Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] OccamNets: Mitigating Dataset Bi...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 28, 2023
Technology
34
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] OccamNets: Mitigating Dataset Bias by Favoring Simpler Hypotheses
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 28, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
kaonavi Tech Night#1
kaonavi
0
160
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
600
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
7
2.9k
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
790
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
2
930
「休む」重要さ
smt7174
6
1.6k
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
160
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
170
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
270
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
750
そのドキュメント、自動化しませんか?
yuksew
1
410
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
340
Featured
See All Featured
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
4 Signs Your Business is Dying
shpigford
187
22k
Mind Mapping
helmedeiros
PRO
1
290
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
410
The Language of Interfaces
destraynor
162
27k
Speed Design
sergeychernyshev
33
1.9k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Transcript
𝑅𝑜𝑏𝑖𝑘 𝑆ℎ𝑟𝑒𝑠𝑡ℎ𝑎1, 𝐾𝑢𝑠ℎ𝑎𝑙 𝐾𝑎𝑓𝑙𝑒2, 𝑎𝑛𝑑 𝐶ℎ𝑟𝑖𝑠𝑡𝑜𝑝ℎ𝑒𝑟 𝐾𝑎𝑛𝑎𝑛1.3 1𝑅𝑜𝑐ℎ𝑒𝑠𝑡𝑒𝑟 𝐼𝑛𝑠𝑡𝑖𝑡𝑢𝑡𝑒 𝑜𝑓
𝑇𝑒𝑐ℎ𝑛𝑜𝑙𝑜𝑔𝑦, 2𝐴𝑑𝑜𝑏𝑒 𝑅𝑒𝑠𝑒𝑎𝑟𝑐ℎ, 3𝑈𝑛𝑖𝑣𝑒𝑟𝑠𝑖𝑡𝑦 𝑜𝑓 𝑅𝑜𝑐ℎ𝑒𝑠𝑡𝑒𝑟 ECCV 2022 OccamNets: Mitigating Dataset Bias by Favoring Simpler Hypotheses 慶應義塾大学 杉浦孔明研究室 平野慎之助
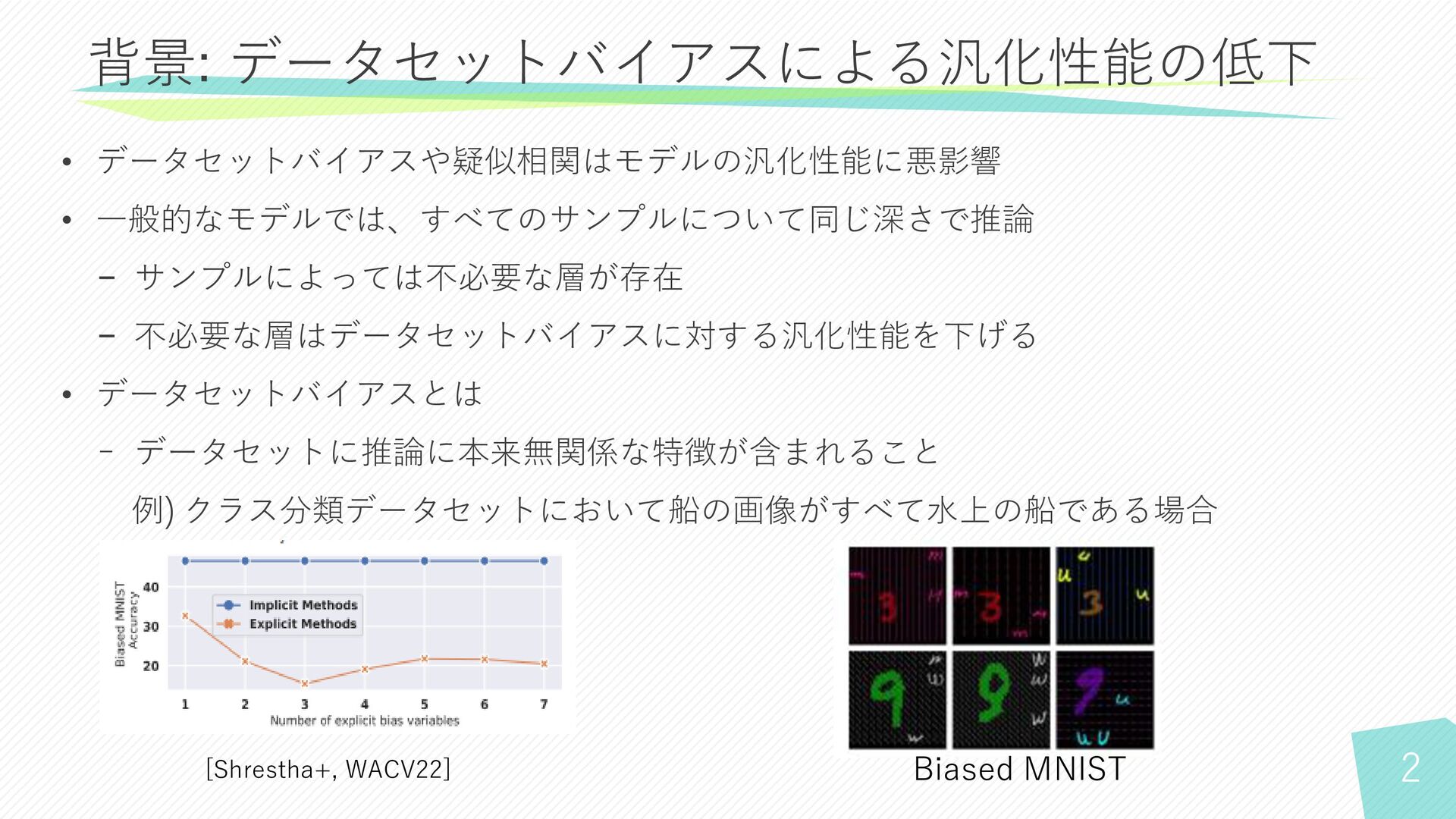
2 • データセットバイアスや疑似相関はモデルの汎化性能に悪影響 • 一般的なモデルでは、すべてのサンプルについて同じ深さで推論 − サンプルによっては不必要な層が存在 − 不必要な層はデータセットバイアスに対する汎化性能を下げる •
データセットバイアスとは − データセットに推論に本来無関係な特徴が含まれること 例) クラス分類データセットにおいて船の画像がすべて水上の船である場合 背景: データセットバイアスによる汎化性能の低下 Biased MNIST [Shrestha+, WACV22]
3 関連研究: 既存手法 特徴や問題等 [Kim+, CVPR19] 正則化と敵対的ネットワークを用いたモデルによりデータセット バイアスに対応 データセットバイアスの要因がわかっている必要がある [Wolczyk+,
NeurIPS21] 難度の低いサンプルについて早期終了を行うことで推論時間を削減 データセットバイアスに対応できていない [Kim+, CVPR19] [Wolczyk+, NeurIPS21]
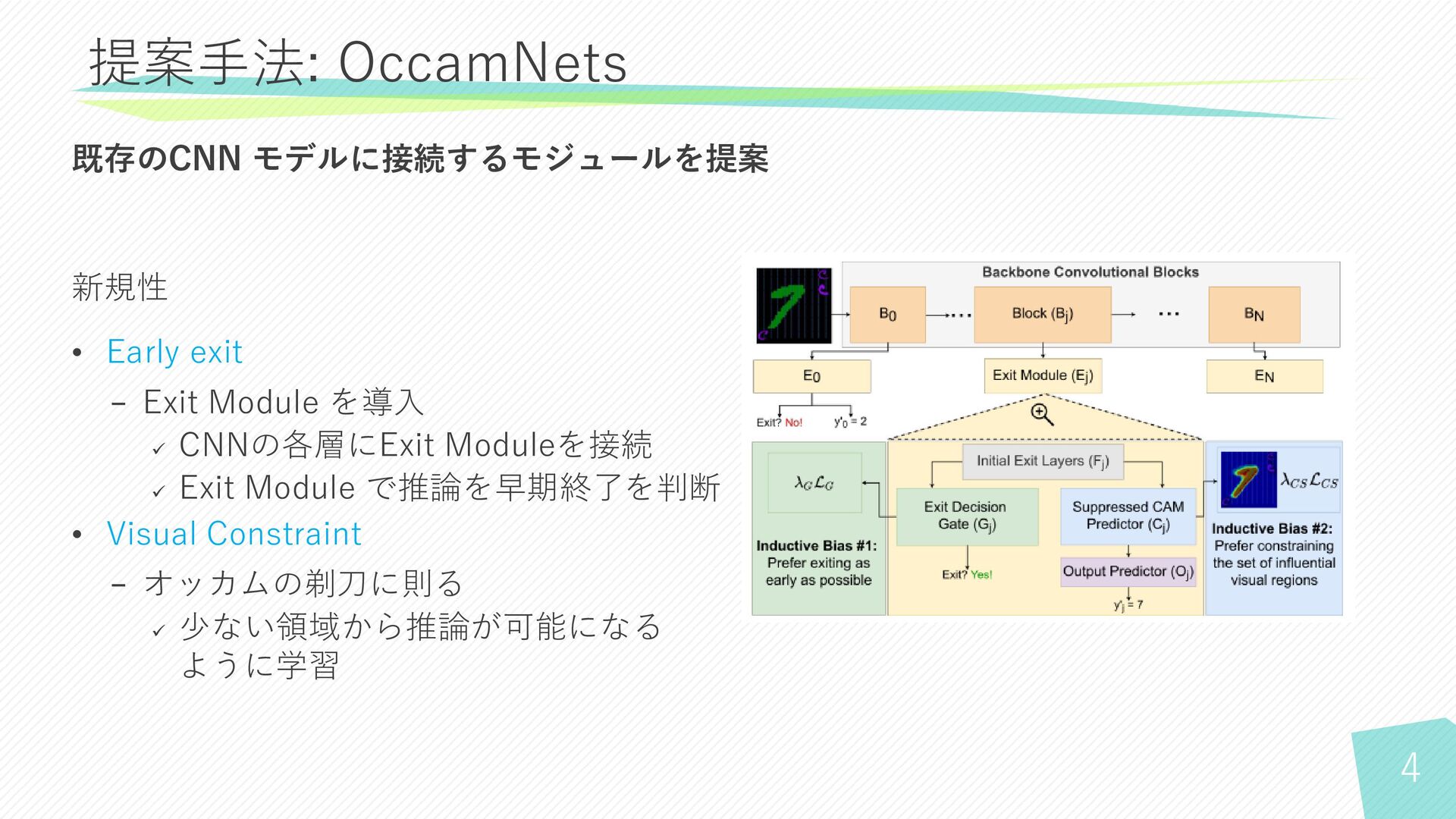
4 提案手法: OccamNets 既存のCNN モデルに接続するモジュールを提案 新規性 • Early exit −
Exit Module を導入 ✓ CNNの各層にExit Moduleを接続 ✓ Exit Module で推論を早期終了を判断 • Visual Constraint − オッカムの剃刀に則る ✓ 少ない領域から推論が可能になる ように学習
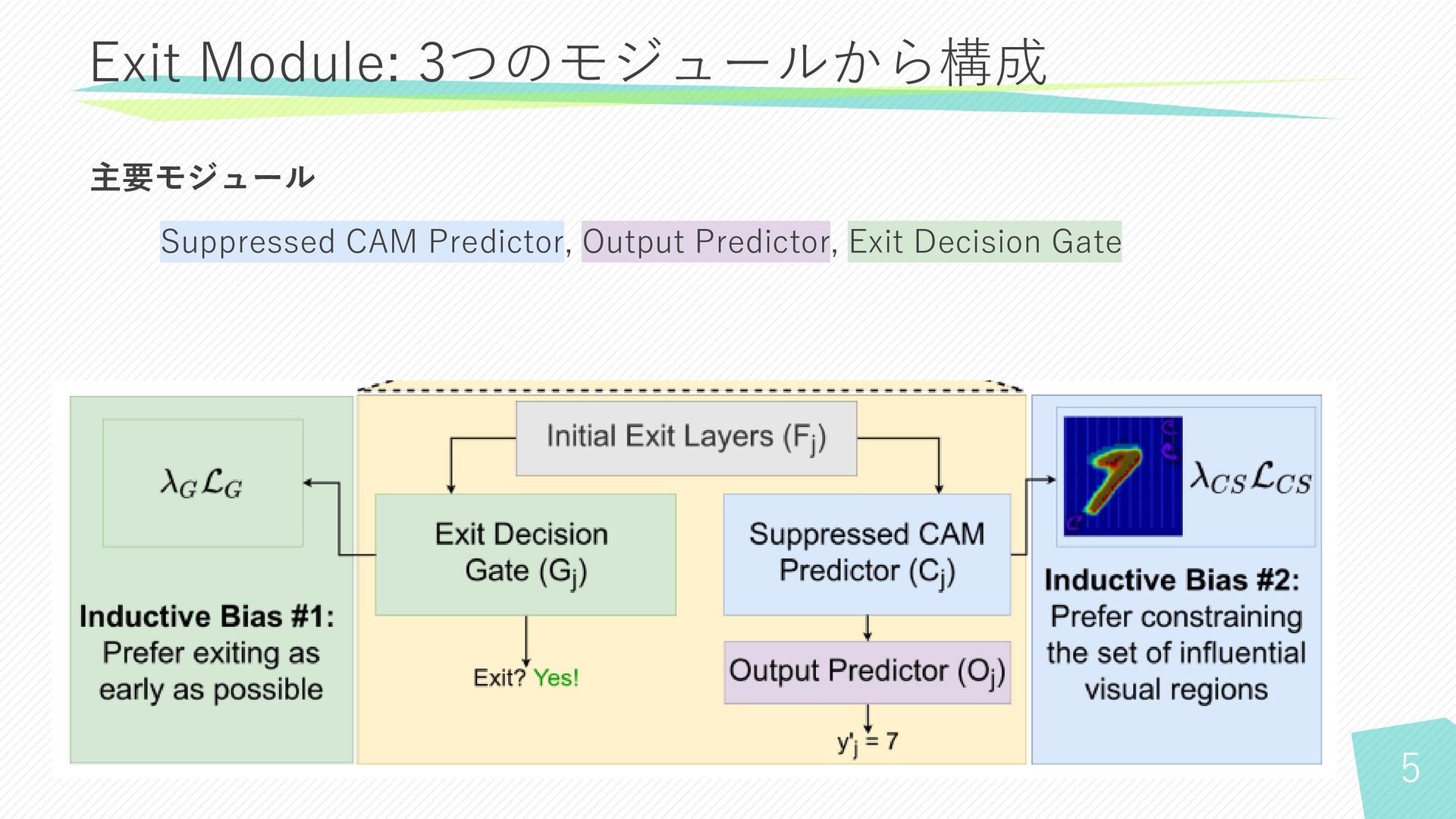
5 主要モジュール Suppressed CAM Predictor, Output Predictor, Exit Decision Gate
Exit Module: 3つのモジュールから構成
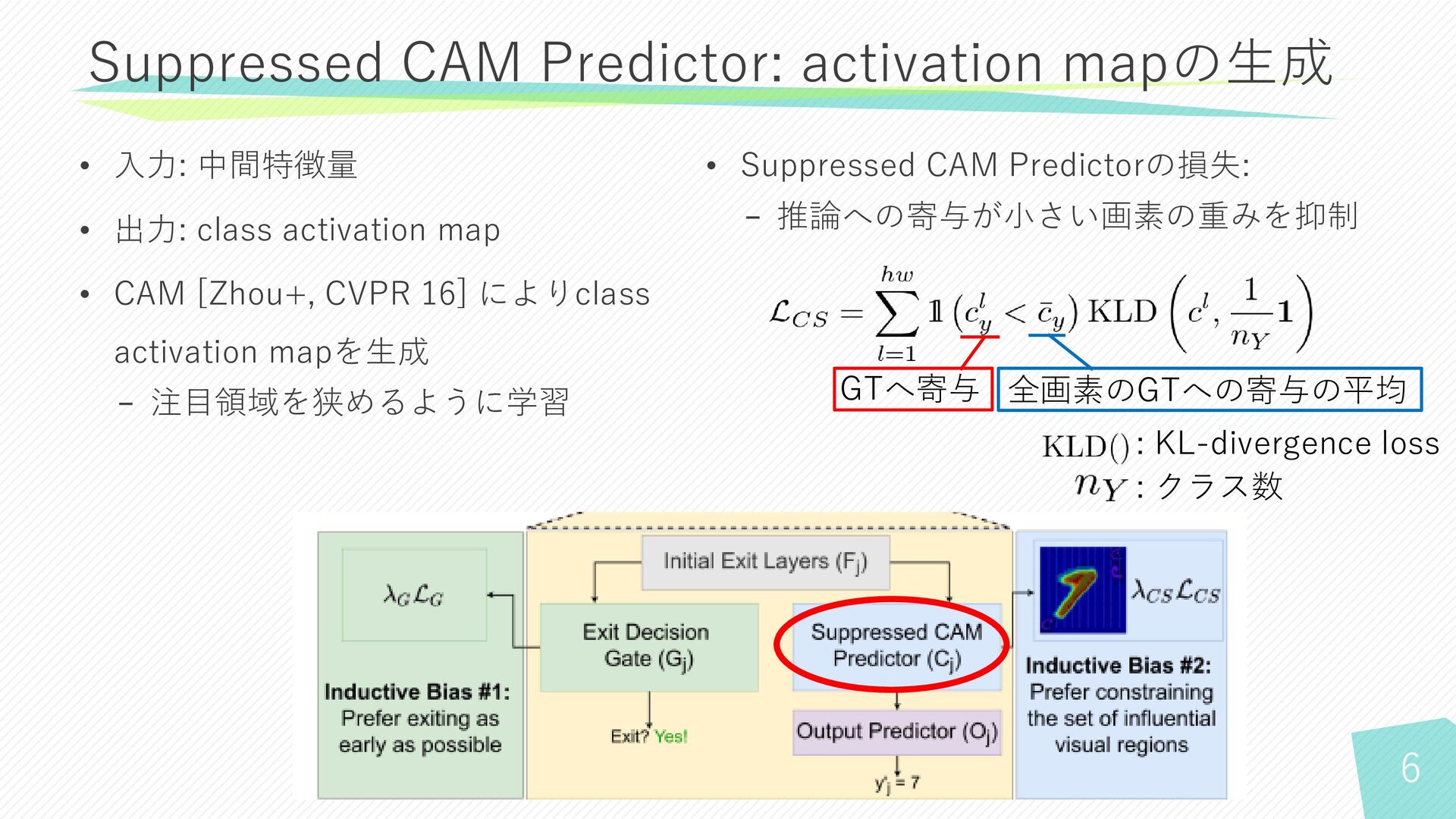
6 Suppressed CAM Predictor: activation mapの生成 GTへ寄与 全画素のGTへの寄与の平均 : KL-divergence
loss • 入力: 中間特徴量 • 出力: class activation map • CAM [Zhou+, CVPR 16] によりclass activation mapを生成 − 注目領域を狭めるように学習 • Suppressed CAM Predictorの損失: − 推論への寄与が小さい画素の重みを抑制 : クラス数
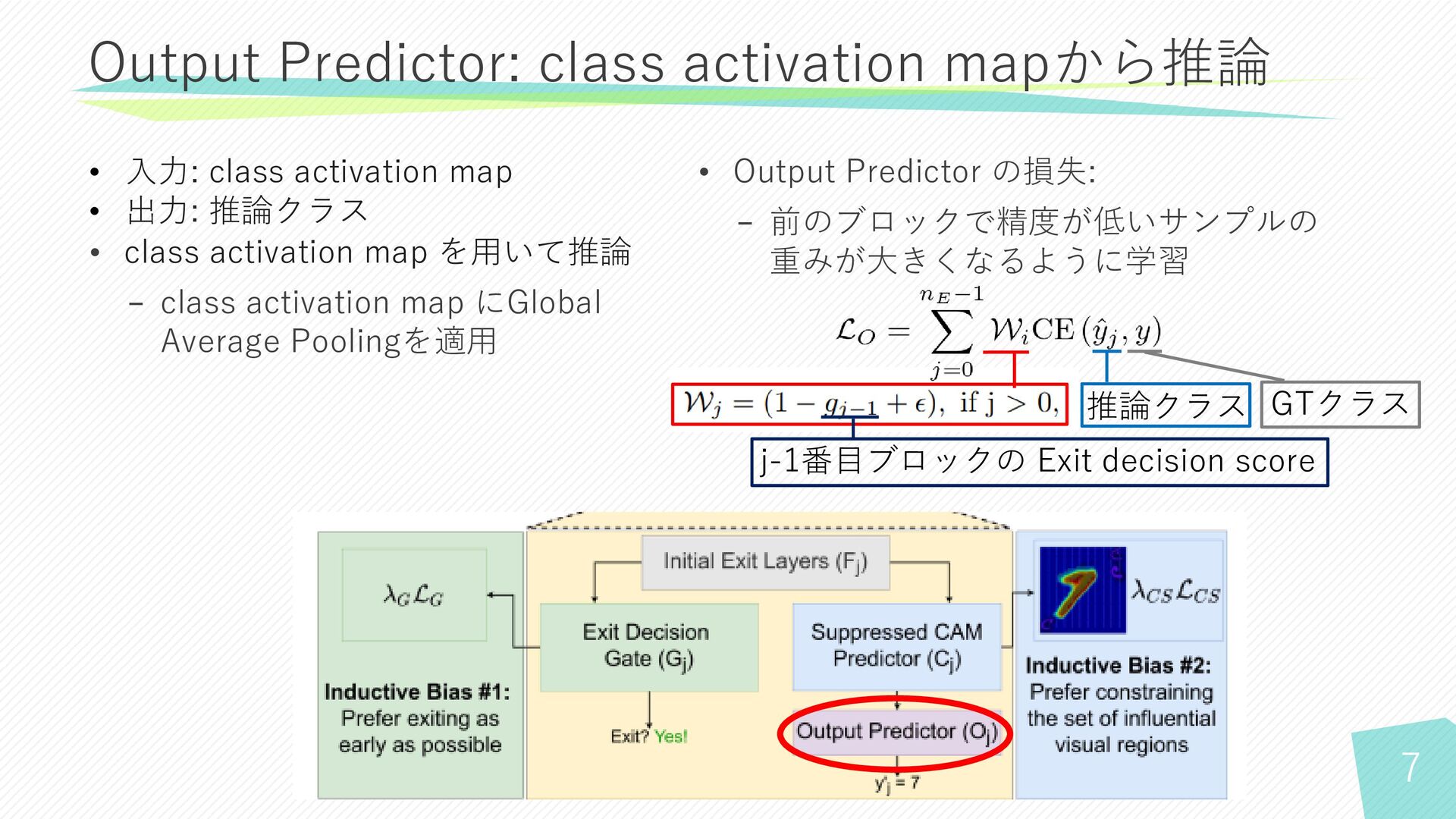
7 • class activation map を用いて推論 − class activation map
にGlobal Average Poolingを適用 Output Predictor: class activation mapから推論 • 入力: class activation map • 出力: 推論クラス • Output Predictor の損失: − 前のブロックで精度が低いサンプルの 重みが大きくなるように学習 j-1番目ブロックの Exit decision score 推論クラス GTクラス
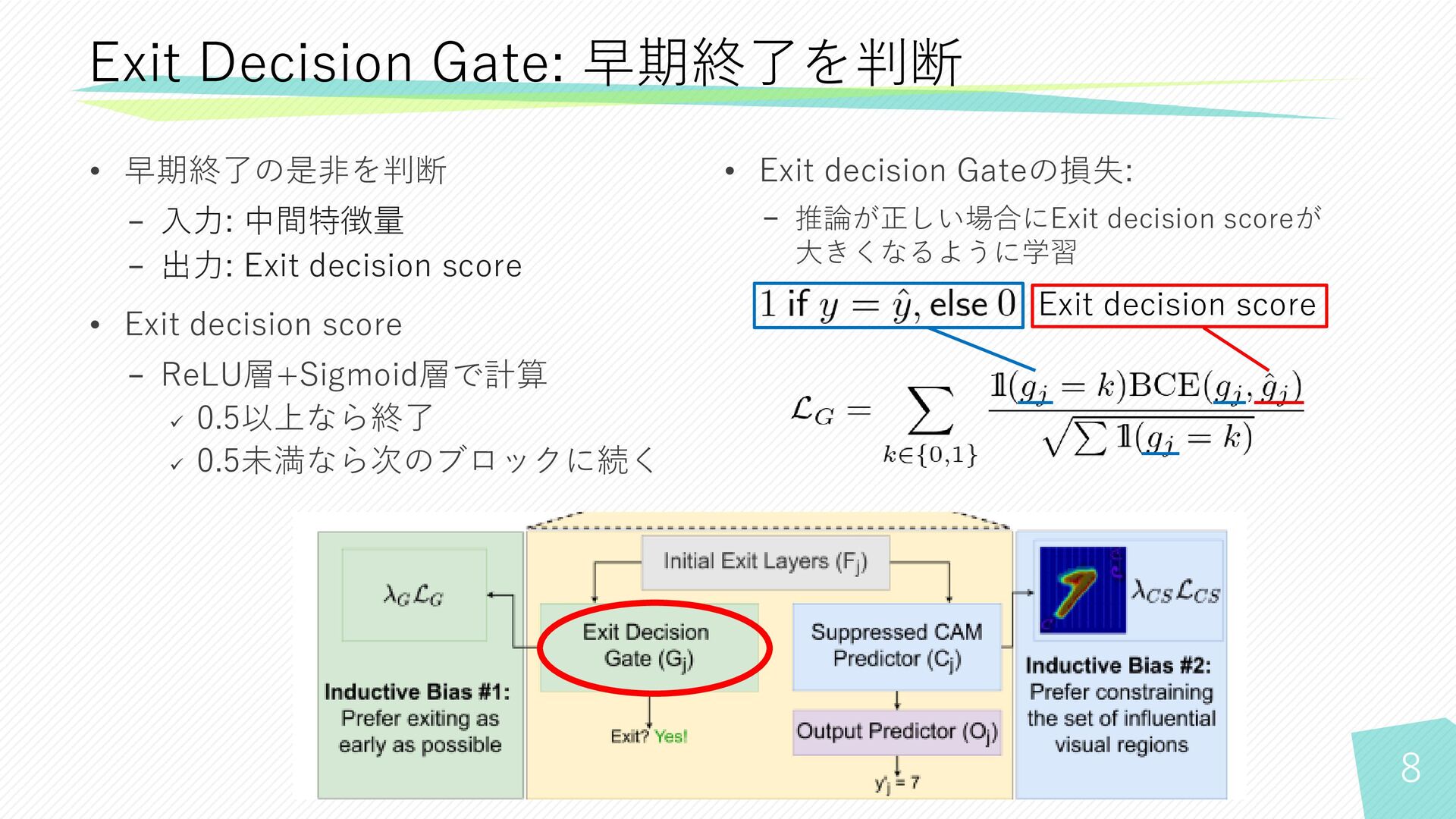
8 • 早期終了の是非を判断 − 入力: 中間特徴量 − 出力: Exit decision
score • Exit decision score − ReLU層+Sigmoid層で計算 ✓ 0.5以上なら終了 ✓ 0.5未満なら次のブロックに続く Exit Decision Gate: 早期終了を判断 Exit decision score • Exit decision Gateの損失: − 推論が正しい場合にExit decision scoreが 大きくなるように学習
9 • Biased MNIST − MNISTにテキストの色や背景の柄、無駄書き など、推論に無関係な要素を付与 • COCO-on-Places [Ahmed+,
ICLR21] − 物体を無関係な背景に配置 • BAR [Nam+, NeurIPS20] − 同じ対象に対して訓練データとテストデータ で背景の異なるデータセット 実験設定: データセット Biased MNIST COCO-on-Places BAR[Nam+, NeurIPS20]
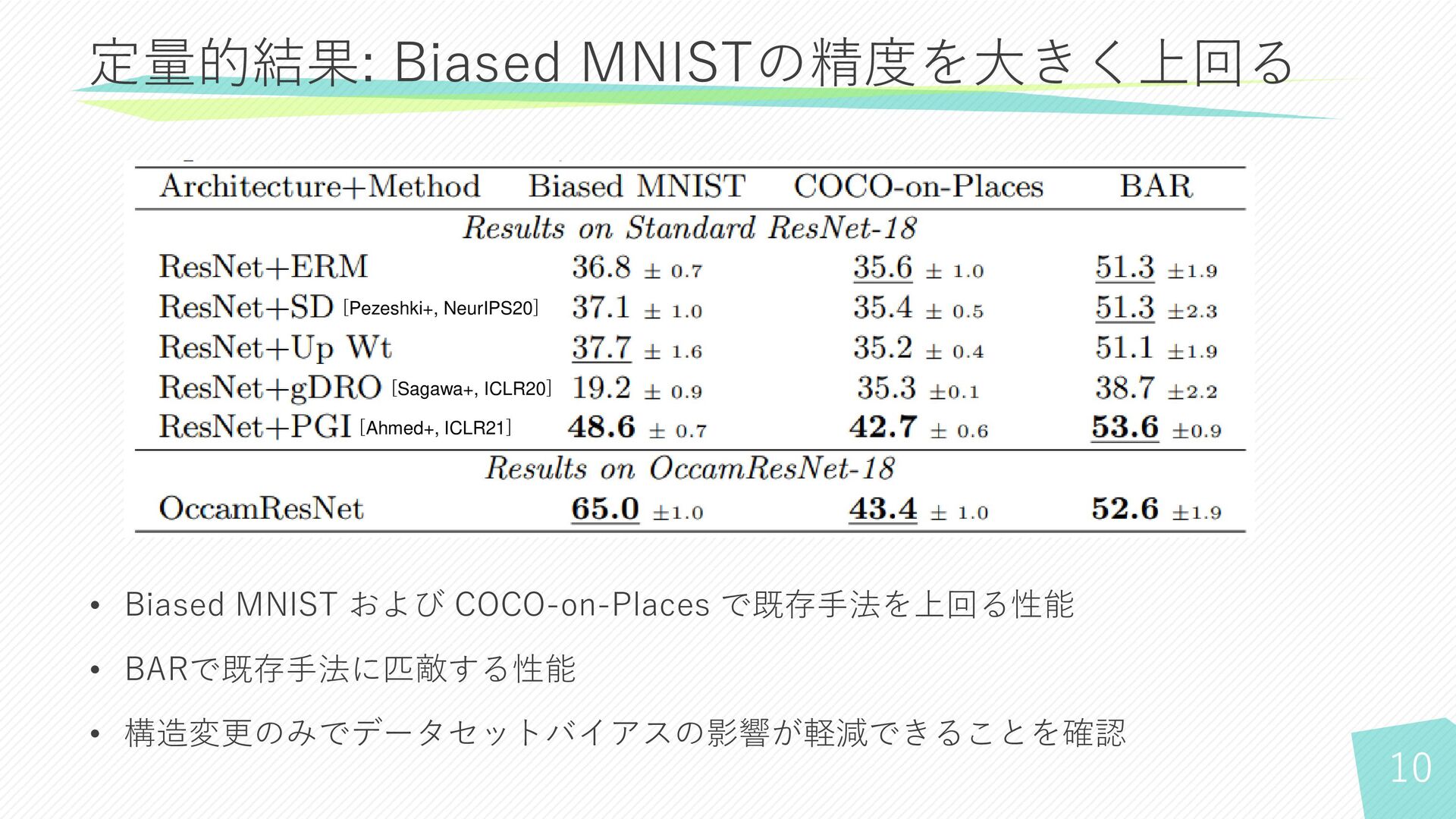
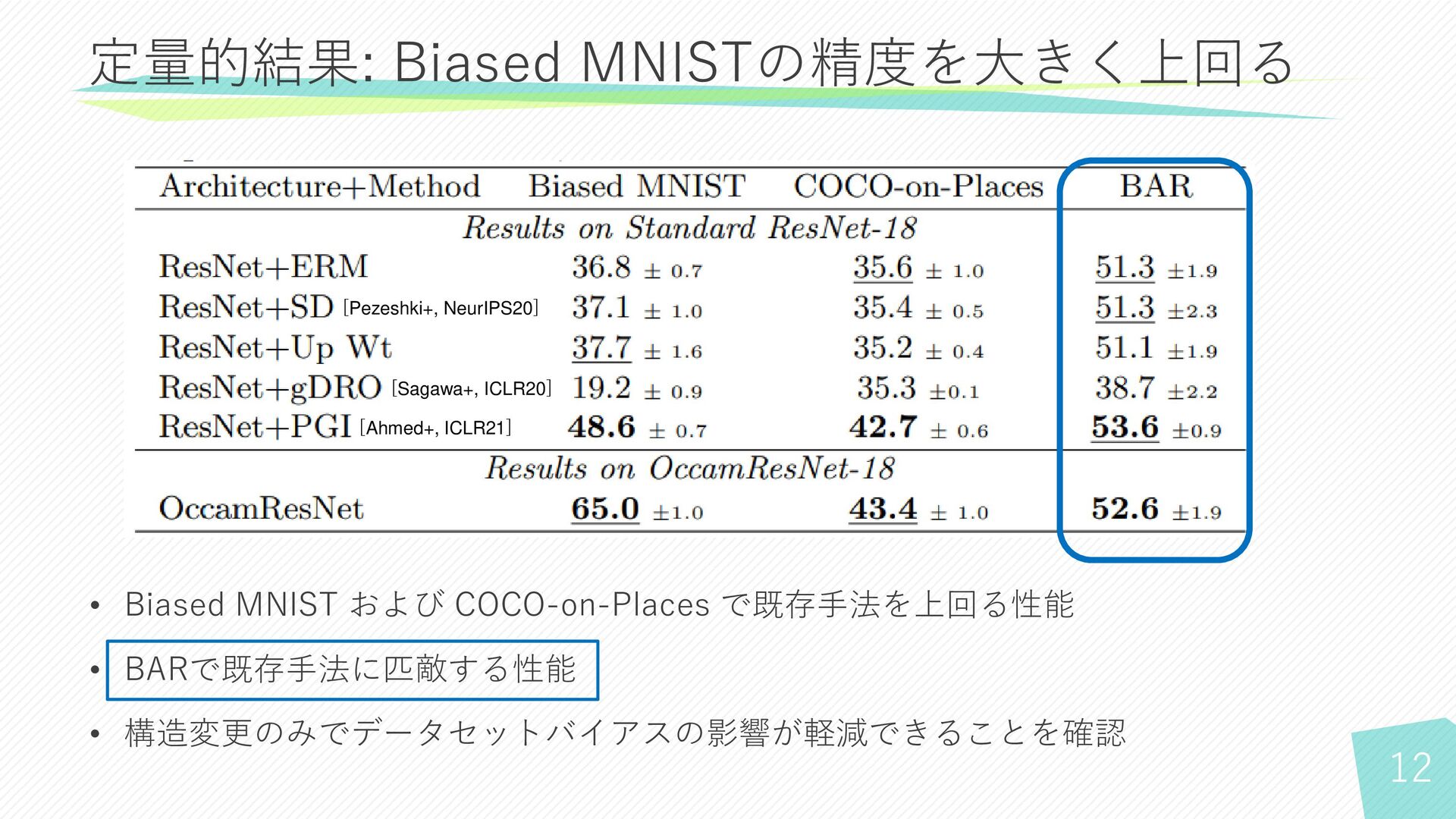
10 定量的結果: Biased MNISTの精度を大きく上回る • Biased MNIST および COCO-on-Places で既存手法を上回る性能
• BARで既存手法に匹敵する性能 • 構造変更のみでデータセットバイアスの影響が軽減できることを確認 [Pezeshki+, NeurIPS20] [Sagawa+, ICLR20] [Ahmed+, ICLR21]
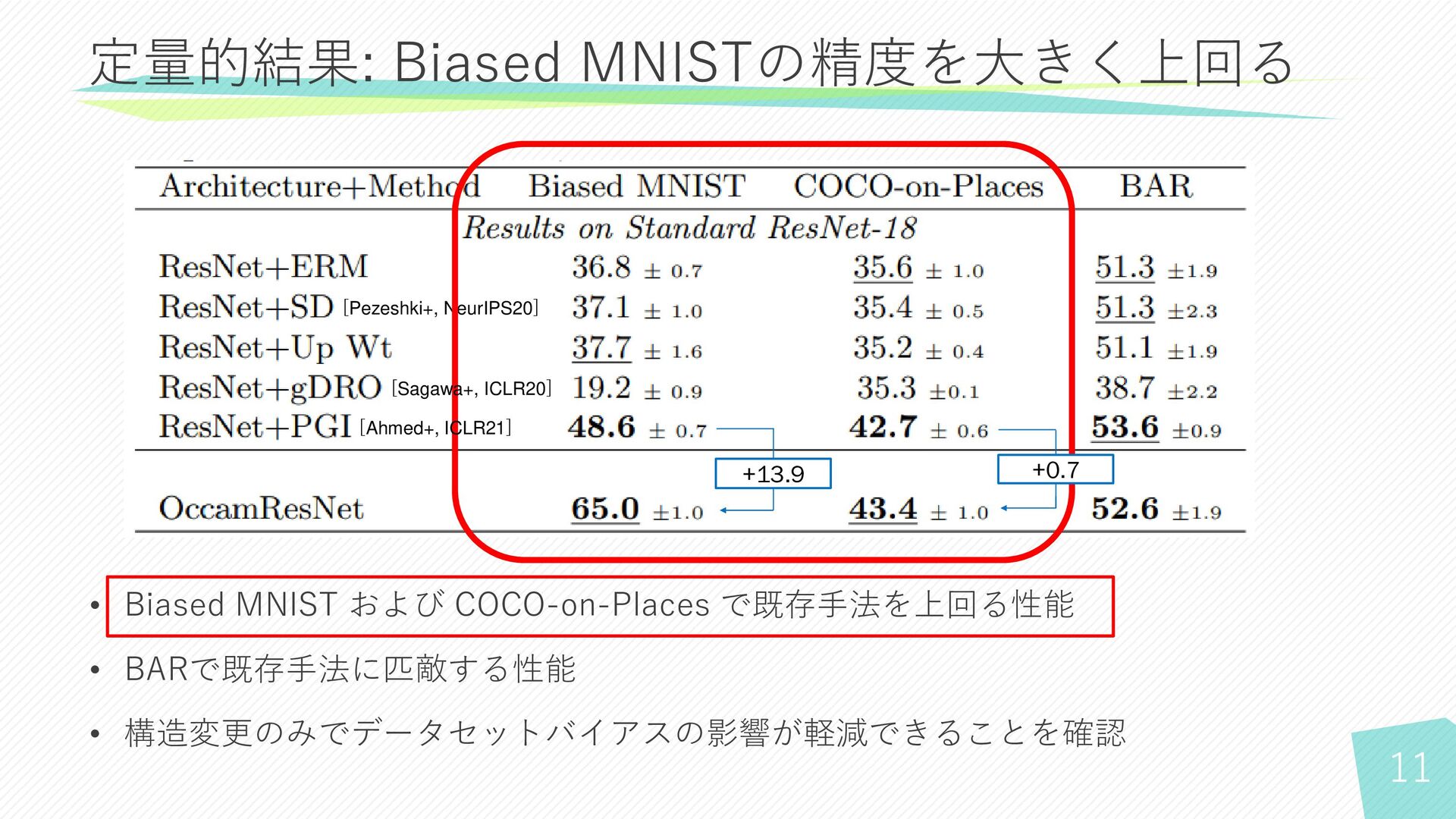
11 定量的結果: Biased MNISTの精度を大きく上回る • Biased MNIST および COCO-on-Places で既存手法を上回る性能
• BARで既存手法に匹敵する性能 • 構造変更のみでデータセットバイアスの影響が軽減できることを確認 [Pezeshki+, NeurIPS20] Shrestha [Sagawa+, ICLR20] [Ahmed+, ICLR21] +13.9 +0.7
12 定量的結果: Biased MNISTの精度を大きく上回る • Biased MNIST および COCO-on-Places で既存手法を上回る性能
• BARで既存手法に匹敵する性能 • 構造変更のみでデータセットバイアスの影響が軽減できることを確認 [Pezeshki+, NeurIPS20] [Sagawa+, ICLR20] [Ahmed+, ICLR21]
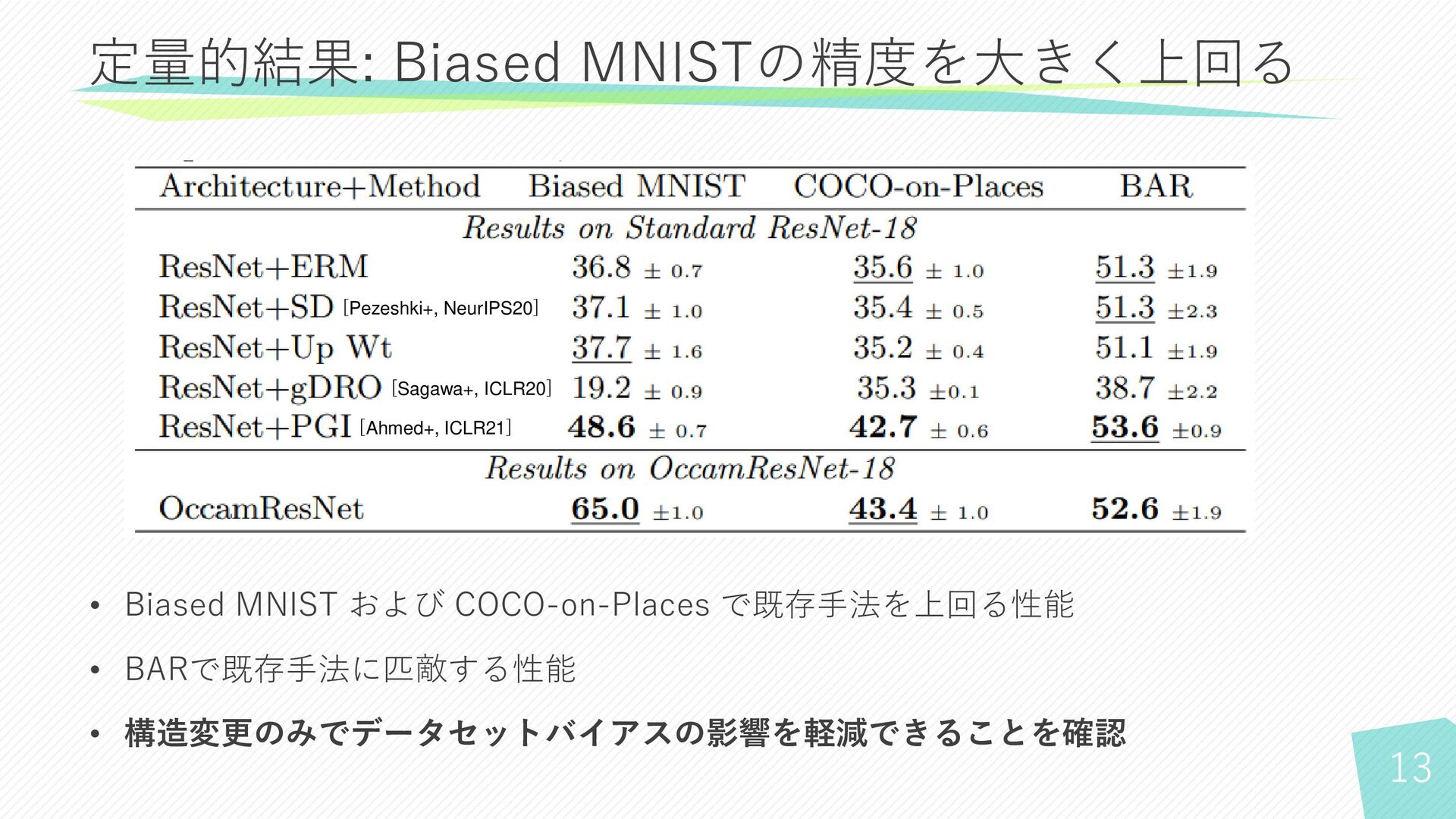
13 定量的結果: Biased MNISTの精度を大きく上回る • Biased MNIST および COCO-on-Places で既存手法を上回る性能
• BARで既存手法に匹敵する性能 • 構造変更のみでデータセットバイアスの影響を軽減できることを確認 [Pezeshki+, NeurIPS20] [Sagawa+, ICLR20] [Ahmed+, ICLR21]
14 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目
15 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目 無駄書き付近に注目
16 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目 適切な領域に注目
17 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目 注目箇所が不適切
注目領域が広すぎる
18 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目 適切な限られた領域に注目
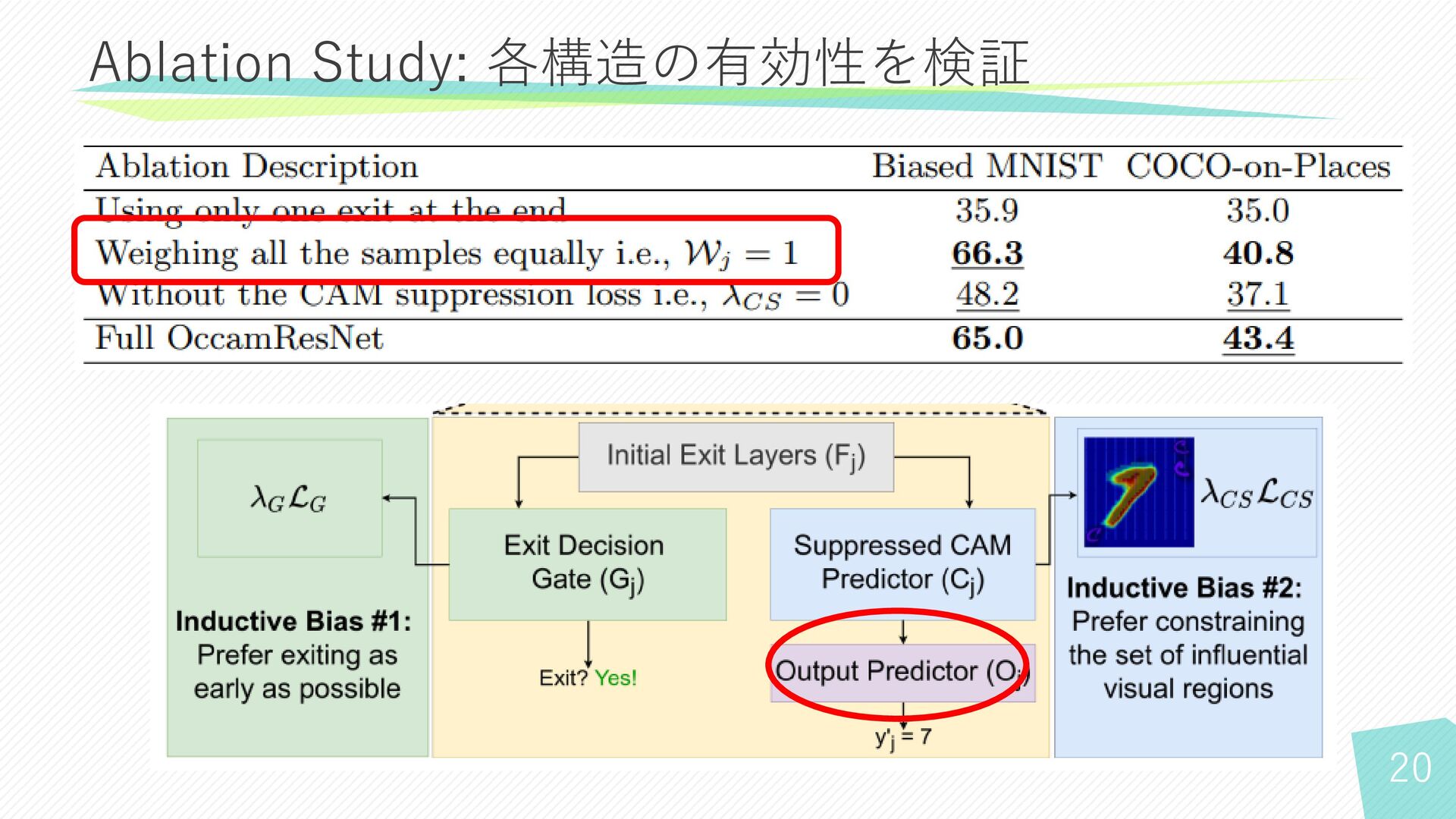
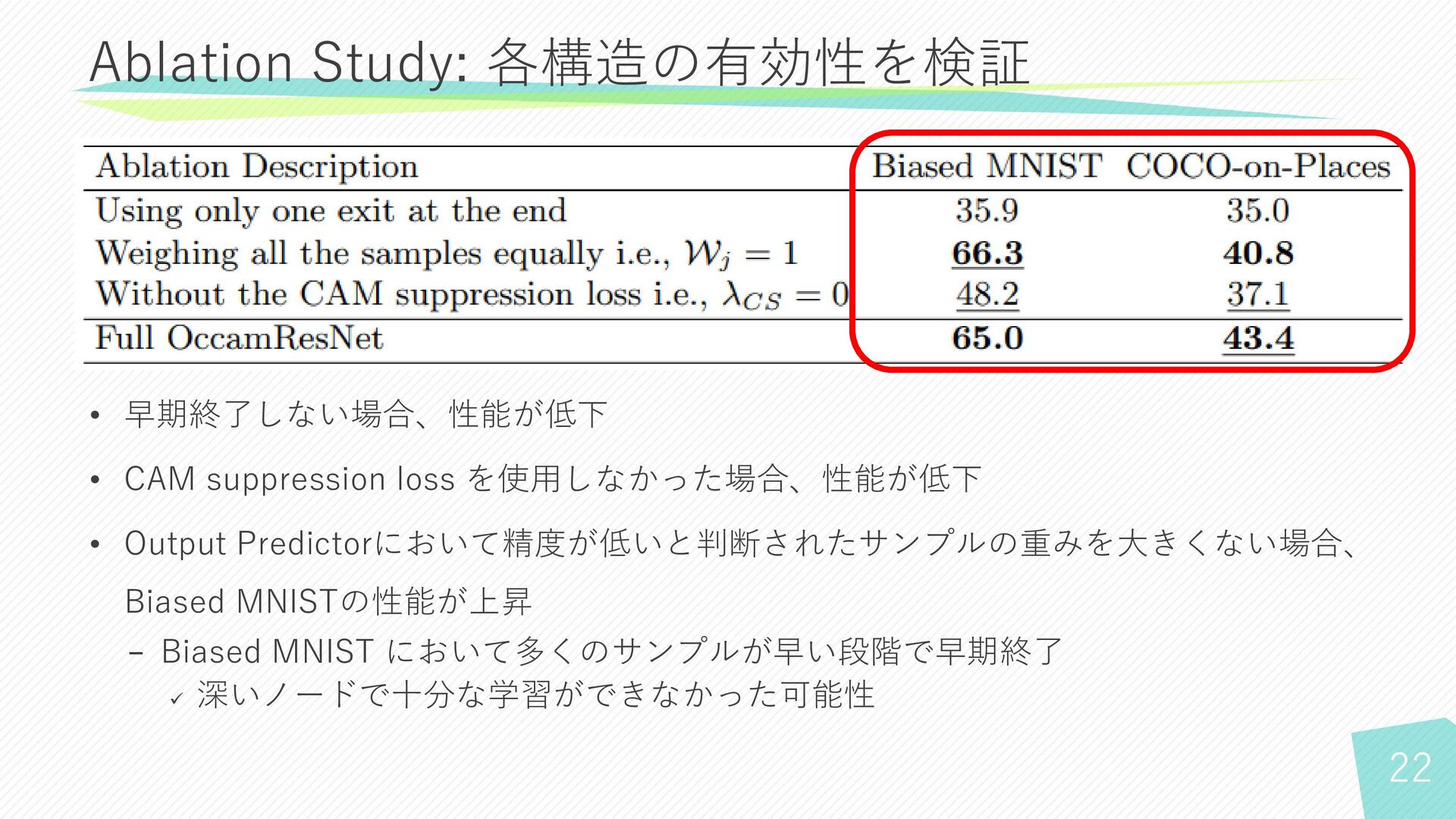
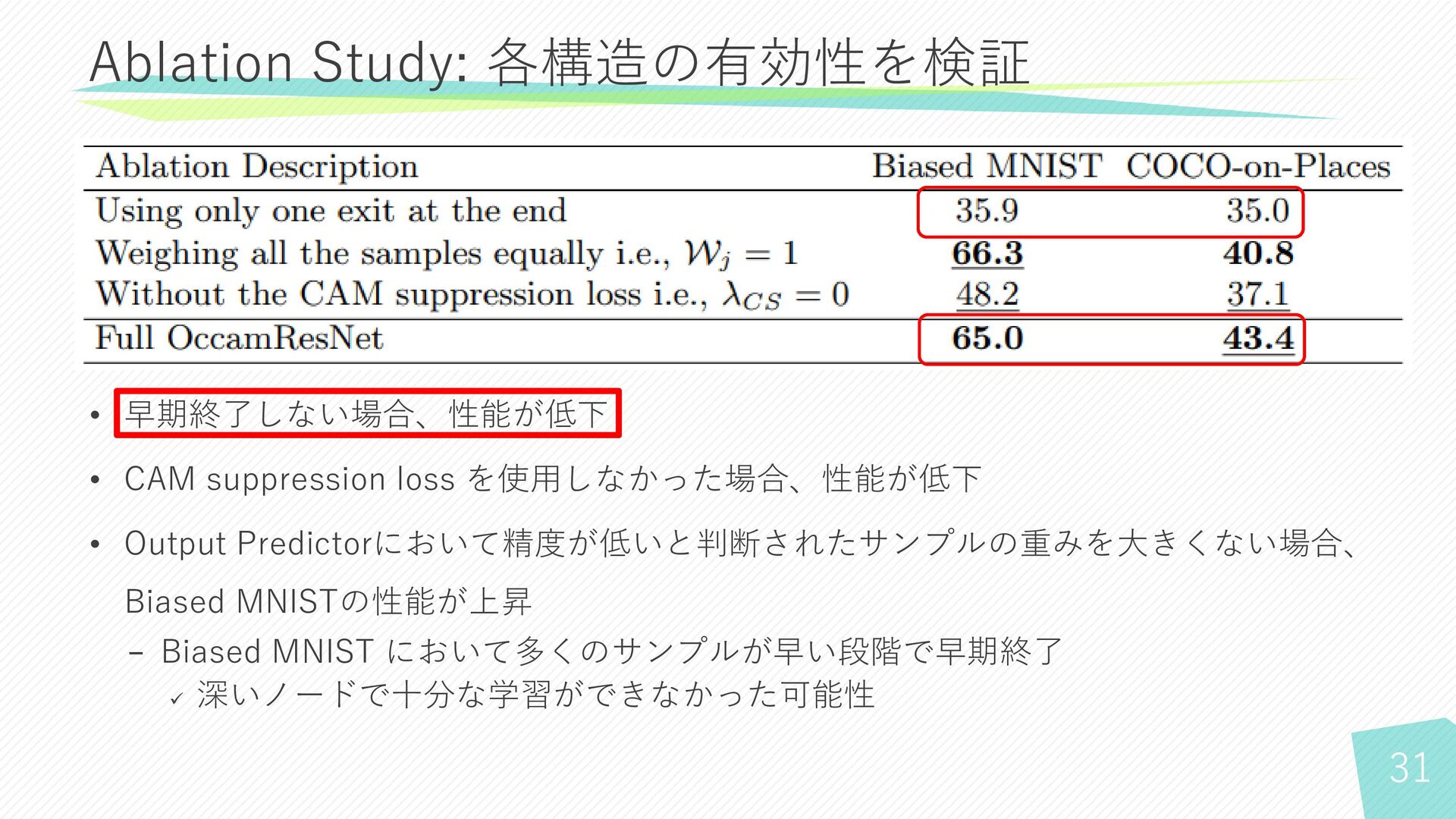
19 Ablation Study: 各構造の有効性を検証
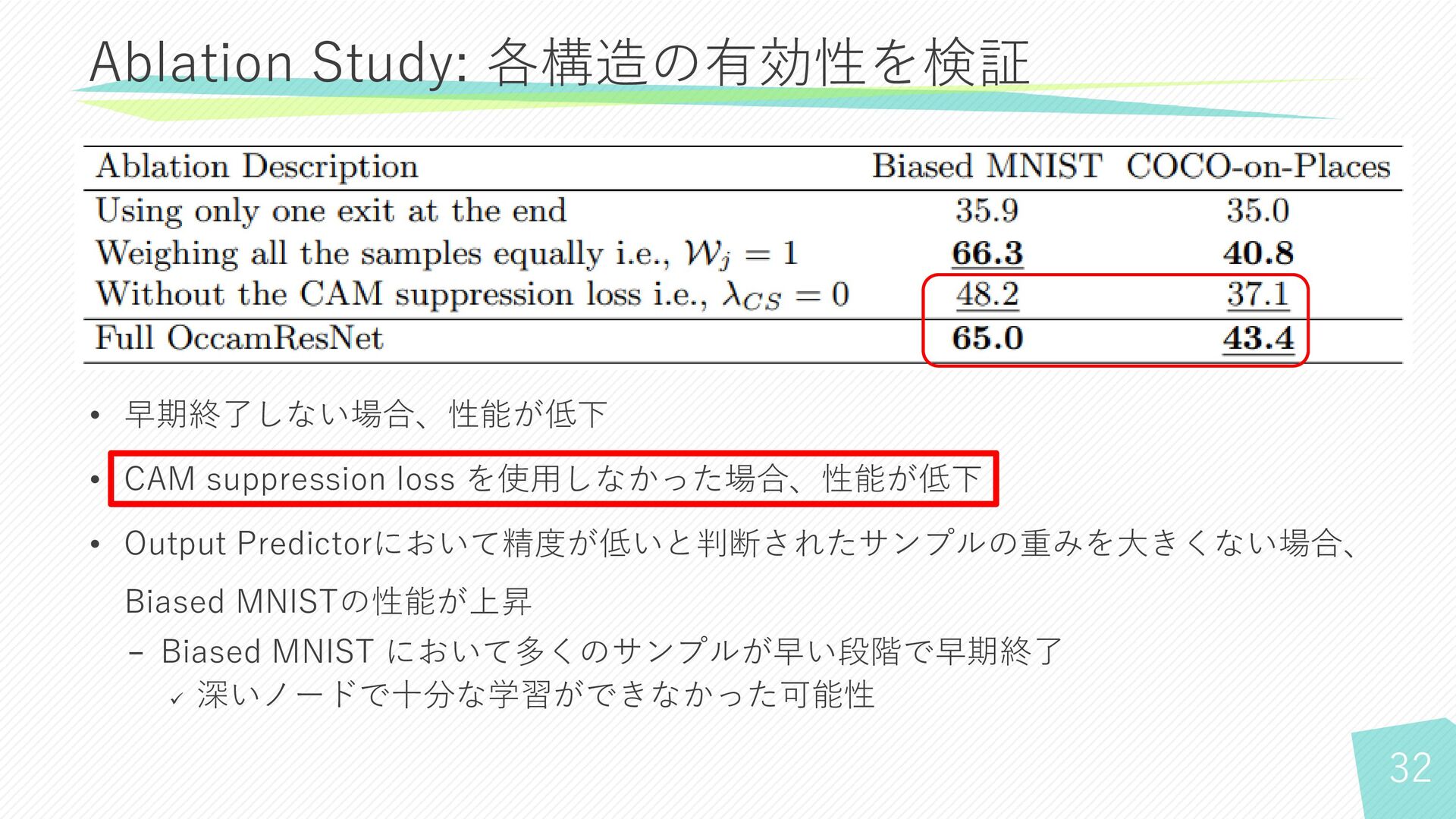
20 Ablation Study: 各構造の有効性を検証
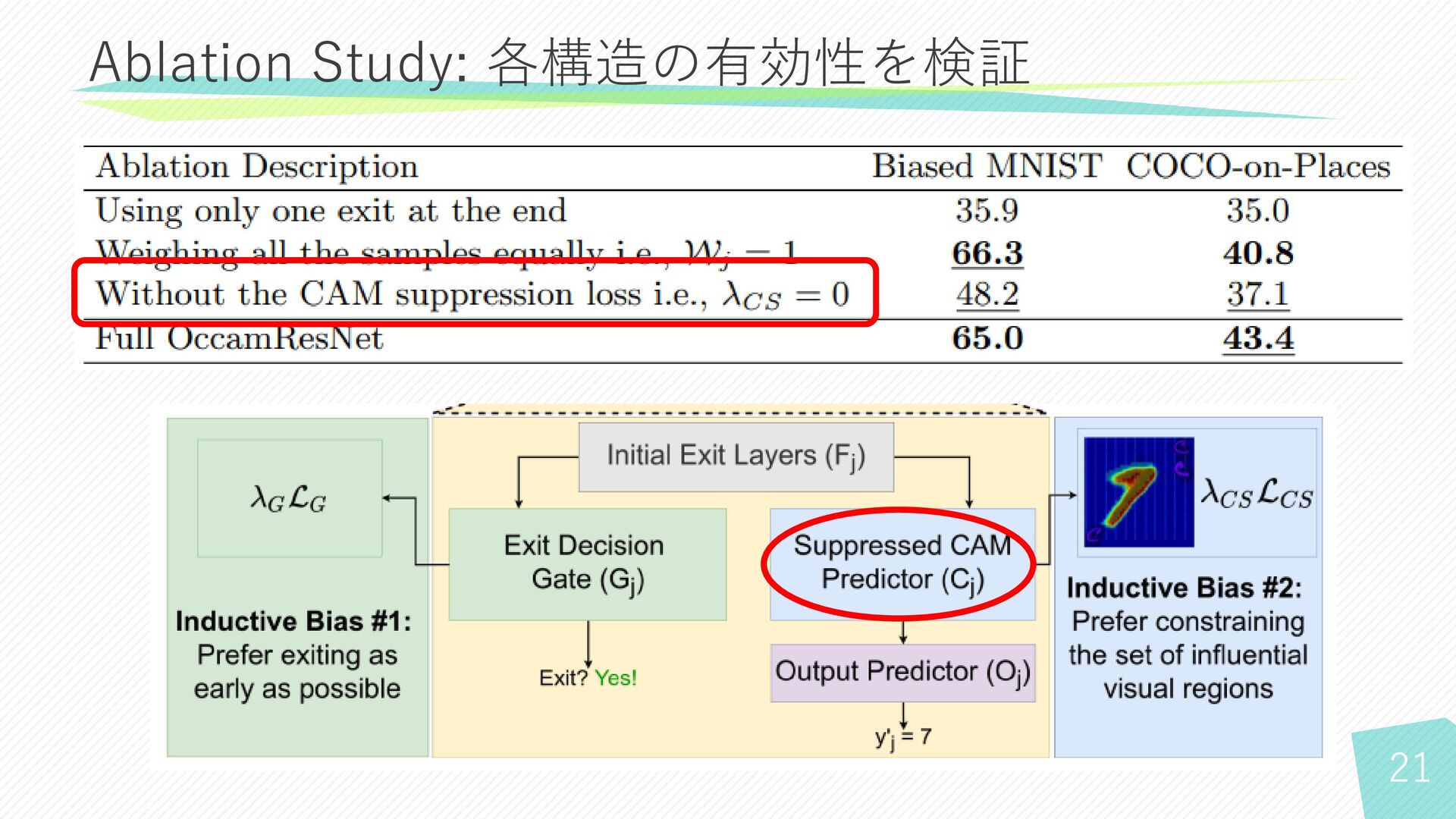
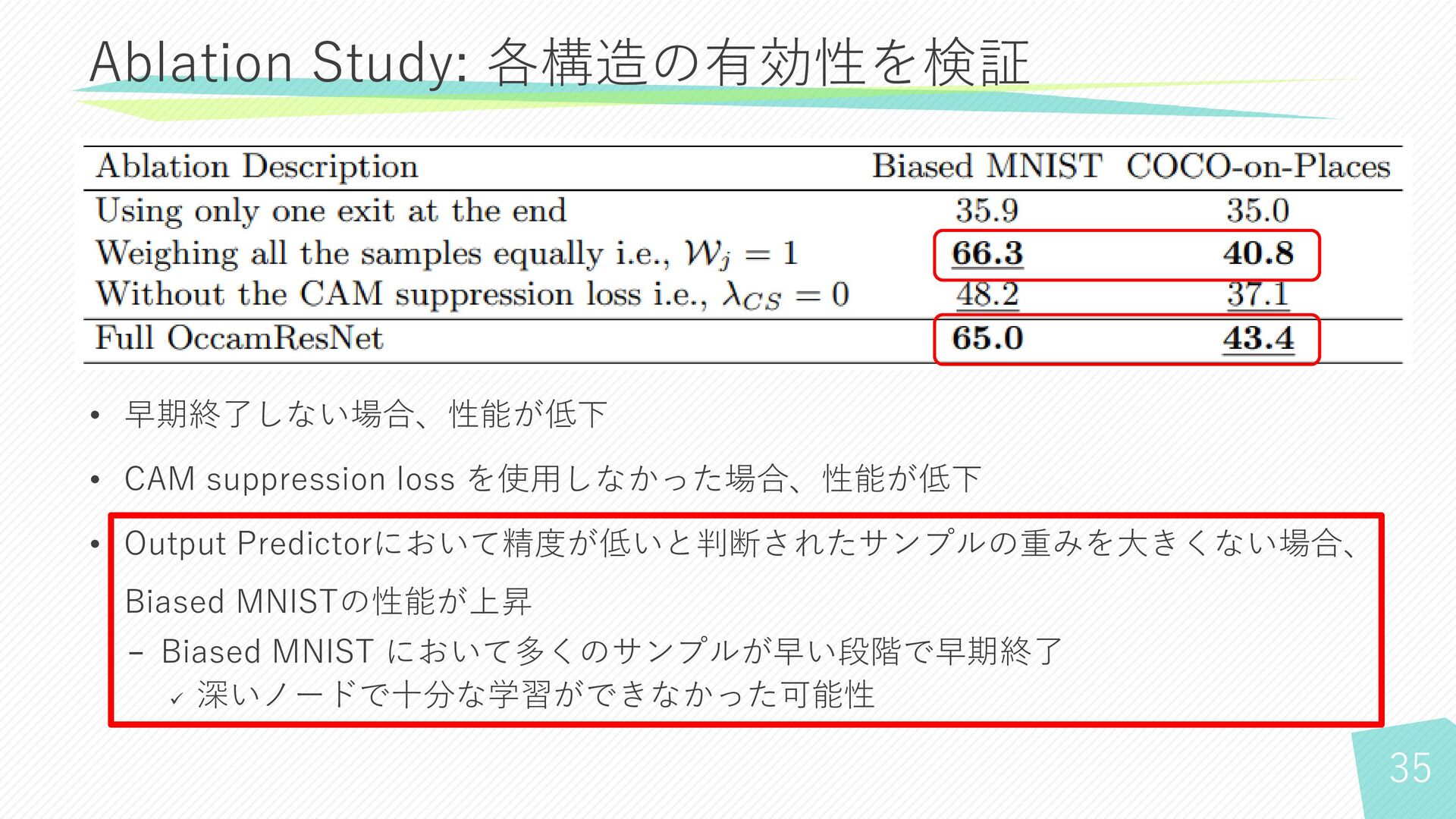
21 Ablation Study: 各構造の有効性を検証
22 Ablation Study: 各構造の有効性を検証 • 早期終了しない場合、性能が低下 • CAM suppression loss
を使用しなかった場合、性能が低下 • Output Predictorにおいて精度が低いと判断されたサンプルの重みを大きくない場合、 Biased MNISTの性能が上昇 − Biased MNIST において多くのサンプルが早い段階で早期終了 ✓ 深いノードで十分な学習ができなかった可能性
23 • attention map が不適切 • GTが9のサンプルを0と予測 • 背景のバイアスが強いサンプルでも 適切に注目
Biased MNISTにおける追試 (左: 成功例、右: 失敗例) original OccamNet 予測: 0 OccamNet original 予測: 7 original OccamNet 予測: 7
24 • attention map が不適切 • GTが9のサンプルを0と予測 • 背景のバイアスが強いサンプルでも 適切に注目
Biased MNISTにおける追試 (左: 成功例、右: 失敗例) original OccamNet 予測: 0 OccamNet original 予測: 7 original OccamNet 予測: 7
25 • attention map が不適切 • ラベルが9のサンプルを0と予測 • 背景のバイアスが強いサンプルでも 適切に注目
Biased MNISTにおける追試 (左: 成功例、右: 失敗例) original OccamNet 予測: 0 OccamNet original 予測: 7 original OccamNet 予測: 7 「0」部分付近に 注目
26 • 背景: − データセットバイアスや疑似相関が汎化性能に悪影響を与えることがある • 提案手法:OccamNets − サンプルごとに層の早期終了を行う ✓
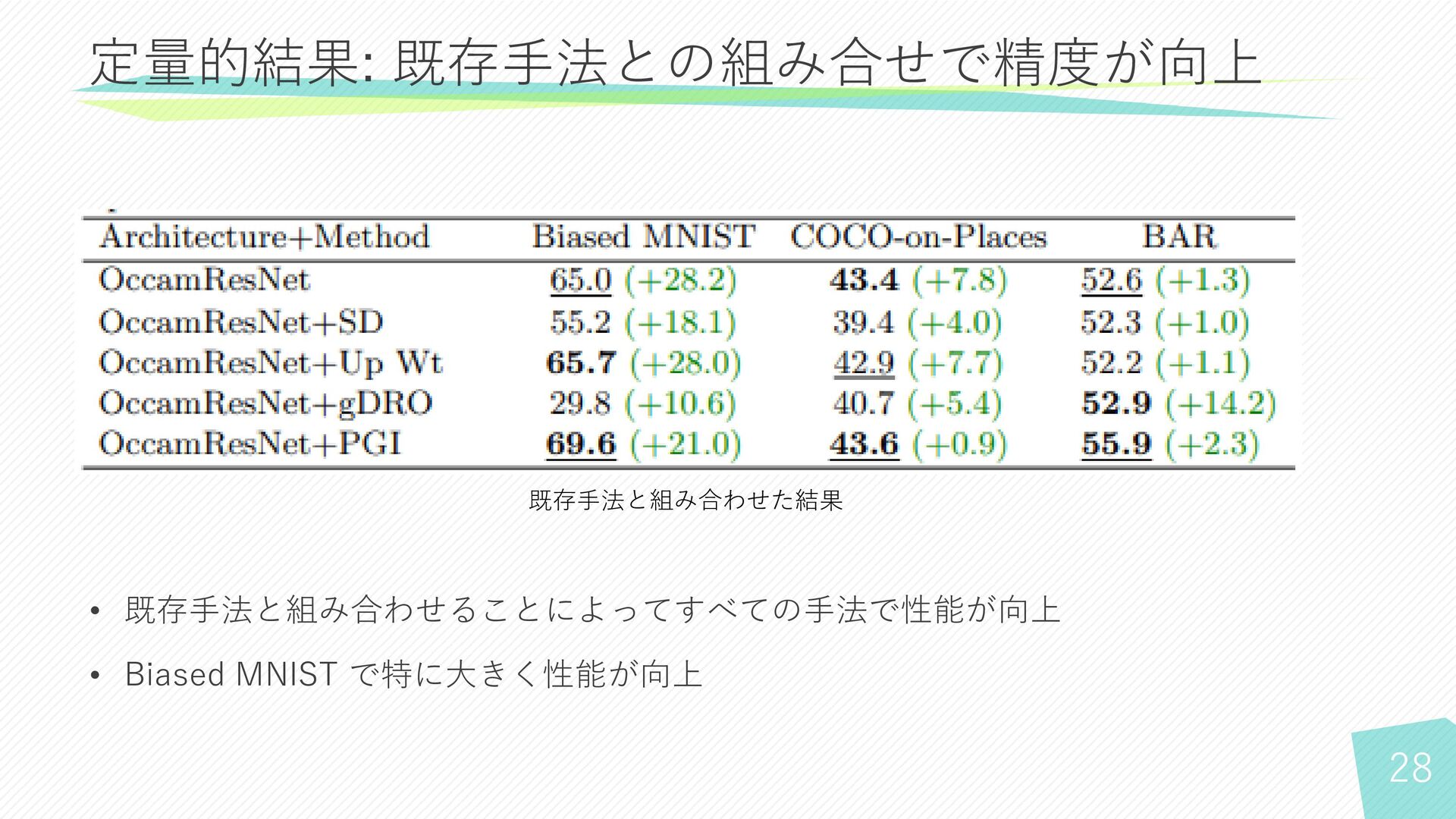
各層で推論が不十分と判断されたサンプルのみ次の層に進む • 結果: − バイアスのあるデータセットで既存手法を上回る性能 − 既存手法と組み合わせることで性能がより向上 まとめ
27 Appendix
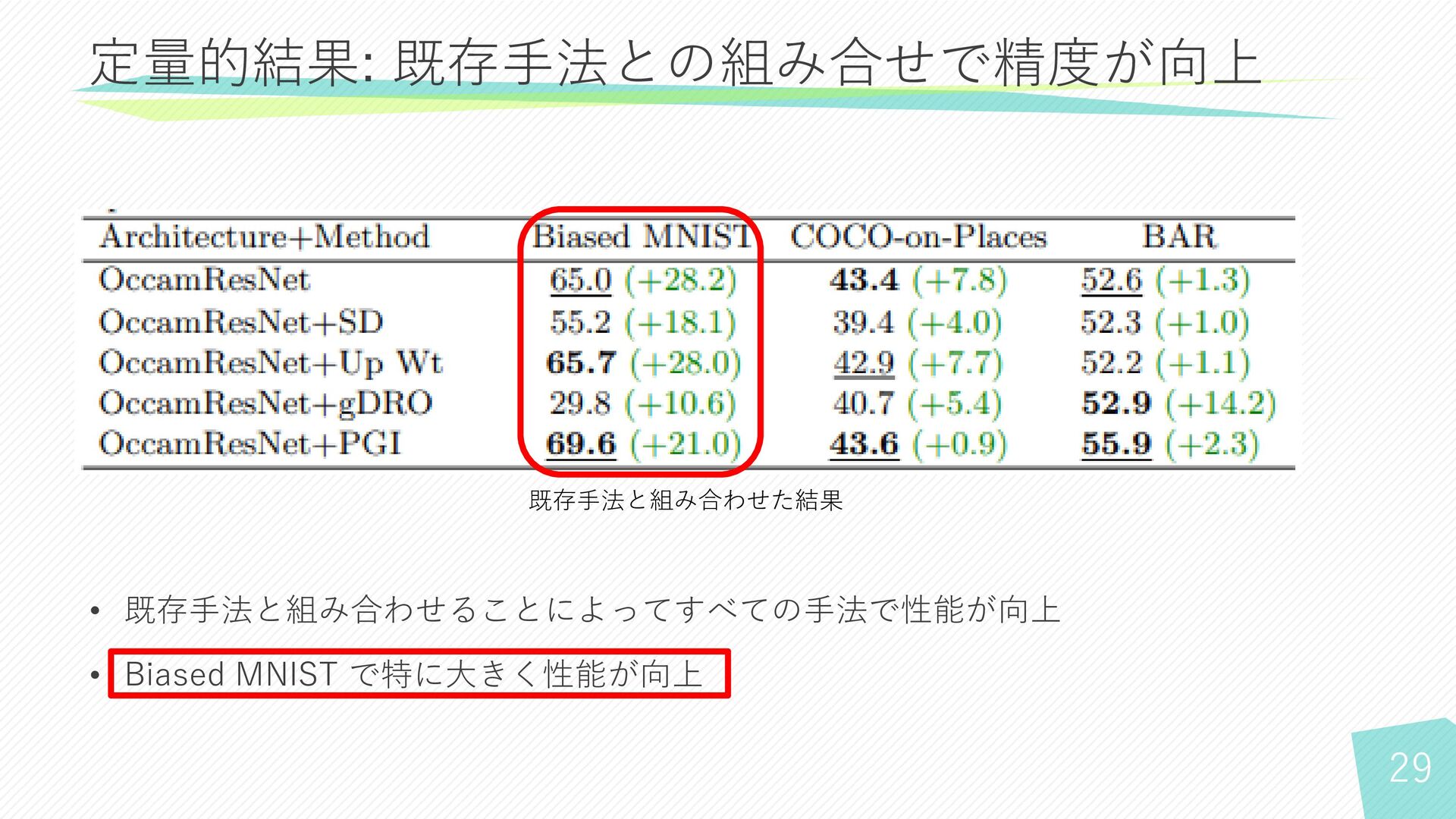
28 • 既存手法と組み合わせることによってすべての手法で性能が向上 • Biased MNIST で特に大きく性能が向上 定量的結果: 既存手法との組み合せで精度が向上 既存手法と組み合わせた結果
29 • 既存手法と組み合わせることによってすべての手法で性能が向上 • Biased MNIST で特に大きく性能が向上 定量的結果: 既存手法との組み合せで精度が向上 既存手法と組み合わせた結果
Robik Shrestha
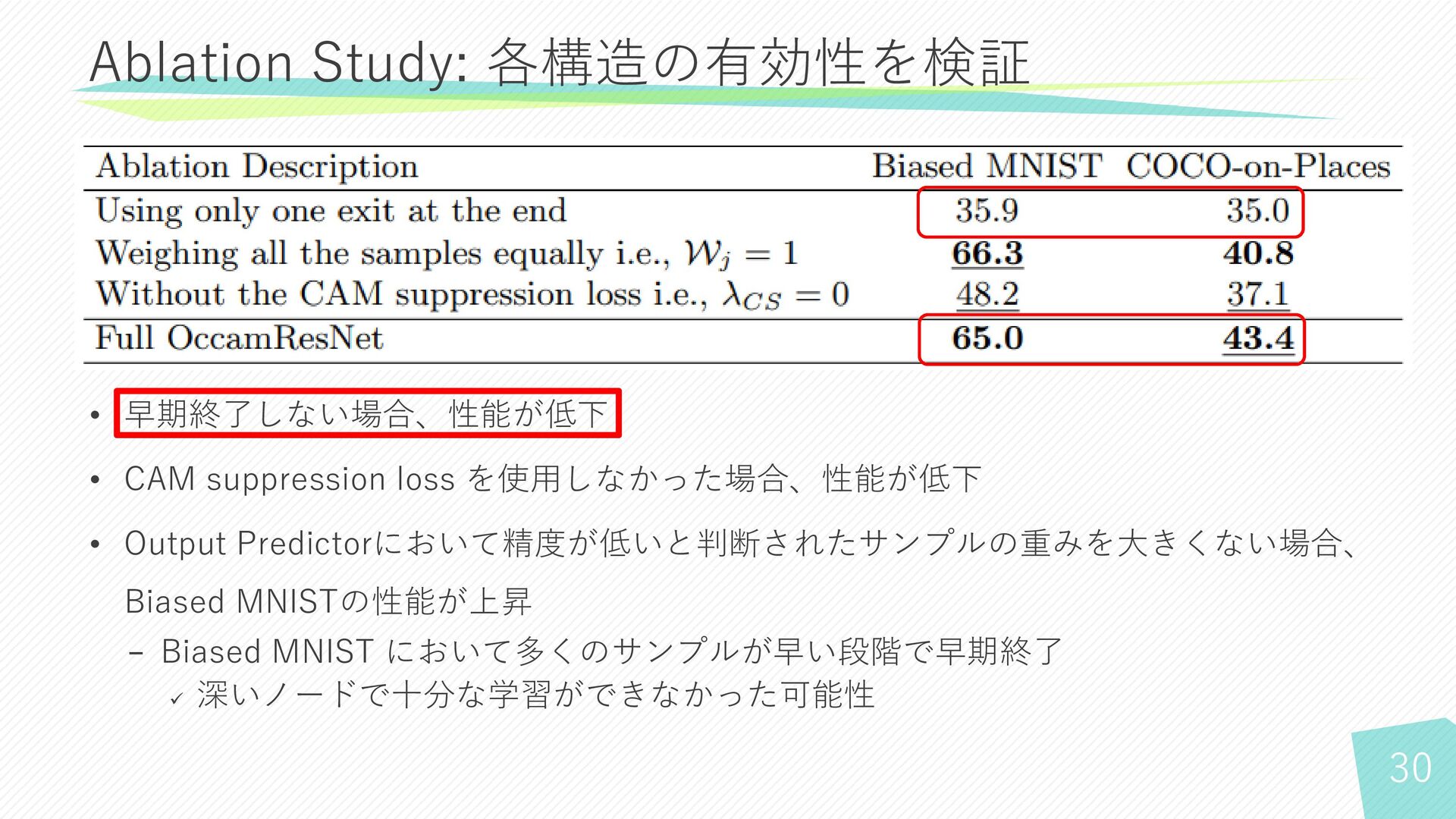
30 • 早期終了しない場合、性能が低下 • CAM suppression loss を使用しなかった場合、性能が低下 • Output
Predictorにおいて精度が低いと判断されたサンプルの重みを大きくない場合、 Biased MNISTの性能が上昇 − Biased MNIST において多くのサンプルが早い段階で早期終了 ✓ 深いノードで十分な学習ができなかった可能性 Ablation Study: 各構造の有効性を検証
31 • 早期終了しない場合、性能が低下 • CAM suppression loss を使用しなかった場合、性能が低下 • Output
Predictorにおいて精度が低いと判断されたサンプルの重みを大きくない場合、 Biased MNISTの性能が上昇 − Biased MNIST において多くのサンプルが早い段階で早期終了 ✓ 深いノードで十分な学習ができなかった可能性 Ablation Study: 各構造の有効性を検証
32 • 早期終了しない場合、性能が低下 • CAM suppression loss を使用しなかった場合、性能が低下 • Output
Predictorにおいて精度が低いと判断されたサンプルの重みを大きくない場合、 Biased MNISTの性能が上昇 − Biased MNIST において多くのサンプルが早い段階で早期終了 ✓ 深いノードで十分な学習ができなかった可能性 Ablation Study: 各構造の有効性を検証
33 • 早期終了しない場合、性能が低下 • CAM suppression loss を使用しなかった場合、性能が低下 • Output
Predictorにおいて精度が低いと判断されたサンプルの重みを大きくない場合、 Biased MNISTの精度が上昇 − Biased MNIST において多くのサンプルが早い段階で早期終了 ✓ 深いノードで十分な学習ができなかった可能性 Ablation Study: 各構造の有効性を検証
34 • 早期終了しない場合、性能が低下 • CAM suppression loss を使用しなかった場合、性能が低下 • Output
Predictorにおいて精度が低いと判断されたサンプルの重みを大きくない場合、 Biased MNISTの精度が上昇 − Biased MNIST において多くのサンプルが早い段階で早期終了 ✓ 深いノードで十分な学習ができなかった可能性 Ablation Study: 各構造の有効性を検証
35 • 早期終了しない場合、性能が低下 • CAM suppression loss を使用しなかった場合、性能が低下 • Output
Predictorにおいて精度が低いと判断されたサンプルの重みを大きくない場合、 Biased MNISTの性能が上昇 − Biased MNIST において多くのサンプルが早い段階で早期終了 ✓ 深いノードで十分な学習ができなかった可能性 Ablation Study: 各構造の有効性を検証
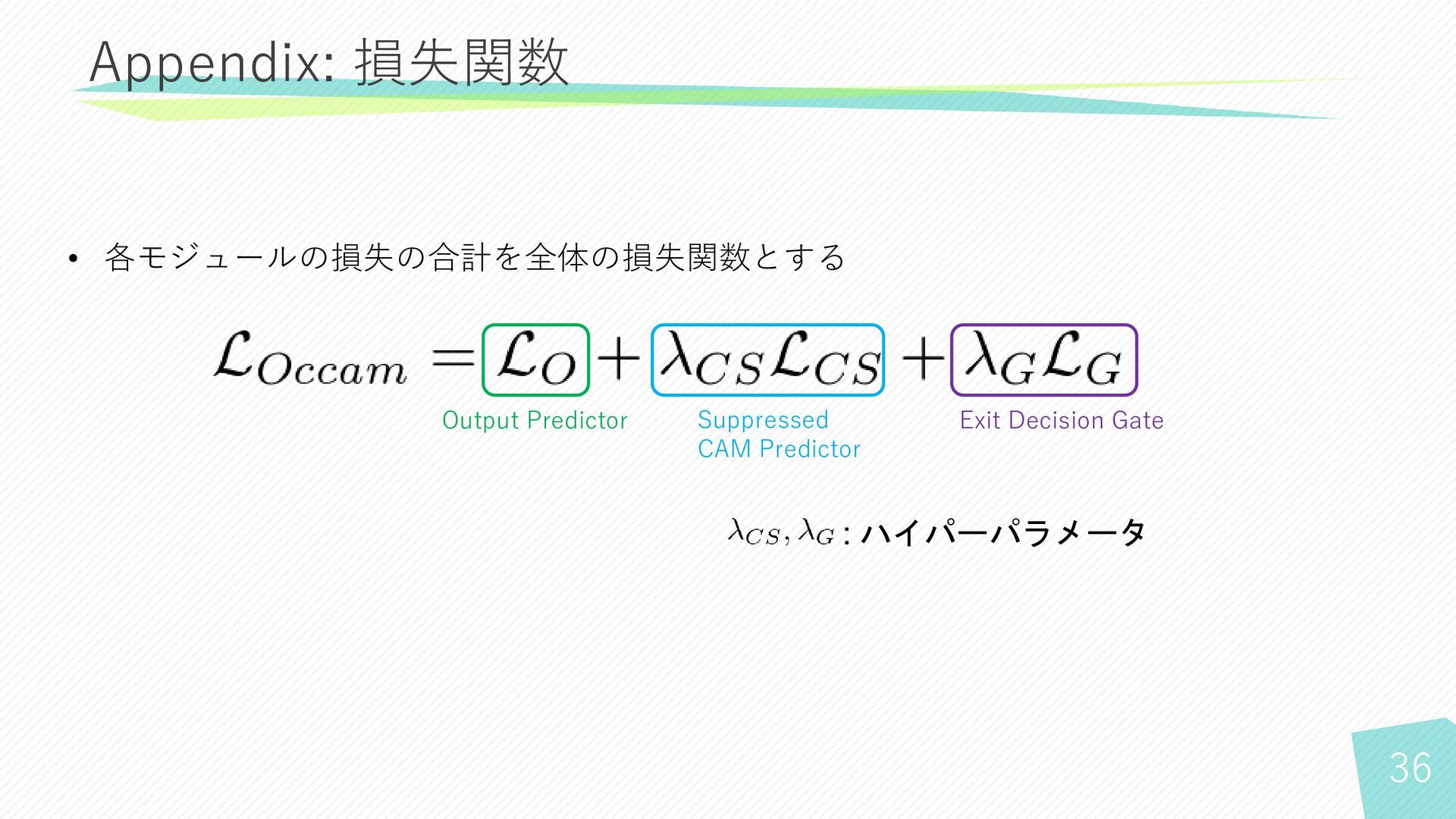
36 Appendix: 損失関数 Output Predictor Suppressed CAM Predictor Exit Decision
Gate • 各モジュールの損失の合計を全体の損失関数とする : ハイパーパラメータ
{kind=link}
{kind=link}
![3 関連研究: 既存手法 特徴や問題等 [Kim+, CVPR19] 正則化と敵対的ネットワークを用いたモデルによりデータセット バイアスに対応 データセットバイアスの要因がわかっている必要がある [Wolczyk+,](https://files.speakerdeck.com/presentations/6c76a4b192304a9ab55d98ed105f6b58/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![14 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目](https://files.speakerdeck.com/presentations/6c76a4b192304a9ab55d98ed105f6b58/slide_13.jpg){kind=link}
![15 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目 無駄書き付近に注目](https://files.speakerdeck.com/presentations/6c76a4b192304a9ab55d98ed105f6b58/slide_14.jpg){kind=link}
![16 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目 適切な領域に注目](https://files.speakerdeck.com/presentations/6c76a4b192304a9ab55d98ed105f6b58/slide_15.jpg){kind=link}
![17 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目 注目箇所が不適切](https://files.speakerdeck.com/presentations/6c76a4b192304a9ab55d98ed105f6b58/slide_16.jpg){kind=link}
![18 • 既存手法にGrad-CAM [Selvaraju+, ICCV 17] を適用し、注目領域を可視化 定性的結果: 適切な領域に注目 適切な限られた領域に注目](https://files.speakerdeck.com/presentations/6c76a4b192304a9ab55d98ed105f6b58/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}