↑バッチ正規化発明以前: 鋭い極小値の影響が強いため学習率を 小さくしなければならなかった ▪ 現代的なDNNではバッチ正規化(とその後継)を多用 ▪ ドロップアウトを一部代替 https://blog.google/products/search/search-language-understanding-bert/ https://www.whichfaceisreal.com/ GAN Transformer 「USA to ブラジル」 が検索上位に 「ブラジル to USA 」 が検索上位に
2. https://qiita.com/omiita/items/1735c1d048fe5f611f80 3. Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. JMLR, 12(7). 4. Zeiler, M. D. (2012). Adadelta: an adaptive learning rate method. arXiv preprint arXiv:1212.5701. 5. Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. 6. Glorot, X., & Bengio, Y. (2010). Understanding the difficulty of training deep feedforward neural networks. In Proc. AISTATS (pp. 249-256). 7. He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proc. IEEE ICCV (pp. 1026-1034).
![情報工学科 教授 杉浦孔明 [email protected] 慶應義塾大学理工学部 機械学習基礎 第5回 最適化](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
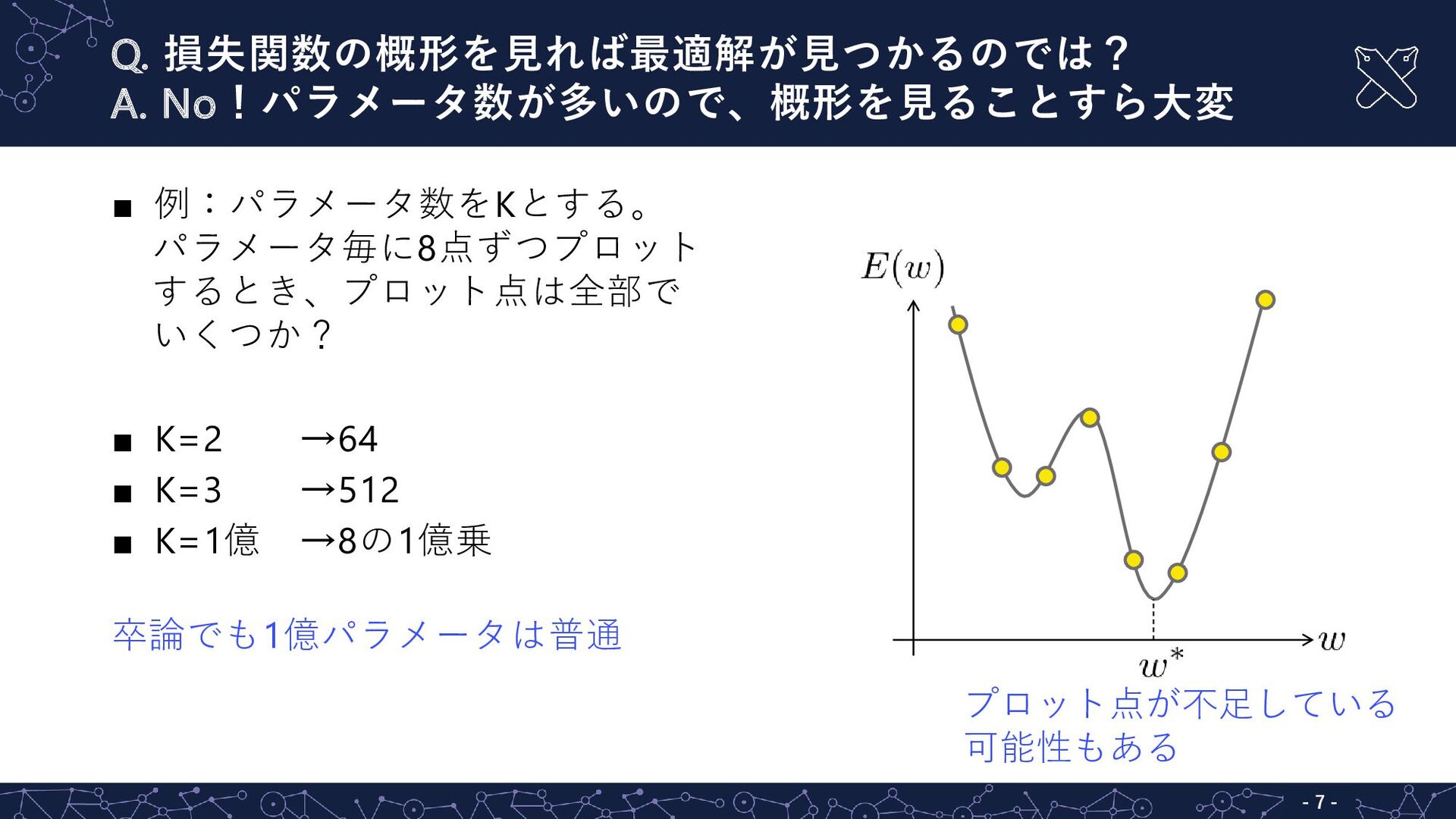{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
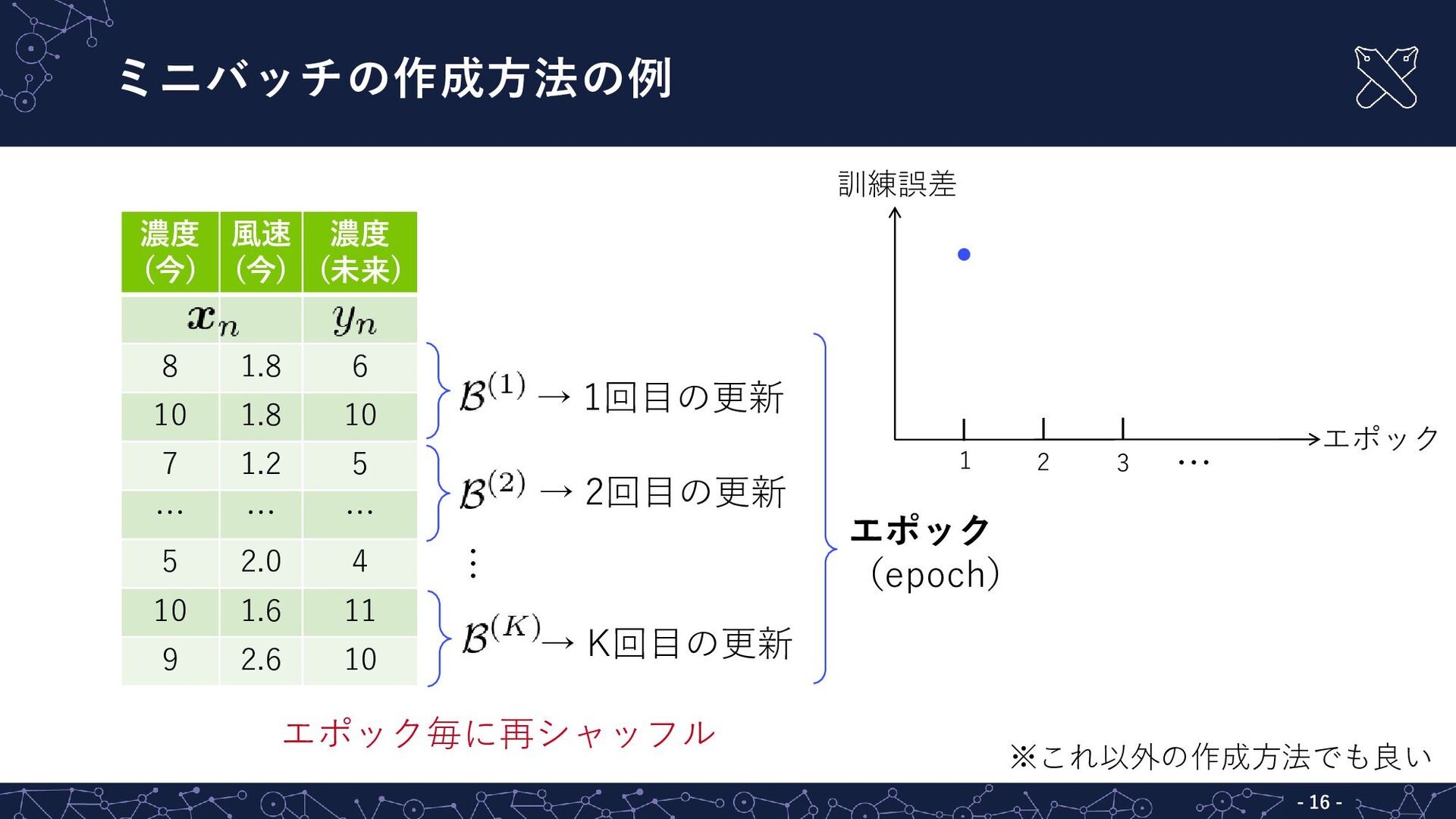{kind=link}
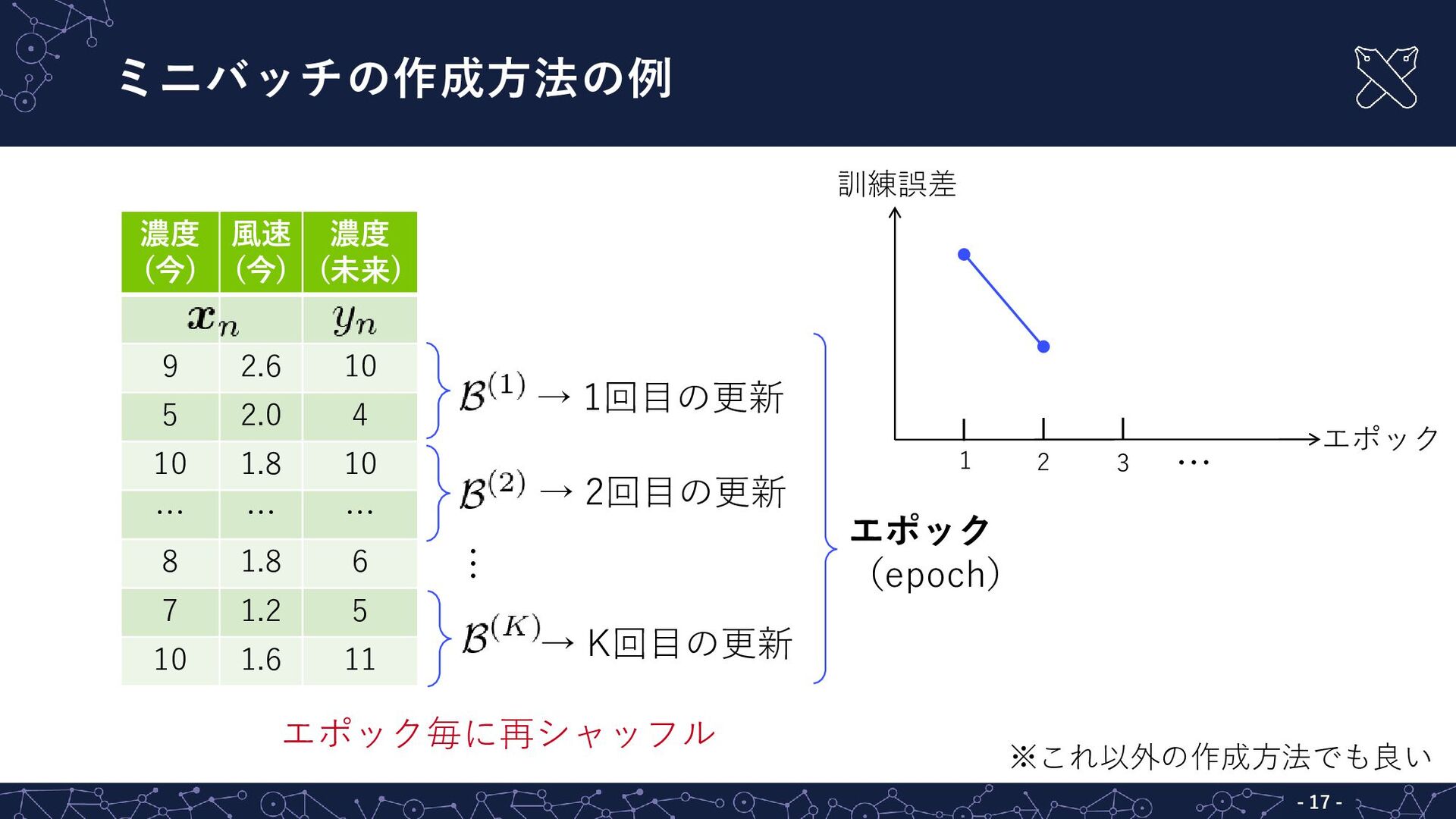{kind=link}
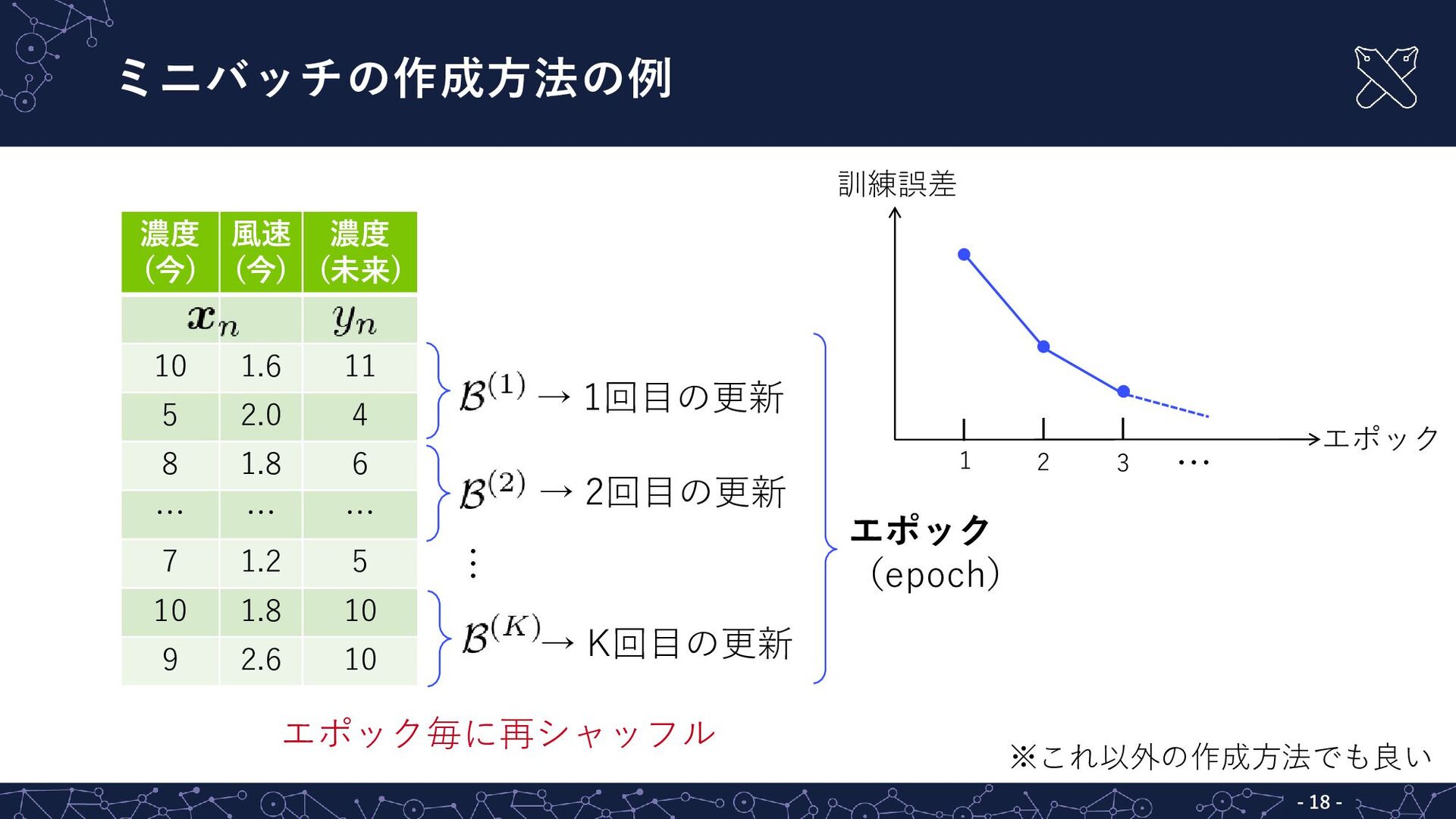{kind=link}
{kind=link}
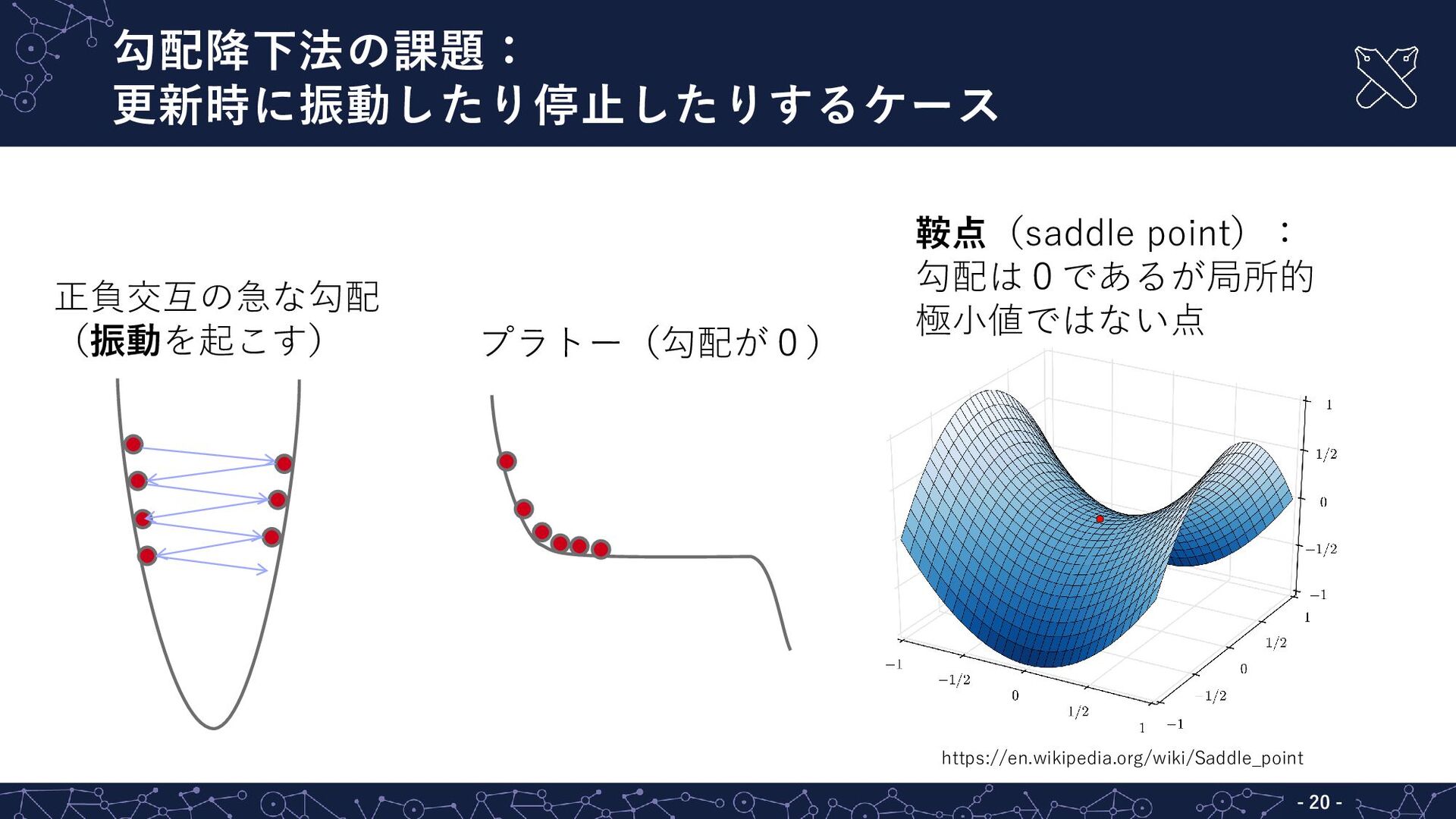{kind=link}
{kind=link}
{kind=link}
![AdaGrad [Duchi+ 2011] 背景 - - 23 ▪ 背景 ▪](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_22.jpg){kind=link}
![AdaGrad [Duchi+ 2011] 更新則 - - 24 ▪ AdaGradの更新則 初期値](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_23.jpg){kind=link}
![AdaGrad [Duchi+ 2011] 欠点 - - 25 ▪ 学習の初期に勾配が大きいと、 急激に](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_24.jpg){kind=link}
{kind=link}
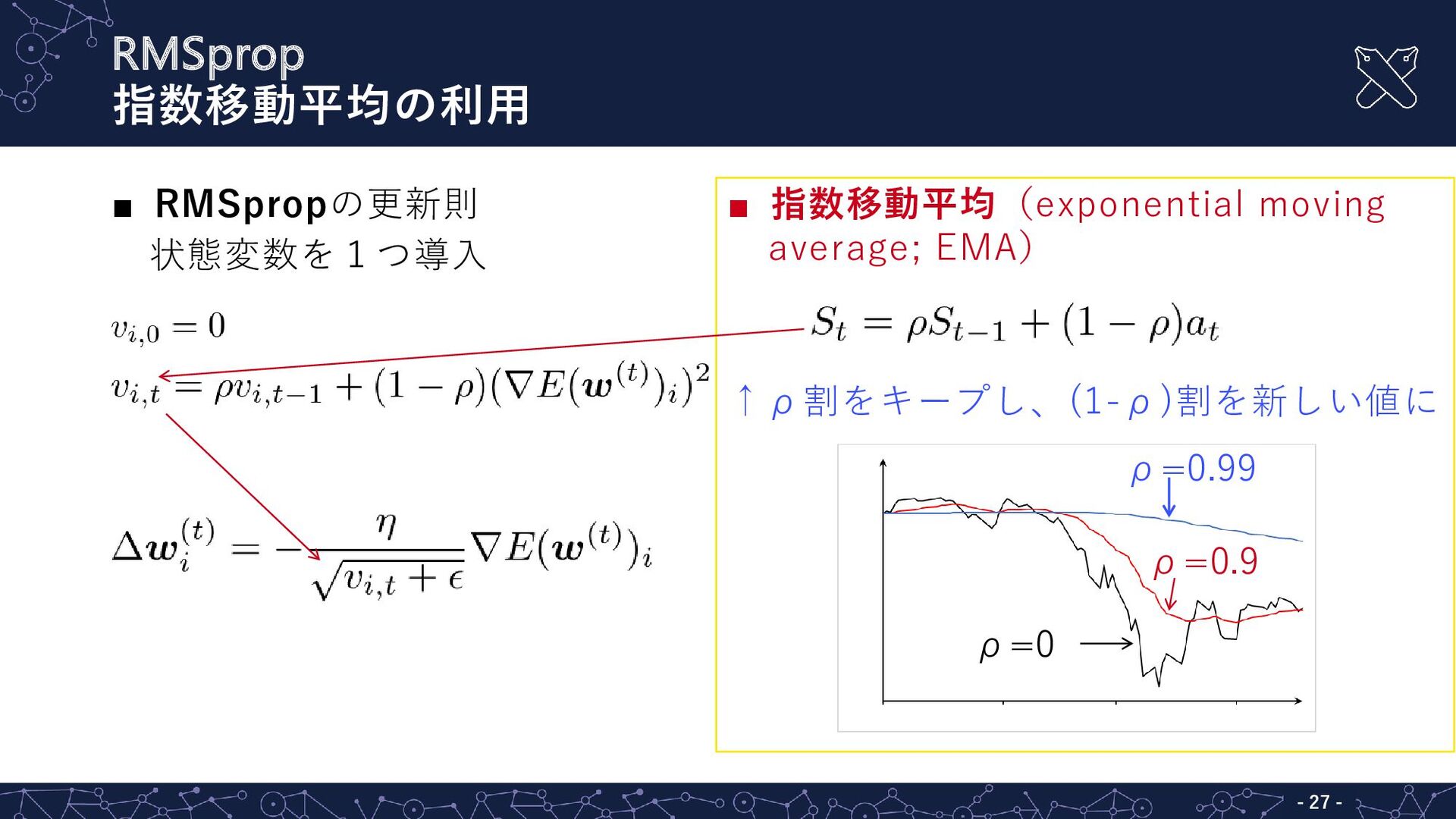{kind=link}
{kind=link}
![AdaDelta [Zeiler 2012] 更新則 - - 29 ▪ RMSpropの更新則 状態変数を1つ導入](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_28.jpg){kind=link}
![AdaDelta [Zeiler 2012] RMSpropとの相違点 - - 30 ▪ 分子 ▪](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_29.jpg){kind=link}
![Adam [Kingma+ 2014] 特徴 - - 31 ▪ 現時点で、深層学習において 最も広く使われている](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_30.jpg){kind=link}
![Adam [Kingma+ 2014] 相違点 - - 32 ▪ Adam ▪](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_31.jpg){kind=link}
![Adam [Kingma+ 2014] 更新則 - - 33 ▪ Adam ▪](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_32.jpg){kind=link}
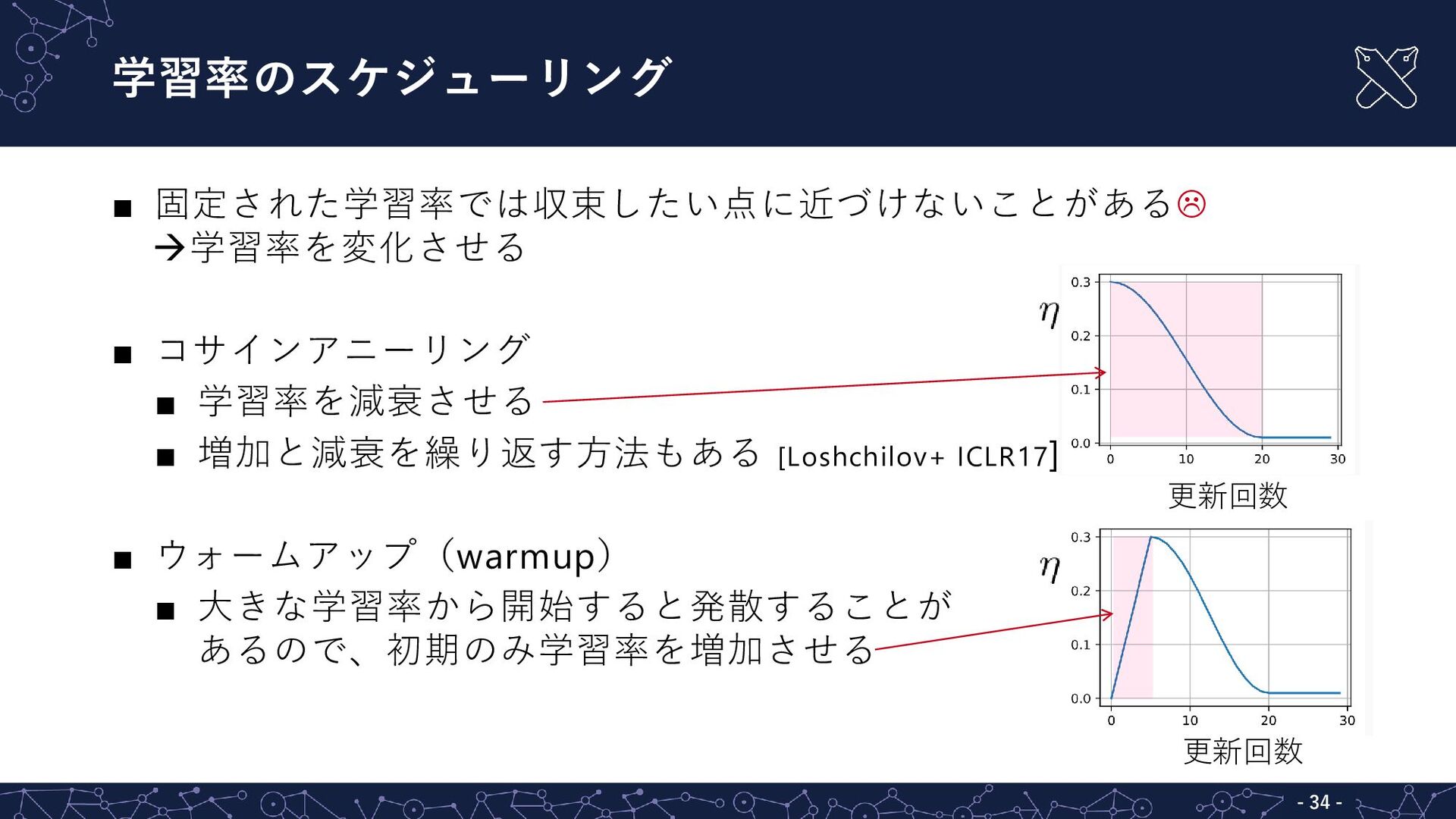{kind=link}
{kind=link}
{kind=link}
{kind=link}
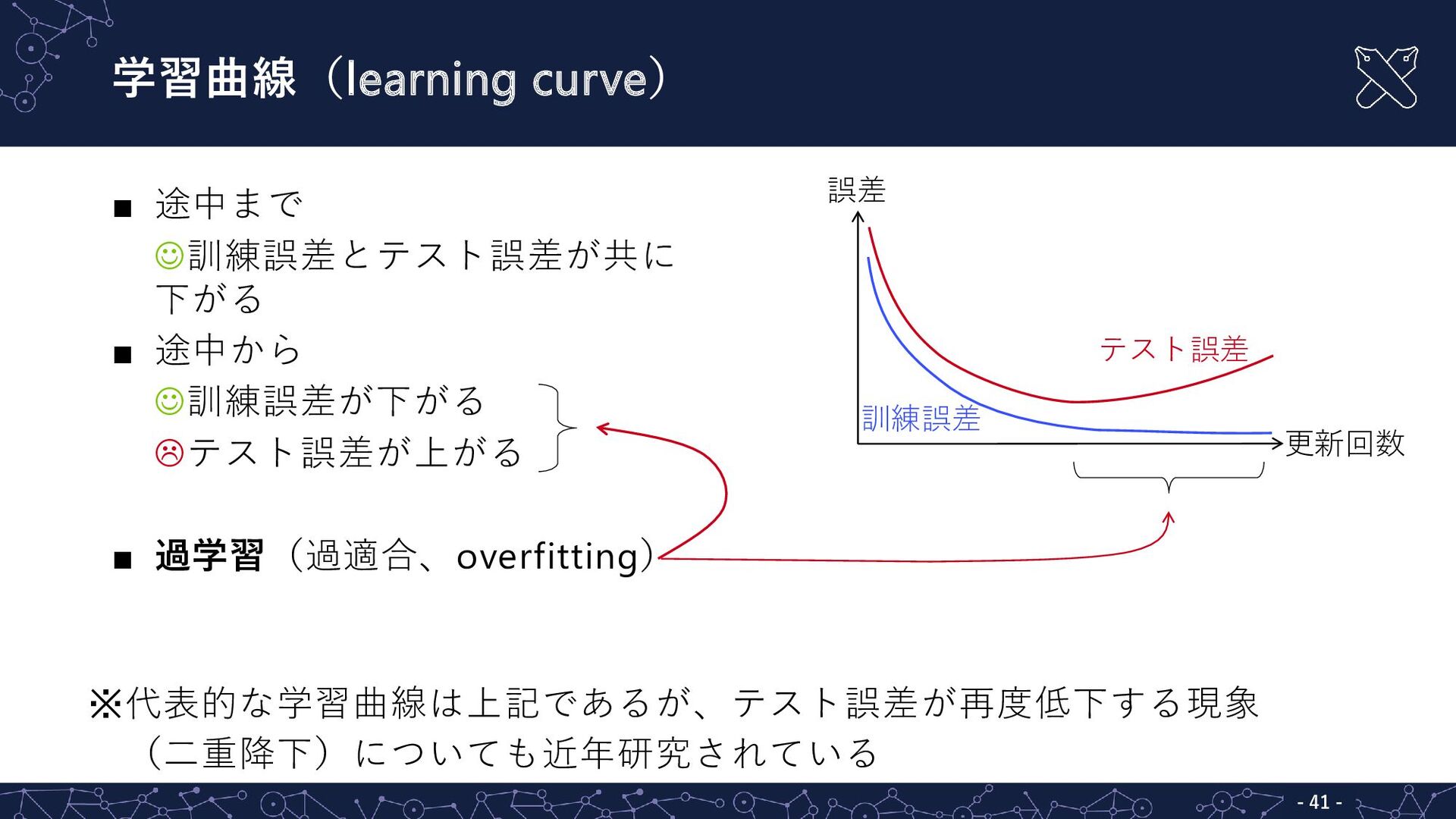{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![★ドロップアウト(dropout) [Srivastava+ 2014] - - 47 ▪ ユニット出力を確率 で0にする ▪](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_43.jpg){kind=link}
![★バッチ正規化(batch normalization) [Ioffe+ 2015] - - 48 ▪ 効果: 学習を安定化させる](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![パラメータの初期値 Xavierの初期化 [Glorot+ 2010] - - 57 ▪ Xavierの初期化 (Xavier](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_53.jpg){kind=link}
![パラメータの初期値 Heの初期化 [He+ 2015] - - 58 ▪ Heの初期化 (He](https://files.speakerdeck.com/presentations/98a304b294364a6eb030b4908fac8432/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}