F. (2017). Deep Learning with Python. MANNING. 4. Lecun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), pp. 2278– 2324. 5. Krizhevsky, A., Sutskever, I., & Hinton, G. (2012). ImageNet Classification with Deep Convolutional Neural Networks. In Proc. NIPS, pp. 1097–1105. 6. Simonyan, K. & Zisserman, A. (2015). Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proc. ICLR, pp. 1–14. 7. Szegedy, C. et al. (2015). Going Deeper with Convolutions. In Proc. CVPR, pp. 1–9. 8. He, K., Zhang, X., Ren, S. & Sun, J. (2016). Deep Residual Learning for Image Recognition. In Proc. CVPR, pp. 770–778.
![情報工学科 教授 杉浦孔明 [email protected] 慶應義塾大学理工学部 機械学習基礎 第7回 畳み込みニューラルネット](https://files.speakerdeck.com/presentations/8ef35977439b47bcb58f88a004912a86/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
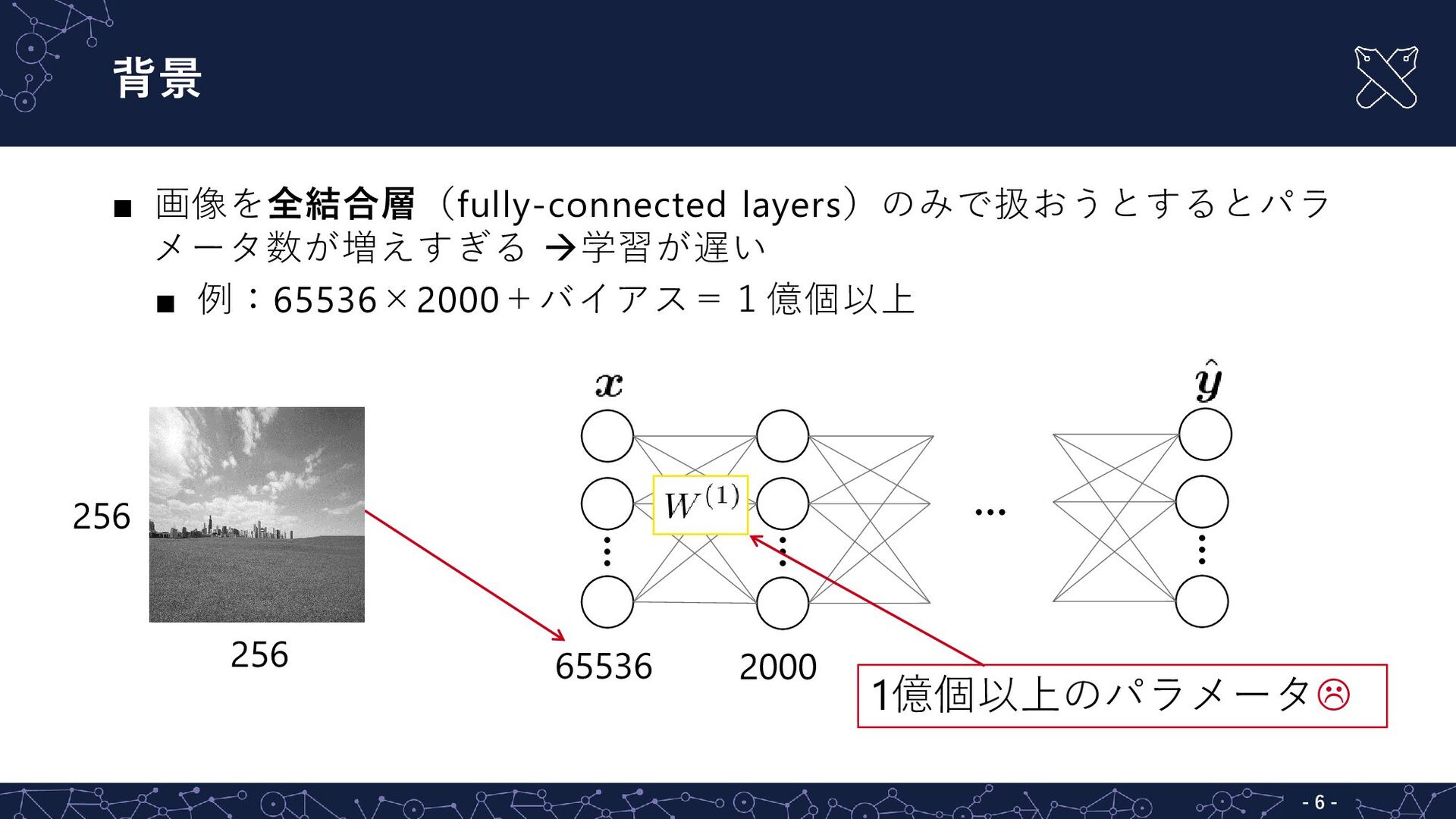{kind=link}
{kind=link}
{kind=link}
{kind=link}
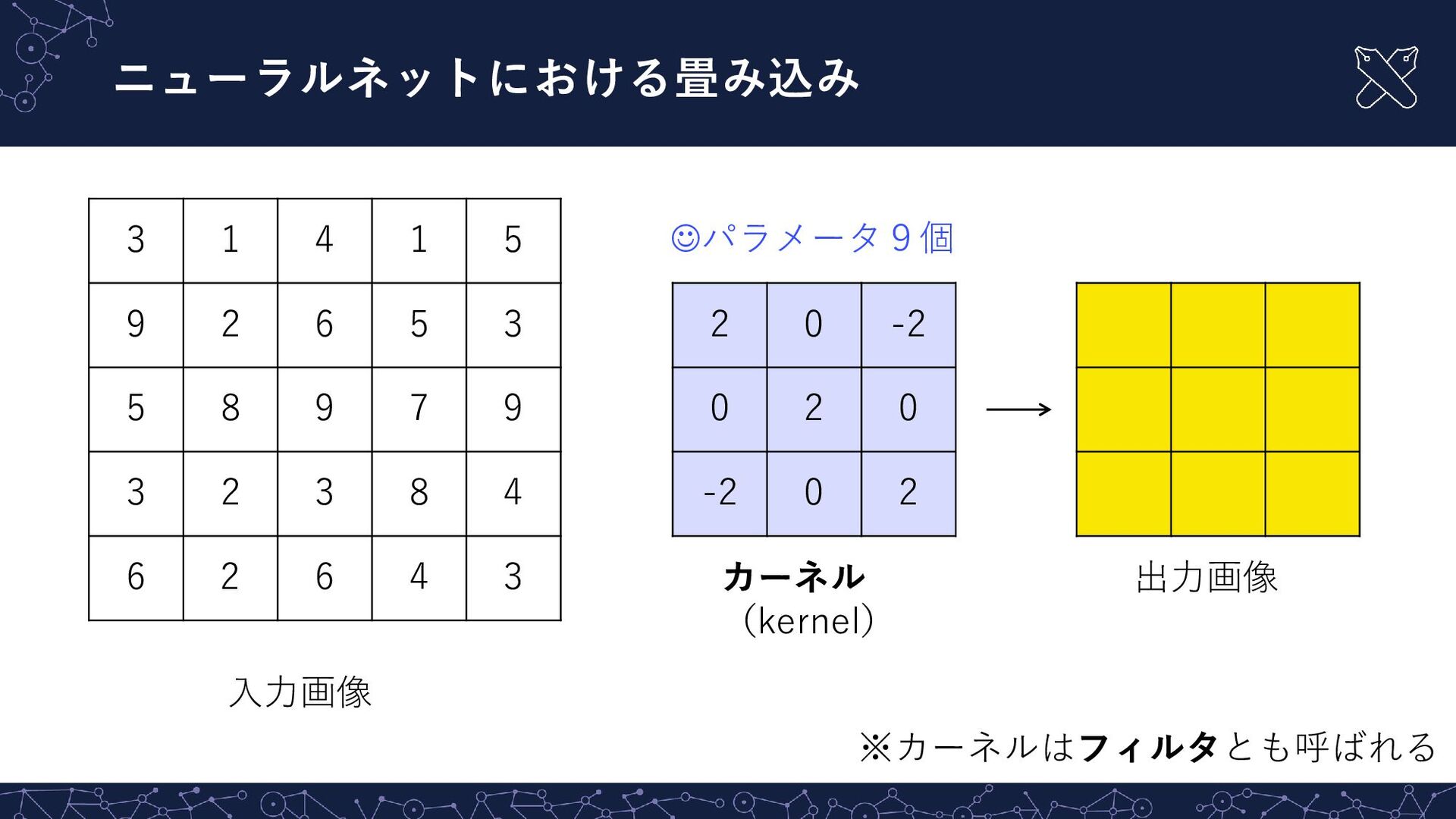{kind=link}
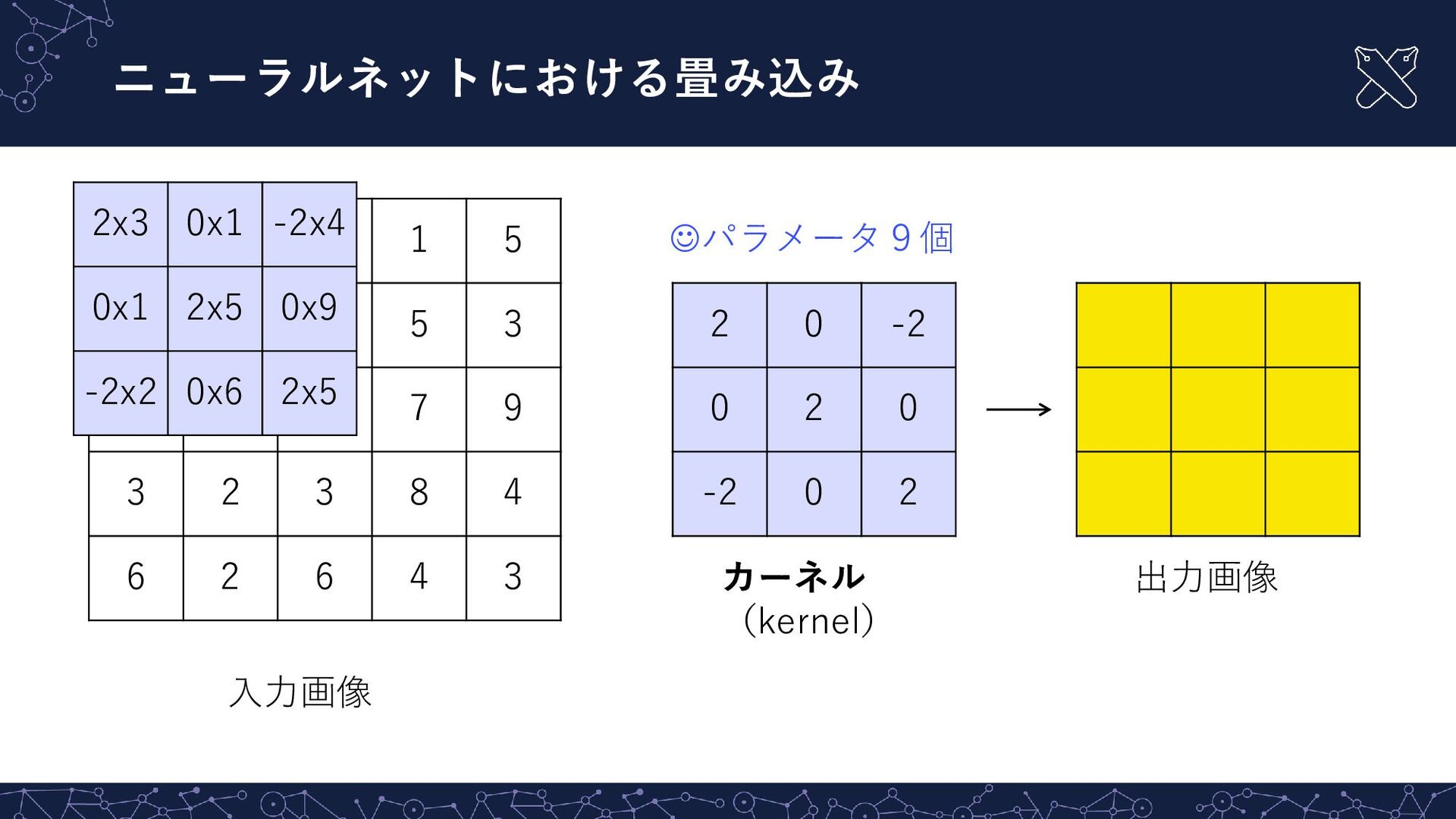{kind=link}
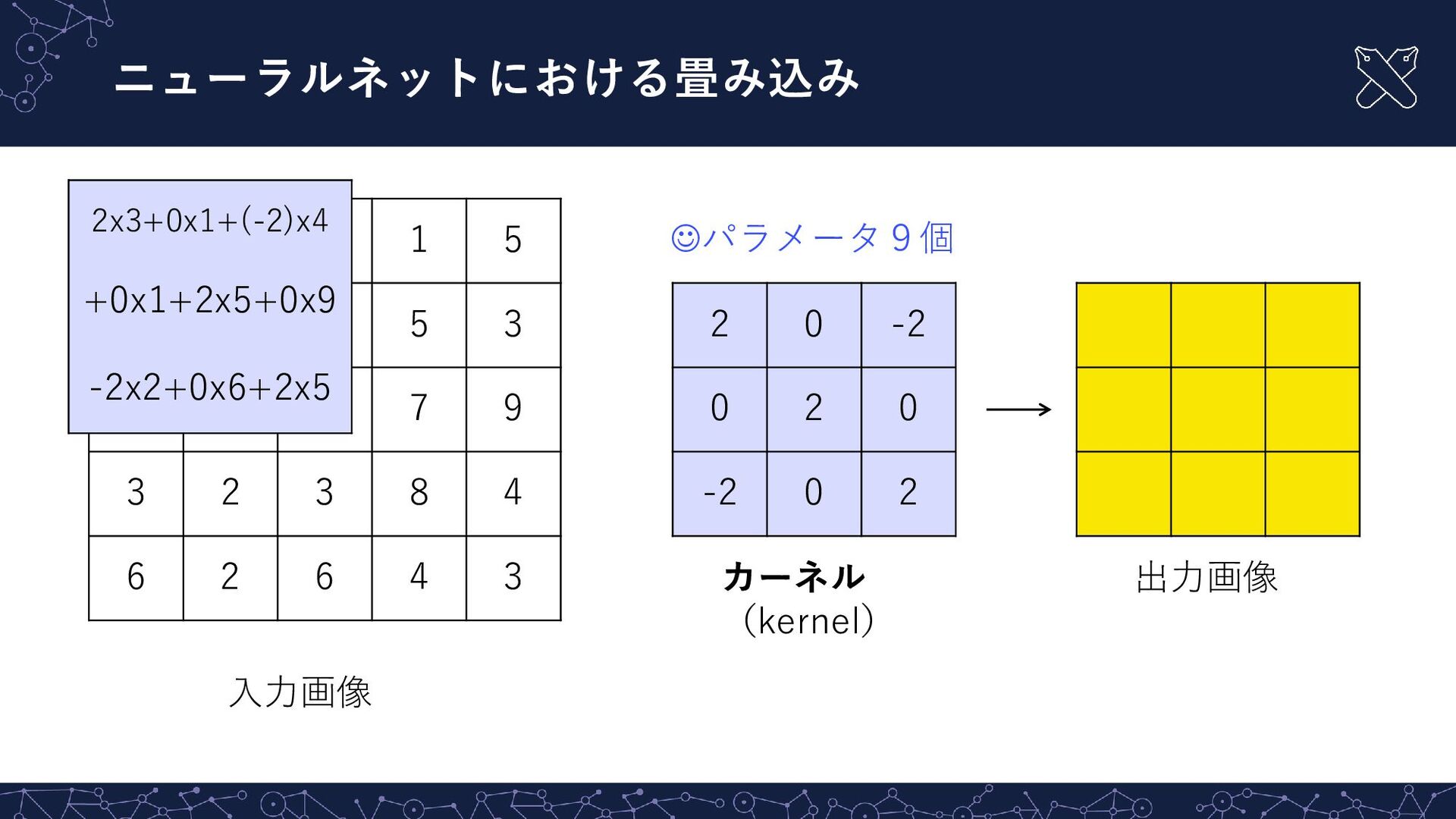{kind=link}
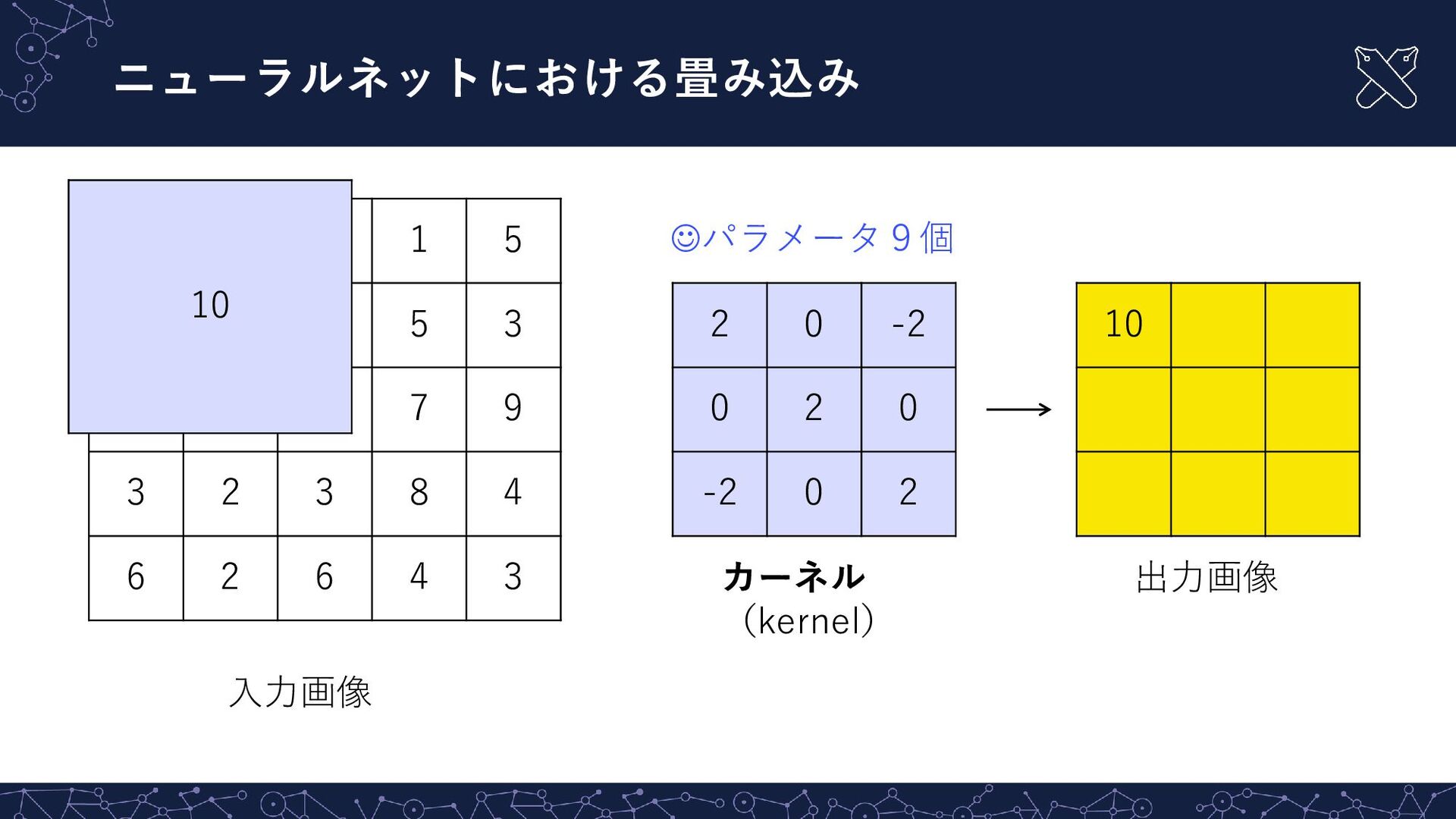{kind=link}
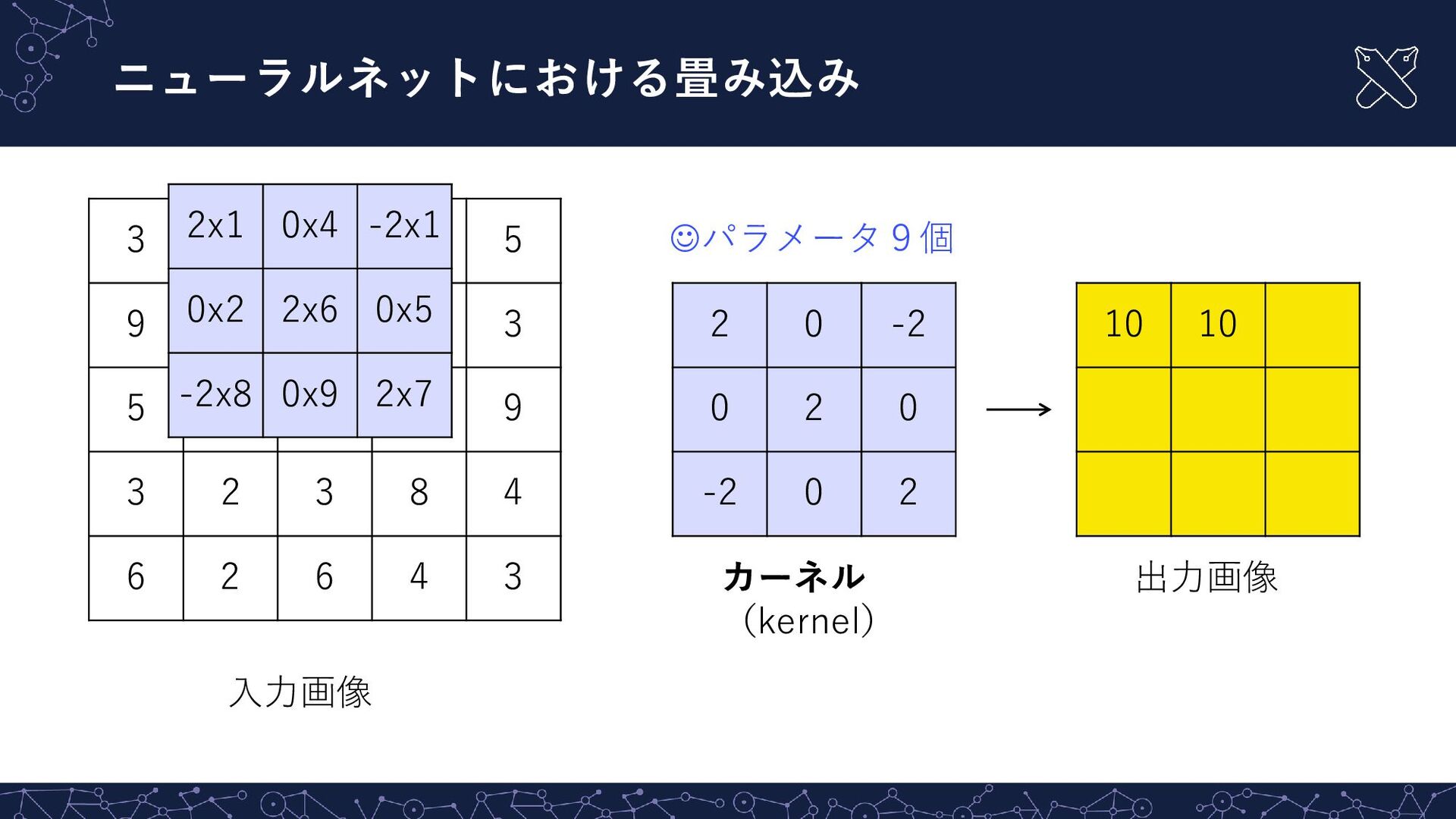{kind=link}
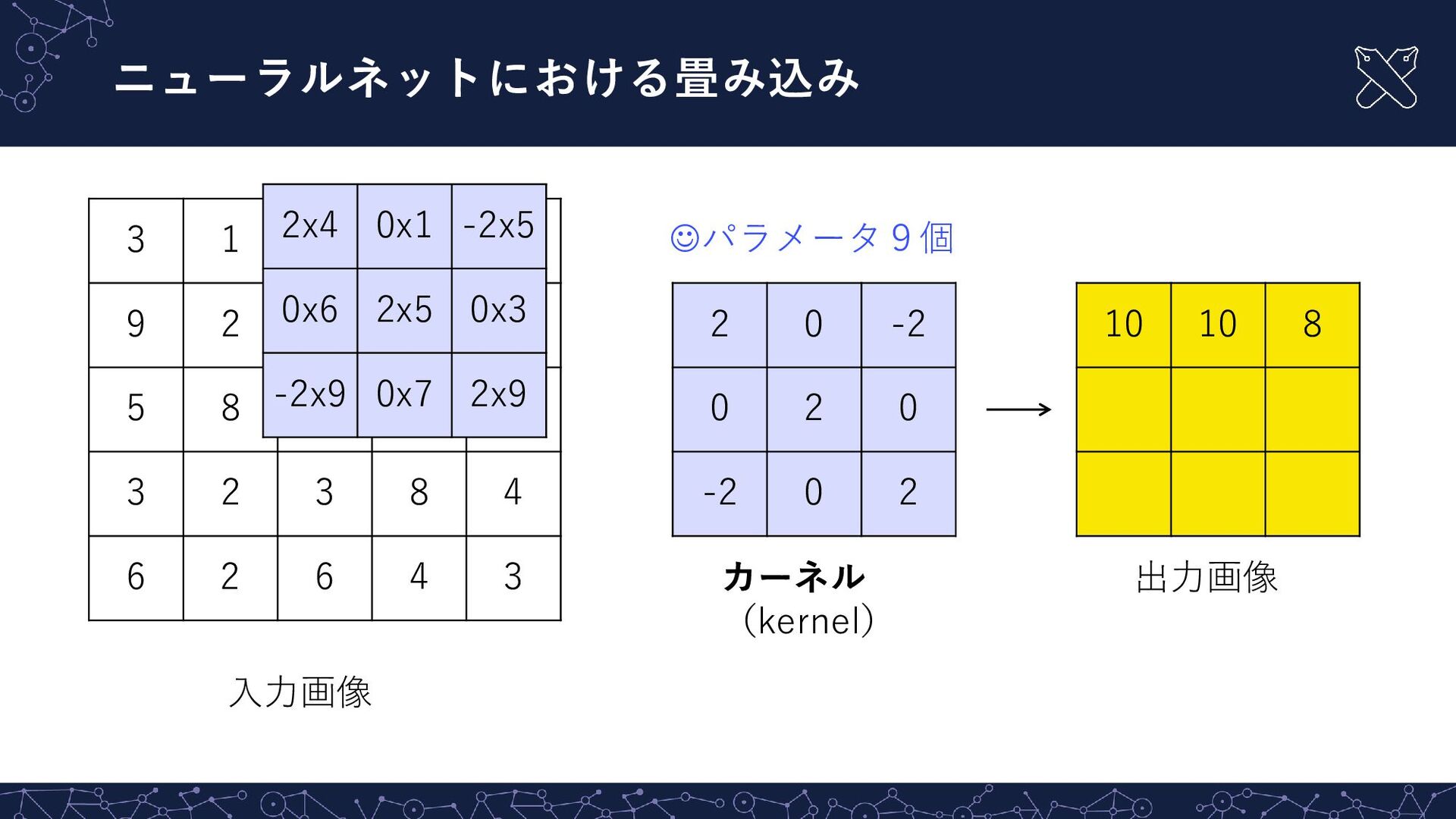{kind=link}
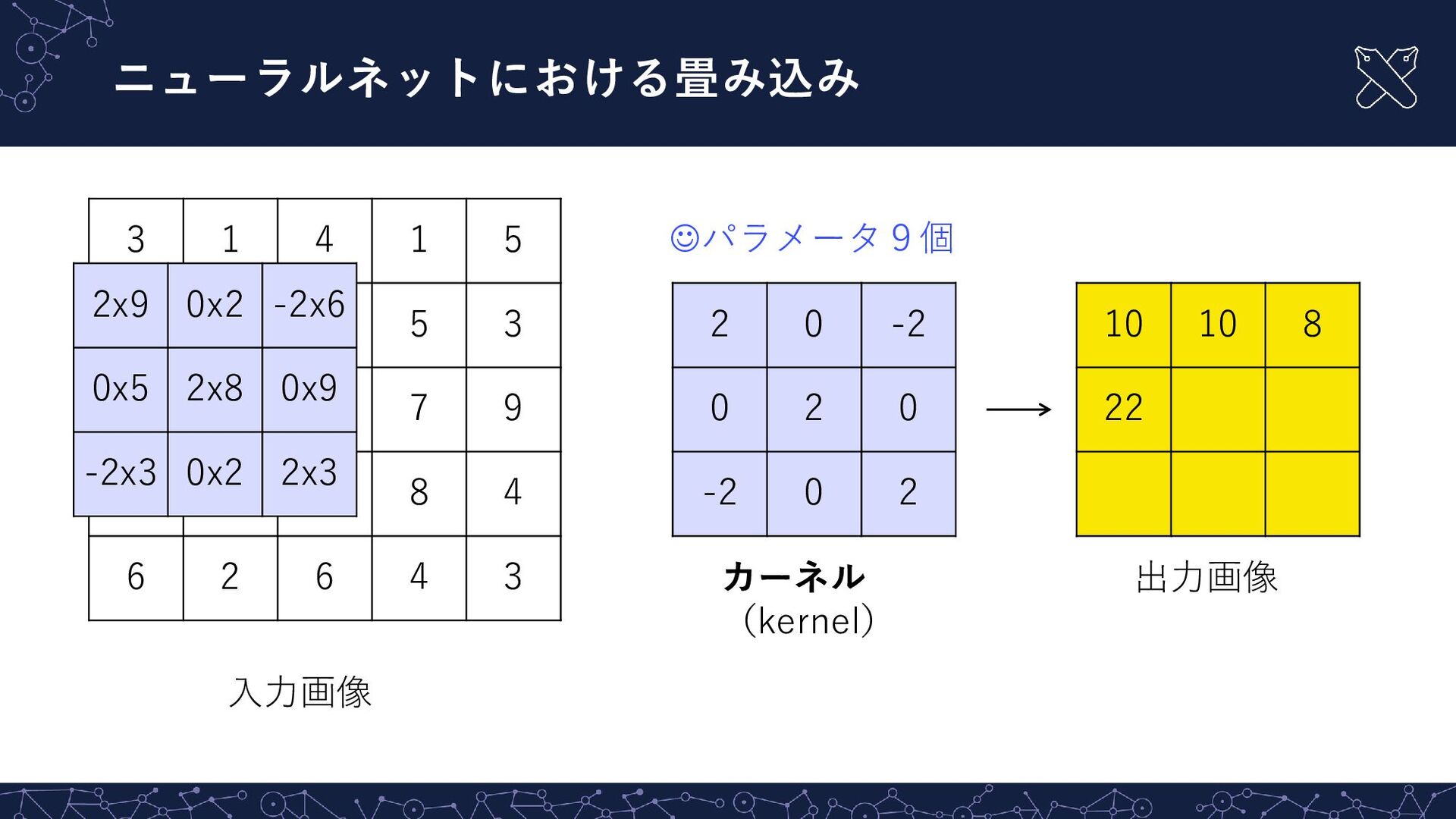{kind=link}
{kind=link}
{kind=link}
![CNN explainer [Wang+ TVCG20]を使ってみよう - - 19 https://poloclub.github.io/cnn- explainer/](https://files.speakerdeck.com/presentations/8ef35977439b47bcb58f88a004912a86/slide_16.jpg){kind=link}
![CNN explainer [Wang+ TVCG20]を使ってみよう - - 20 https://poloclub.github.io/cnn- explainer/ 【グループワーク】画像を入力し](https://files.speakerdeck.com/presentations/8ef35977439b47bcb58f88a004912a86/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
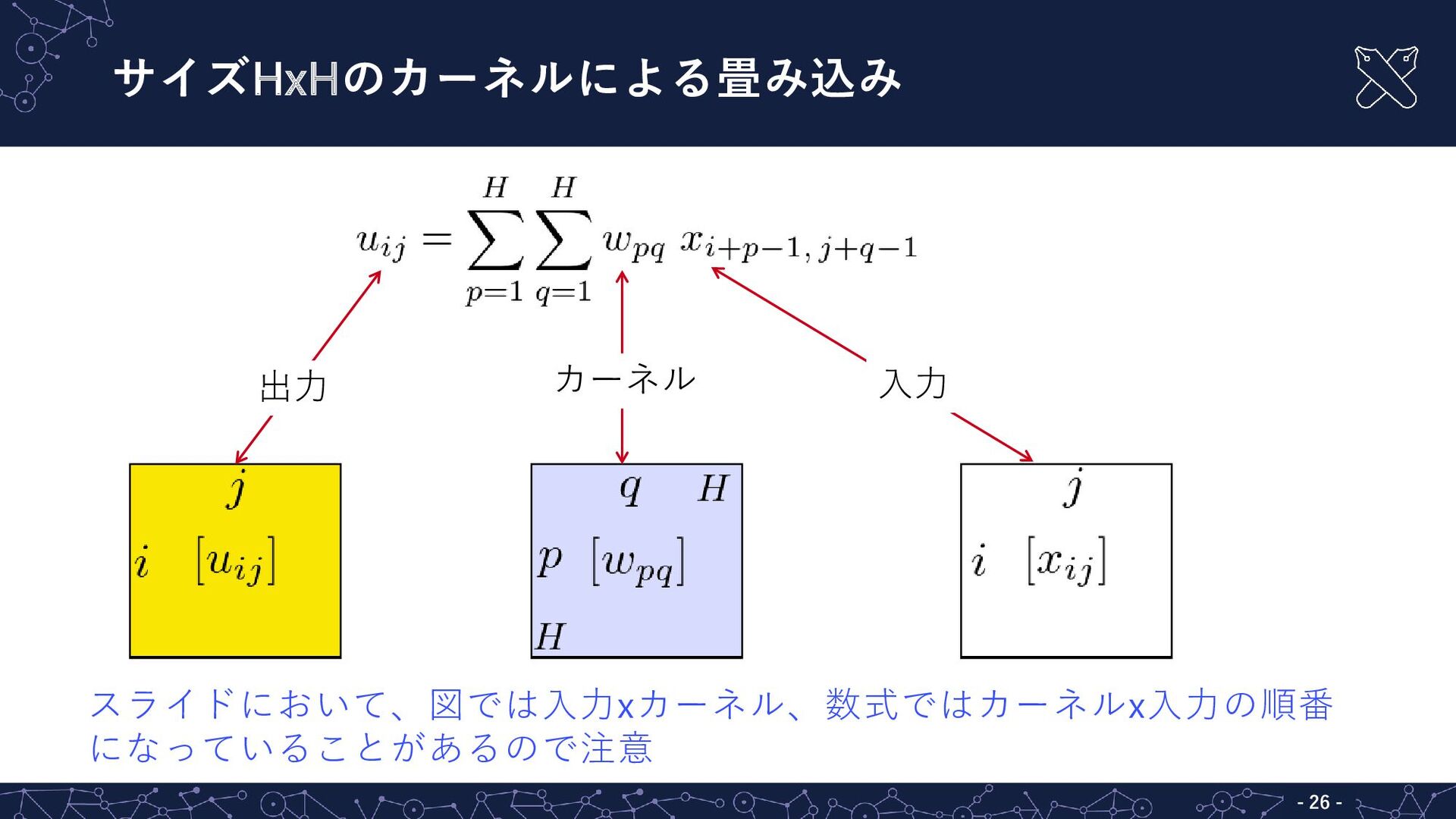{kind=link}
{kind=link}
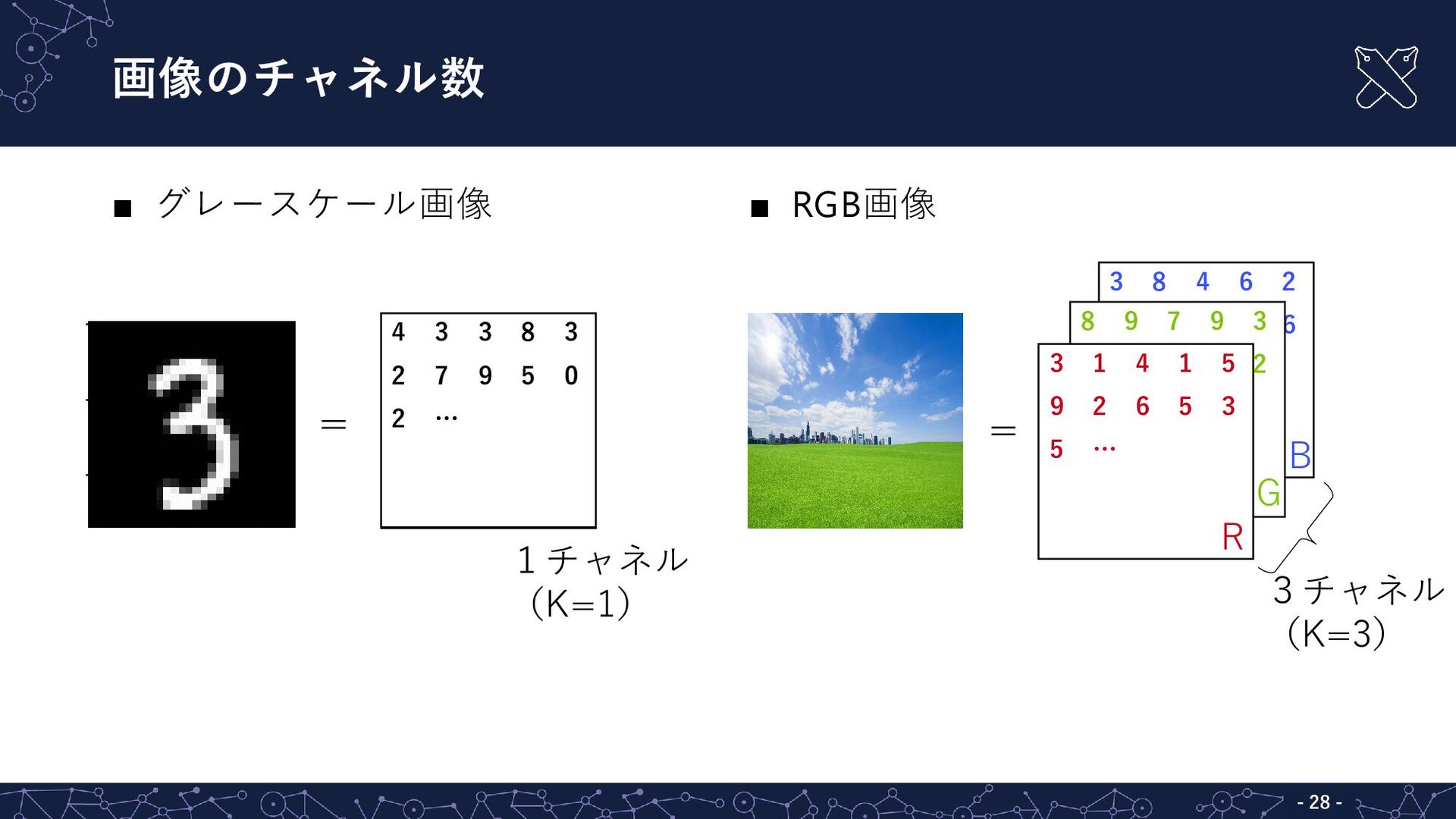{kind=link}
{kind=link}
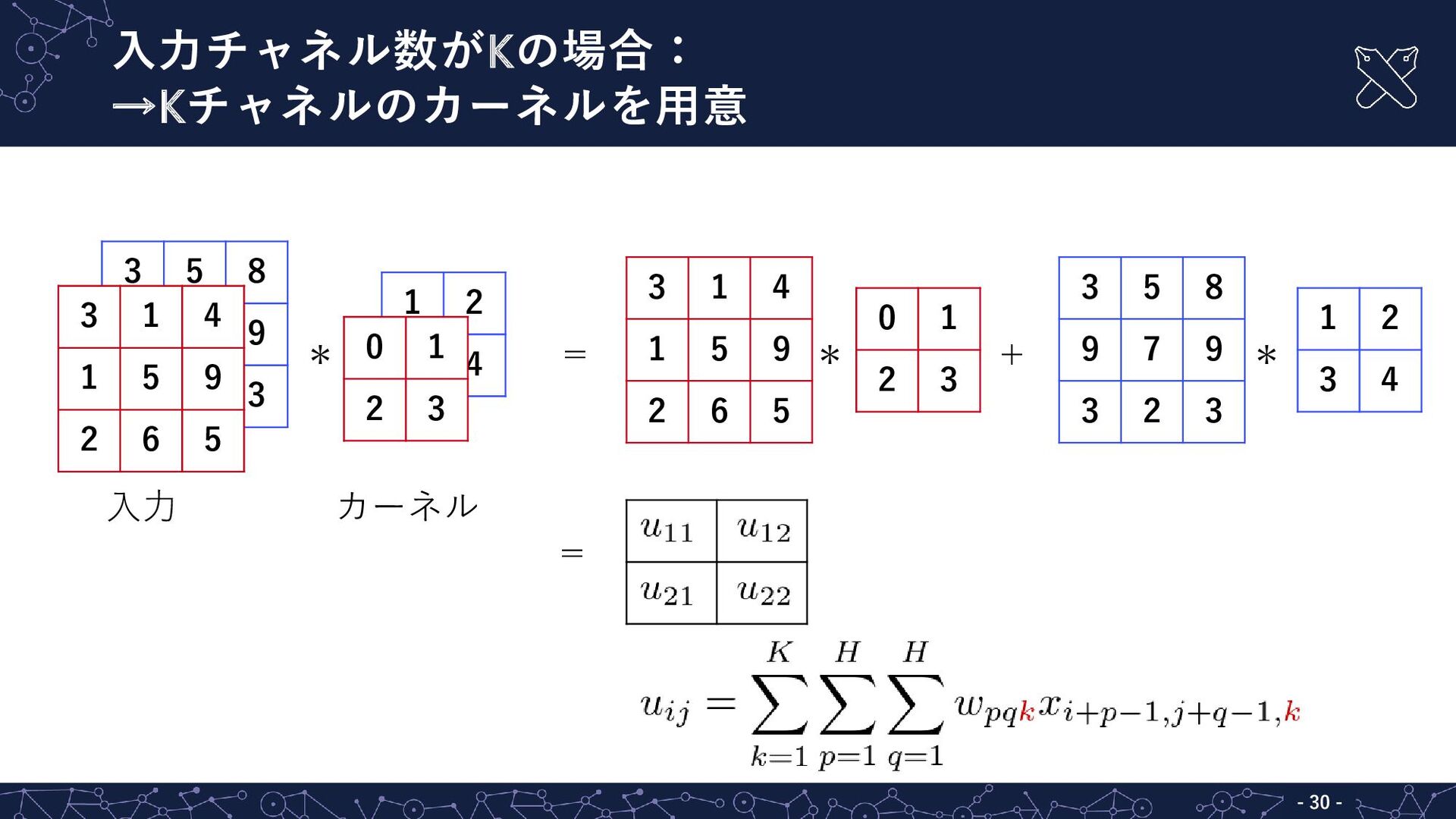{kind=link}
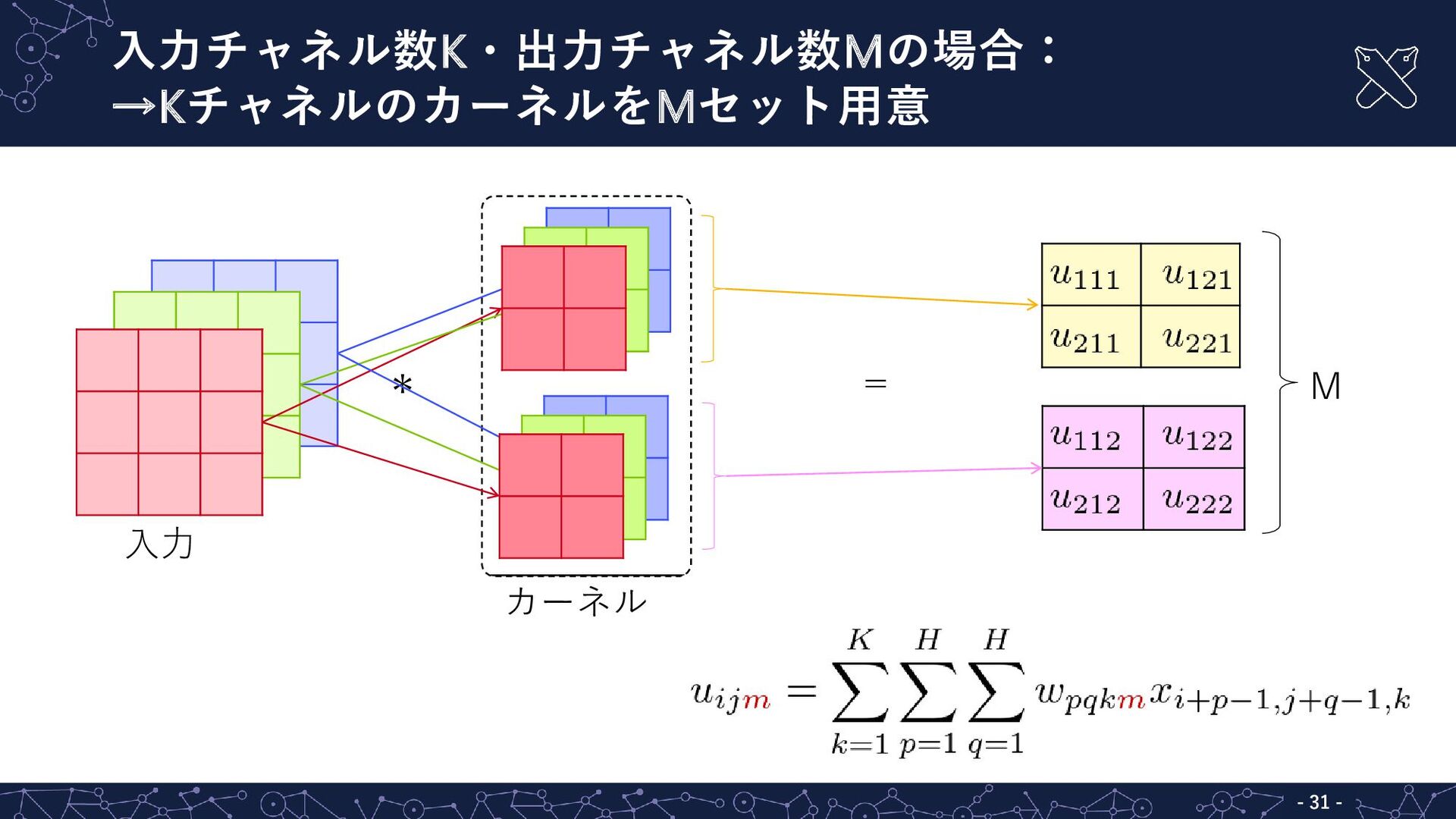{kind=link}
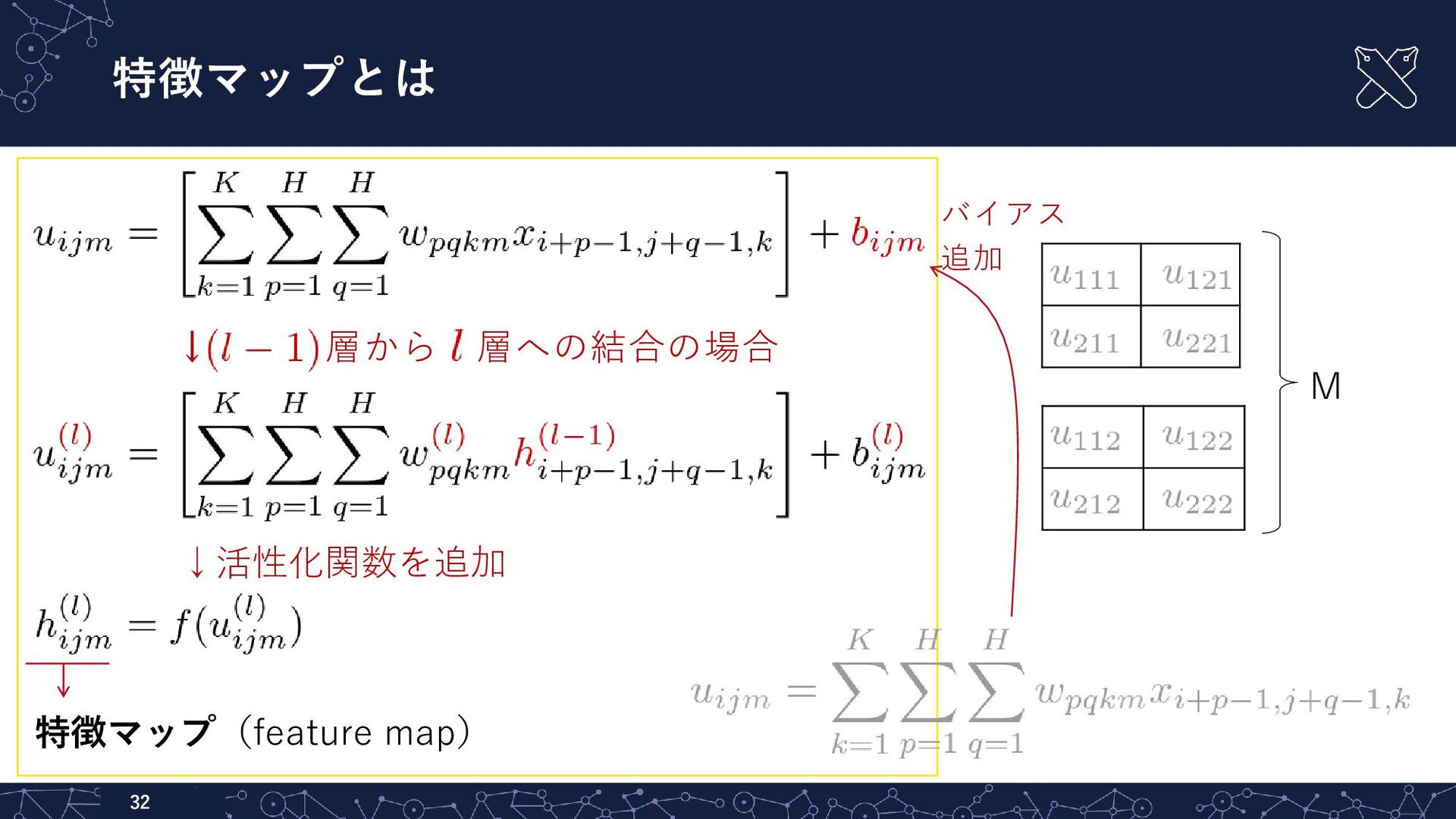{kind=link}
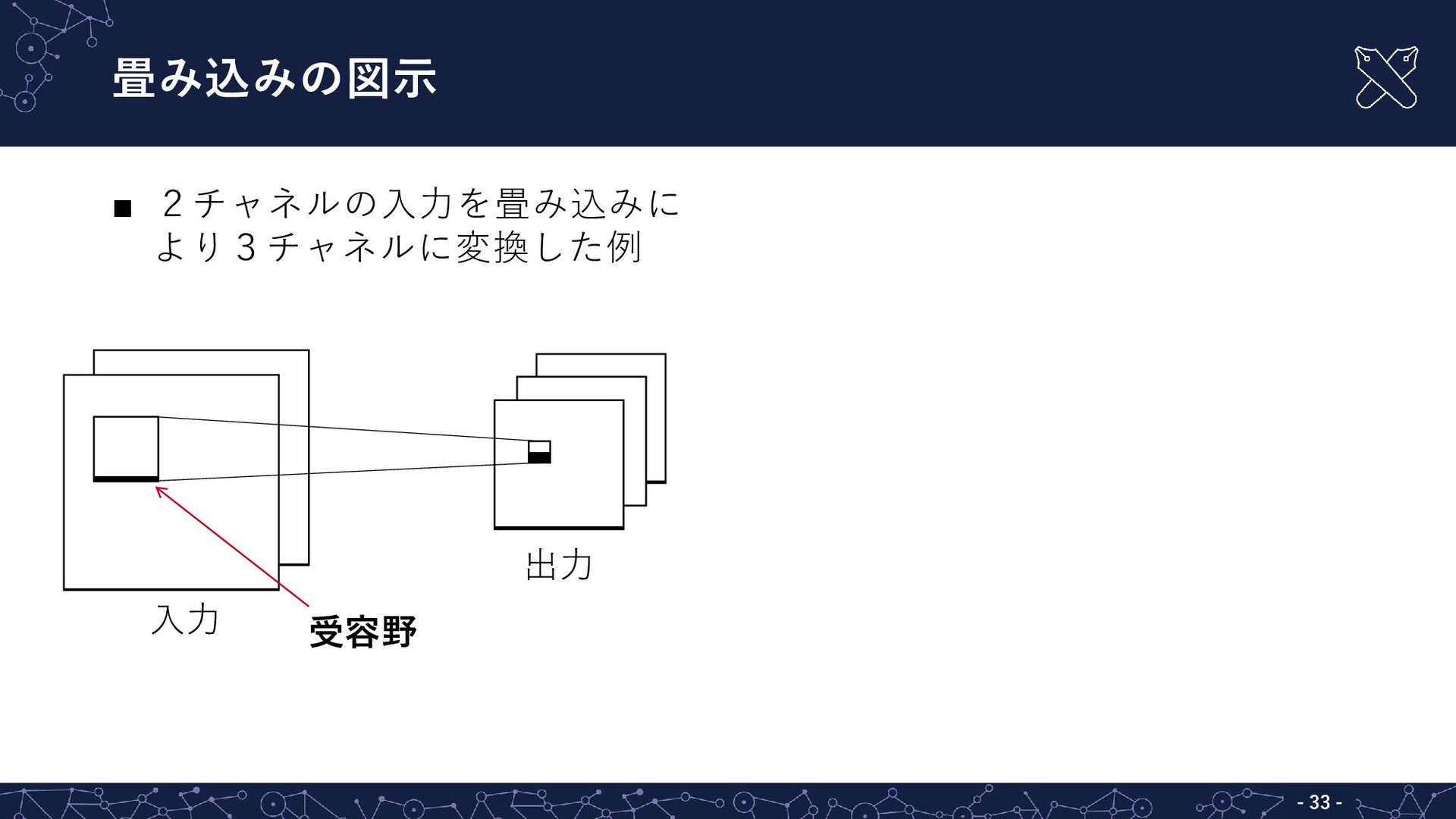{kind=link}
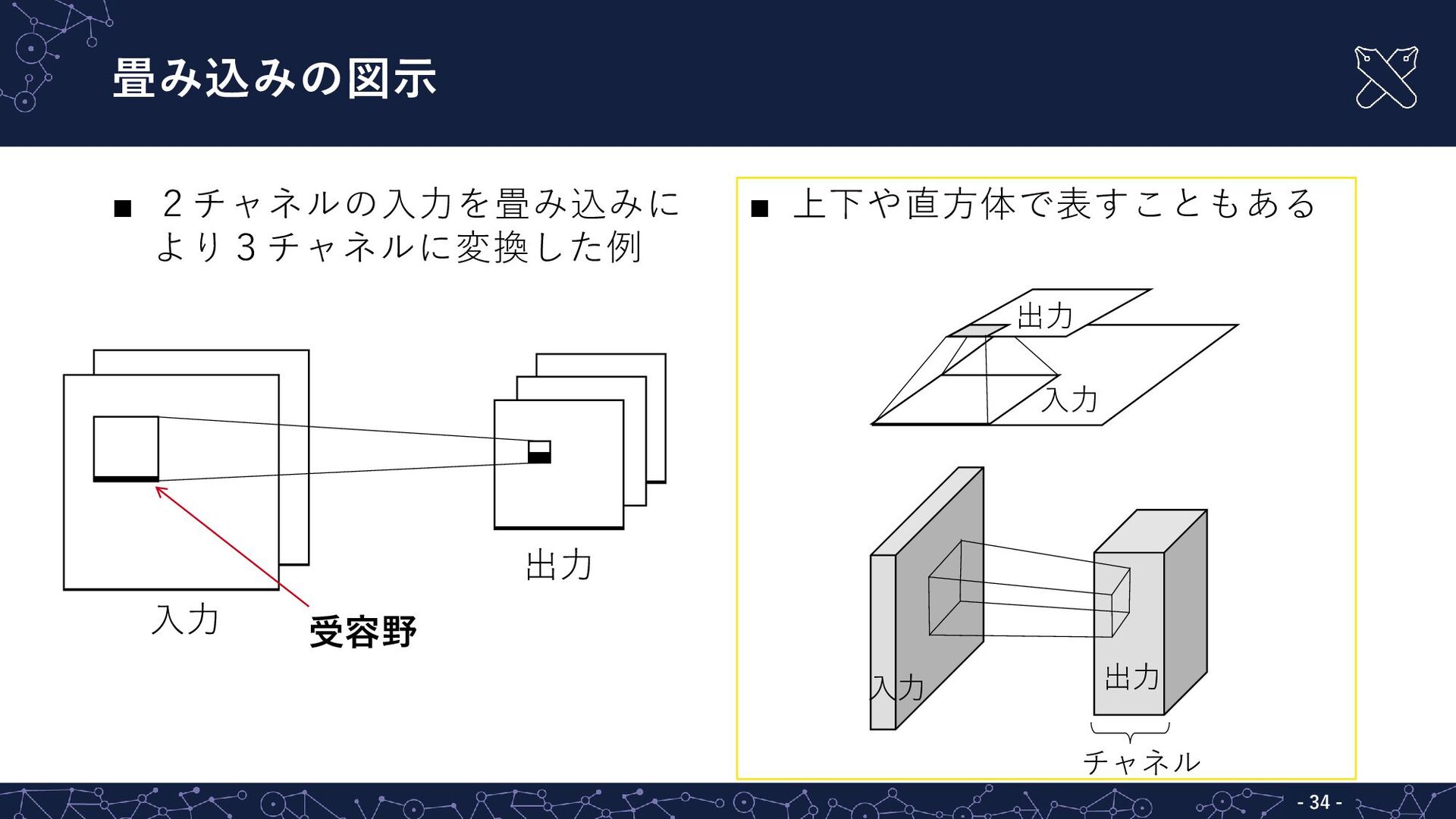{kind=link}
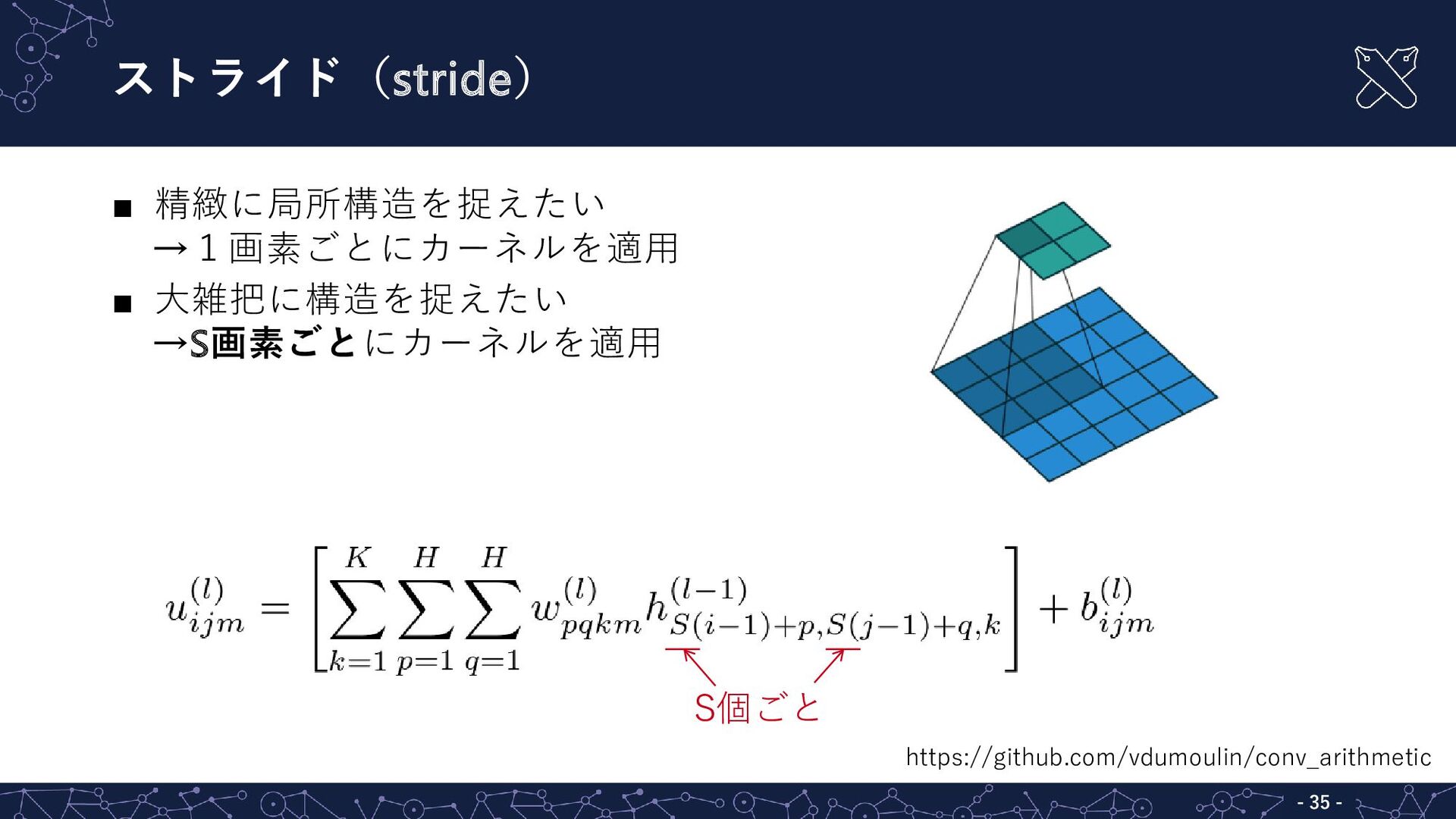{kind=link}
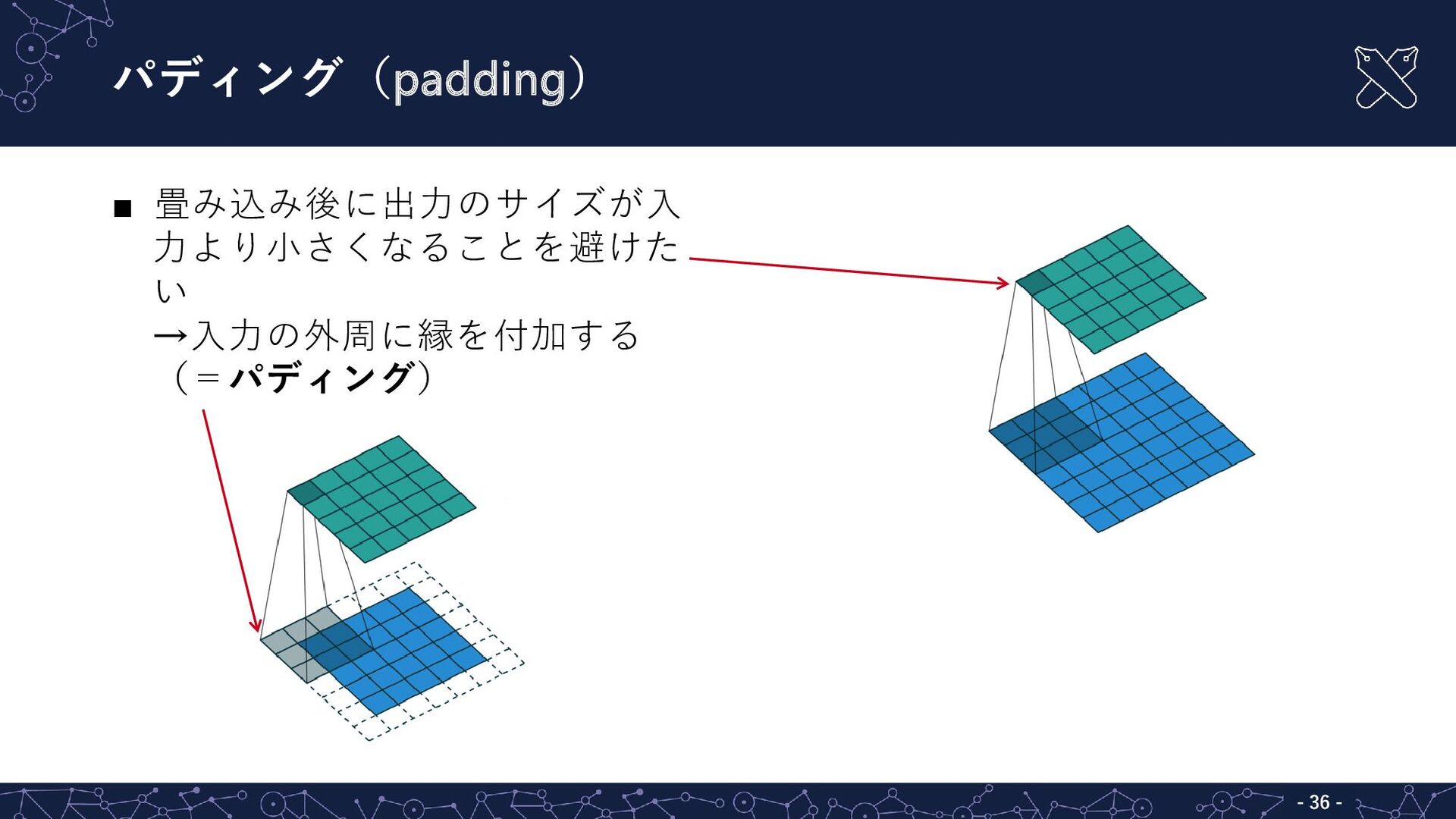{kind=link}
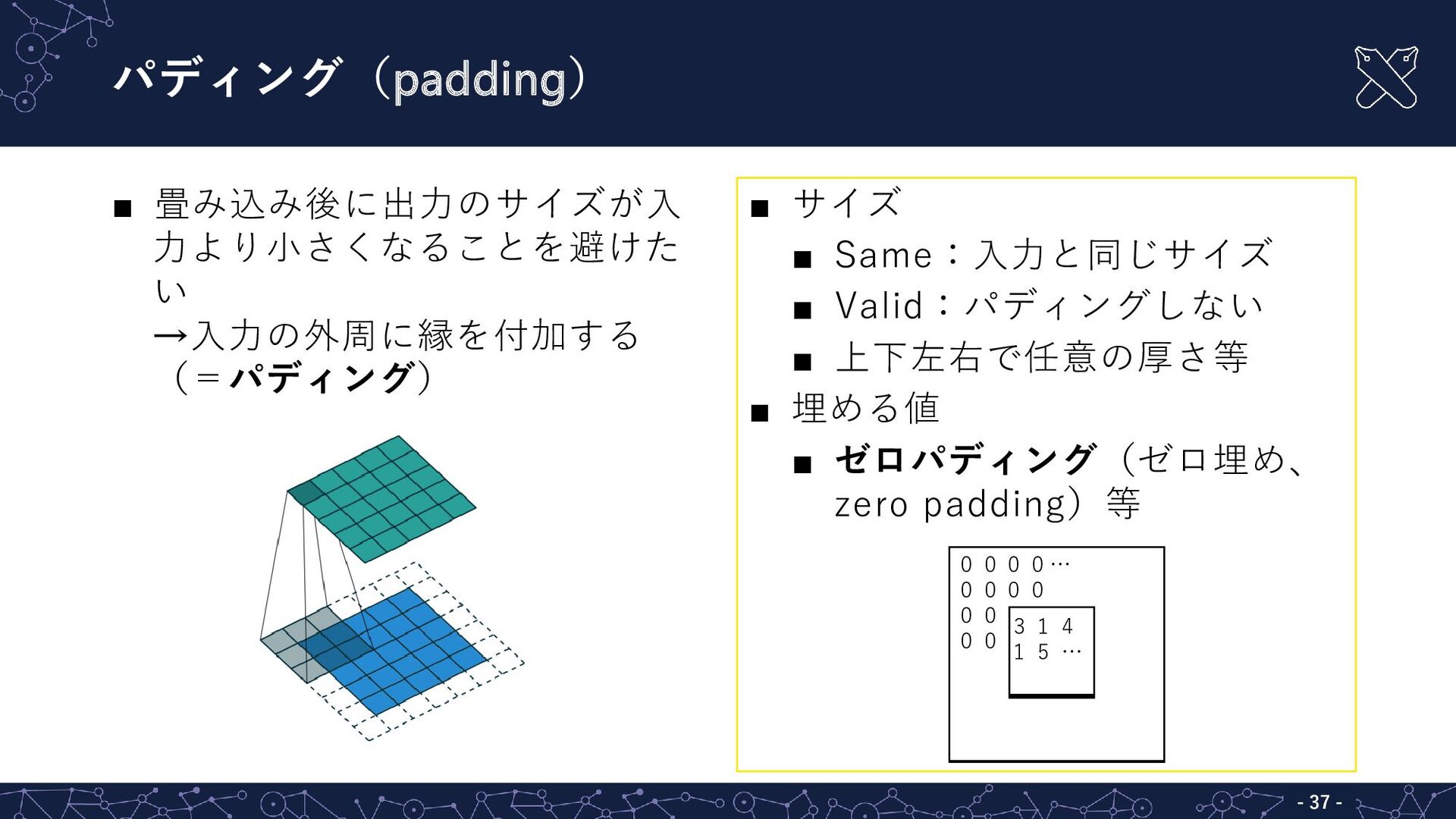{kind=link}
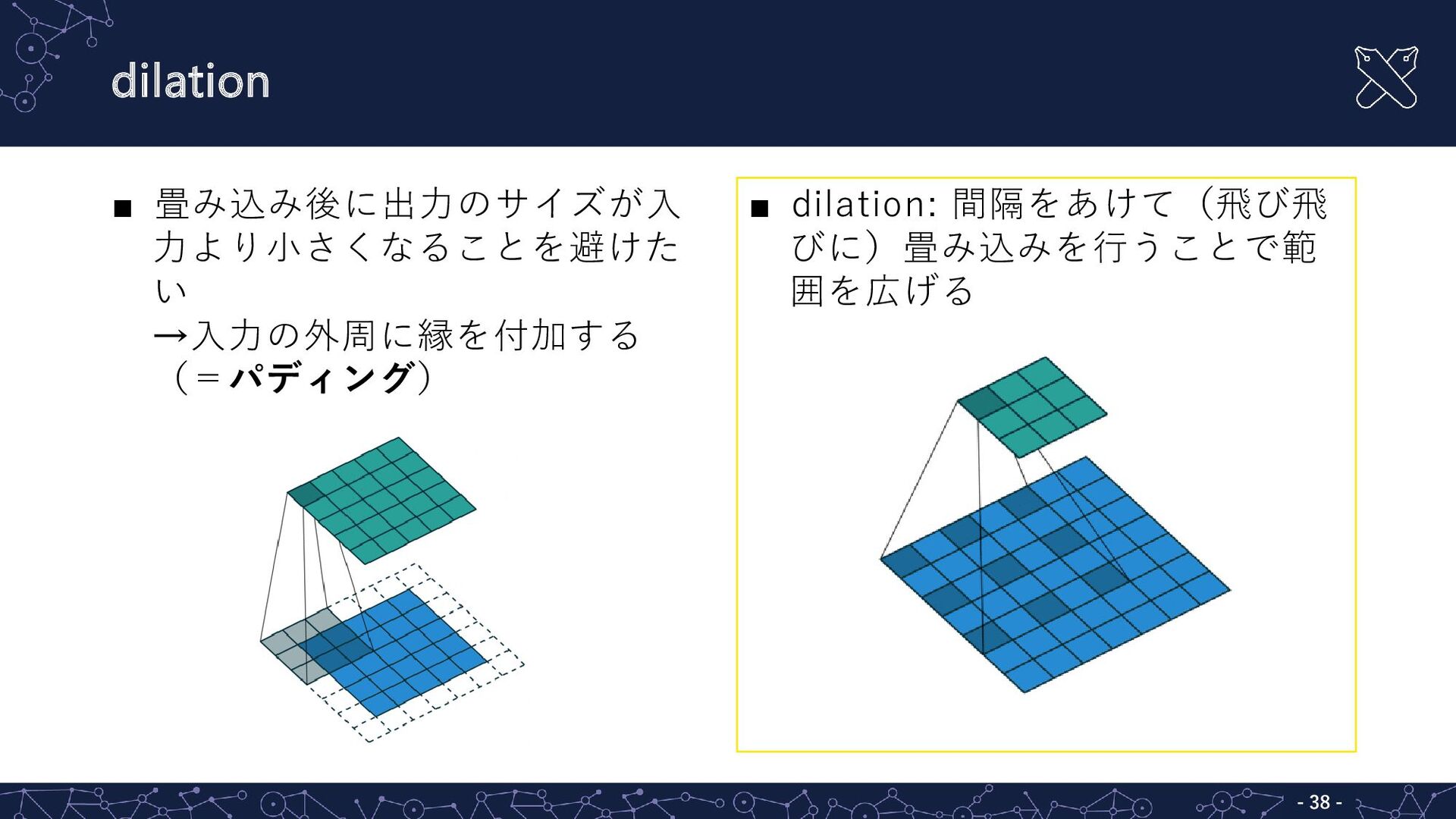{kind=link}
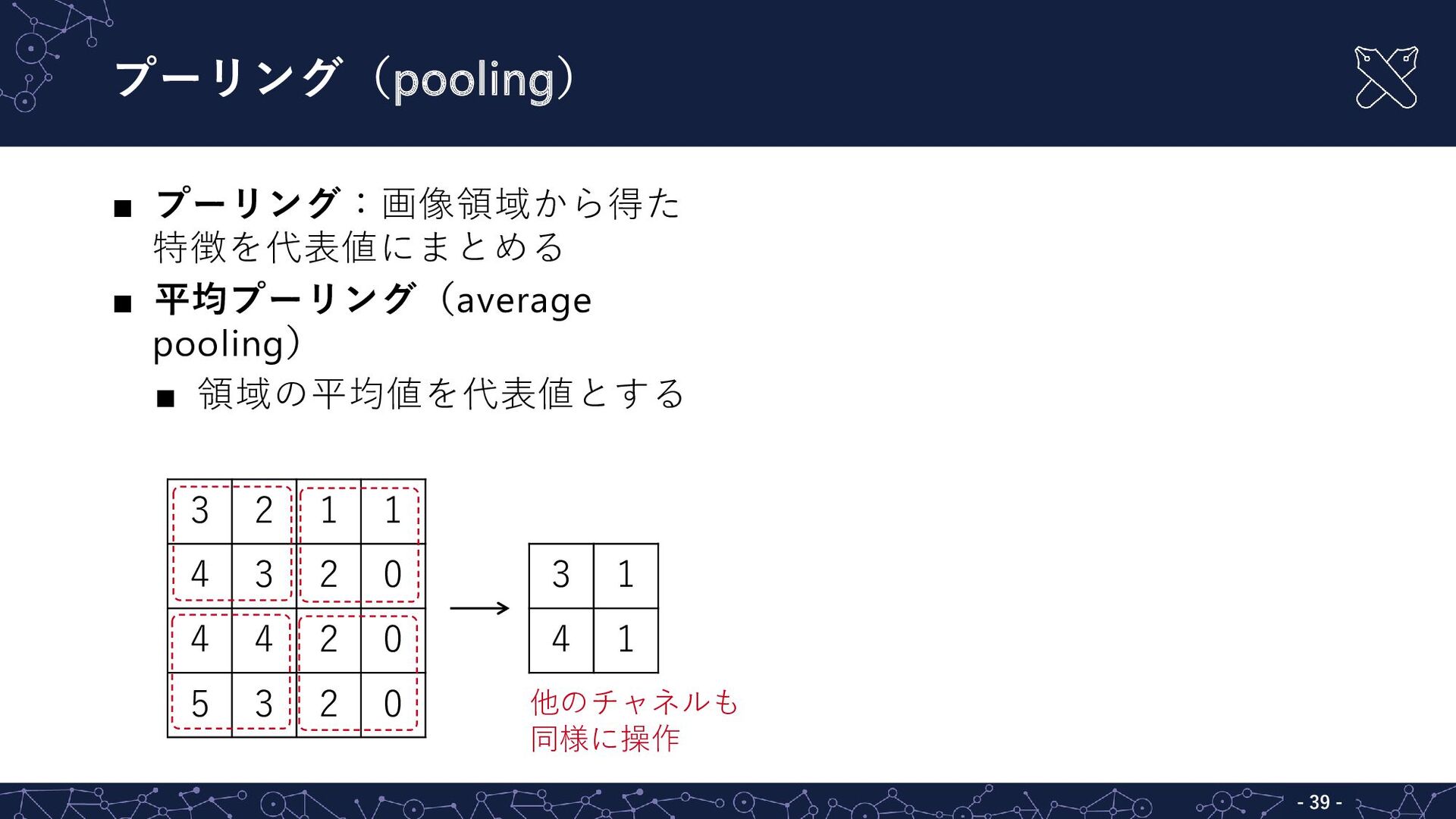{kind=link}
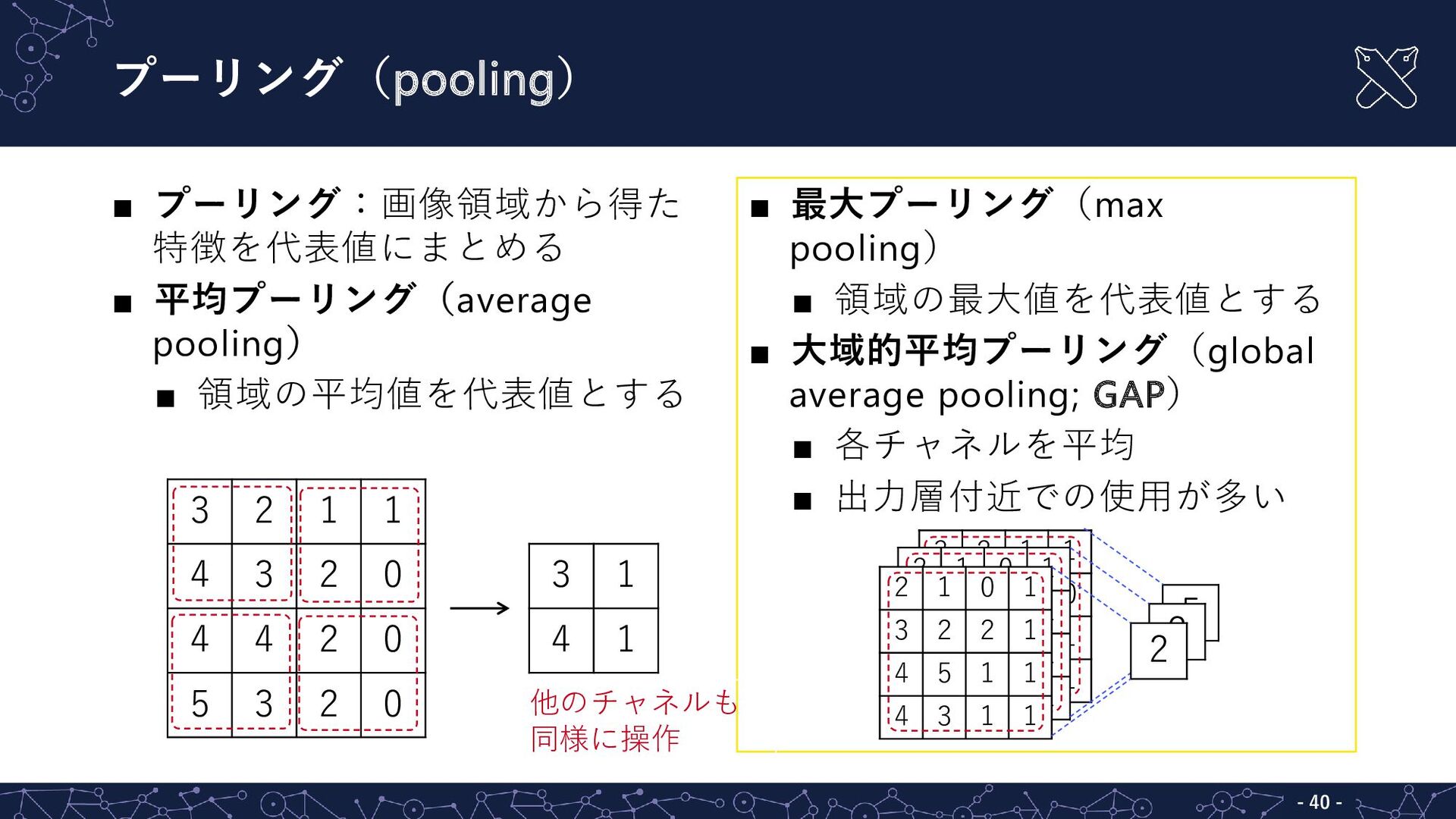{kind=link}
{kind=link}
{kind=link}
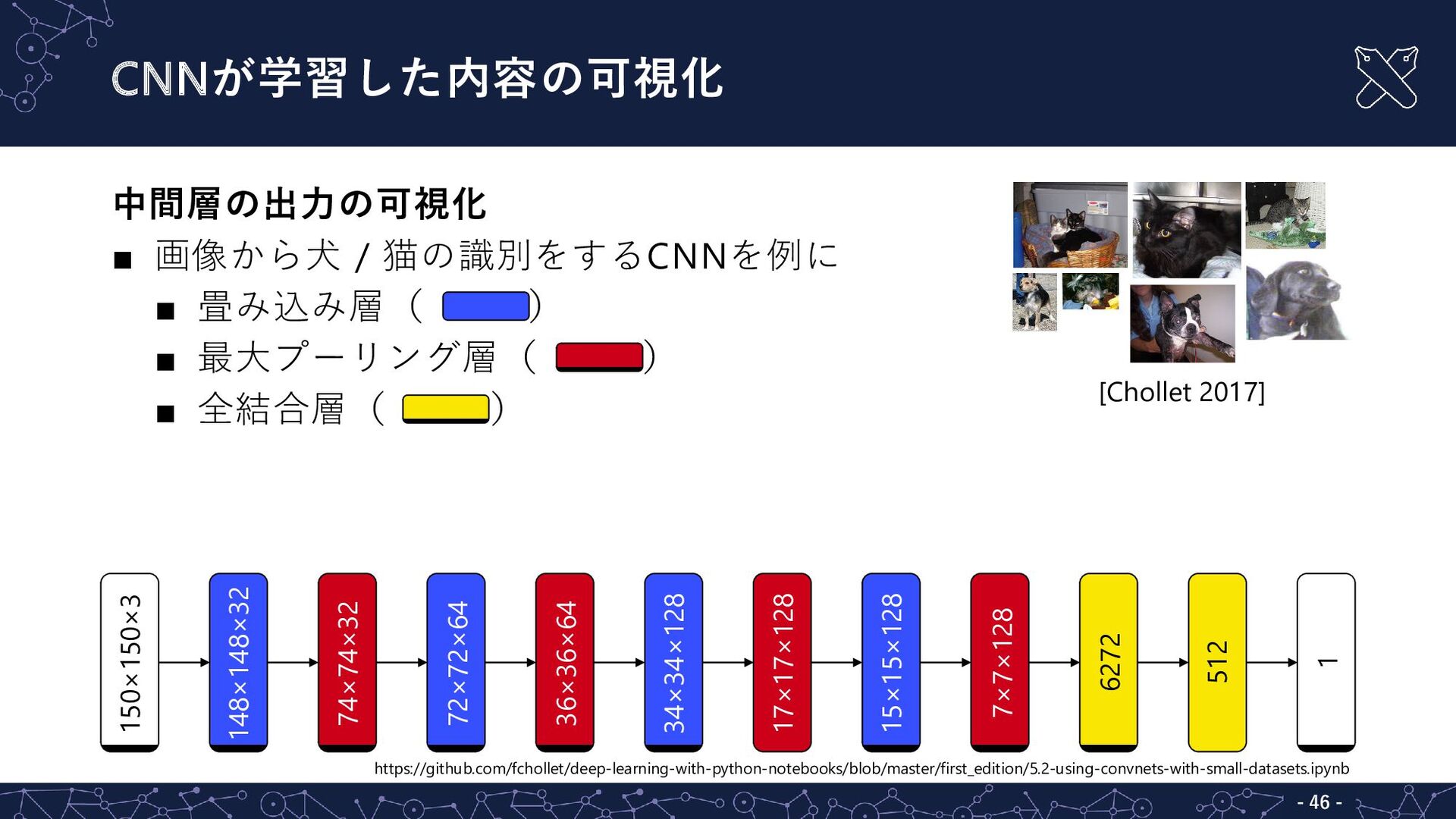{kind=link}
{kind=link}
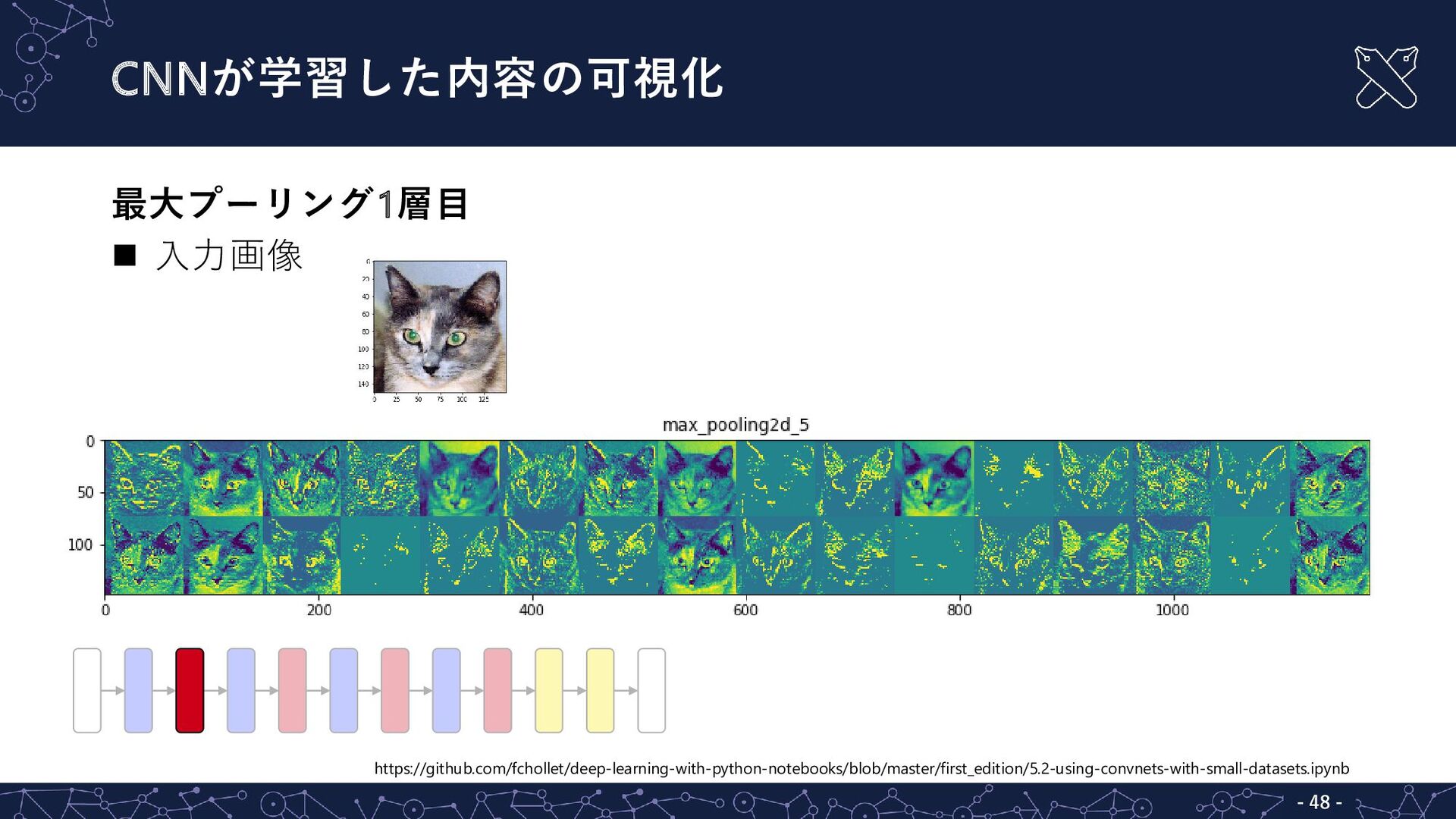{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![代表的なCNN(1) - - 55 LeNet [LeCun+ 1989] ▪ 畳み込み層( )](https://files.speakerdeck.com/presentations/8ef35977439b47bcb58f88a004912a86/slide_49.jpg){kind=link}
![代表的なCNN(2) - - 56 AlexNet [Krizhevsky+ 2012] ▪ 畳み込み層( )](https://files.speakerdeck.com/presentations/8ef35977439b47bcb58f88a004912a86/slide_50.jpg){kind=link}
![代表的なCNN(3) - - 57 VGG [Simonyan+ 2015] ▪ 畳み込み層( )](https://files.speakerdeck.com/presentations/8ef35977439b47bcb58f88a004912a86/slide_51.jpg){kind=link}
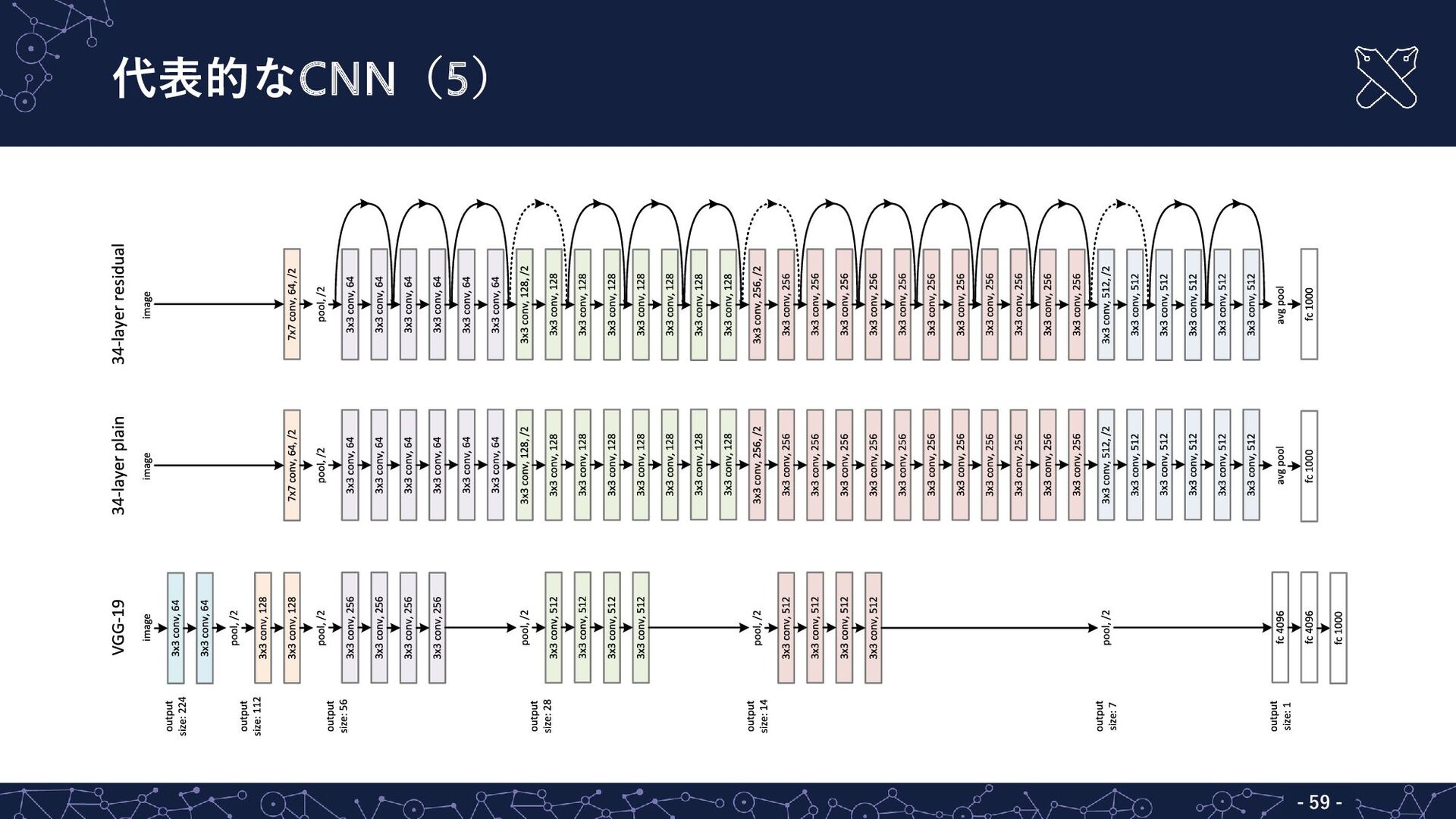
 ▪ 入力と出力を直接接続する経路をもつ残差ブロックを積み上げた 残差ネットワーク(residual](https://files.speakerdeck.com/presentations/8ef35977439b47bcb58f88a004912a86/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![代表的なCNN(4) - - 68 GoogLeNet [Szegedy+ 2015] ▪ 畳み込み層( )](https://files.speakerdeck.com/presentations/8ef35977439b47bcb58f88a004912a86/slide_61.jpg){kind=link}
![代表的なCNN(4) - - 69 GoogLeNet [Szegedy+ 2015] ▪ インセプションモジュール( )](https://files.speakerdeck.com/presentations/8ef35977439b47bcb58f88a004912a86/slide_62.jpg){kind=link}
{kind=link}
{kind=link}