How to combine expressive statistical models with the power of DeepLearning. And why this could be a game changer.
Presented at 1st AI Meetup in Stuttgart.
developer and consultant for software systems, architecture and processes. • Mainly interested in businesses around engineering, manufacturing and logistics. • Self-Employed after high school for 5 years • Right now he's doing a PhD at Institute of Theoretical Physics in Ulm and is still consulting. 4
very flexible creation of custom probabilistic models. • It is mainly concerned with insight and learning from your data. • The approach is inherently Bayesian so we can specify priors to inform and constrain our models and get uncertainty estimation in form of a posterior distribution. • Using MCMC sampling algorithms we can draw samples from this posterior to very flexibly estimate these models. • Variational inference algorithms fit a distribution (e.g. normal) to the posterior turning a sampling problem into an optimization problem. Neal (1995), MCMC using Hamiltonian dynamics. Handbook of Markov Chain Monte Carlo 2.11 Gelman (2016), Automatic differentiation variational inference, arXiv preprint arXiv:1603.00788 5
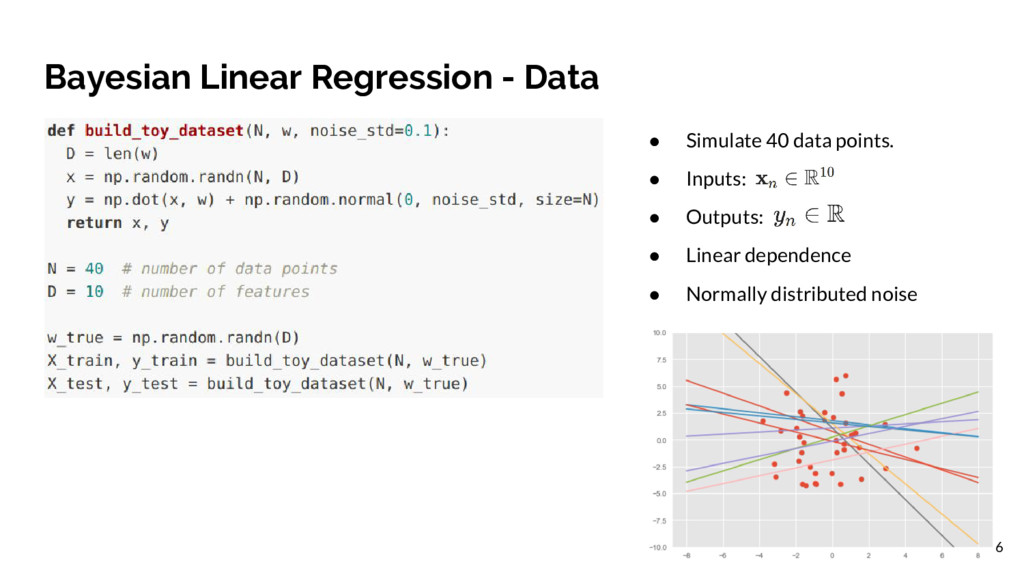
linear relationship between inputs and output . • For a set of N data points the model looks like: • The Variances: ◦ Priors: ◦ Likelihood: • The latent variables: ◦ Model weights: ◦ Intercept/bias: Murphy, K. P. (2012). Machine learning: A probabilistic perspective. MIT Press. 7
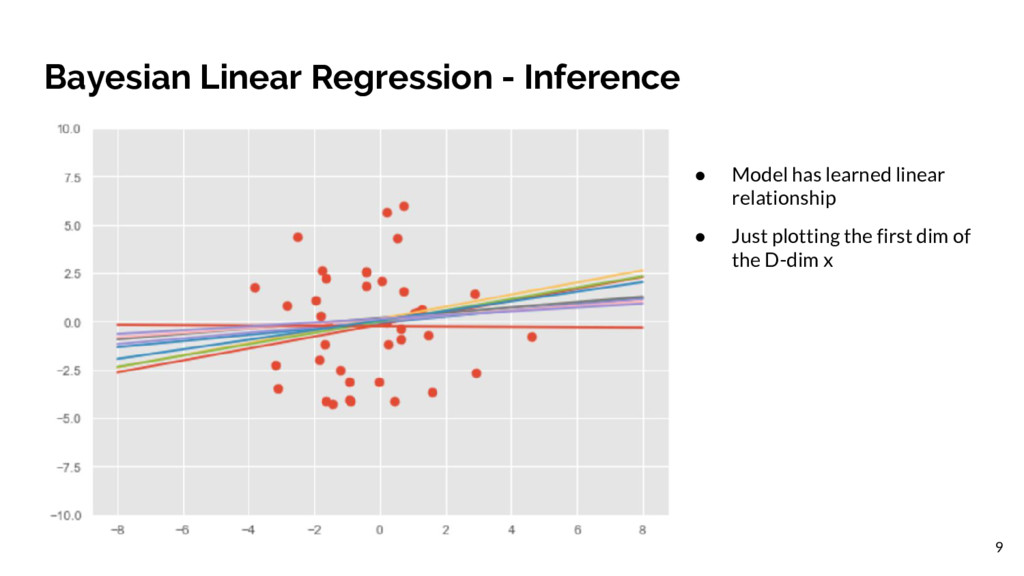
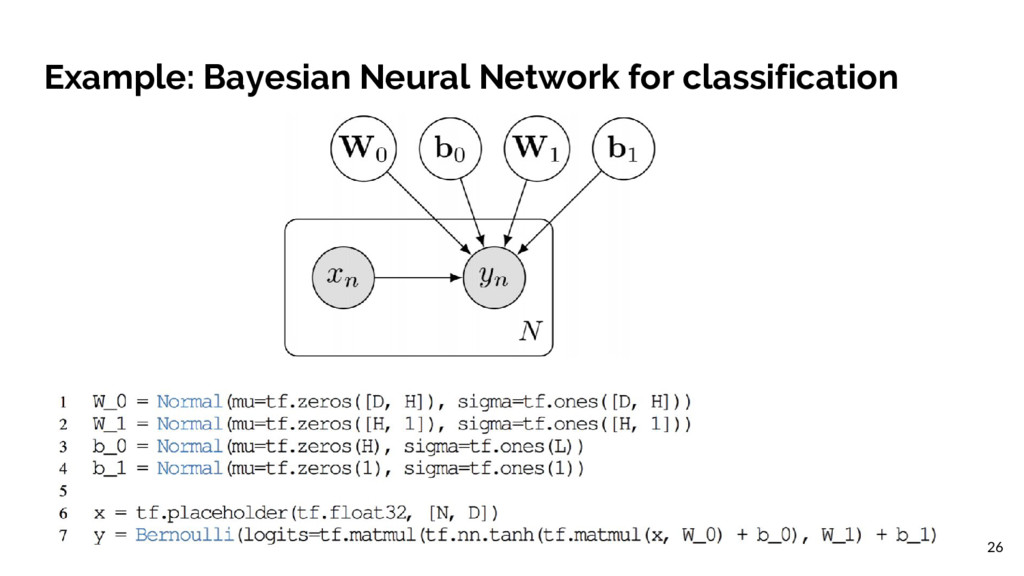
be a fully factorized normal across the weights. Run variational inference with the Kullback-Leibler divergence, using 250 iterations and 5 latent variable samples in the algorithm. The inference is done by minimizing the divergence measure using the reparameterization gradient. Probabilistic Programming emphasizes expressiveness instead of scale. 8
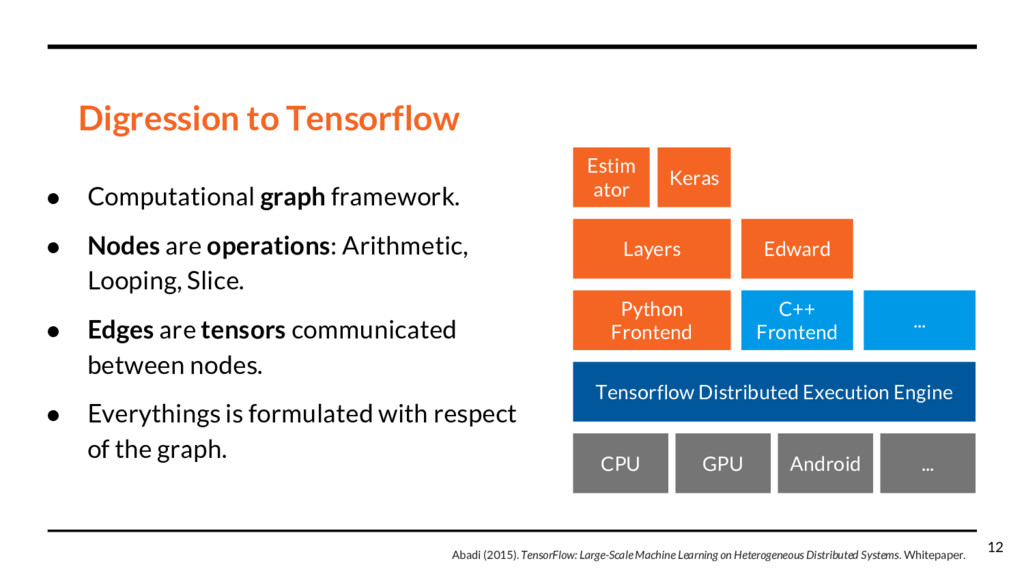
graph • Fetching x from the graph generates a binary vector. • All computation is represented on the graph, enabling to leverage model structure during inference. 10
operations: Arithmetic, Looping, Slice. • Edges are tensors communicated between nodes. • Everythings is formulated with respect of the graph. CPU GPU ... Android Tensorflow Distributed Execution Engine Python Frontend C++ Frontend ... Layers Estim ator Keras Edward Abadi (2015). TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. Whitepaper. 12
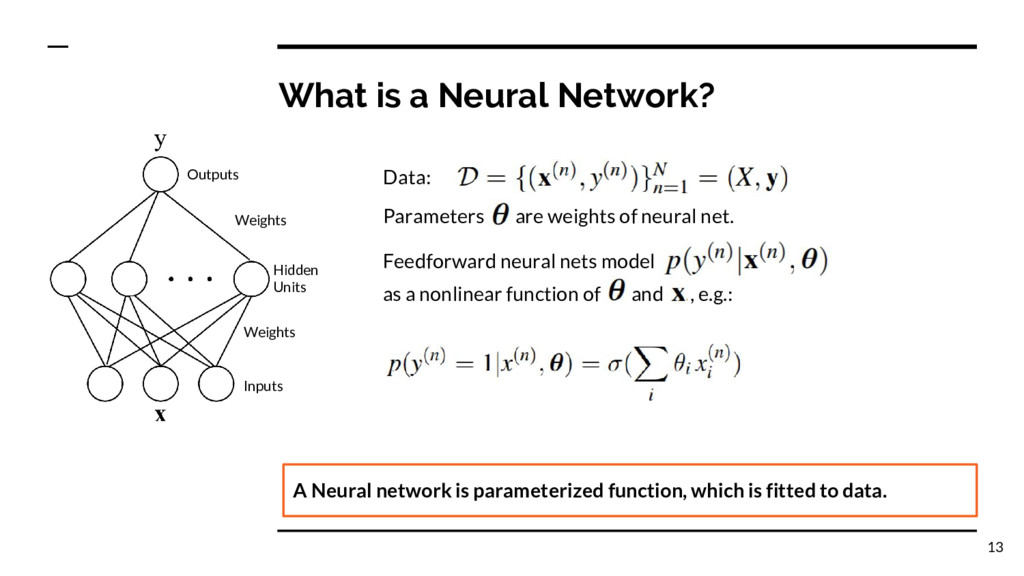
Inputs A Neural network is parameterized function, which is fitted to data. Parameters are weights of neural net. Feedforward neural nets model Data: as a nonlinear function of and , e.g.: 13
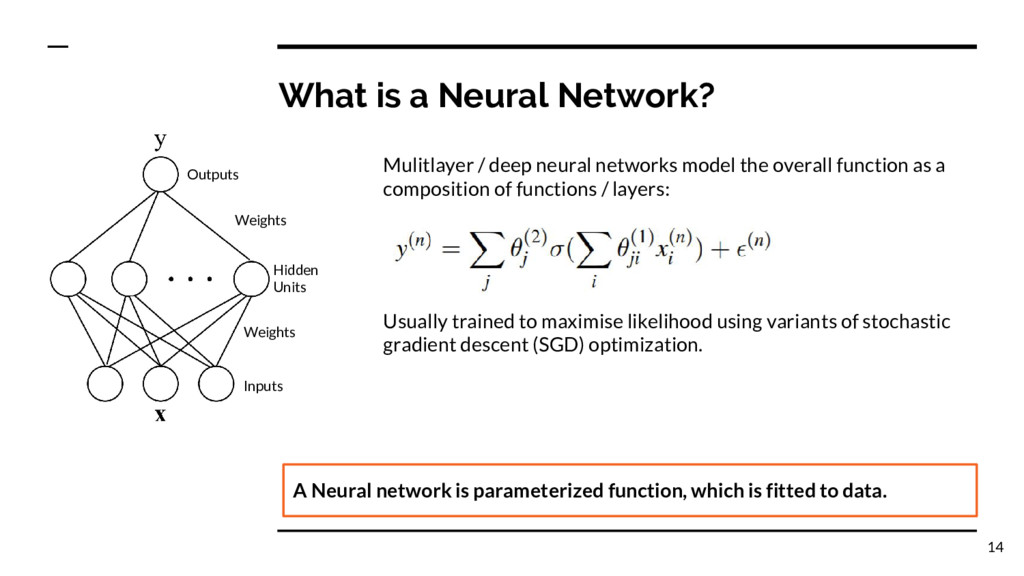
Inputs A Neural network is parameterized function, which is fitted to data. Mulitlayer / deep neural networks model the overall function as a composition of functions / layers: Usually trained to maximise likelihood using variants of stochastic gradient descent (SGD) optimization. 14
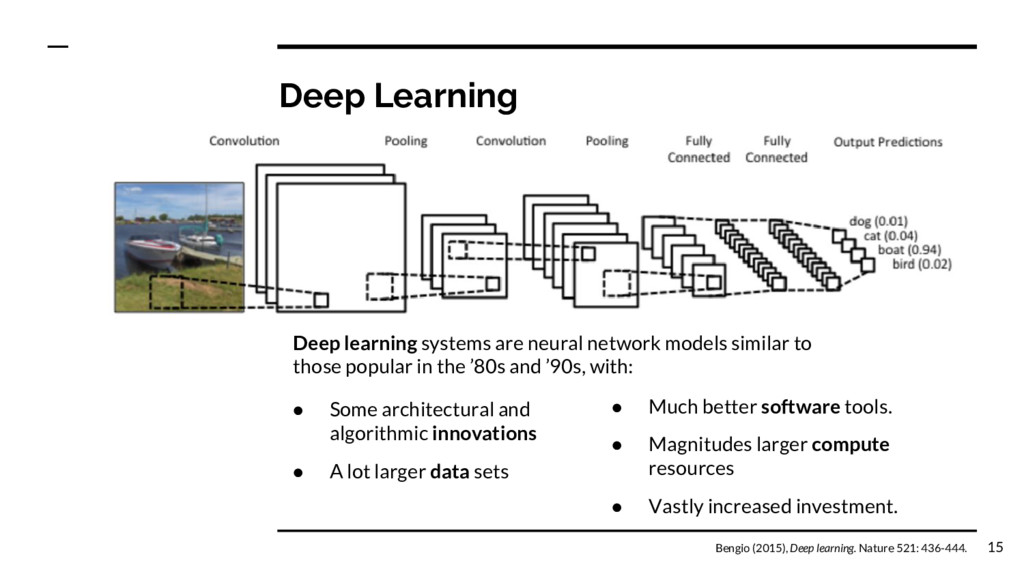
to those popular in the ’80s and ’90s, with: • Some architectural and algorithmic innovations • A lot larger data sets • Much better software tools. • Magnitudes larger compute resources • Vastly increased investment. Bengio (2015), Deep learning. Nature 521: 436-444. 15
certain domains hard. • Very data hungry. • Very compute-intensive to train and deploy. • Poor at representing uncertainty. • Easily fooled by adversarial examples. • Tricky to optimize: non-convex & choice of architecture, learning procedure, initialization. • Uninterpretable black-boxes, lacking in transparency, difficult to trust. • Hard to incorporate prior knowledge on the model. 17
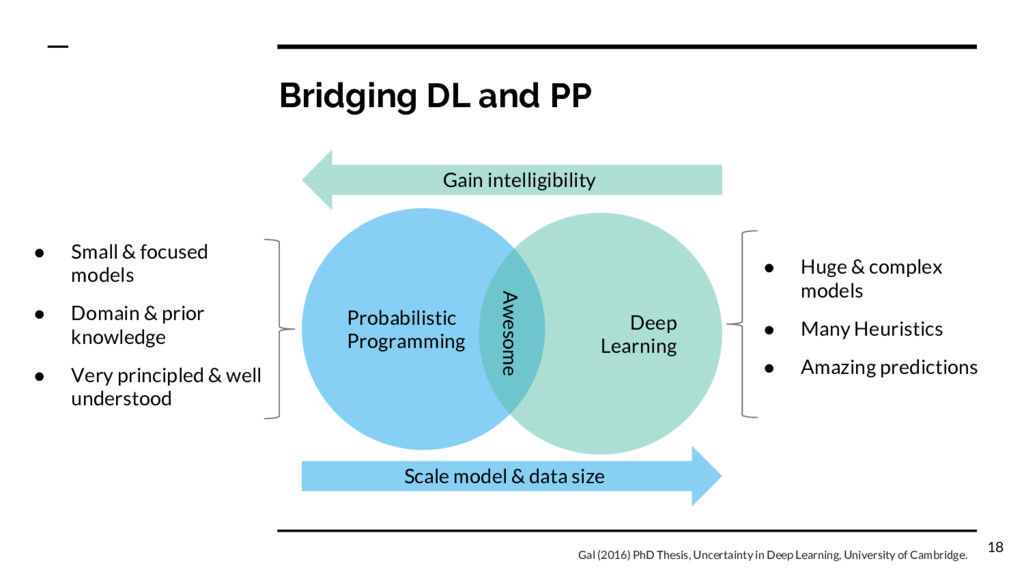
Domain & prior knowledge • Very principled & well understood • Huge & complex models • Many Heuristics • Amazing predictions Probabilistic Programming Deep Learning Gain intelligibility Scale model & data size Awesome Gal (2016) PhD Thesis, Uncertainty in Deep Learning, University of Cambridge. 18
intelligence depend crucially on the careful probabilistic representation of uncertainty: • Forecasting. • Decision making. • Learning from limited, noisy, and missing data • Learning complex personalised models. • Data compression. • Automating scientific modelling, discovery, and experiment design. • Incorporation of Domain Specific Knowledge 19
Getting systems that know when they don’t know. • AI on real-life settings needs safety, e.g. medical domain, drones, cars, finance. • Model confidence and result distribution for human machine interaction. • Low level errors propagating to top level rule-based systems. (Tesla incident). • Framework of model confidence necessary. • Adapt learning to uncertainty: Active learning & Deep Reinforcement Learning. 20
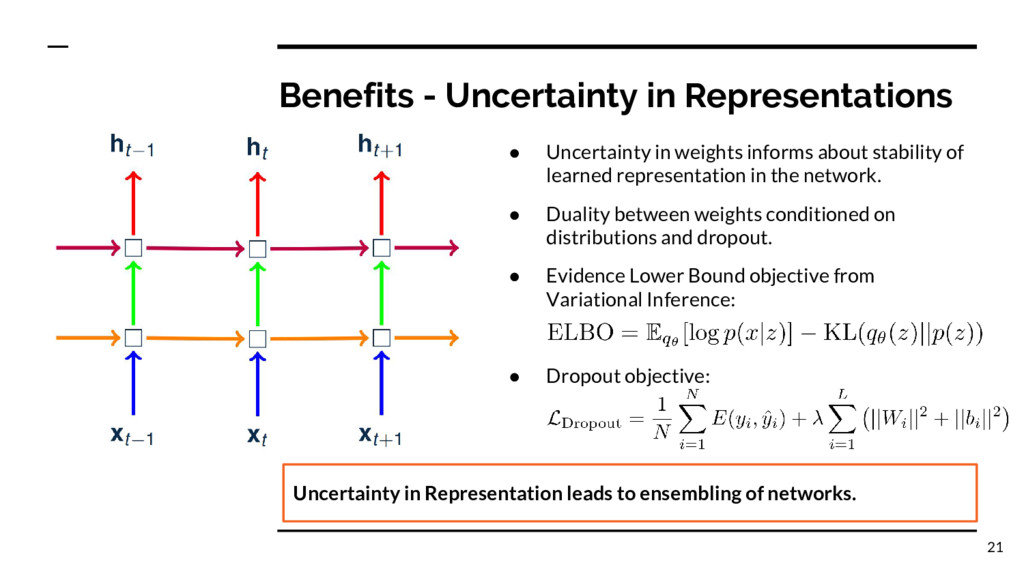
ensembling of networks. • Uncertainty in weights informs about stability of learned representation in the network. • Duality between weights conditioned on distributions and dropout. • Evidence Lower Bound objective from Variational Inference: • Dropout objective: 21
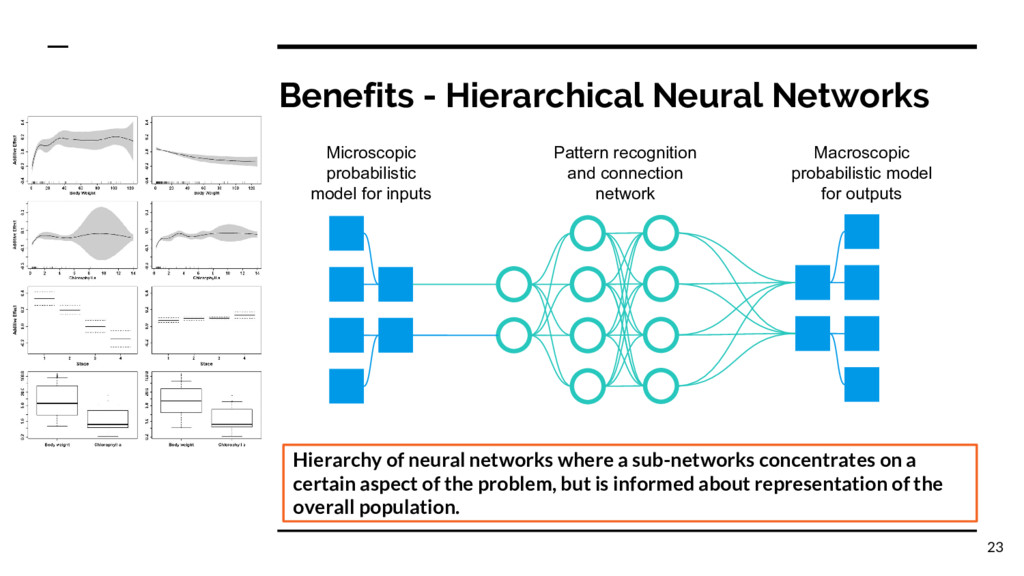
a sub-networks concentrates on a certain aspect of the problem, but is informed about representation of the overall population. Microscopic probabilistic model for inputs Macroscopic probabilistic model for outputs Pattern recognition and connection network 23
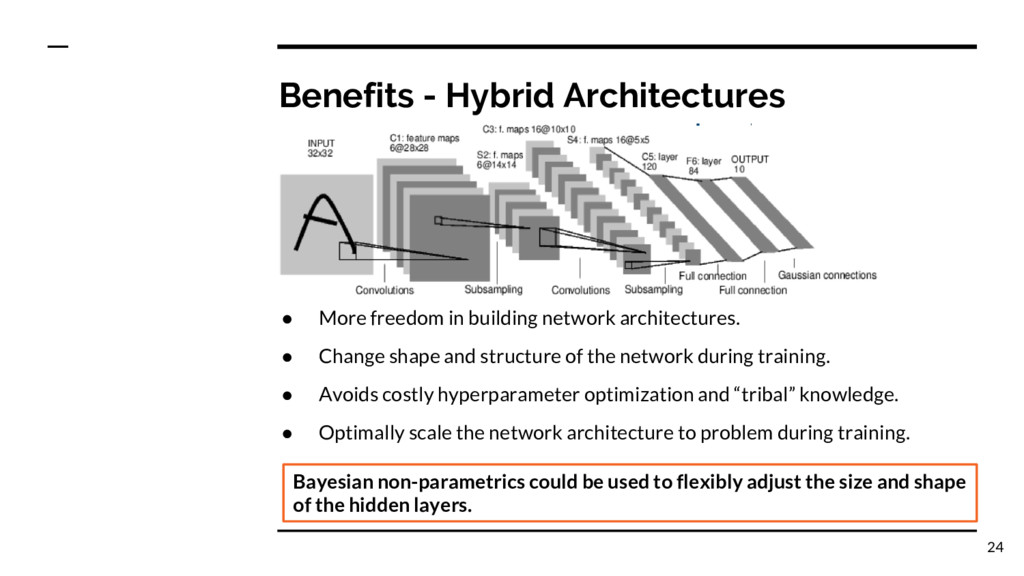
flexibly adjust the size and shape of the hidden layers. • More freedom in building network architectures. • Change shape and structure of the network during training. • Avoids costly hyperparameter optimization and “tribal” knowledge. • Optimally scale the network architecture to problem during training. 24
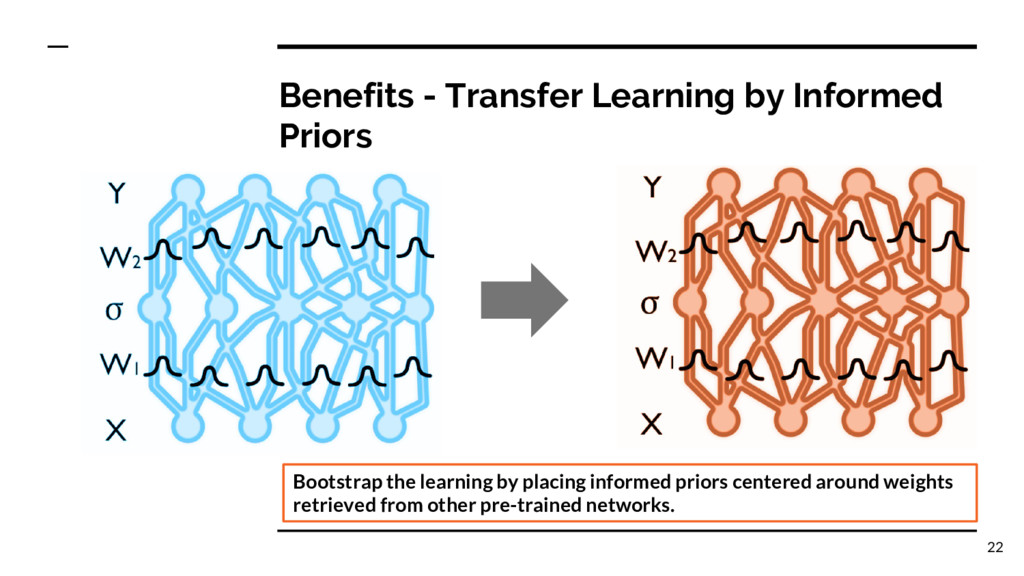
systems that learn from data. • Advantages include better estimates of uncertainty, automatic ways of learning structure and avoiding overfitting, and a principled foundation. • Disadvantages include higher computational cost, depending on the approximate inference algorithm • Bayesian neural networks have a long history and are undergoing a tremendous wave of revival • There could be a lot of practical benefit to marry Probabilistic Programming and Neural Networks 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}