segmentation," European Conference on Computer Vision, Cham: Springer Nature Switzerland, 2022, • Dosovitskiy, Alexey, et al, "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale," International Conference on Learning Representations, 2020, • Cho, S,, Hong, S,, Jeon, S,, Lee, Y,, Sohn, K,, Kim, S,: Cats: Cost aggregation transformers for visual correspondence, In: Thirty-Fifth Conference on Neural Information Processing Systems (2021) • Cheng, H,K,, Chung, J,, Tai, Y,W,, Tang, C,K,: CascadePSP: Toward classagnostic and very high- resolution segmentation via global and local refinement,In: CVPR (2020) • Shaban, Amirreza, et al, "One-shot learning for semantic segmentation," arXiv preprint arXiv:1709,03410 (2017), • Wu, Chuhan, et al, "Fastformer: Additive attention can be all you need," arXiv preprint arXiv:2108,09084 (2021), • Katharopoulos, Angelos, et al, "Transformers are rnns: Fast autoregressive transformers with linear attention," International conference on machine learning, PMLR, 2020, 30 参考文献 (1/2)
{kind=link}
{kind=link}
![• semantic correspondence • 外観が大きく異なるものから、 意味的に類似した対応点を見つける [Min+, IEEE TPAMI’23] 3](https://files.speakerdeck.com/presentations/99ab45d3a17f4a9f849ef59c56ba60d3/slide_2.jpg){kind=link}
![4 関連研究:類似タスクではAttentionによるコスト集約が可能 既存手法 概要 CATs [Cho+, NeurIPS’21] • semantic correspondenceタスクを扱うモデルの一つ](https://files.speakerdeck.com/presentations/99ab45d3a17f4a9f849ef59c56ba60d3/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
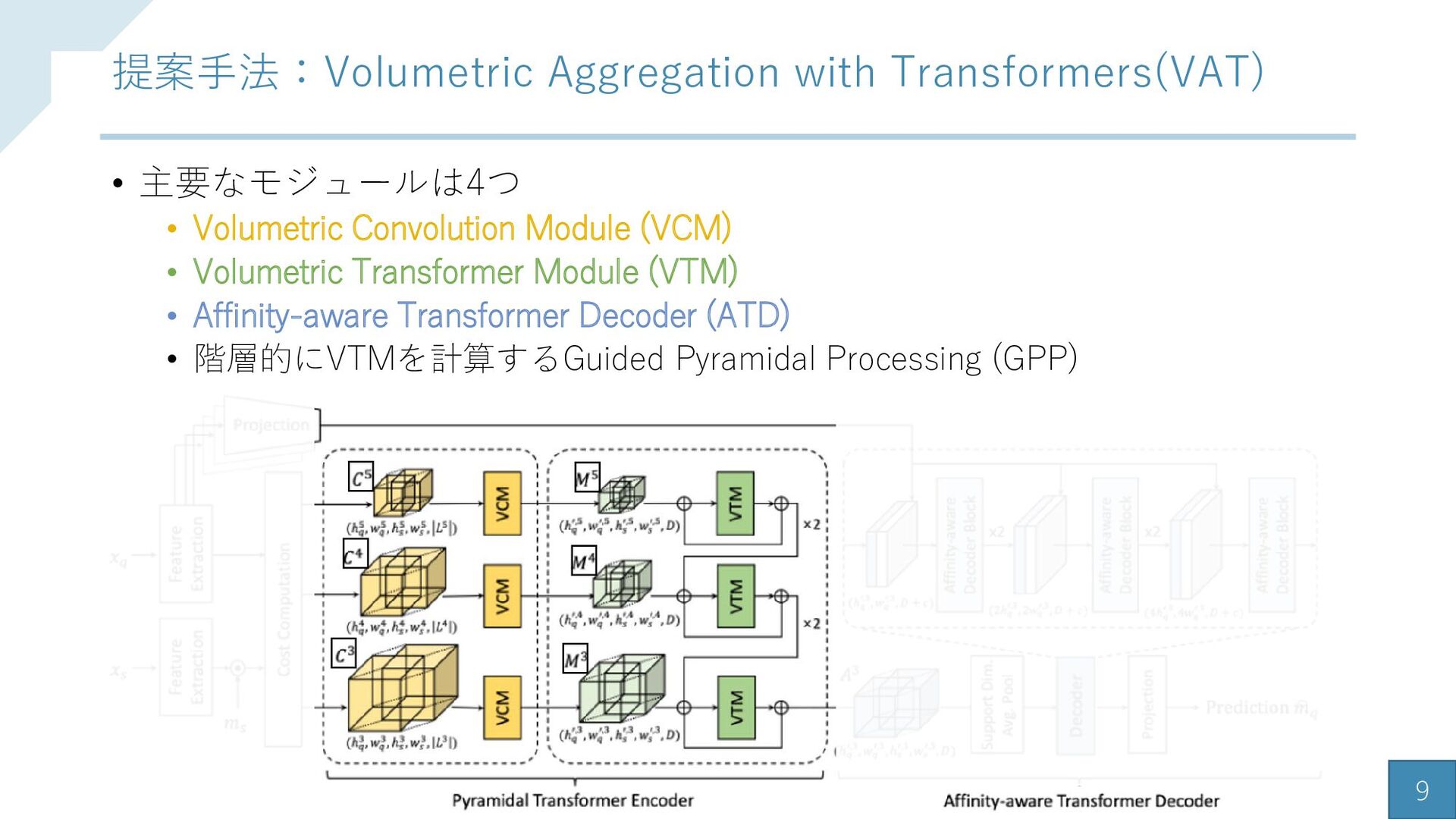{kind=link}
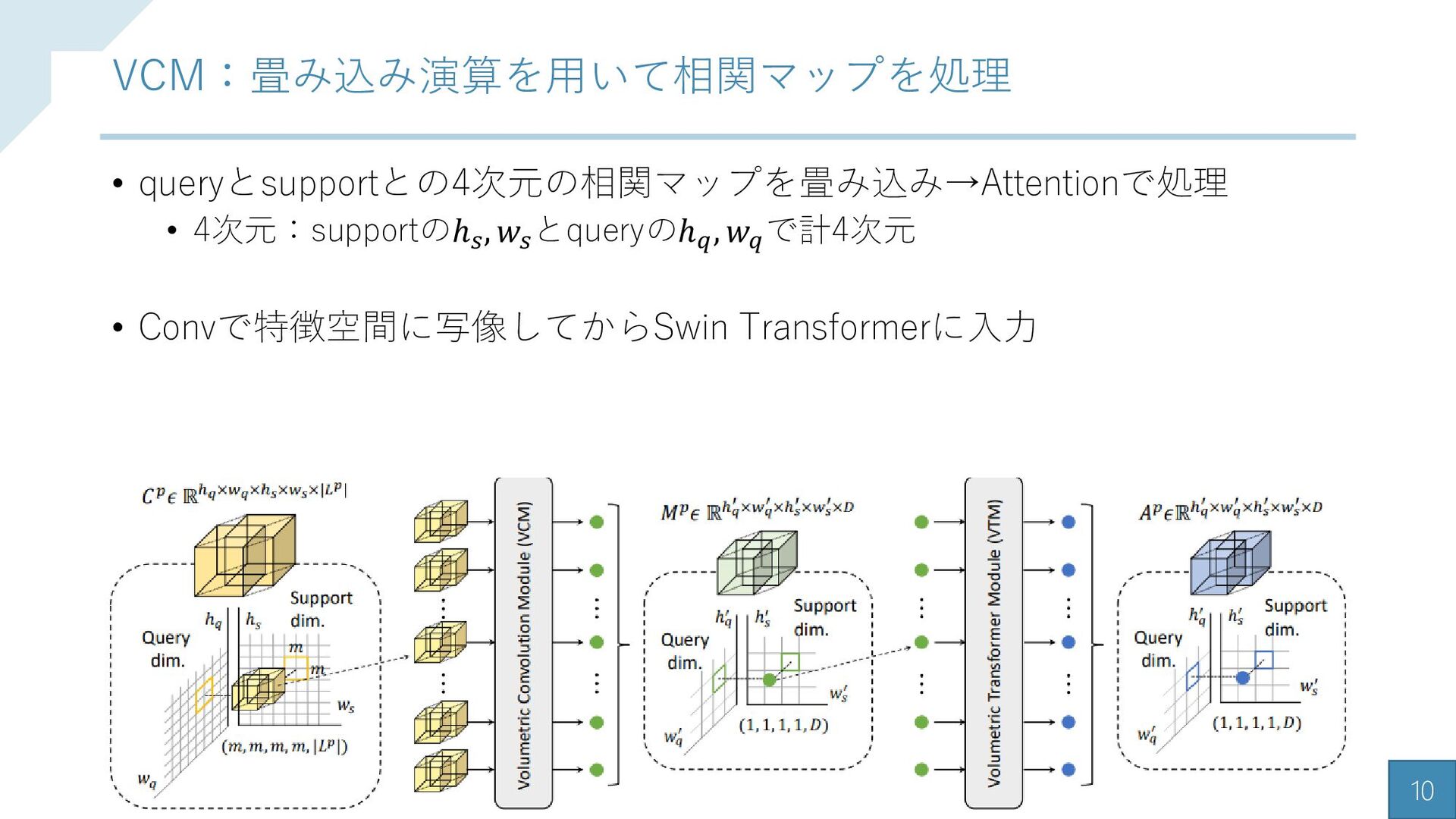{kind=link}
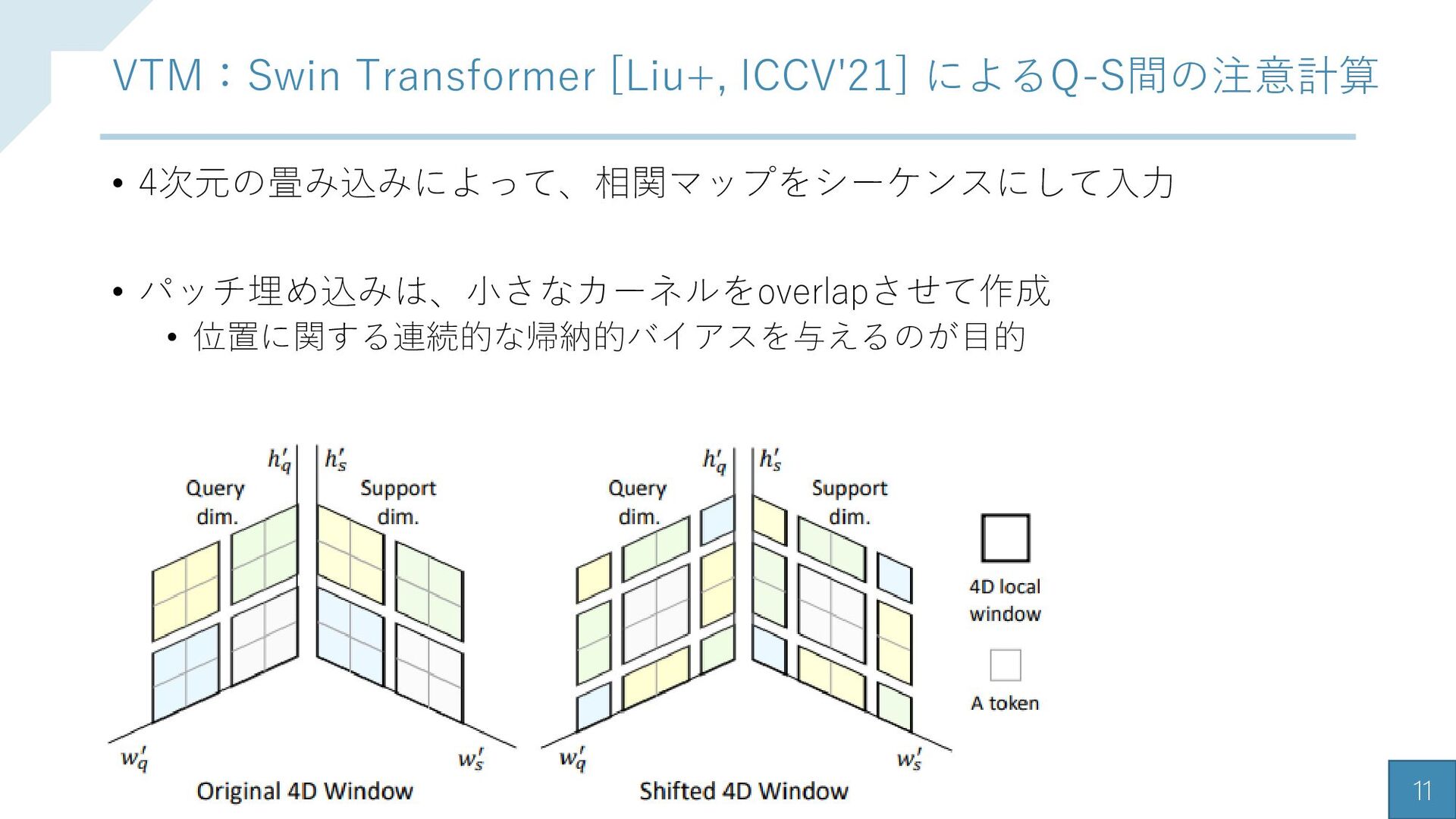{kind=link}
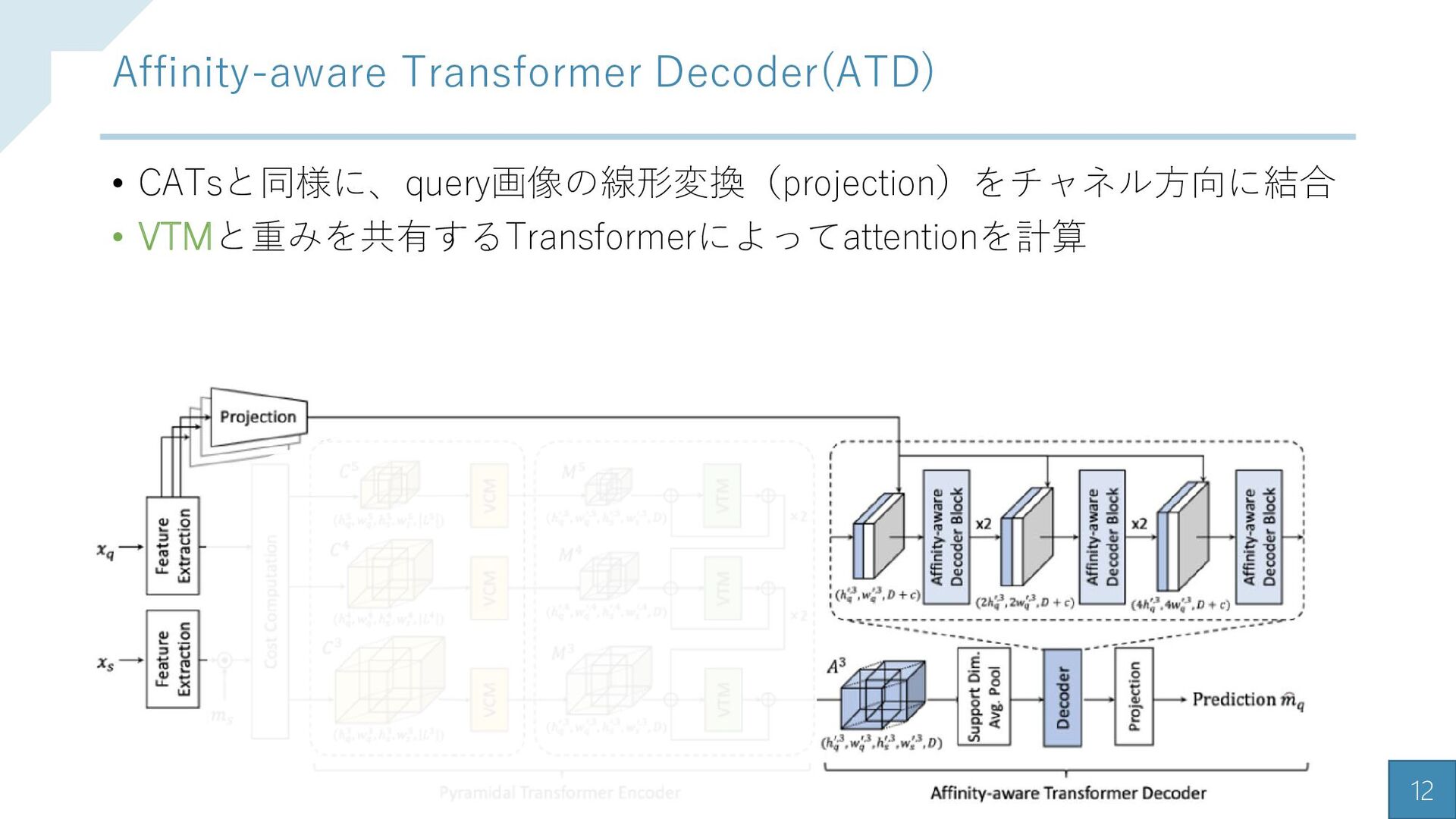{kind=link}
![• Dataset:PASCAL-5i [Shaban+, ’17]、COCO-20i [Lin+, ECCV’14]、 FSS-1000 [Li+, CVPR’20] •](https://files.speakerdeck.com/presentations/99ab45d3a17f4a9f849ef59c56ba60d3/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
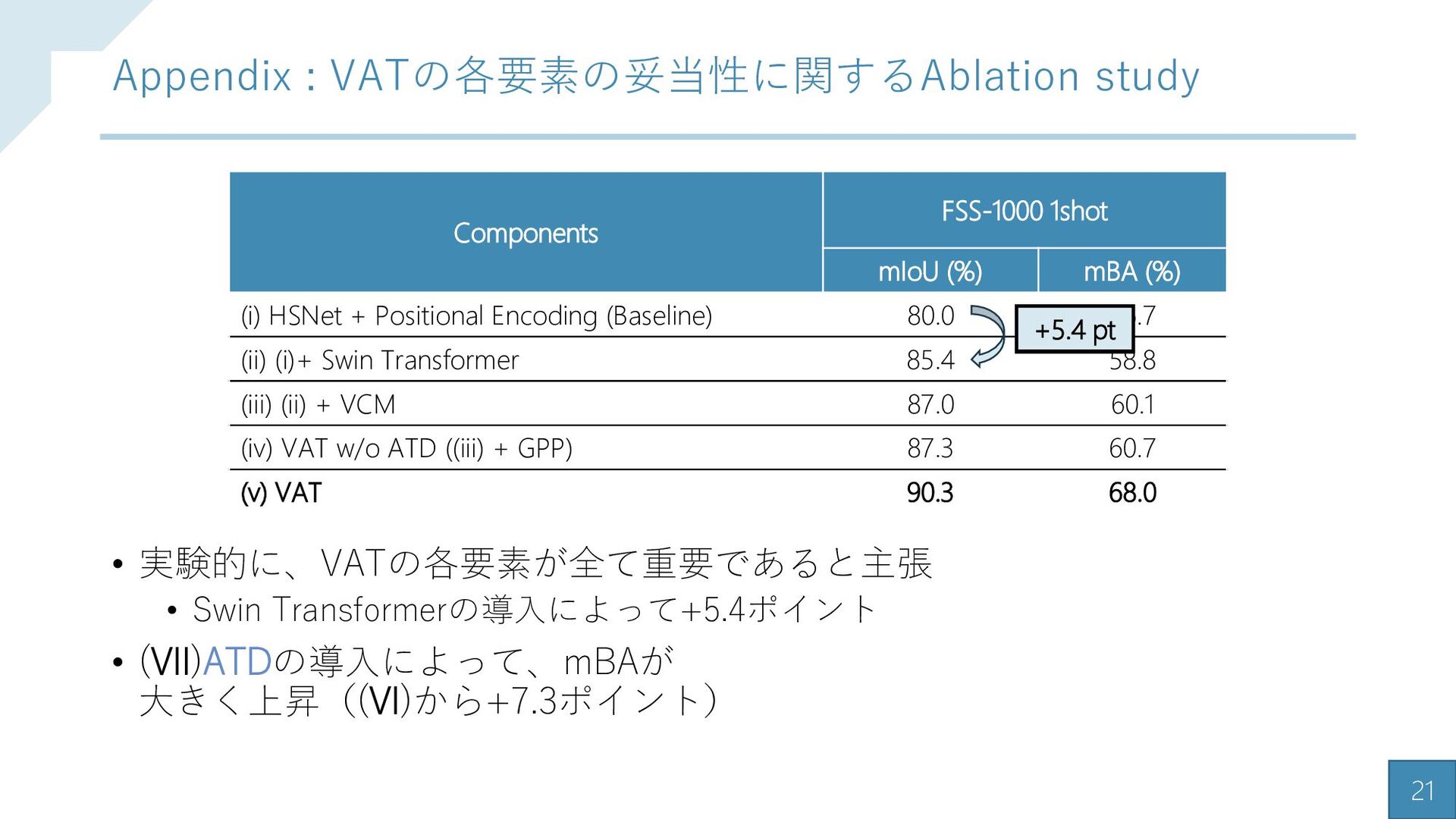{kind=link}
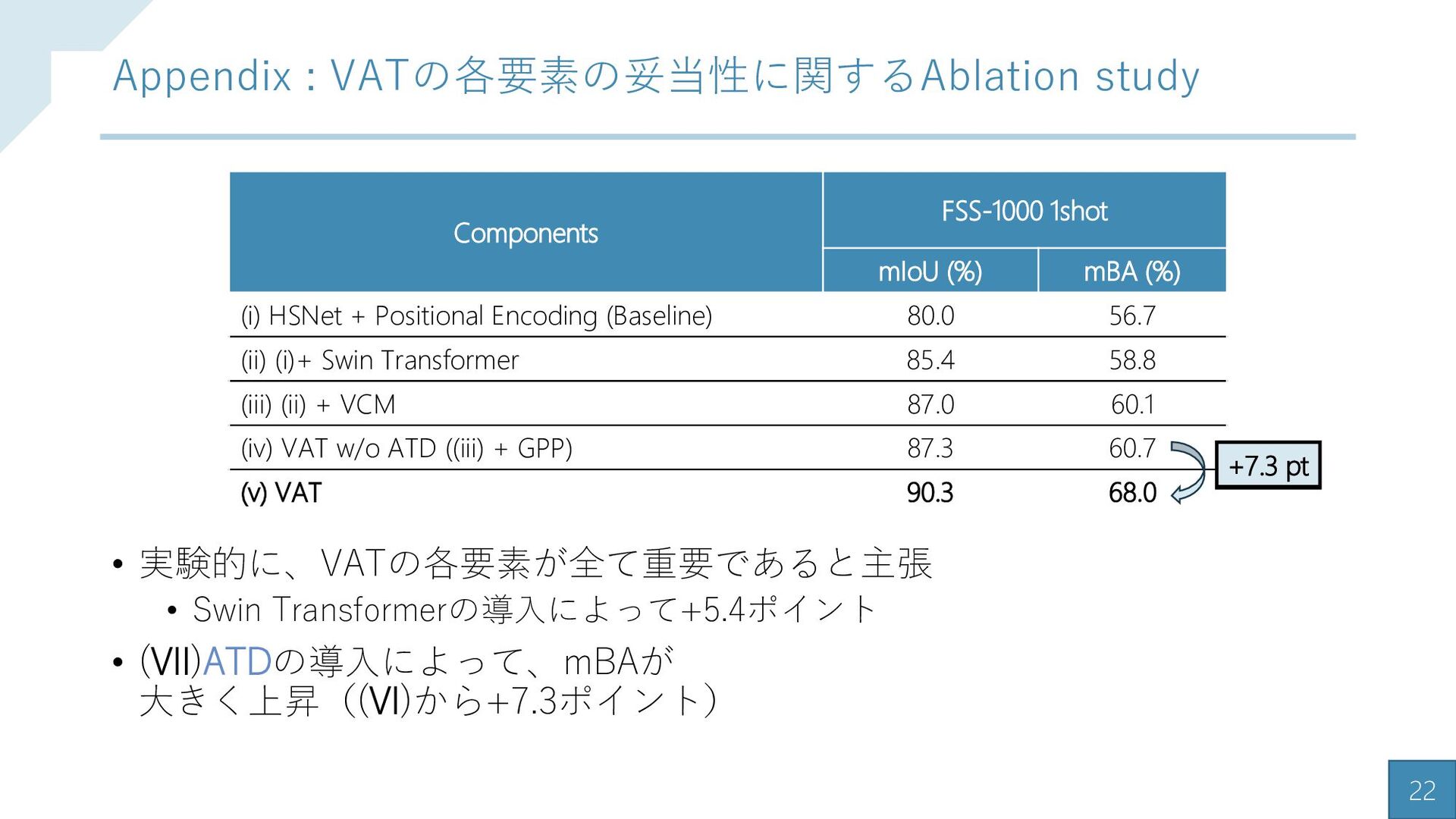{kind=link}
![• Dataset:SPair-71k [Min+, ’19] 、PF-PASCAL [Ham+, IEEE TPAMI’17]、 PF-WILLOW [Ham+,](https://files.speakerdeck.com/presentations/99ab45d3a17f4a9f849ef59c56ba60d3/slide_22.jpg){kind=link}
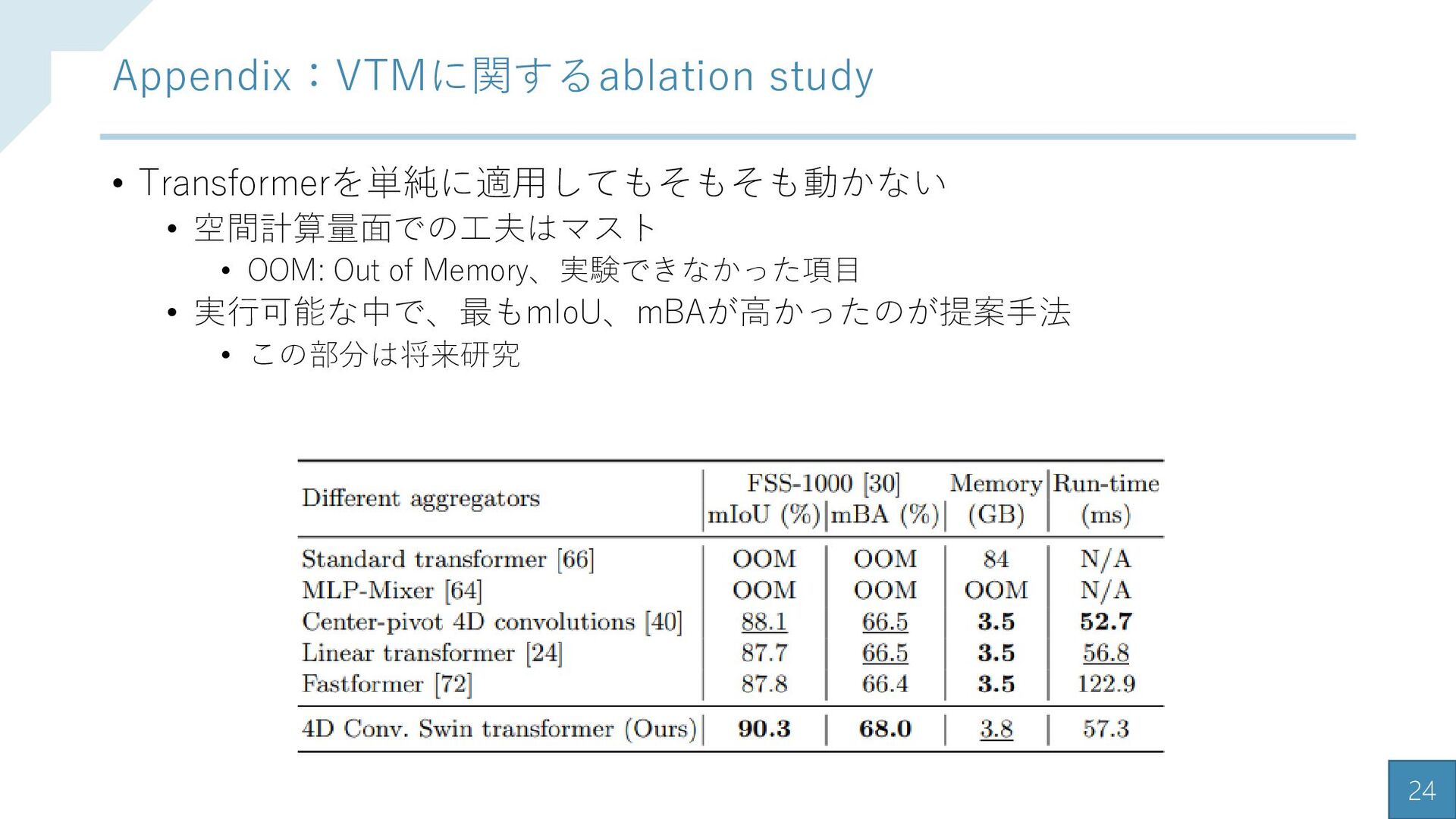{kind=link}
![• VCM • Ablation条件:Conv→ViT [Dosovitskiy+, ICLR’20]のpatch embedding (VEM) • VEM、VCM間には1pt以下の差](https://files.speakerdeck.com/presentations/99ab45d3a17f4a9f849ef59c56ba60d3/slide_24.jpg){kind=link}
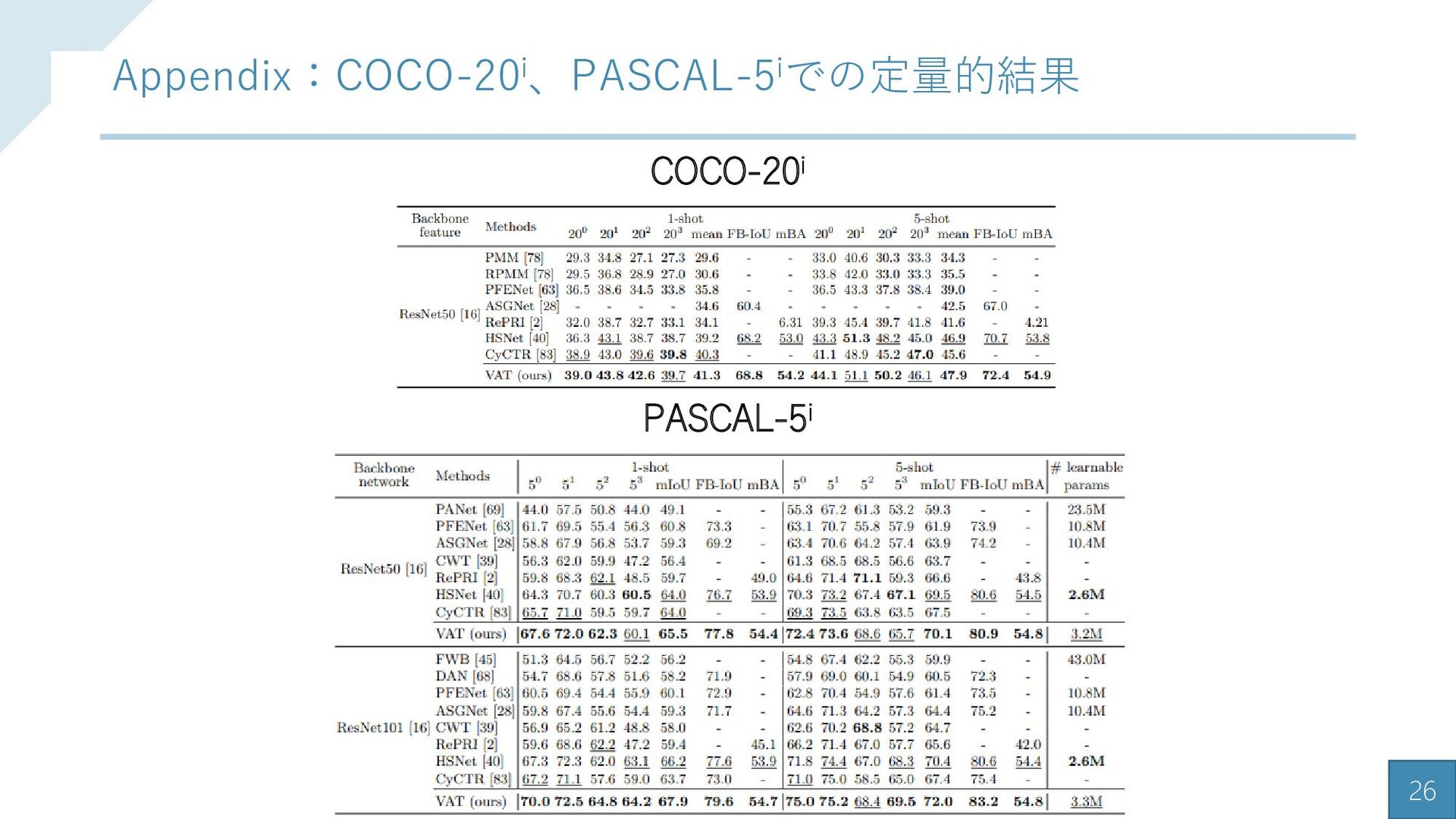{kind=link}
![• モデルが物体を詳細まで捉えられる能力を評価する指標 • 物体の輪郭のみに着目した評価指標 1. [3, 𝑤𝑤+ℎ 300 ] から等間隔で5つの半径の値をサンプリング](https://files.speakerdeck.com/presentations/99ab45d3a17f4a9f849ef59c56ba60d3/slide_26.jpg){kind=link}
![左:2クラス 右:多クラス 28 Appendix:mBAの[Cheng+,CVPR20]での実装](https://files.speakerdeck.com/presentations/99ab45d3a17f4a9f849ef59c56ba60d3/slide_27.jpg){kind=link}
![29 Appendix : Personalize SAM [Zhang+. ’23] との比較実験 Support Query+Pred](https://files.speakerdeck.com/presentations/99ab45d3a17f4a9f849ef59c56ba60d3/slide_28.jpg){kind=link}
{kind=link}
{kind=link}