J. (1991). Creating artificial neural networks that generalize. Neural networks, 4(1), 67-79. 2. Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1), 1929-1958. 3. Ioffe, S., & Szegedy, C. (2015, June). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning (pp. 448- 456). PMLR.
![情報工学科 教授 杉浦孔明 [email protected] 慶應義塾大学理工学部 機械学習基礎 第6回 誤差逆伝播法](https://files.speakerdeck.com/presentations/61b76cd967ea44938577870eed1f81de/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
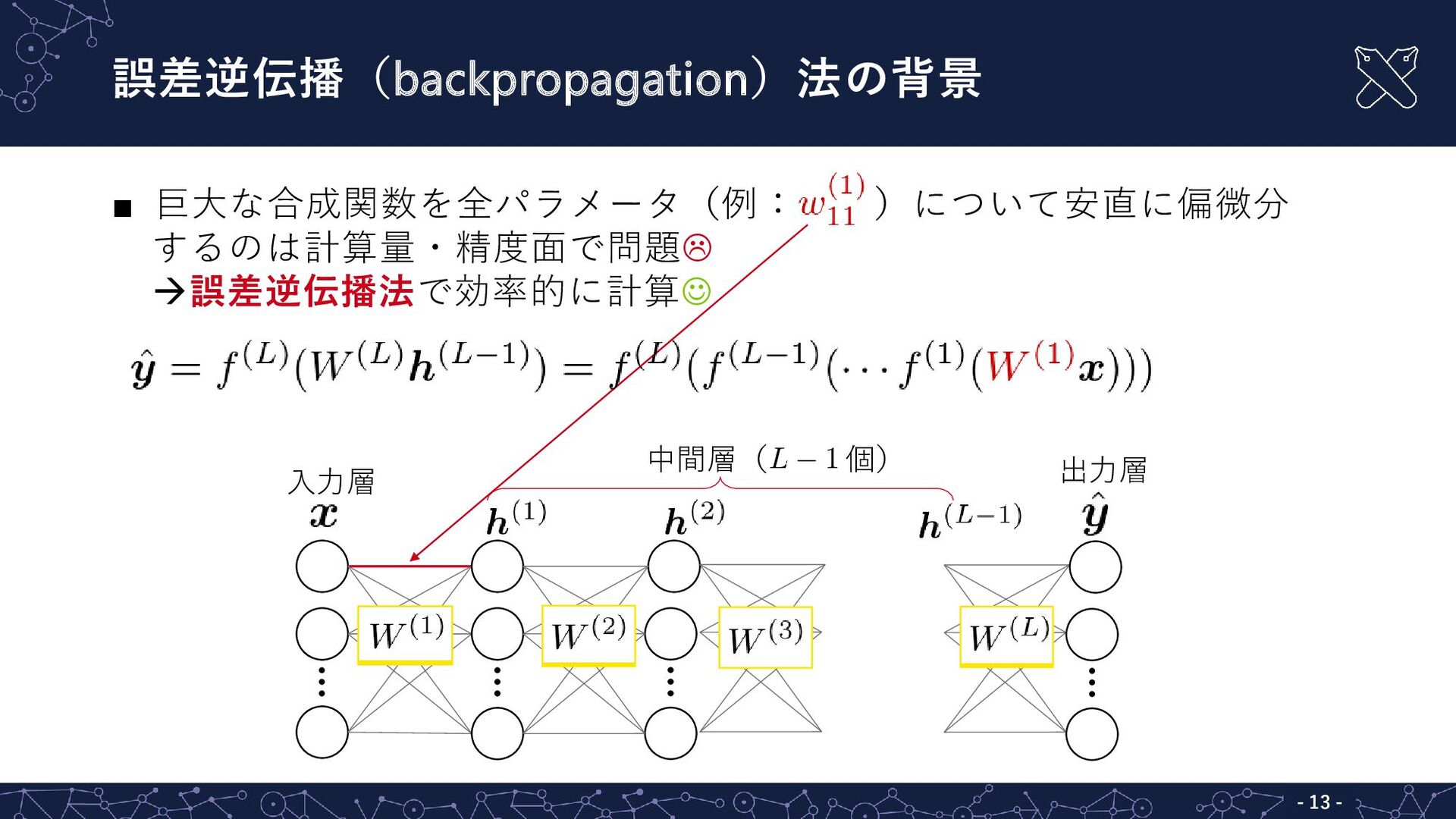{kind=link}
{kind=link}
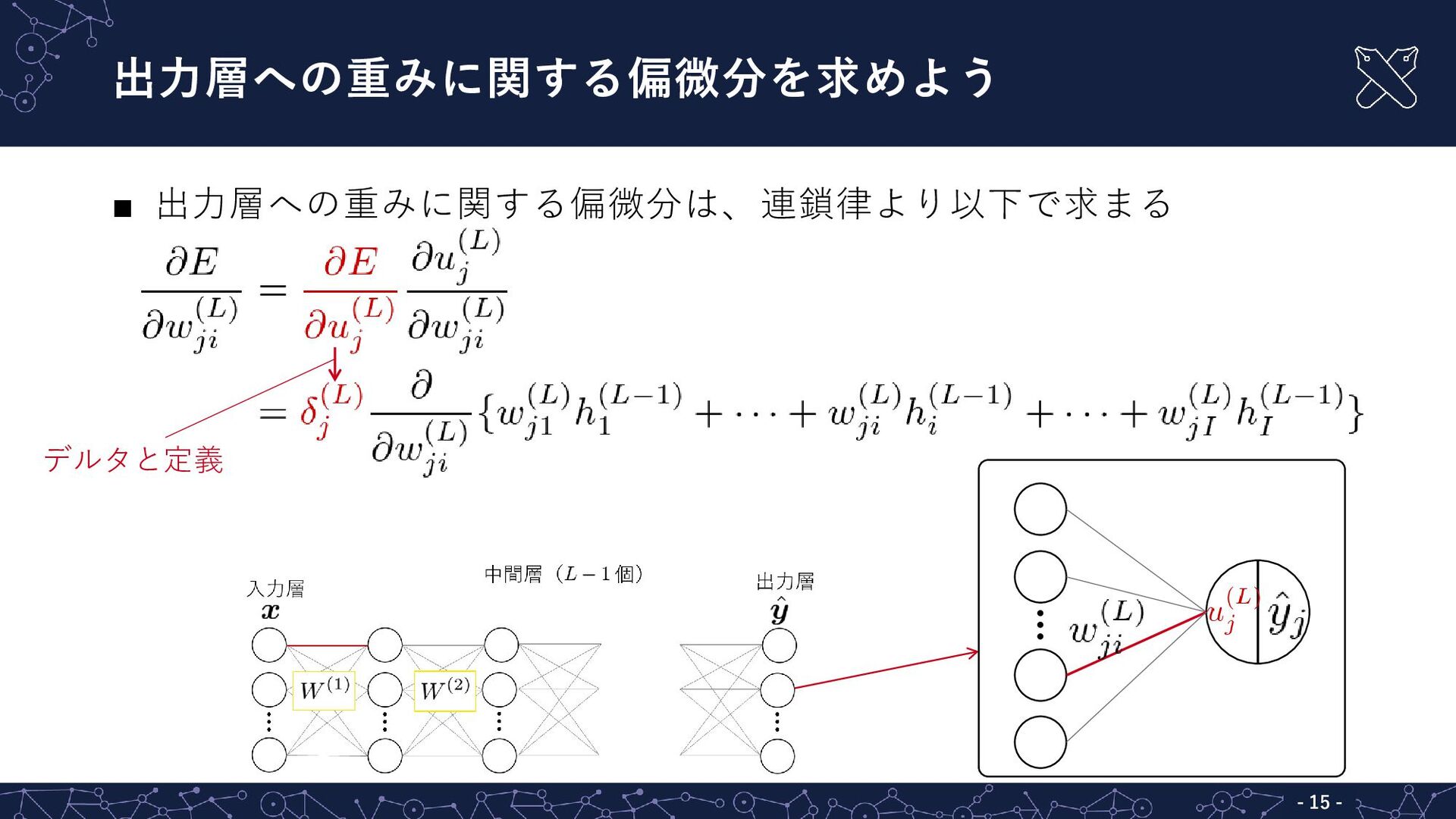{kind=link}
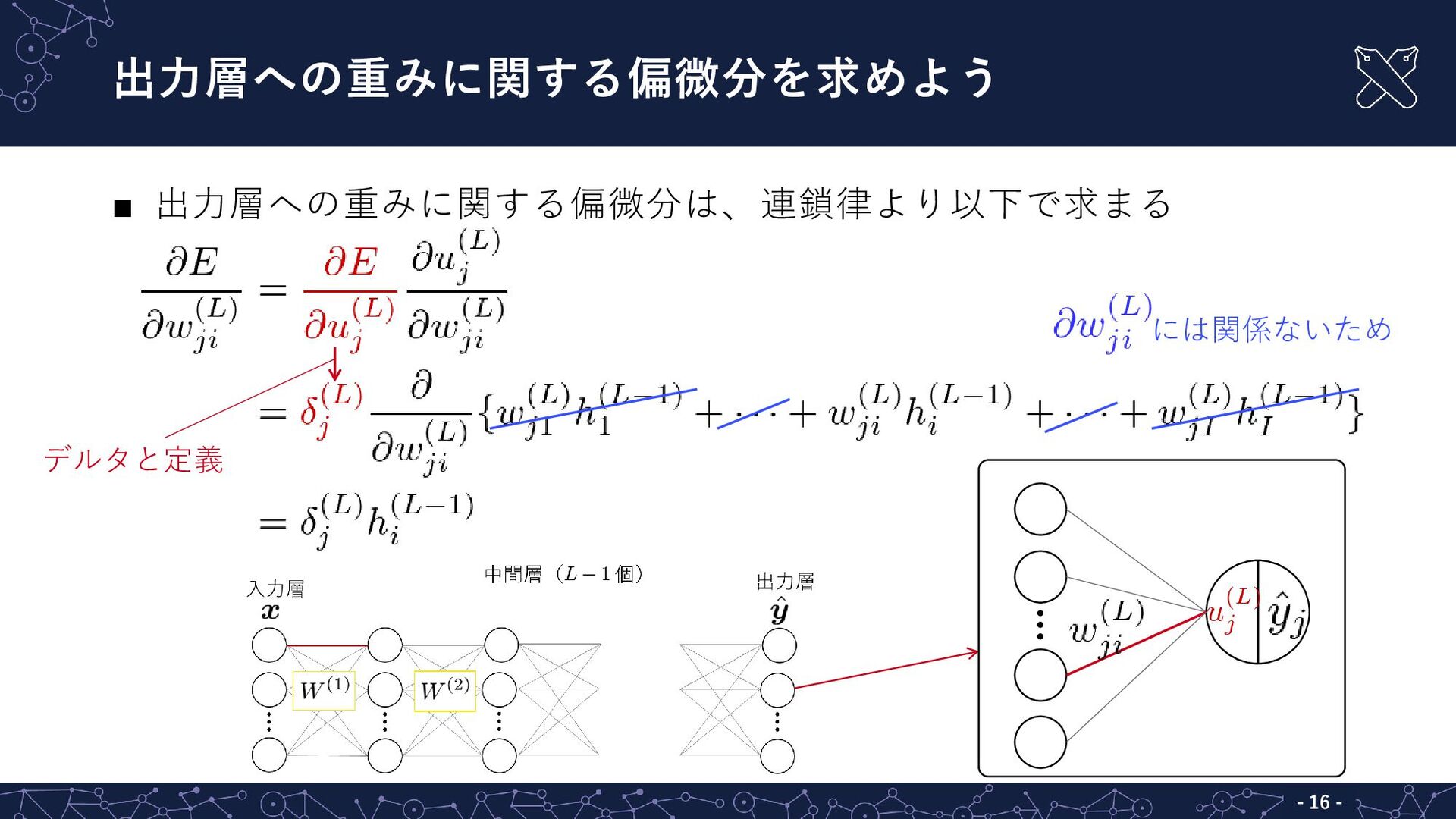{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
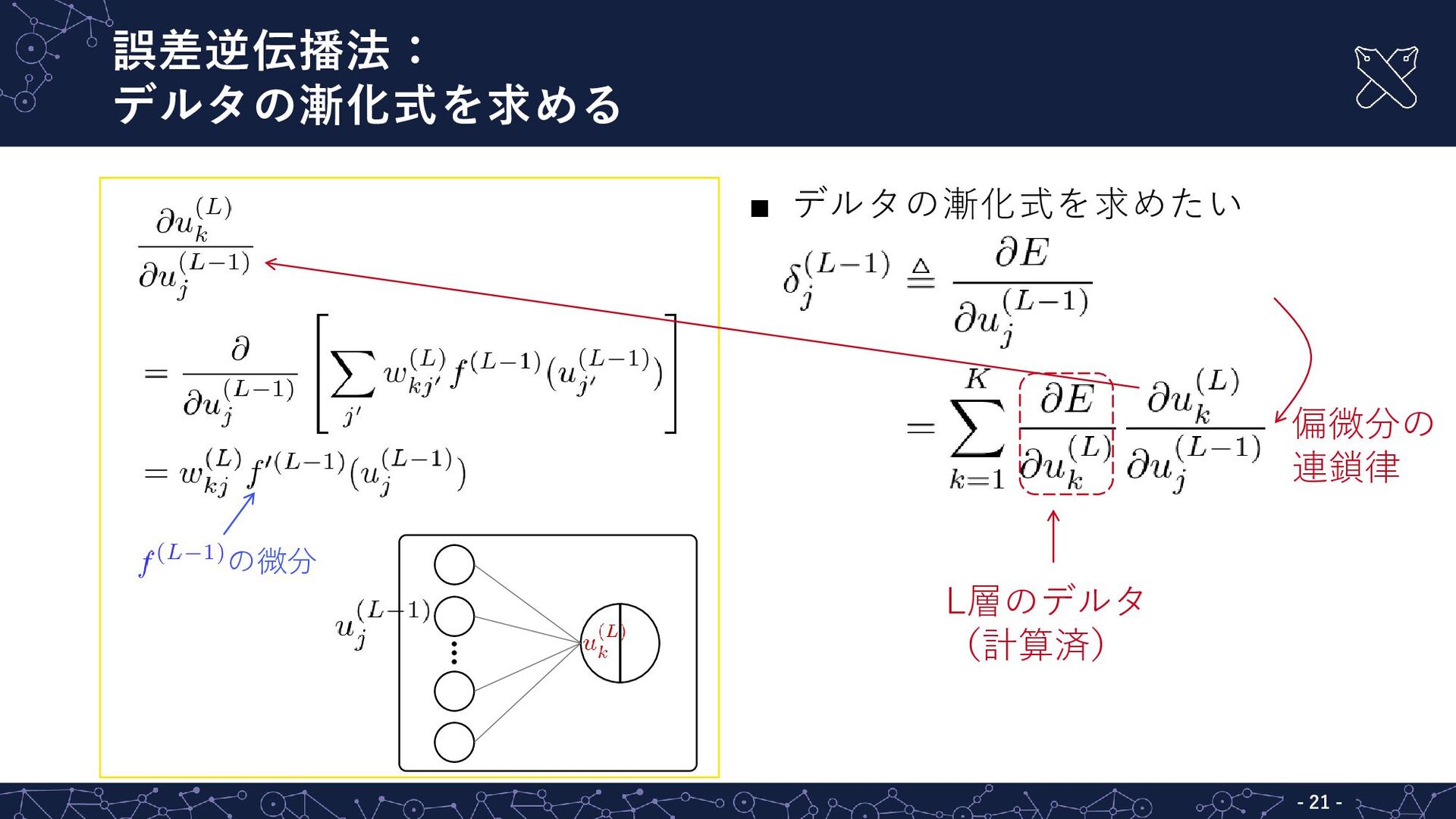{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![★残差接続(residual connection)[He+ 2016] - - 29 ▪ 層を迂回する近道を設ける接続方法 ▪ 効果:](https://files.speakerdeck.com/presentations/61b76cd967ea44938577870eed1f81de/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
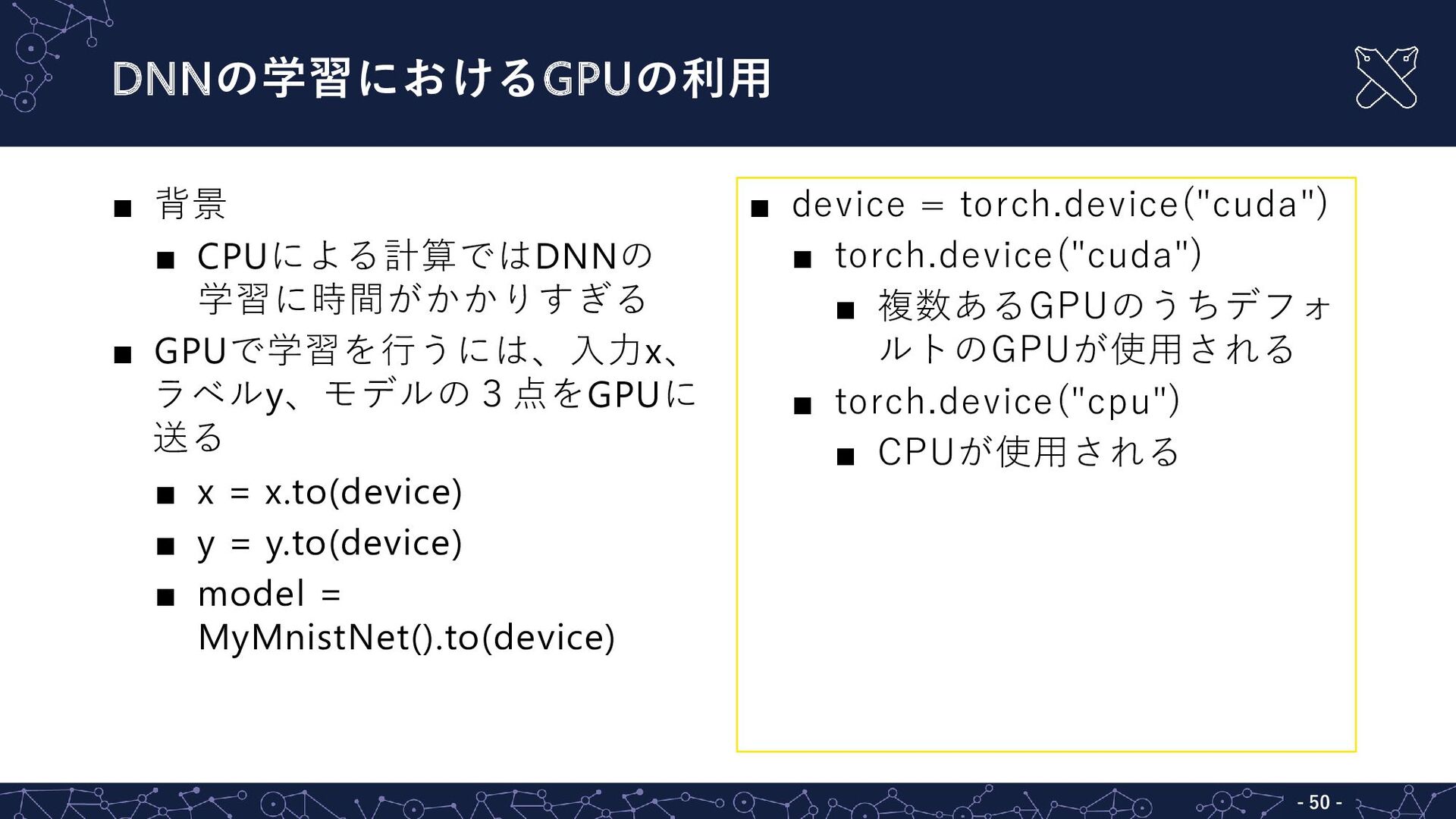{kind=link}