Li4∗ Xunqiang Tao2 Yandong Guo2 Mingming Gong5 Tongliang Liu1 1University of Sydney; 2OPPO Research Institute; 3Beijing University of Posts and Telecommunications 4Kuaishou Technology; 5University of Melbourne 慶應義塾大学 杉浦孔明研究室 畑中駿平 Wang, Zhaoqing, et al. "Cris: Clip-driven referring image segmentation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
{kind=link}
{kind=link}
![▸ Referring Image Segmentation ( RIS ) ▹ [Hu+, ECCV16]](https://files.speakerdeck.com/presentations/a5b9ad355bb74be8bcc8007bfcad03b3/slide_2.jpg){kind=link}
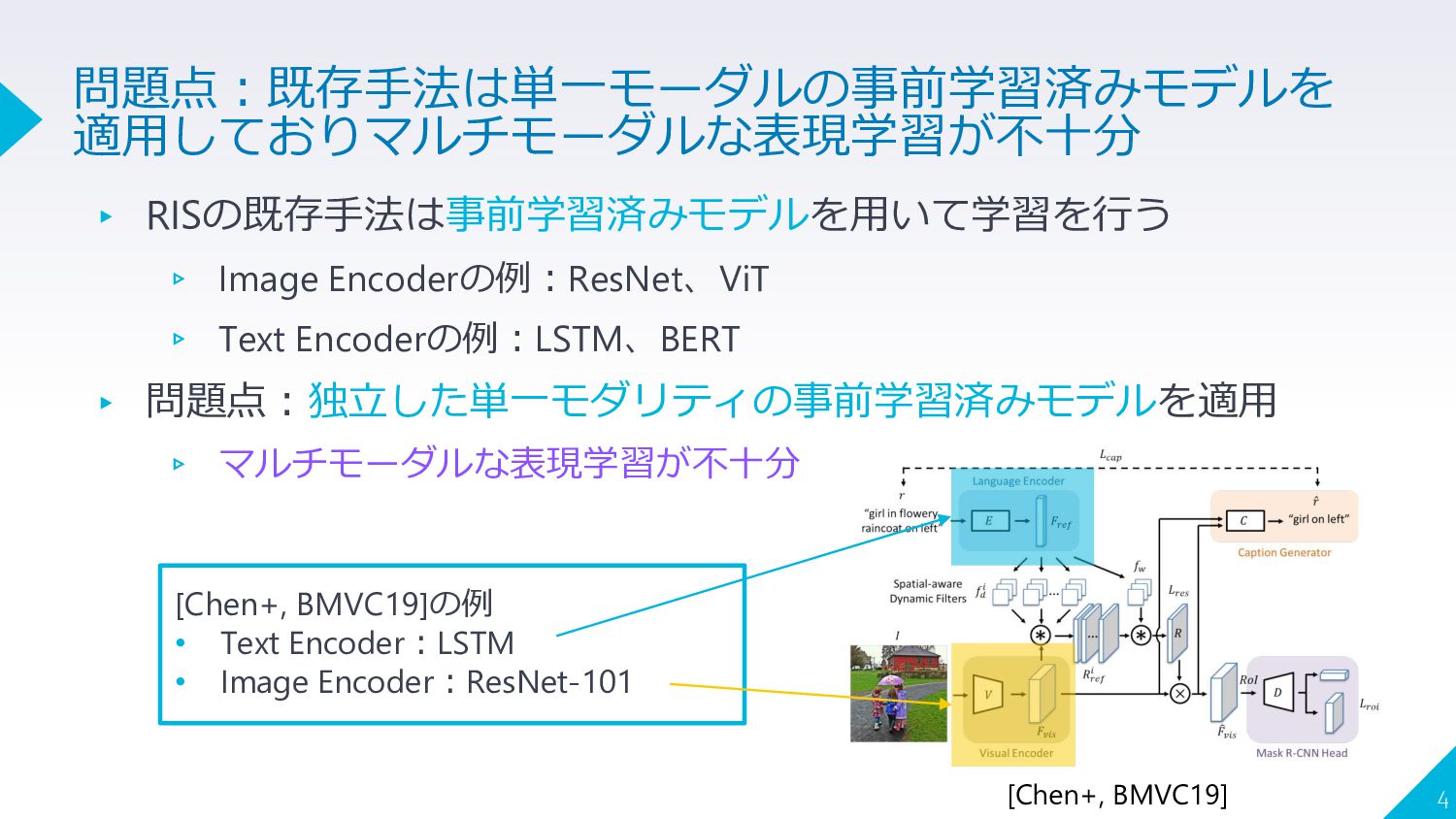{kind=link}
![▸ SimVLM [Wang+, 21]やCLIP [Radford+, PMLR21] ▹ 大規模なvision-language事前学習によりマルチモーダルな表現を学習 可能 ▸](https://files.speakerdeck.com/presentations/a5b9ad355bb74be8bcc8007bfcad03b3/slide_4.jpg){kind=link}
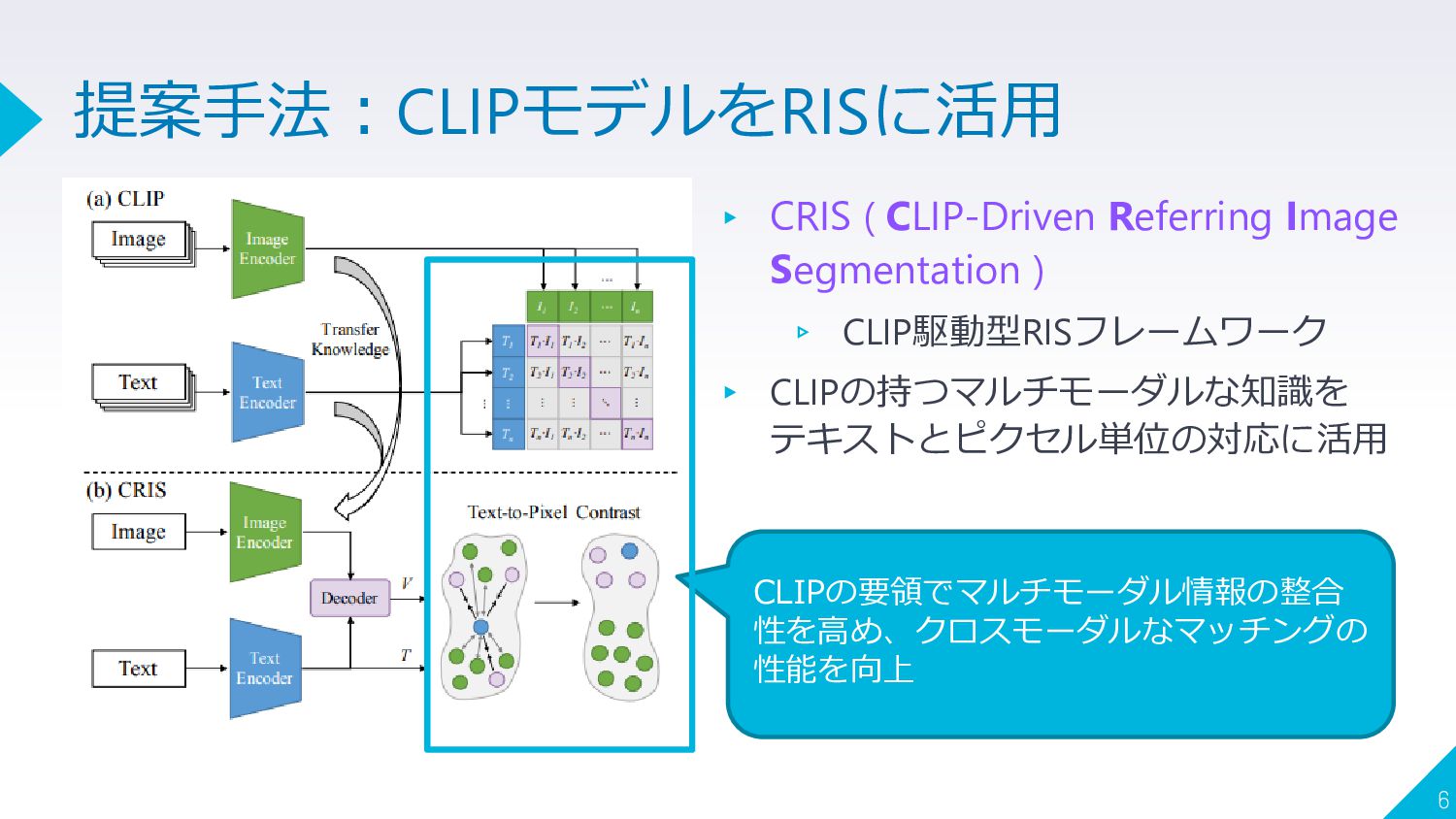{kind=link}
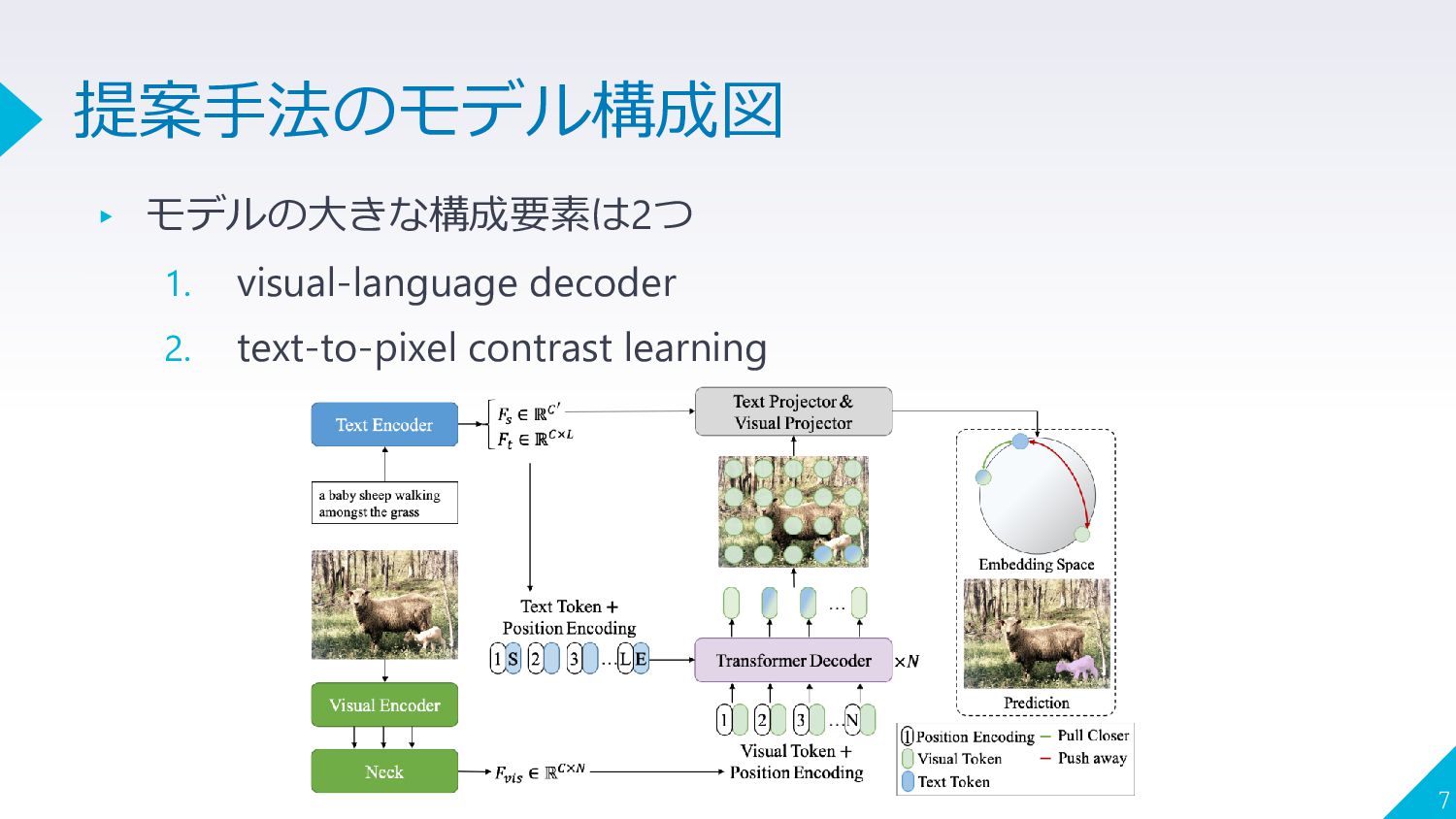{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
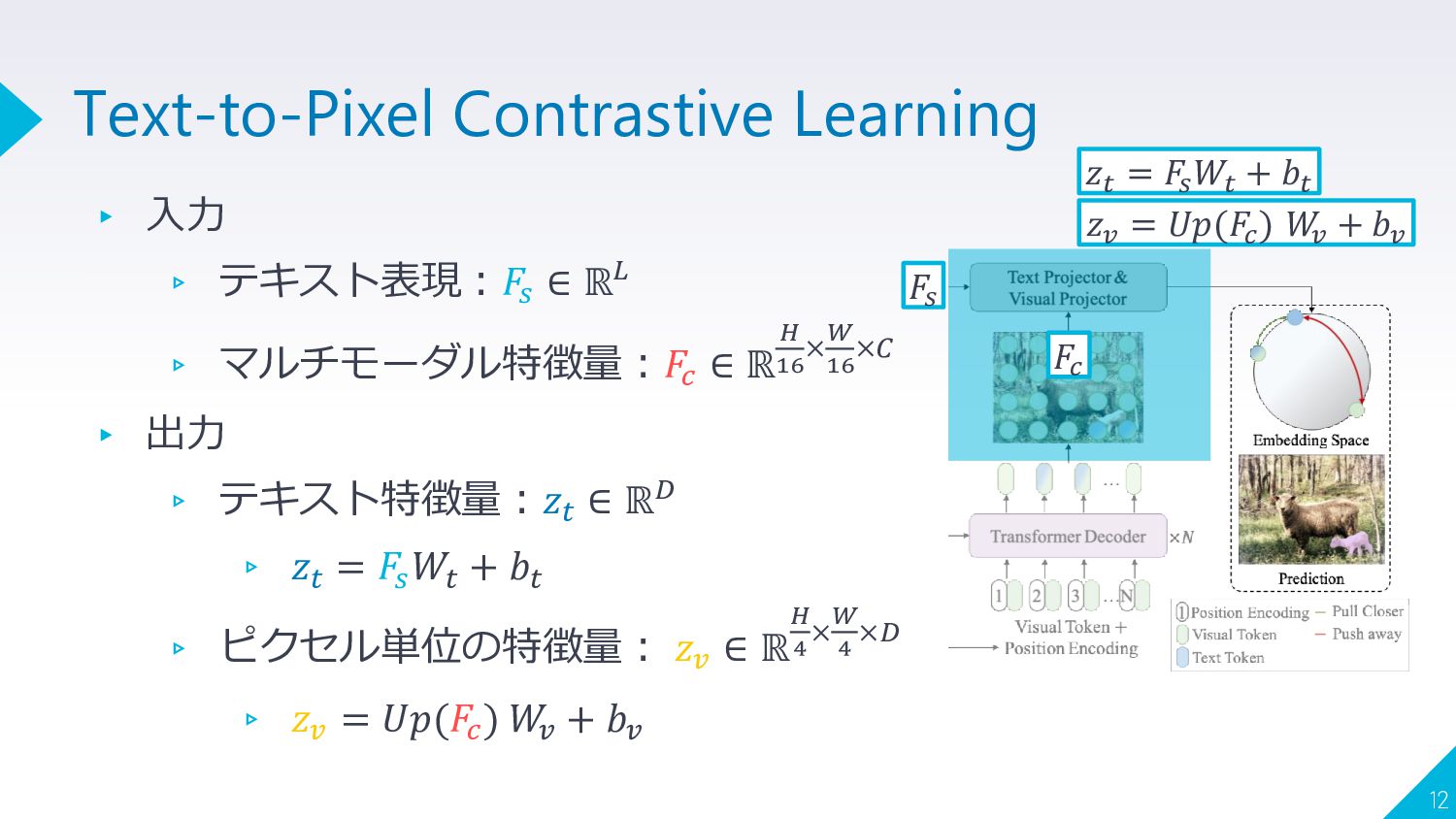{kind=link}
{kind=link}
{kind=link}
{kind=link}
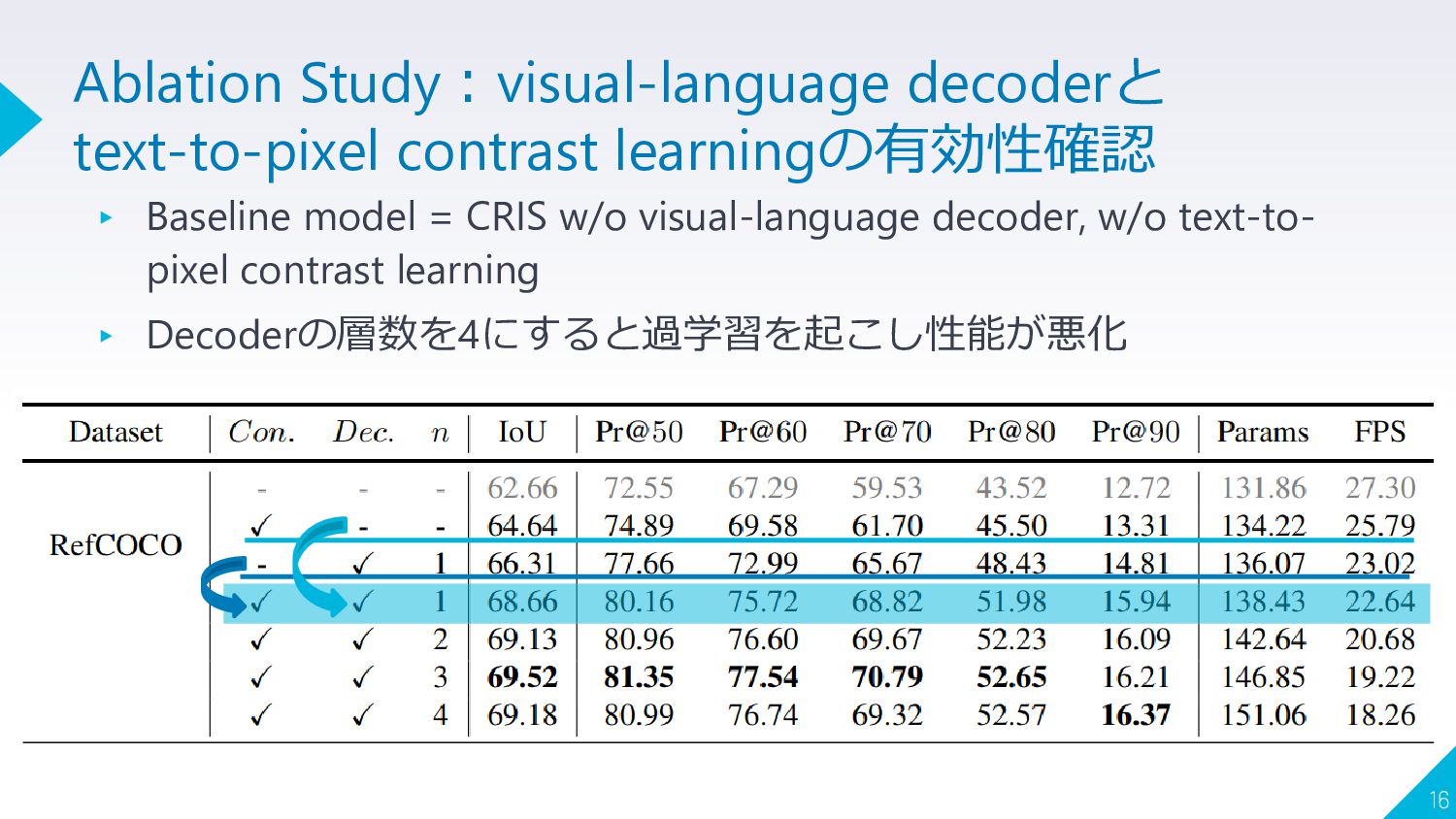{kind=link}
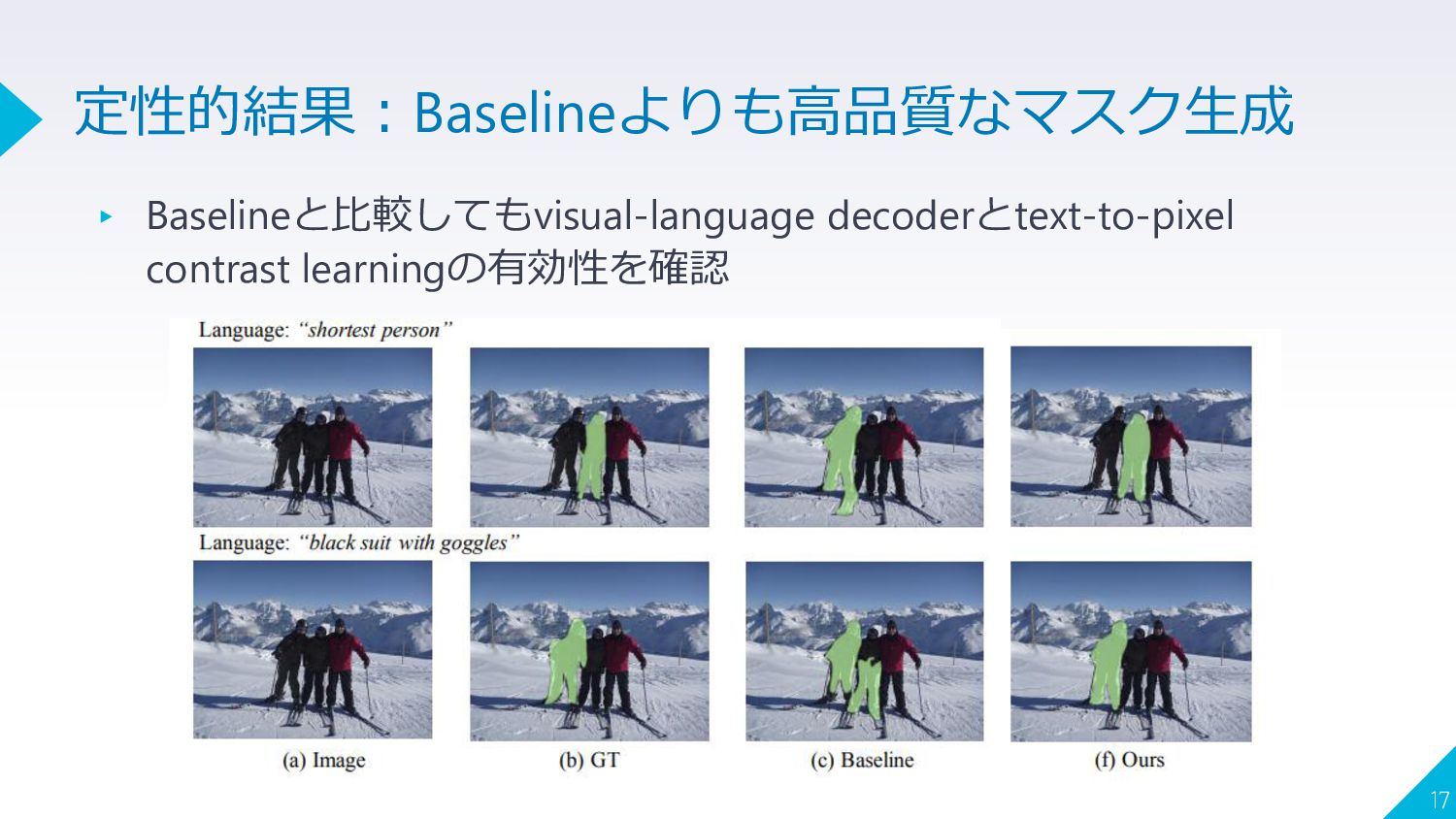{kind=link}
{kind=link}