Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[FIT22] Visual Explanation Generation Using Lam...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 11, 2022
Technology
880
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[FIT22] Visual Explanation Generation Using Lambda Attention Branch Networks with Saliency Guided Training
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 11, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
370
キャリアLT会#3
beli68
2
240
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1k
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
780
文字起こし基盤の信頼性
abnoumaru
0
120
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
0
100
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
210
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
200
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.5k
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
1
140
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
420
Featured
See All Featured
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Docker and Python
trallard
47
4k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
How to build a perfect <img>
jonoalderson
1
5.8k
Designing for Timeless Needs
cassininazir
1
400
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
410
Building Adaptive Systems
keathley
44
3.1k
Transcript
1 Saliency Guided Trainingを使用した Lambda Attention Branch Networks による視覚的説明生成 小松
拓実1 飯田 紡1 兼田 寛大1 平川 翼2 山下 隆義2 藤吉 弘亘2 杉浦 孔明1 1. 慶應義塾大学 2. 中部大学
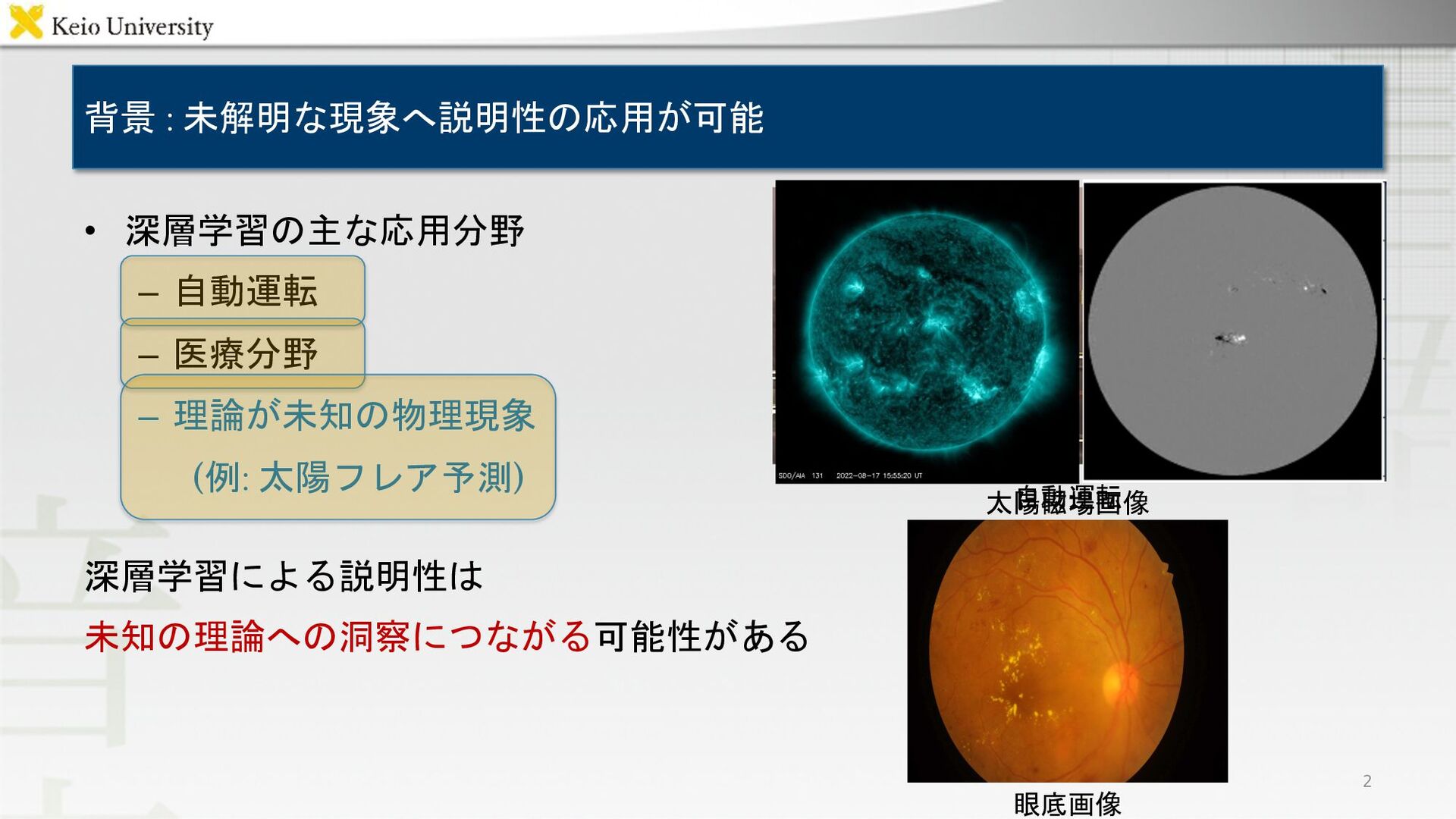
背景 : 未解明な現象へ説明性の応用が可能 • 深層学習の主な応用分野 – 自動運転 – 医療分野 –
理論が未知の物理現象 (例: 太陽フレア予測) 深層学習による説明性は 未知の理論への洞察につながる可能性がある 眼底画像 2 自動運転 太陽磁場画像
背景 : 未解明な現象へ説明性の応用が可能 • 深層学習の主な応用分野 – 自動運転 – 医療分野 –
理論が未知の物理現象 (例: 太陽フレア予測) magnetogram(磁場画像) 深層学習による説明性は 未知の理論への洞察につながる可能性がある 視覚的説明 3 太陽フレアの 原因解明の鍵となる 可能性
背景 : 太陽フレアによる現実への影響は甚大だが現象として未解明 ▪ 太陽フレア – 太陽表面で起きる爆発現象 ▪ X線等級 –
X, M, C, Oクラスに分類 ▪ 主な被害 – 大規模な停電 [1989] – 人工衛星への被害[2022] (日経新聞2022/4/26) 等級の分類 4 大 小 規模・被害 被害想定額は 約40兆円 (保険会社試算) NASA, https://svs.gsfc.nasa.gov/4491 TBS, https://newsdig.tbs.co.jp/articles/-/78060?display=1
関連研究 : 既存手法は重要でない領域を重要視する粗い説明を生成 • 重要でない領域の影響も含まれた 粗い説明を生成する傾向がある RISE [Petsiuk+, BMCV18] 説明の標準的な手法,
評価指標であるInsertion-Deletion scoreを提案 Lambda Attention Branch Networks [飯田+, JSAI22] ABN[Fukui+, CVPR19]を利用して Lambda Networks[Bello+, ICLR21]の説明を生成 Full-Gradient [Srinivas+, NeurlPS19] バイアス項の勾配を含めた説明生成を提案 マスクによる予測への影響を示唆 5 RISE LABN
関連研究: Insertion-Deletion score (IDs) [Petsiuk+, BMCV18] 6 Deletion Insertion n
Insertion-Deletion score (IDs) 1. 計算した重要度に基づき 重要な画素から挿入/削除を行う 2. 挿入 / 削除したパッチ数と モデルの予測確率をプロット 3. プロット図のAUCを計算 IDs = AUC Insertion − AUC(Deletion)
問題点 : 注目領域の範囲が広範囲 • 既存手法は重要でない領域も注目 幅のある粗い視覚的説明を生成する 重要でない領域の重要度が全体的に大きい 元画像 幅のある粗い説明 重要でない領域の重要度が高い
7 Saliency Guided Training[Ismail+, NeurIPS21]による学習を導入
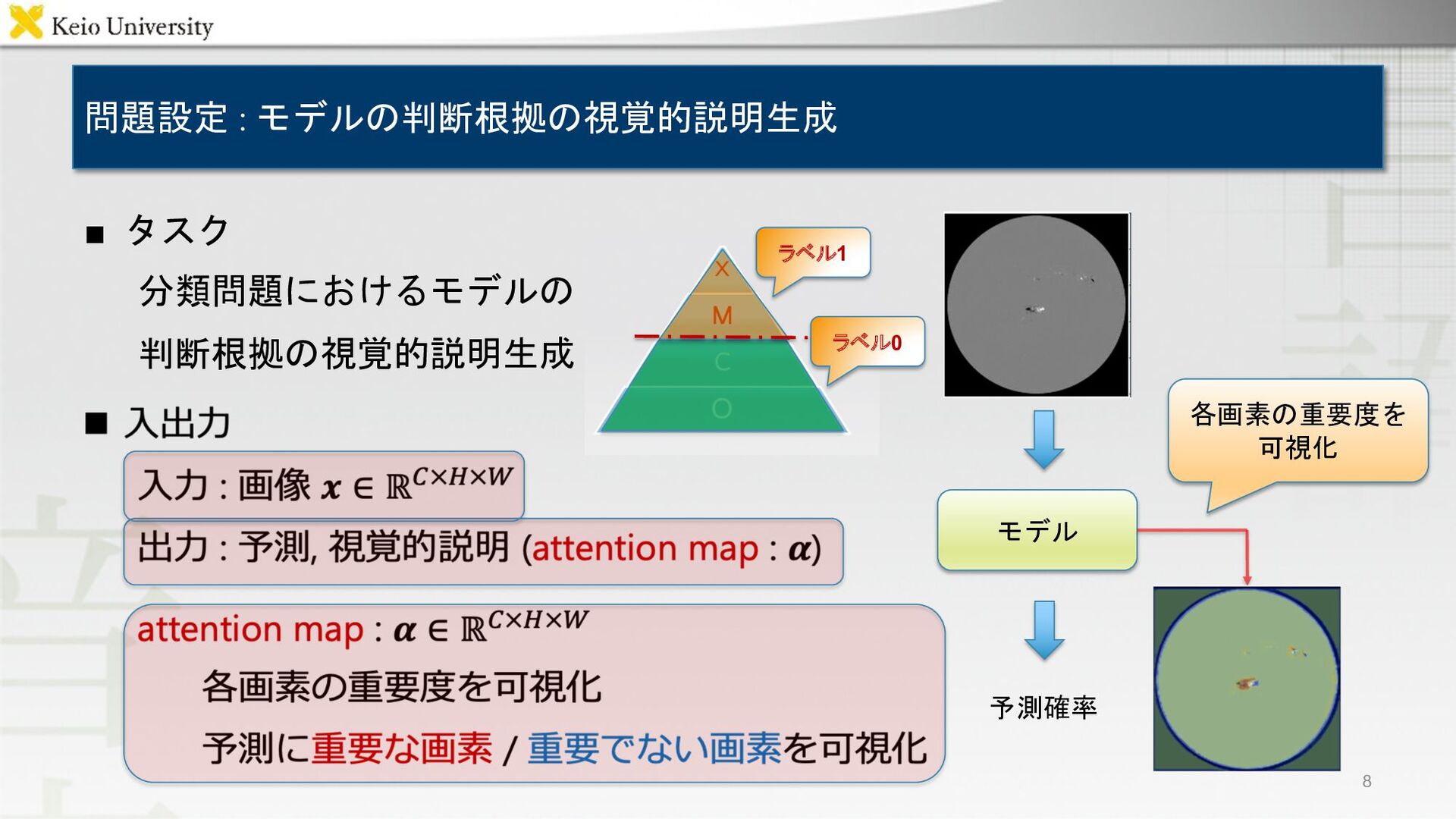
問題設定 : モデルの判断根拠の視覚的説明生成 ▪ タスク 分類問題におけるモデルの 判断根拠の視覚的説明生成 8 モデル 予測確率
各画素の重要度を 可視化 ラベル1 ラベル0
モデル構造の概要 : 視覚的説明生成専用のブランチ構造を導入 • Lambda Networks[Bello+, ICLR21]を基にした3つのモジュールから成る • 説明生成モジュールとしてABN[Fukui+, CVPR19]を導入したLABNを使用
9
モジュール① : Lambda Feature Extractor (LFE)で特徴を抽出 • 10
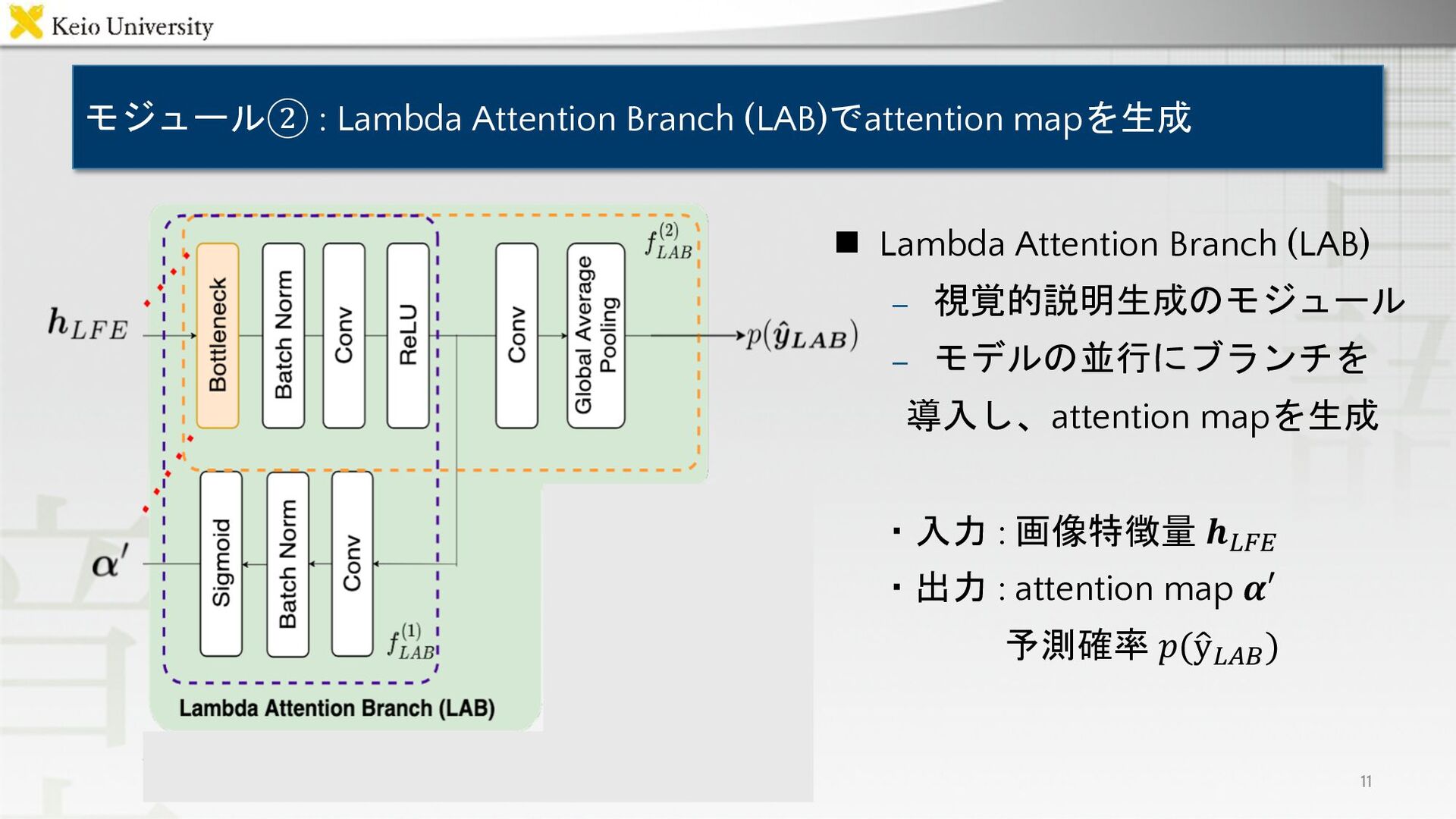
モジュール② : Lambda Attention Branch (LAB)でattention mapを生成 11 n Lambda
Attention Branch (LAB) – 視覚的説明生成のモジュール – モデルの並行にブランチを 導入し、attention mapを生成 ・入力 : 画像特徴量 𝒉!"# ・出力 : attention map 𝜶′ 予測確率 𝑝(: y!$% )
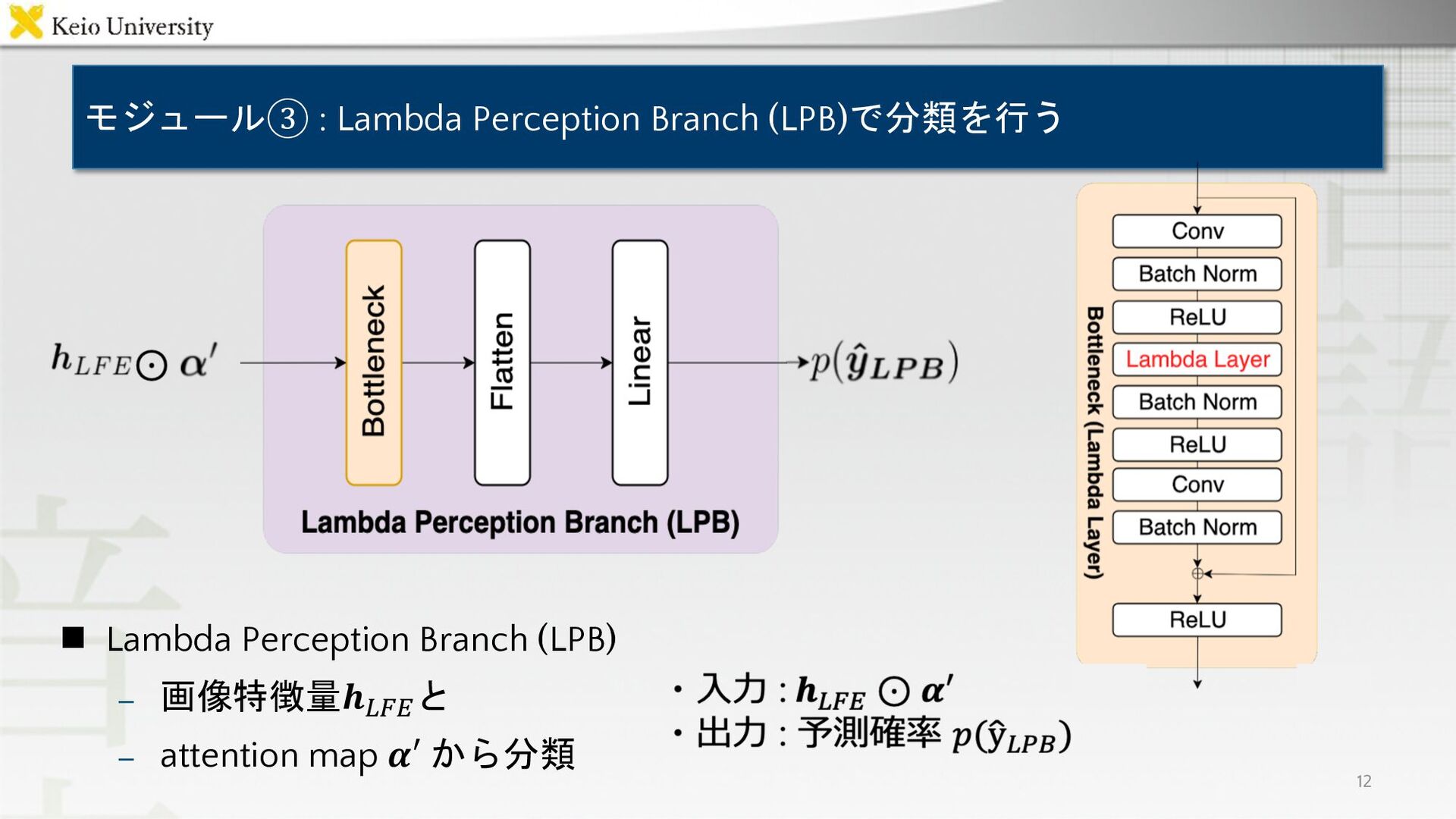
モジュール③ : Lambda Perception Branch (LPB)で分類を行う 12 n Lambda Perception
Branch (LPB) – 画像特徴量𝒉!"# と – attention map 𝜶′ から分類
損失関数 以下の損失𝐿を使用 𝐿 = 𝐿"#$ + 𝛼% 𝐿"&$ + 𝛼'
𝐿(" 𝐿!"# = 𝐶𝐸 𝑓!"# $ ⋅ , 𝒚 𝐿"&$ = 𝐶𝐸 𝑓)*+ ⋅ , 𝒚 𝐿(" = D,) 𝑓"&$ 𝑥 ||𝑓"&$ (𝑥-) 𝑓(⋅) 提案ネットワーク 𝒙, 𝑦 , 𝑥′ 入出力, マスクした画像 𝐶𝐸(⋅,⋅) 交差エントロピー 𝐷!" -∥- KLダイバージェンス 𝛼# , 𝛼$ 損失の重み 13 𝑓!&% 𝑓!$% (()
新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 attention
map 14
新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 attention
map 15
新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 attention
map 16
新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 マスクした画像
17 重要な領域の影響を大きくし、 重要でない領域の影響を軽減
新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 attention
map 18 実際は、バイアス画像 でマスク画像を作成
新規性②: バイアス画像によるマスク • 元画像 バイアス画像 Deletion 19 Insertion マスクされている
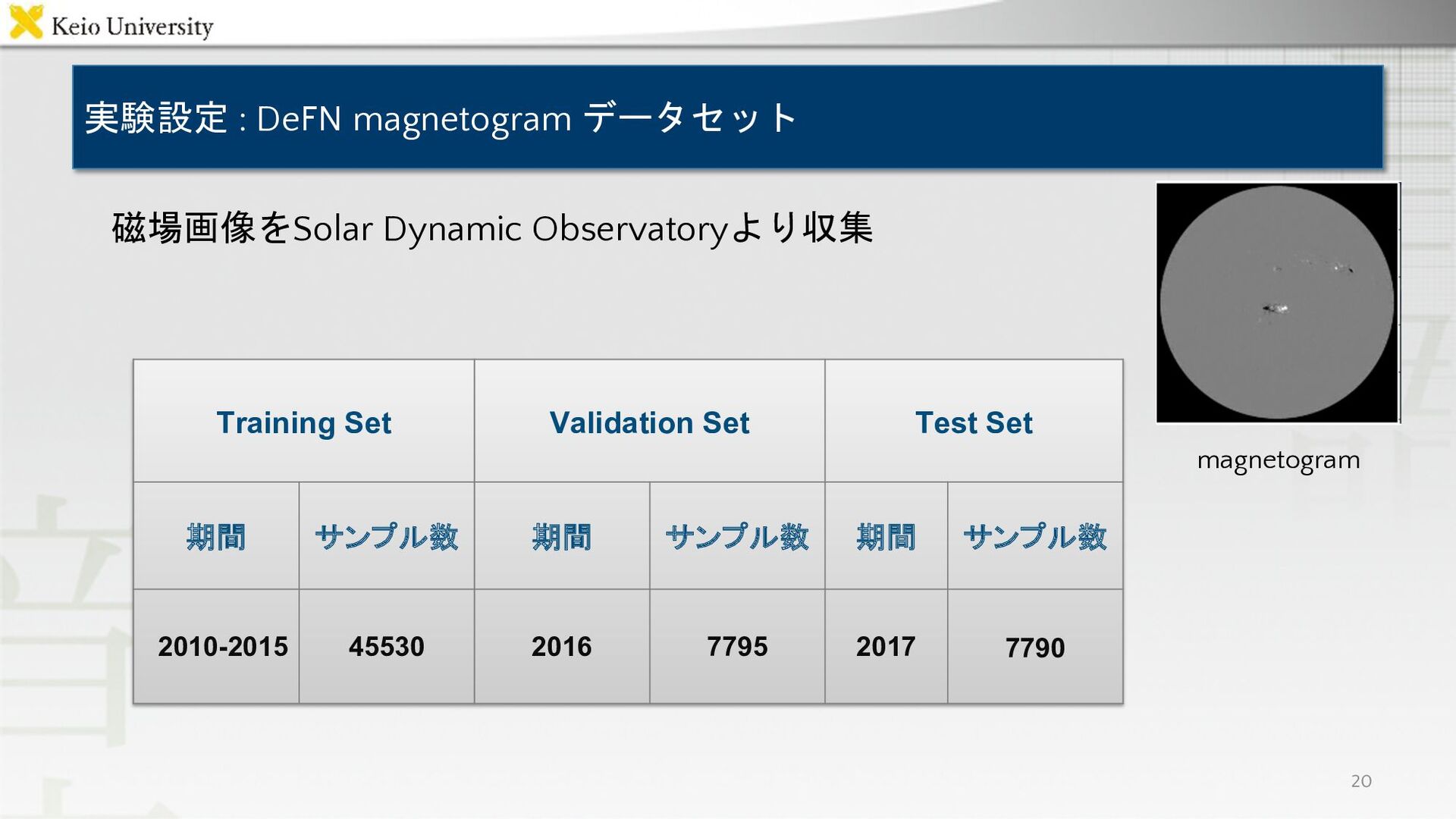
実験設定 : DeFN magnetogram データセット 20 磁場画像をSolar Dynamic Observatoryより収集 Training
Set Validation Set Test Set 期間 サンプル数 期間 サンプル数 期間 サンプル数 2010-2015 45530 2016 7795 2017 7790 magnetogram
評価指標 : Insertion-Deletion score(IDs) ・Patch Insertion-Deletion score(PID) 21 Deletion Insertion
Patch Deletion Patch Insertion Patch Insertion-Deletion score (PID) 1. 画像を𝑚×𝑚のパッチに分割 2. attention mapに基づき、 重要なパッチから挿入/削除を行う 3. 挿入 / 削除したパッチ数と モデルの予測確率をプロット PID = AUC Insertion − AUC(Deletion) 1画素単位ではなく パッチ単位で挿入/削除
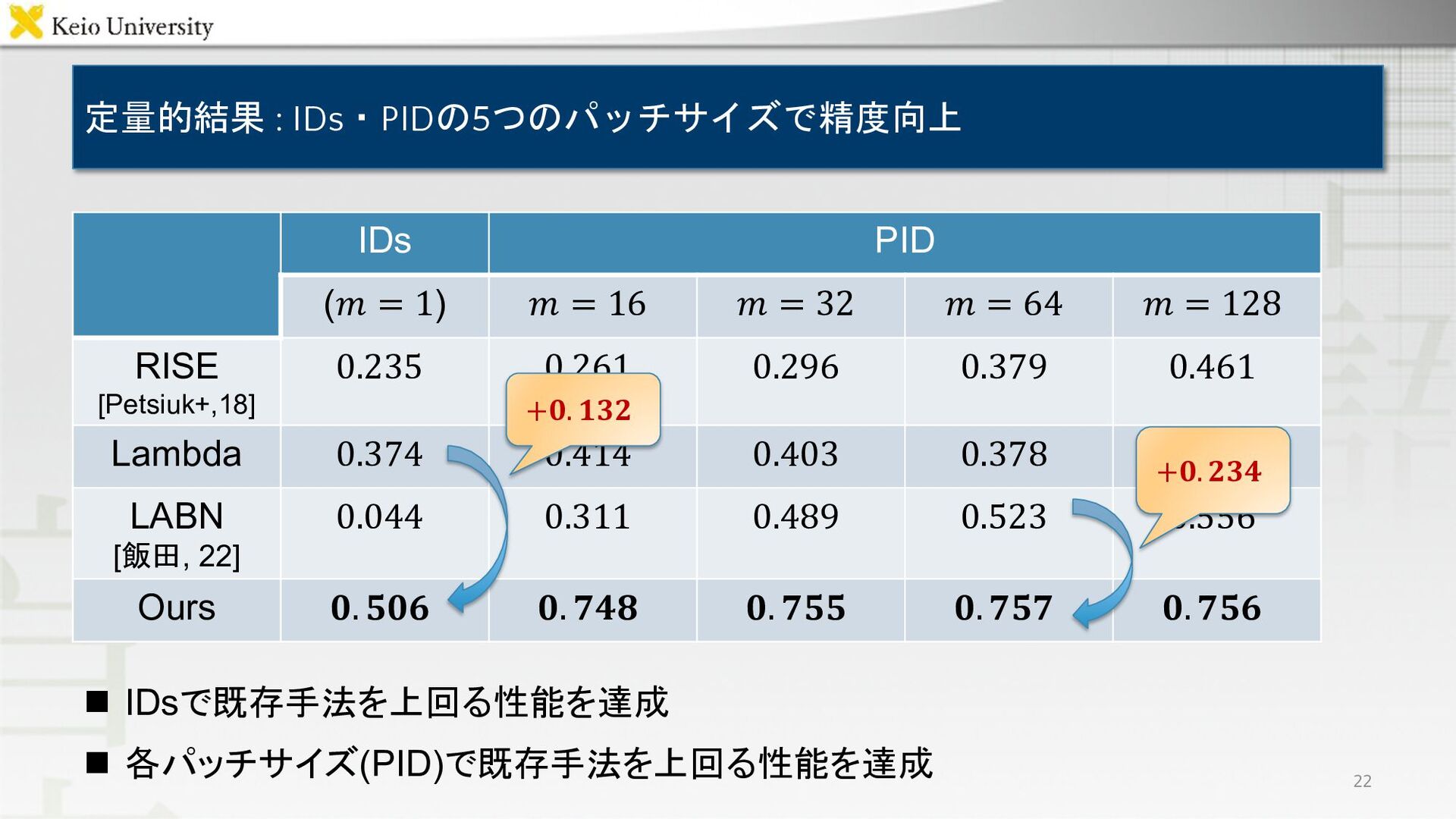
定量的結果 : IDs・PIDの5つのパッチサイズで精度向上 IDs PID (𝑚 = 1) 𝑚 =
16 𝑚 = 32 𝑚 = 64 𝑚 = 128 RISE [Petsiuk+,18] 0.235 0.261 0.296 0.379 0.461 Lambda 0.374 0.414 0.403 0.378 0.291 LABN [飯田, 22] 0.044 0.311 0.489 0.523 0.556 Ours 𝟎. 𝟓𝟎𝟔 𝟎. 𝟕𝟒𝟖 𝟎. 𝟕𝟓𝟓 𝟎. 𝟕𝟓𝟕 𝟎. 𝟕𝟓𝟔 n IDsで既存手法を上回る性能を達成 n 各パッチサイズ(PID)で既存手法を上回る性能を達成 22 +𝟎. 𝟏𝟑𝟐 +𝟎. 𝟐𝟑𝟒
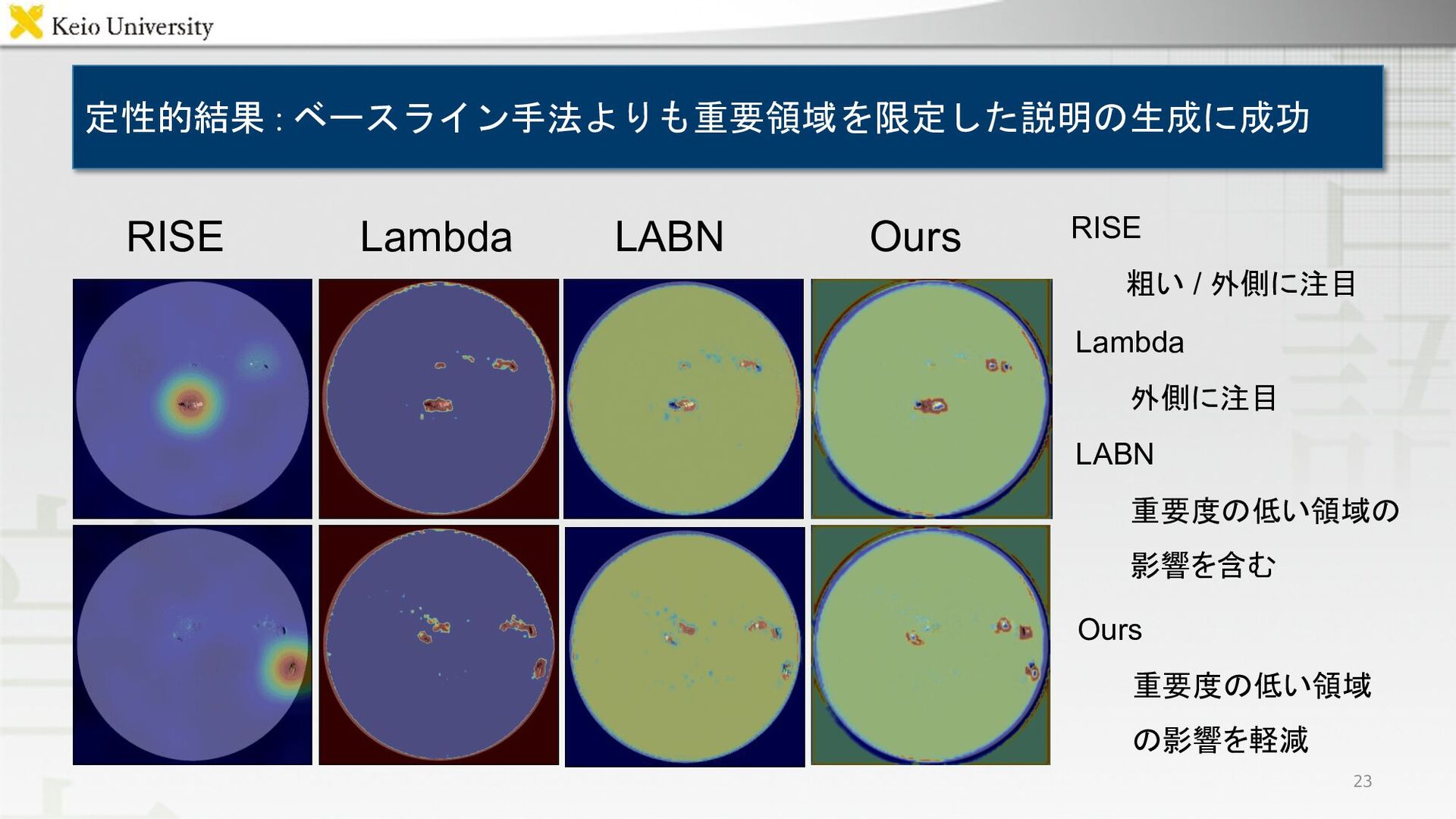
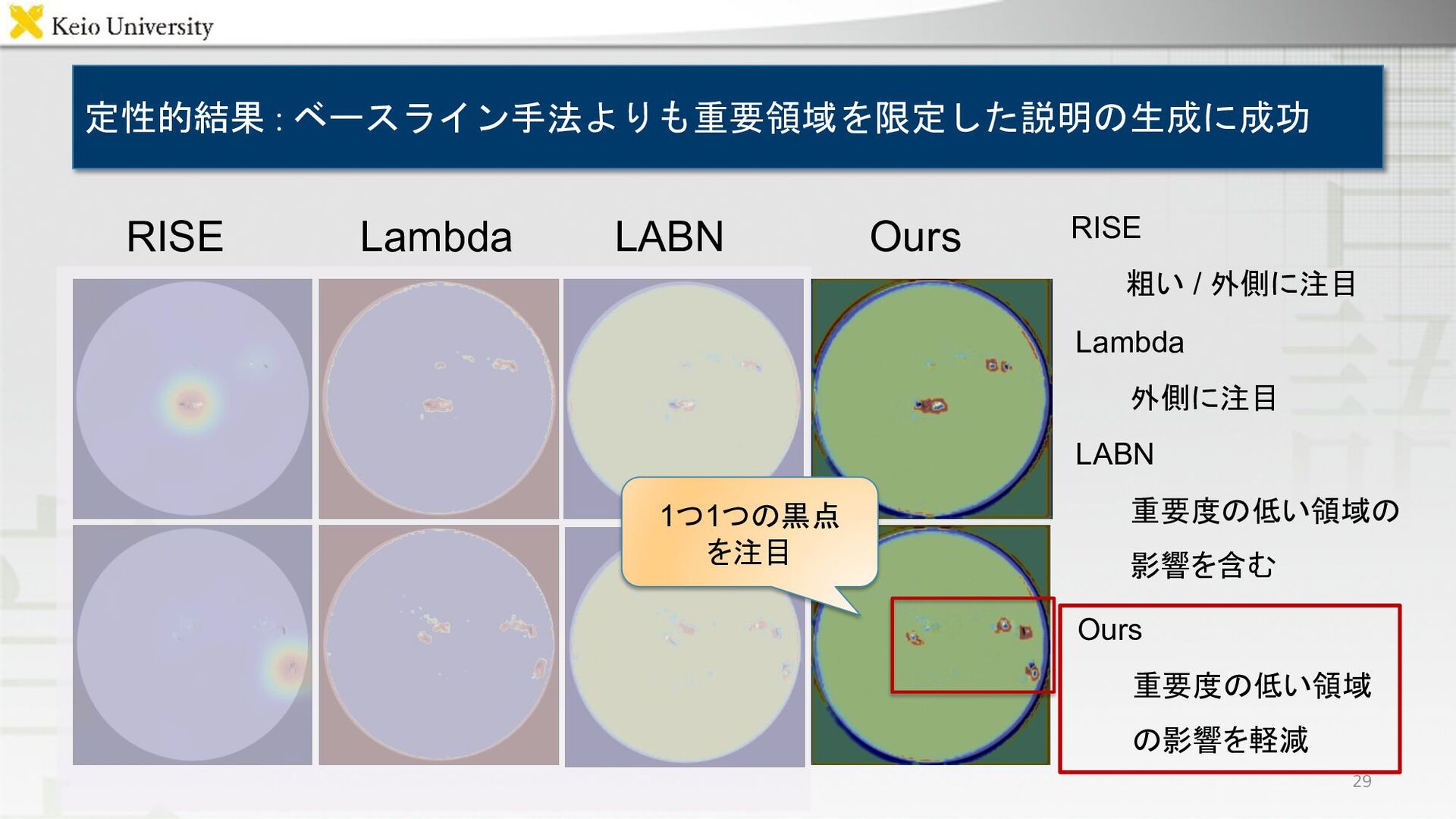
定性的結果 : ベースライン手法よりも重要領域を限定した説明の生成に成功 RISE Lambda LABN Ours Ours 重要度の低い領域 の影響を軽減
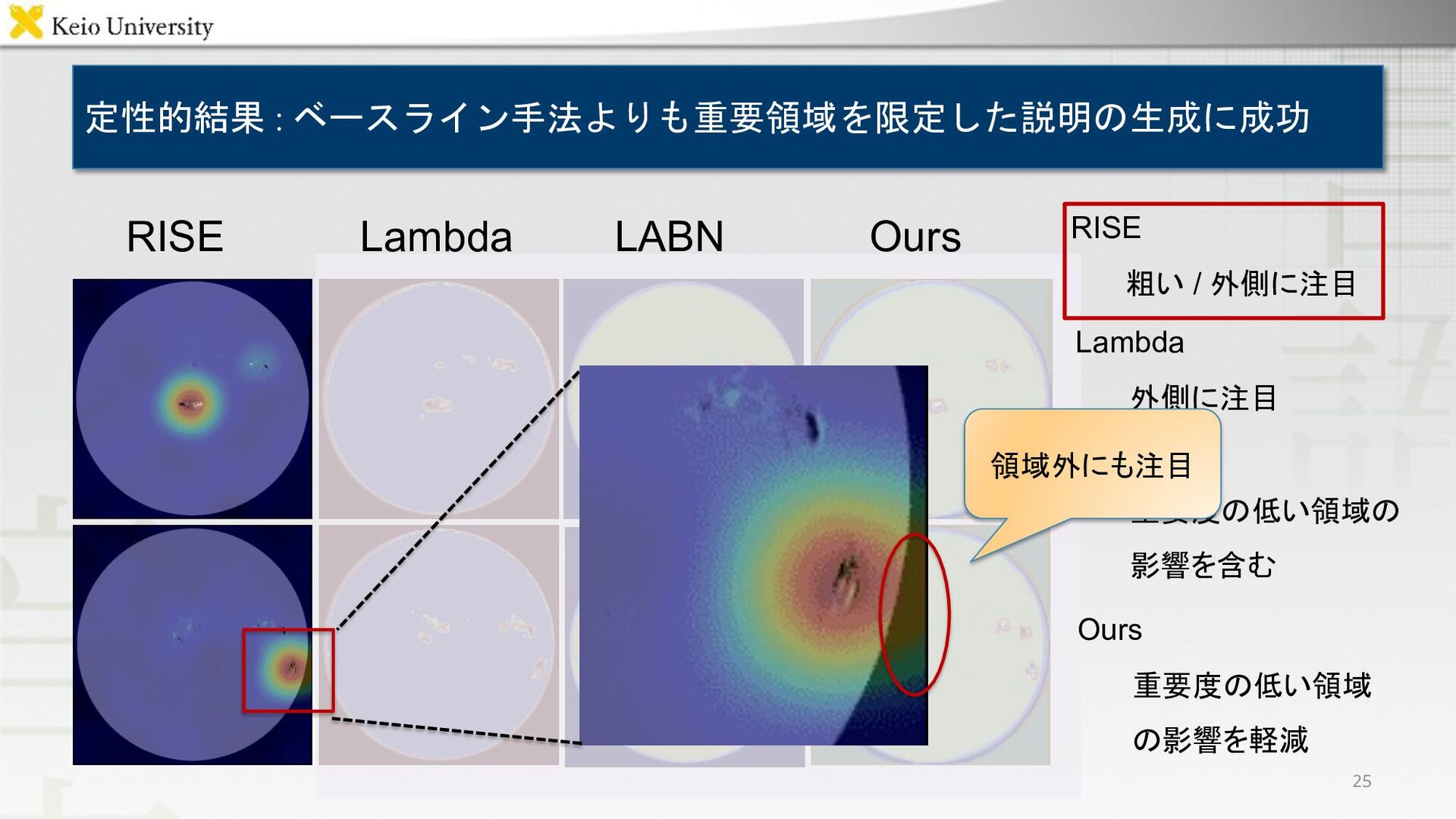
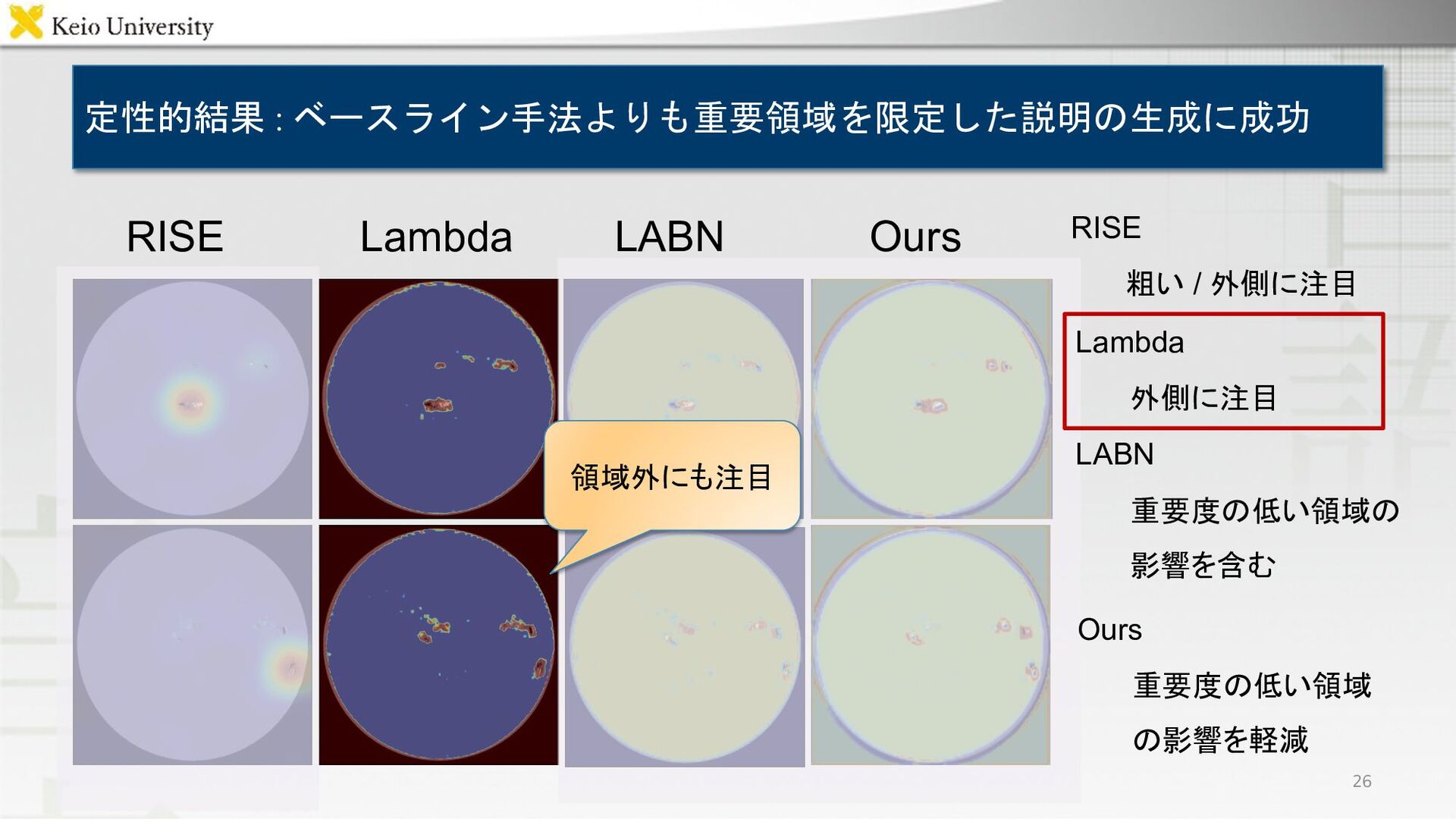
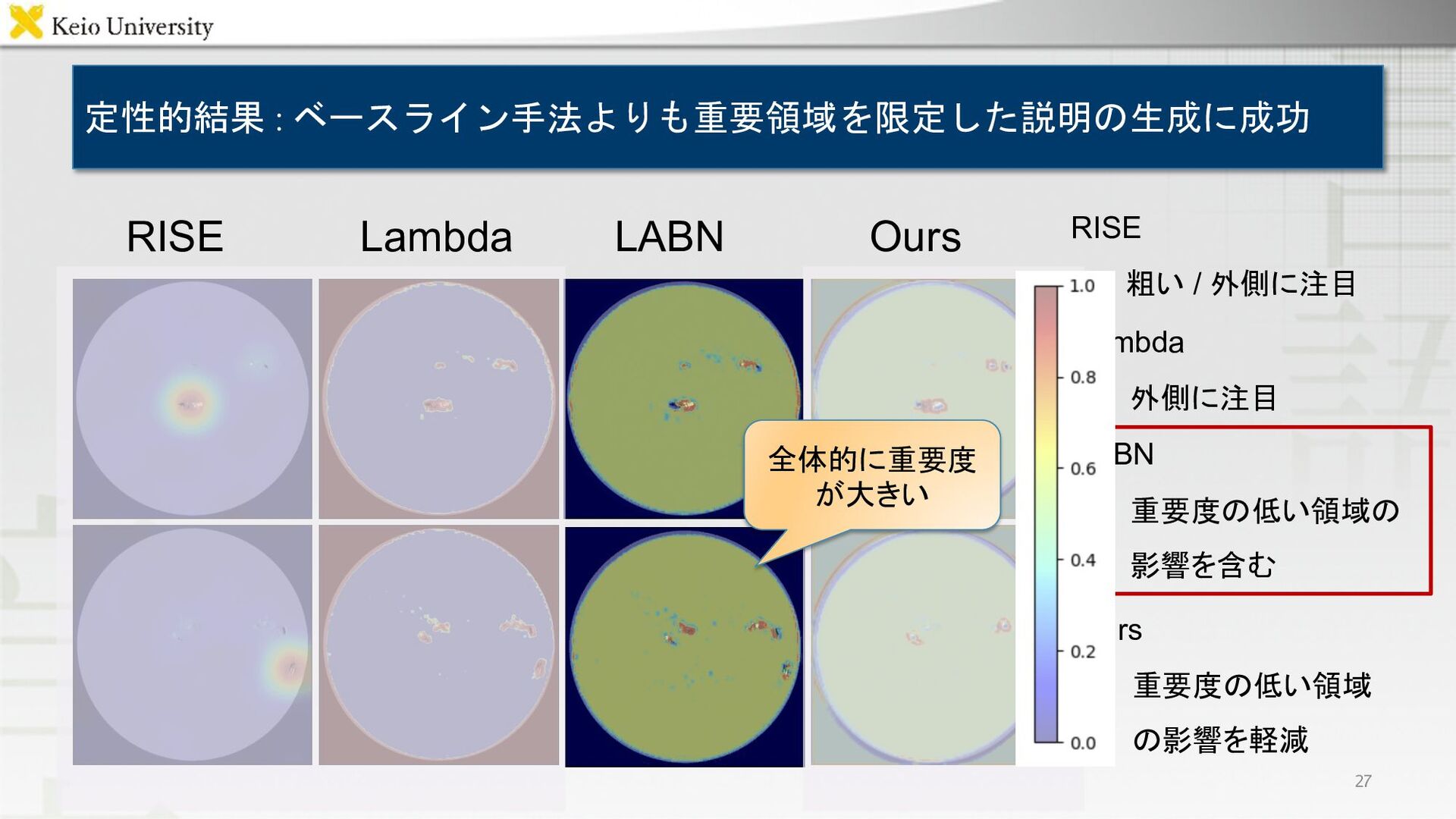
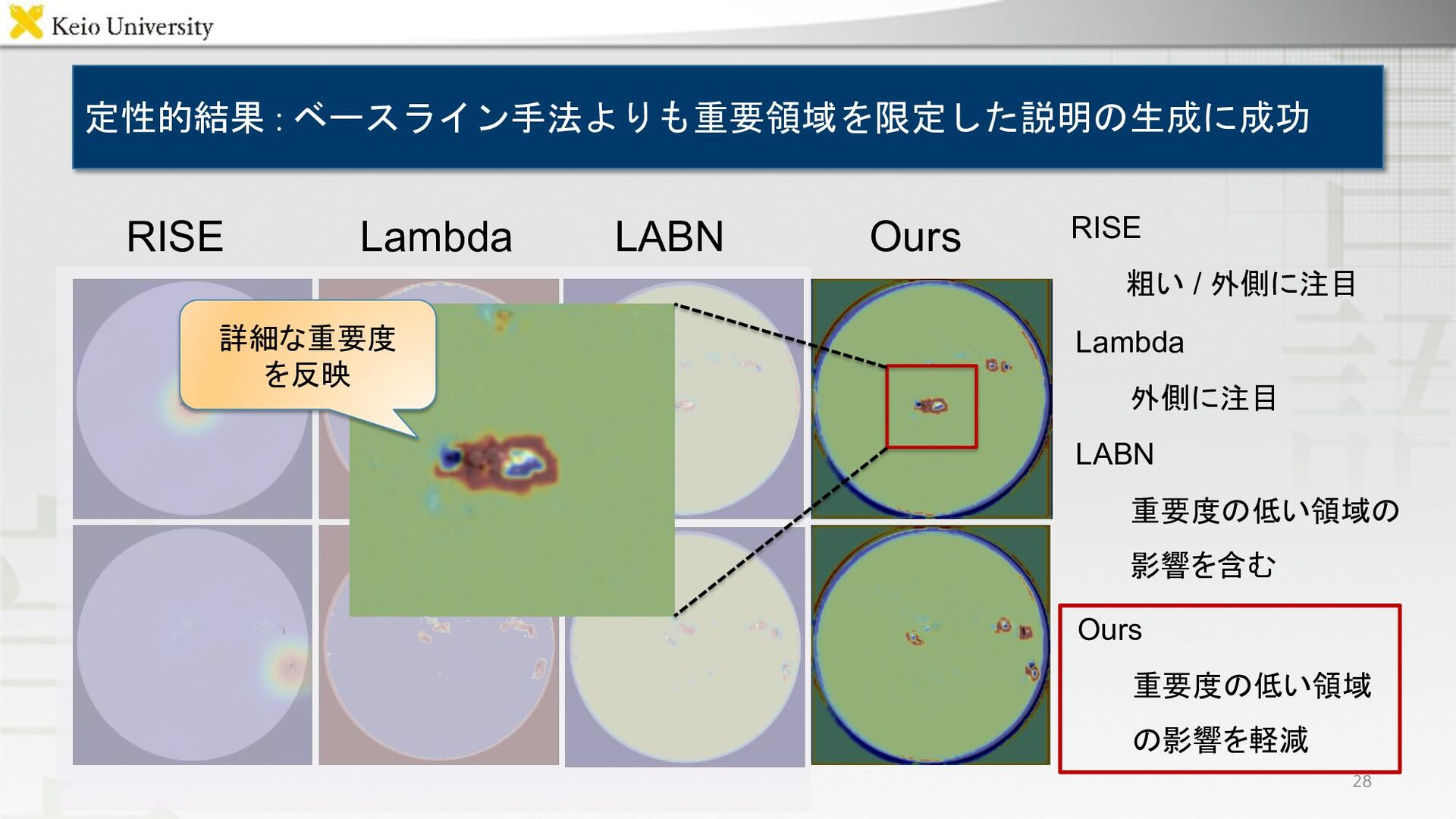
RISE 粗い / 外側に注目 Lambda 外側に注目 LABN 重要度の低い領域の 影響を含む 23
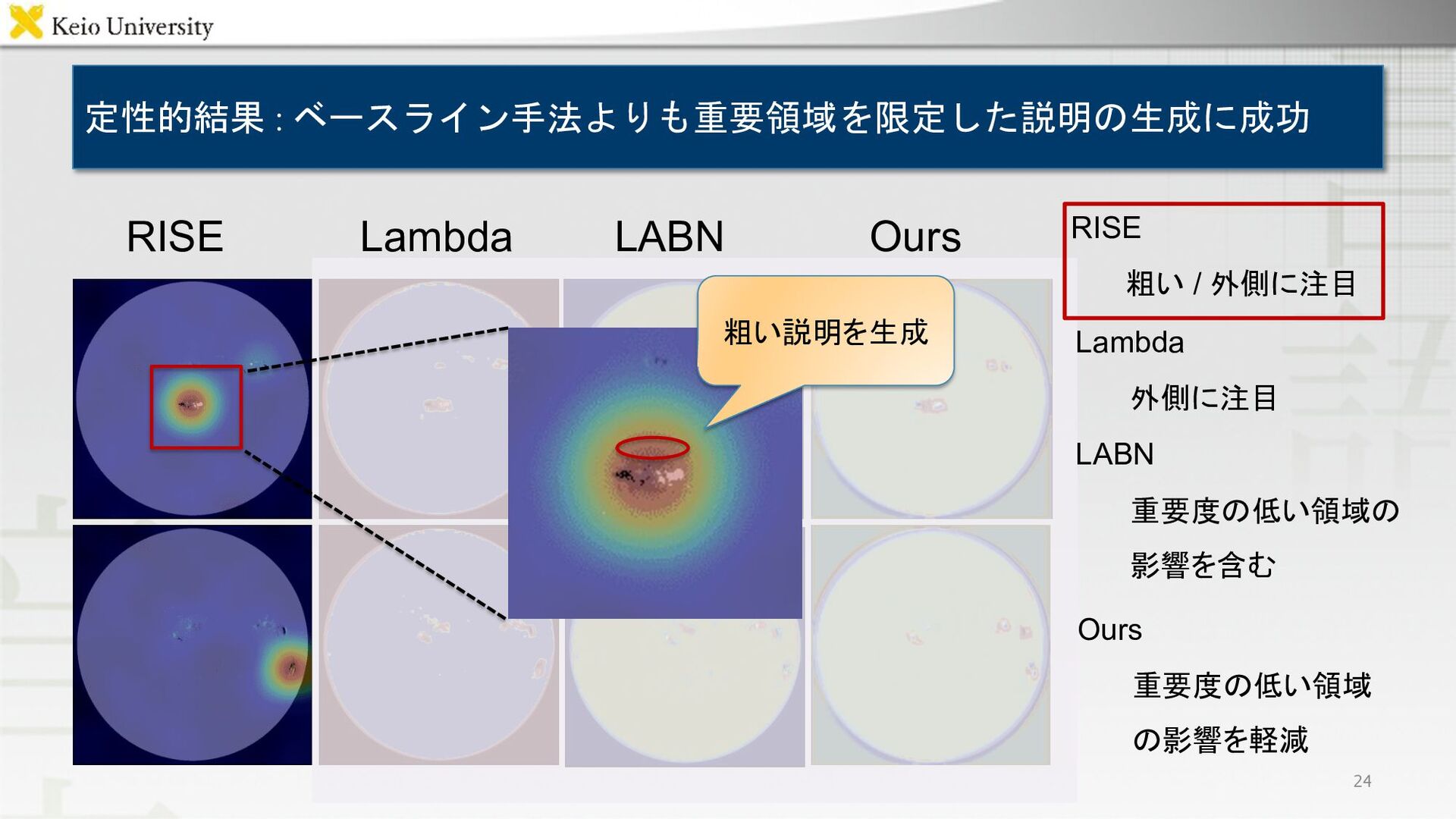
定性的結果 : ベースライン手法よりも重要領域を限定した説明の生成に成功 RISE Lambda LABN Ours 24 粗い説明を生成 Ours
重要度の低い領域 の影響を軽減 RISE 粗い / 外側に注目 Lambda 外側に注目 LABN 重要度の低い領域の 影響を含む
定性的結果 : ベースライン手法よりも重要領域を限定した説明の生成に成功 RISE Lambda LABN Ours 25 Ours 重要度の低い領域
の影響を軽減 RISE 粗い / 外側に注目 Lambda 外側に注目 LABN 重要度の低い領域の 影響を含む 領域外にも注目
定性的結果 : ベースライン手法よりも重要領域を限定した説明の生成に成功 RISE Lambda LABN Ours 26 領域外にも注目 Ours
重要度の低い領域 の影響を軽減 RISE 粗い / 外側に注目 Lambda 外側に注目 LABN 重要度の低い領域の 影響を含む
定性的結果 : ベースライン手法よりも重要領域を限定した説明の生成に成功 RISE Lambda LABN Ours 27 全体的に重要度 が大きい
Ours 重要度の低い領域 の影響を軽減 RISE 粗い / 外側に注目 Lambda 外側に注目 LABN 重要度の低い領域の 影響を含む
定性的結果 : ベースライン手法よりも重要領域を限定した説明の生成に成功 RISE Lambda LABN Ours 28 詳細な重要度 を反映
Ours 重要度の低い領域 の影響を軽減 RISE 粗い / 外側に注目 Lambda 外側に注目 LABN 重要度の低い領域の 影響を含む
定性的結果 : ベースライン手法よりも重要領域を限定した説明の生成に成功 RISE Lambda LABN Ours 29 1つ1つの黒点 を注目
Ours 重要度の低い領域 の影響を軽減 RISE 粗い / 外側に注目 Lambda 外側に注目 LABN 重要度の低い領域の 影響を含む
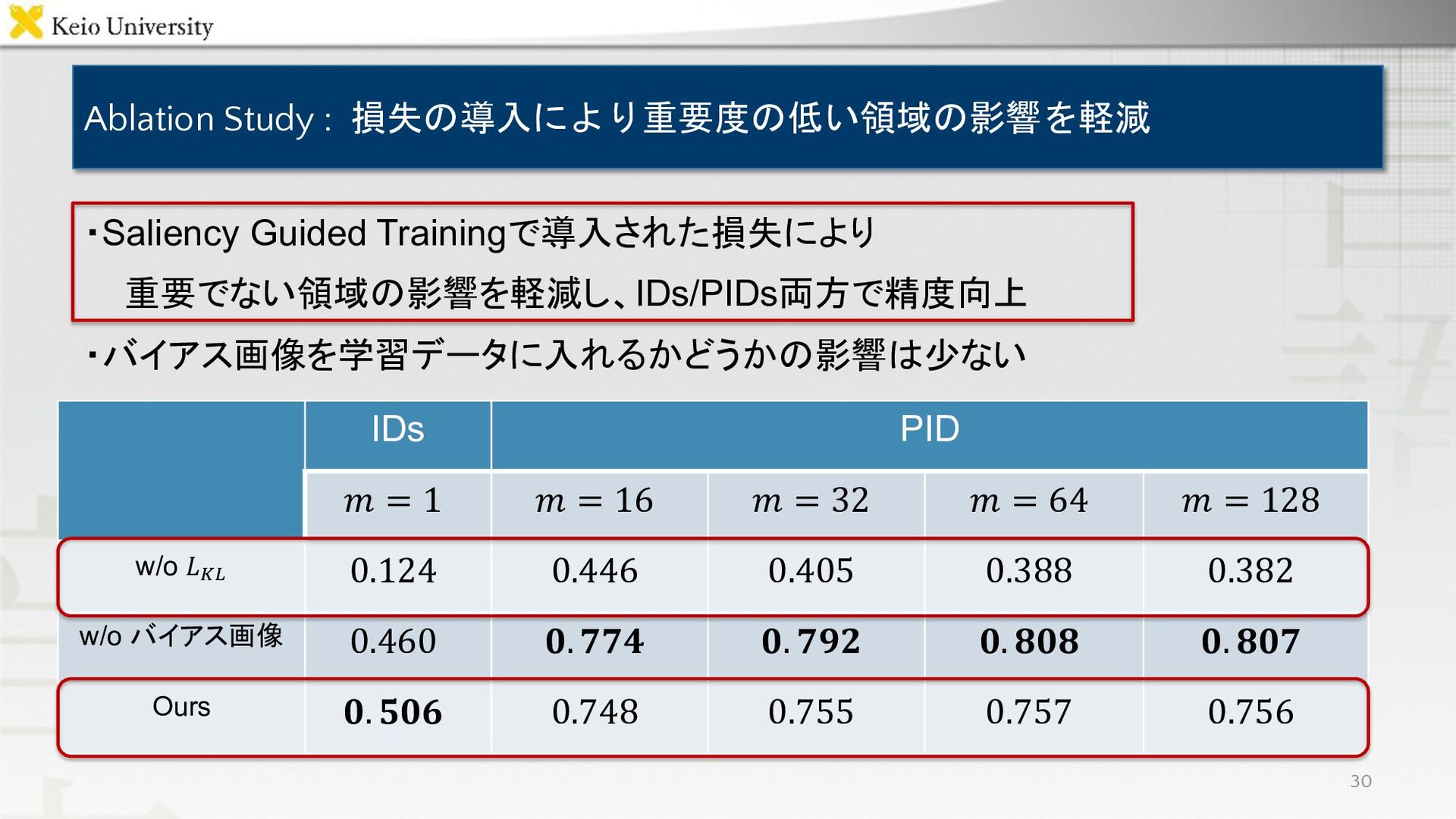
Ablation Study : 損失の導入により重要度の低い領域の影響を軽減 IDs PID 𝑚 = 1 𝑚
= 16 𝑚 = 32 𝑚 = 64 𝑚 = 128 w/o 𝐿!" 0.124 0.446 0.405 0.388 0.382 w/o バイアス画像 0.460 𝟎. 𝟕𝟕𝟒 𝟎. 𝟕𝟗𝟐 𝟎. 𝟖𝟎𝟖 𝟎. 𝟖𝟎𝟕 Ours 𝟎. 𝟓𝟎𝟔 0.748 0.755 0.757 0.756 ・Saliency Guided Trainingで導入された損失により 重要でない領域の影響を軽減し、IDs/PIDs両方で精度向上 ・バイアス画像を学習データに入れるかどうかの影響は少ない 30
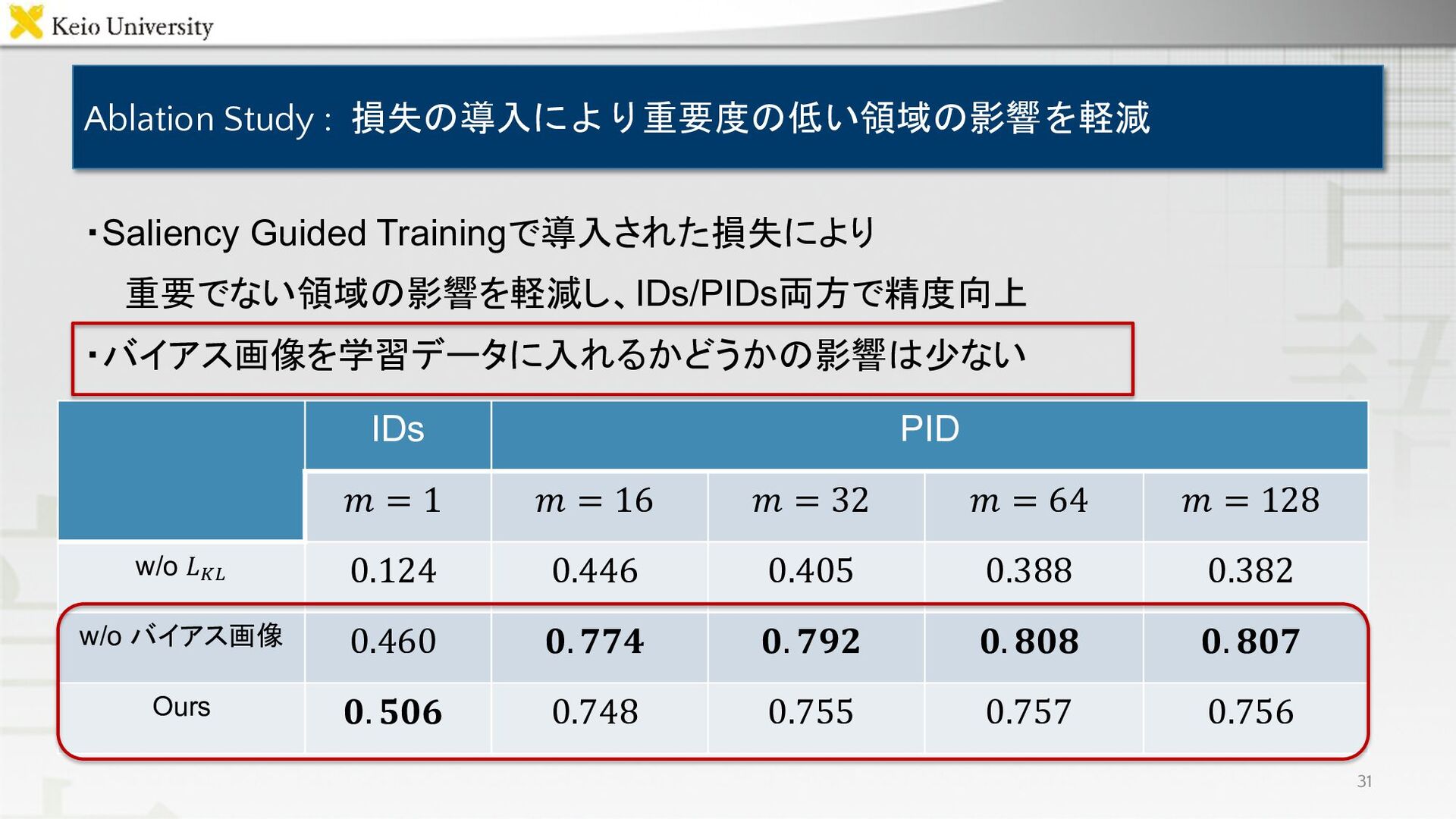
Ablation Study : 損失の導入により重要度の低い領域の影響を軽減 IDs PID 𝑚 = 1 𝑚
= 16 𝑚 = 32 𝑚 = 64 𝑚 = 128 w/o 𝐿!" 0.124 0.446 0.405 0.388 0.382 w/o バイアス画像 0.460 𝟎. 𝟕𝟕𝟒 𝟎. 𝟕𝟗𝟐 𝟎. 𝟖𝟎𝟖 𝟎. 𝟖𝟎𝟕 Ours 𝟎. 𝟓𝟎𝟔 0.748 0.755 0.757 0.756 ・Saliency Guided Trainingで導入された損失により 重要でない領域の影響を軽減し、IDs/PIDs両方で精度向上 ・バイアス画像を学習データに入れるかどうかの影響は少ない 31
まとめ • 背景 視覚的説明生成により、未解明な現象に洞察を与えることが可能 一方、既存手法では粗い説明を生成する • 提案手法 Saliency Guided Trainingによる学習方法を導入し
非重要領域の影響を軽減 マスク画像としてバイアス画像を提案 • 結果 IDs / PID の5つのパッチサイズでベースライン手法を上回った 32 Deletion バイアス画像 黒画素
Appendix︓Lambda Networks [Bello+, ICLR21] ・Lambda Layer CNNとの親和性が高い ・transformer層 ViTより少ない計算量で 広範囲の関係を捉えることが可能
ViT Lambda 33
Appendix︓Lambda Networks [Bello+, ICLR21] 34 ・入力𝒉を畳みこみQuery, Key, Valueの生成 𝑄 =
𝐶𝑜𝑛𝑣 𝒉 , 𝑉 = 𝑐𝑜𝑛𝑣 𝒉 , 𝐾 = 𝑆𝑜𝑓𝑡𝑚𝑎𝑥(𝐶𝑜𝑛𝑣 𝒉 ) ・valueの変換, key,valueの積で𝝀! , 𝝀" を生成 𝝀! = 𝐶𝑜𝑛𝑣 𝑉 , 𝝀" = 𝐾#𝑉 ・最終出力: 𝒉$ 𝒉$ = 𝝀! + 𝝀" # 𝑄
Appendix︓Lambda Networks [Bello+, ICLR21] 35 ・計算 𝝀! = 𝐶𝑜𝑛𝑣 𝑉
, 𝝀" = 𝐾#𝑉 𝒉$ = 𝝀! + 𝝀" # 𝑄 à 𝝀" はQを縮約する関数と見做せる
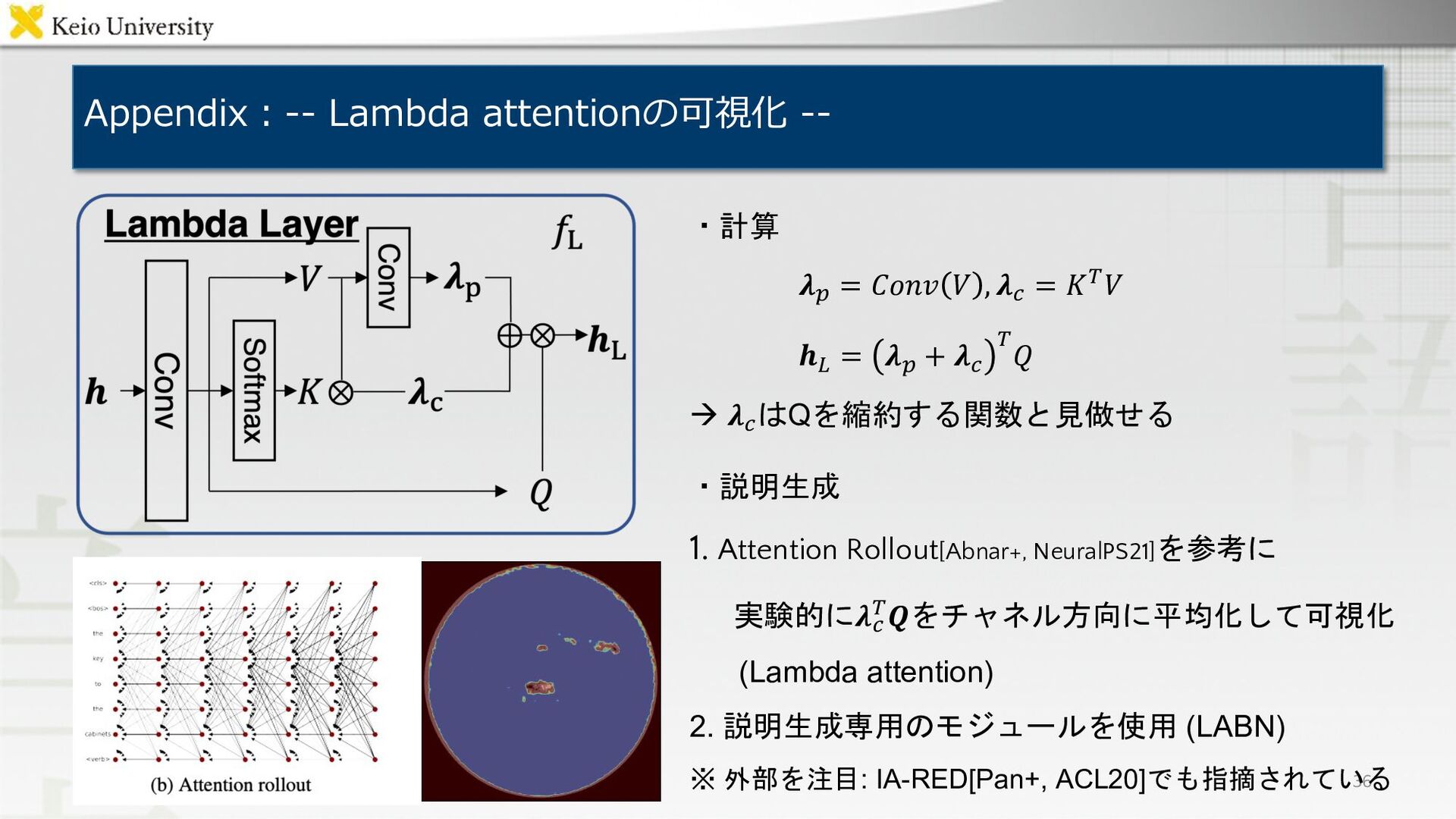
Appendix︓-- Lambda attentionの可視化 -- 36 ・計算 𝝀! = 𝐶𝑜𝑛𝑣 𝑉
, 𝝀" = 𝐾#𝑉 𝒉$ = 𝝀! + 𝝀" # 𝑄 à 𝝀" はQを縮約する関数と見做せる ・説明生成 1. Attention Rollout[Abnar+, NeuralPS21]を参考に 実験的に𝝀" #𝑸をチャネル方向に平均化して可視化 (Lambda attention) 2. 説明生成専用のモジュールを使用 (LABN) ※ 外部を注目: IA-RED[Pan+, ACL20]でも指摘されている
Appendix : 既存研究 -- RISE[Petsiuk+, BMCV18] -- 37 ▪ 可視化手順
1. ランダムにマスクを生成 2. マスクした画像を モデルに入力 3. 予測の変化に応じて マスクに重み付け 4. 3を可視化 ▪ 予測の変化 予測の変化大 à 重要 予測の変化小 à 非重要
Appendix︓IDsは重要領域がスパースな画像に不適切 -- PID -- 6 粗いattention map deletionの入力 詳細なattention map
deletionの入力 元画像 1 2 3 4 5 6 7 8 9 カーネル 0 0 0 0 0 0 0 0 0 粗く削除された場合 0 0 1 1 0 0 0 0 0 細かく削除された場合 位置・カーネルによって出力が異なる 位置・カーネル依存性無し 0 7
Appendix:Patch Insertion-Deletion score 定義式 1. 入力画像 𝒙 を𝑚 × 𝑚のパッチ
𝒑%& ∈ ℝ"!×(" に分割 2. attention map 𝜶 にmax-poolingを適用して パッチごとのattention map 𝒂) ∈ ℝ(" を作成 3. 𝒂) の要素を、値が大きい順番に𝛼%#&# , 𝛼%"&" , ⋯ , 𝛼%$&$ とする 4. 集合𝐴* を 𝐴* = 𝑖+, 𝑗+ | 𝑘 ≤ 𝑛 と定義(重要度上位𝑛個のインデックス) 5. Insertion, Deletionの入力𝒊*, 𝒅* はそれぞれ下記の様に定義される
Appendix : マスクによる予測への影響[Srinivas+, NeurlPS19] ▪ 問題点 予測の変化に対する影響が ・重要箇所の挿入/削除 ・分布の変化 ・高周波成分(エッジなど)
どの影響なのか明確化するのは困難 従来の手法でmaskした画像 40 ▪ 既存手法 重要度の高い領域から 黒画素で挿入/削除を行う
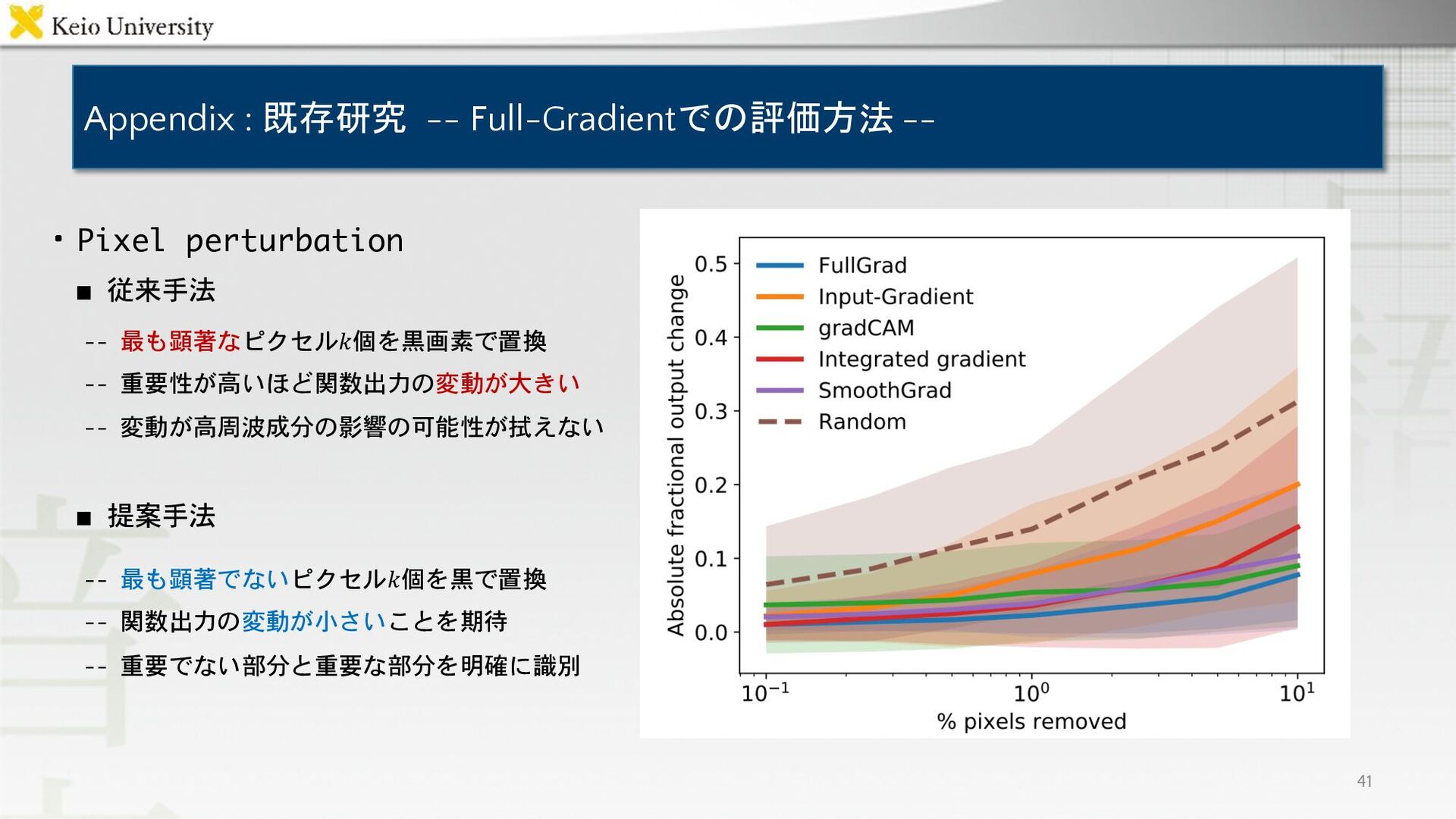
Appendix : 既存研究 -- Full-Gradientでの評価方法 -- 41 ・Pixel perturbation ▪
従来手法 -- 最も顕著なピクセル𝑘個を黒画素で置換 -- 重要性が高いほど関数出力の変動が大きい -- 変動が高周波成分の影響の可能性が拭えない ▪ 提案手法 -- 最も顕著でないピクセル𝑘個を黒で置換 -- 関数出力の変動が小さいことを期待 -- 重要でない部分と重要な部分を明確に識別
Appendix : 既存研究 -- Full-Gradientでの評価方法 -- 42 ▪ 従来手法 --
最も顕著なピクセル𝑘個を黒画素で置換 -- 重要性が高いほど関数出力の変動が大きい -- 変動が高周波成分の影響の可能性が拭えない ▪ 提案手法 -- 最も顕著でないピクセル𝑘個を黒で置換 -- 関数出力の変動が小さいことを期待 -- 重要でない部分と重要な部分を明確に識別 元画像 25%置換 75%置換 0.90 0.88 0.85 ⇦ 0.90 ⇦ 0.90 元画像 25%置換 75%置換 0.90 0.20 0.10 ⇦ 0.90 ⇦ 0.90
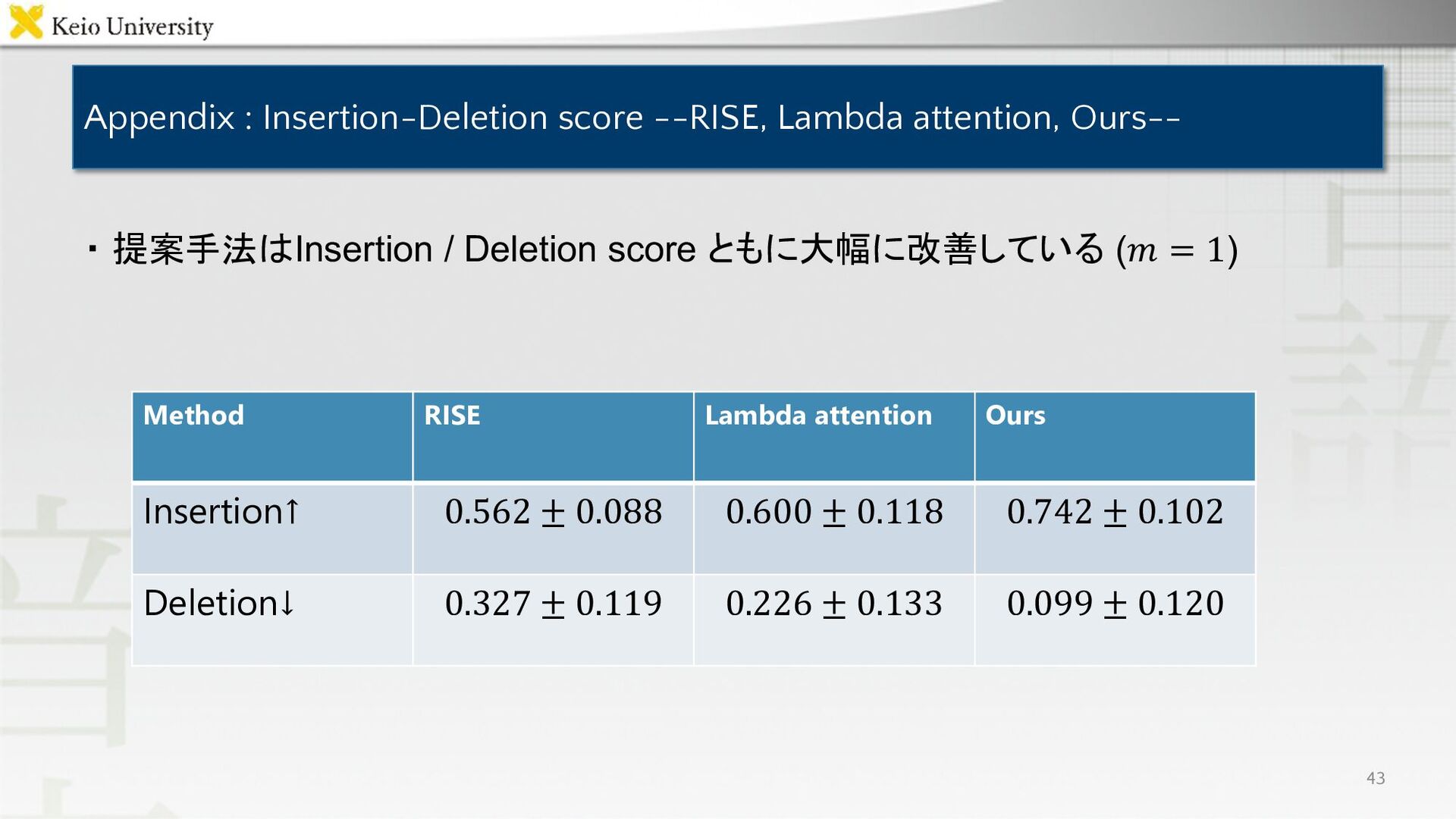
Appendix : Insertion-Deletion score --RISE, Lambda attention, Ours-- ・ 提案手法はInsertion
/ Deletion score ともに大幅に改善している (𝑚 = 1) 43 Method RISE Lambda attention Ours Insertion↑ 0.562 ± 0.088 0.600 ± 0.118 0.742 ± 0.102 Deletion↓ 0.327 ± 0.119 0.226 ± 0.133 0.099 ± 0.120
Appendix : 既存研究 -- LABM[飯田+, JSAI22] との比較 -- DeFN PID
𝑚 = 1 𝑚 = 16 𝑚 = 32 𝑚 = 64 𝑚 = 128 RISE [1] 0.235 0.261 0.296 0.379 0.461 Lambda 0.374 0.414 0.403 0.378 0.291 Ours 0.044 0.311 0.489 0.523 0.556 ・ 標準的な評価指標であるInsertion-Deletion scoreやパッチサイズの小さい時に ベースライン手法を超えていないという問題点があった
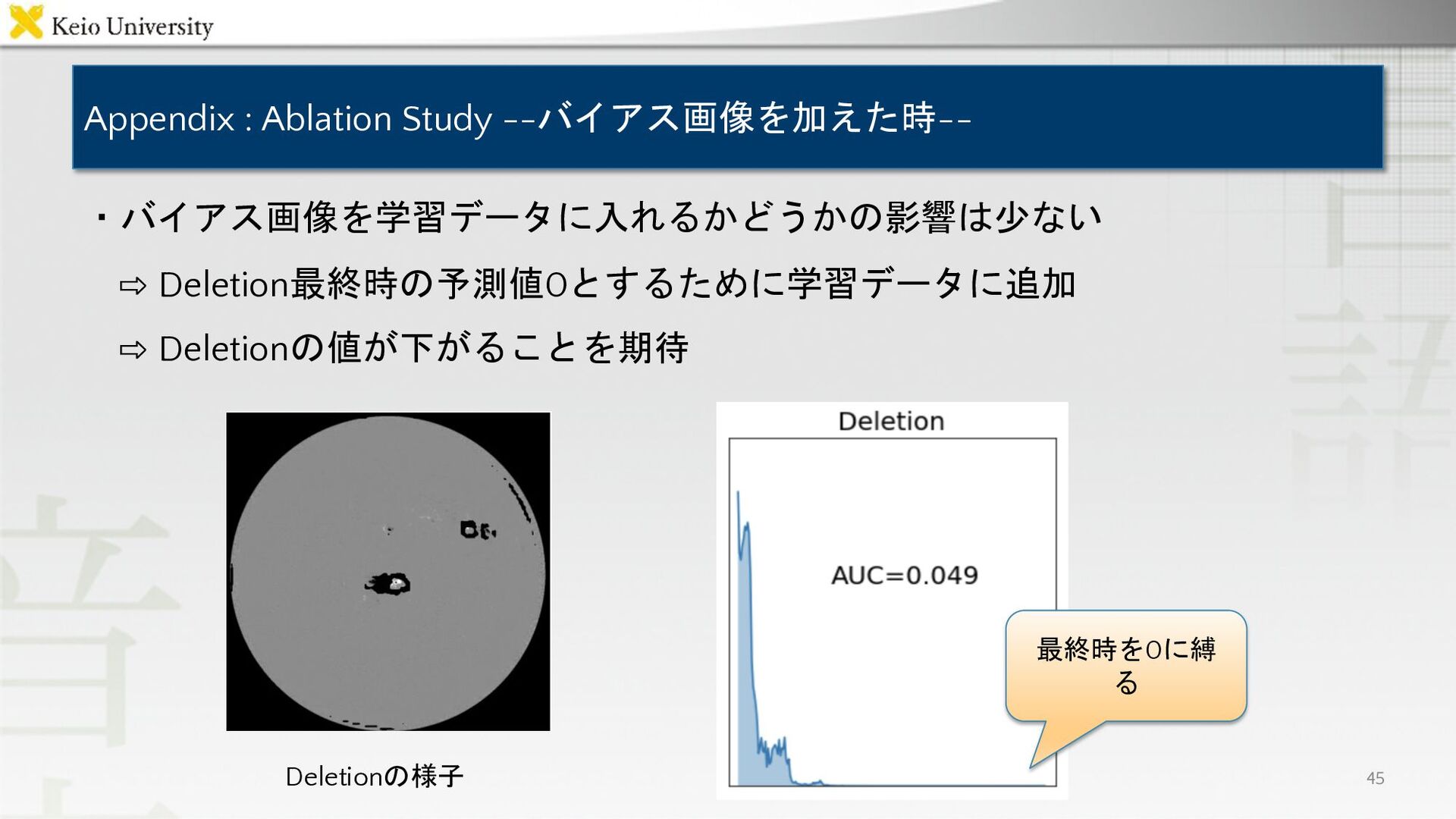
Appendix : Ablation Study --バイアス画像を加えた時-- ・バイアス画像を学習データに入れるかどうかの影響は少ない 45 ⇨ Deletion最終時の予測値0とするために学習データに追加 ⇨
Deletionの値が下がることを期待 Deletionの様子 最終時を0に縛 る
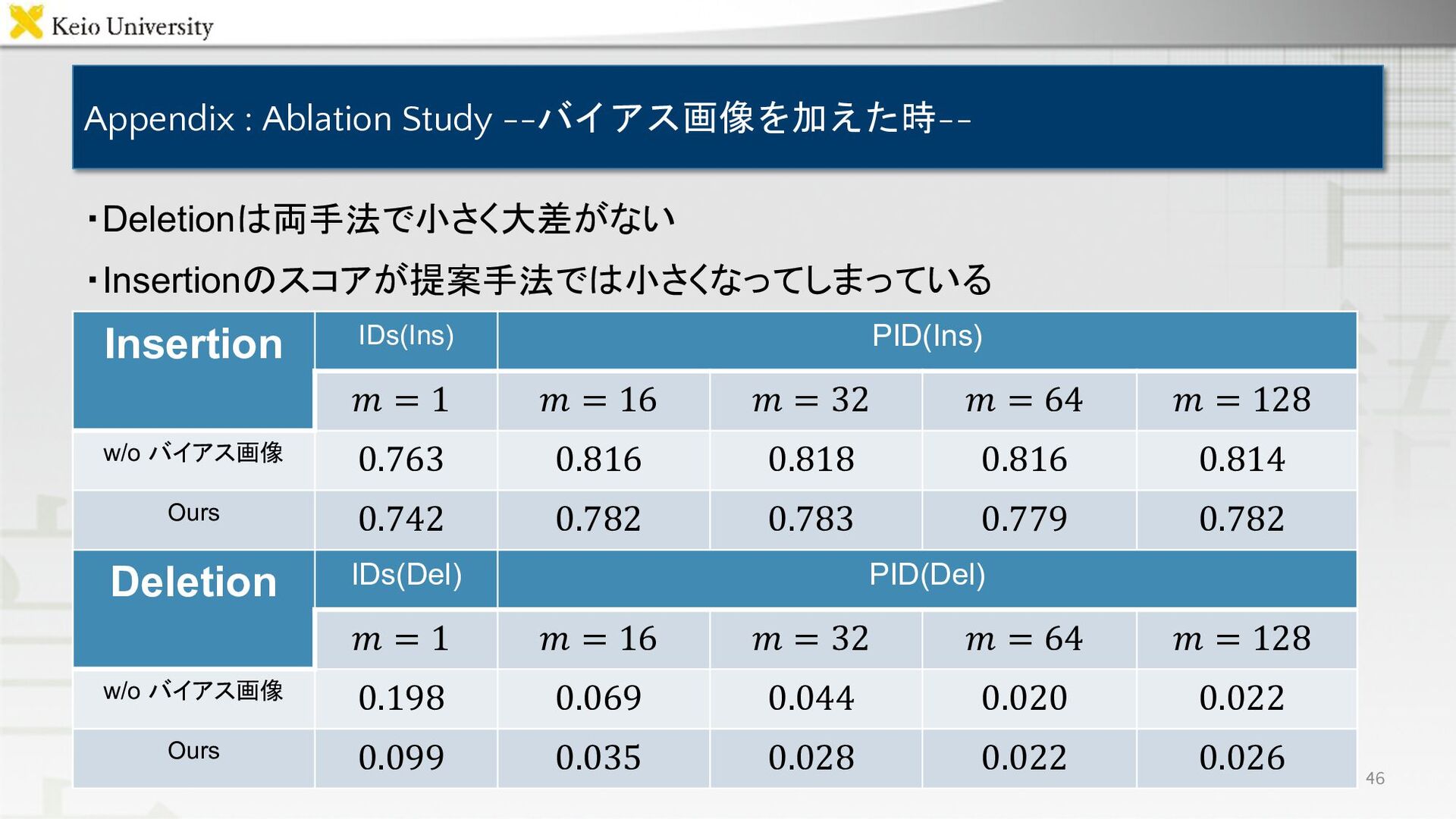
Appendix : Ablation Study --バイアス画像を加えた時-- Insertion IDs(Ins) PID(Ins) 𝑚 =
1 𝑚 = 16 𝑚 = 32 𝑚 = 64 𝑚 = 128 w/o バイアス画像 0.763 0.816 0.818 0.816 0.814 Ours 0.742 0.782 0.783 0.779 0.782 ・Deletionは両手法で小さく大差がない ・Insertionのスコアが提案手法では小さくなってしまっている 46 Deletion IDs(Del) PID(Del) 𝑚 = 1 𝑚 = 16 𝑚 = 32 𝑚 = 64 𝑚 = 128 w/o バイアス画像 0.198 0.069 0.044 0.020 0.022 Ours 0.099 0.035 0.028 0.022 0.026
Appendix : 発展 -- LABM[飯田+, JSAI22] との比較 (IDRiDを用いた場合でも最良) -- ・
追加実験 -- LABNと同様に、 IDRiDを用いた実験を行った ・結果 -- Insertion-Deletion score Patch Insertion-Deletion score 全てのパッチサイズで最良 IDRiD PID 𝑚 = 1 𝑚 = 2 𝑚 = 4 𝑚 = 8 𝑚 = 16 RISE [1] 0.319 0.179 0.130 0.136 0.148 Lambda -0.101 -0.105 -0.116 -0.123 0.093 LABN 0.111 0.084 0.150 0.183 0.230 Ours 0.431 0.458 0.473 0.470 0.455 DeFN PID 𝑚 = 1 𝑚 = 16 𝑚 = 32 𝑚 = 64 𝑚 = 128 RISE [1] 0.235 0.261 0.296 0.379 0.461 Lambda 0.374 0.414 0.403 0.378 0.291 LABN 0.044 0.311 0.489 0.523 0.556 Ours 0.506 0.748 0.755 0.757 0.756 IDRiD
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関連研究 : 既存手法は重要でない領域を重要視する粗い説明を生成 • 重要でない領域の影響も含まれた 粗い説明を生成する傾向がある RISE [Petsiuk+, BMCV18] 説明の標準的な手法,](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_4.jpg){kind=link}
![関連研究: Insertion-Deletion score (IDs) [Petsiuk+, BMCV18] 6 Deletion Insertion n](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
![モデル構造の概要 : 視覚的説明生成専用のブランチ構造を導入 • Lambda Networks[Bello+, ICLR21]を基にした3つのモジュールから成る • 説明生成モジュールとしてABN[Fukui+, CVPR19]を導入したLABNを使用](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 attention](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_13.jpg){kind=link}
![新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 attention](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_14.jpg){kind=link}
![新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 attention](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_15.jpg){kind=link}
![新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 マスクした画像](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_16.jpg){kind=link}
![新規性① : Saliency Guided Training [Ismail+, NeurIPS21]の導入 • 元画像 attention](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appendix︓Lambda Networks [Bello+, ICLR21] ・Lambda Layer CNNとの親和性が高い ・transformer層 ViTより少ない計算量で 広範囲の関係を捉えることが可能](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_32.jpg){kind=link}
![Appendix︓Lambda Networks [Bello+, ICLR21] 34 ・入力𝒉を畳みこみQuery, Key, Valueの生成 𝑄 =](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_33.jpg){kind=link}
![Appendix︓Lambda Networks [Bello+, ICLR21] 35 ・計算 𝝀! = 𝐶𝑜𝑛𝑣 𝑉](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_34.jpg){kind=link}
{kind=link}
![Appendix : 既存研究 -- RISE[Petsiuk+, BMCV18] -- 37 ▪ 可視化手順](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
![Appendix : マスクによる予測への影響[Srinivas+, NeurlPS19] ▪ 問題点 予測の変化に対する影響が ・重要箇所の挿入/削除 ・分布の変化 ・高周波成分(エッジなど)](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appendix : 既存研究 -- LABM[飯田+, JSAI22] との比較 -- DeFN PID](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
![Appendix : 発展 -- LABM[飯田+, JSAI22] との比較 (IDRiDを用いた場合でも最良) -- ・](https://files.speakerdeck.com/presentations/6fdd86c86ca540da84d475744efede15/slide_46.jpg){kind=link}