Share
2025年9月3日(水)〜9月5日(金)で開催されました、FIT2025 (https://www.ipsj.or.jp/event/fit/fit2025/index.html) のインダストリアルセッションにて「さくらインターネット研究所の研究開発のご紹介とさくらONEについて」というタイトルで発表しました。
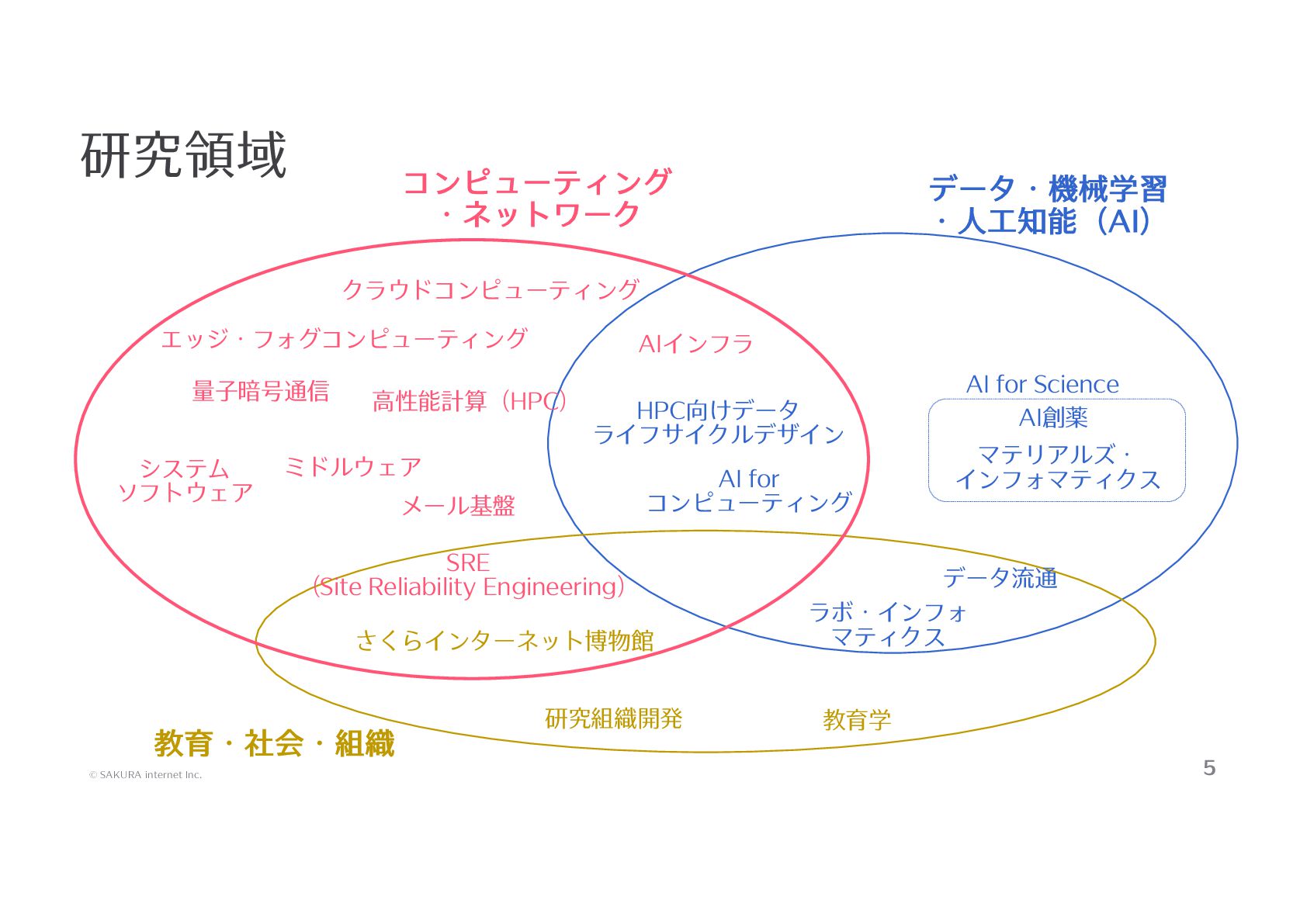
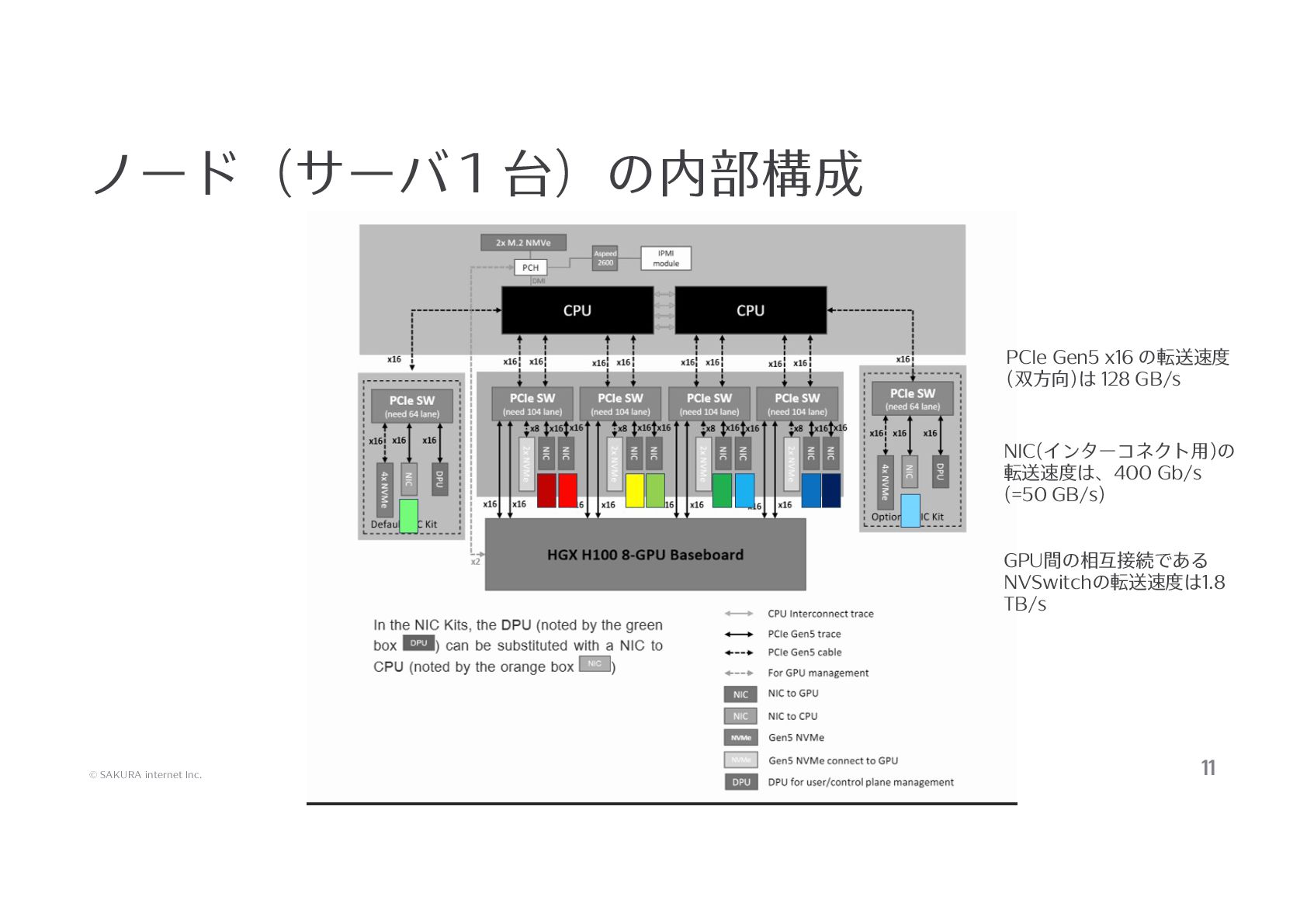
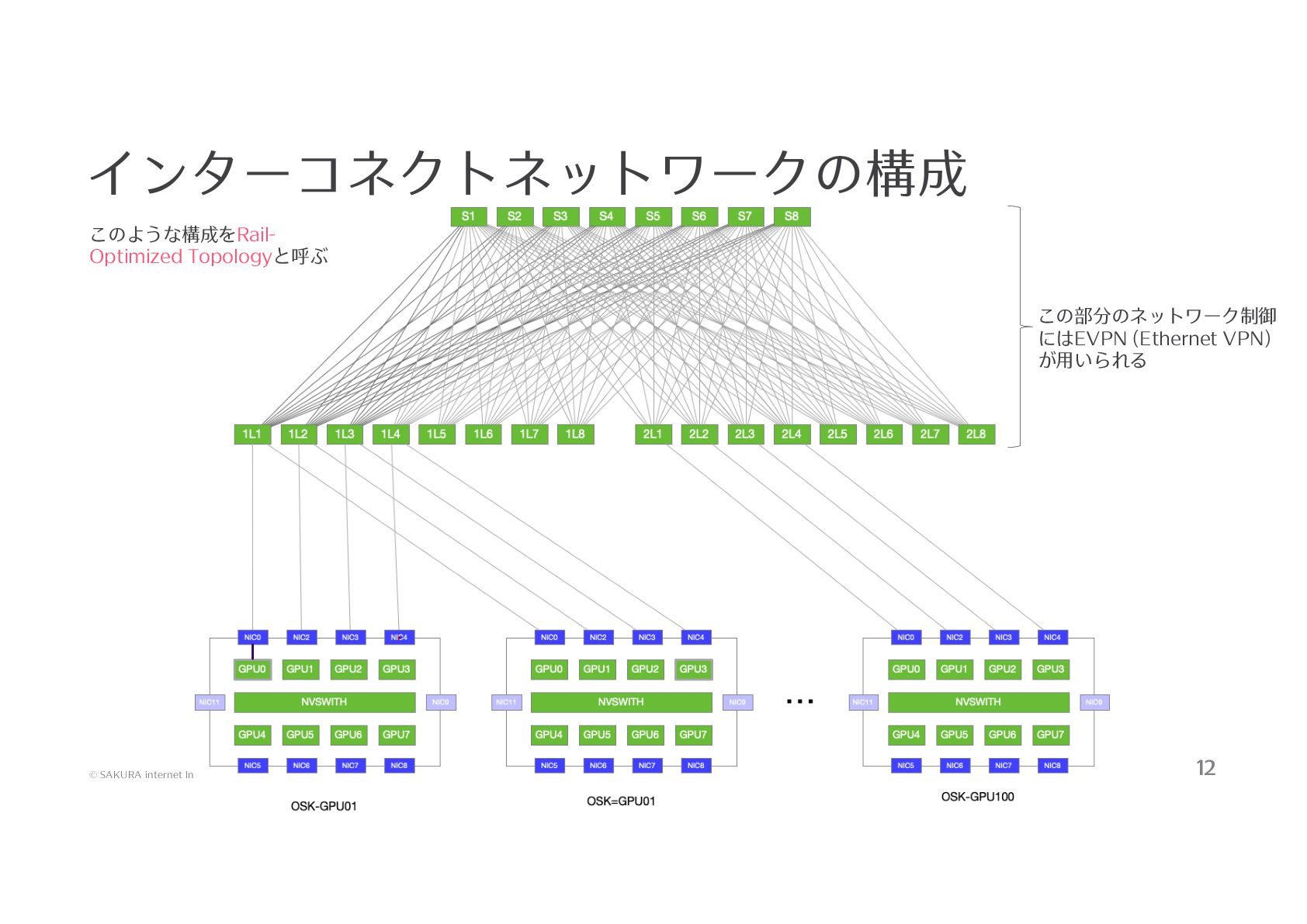
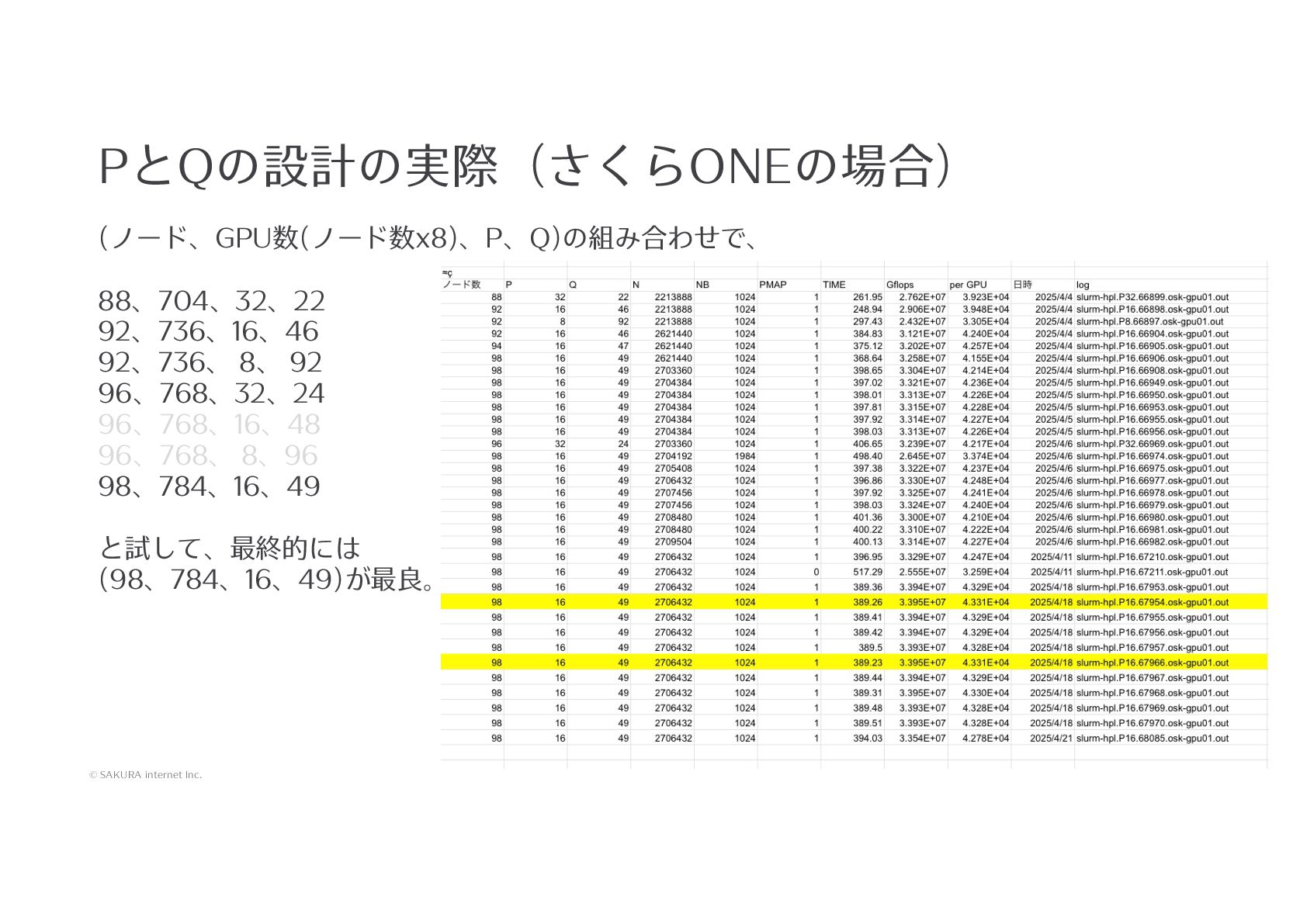
発表資料を公開いたします。 ほとんどが「さくらONE」の解説になっておりますので、ご参照ください。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© SAKURA internet Inc. TOP500で49位を獲得! 17 LINPACK : 33,950.00 [TFlop/s]](https://files.speakerdeck.com/presentations/bb6507005d0545c5a164ab00d00395c9/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
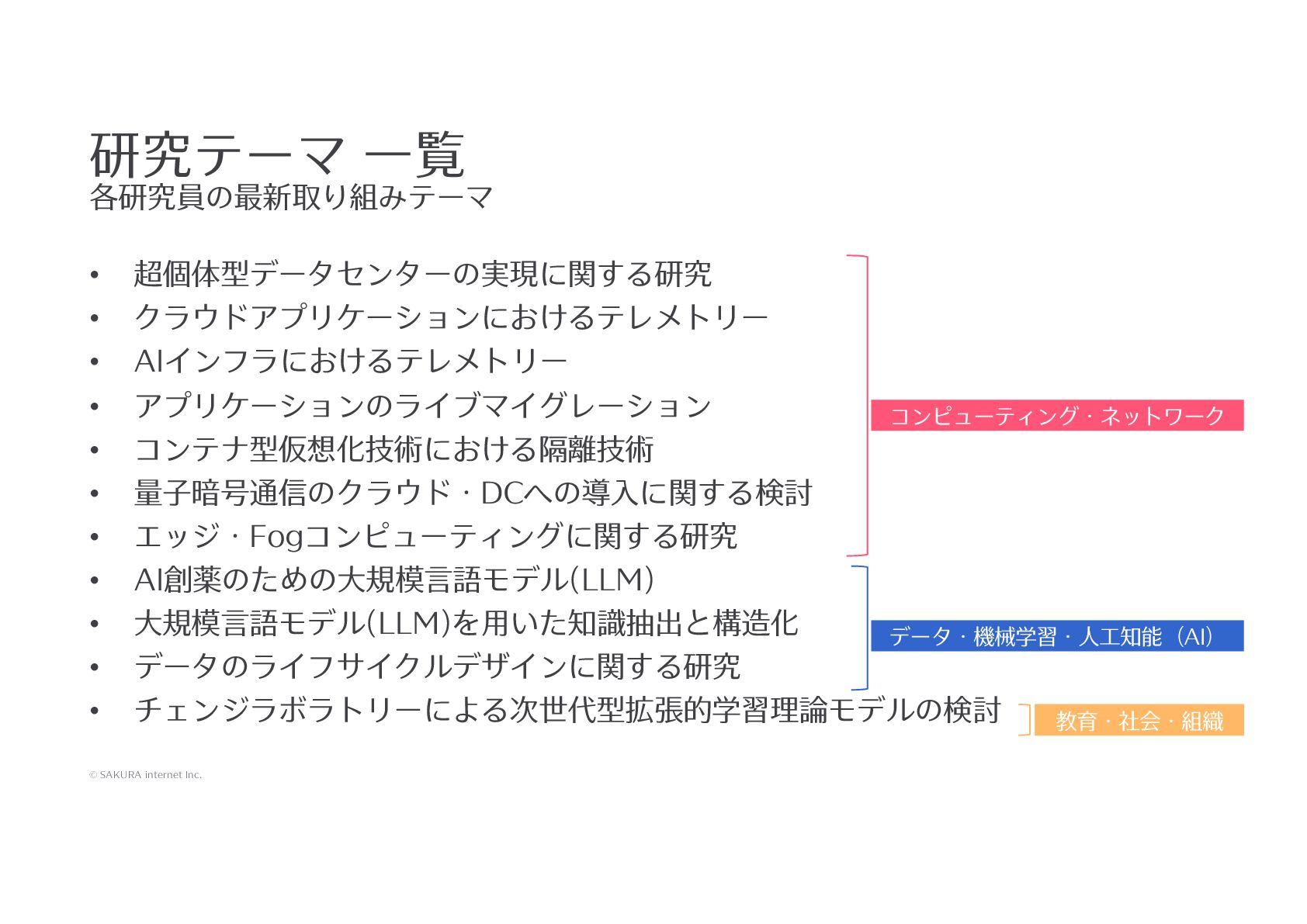{kind=link}
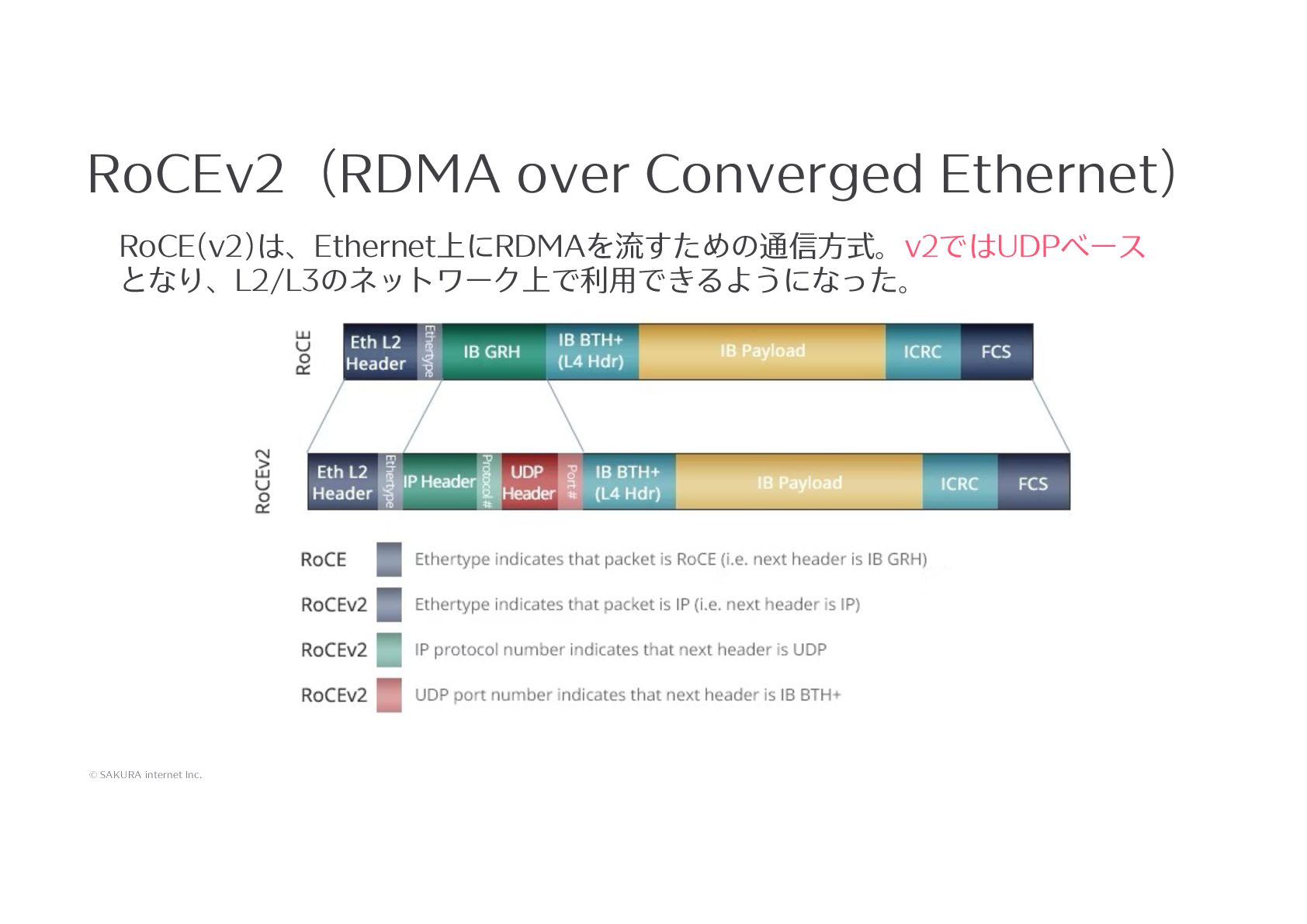{kind=link}
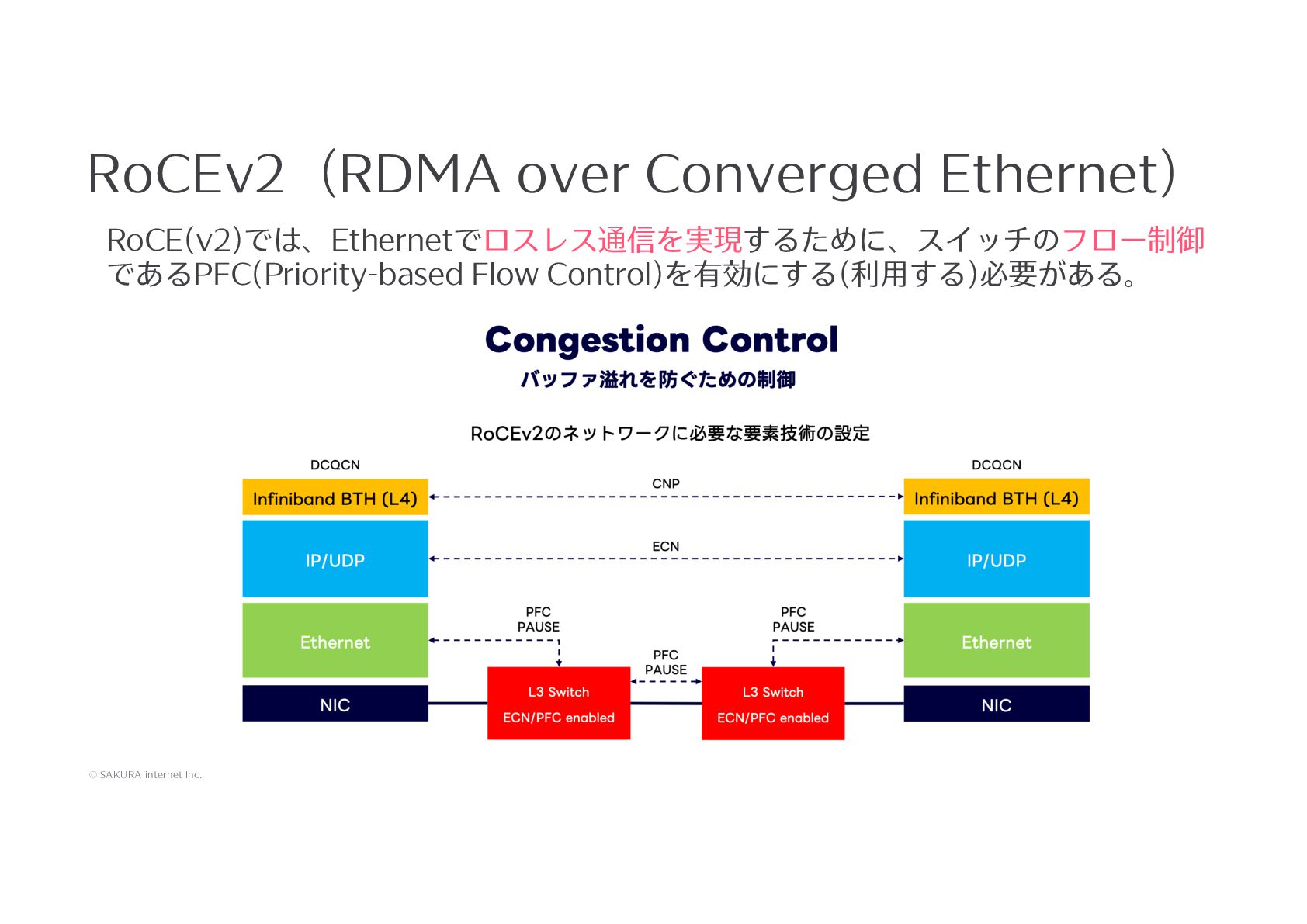{kind=link}
{kind=link}
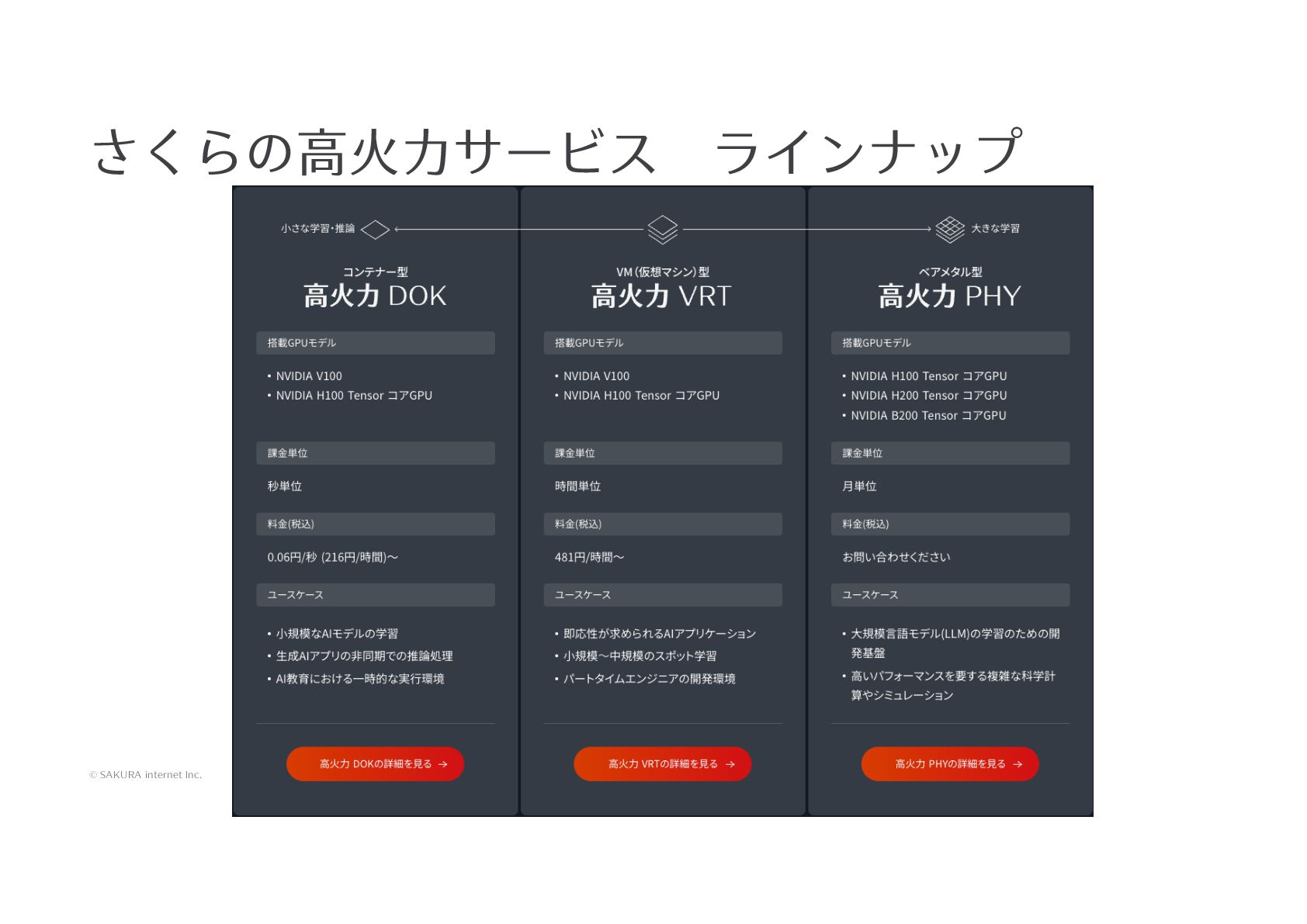{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© SAKURA internet Inc. ベンチマーク結果 LINPACK : 33,950.00 [TFlop/s] =](https://files.speakerdeck.com/presentations/bb6507005d0545c5a164ab00d00395c9/slide_38.jpg){kind=link}