type string length in bytes [n]T, *[n]T array length (== n) []T slice length map[K]T map length (number of defined keys) chan T number of elements queued in channel buffer type parameter see below cap(s) [n]T, *[n]T array length (== n) []T slice capacity chan T channel buffer capacity type parameter see below from: https://go.dev/ref/spec#Length_and_capacity
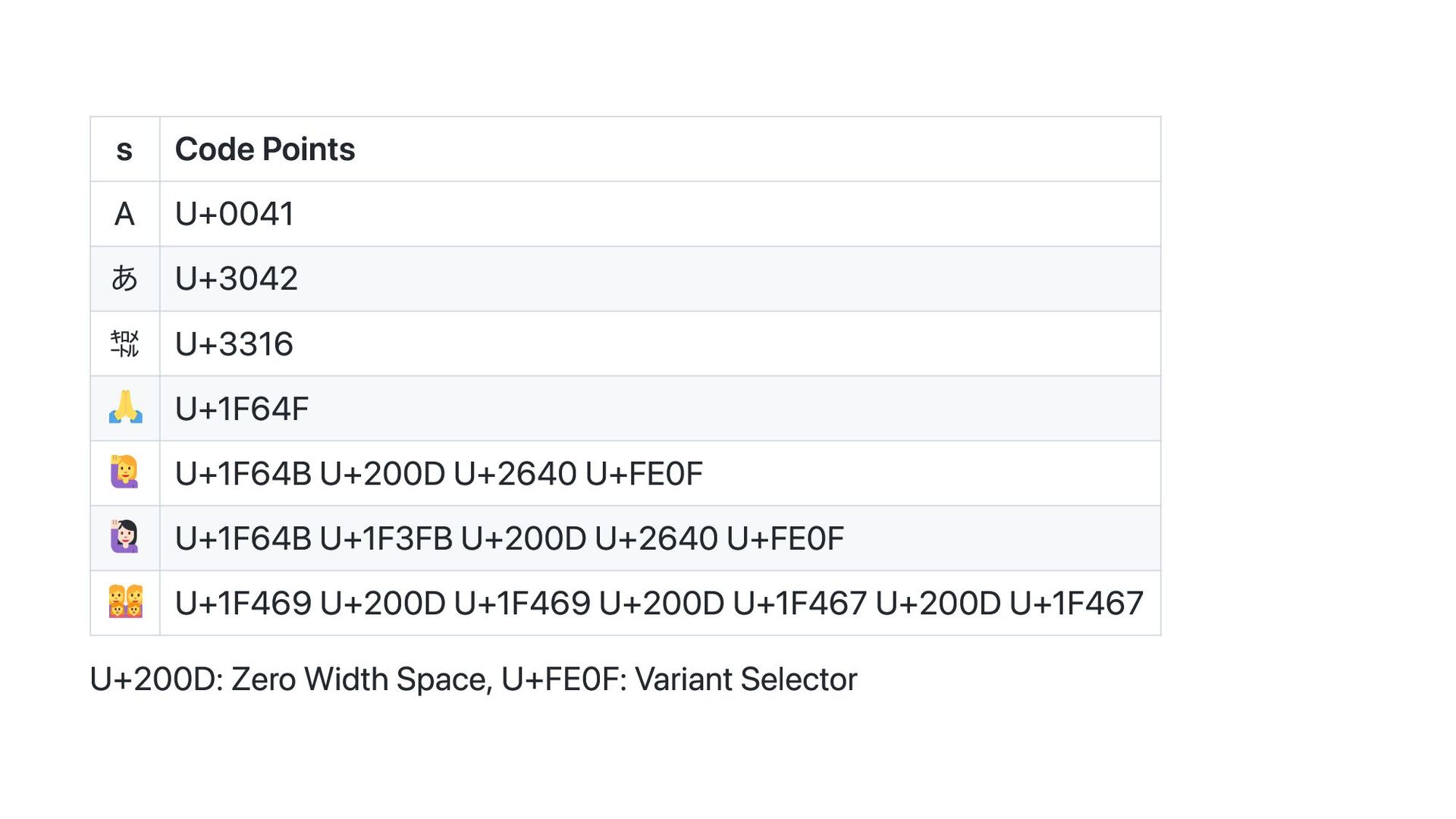
an integer value identifying a Unicode code point. A rune literal is expressed as one or more characters enclosed in single quotes, as in 'x' or '\n'. Within the quotes, any character may appear except newline and unescaped single quote. A single quoted character represents the Unicode value of the character itself, while multi-character sequences beginning with a backslash encode values in various formats. from: https://go.dev/ref/spec#Rune_literals
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![結果 s len(s) len([]rune(s)) A 1 1 あ 3 1](https://files.speakerdeck.com/presentations/38a7eaec910c450cbfaed934043f74ff/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![結果 s len(s) len([]rune(s)) uniseg.GraphemeClusterCount A 1 1 1 あ](https://files.speakerdeck.com/presentations/38a7eaec910c450cbfaed934043f74ff/slide_19.jpg){kind=link}
![「午前3時のいばらきけん」に様々な Combining Diacritical Mark をつけたテキスト。 Unicode的には11文字+いろんな修飾という認識になる。 len(s) len([]rune(s)) uniseg.GraphemeClusterCount 129](https://files.speakerdeck.com/presentations/38a7eaec910c450cbfaed934043f74ff/slide_20.jpg){kind=link}
{kind=link}