[JSAI23]Fully Automated Task Management for Generation, Execution, and Evaluation: A Framework for Fetch-and-Carry Tasks with Natural Language Instructions in Continuous Space
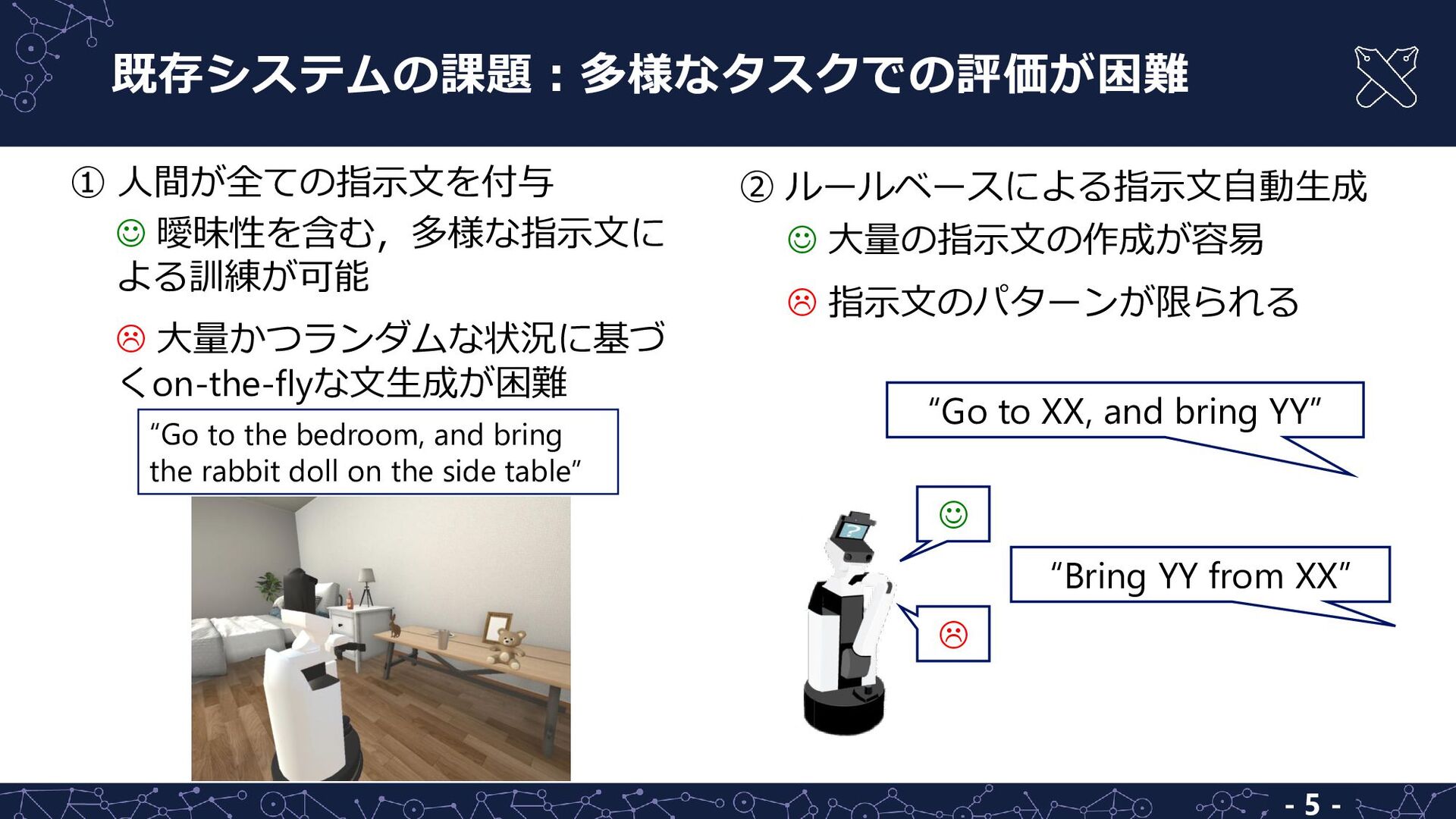
くon-the-flyな文生成が困難 ☺ 大量の指示文の作成が容易 指示文のパターンが限られる “Go to the bedroom, and bring the rabbit doll on the side table” “Go to XX, and bring YY” ☺ “Bring YY from XX” - 5 -
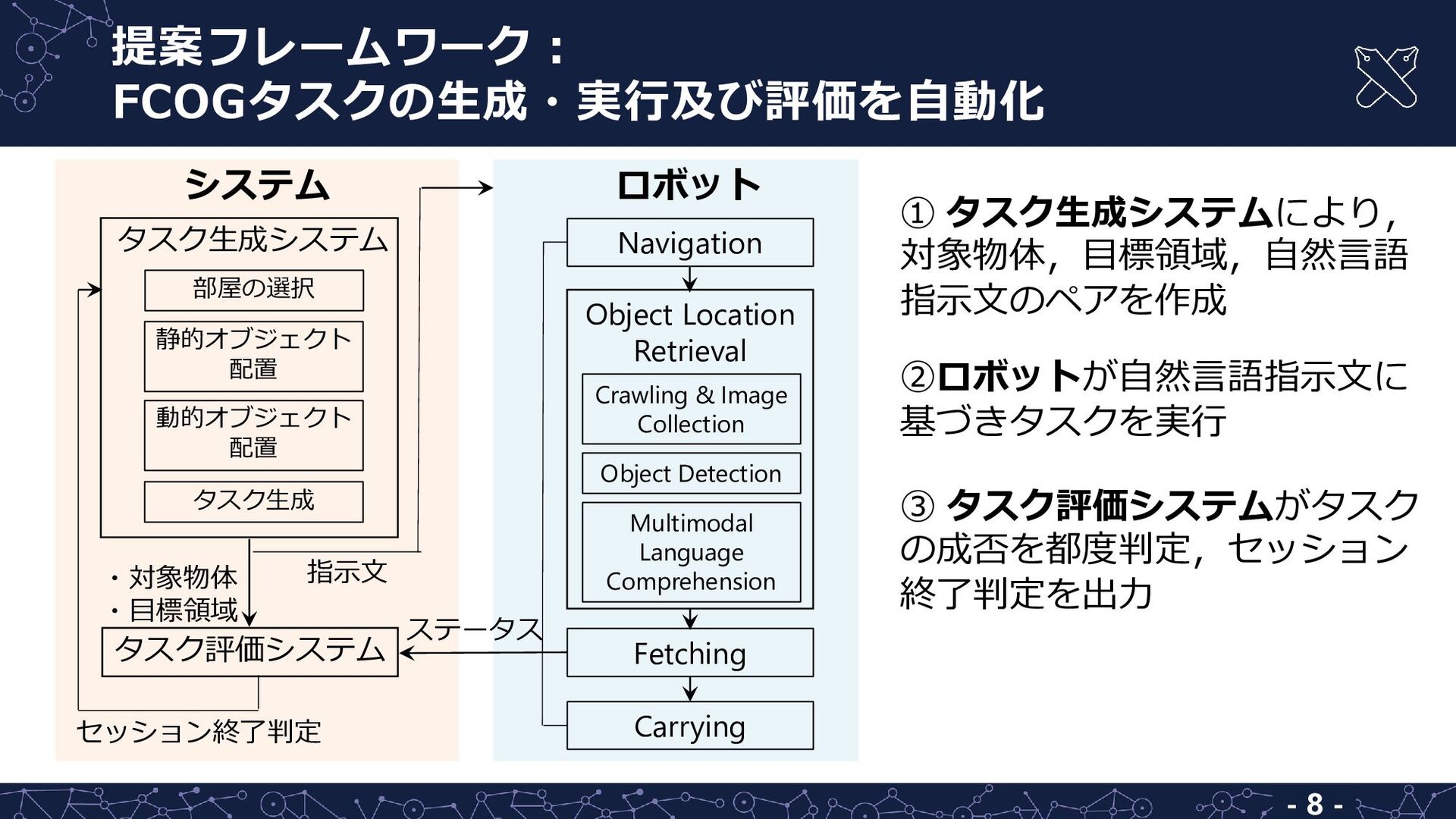
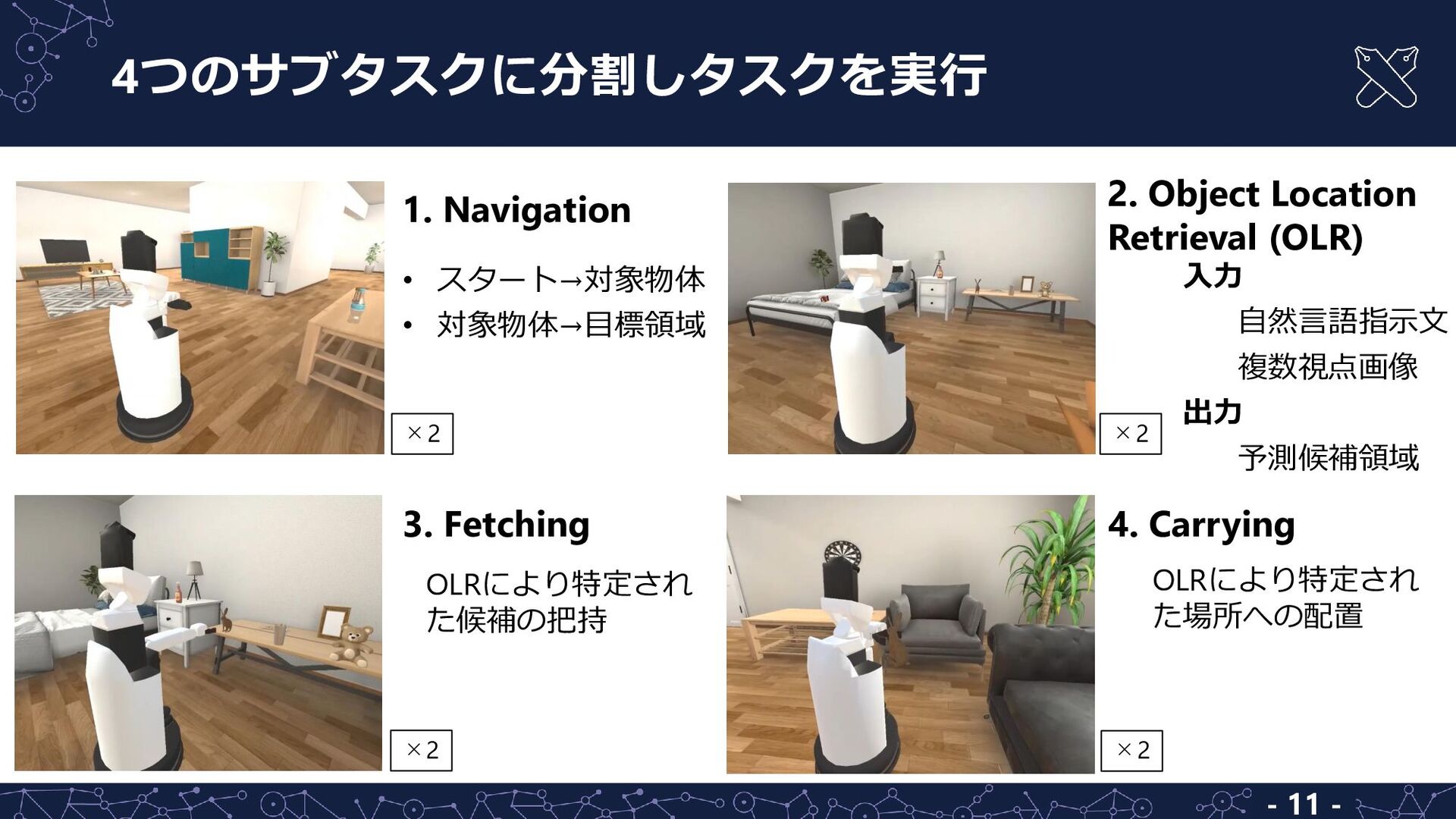
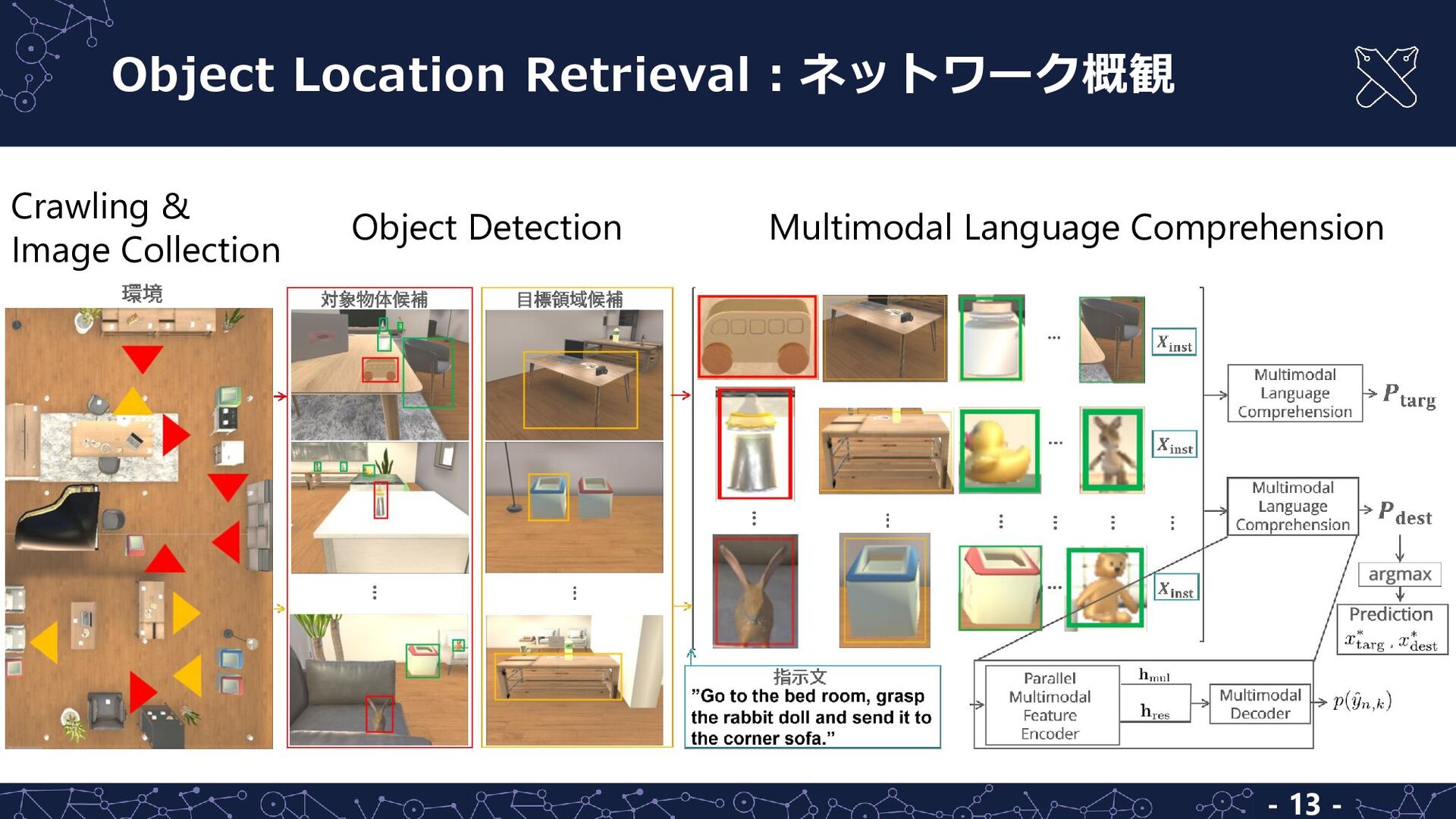
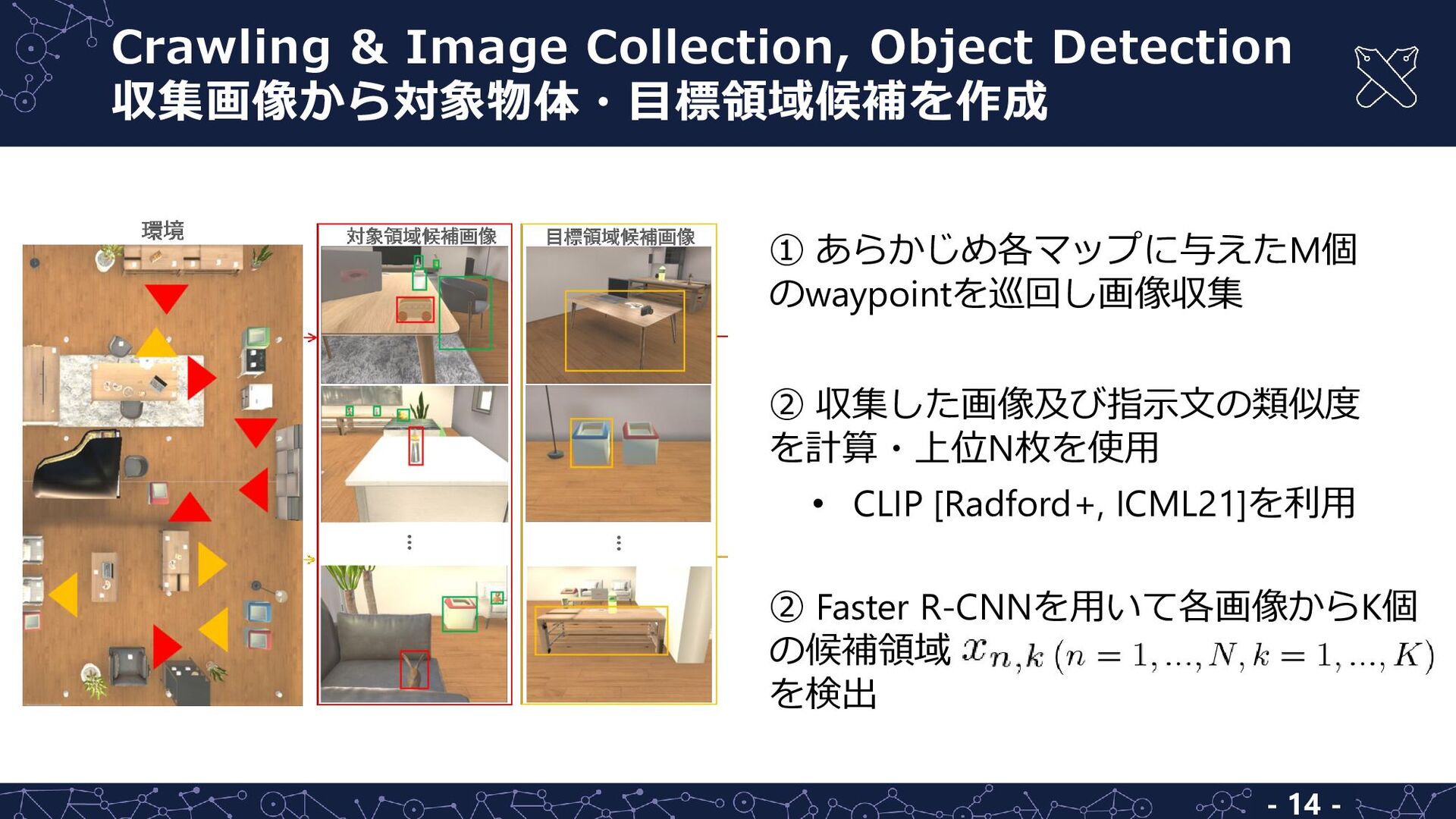
a toy wooden car on the table” • 対象物体及び目標領域の領域 • 対象物体の含まれる画像から 抽出した領域群 入力 出力 自然言語指示文 ① 対象物体及び目標領域をランダムに選択 ② それぞれの座標をシミュレータから取得・画像を撮影 ③ クロスモーダル言語生成モデルにより指示文を生成,ペアを作成 タスク生成手順 - 9 -
chair” “Put a box on the couch” “Move a statue to the coffee table” “Pick up the apple from the table” “Open the fridge door, put the bottle in the fridge, close the door, wait a few seconds, open the fridge, take the bottle out, and close the door” “Heat the brown round object in the box” “Put a red round object in the silver box” - 10 -
{kind=link}
{kind=link}
{kind=link}
![関連研究:Fetch-and-carryタスクに関連するフレームワーク ・手法は多く存在 手法 概要 REVERIE [Qi+, CVPR20] 高レベルな指示文を含むREVERIEベンチマークを提案 ALFRED [Shridhar+,](https://files.speakerdeck.com/presentations/bbcfcd8eb4ce42bf99284084a4929829/slide_3.jpg){kind=link}
{kind=link}
![既存手法の課題:離散的な行動の生成に留まる FILM [Min+, ICLR22] ALFREDやREVERIE等のシミュレーションにおけるベンチマークについて, 多くの既存手法が存在 VLN-DUET [Chen+, CVPR22] 多くは離散的な行動(move,](https://files.speakerdeck.com/presentations/bbcfcd8eb4ce42bf99284084a4929829/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
![タスク生成システム: クロスモーダル言語生成モデルを利用 対象領域 目標領域 画像中の領域群 … CRT [Kambara+, RA-L21] 出力:”Put](https://files.speakerdeck.com/presentations/bbcfcd8eb4ce42bf99284084a4929829/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![提案手法がタスク成功率でベースライン手法を上回る 手法 Navigation 成功率 [%] OLR 正解率 [%] Fetching 成功率](https://files.speakerdeck.com/presentations/bbcfcd8eb4ce42bf99284084a4929829/slide_16.jpg){kind=link}
![提案手法がタスク成功率でベースライン手法を上回る 手法 Navigation 成功率 [%] OLR 正解率 [%] Fetching 成功率](https://files.speakerdeck.com/presentations/bbcfcd8eb4ce42bf99284084a4929829/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
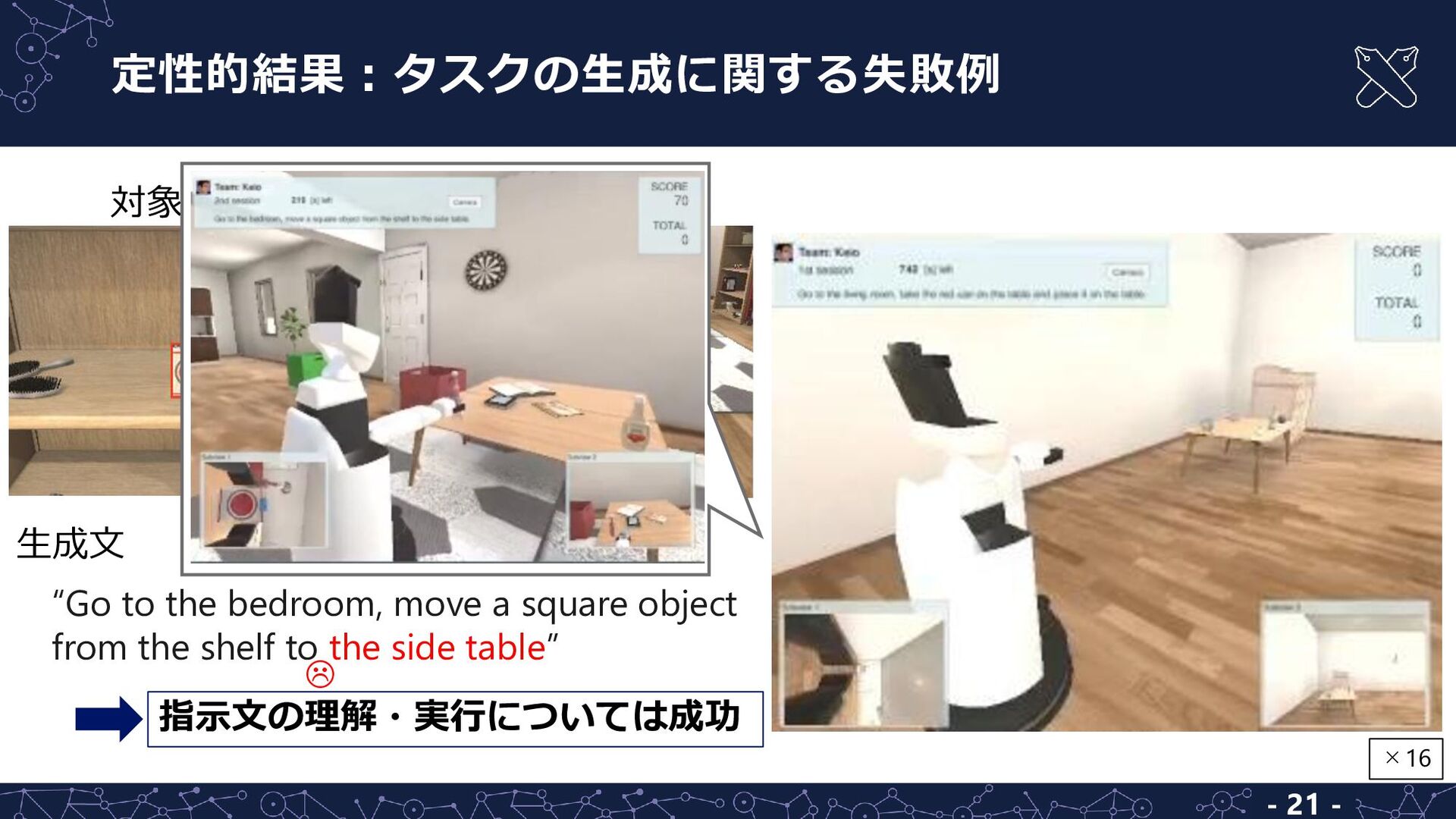
![マルチモーダル言語理解モデルについても,ベースライン 手法を上回る結果 - 22 - 手法 対象物体 正解率 [%] 目標領域](https://files.speakerdeck.com/presentations/bbcfcd8eb4ce42bf99284084a4929829/slide_21.jpg){kind=link}
{kind=link}