識精度 •
翻訳精度 – 翻訳単体精度 – 音声翻訳精度
翻訳辞書 • 原言語側辞書 – 読みにおいて • 約3000個減少 10000 11000 12000
13000 14000 15000 16000 17000 18000 19000 20000 表層 読み 正規 品詞 補助 表層 読み 正規 品詞 読み 正規 読み 品詞 読み
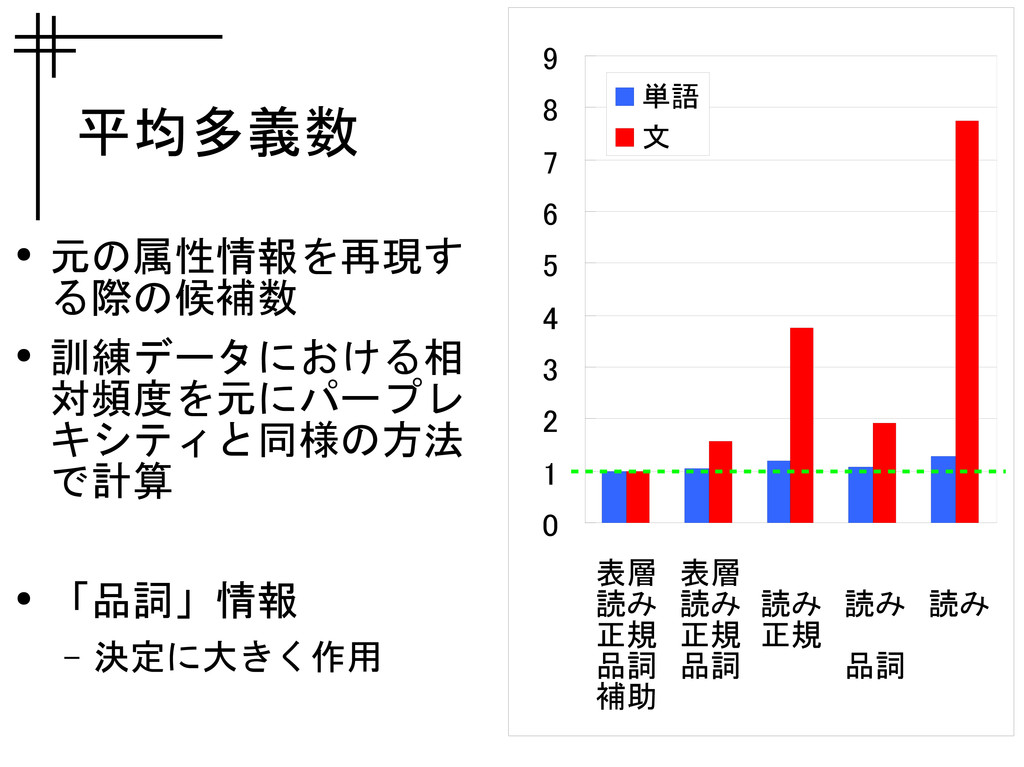
平均多義数 • 元の属性情報を再現す る際の候補数 • 訓練データにおける相 対頻度を元にパープレ キシティと同様の方法 で計算 •
「品詞」情報 – 決定に大きく作用 0 1 2 3 4 5 6 7 8 9 単語 文 表層 読み 正規 品詞 補助 表層 読み 正規 品詞 読み 正規 読み 品詞 読み
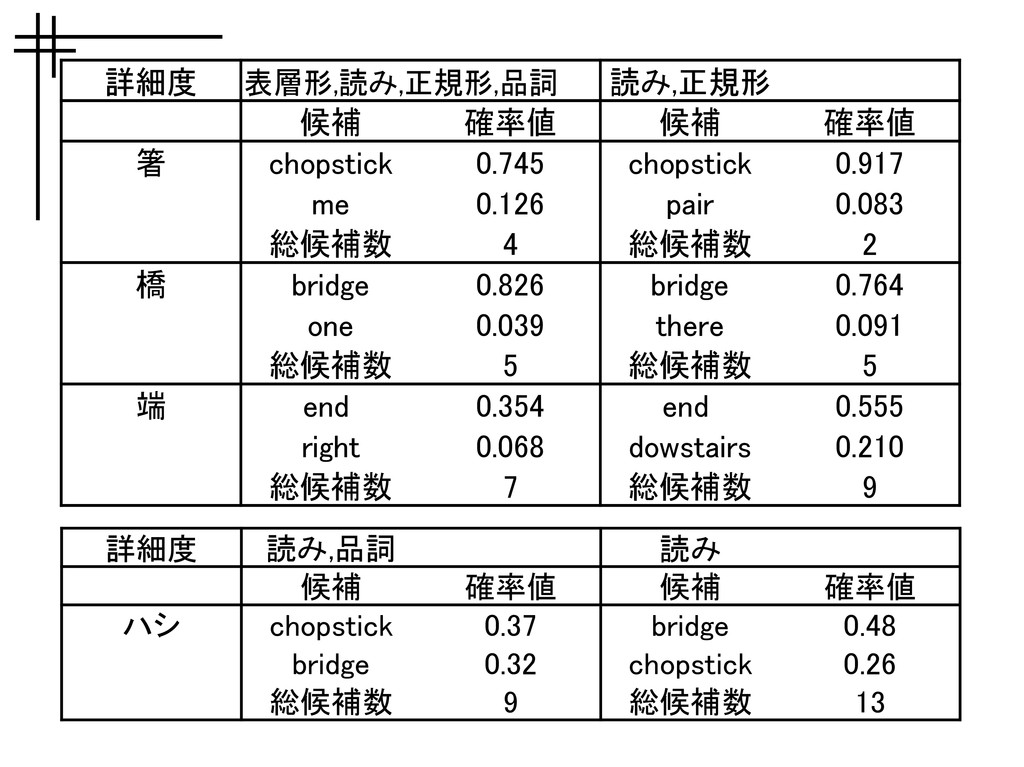
詳細度 候補 確率値 候補 確率値 箸 chopstick 0.745 chopstick 0.917
me 0.126 pair 0.083 総候補数 4 総候補数 2 橋 bridge 0.826 bridge 0.764 one 0.039 there 0.091 総候補数 5 総候補数 5 端 end 0.354 end 0.555 right 0.068 dowstairs 0.210 総候補数 7 総候補数 9 表層形,読み,正規形,品詞 読み,正規形 詳細度 読み 候補 確率値 候補 確率値 ハシ chopstick 0.37 bridge 0.48 bridge 0.32 chopstick 0.26 総候補数 9 総候補数 13 読み,品詞
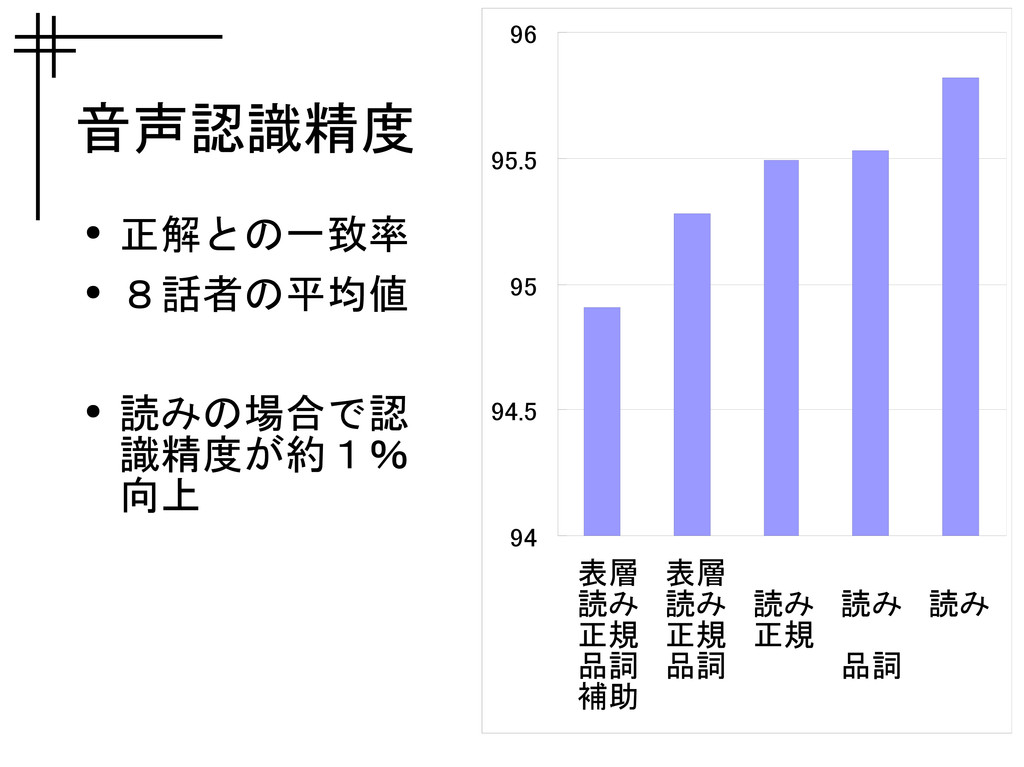
音声認識精度 • 正解との一致率 • 8話者の平均値 • 読みの場合で認 識精度が約1% 向上 94
94.5 95 95.5 96 表層 読み 正規 品詞 補助 表層 読み 正規 品詞 読み 正規 読み 品詞 読み
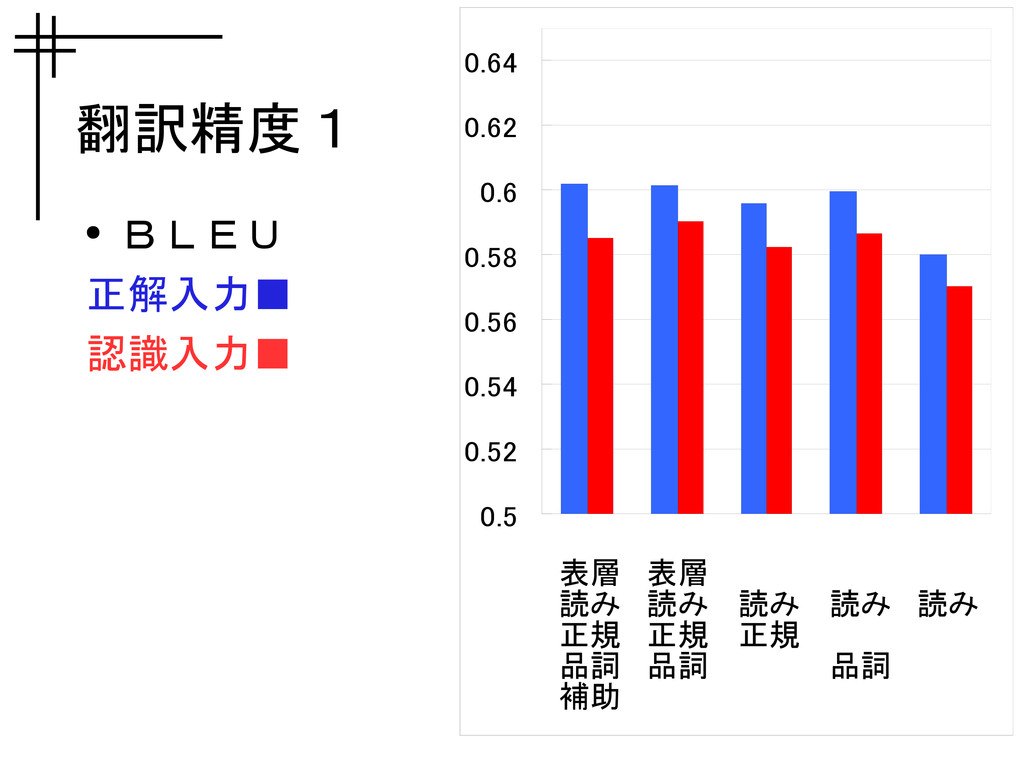
翻訳精度1 • BLEU 正解入力▪ 認識入力▪ 0.5 0.52 0.54 0.56 0.58
0.6 0.62 0.64 表層 読み 正規 品詞 補助 表層 読み 正規 品詞 読み 正規 読み 品詞 読み
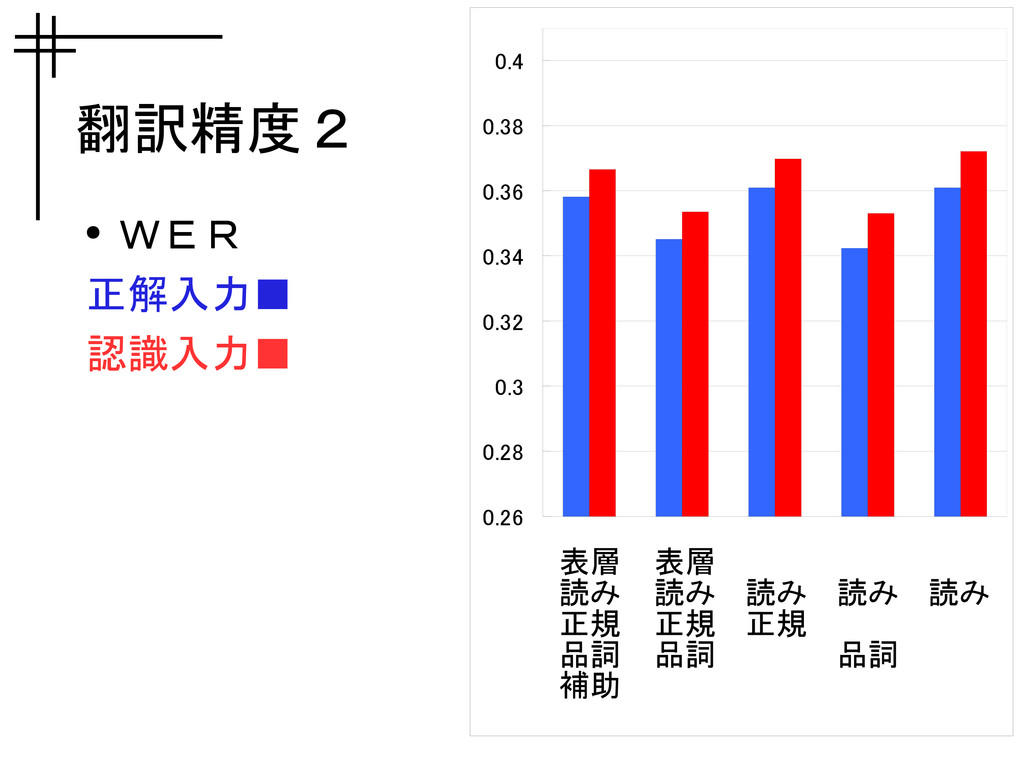
翻訳精度2 • WER 正解入力▪ 認識入力▪ 0.26 0.28 0.3 0.32 0.34
0.36 0.38 0.4 表層 読み 正規 品詞 補助 表層 読み 正規 品詞 読み 正規 読み 品詞 読み
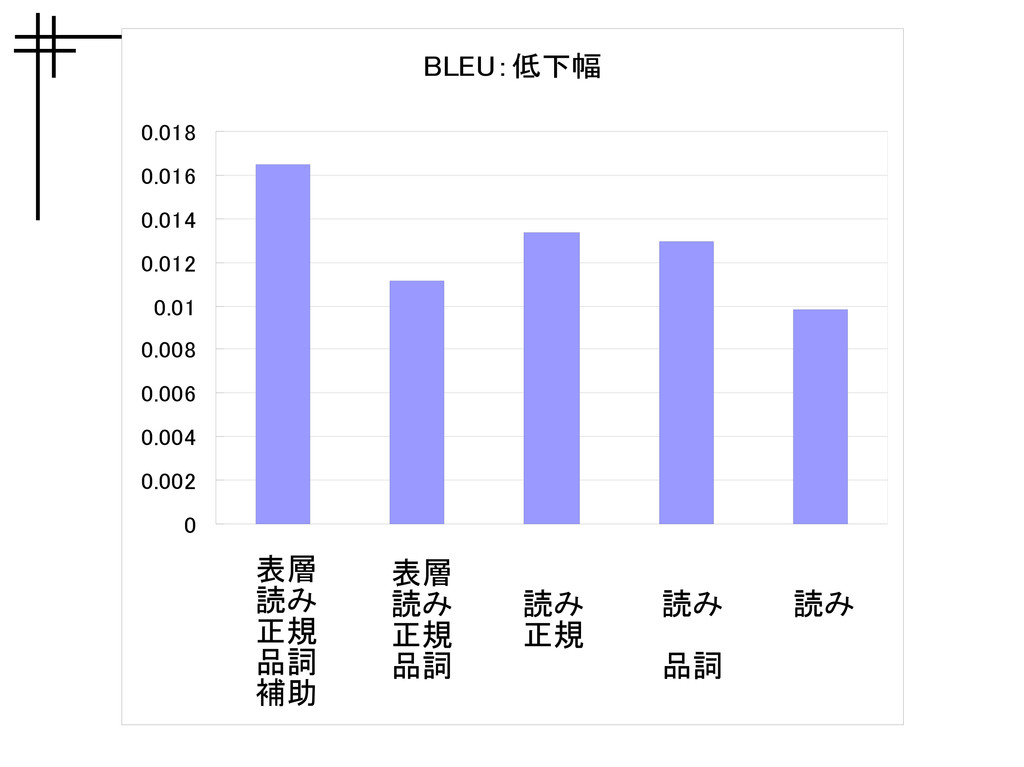
翻訳精度 • BLEU – 0.02 の変動幅 • WER – 0.02
の変動幅 詳細度を荒くしても評価セット全体の平均的 な精度はほとんど変わらない
考察:詳細度と翻訳精度 • 読みだけの場合 – 全ての情報を付加と同等の精度 • 翻訳結果 – 入力の曖昧性上昇により正解と誤りが混在
考察:翻訳精度向上の可能性 • 評価セット全体の平均 – 差は小さい • 五種類の翻訳結果から正解に近い出力を選択 ( oracle )
– BLEU :0.585 → 0.628 – WER :0.365 → 0.289 • 形態素属性を使い分けることで性能改善の可 能性がある。
まとめ 音声翻訳において、形態素の同定処理を音 声認識から自動翻訳に移動しても、翻訳結果 の精度はほとんど変化しない。 今後の課題 – 翻訳結果の自動選択 – 単語単位で属性の使い分け
ありがとうございました。
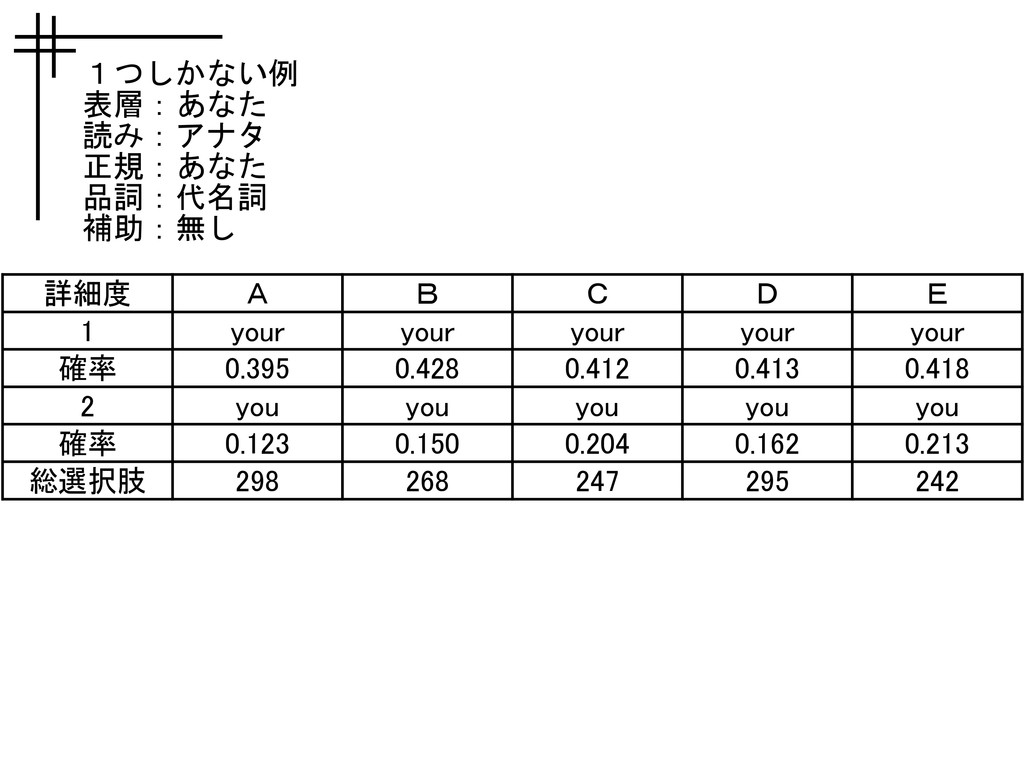
1つしかない例 表層:あなた 読み:アナタ 正規:あなた 品詞:代名詞 補助:無し 詳細度 A B C
D E 1 your your your your your 確率 0.395 0.428 0.412 0.413 0.418 2 you you you you you 確率 0.123 0.150 0.204 0.162 0.213 総選択肢 298 268 247 295 242
BLEU:低下幅 0 0.002 0.004 0.006 0.008 0.01 0.012 0.014 0.016
0.018 表層 読み 正規 品詞 補助 表層 読み 正規 品詞 読み 正規 読み 品詞 読み
機能分担 • 形態素情報「読み」以外を無視 – 音声認識 同音異義語の解消の処理を行わない 負担軽減 – 翻訳 翻訳多義解消の機構で同音異義解消
負担増加 機能分担が変更される
実験システム • ATR音声翻訳システム 使用条件 音声認識と自動翻訳の間について行う 日英に限定する – 認識 • 音響モデル HMM
• 言語モデル 単語Nグラム – 翻訳 • 統計モデル IBMモデル4
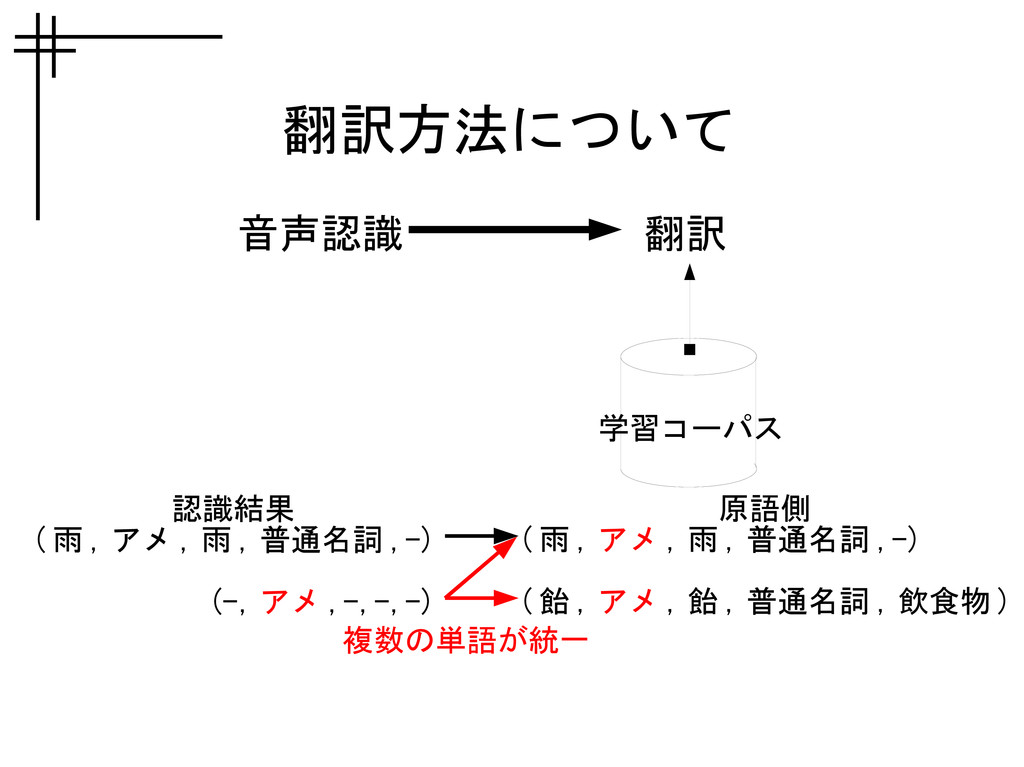
翻訳方法について 音声認識 翻訳 学習コーパス 認識結果 ( 雨 , アメ ,
雨 , 普通名詞 ,-) (-, アメ ,-,-,-) 原語側 ( 雨 , アメ , 雨 , 普通名詞 ,-) ( 飴 , アメ , 飴 , 普通名詞 , 飲食物 ) 複数の単語が統一
音声認識出力と自動翻訳 • 音声認識モジュール出力 – 音声認識用の言語モデルにおける形態素情報、 表層形、読み、正規、品詞、品詞補助の組み合 わせで決定 • 翻訳モジュール –
原語側を音声認識出力に対応させて学習 表層形 読み 正規形 品詞 品詞補助 言っ イッ 言う 本動詞 ワ行五段
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}