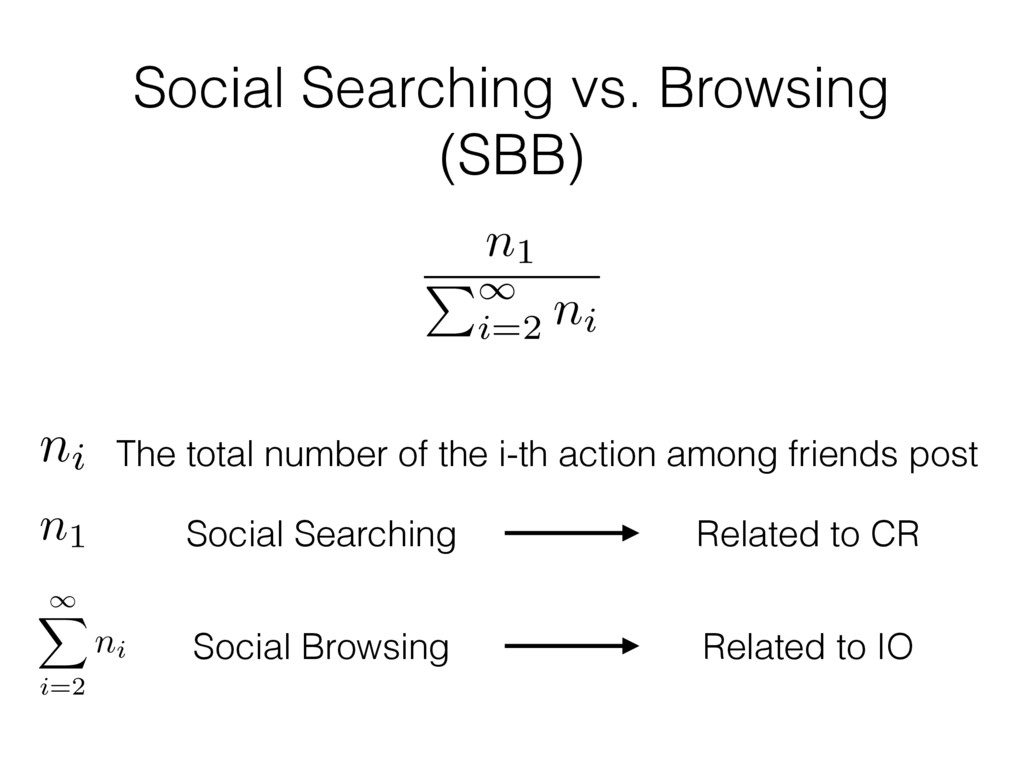
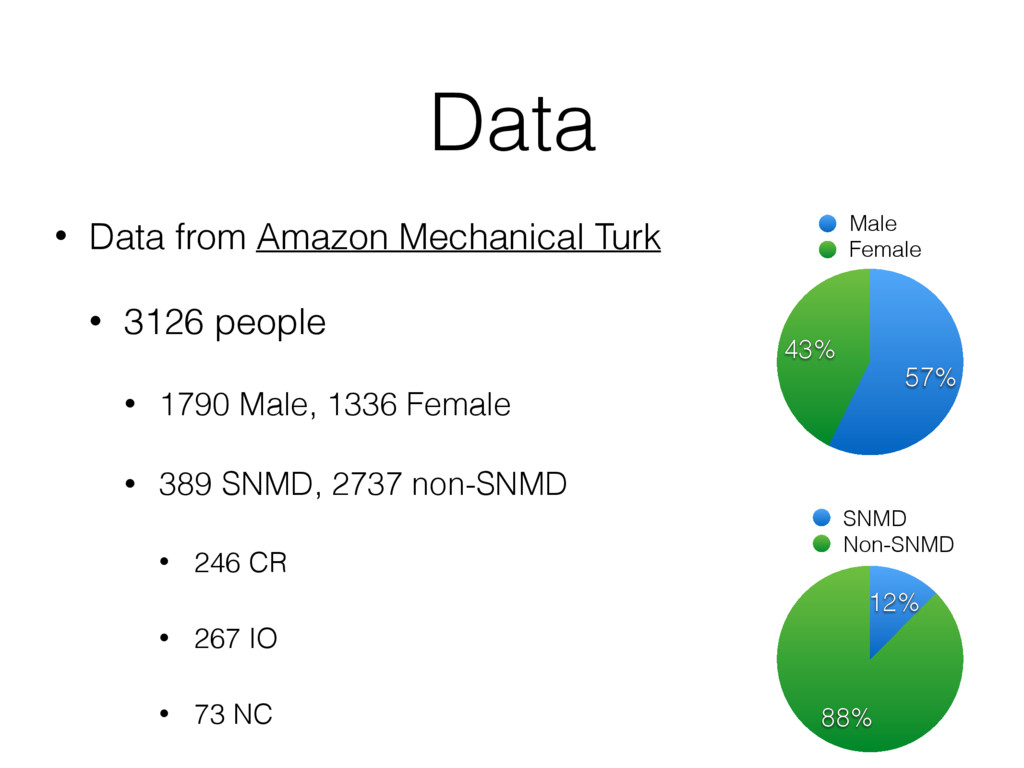
V, W need to be orthogonal element (i, j, k) of a three-mode tensor T is denoted by tijk , whereas the i-th row and the j-th column of a two-dimensional matrix U are respectively denoted by ui: and u:j . Specifically, Tucker decomposition [31] of a tensor T ∈ RN×D×M is defined as: T = C ×1 U ×2 V ×3 W, (1) where U ∈ RN×R, V ∈ RD×S and W ∈ RM×T are latent matrices. In this paper, the matrix of users’ latent features U plays a crucial role. In Tucker decomposition, R, S, and T are parameters to be set according to different criteria [31]. The 1-mode product of C ∈ RR×S×T and U ∈ RN×R, denoted by C ×1 U, is a ma- trix with size N × S × T, where each element (C ×1 U) nst = R r=1 crst urn . Given the input tensor matrix T that consists of the features of all users from every OSN, Tucker decompo- sition derives C, U, V, and W to meet the above equality on while vectors are denoted by boldface lowercase letters, e.g., u. Matrices are represented by boldface capital letters, e.g., U, and tensors are denoted by calligraphic letters, e.g., T . Each element (i, j, k) of a three-mode tensor T is denoted by tijk , whereas the i-th row and the j-th column of a two-dimensional matrix U are respectively denoted by ui: and u:j . Specifically, Tucker decomposition [31] of a tensor T ∈ RN×D×M is defined as: T = C ×1 U ×2 V ×3 W, (1) where U ∈ RN×R, V ∈ RD×S and W ∈ RM×T are latent matrices. In this paper, the matrix of users’ latent features U plays a crucial role. In Tucker decomposition, R, S, and T are parameters to be set according to different criteria [31]. The 1-mode product of C ∈ RR×S×T and U ∈ RN×R, denoted by C ×1 U, is a ma- trix with size N × S × T , where each element (C ×1 U) nst = R r=1 crst urn . Given the input tensor matrix T that consists of the features of all users from every OSN, Tucker decompo- sition derives C, U, V, and W to meet the above equality on Tndm for every n, d, and m, where C needs to be diagonal, and U, V , and W are required to be orthogonal [31]. By regard- ing ui: in U as the latent features of user i, we can efficiently integrate the information from different networks for i. whereas the i-th row and the j-th column of a two-dimensional matrix U are respectively denoted by ui: and u:j . Specifically, Tucker decomposition [31] of a tensor T ∈ RN×D×M is defined as: T = C ×1 U ×2 V ×3 W, (1) where U ∈ RN×R, V ∈ RD×S and W ∈ RM×T are latent matrices. In this paper, the matrix of users’ latent features U plays a crucial role. In Tucker decomposition, R, S, and T are parameters to be set according to different criteria [31]. The 1-mode product of C ∈ RR×S×T and U ∈ RN×R, denoted by C ×1 U, is a ma- trix with size N × S × T , where each element (C ×1 U) nst = R r=1 crst urn . Given the input tensor matrix T that consists of the features of all users from every OSN, Tucker decompo- sition derives C, U, V, and W to meet the above equality on Tndm for every n, d, and m, where C needs to be diagonal, and U, V , and W are required to be orthogonal [31]. By regard- ing ui: in U as the latent features of user i, we can efficiently integrate the information from different networks for i. Equipped with tensor decomposition on T , we propose a new SNMD-based Tensor Model (STM) to minimize the fol- lowing objective function L, L(U, V, W, C) = 1 2 ∥T − C ×1 U ×2 V ×3 W∥2 λ1 T λ2 2 Notice that factors for a does not en friends to b increases in pearing in t be smaller i Therefore, t acteristics o i.e., the user auxiliary in To prope weighted ad the Laplaci where D is We present each elemen gradient, w follows: ∇ui: L = ∇ vi: L =
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}