Les index logiciels accélèrent les applications en intelligence d'affaire, en apprentissage machine et en science des données. Ils déterminent souvent la performance des applications portant sur les mégadonnées. Les index efficaces améliorent non seulement la latence et le débit, mais aussi la consommation d'énergie. Plusieurs index font une utilisation parcimonieuse de la mémoire vive afin que les données critiques demeurent près du processeur. Il est aussi souhaitable de travailler directement sur les données compressées afin d'éviter une étape de décodage supplémentaire.
(1) Nous nous intéressons aux index bitmap. Nous les trouvons dans une vaste gamme de systèmes :
Oracle, Hive, Spark, Druid, Kylin, Lucene, Elastic, Git... Ils sont une composante de systèmes, tels que Wikipedia ou GitHub, dont dépendent des millions d'utilisateurs à tous les jours. Nous
présenterons certains progrès récents ayant trait à l'optimisation des index bitmap, tels qu'ils sont utilisés au sein des systèmes actuels. Nous montrons par des exemples comment multiplier la
performance de ces index dans certains cas sur les processeurs bénéficiant d'instructions SIMD (instruction unique, données multiples) avancées.
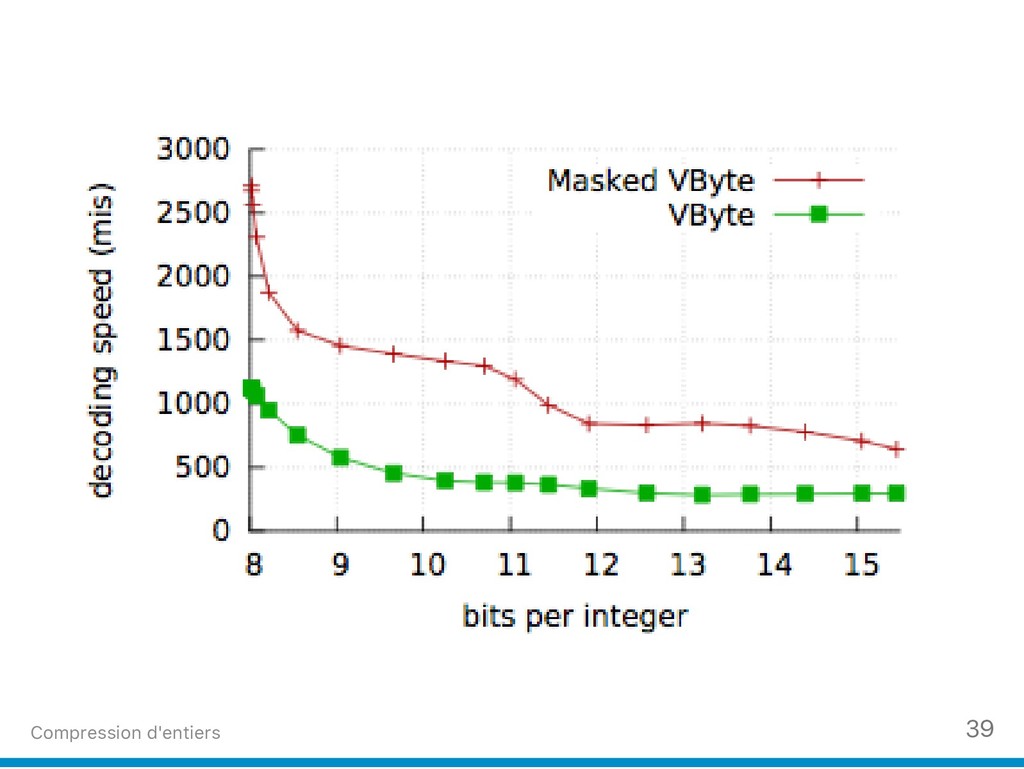
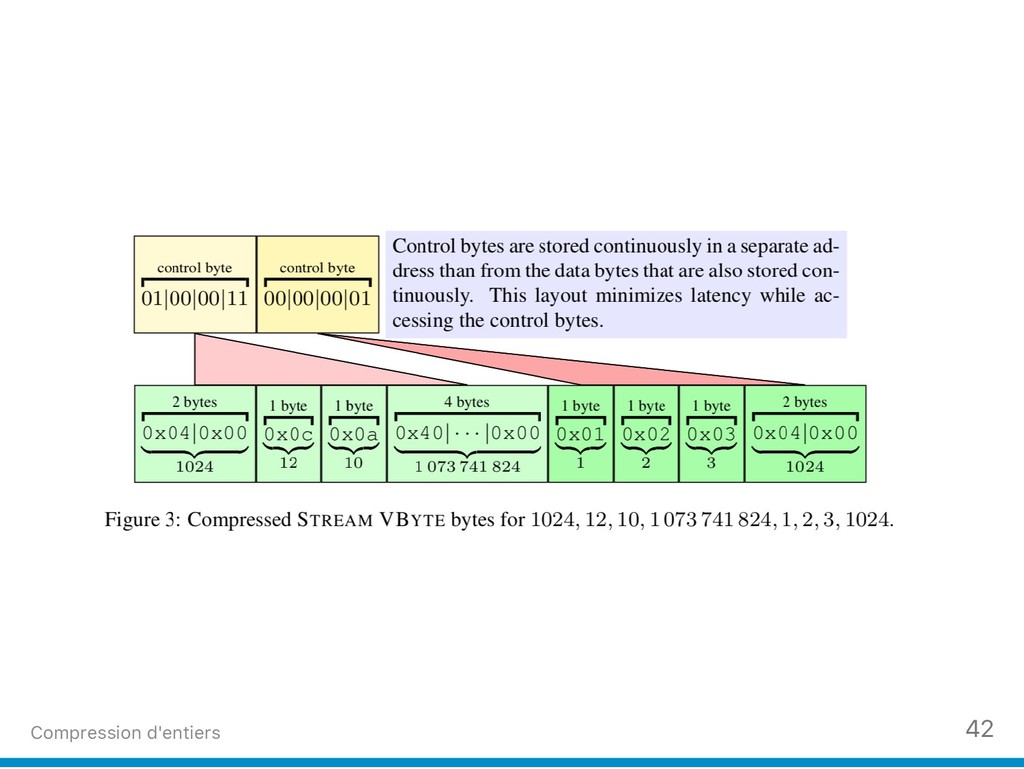
(2) Nous ciblons aussi les listes d'entiers que l'on trouve au sein des arbres B+, dans les indexes inversés et les index bitmap compressés. Nous donnons un exemple récent de technique de compression (Stream VByte) d’entiers qui permet de décoder des milliards d’entiers compressés par seconde.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[EWAH in Git] has already saved our users roughly a](https://files.speakerdeck.com/presentations/400803b884ec4843b8a1d68351441315/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
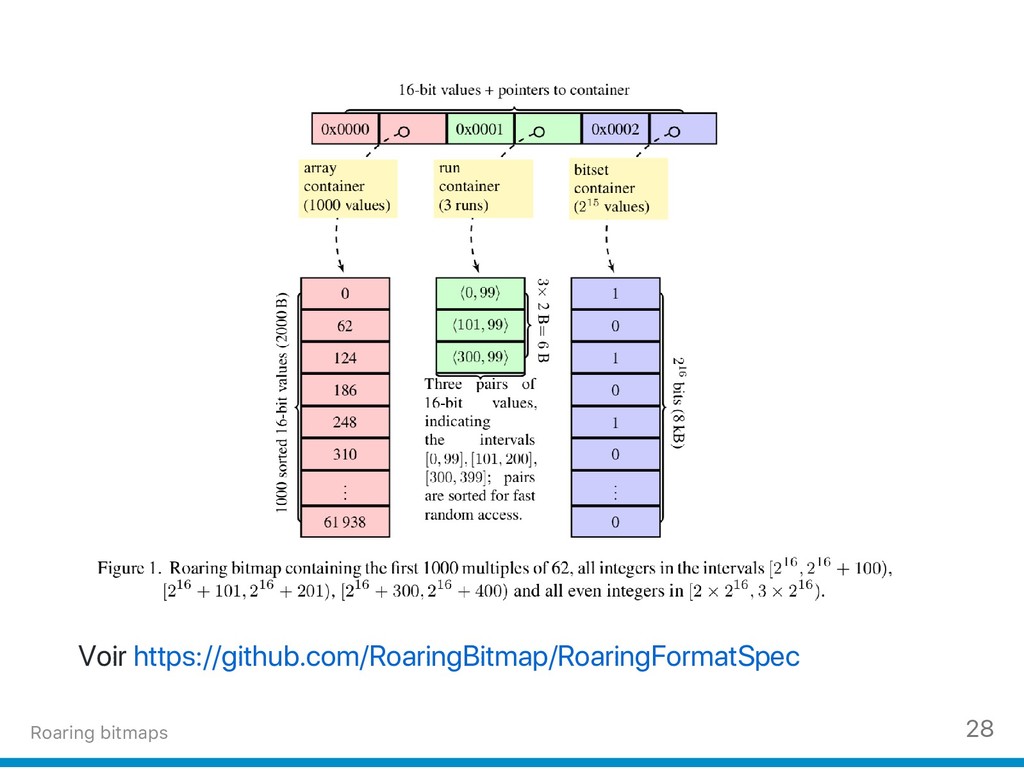{kind=link}
{kind=link}
{kind=link}
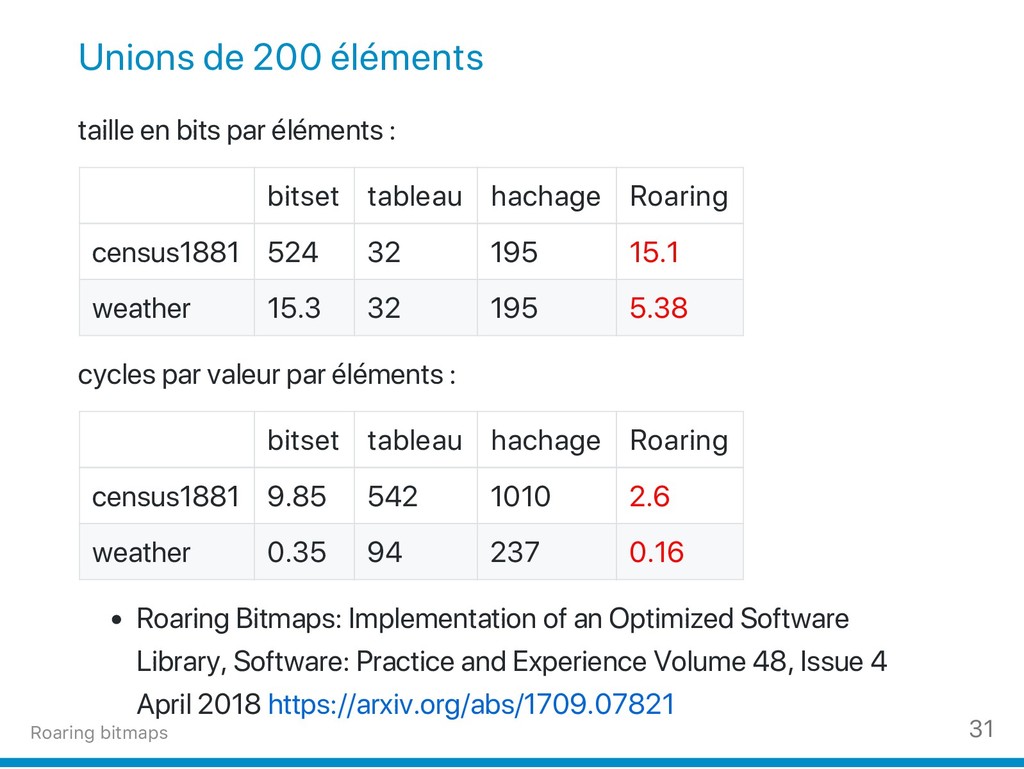{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
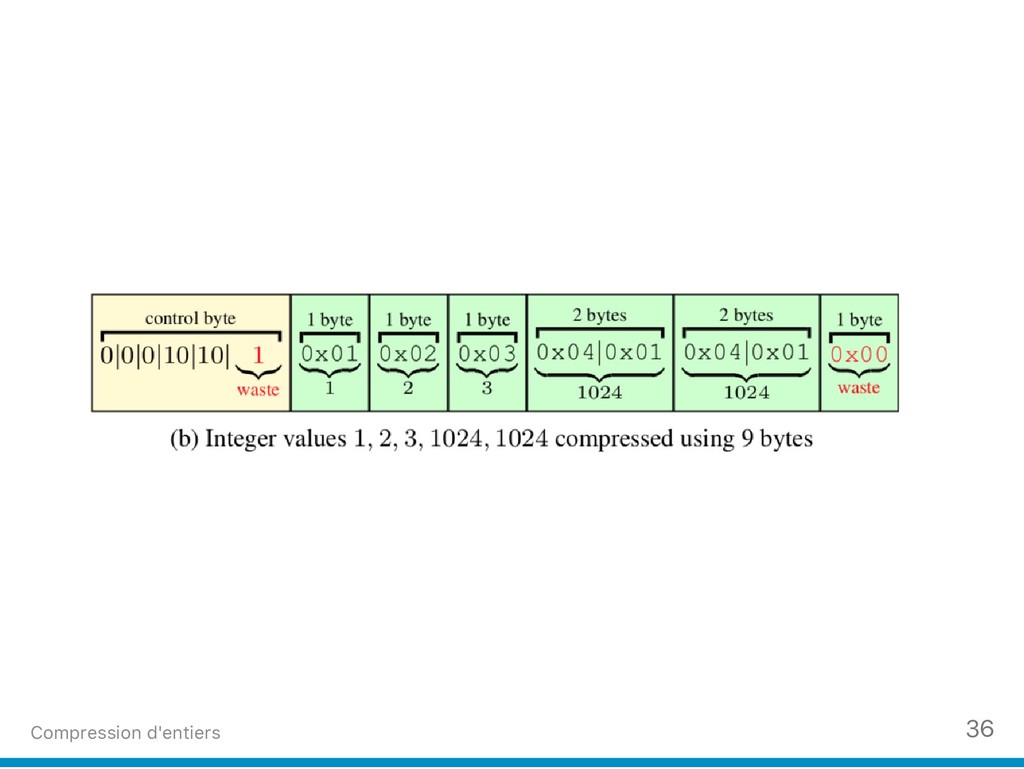{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}