Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Phrase-level Self-Attention Networks for Univer...
Search
katsutan
January 28, 2019
Technology
270
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Phrase-level Self-Attention Networks for Universal Sentence Encoding
文献紹介
長岡技術科学大学 勝田 哲弘
http://aclweb.org/anthology/D18-1408
katsutan
January 28, 2019
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
260
Simple and Effective Paraphrastic Similarity from Parallel Translations
katsutan
0
230
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Character Eyes: Seeing Language through Character-Level Taggers
katsutan
1
240
Improving Word Embeddings Using Kernel PCA
katsutan
0
250
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
katsutan
0
320
Other Decks in Technology
See All in Technology
AIに障害切り分けを全部やってもらった。 。 。 。
estie
0
350
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
350
デジタル・デザイン:次の50年を描く「進化する青写真」
y150saya
0
800
背中から、背中へ /paying forward to community
naitosatoshi
0
220
記録をかんたんに、提案をパーソナルに ── AIであすけんが目指すもの
oprstchn
0
140
#エンジニアBooks 30分でわかる 「技術記事を書く技術」 / engineer-books 2026-06-30
jnchito
1
180
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
520
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
300
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.3k
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
0
210
トークン最適化のためのユーザーストーリー分析 / User Story Analysis for Token Optimization
oomatomo
0
170
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
150
Featured
See All Featured
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
How GitHub (no longer) Works
holman
316
150k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
sira's awesome portfolio website redesign presentation
elsirapls
0
290
Chasing Engaging Ingredients in Design
codingconduct
0
230
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
400
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Amusing Abliteration
ianozsvald
1
220
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Discover your Explorer Soul
emna__ayadi
2
1.2k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
Phrase-level Self-Attention Networks for Universal Sentence Encoding Wei Wu, Houfeng
Wang, Tianyu Liu, Shuming Ma Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3729–3738 Brussels, Belgium, 2018. 文献紹介 長岡技術科学大学 勝田 哲弘
Abstract • Phrase-level SelfAttention Networks (PSAN)を提案 • フレーズで自己注意を行うため、メモリ消費が少ない • gated
memory updating mechanismでツリー構造を組み込 むことで階層的に単語表現を学習できる • 少ないメモリで様々なタスクでSotAを達成
Introduction 文のエンコーダにはRNNやCNNが用いられる • RNN:並列化できず、時間効率が悪い • CNN:パフォーマンスがRNNより悪い RNN/CNNを用いない Phrase-level SelfAttention Networks
(PSAN)を提案
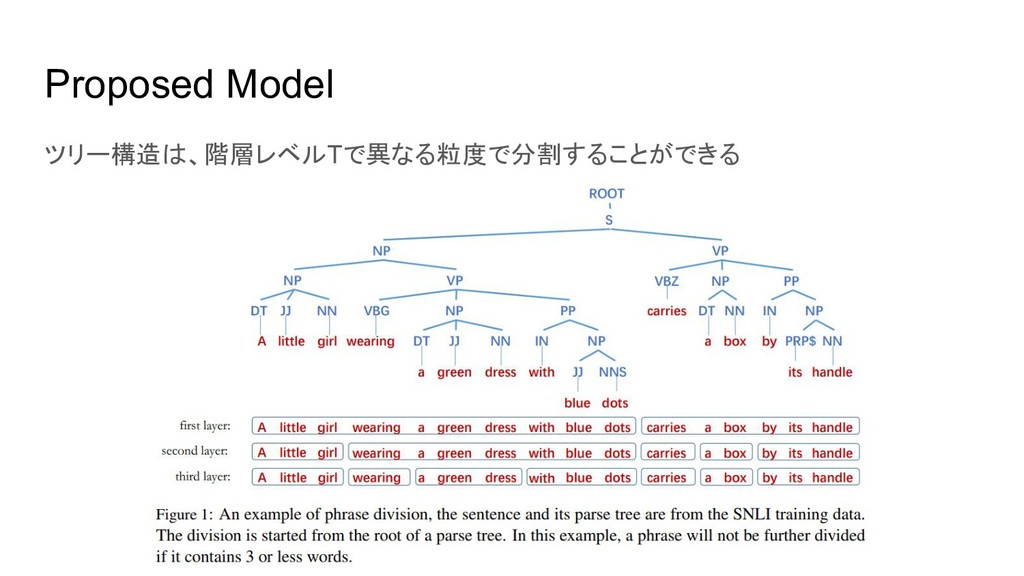
Proposed Model ツリー構造は、階層レベルTで異なる粒度で分割することができる
Proposed Model phrase represented: word embeddings: 最初にフレーズ内の単語アライメントを計算する
Proposed Model attention mechanismの出力はフレーズ内の各単語間の加重合計 Phrase-level Self-Attentionの最終的な出力は各入力単語ベクトルをattention mechanismの出力と比較することで得られる。
Gated Memory Updatin • 先程の手法(PSA)は1つの分割レベルに対する計算 ◦ ツリー構造は様々な粒度で分割できる ◦ 階層的に学習するためにgated memory
updating mechanismを提案 各レイヤ間でパラメータを共有
Sentence Summarization 最終的に固定長の文ベクトルに要約する
Experiments word embedding:GloVe (300次元) 階層レベルT:3(固定) 学習データ:SNLIデータセット 文分類、自然言語推論、テキスト類似性を含む様々なNLPタスク でPSANを評価 構文解析:Stanford PCFG
Parser 3.5.2
Training Setting Natural language inference(NLI)によってエンコーダを学習する 学習データ:Stanford Natural Language Inference (SNLI)
dataset • 549367/9842/9824 sentence pairs
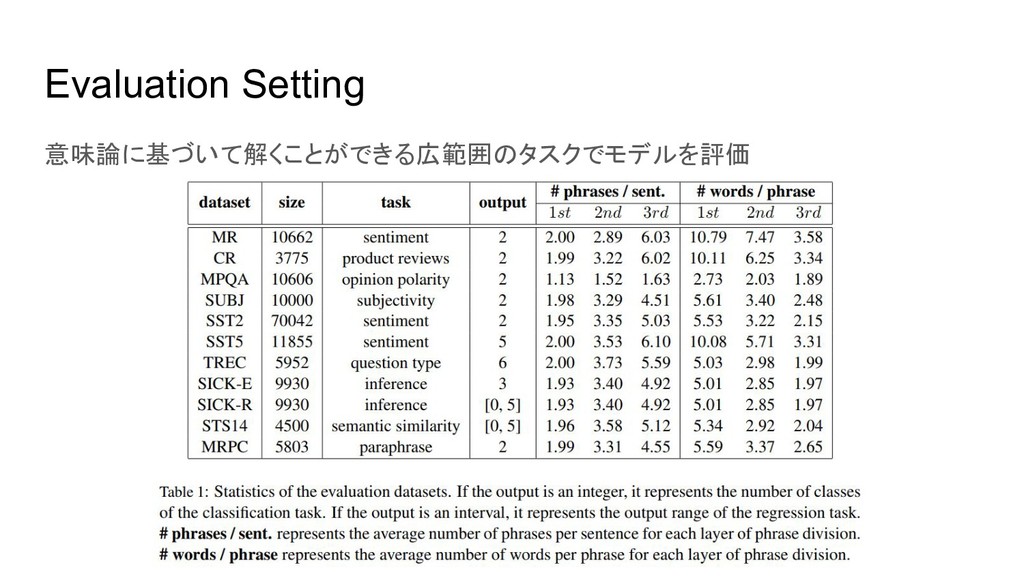
Evaluation Setting 意味論に基づいて解くことができる広範囲のタスクでモデルを評価
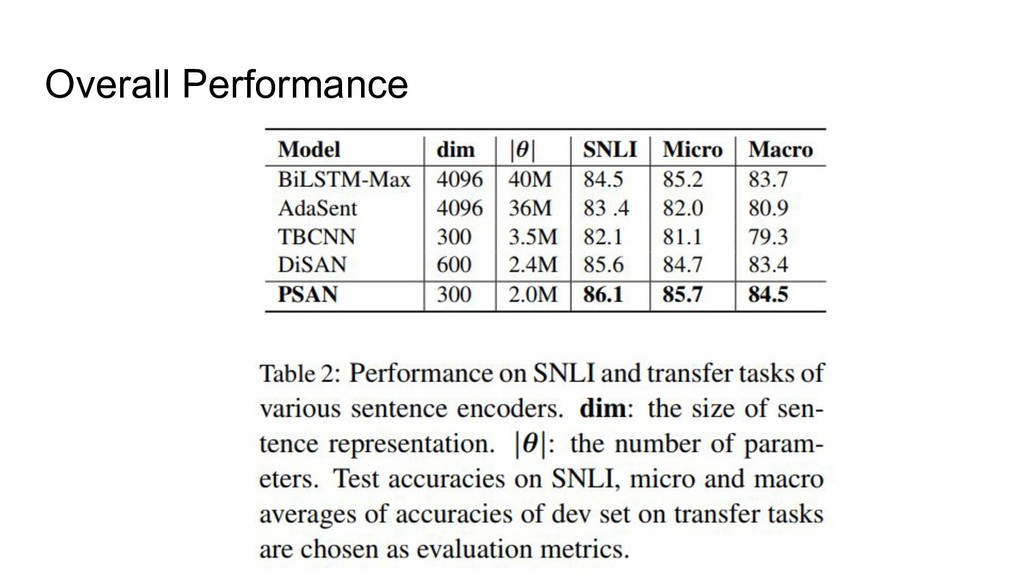
Overall Performance
Overall Performance
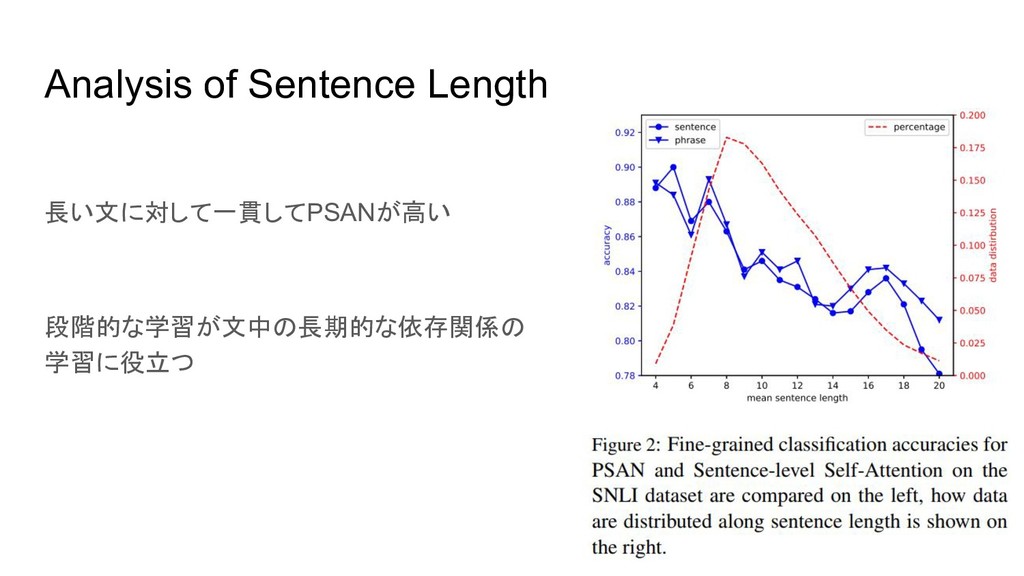
Analysis of Sentence Length 長い文に対して一貫してPSANが高い 段階的な学習が文中の長期的な依存関係の 学習に役立つ
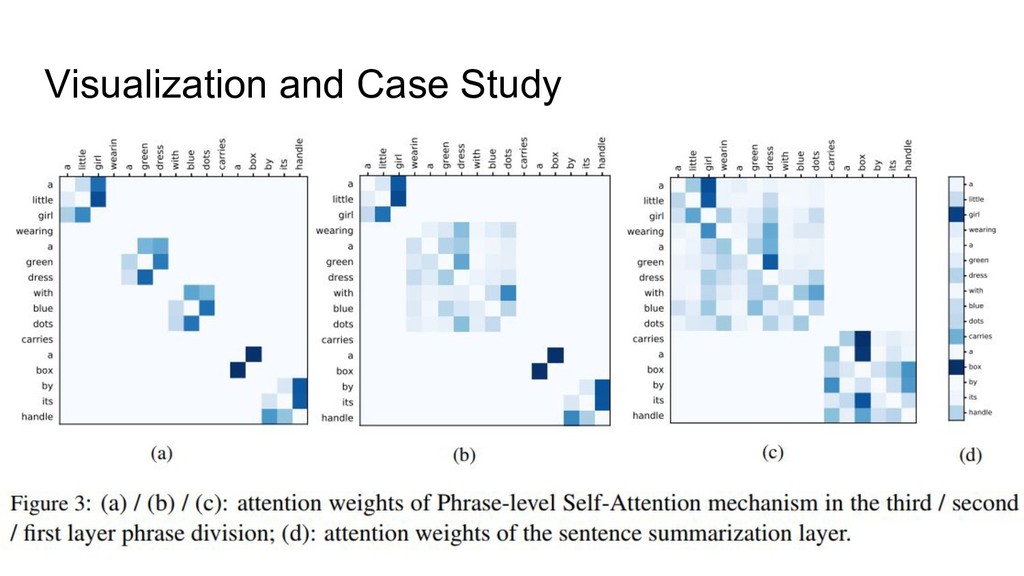
Visualization and Case Study
Conclusion • 構文情報を用いた文のエンコーダモデルを提案 ◦ 意味的、構文的に重要な単語間の相互作用に注目 • パラメータ数を減らし、メモリ消費を20%以上削減 • 様々なタスクで有効性が示された
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}