2. Abdulle, A., & Wanner, G. (2002). 200 years of least squares method. Elemente der Mathematik, 57(2), 45-60. 3. Rosenblatt, Frank. "The perceptron: a probabilistic model for information storage and organization in the brain." Psychological review 65.6 (1958): 386. 4. Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. "Learning representations by back-propagating errors." nature 323.6088 (1986): 533-536. 5. Cybenko, George. "Approximation by superpositions of a sigmoidal function." Mathematics of control, signals and systems 2.4 (1989): 303-314. 6. Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. "A fast learning algorithm for deep belief nets." Neural computation 18.7 (2006): 1527-1554.
![情報工学科 教授 杉浦孔明 [email protected] 慶應義塾大学理工学部 機械学習基礎 第3回 機械学習の基礎(2):基礎的概念](https://files.speakerdeck.com/presentations/4859d16ab24a4ee2a5428ffe5346abc2/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![簡単な歴史① 1800年頃 ガウスやルジャンドルらが最小二乗法を発明 「なぜ4乗や6乗でなく2乗なのか」をガウス分布で説明 1958年 パーセプトロン発表 [Rosenblatt 1958] 第1次AIブーム](https://files.speakerdeck.com/presentations/4859d16ab24a4ee2a5428ffe5346abc2/slide_4.jpg){kind=link}
![簡単な歴史② 1800年頃 ガウスやルジャンドルらが最小二乗法を発明 「なぜ4乗や6乗でなく2乗なのか」をガウス分布で説明 1958年 パーセプトロン発表 [Rosenblatt 1958] 第1次AIブーム 1960年代後半](https://files.speakerdeck.com/presentations/4859d16ab24a4ee2a5428ffe5346abc2/slide_5.jpg){kind=link}
![ニューラルネットの低迷 2003年に発表された論文 [Simard+ 2003] のイントロ 「1990年代前半まではニューラルネットは広く研究されていたが、最近 5年間、見向きされなくなった。 2000年には、Neural Information Processing](https://files.speakerdeck.com/presentations/4859d16ab24a4ee2a5428ffe5346abc2/slide_6.jpg){kind=link}
![簡単な歴史③ 2006年 Hintonらが深層学習を提唱 [Hinton+ 2006] 学術会議等で徐々に浸透するものの、広まりは緩やか 「3層ニューラルネットで十分では?」と思われていた 2012年 深層ニューラルネットが画像認識コンペILSVRCにおいて優勝し注 目される(ImageNetデータセット)](https://files.speakerdeck.com/presentations/4859d16ab24a4ee2a5428ffe5346abc2/slide_7.jpg){kind=link}
![簡単な歴史③ 2006年 Hintonらが深層学習を提唱 [Hinton+ 2006] 学術会議等で徐々に浸透するものの、広まりは緩やか 「3層ニューラルネットで十分では?」と思われていた 2012年 深層ニューラルネットが画像認識コンペILSVRCにおいて優勝し注 目される(ImageNetデータセット)](https://files.speakerdeck.com/presentations/4859d16ab24a4ee2a5428ffe5346abc2/slide_8.jpg){kind=link}
![甘利俊一先生と福島邦彦先生 - - 10 甘利俊一先生 ▪ 多層パーセプトロンの 確率的勾配降下法 [Amari 1967]](https://files.speakerdeck.com/presentations/4859d16ab24a4ee2a5428ffe5346abc2/slide_9.jpg){kind=link}
{kind=link}
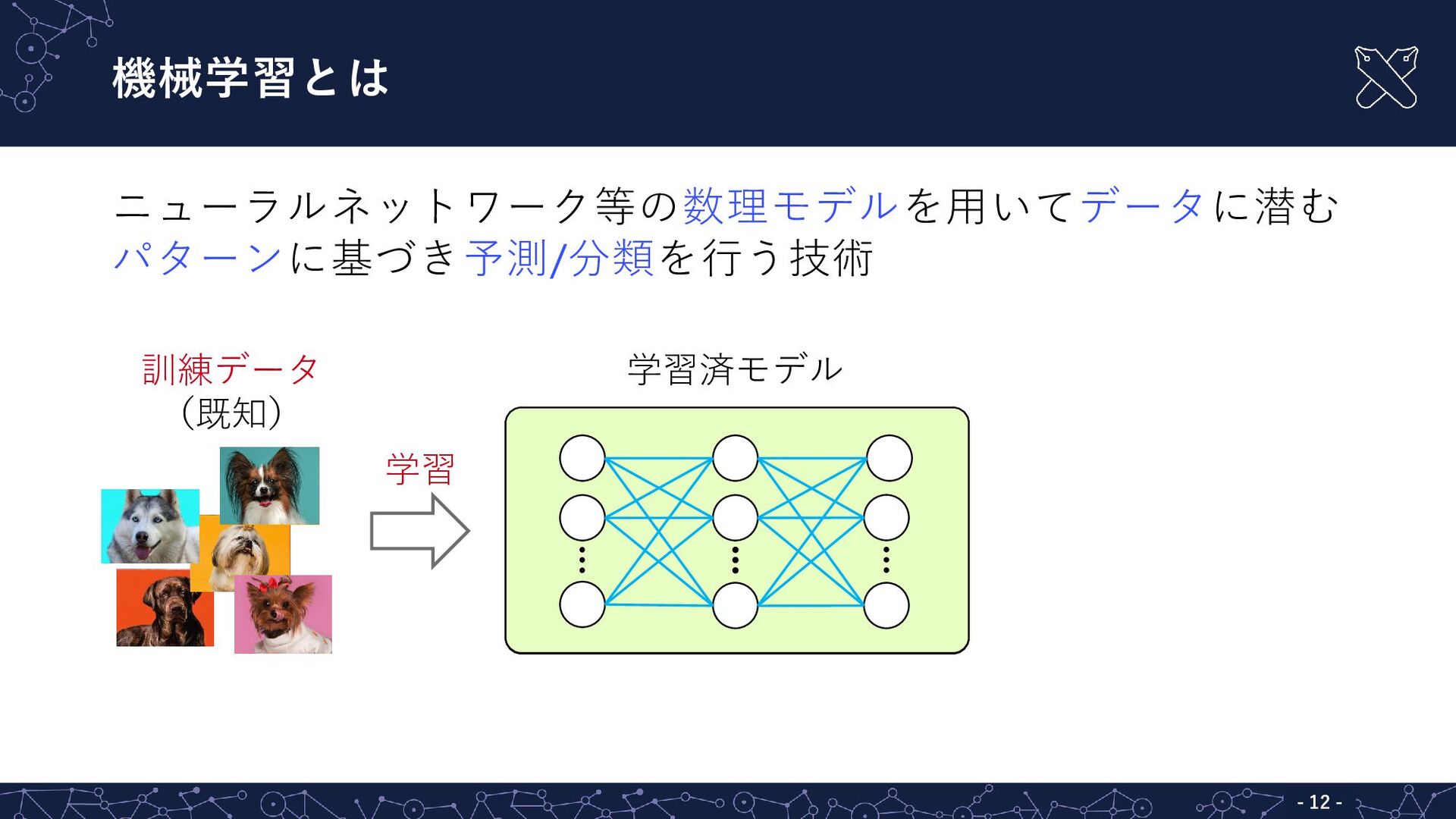{kind=link}
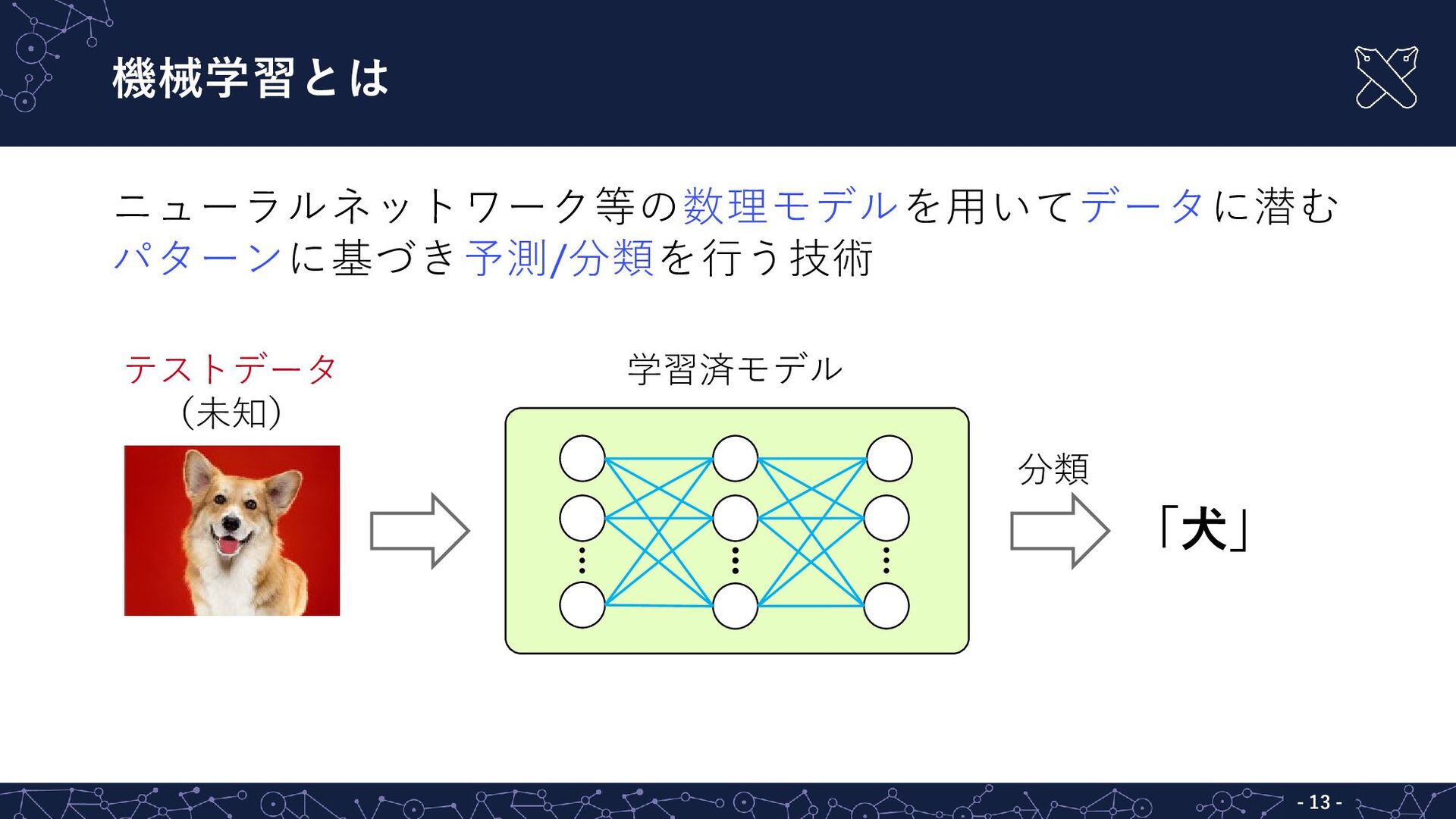{kind=link}
{kind=link}
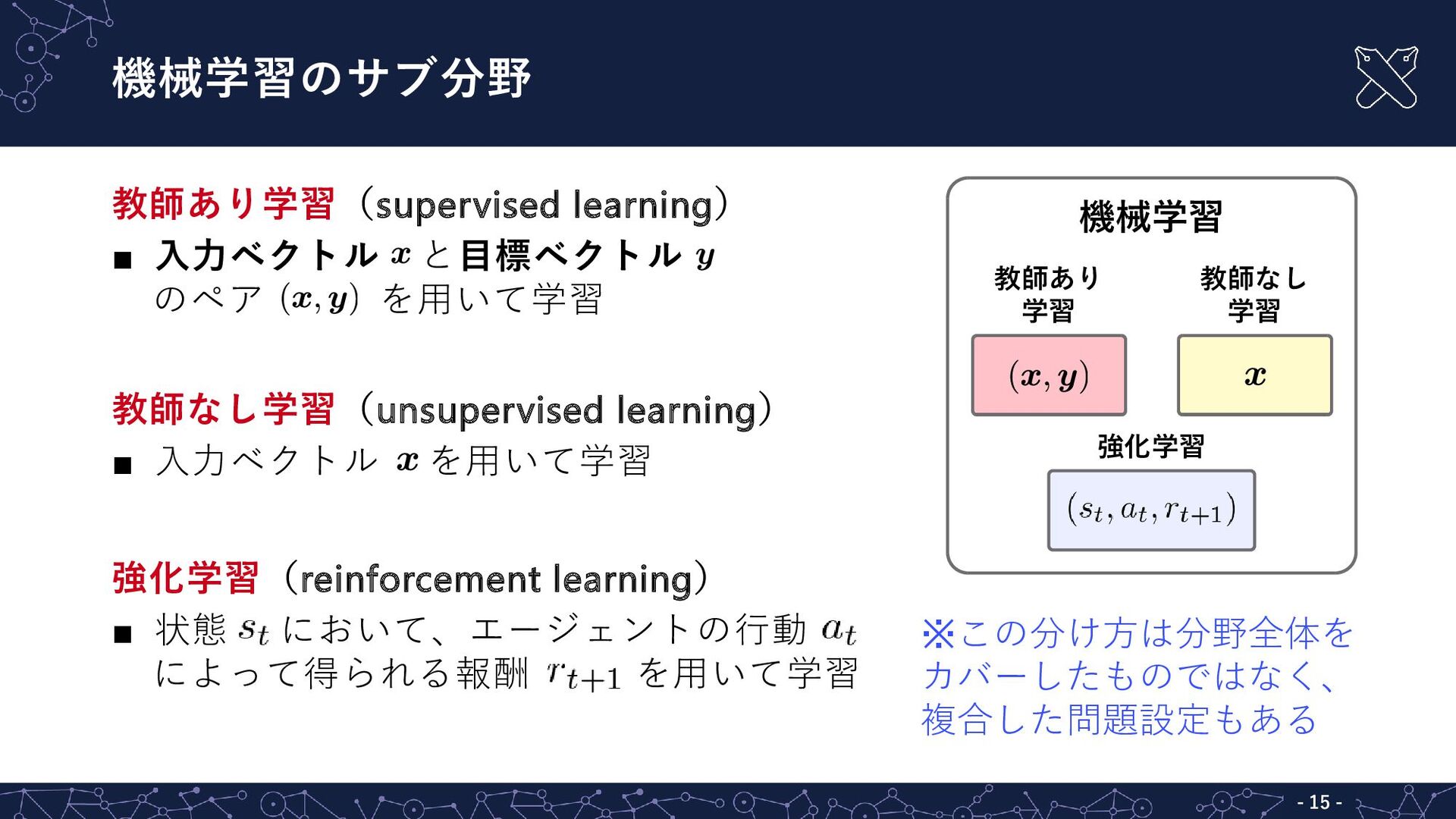{kind=link}
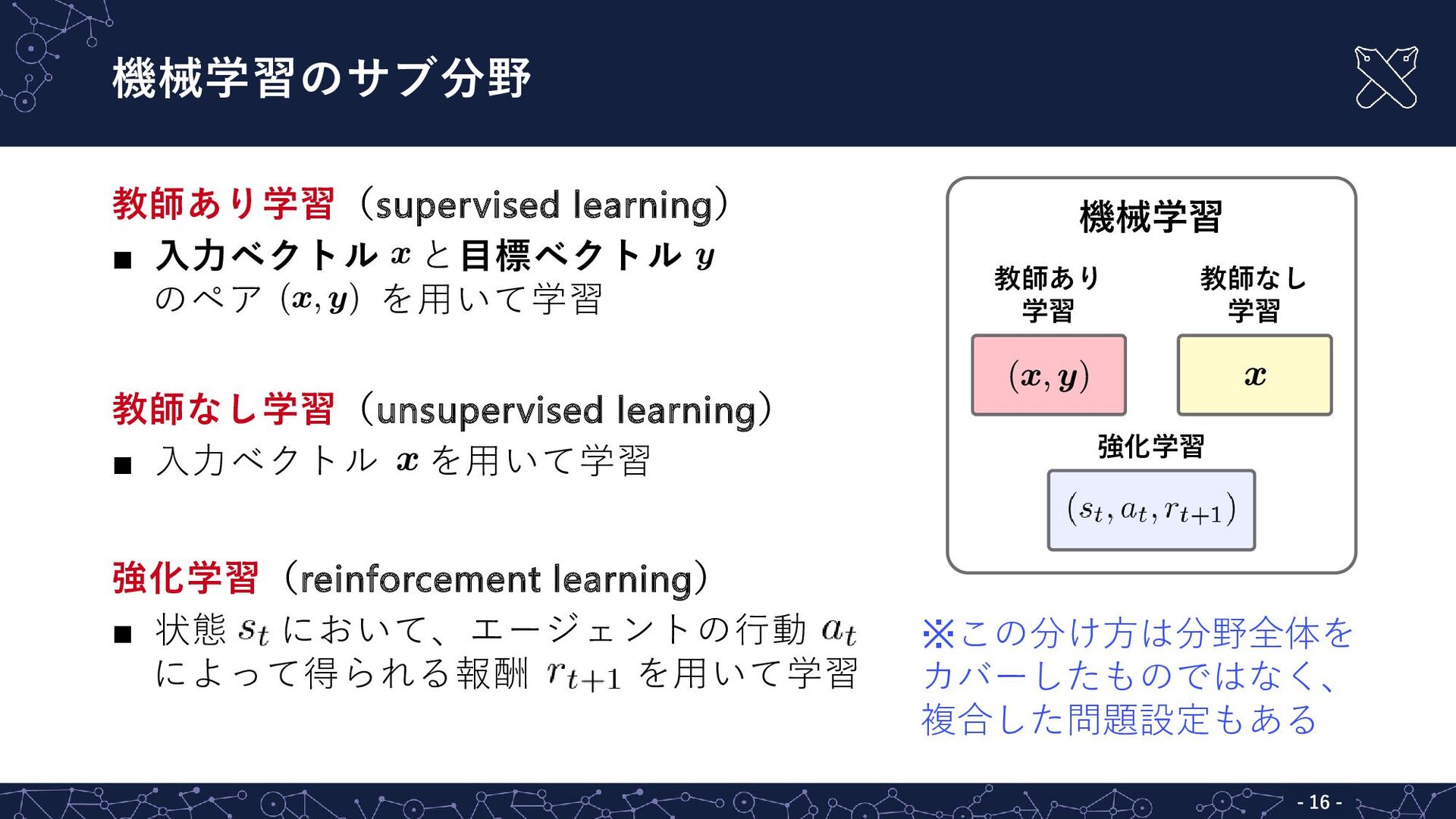{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
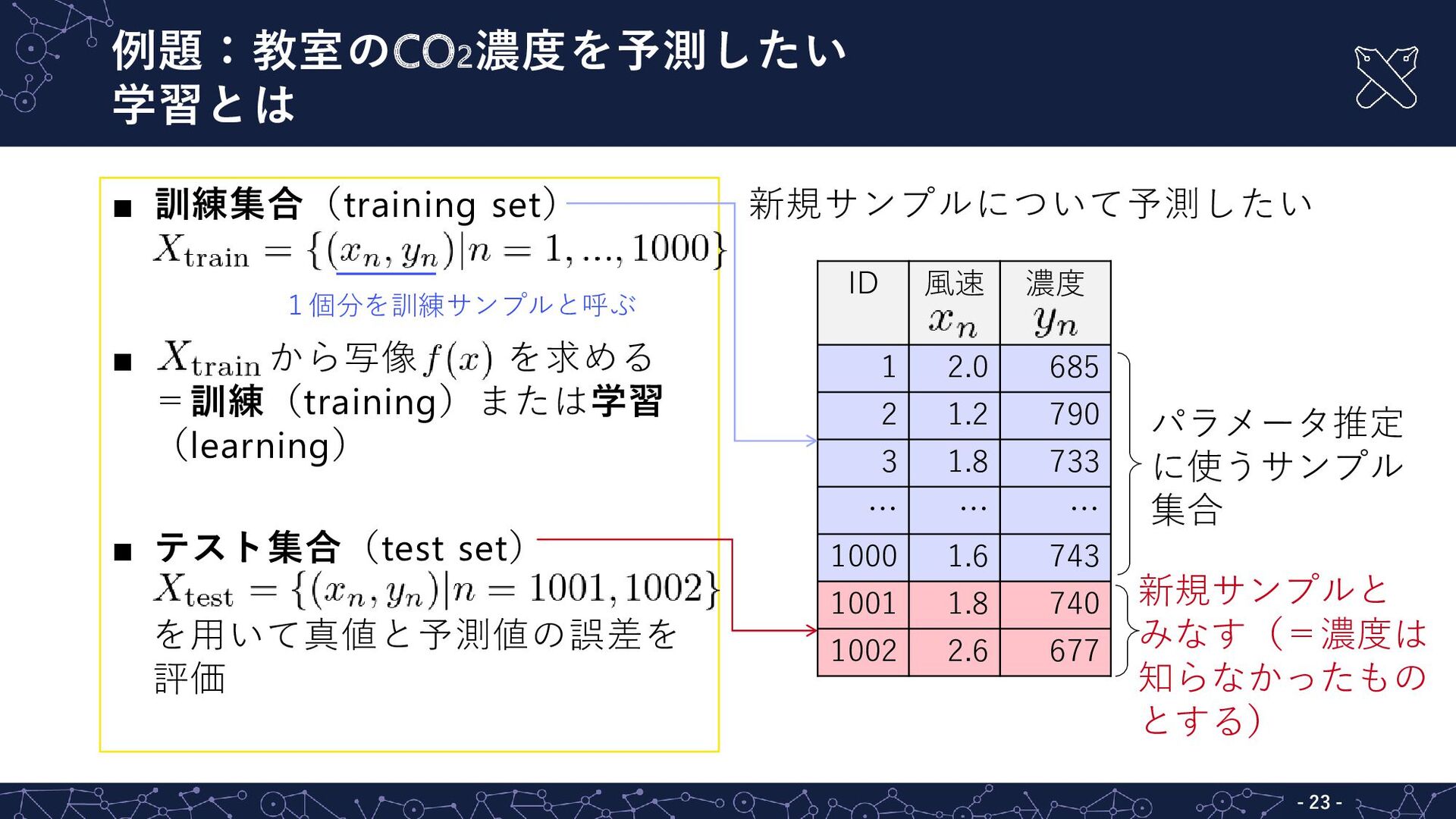{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
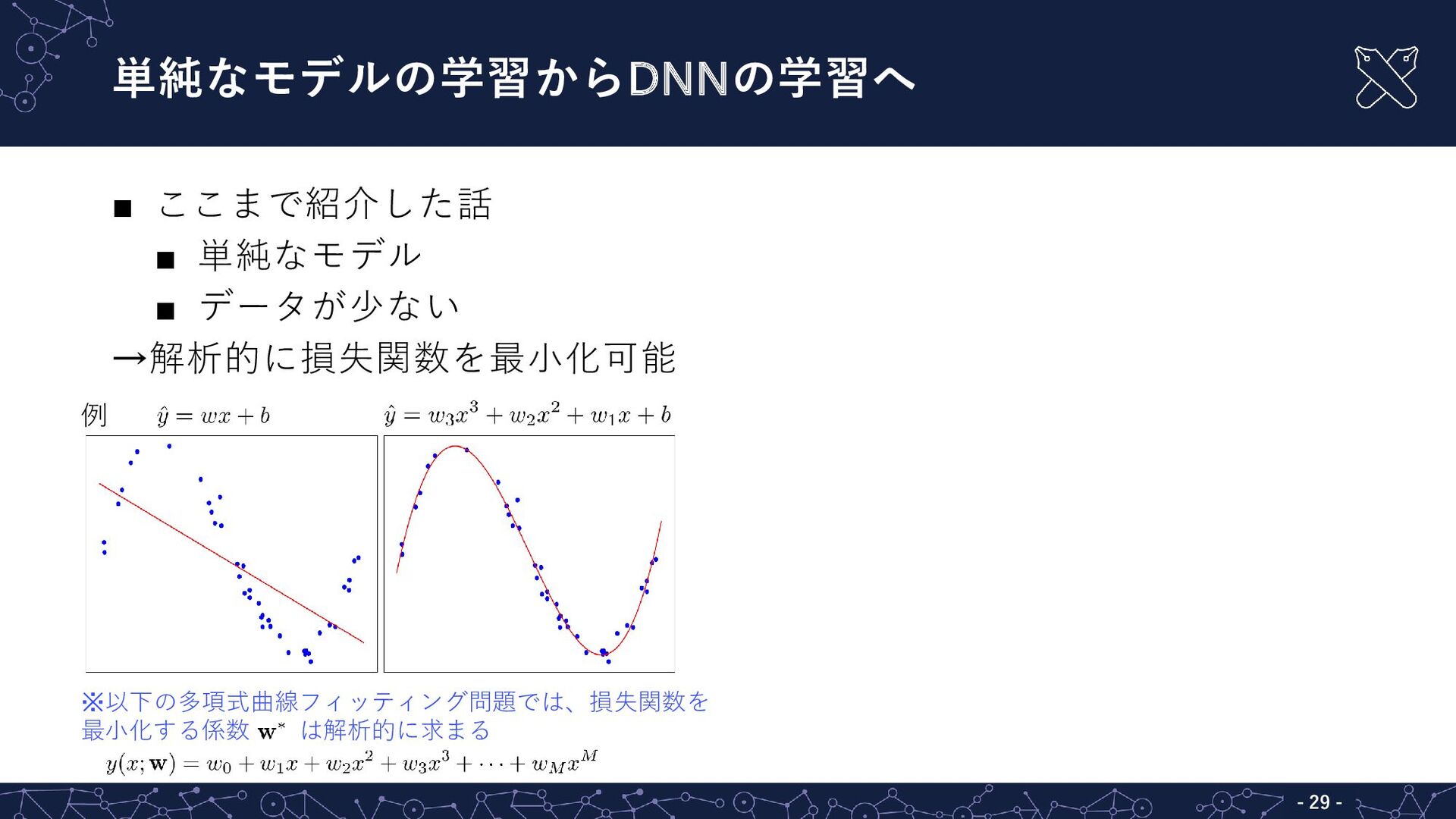{kind=link}
{kind=link}
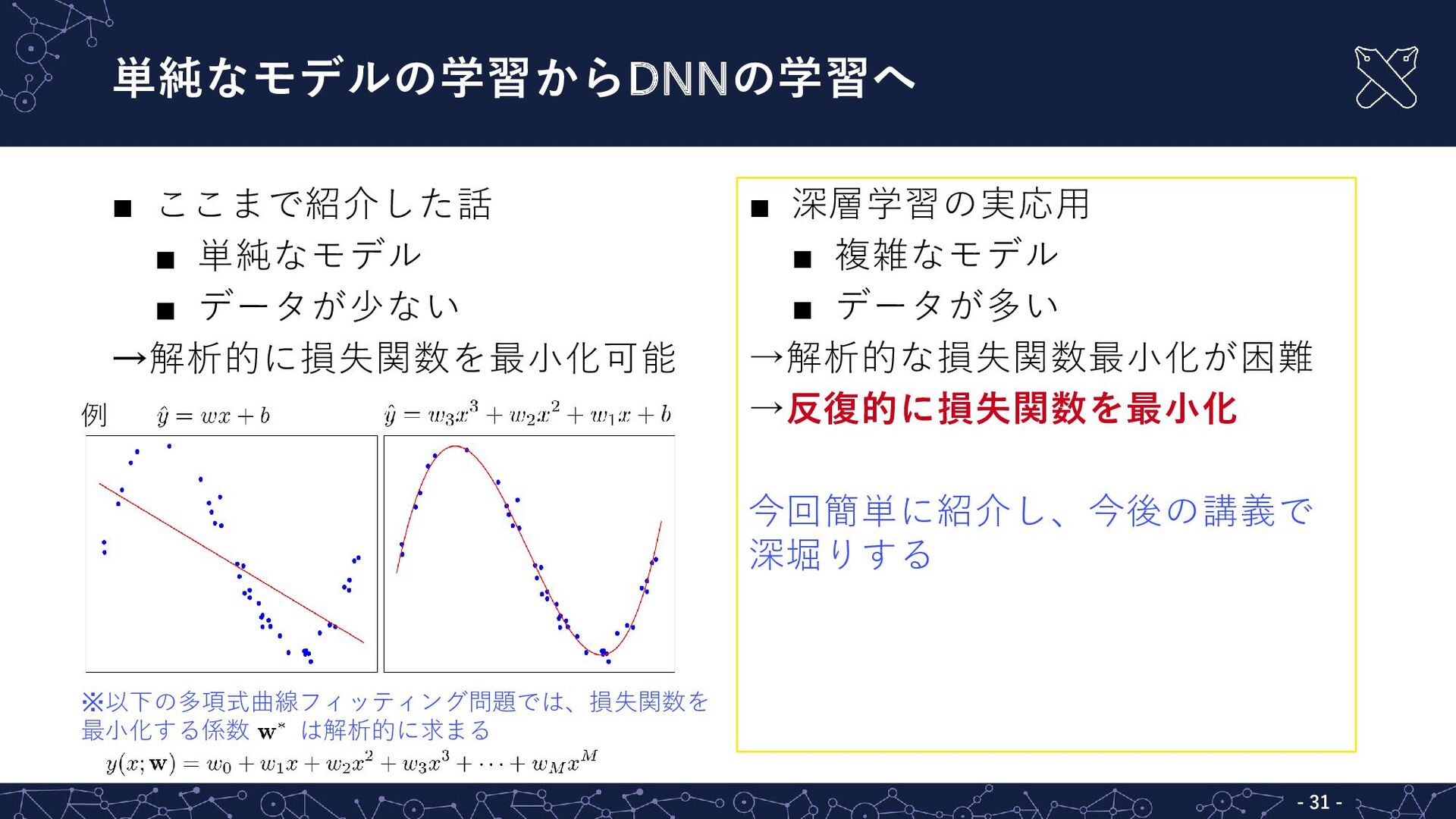{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}