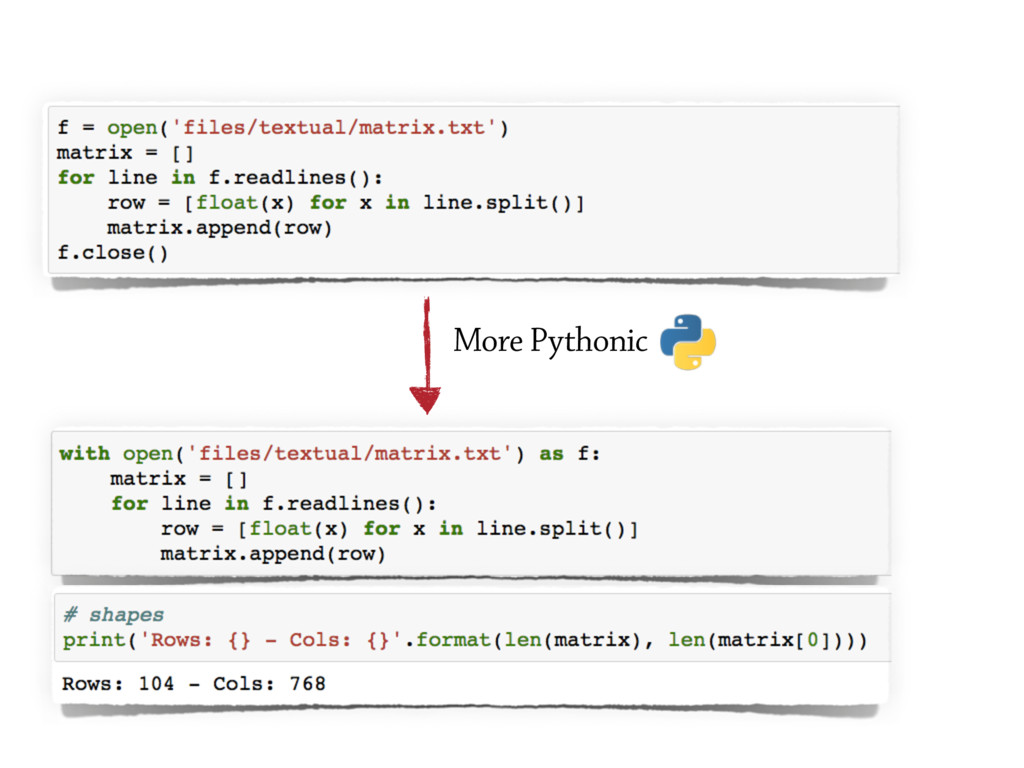
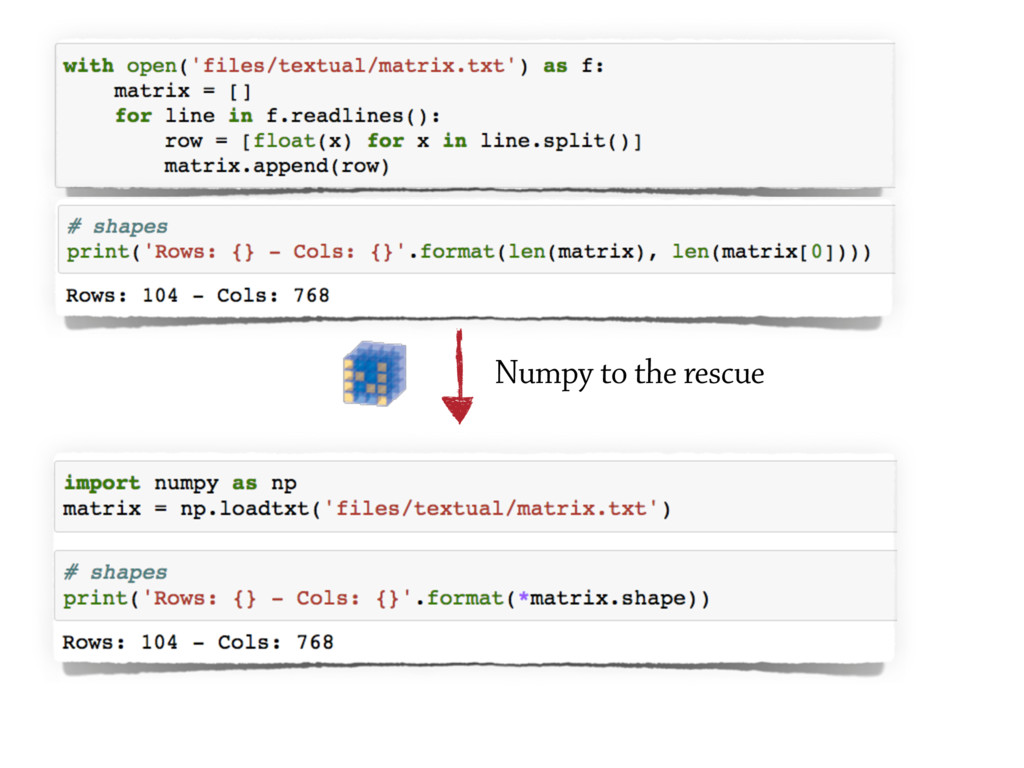
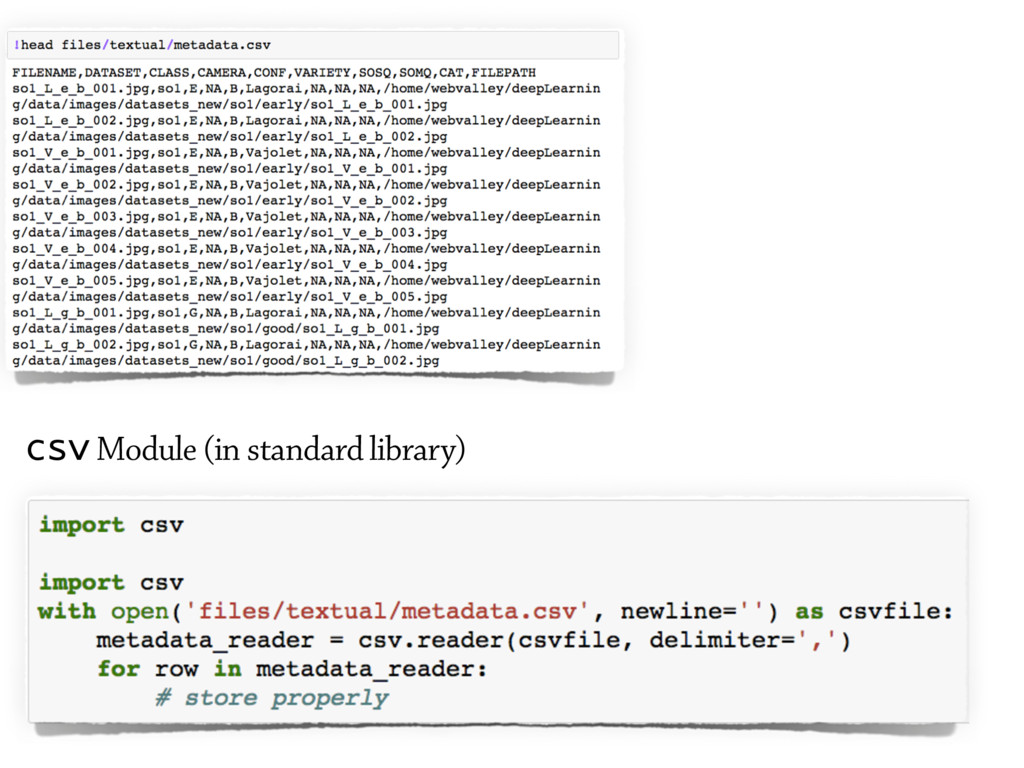
The plain text is one of the simplest yet most intuitive format in which data could be stored.
It is easy to create, human and machine readable,
storage-friendly (i.e. highly compressible), and quite fast to process.
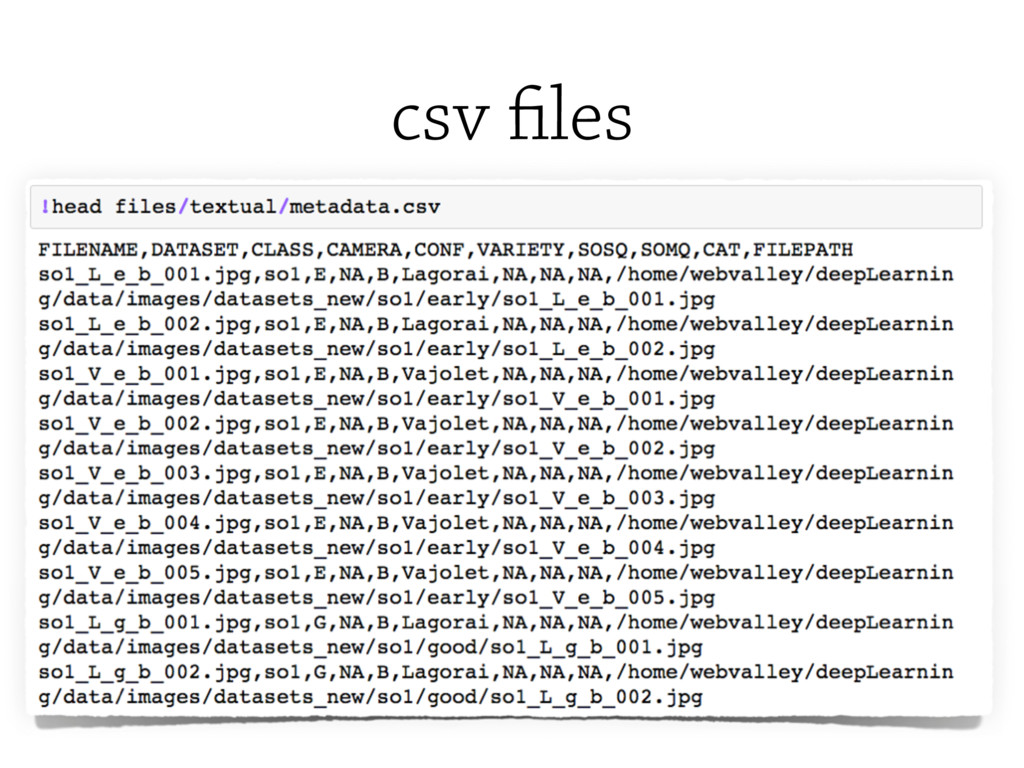
Textual data can also be easily structured; in fact to date the
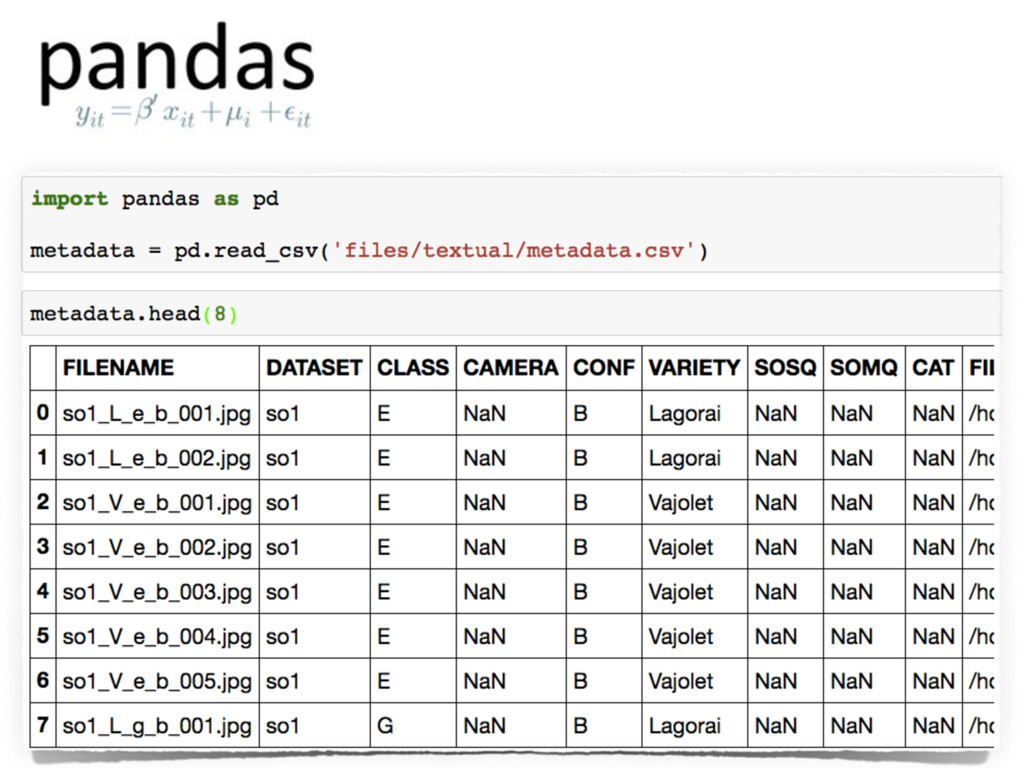
CSV (Comma Separated Values) is the most common data format among data scientists.
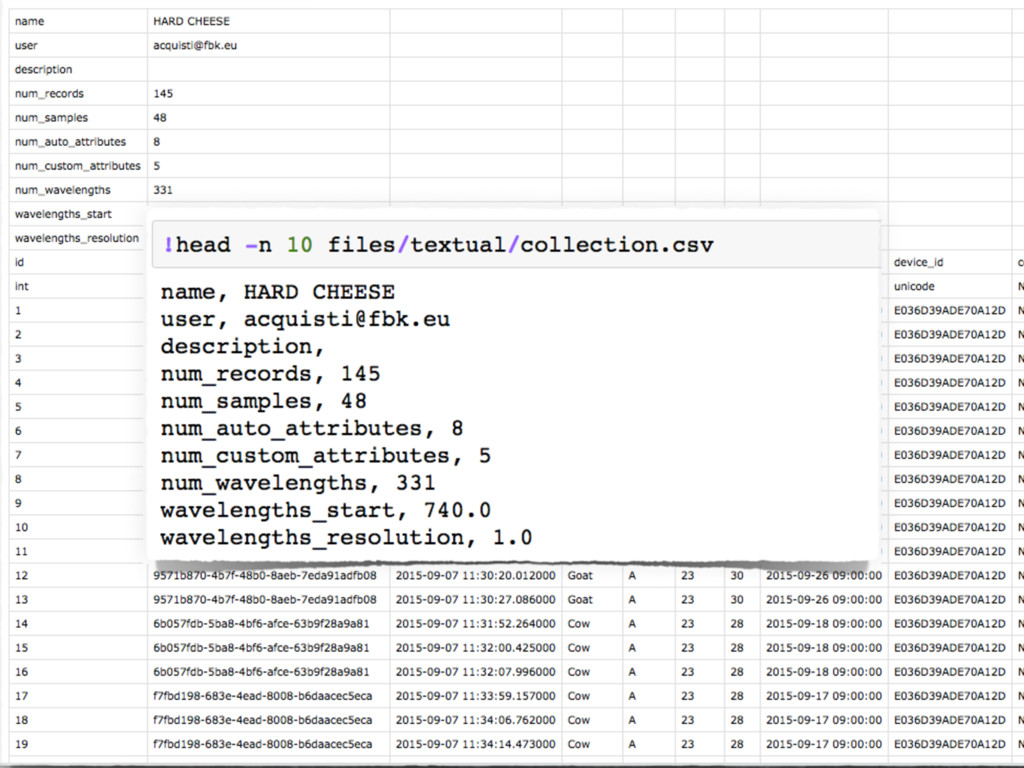
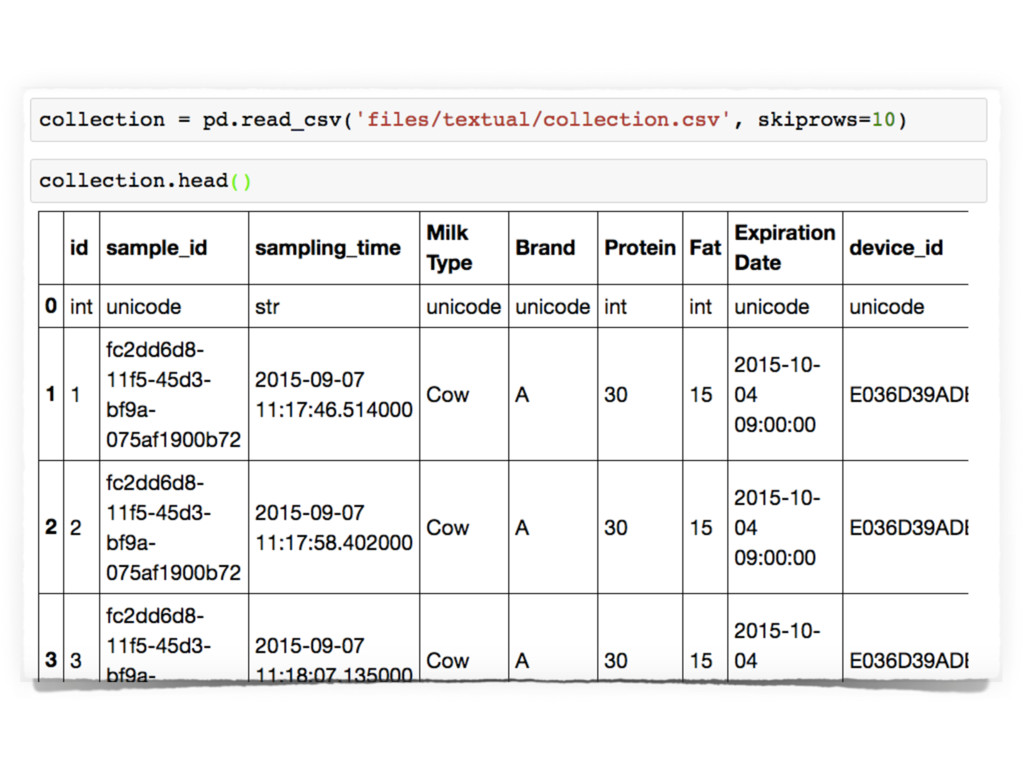
However, this format is not properly suited in case data require any sort of internal
hierarchical structure, or if data are too big to fit in a single disk.
In these cases, other formats must be considered, according to the shape of data, and the specific constraints imposed by the context.
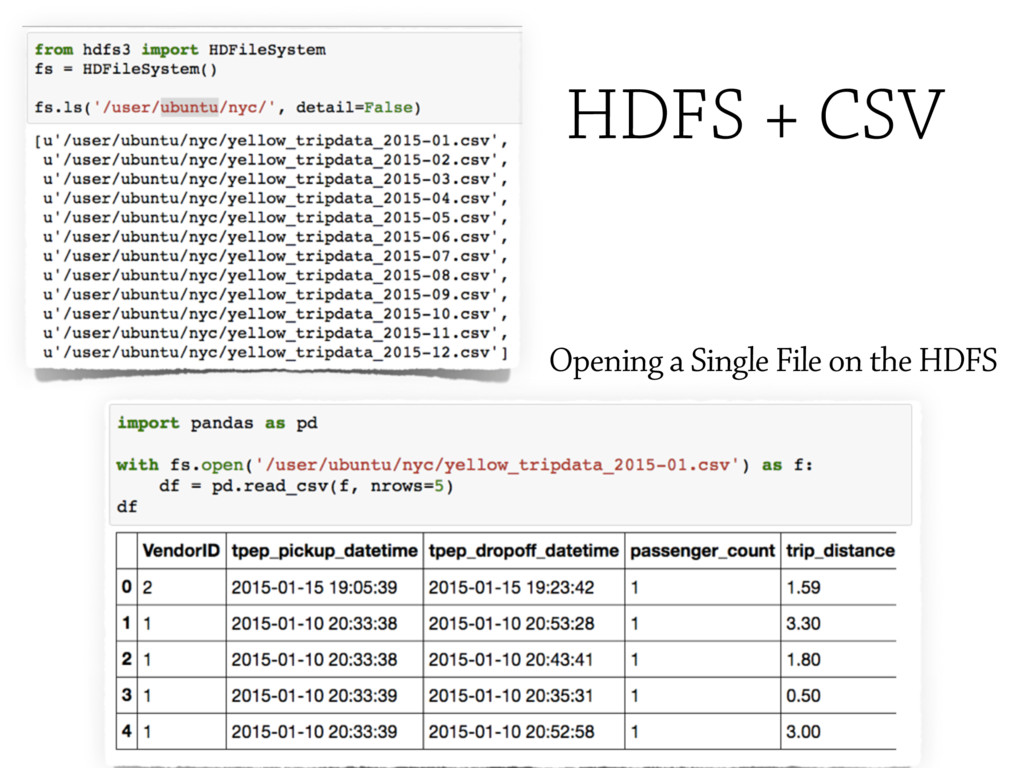
These formats may include general purpose solutions, e.g. [No]SQL databases, HDFS (Hadoop File System);
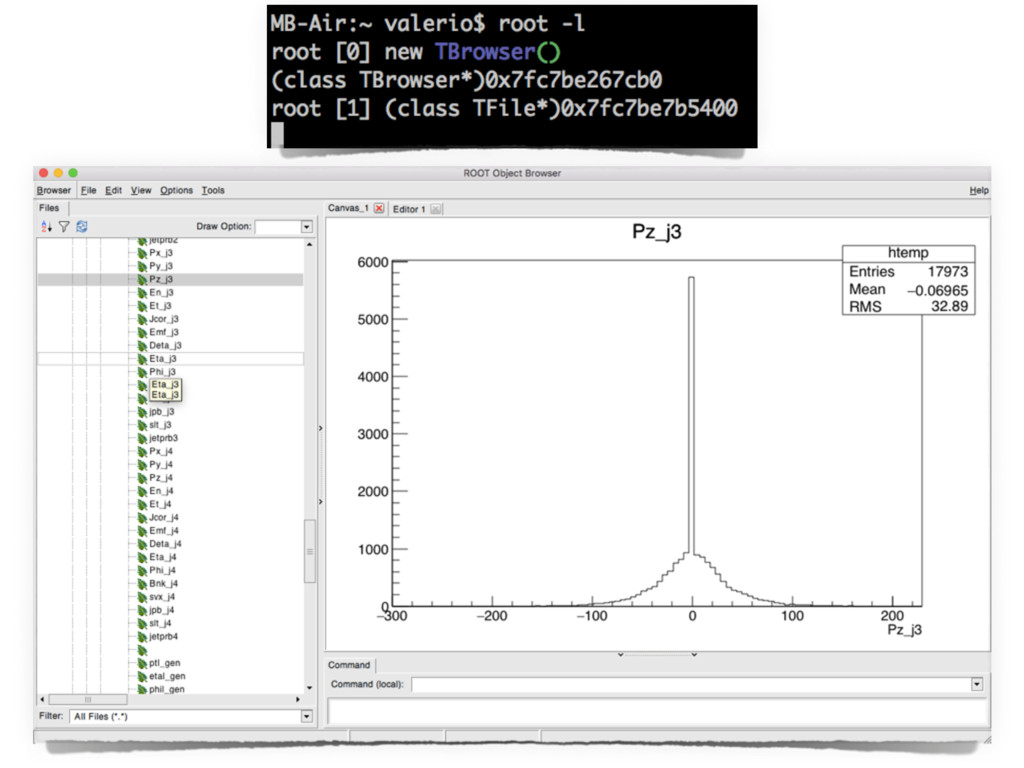
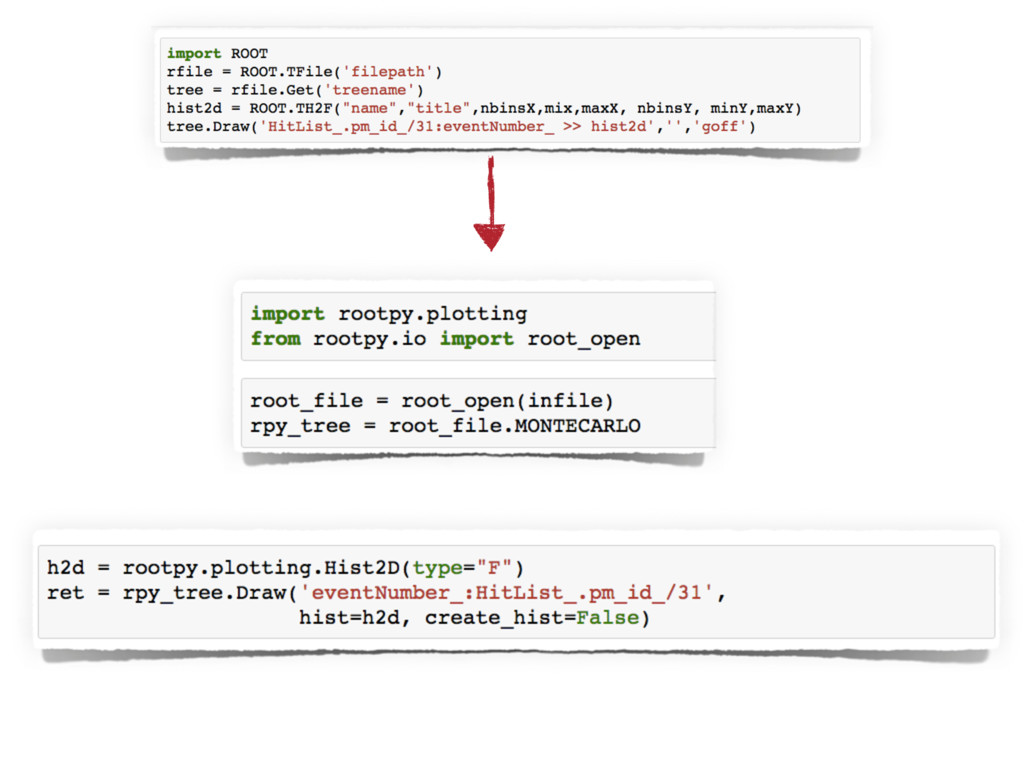
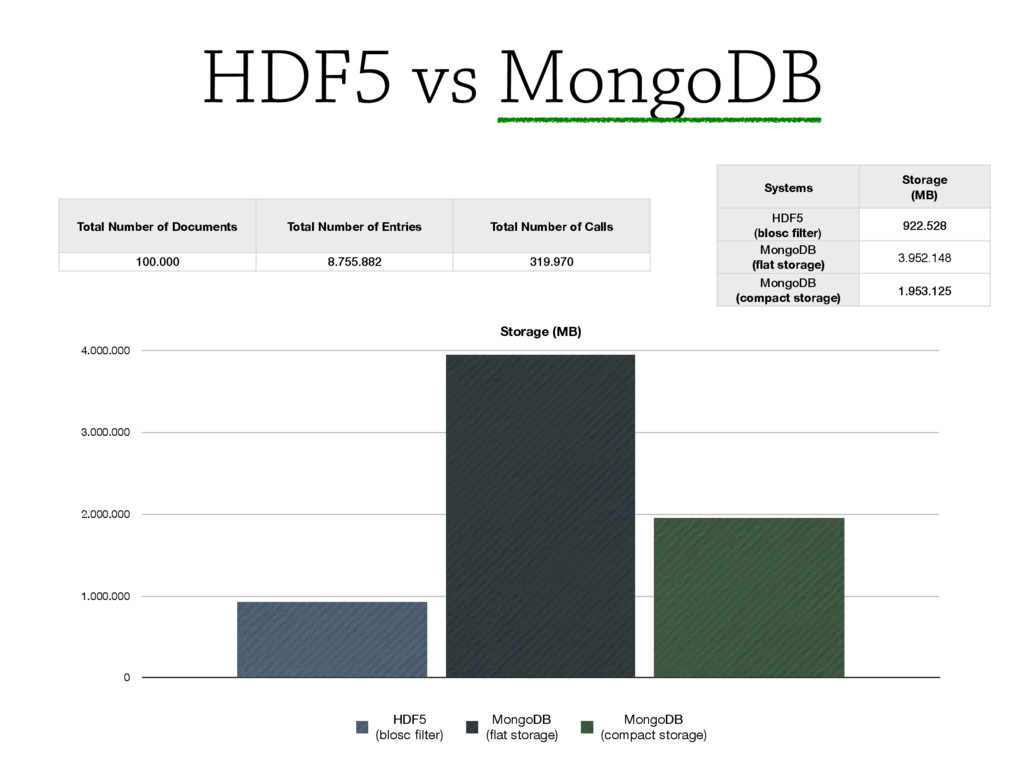
or may be specifically designed for scientific data, e.g. hdf5, ROOT, NetCDF.
In this talk, I would like to discuss strength and flaws of each solution
w.r.t. their usage for scientific computations in order to provide some practical guidelines for data scientists.
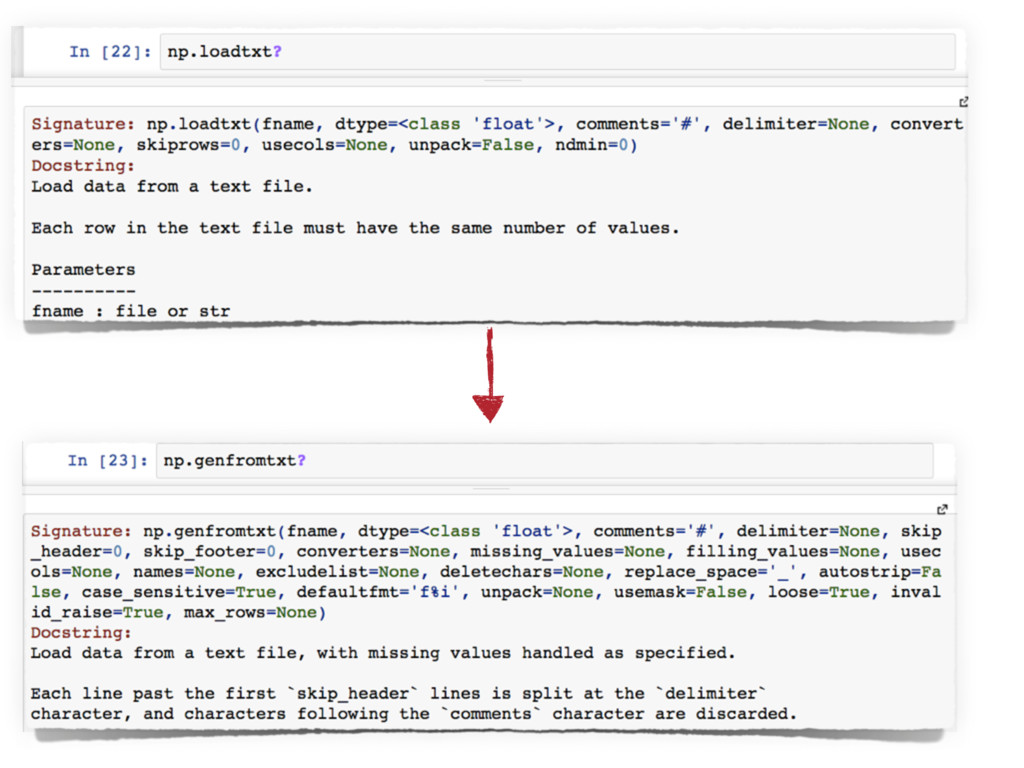
The different data formats will be presented in combination with a set of related Python projects, that will be analysed and compared in terms of efficiency and features provided.
These projects include xarray, pyROOT vs rootpy, h5py vs PyTables, and blaze.
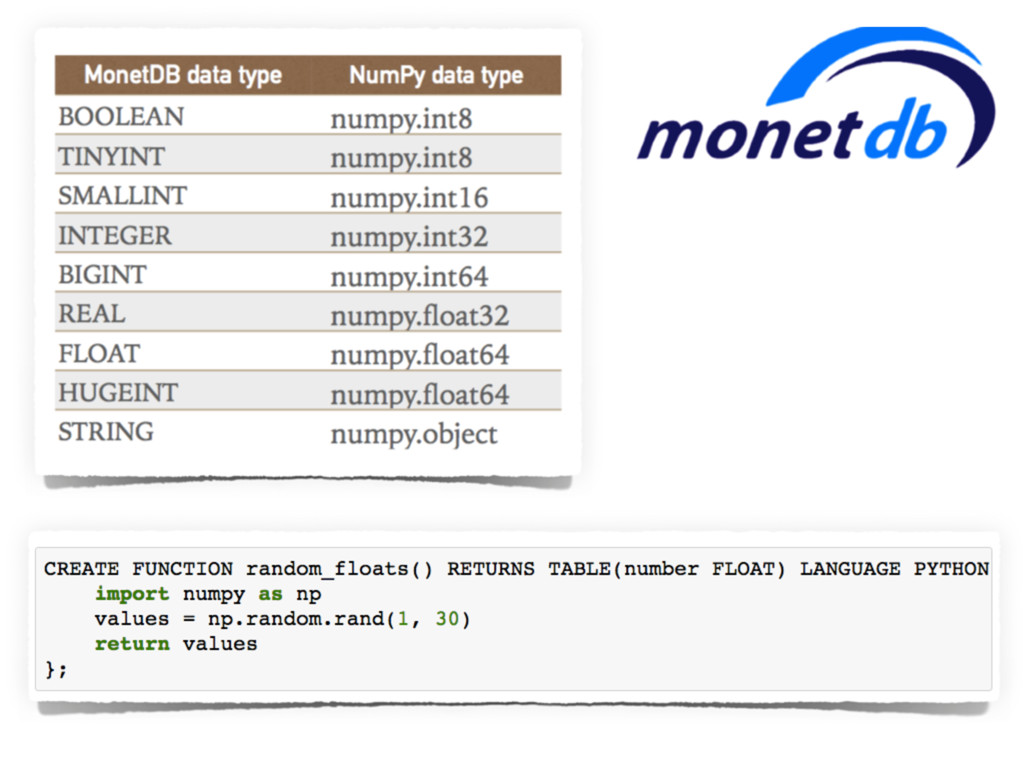
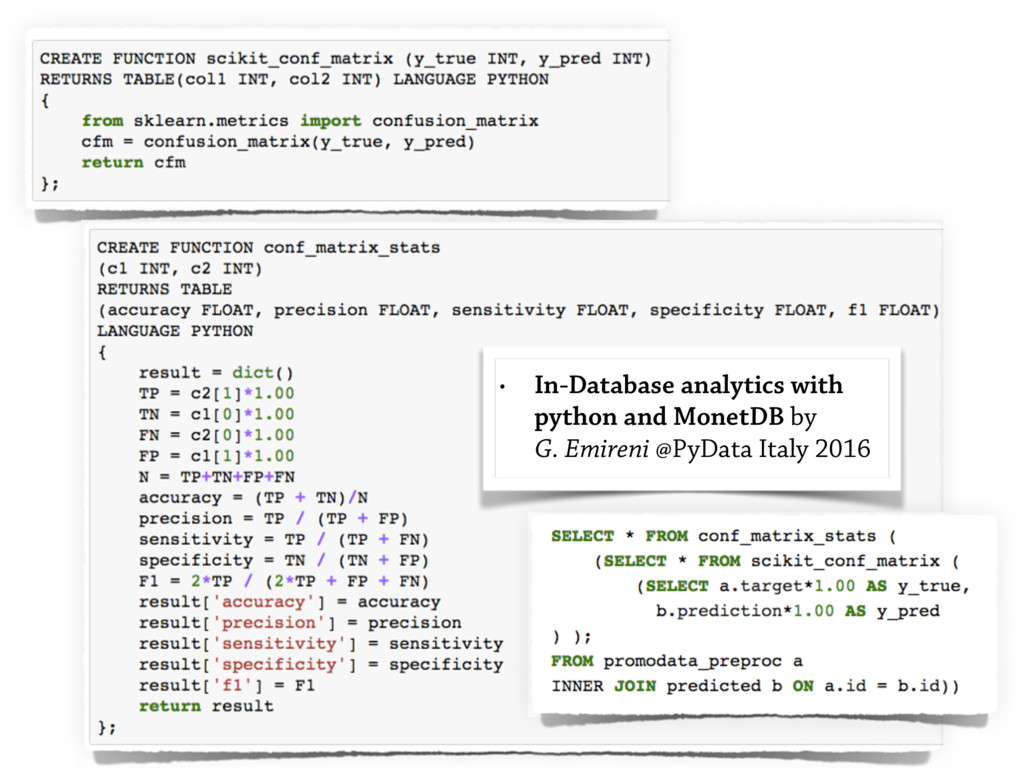
Finally, few notes about the new trends for **columnar databases** will be discussed for very fast
in-memory analytics (e.g. *MonetDB*).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks a lot for your kind attention +ValerioMaggio [email protected] it.linkedin.com/in/valeriomaggio](https://files.speakerdeck.com/presentations/68d273ab3e034c6787ce90b3faf2376a/slide_53.jpg){kind=link}