and Christophe Gravier and Amaury Habrard Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 254–263 長岡技術科学大学 自然言語処理研究室 勝田 哲弘
four wheels, powered by an internal combustion engine and able to carry a small number of people. – 関連を抽出:“vehicle”, “road” or “engine” • 強い関連:お互いが定義文中に現れる場合 • 弱い関連:片方にしか現れない場合
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
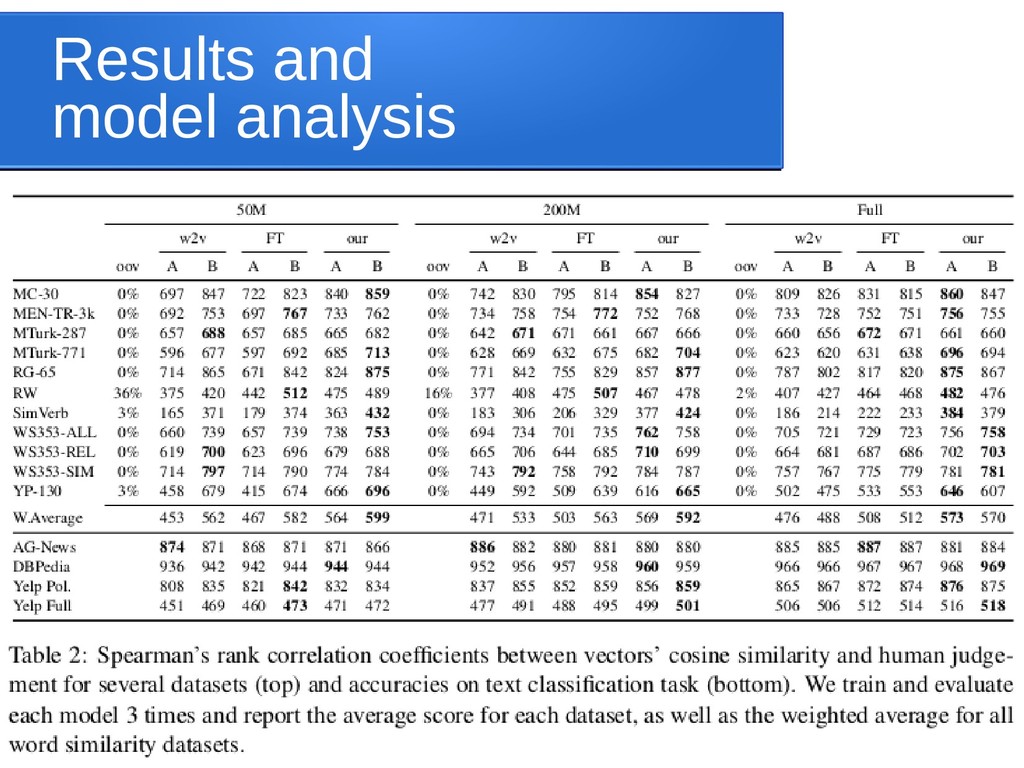{kind=link}
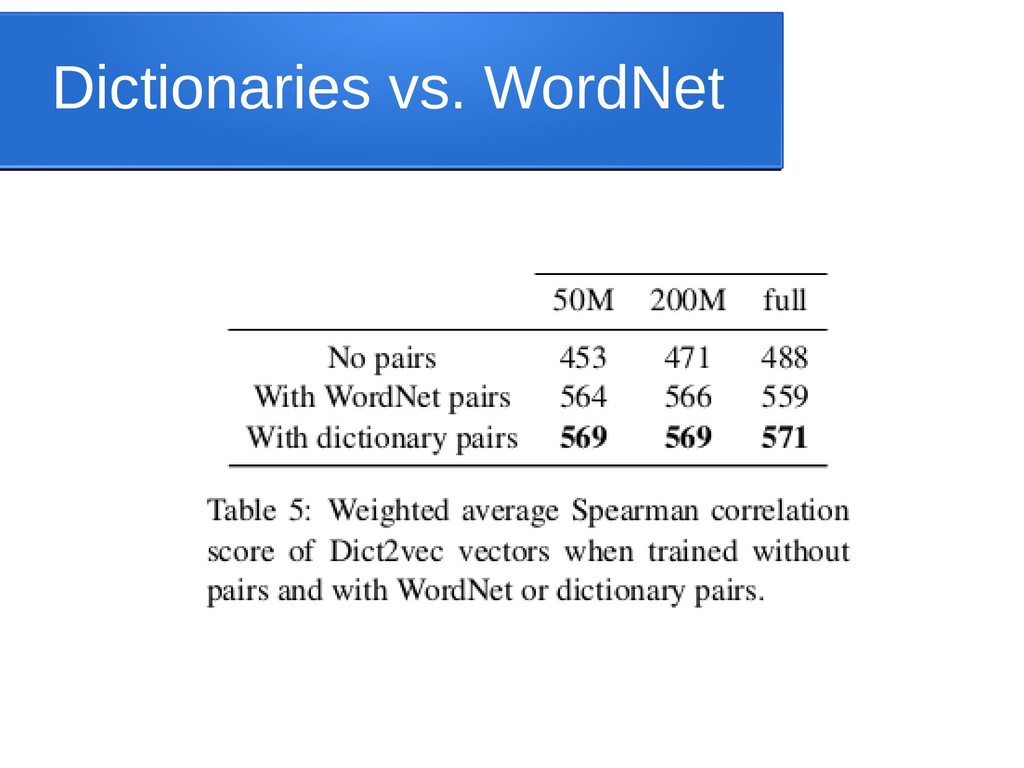{kind=link}
{kind=link}
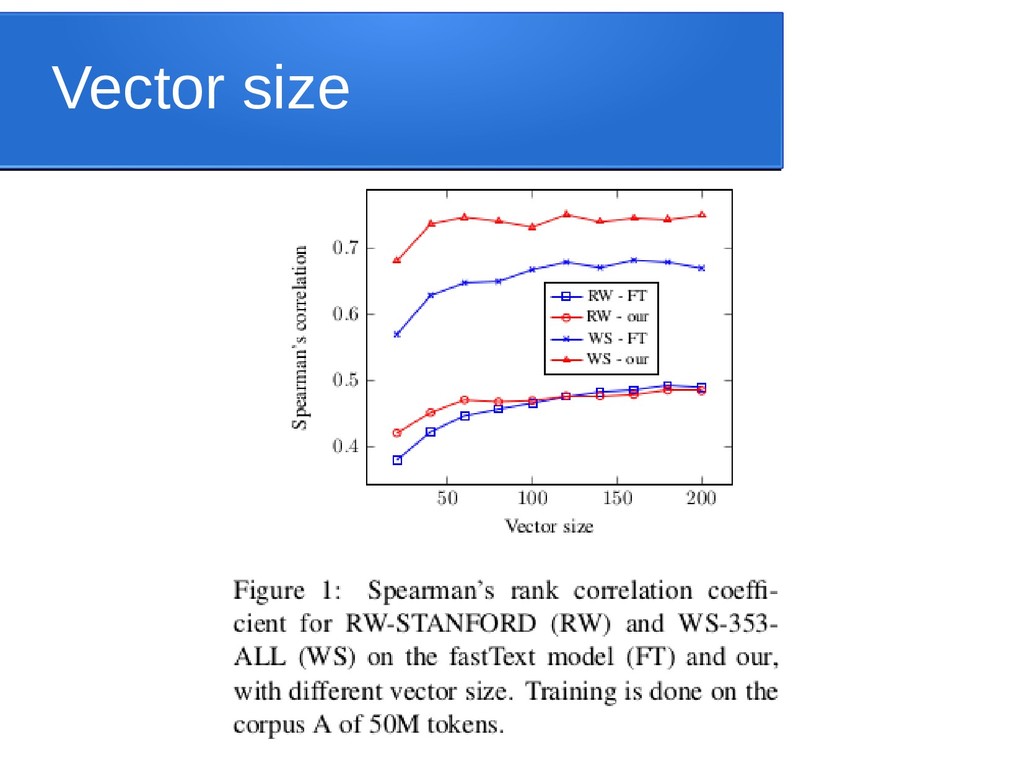{kind=link}
{kind=link}