Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MixPoet
Search
Zhang Yixiao
April 30, 2020
Research
450
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MixPoet
Zhang Yixiao
April 30, 2020
More Decks by Zhang Yixiao
See All by Zhang Yixiao
CoCon
ldzhangyx
0
400
vq-cpc
ldzhangyx
0
380
diora
ldzhangyx
0
290
drummernet
ldzhangyx
0
250
ON-LSTM
ldzhangyx
0
220
Other Decks in Research
See All in Research
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
230
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
6
3.5k
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
800
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
120
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
130
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.7k
人間中心の意思決定支援AI
yukinobaba
PRO
6
3.1k
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
220
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
140
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
520
世界モデルにおける分布外データ対応の方法論
koukyo1994
7
2.2k
Featured
See All Featured
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
540
The SEO identity crisis: Don't let AI make you average
varn
0
500
Being A Developer After 40
akosma
91
590k
Google's AI Overviews - The New Search
badams
0
1k
Optimizing for Happiness
mojombo
378
71k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
240
What's in a price? How to price your products and services
michaelherold
247
13k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
200
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
210
Transcript
MixPoet: Diverse Poetry Generation via Learning Controllable Mixed Latent Space
ArXiv: 2003.06094v1 Presenter: Yixiao Zhang
Overview • Idea: 诗人经历、历史背景等 => 诗歌风格多样化 • Methods: • semi-supervised
VAE • disentangling latent space to sub-spaces • each sub-space corresponds to one factor conditioning • adversarial training
Introduction • 近年的研究,主要考虑语义连贯、主题相关 • 存在diversity的困扰 • diversity: • 主题间多样性:给定两个topic words,生成不同的诗歌
• 主题内多样性:给定一个topic word,生成不同的诗歌 • * 现有的模型倾向于记住常见pattern
Introduction • 生活经历、历史背景、文学流派 => 影响风格
Introduction • MixPoet: semi-supervised VAE • 将latent space分解为sub-spaces,与影响因子一一对应 • 训练阶段:模型预测无label诗歌的factors
• 测试阶段:指定factor的值,生成风格化的诗歌
Related Work • 诗歌生成模型 (RNNs, Memory Models, etc. ) •
多样性的先前研究: • MRL system: 强化学习,鼓励选用高TF-IDF的词汇 • USPG: 无监督最大化style vector和诗歌的mutual information
Related Work • VAE文本生成/诗歌生成 • Yang et. al, 2018b: 学习context-conditioned
latent variable • Hu et al. 2017: 对生成的诗歌进行对抗训练,增强topic相关性 • CVAE 对话多样性: Learning Discourse-level Diversity for Neural Dialog Models using Conditional Variational Autoencoders, ACL 2017 • 本文的对抗:在latent space上做对抗训练
Method • topic keyword: mixture empirical distributions: labeled/ unlabeled
Method: Generator • GRU based model • 是length embedding
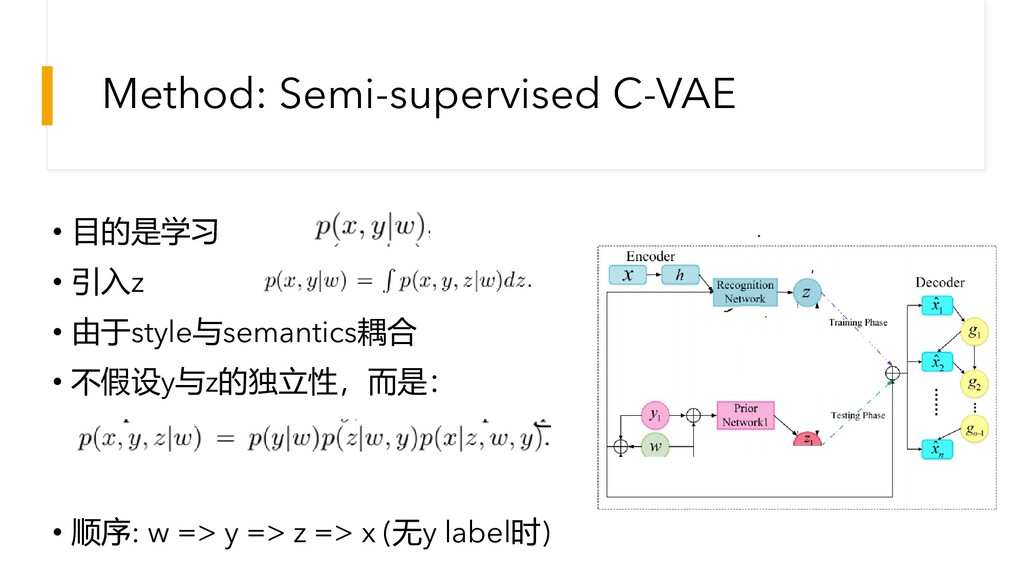
Method: Semi-supervised C-VAE • 目的是学习 • 引入z • 由于style与semantics耦合 •
不假设y与z的独立性,而是: • 顺序: w => y => z => x (无y label时)
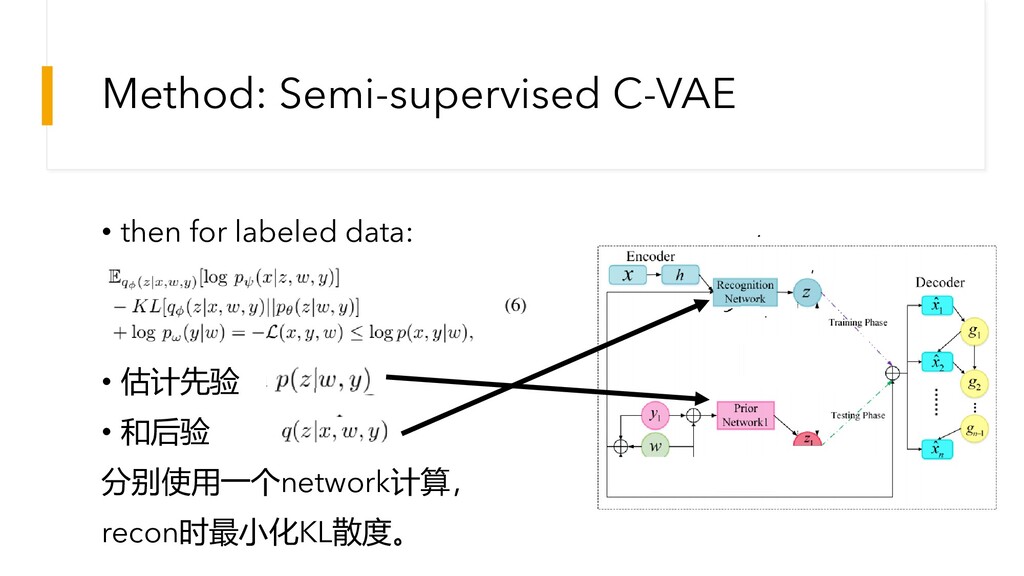
Method: Semi-supervised C-VAE • then for labeled data: • 估计先验
• 和后验 分别使用一个network计算, recon时最小化KL散度。
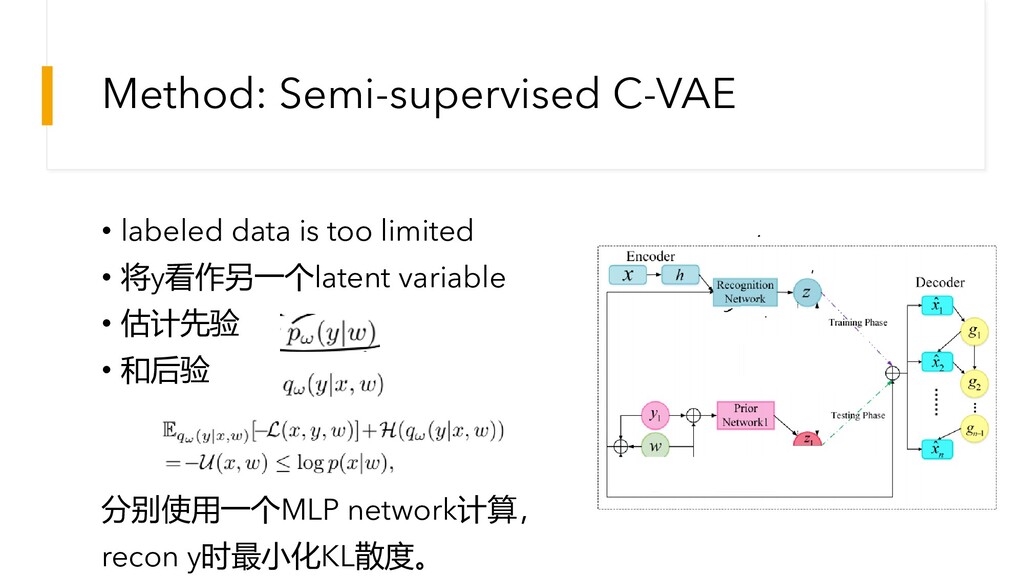
Method: Semi-supervised C-VAE • labeled data is too limited •
将y看作另一个latent variable • 估计先验 • 和后验 分别使用一个MLP network计算, recon y时最小化KL散度。
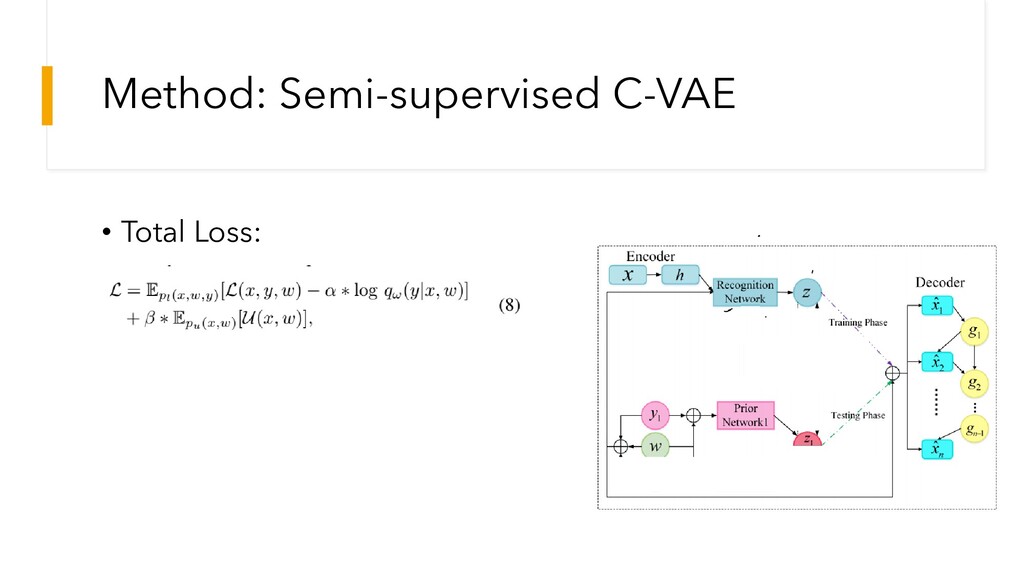
Method: Semi-supervised C-VAE • Total Loss:
Method: Latent Space Mixture • 多个factor时的情形: • 独立性假设:
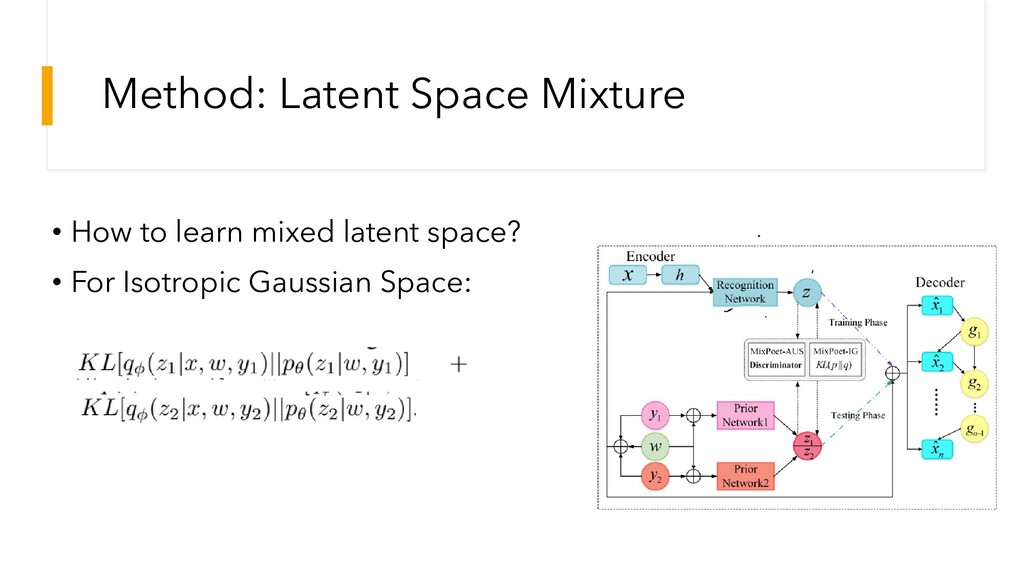
Method: Latent Space Mixture • How to learn mixed latent
space? • For Isotropic Gaussian Space:
Method: Latent Space Mixture • How to learn mixed latent
space? • For Universal Space: 对于condition: ita是噪声,delta是脉冲函数,c是w, y => 从分布中sample出一个值
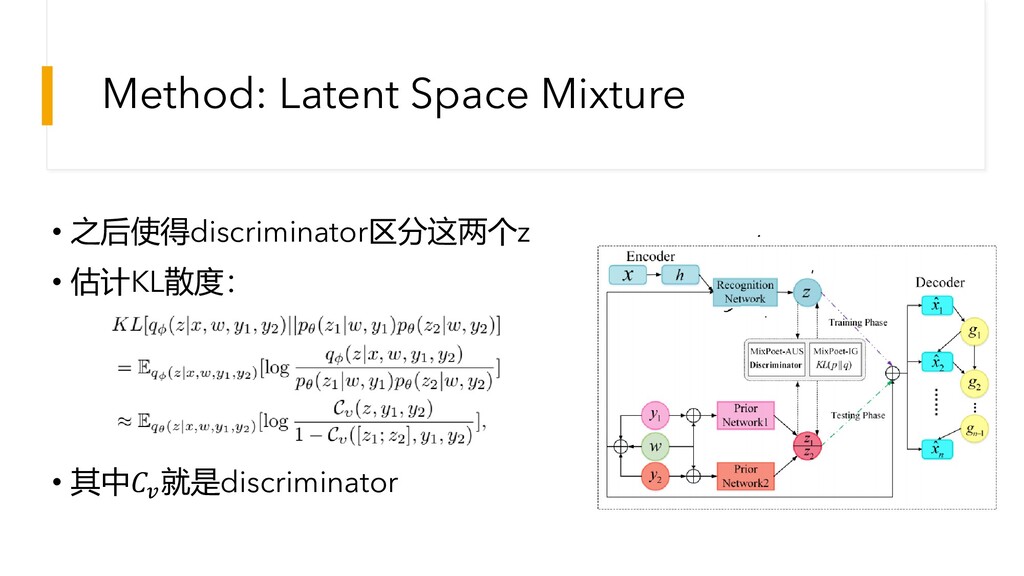
Method: Latent Space Mixture • 之后使得discriminator区分这两个z • 估计KL散度: • 其中
就是discriminator
Experiments • factors: • 军旅生涯, 乡村生活, 其他 • 时代繁荣, 时代衰落
• => 6种style
Experiments • Baseline: • Ground Truth • C-VAE • USPG
• MRL: SOTA • fBasic, 监督学习模型
Experiments • 多样性,使用Jaccard Similarity指数评价,越低越好 • 诗歌质量:使用Language Model Score(LMS)评价 • 观察:
• 大多数模型倾向生成重复的短语 • MRL与Basic在intra部分只能生成极其相似的诗歌 • C-VAE情况类似
Experiments • Factor Control Results: • 测试生成的诗歌是否与给定因子类别一致
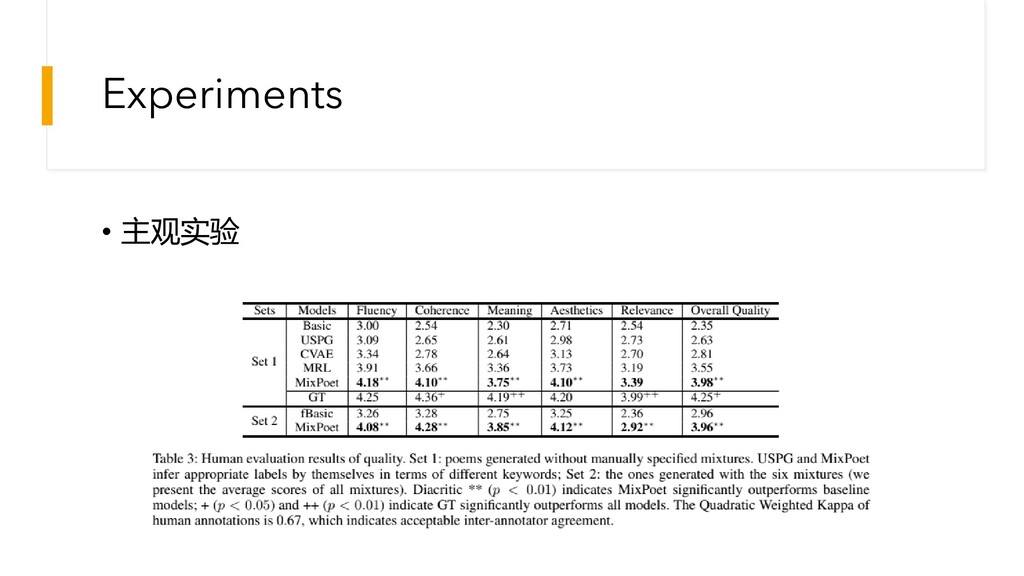
Experiments • 主观实验
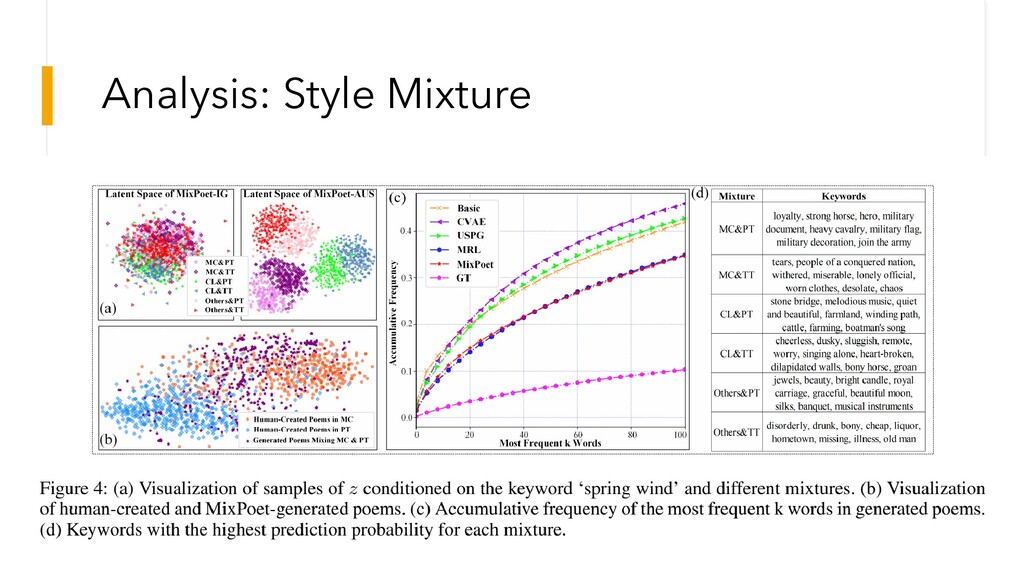
Analysis: Style Mixture
Analysis
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}