様々なVision and Languageタスクを実行可能 ▪ 今回は、”Image Captioning” と “VQA” を実際にBLIPに実行させます “A man swinging a tennis racket at a tennis ball” [Image Captioning] [VQA] Q. “What sport does he play?” A. “Tennis” https://mainichi.jp/articles/20220114/k00/00m/050/207000 c
a red bicycle on a sidewalk” https://www.pinterest.jp/pin/cat-on-a-bike-- 356558495482515964/ “a group of men playing a game of volleyball” https://helloworld.international/events_/free-event-sepak-takraw/
what is the mood of the children? A. happy Q. how many children in the picture? A. 3 [2] Wang, Peng, et al. "Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework." arXiv preprint arXiv:2202.03052 (2022). [2] Q. what is the woman doing? A. snowboarding Q. what is the season in the picture? [1] https://livejapan.com/ja/article- a0000435/ A. winter [1]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CLIP[Radford+, ICML21] • 画像もベクトルに変換することができる • CLIP[Radford+, ICML21] • 自然言語と画像のベクトルを近づける →](https://files.speakerdeck.com/presentations/04d74c26fe034a8ba5ec45330058c251/slide_17.jpg){kind=link}
![CLIP[Radford+, ICML21] • 画像もベクトルに変換することができる • CLIP[Radford+, ICML21] • 自然言語と画像のベクトルを近づける →](https://files.speakerdeck.com/presentations/04d74c26fe034a8ba5ec45330058c251/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
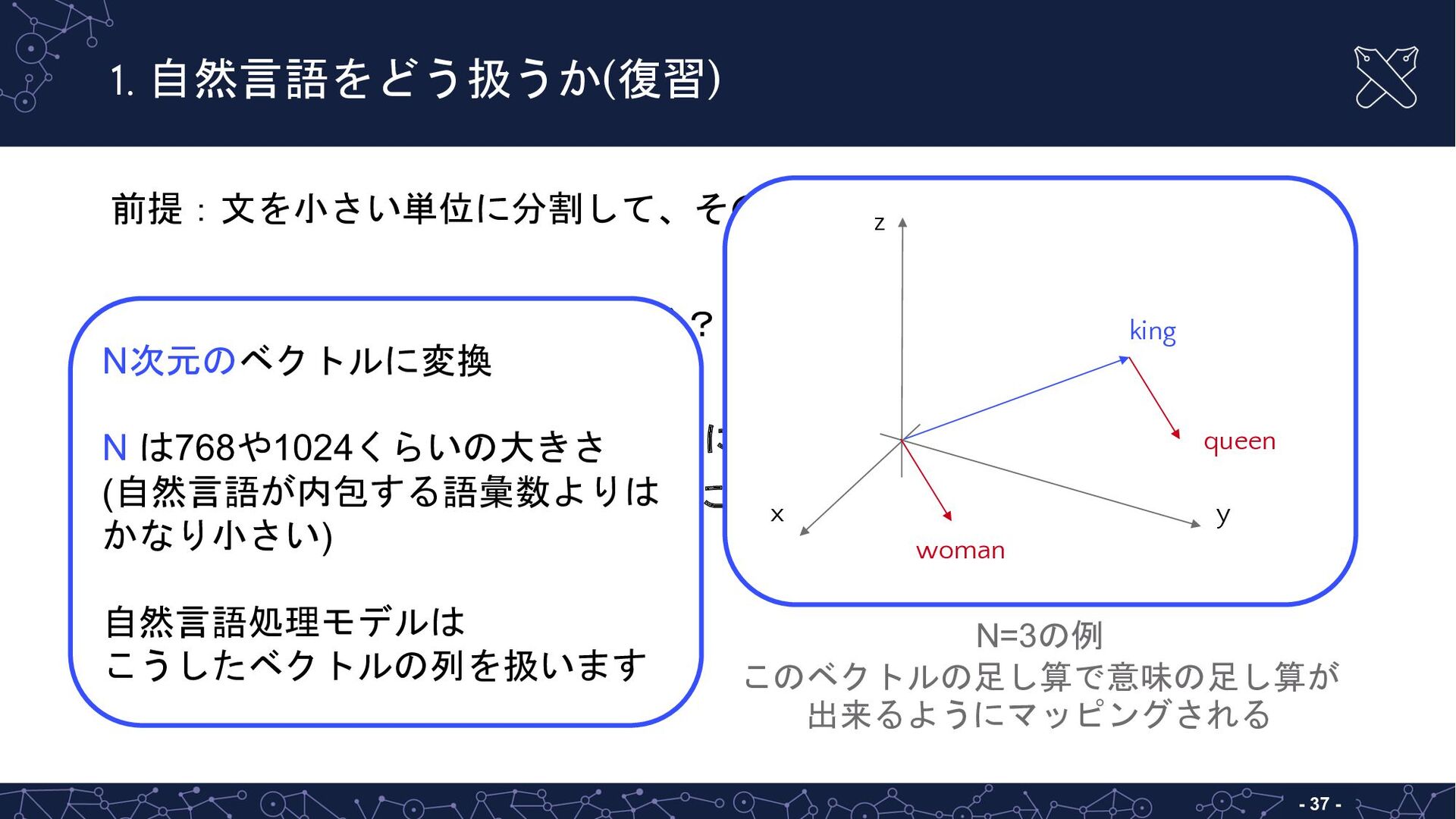{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
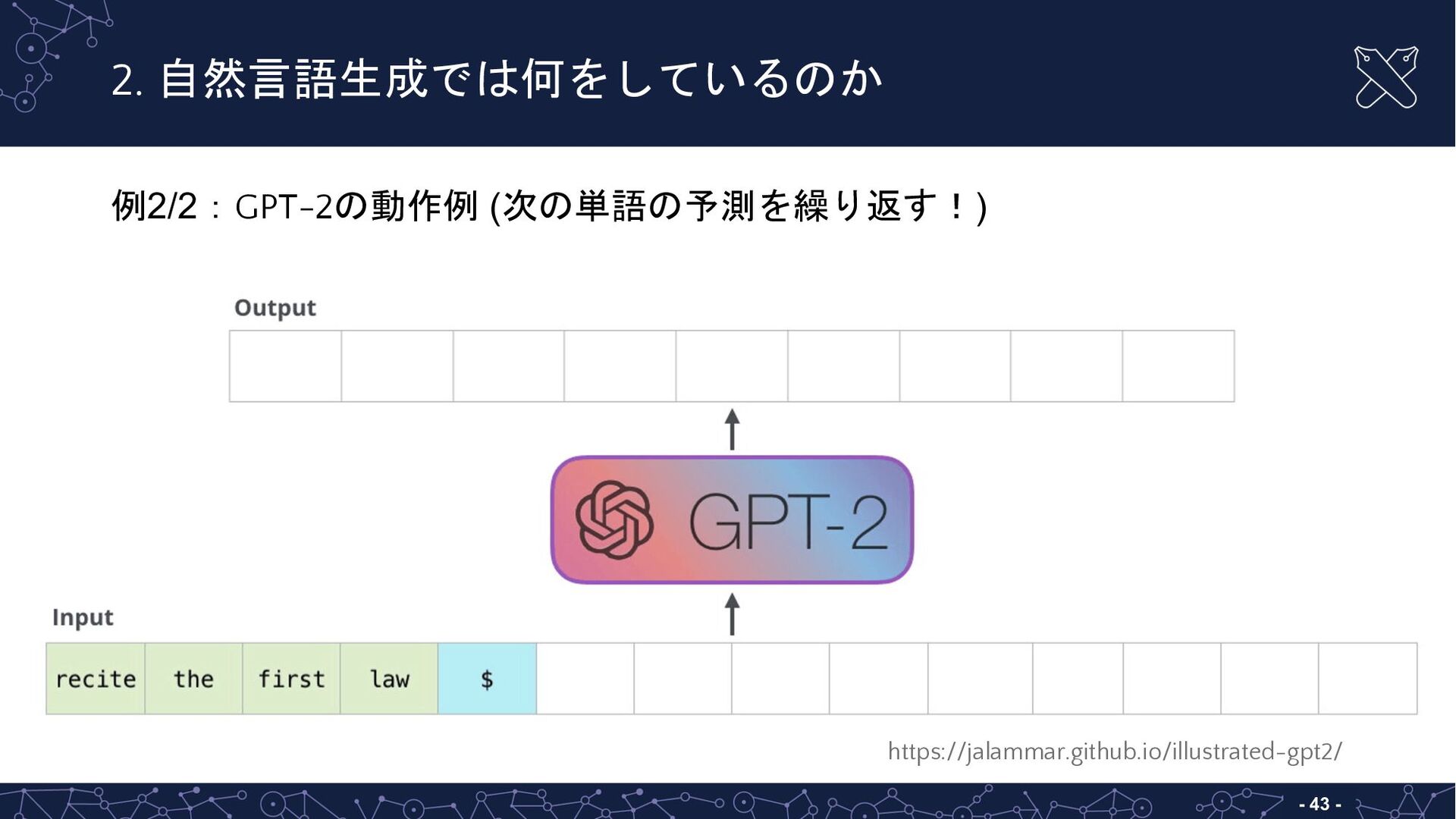{kind=link}
{kind=link}
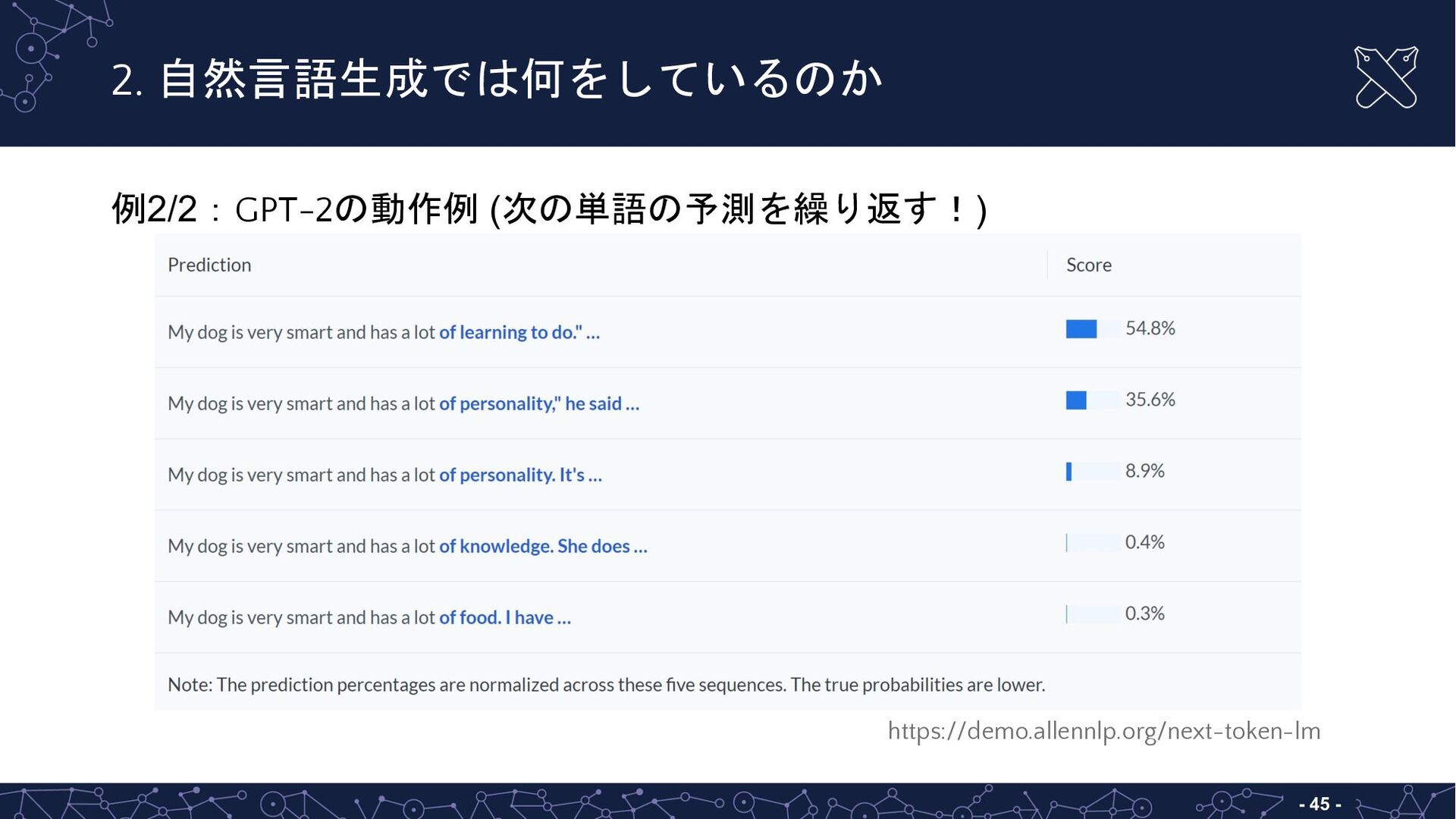{kind=link}
{kind=link}
{kind=link}
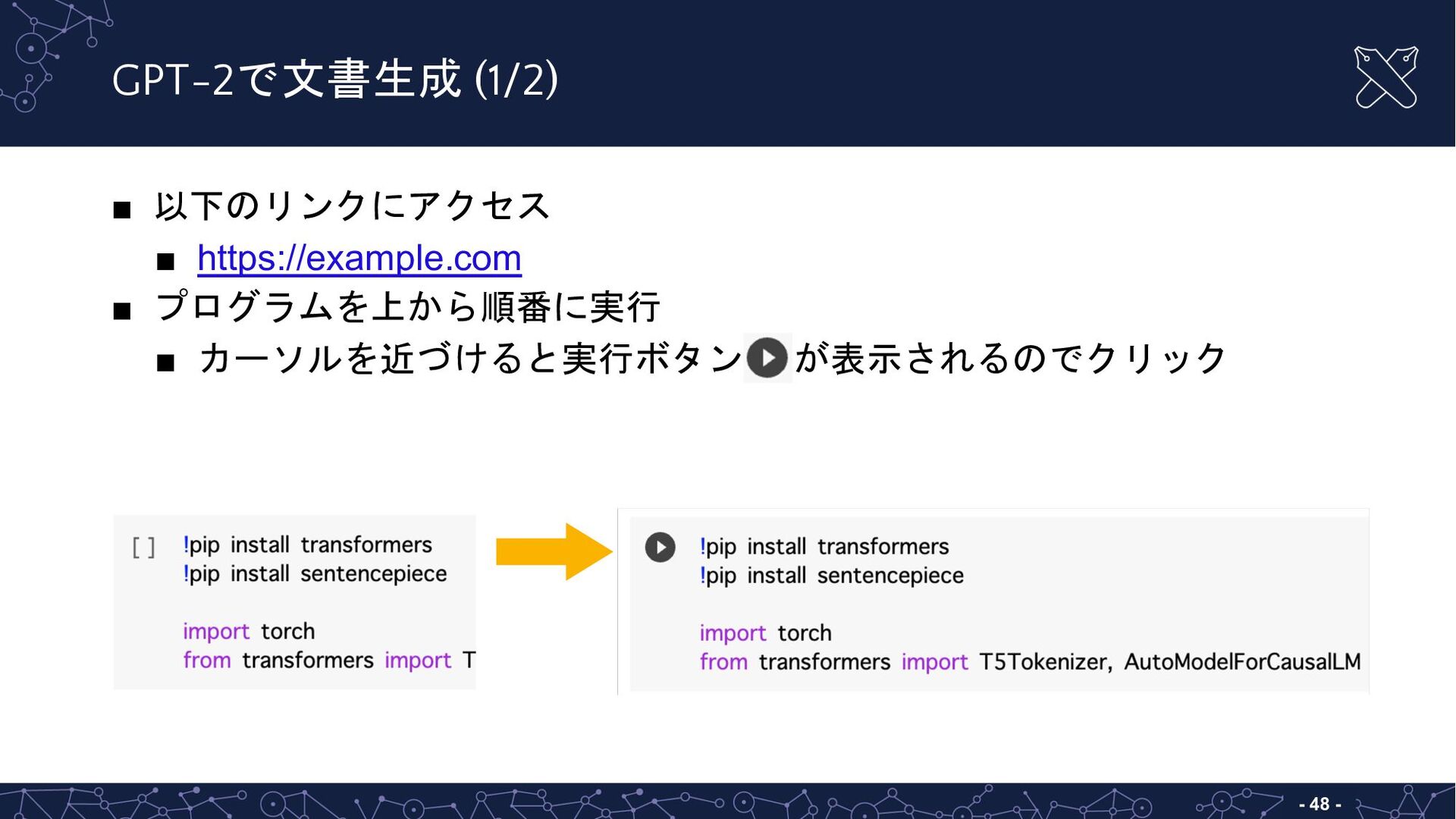{kind=link}
{kind=link}
{kind=link}
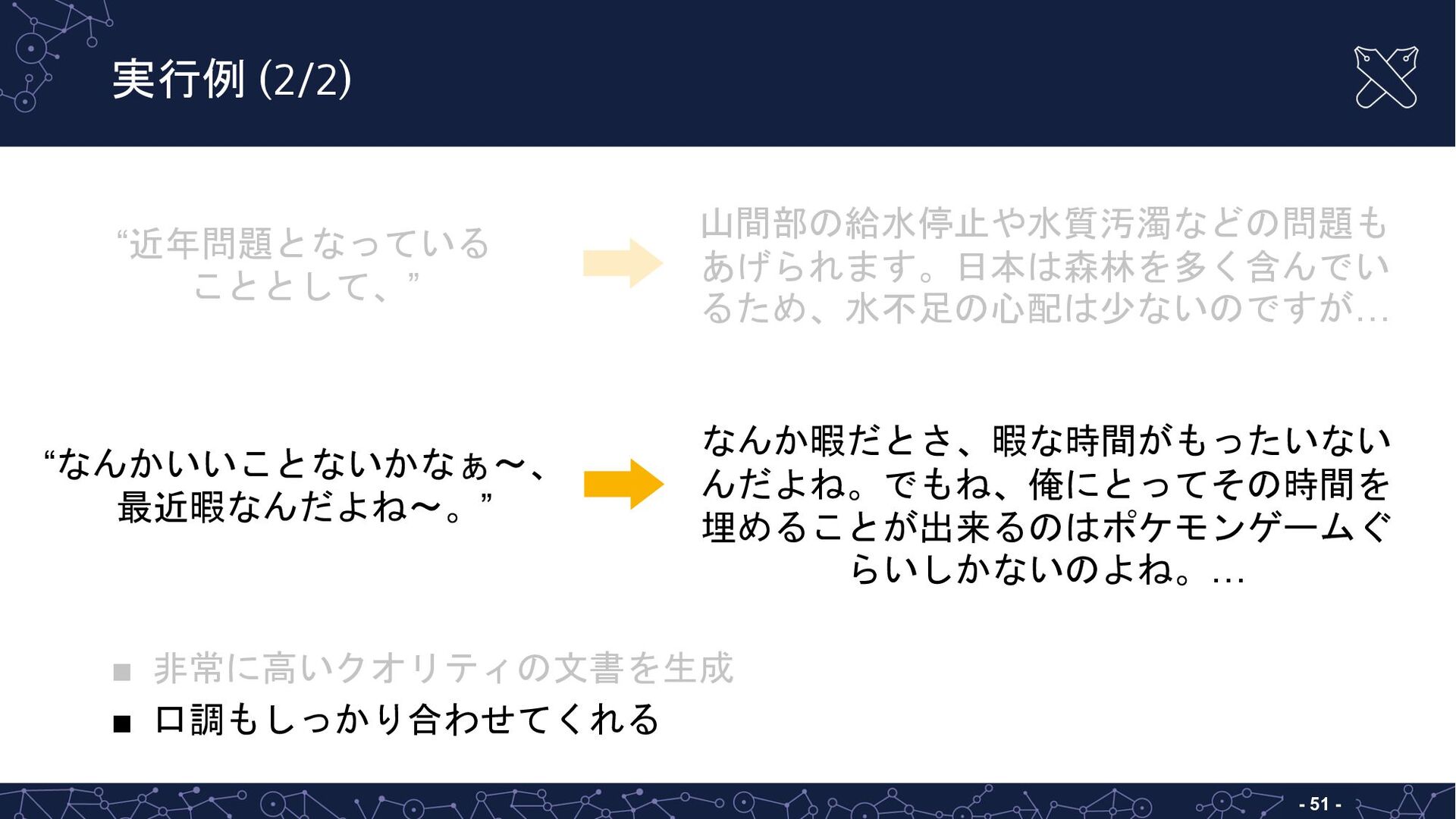{kind=link}
{kind=link}