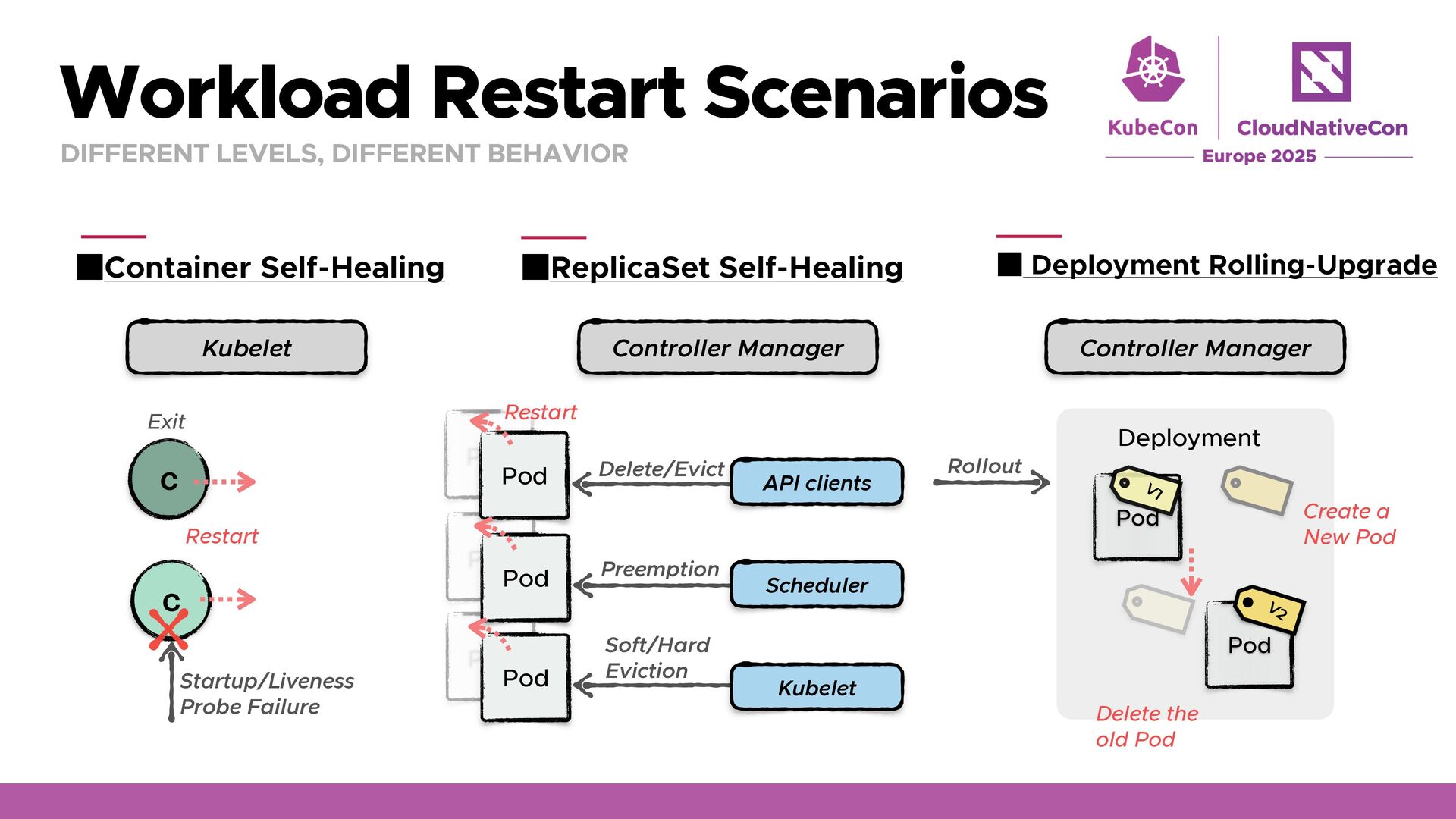
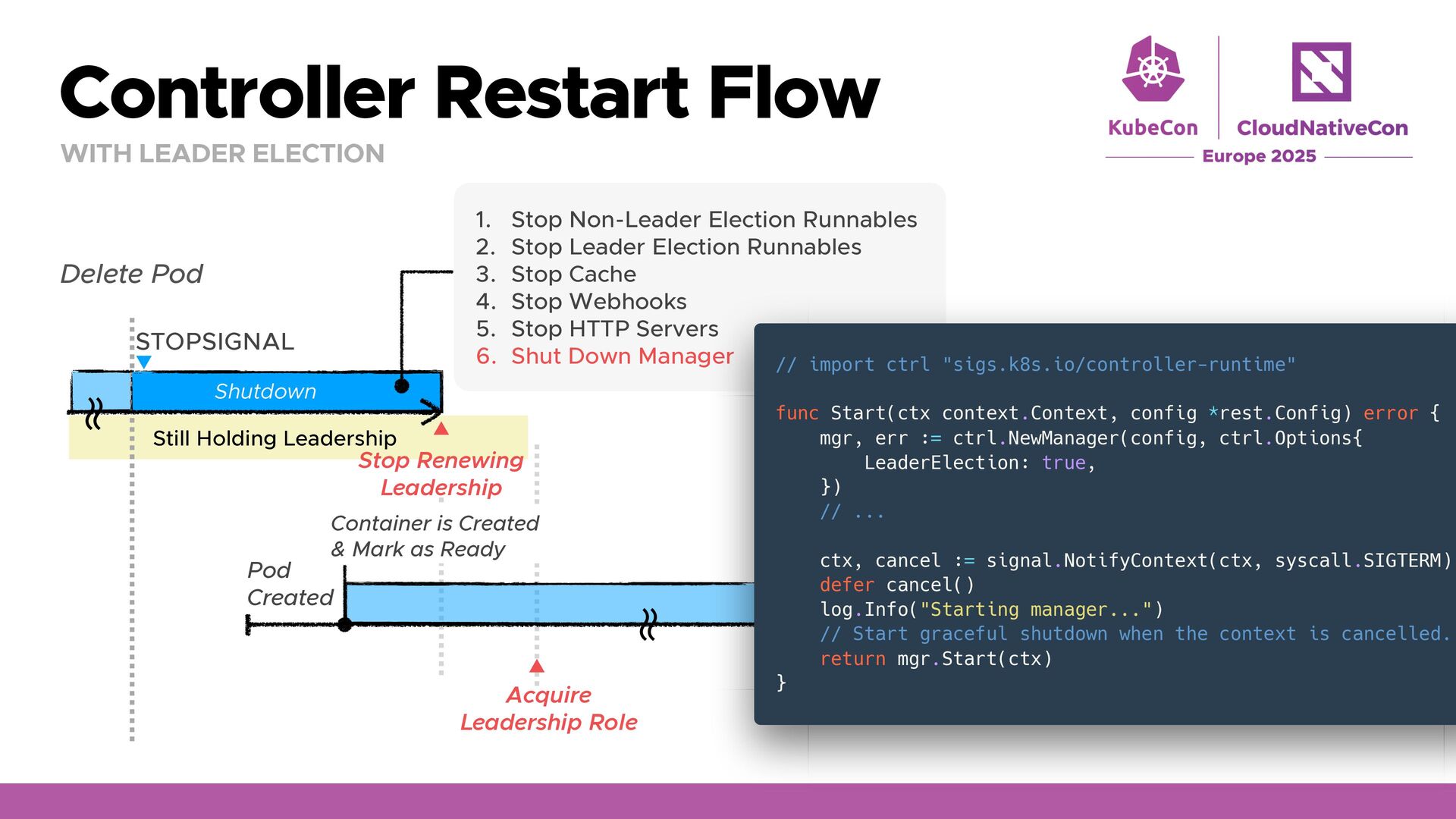
Restart Scenarios DIFFERENT LEVELS, DIFFERENT BEHAVIOR Container Self-Healing ReplicaSet Self-Healing Deployment Rolling-Upgrade Kubelet Rollout Controller Manager Controller Manager Startup/Liveness Probe Failure Exit C C C C Pod Pod Pod Pod Delete/Evict Preemption Soft/Hard Eviction API clients Scheduler Kubelet Pod Pod Restart Restart Create a New Pod Delete the old Pod
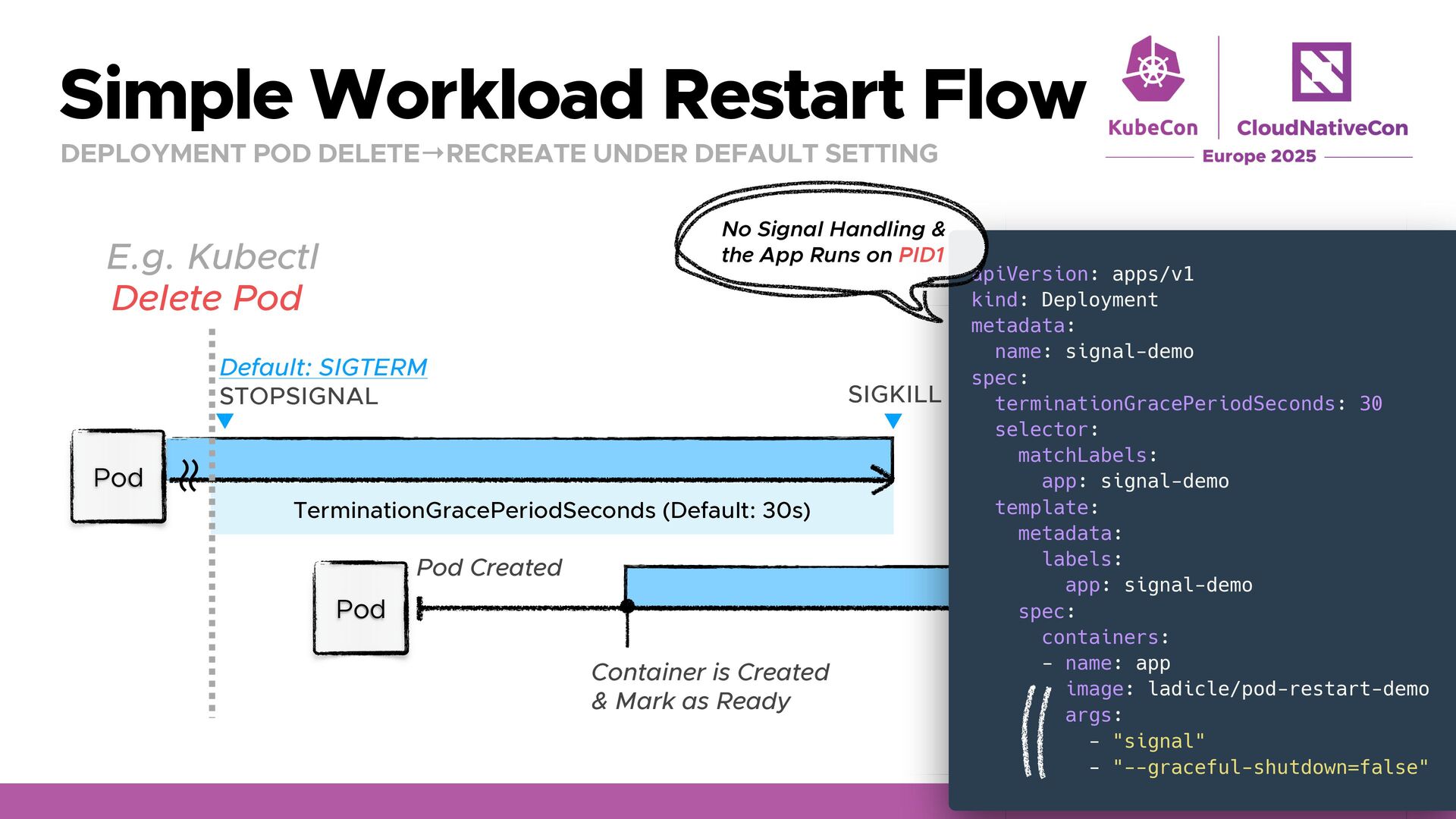
UNDER DEFAULT SETTING Delete Pod E.g. Kubectl Pod Default: SIGTERM STOPSIGNAL SIGKILL Pod Created Container is Created & Mark as Ready ʙ ʙ Pod apiVersion: apps/v1 kind: Deployment metadata: name: signal-demo spec: terminationGracePeriodSeconds: 30 selector: matchLabels: app: signal-demo template: metadata: labels: app: signal-demo spec: containers: - name: app image: ladicle/pod-restart-demo args: - "signal" - "--graceful-shutdown=false" No Signal Handling & the App Runs on PID1
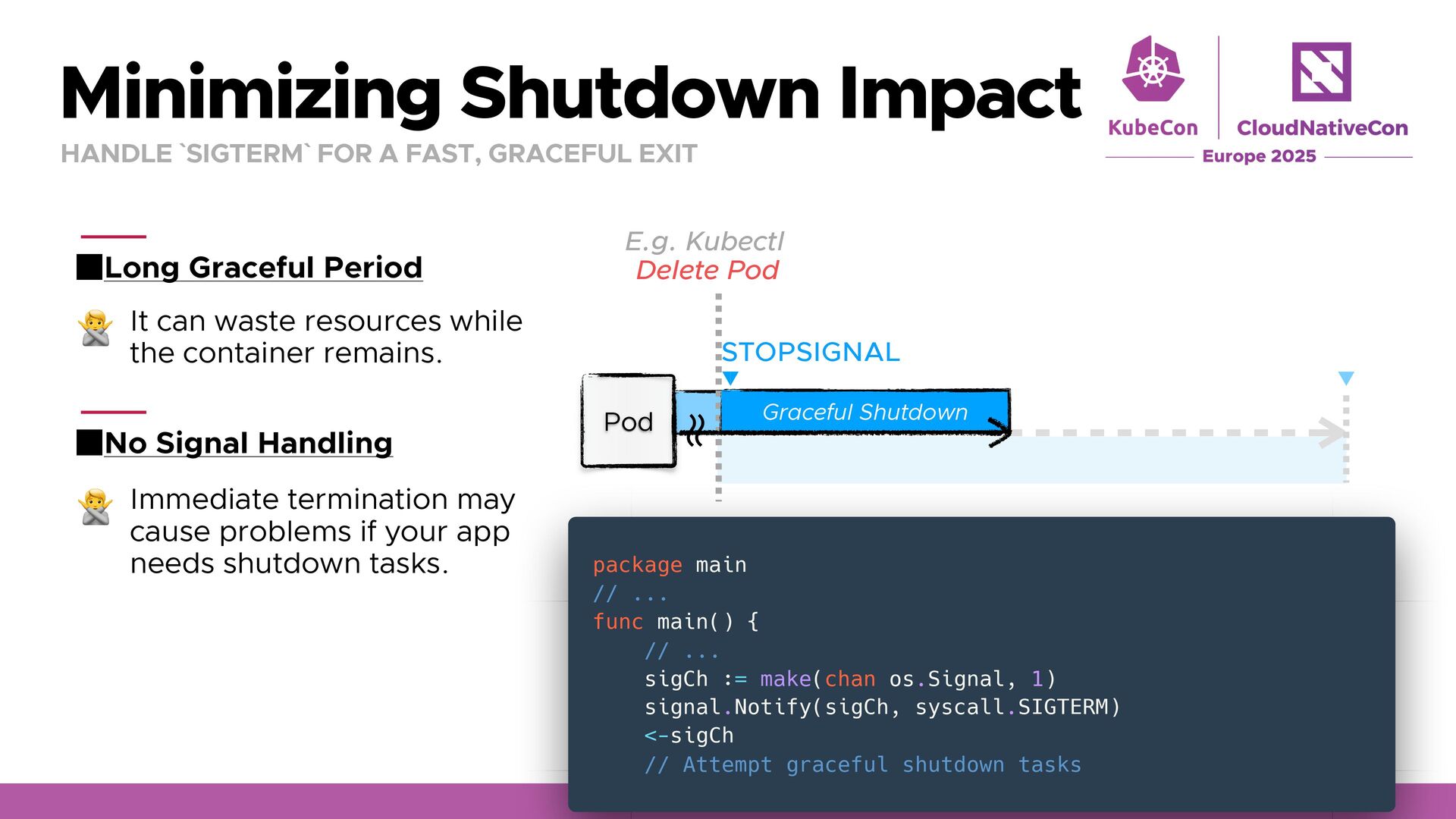
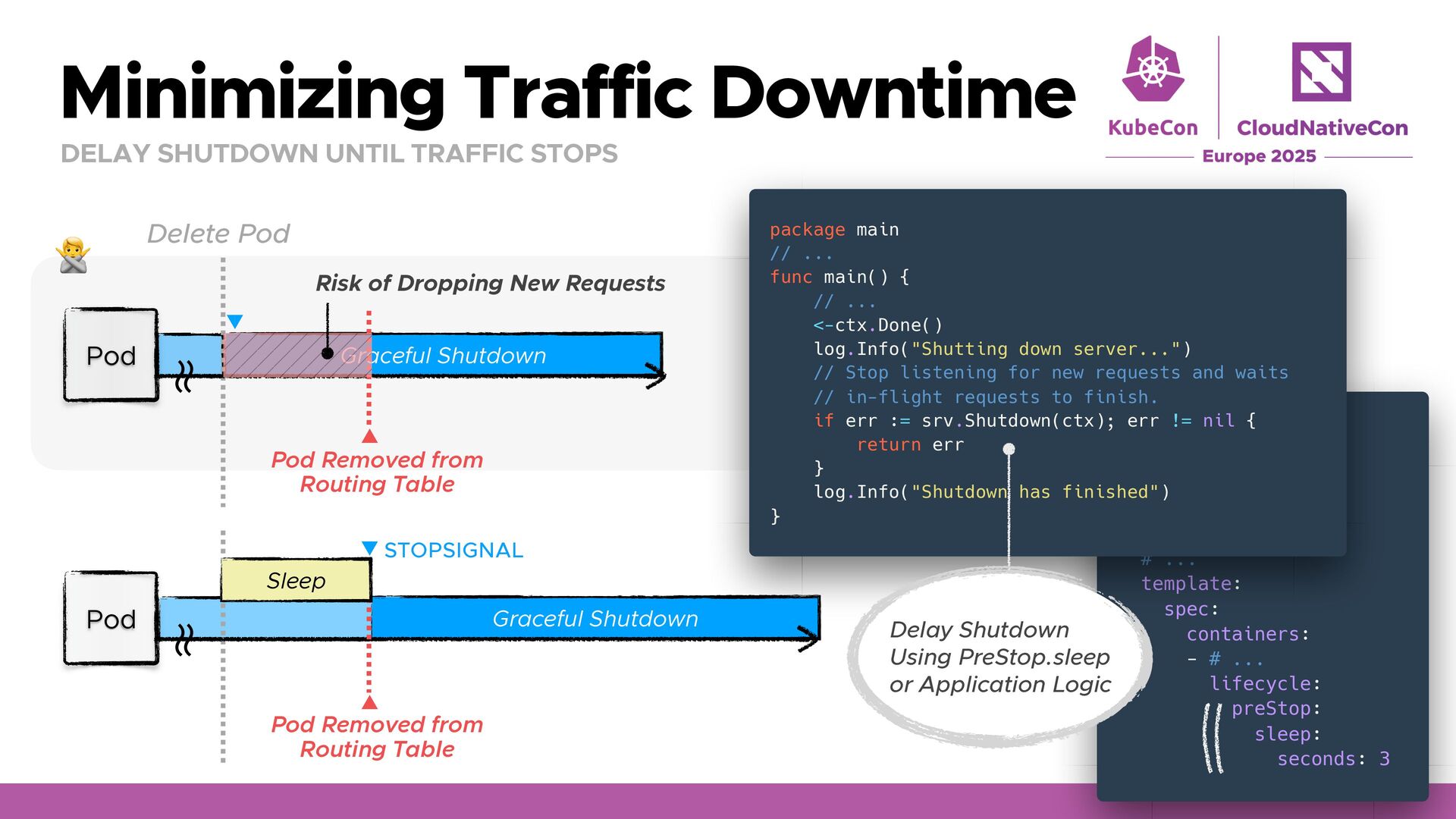
FAST, GRACEFUL EXIT No Signal Handling It can waste resources while the container remains. 🙅 Immediate termination may cause problems if your app needs shutdown tasks. 🙅 TerminationGracePeriodSeconds (Default: 30s) Delete Pod E.g. Kubectl Pod STOPSIGNAL Graceful Shutdown SIGKILL ʙ ʙ package main // ... func main() { // ... sigCh := make(chan os.Signal, 1) signal.Notify(sigCh, syscall.SIGTERM) <-sigCh // Attempt graceful shutdown tasks
SIGNAL HANDLING WAYS FOR THIRD-PARTY APPS (1) Set the custom signal for the container to terminate. (Default: SIGTERM) Container Lifecycle Hook: PreStop PreStop hook is called immediately before a container is terminated. FROM gcr.io/distroless/static-debian12:nonroot STOPSIGNAL SIGQUIT COPY --from=builder /out/demo /bin/ ENTRYPOINT ["/bin/demo"] 👉 Dockerfile: STOPSIGNAL
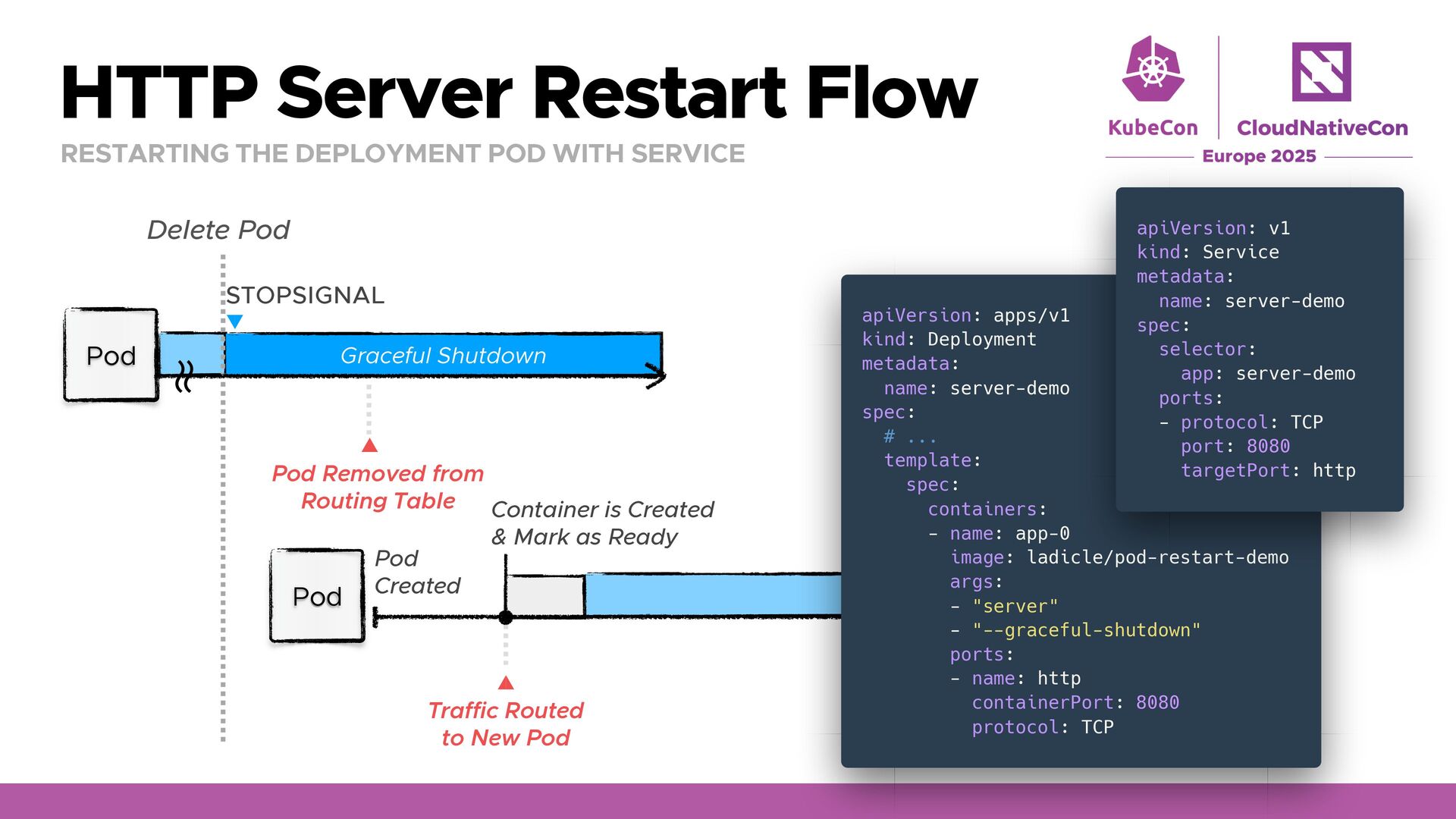
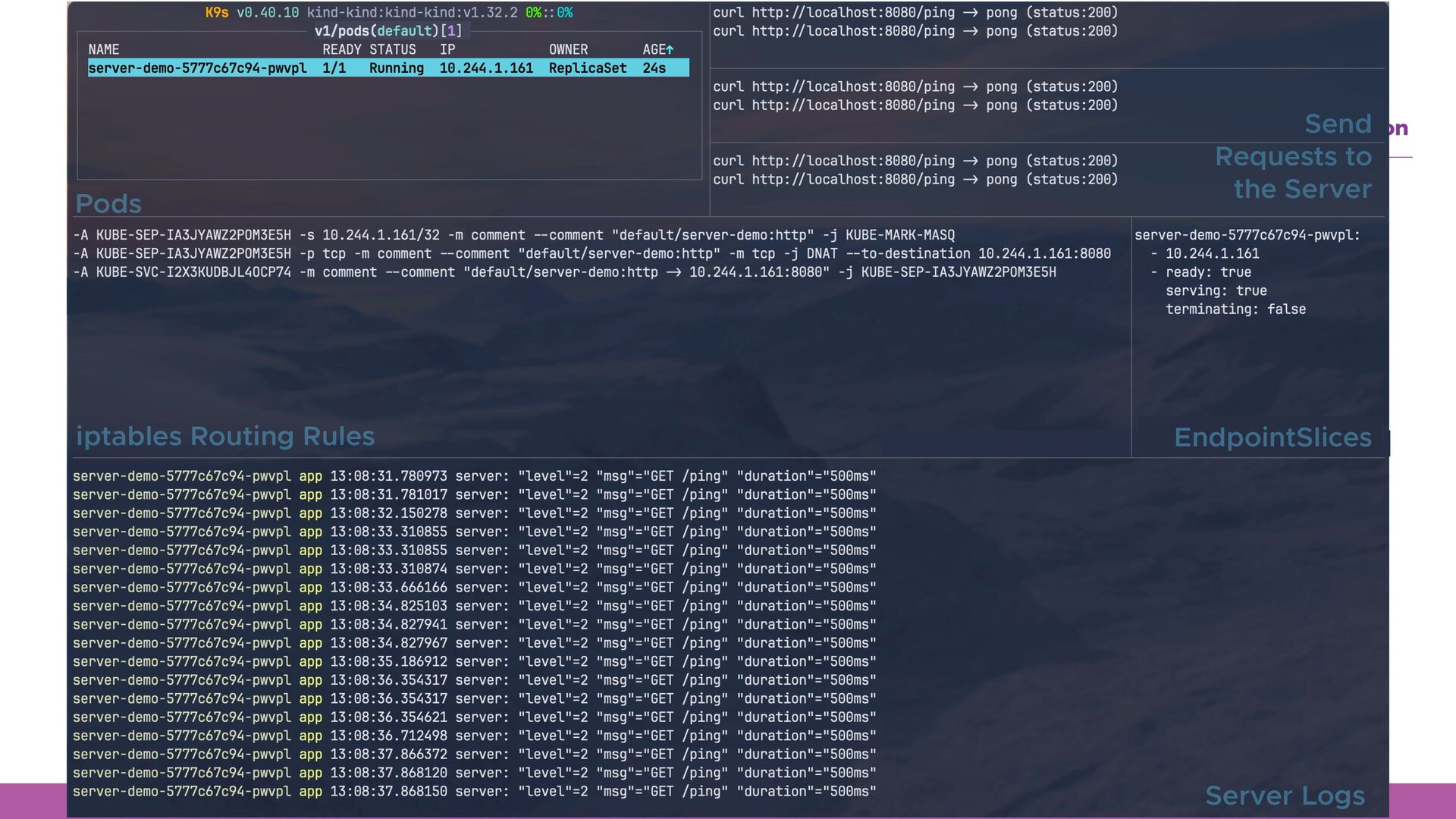
WITH SERVICE Receiving Traffic Delete Pod Pod STOPSIGNAL Graceful Shutdown ʙ ʙ Pod Pod Created Container is Created & Mark as Ready Traffic Routed to New Pod Pod Removed from Routing Table apiVersion: apps/v1 kind: Deployment metadata: name: server-demo spec: # ... template: spec: containers: - name: app-0 image: ladicle/pod-restart-demo args: - "server" - "--graceful-shutdown" ports: - name: http containerPort: 8080 protocol: TCP apiVersion: v1 kind: Service metadata: name: server-demo spec: selector: app: server-demo ports: - protocol: TCP port: 8080 targetPort: http
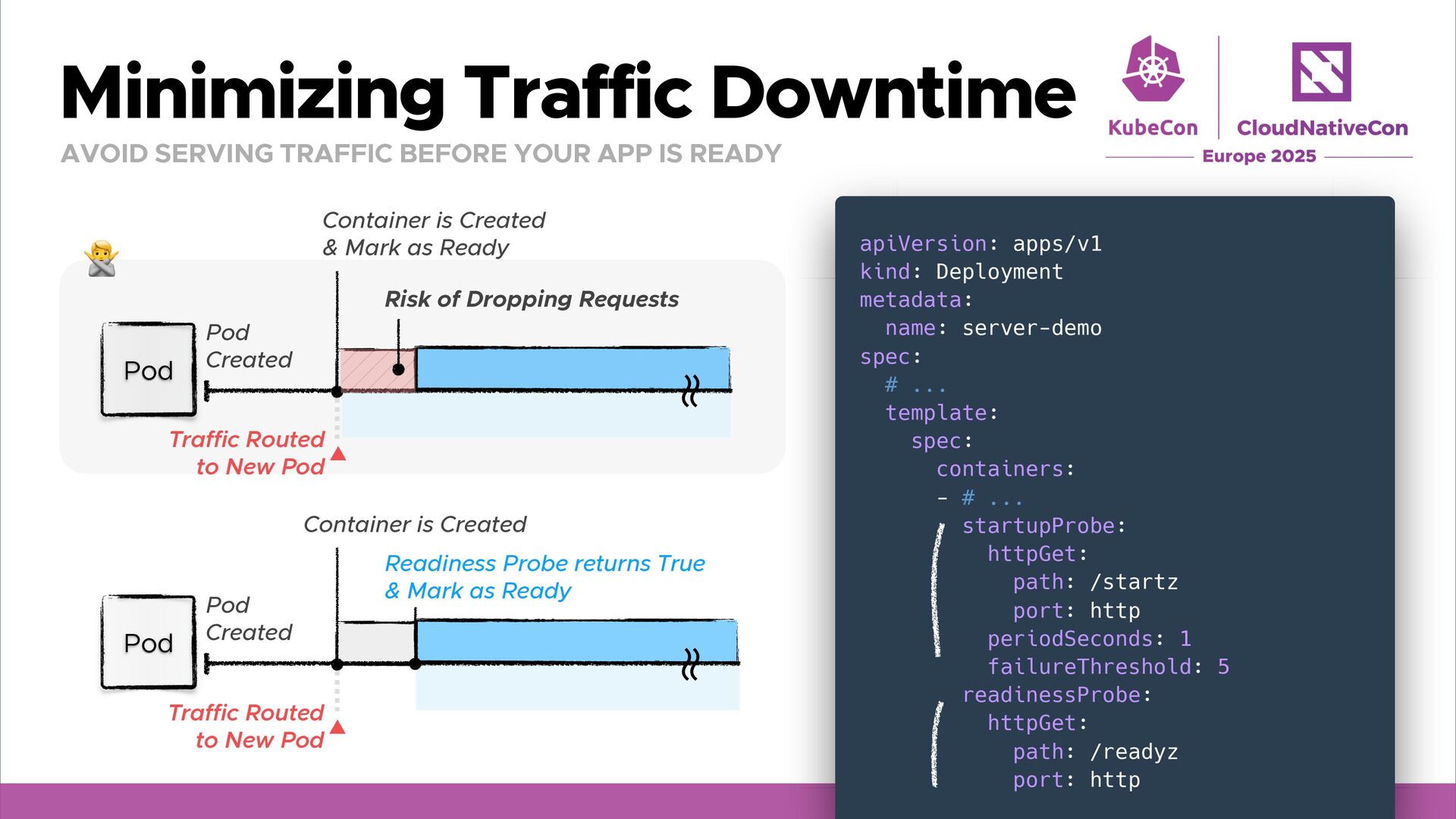
READY Receiving Traffic Pod Pod Created Container is Created & Mark as Ready Traffic Routed to New Pod Risk of Dropping Requests Receiving Traffic Pod Pod Created Container is Created Readiness Probe returns True & Mark as Ready Traffic Routed to New Pod 🙅 apiVersion: apps/v1 kind: Deployment metadata: name: server-demo spec: # ... template: spec: containers: - # ... startupProbe: httpGet: path: /startz port: http periodSeconds: 1 failureThreshold: 5 readinessProbe: httpGet: path: /readyz port: http ʙ ʙ ʙ ʙ
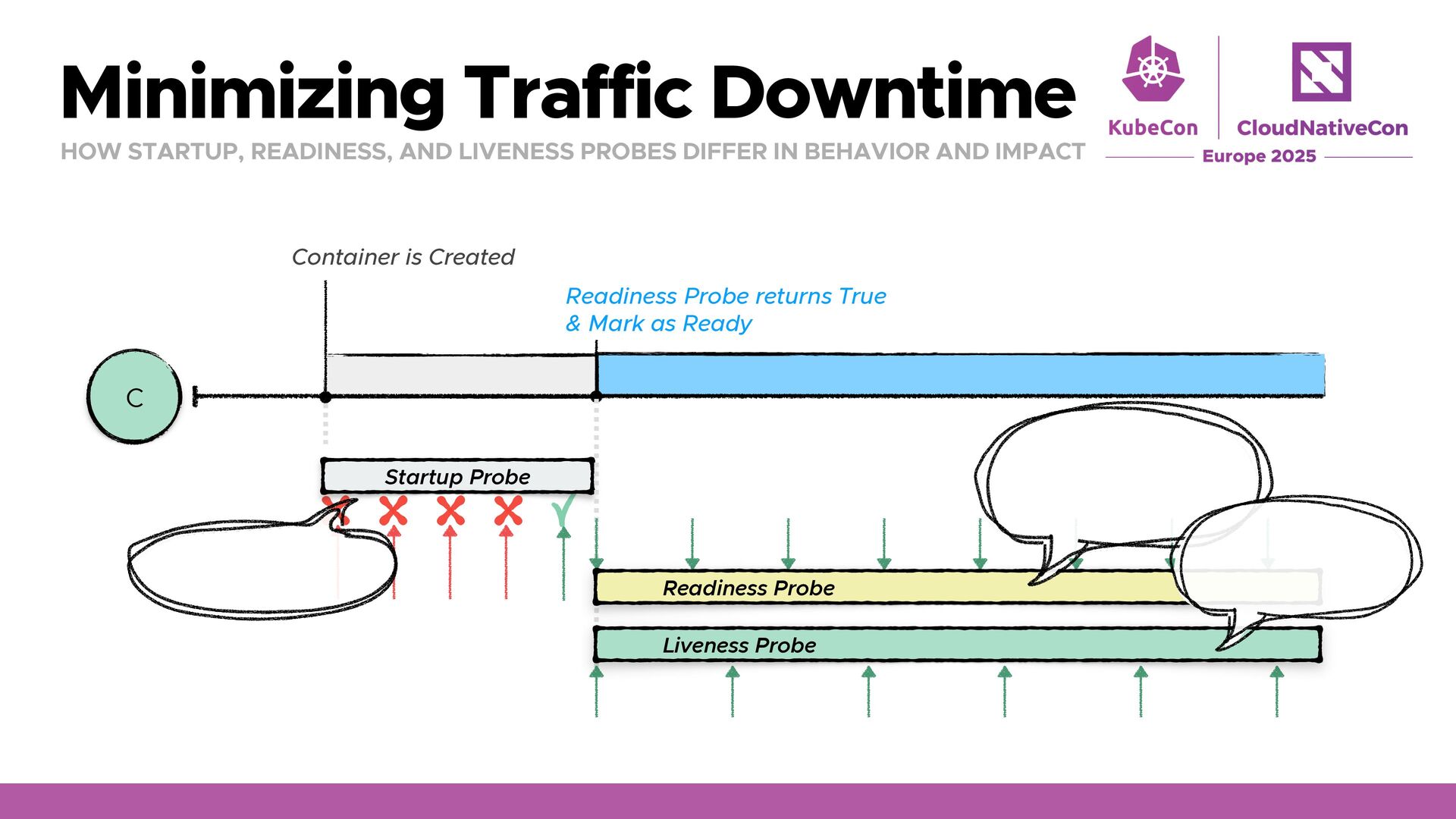
IN BEHAVIOR AND IMPACT ɹɹɹɹ Receiving Traffic Container is Created Readiness Probe returns True & Mark as Ready C Startup Probe Readiness Probe Liveness Probe Restarted on failure Removed from Service endpoints on failure Restarted on failure
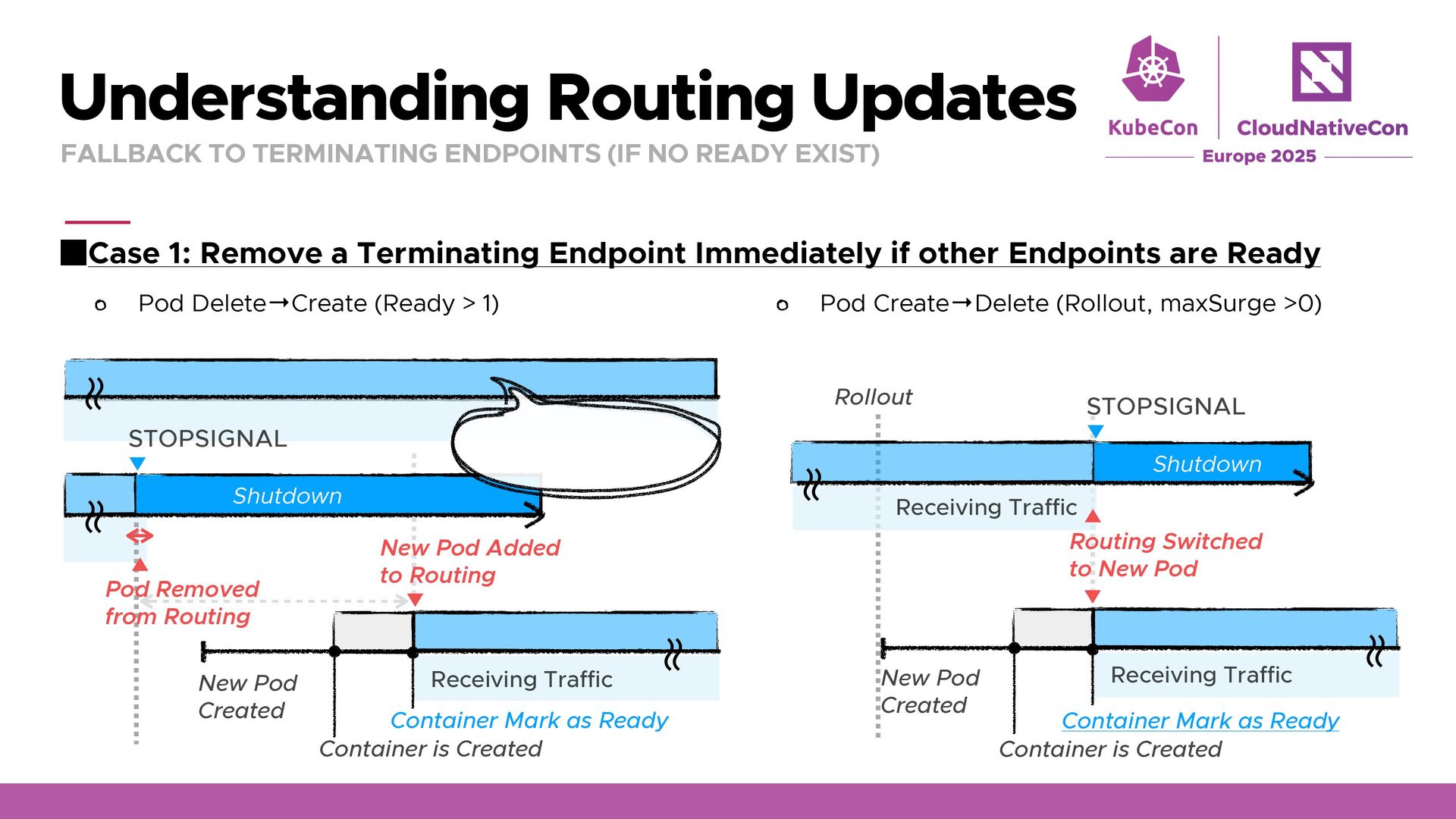
are Ready Pod Delete→Create (Ready > 1) Understanding Routing Updates FALLBACK TO TERMINATING ENDPOINTS (IF NO READY EXIST) Pod Create→Delete (Rollout, maxSurge >0) ʙ ʙ STOPSIGNAL New Pod Created Container is Created Container Mark as Ready New Pod Added to Routing Shutdown Receiving Traffic ʙ ʙ Pod Removed from Routing ʙ ʙ Traffic is Served by Other Replicas New Pod Created Container is Created Container Mark as Ready Receiving Traffic ʙ ʙ Rollout ʙ ʙ Routing Switched to New Pod Shutdown Receiving Traffic STOPSIGNAL
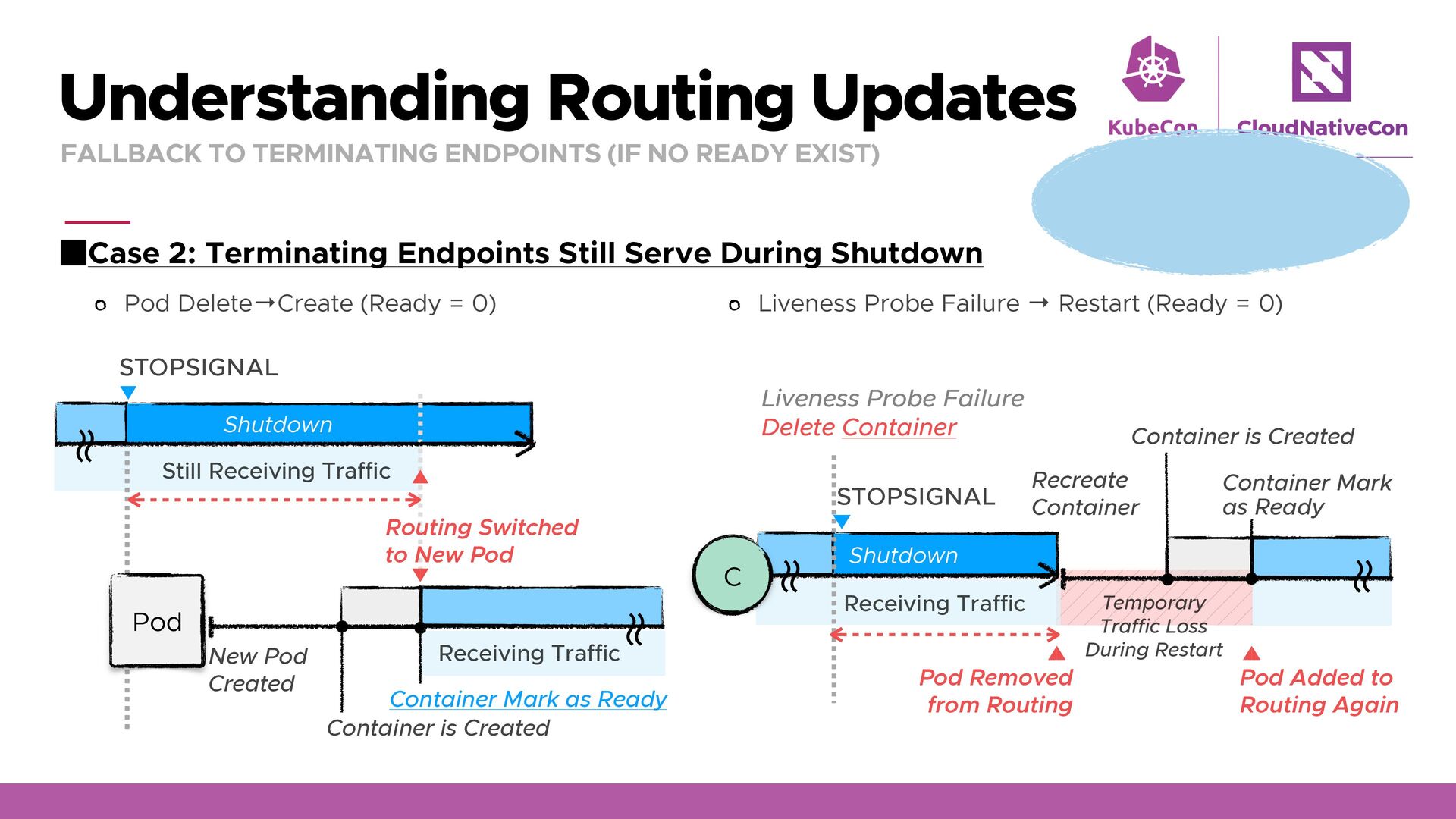
Serve During Shutdown Understanding Routing Updates FALLBACK TO TERMINATING ENDPOINTS (IF NO READY EXIST) Pod Delete→Create (Ready = 0) ʙ ʙ STOPSIGNAL Recreate Container Pod Added to Routing Again Shutdown ʙ ʙ Pod Removed from Routing Liveness Probe Failure Delete Container Container is Created Container Mark as Ready Receiving Traffic Temporary Traffic Loss During Restart C Liveness Probe Failure → Restart (Ready = 0) ʙ ʙ STOPSIGNAL New Pod Created Container is Created Container Mark as Ready Routing Switched to New Pod Shutdown Still Receiving Traffic Receiving Traffic ʙ ʙ Pod
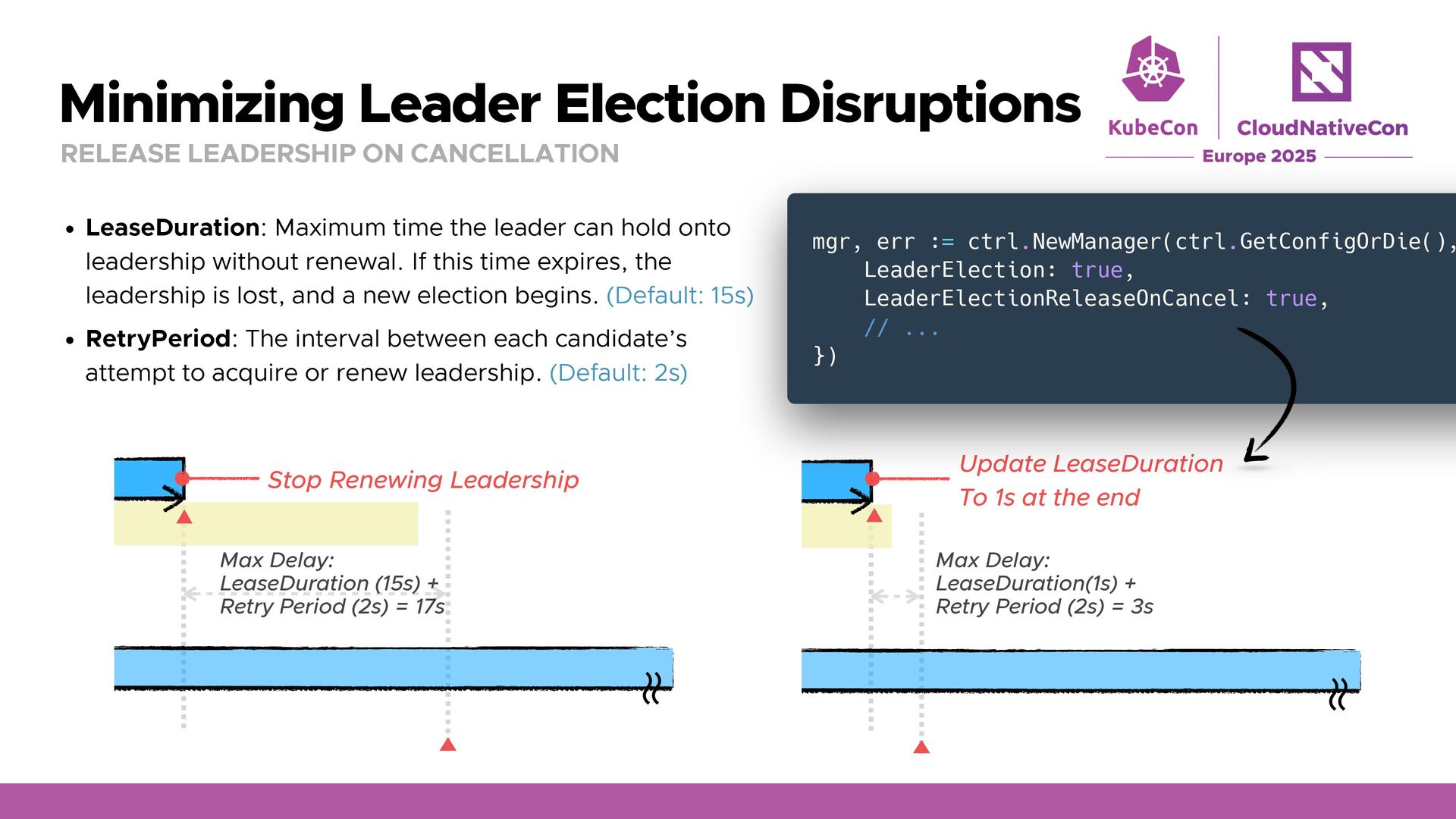
= 17s ʙ ʙ Stop Renewing Leadership Minimizing Leader Election Disruptions RELEASE LEADERSHIP ON CANCELLATION • LeaseDuration: Maximum time the leader can hold onto leadership without renewal. If this time expires, the leadership is lost, and a new election begins. (Default: 15s) • RetryPeriod: The interval between each candidate’s attempt to acquire or renew leadership. (Default: 2s) apiVersion: coordination.k8s.io/v1 kind: Lease metadata: name: controller-demo namespace: default # ... spec: holderIdentity: controller-demo-e7c7d31534-b698j_42 leaseDurationSeconds: 15 leaseTransitions: 1 acquireTime: "2025-04-04T14:30:17.572844Z" renewTime: "2025-04-04T15:00:29.117662Z" Lease 1. Success to update Lock Shared Resource Leader 2. Failed to Update Pod A Pod B Pod A
3s ʙ ʙ Update LeaseDuration To 1s at the end Holding Leadership Max Delay: LeaseDuration (15s) + Retry Period (2s) = 17s ʙ ʙ Stop Renewing Leadership Minimizing Leader Election Disruptions RELEASE LEADERSHIP ON CANCELLATION • LeaseDuration: Maximum time the leader can hold onto leadership without renewal. If this time expires, the leadership is lost, and a new election begins. (Default: 15s) • RetryPeriod: The interval between each candidate’s attempt to acquire or renew leadership. (Default: 2s) mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), LeaderElection: true, LeaderElectionReleaseOnCancel: true, // ... })
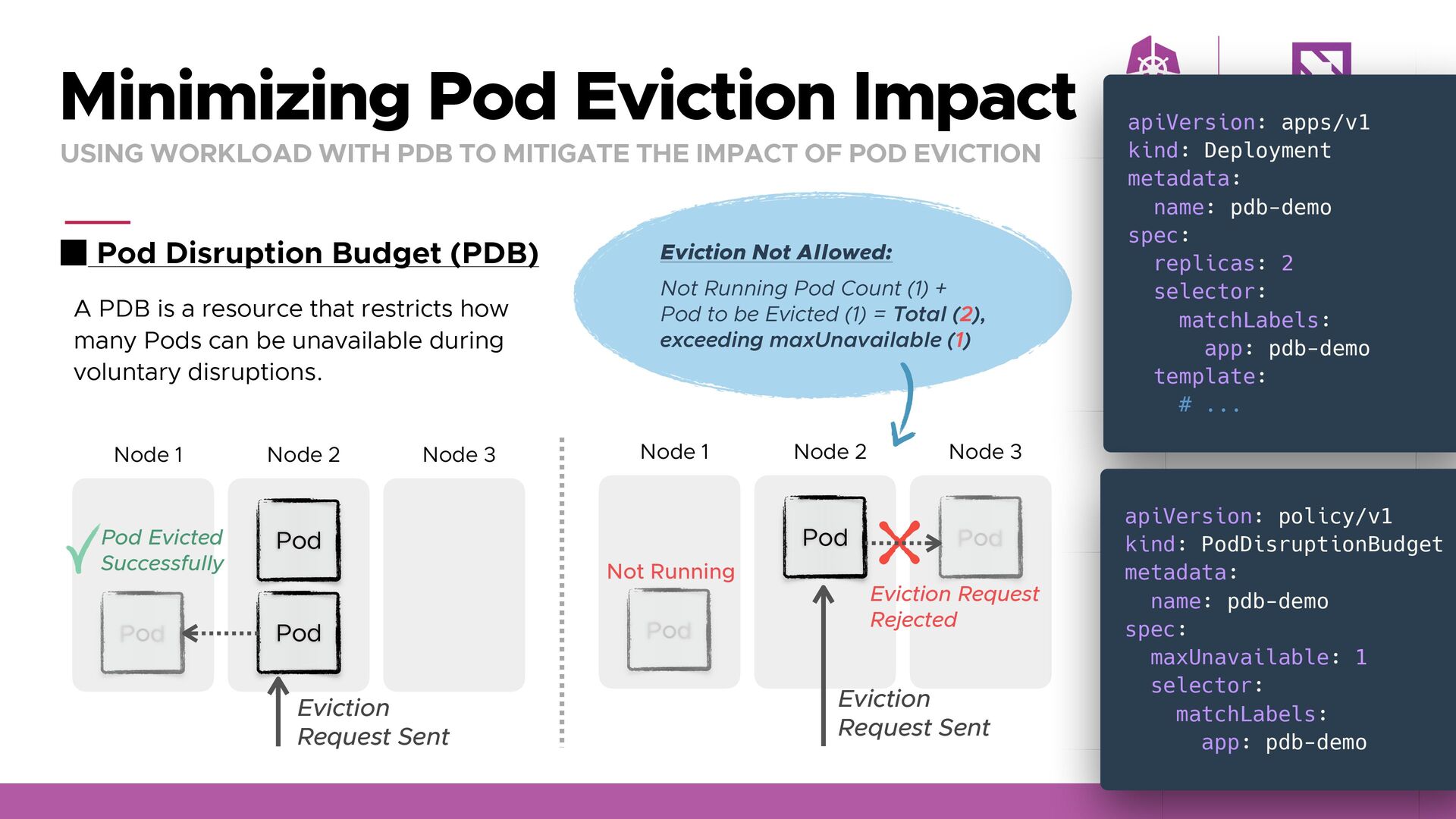
selector: matchLabels: app: pdb-demo template: # ... Pod Node 1 Pod Node 2 Node 3 Pod Minimizing Pod Eviction Impact USING WORKLOAD WITH PDB TO MITIGATE THE IMPACT OF POD EVICTION apiVersion: policy/v1 kind: PodDisruptionBudget metadata: name: pdb-demo spec: maxUnavailable: 1 selector: matchLabels: app: pdb-demo Pod Node 1 Pod Node 2 Node 3 Pod Eviction Request Sent Pod Evicted Successfully Not Running Eviction Request Sent Eviction Request Rejected Eviction Not Allowed: Not Running Pod Count (1) + Pod to be Evicted (1) = Total (2), exceeding maxUnavailable (1) Pod Disruption Budget (PDB) A PDB is a resource that restricts how many Pods can be unavailable during voluntary disruptions.
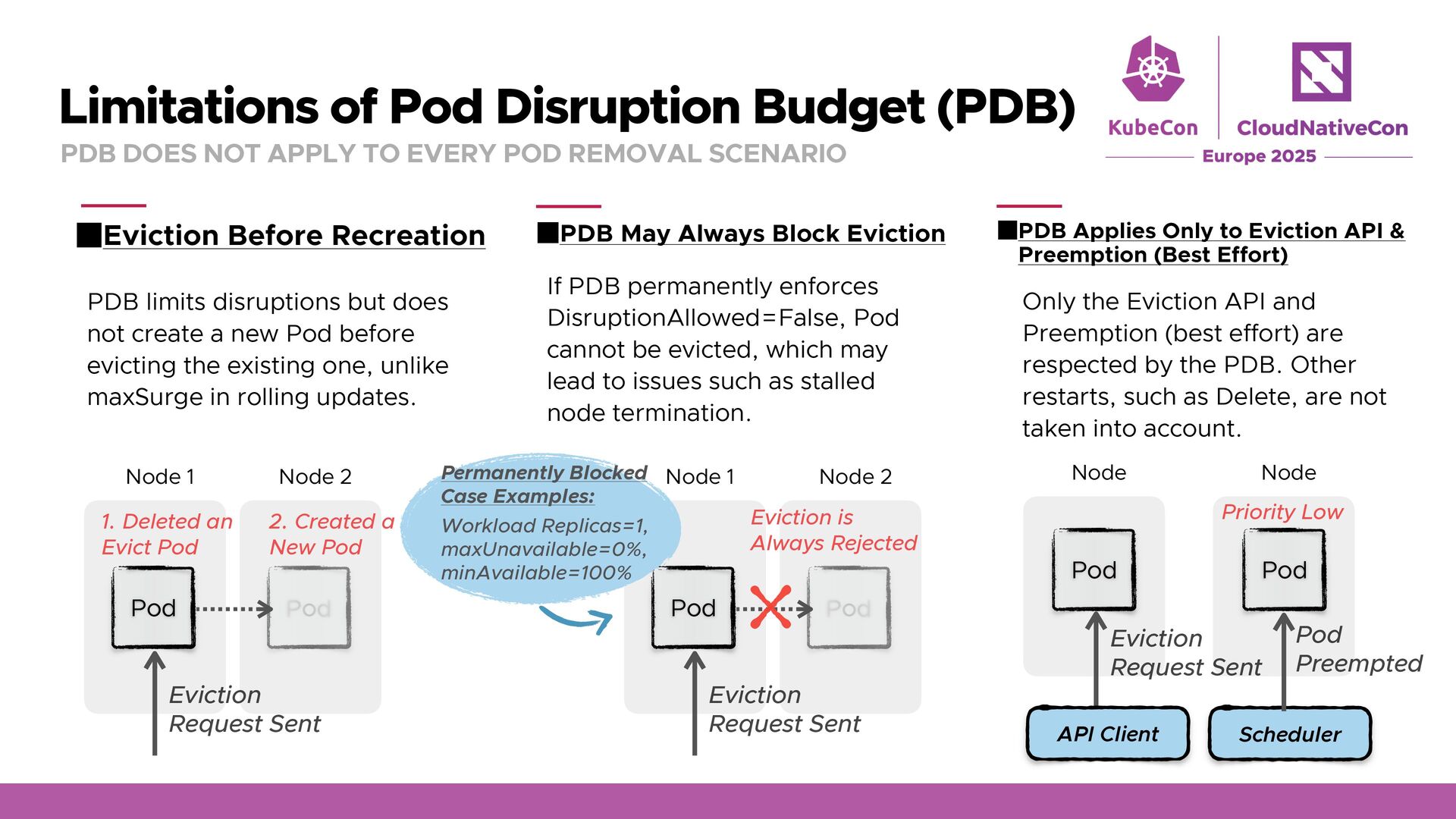
TO EVERY POD REMOVAL SCENARIO Eviction Before Recreation PDB May Always Block Eviction PDB Applies Only to Eviction API & Preemption (Best Effort) Pod Node 1 Node 2 Pod Eviction Request Sent 1. Deleted an Evict Pod 2. Created a New Pod PDB limits disruptions but does not create a new Pod before evicting the existing one, unlike maxSurge in rolling updates. If PDB permanently enforces DisruptionAllowed=False, Pod cannot be evicted, which may lead to issues such as stalled node termination. Pod Node 1 Node 2 Pod Eviction Request Sent Eviction is Always Rejected Permanently Blocked Case Examples: Workload Replicas=1, maxUnavailable=0%, minAvailable=100% Only the Eviction API and Preemption (best effort) are respected by the PDB. Other restarts, such as Delete, are not taken into account. Scheduler Pod Node Node Pod Pod Preempted Priority Low Eviction Request Sent API Client
TO EVERY POD REMOVAL SCENARIO Eviction Before Recreation PDB May Always Block Eviction PDB Applies Only to Eviction API & Preemption (Best Effort) Pod Node 1 Node 2 Pod Eviction Request Sent 1. Deleted an Evict Pod 2. Created a New Pod PDB limits disruptions but does not create a new Pod before evicting the existing one, unlike maxSurge in rolling updates. If PDB permanently enforces DisruptionAllowed=False, Pod cannot be evicted, which may lead to issues such as stalled node termination. Pod Node 1 Node 2 Pod Eviction Request Sent Eviction is Always Rejected Permanently Blocked Case Examples: Workload Replicas=1, maxUnavailable=0%, minAvailable=100% Only the Eviction API and Preemption (best effort) are respected by the PDB. Other restarts, such as Delete, are not taken into account. Scheduler Pod Node Node Pod Pod Preempted Priority Low Eviction Request Sent API Client apiVersion: policy/v1 kind: PodDisruptionBudget metadata: name: pdb-demo spec: maxUnavailable: 1 unhealthyPodEvictionPolicy: AlwaysAllow selector: matchLabels: app: pdb-demo This field ensures evictions are not permanently blocked when an app has a bug and is never in a Running state.
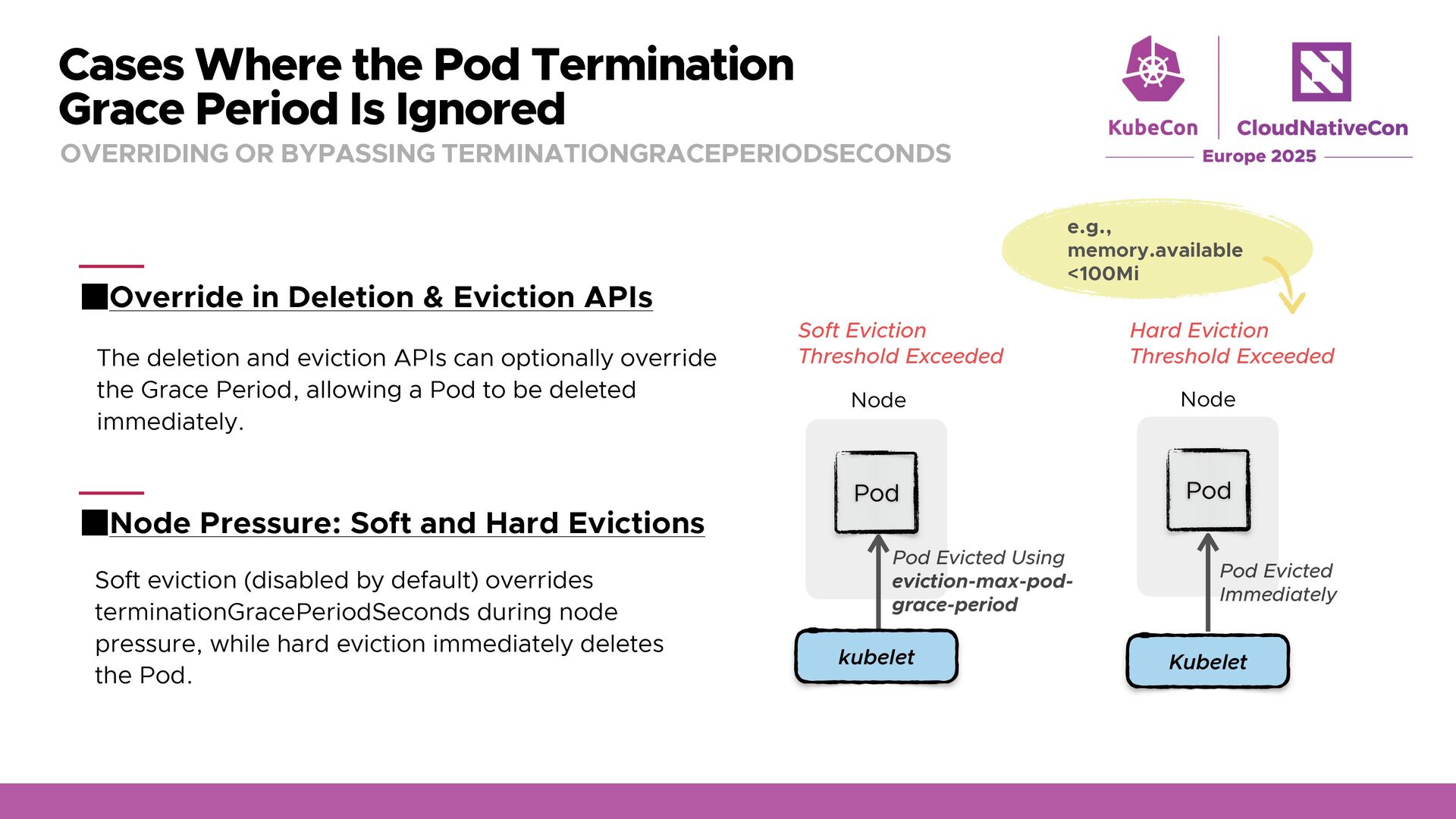
OR BYPASSING TERMINATIONGRACEPERIODSECONDS Override in Deletion & Eviction APIs Node Pressure: Soft and Hard Evictions The deletion and eviction APIs can optionally override the Grace Period, allowing a Pod to be deleted immediately. Soft eviction (disabled by default) overrides terminationGracePeriodSeconds during node pressure, while hard eviction immediately deletes the Pod. Kubelet Node Pod Pod Evicted Immediately Hard Eviction Threshold Exceeded Pod Node Pod Evicted Using eviction-max-pod- grace-period kubelet Soft Eviction Threshold Exceeded e.g., memory.available <100Mi
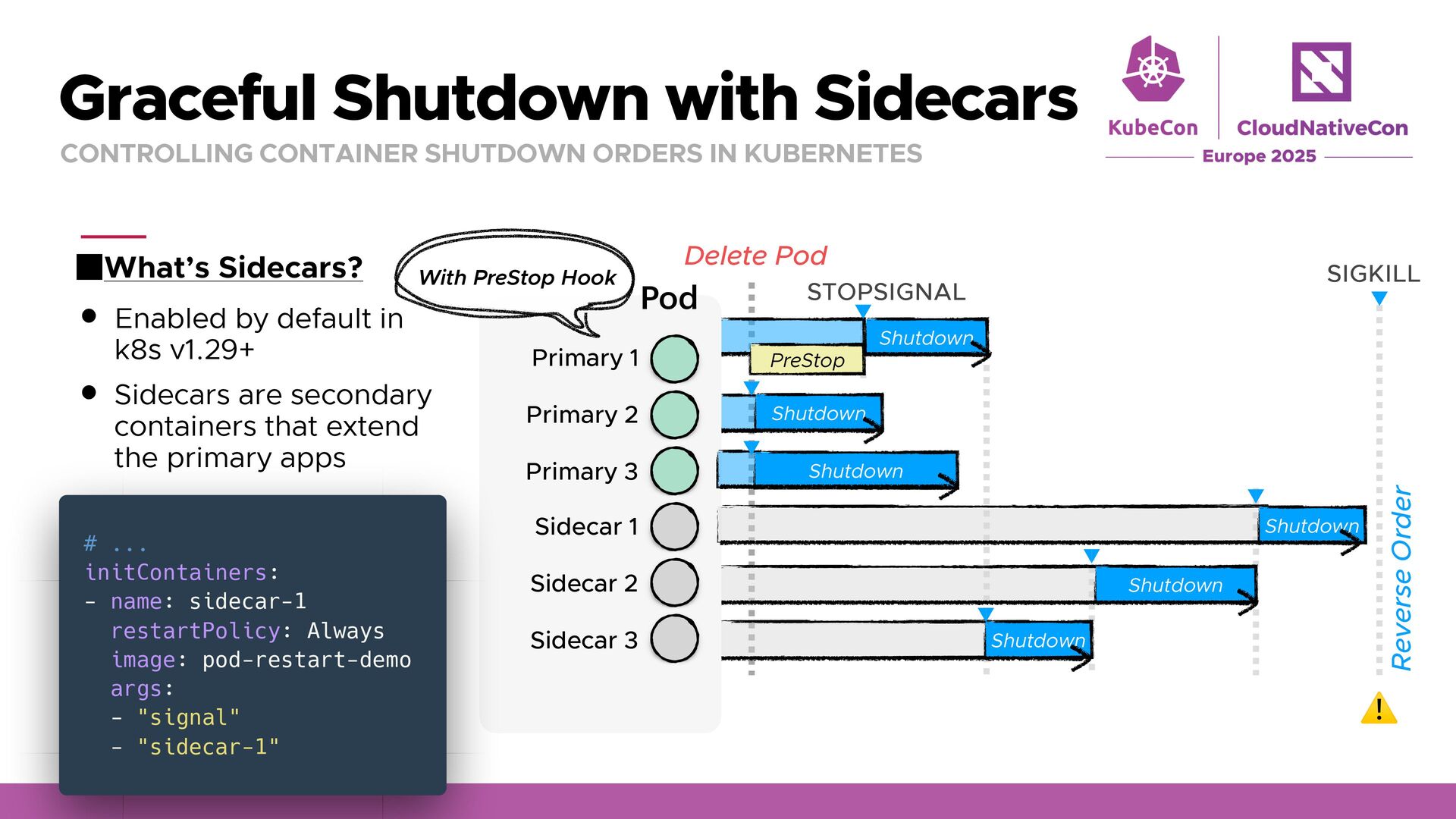
Graceful Shutdown Ensure your application handles SIGTERM (or a custom stop signal) properly. Dockerfile STOPSIGNAL and PreStop exec/httpGet can be used for a custom signal. Sidecars are terminated sequentially after primary containers exit. Remember that terminationGracePeriodSeconds is not always guaranteed. Minimize Traffic Downtime Use PreStop Sleep to give enough time for traffic stops before shutting down. Set Readiness/Startup Probes so the server receives traffic when actually ready. Plan for Leader Election Restarts Controllers using Leader Election can speed up leadership handover by enabling LeaderElectionReleaseOnCancel, but be careful split-brain. Mitigate Node Maintenance Disruptions Use Pod Disruption Budgets (PDBs) to limit disruption by evictions Restartability brings you leverage k8s’ strengths (self-healing, rolling updates, autoscaling).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}