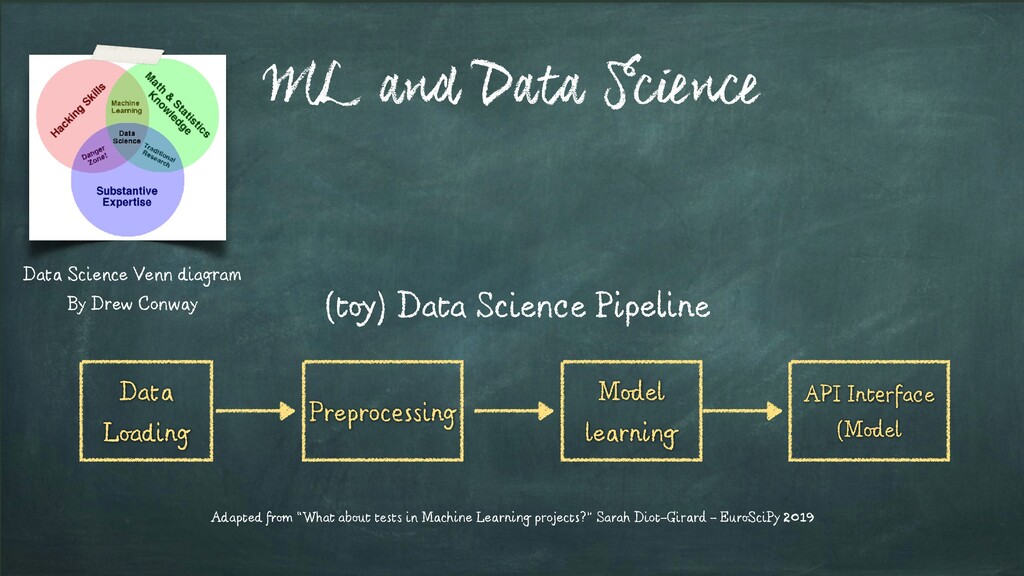
Conway Data Loading Preprocessing Model learning API Interface (Model Adapted from “What about tests in Machine Learning projects?” Sarah Diot-Girard - EuroSciPy 2019 (toy) Data Science Pipeline
programming computers so they can learn from data” Aurélien Géron, Hands-on Machine Learning with Scikit-Learn and TensorFlow Source: bit.ly/ml-simple-definition “(ml) focuses on teaching computers how to learn without the need to be programmed for specific tasks” S. Pal & A. Gulli, Deep Learning with Keras
tasks by themselves. It is that simple. The complexity comes with the details Louis Pedro Coelho, Building Machine Learning Systems with Python (and that’s probably one of the reason why you’re here :)
data recent advances in sequencing techs and instruments (e.g. “bio-images”) huge datasets generated at incredible pace from human observation to data analysis cheminformatics (drug discovery) Research Impact —> Social and Human Impact
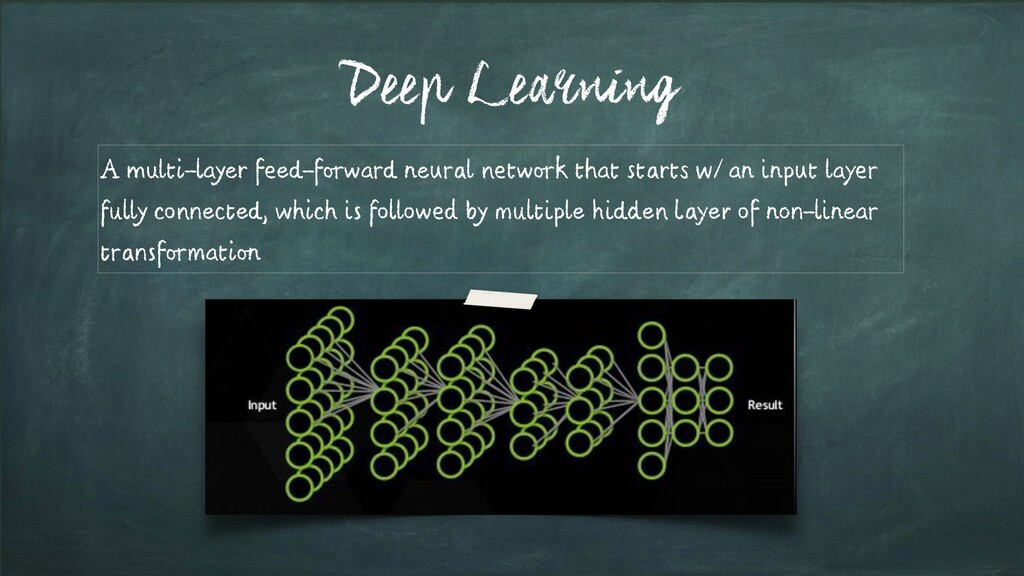
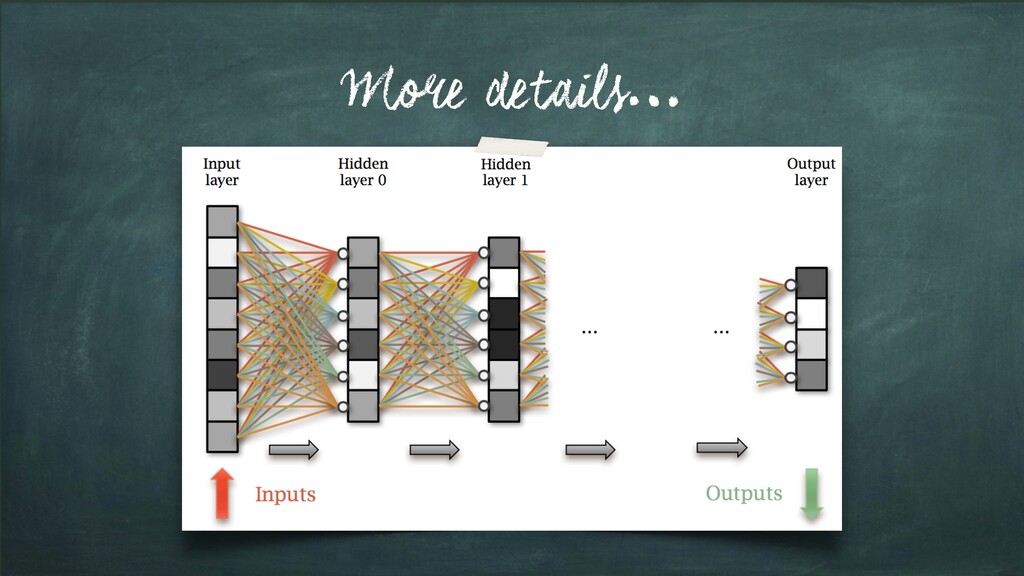
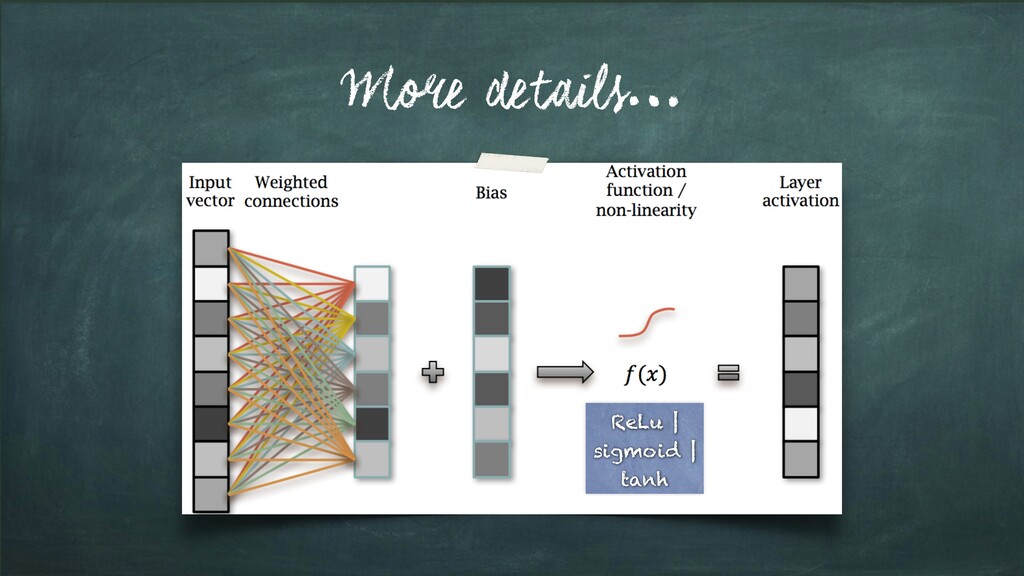
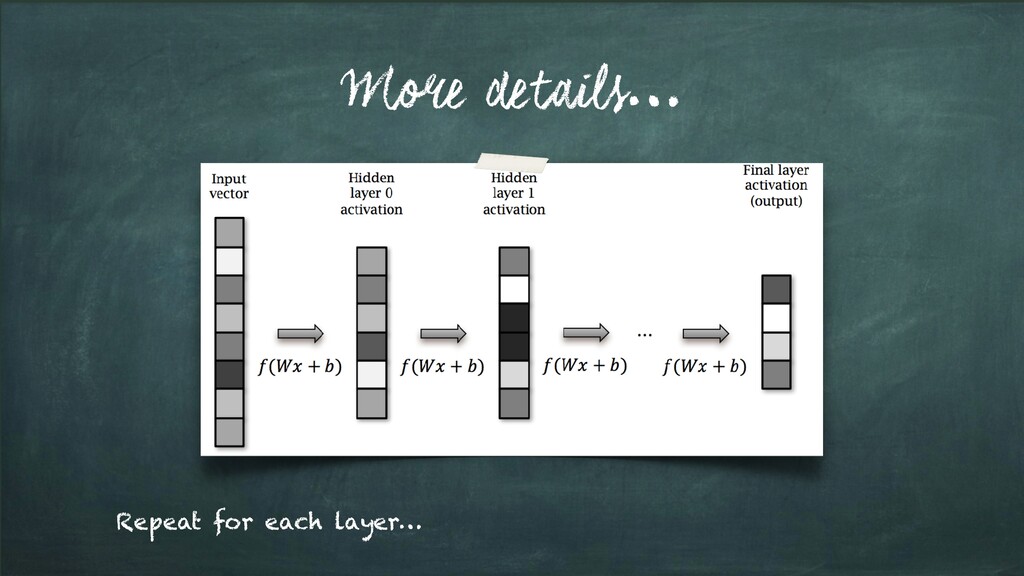
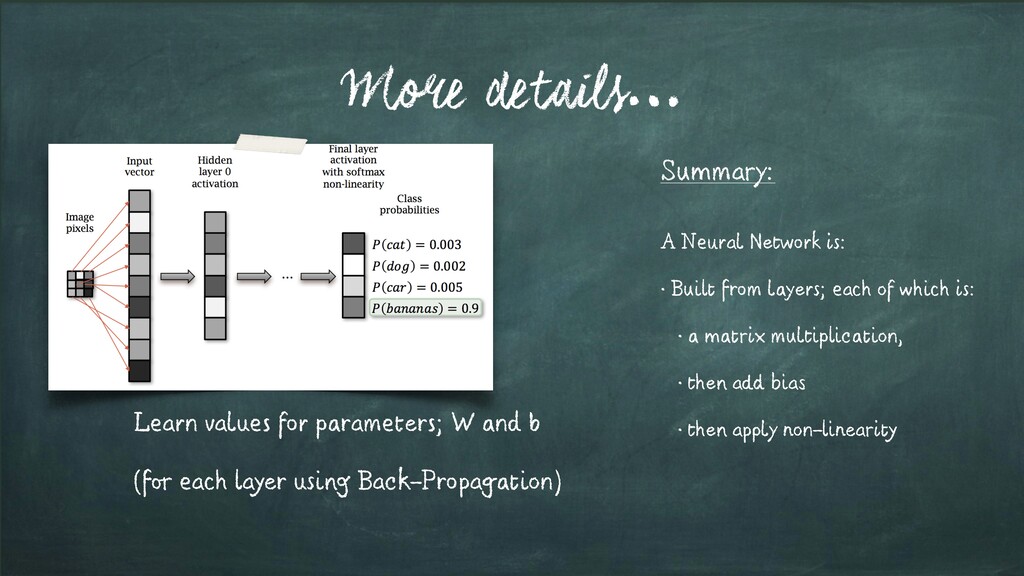
layers; each of which is: • a matrix multiplication, • then add bias • then apply non-linearity Learn values for parameters; W and b (for each layer using Back-Propagation)
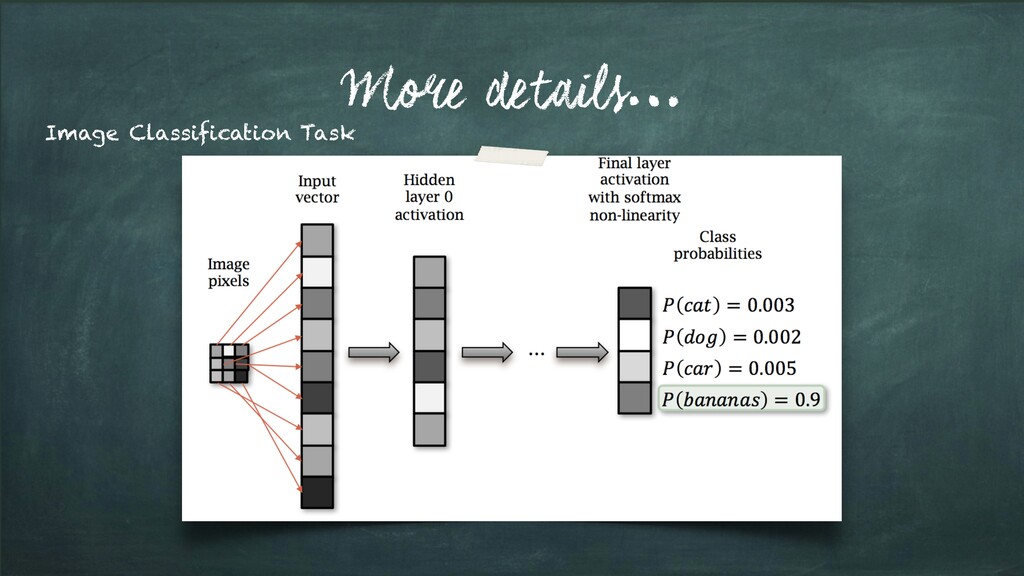
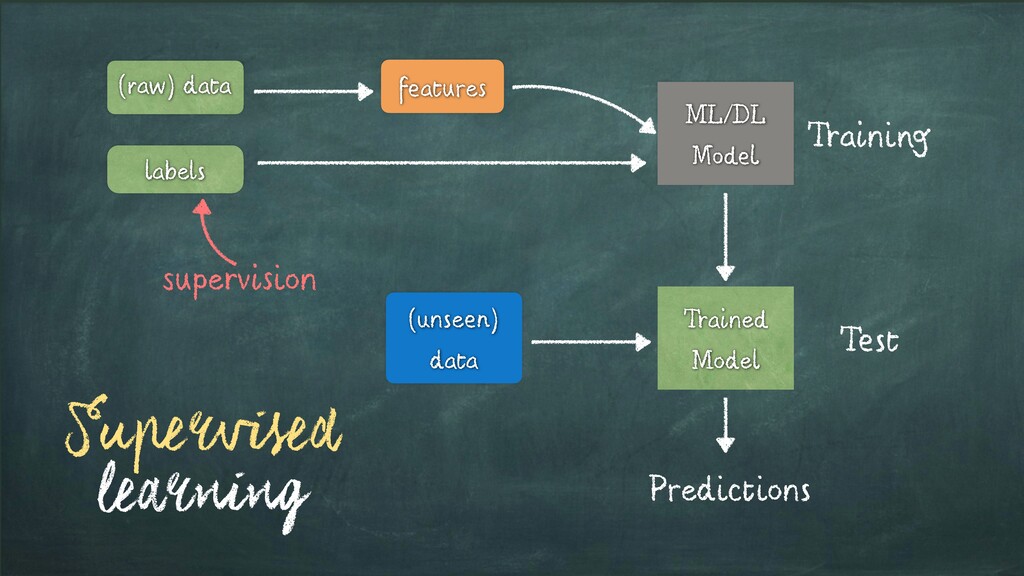
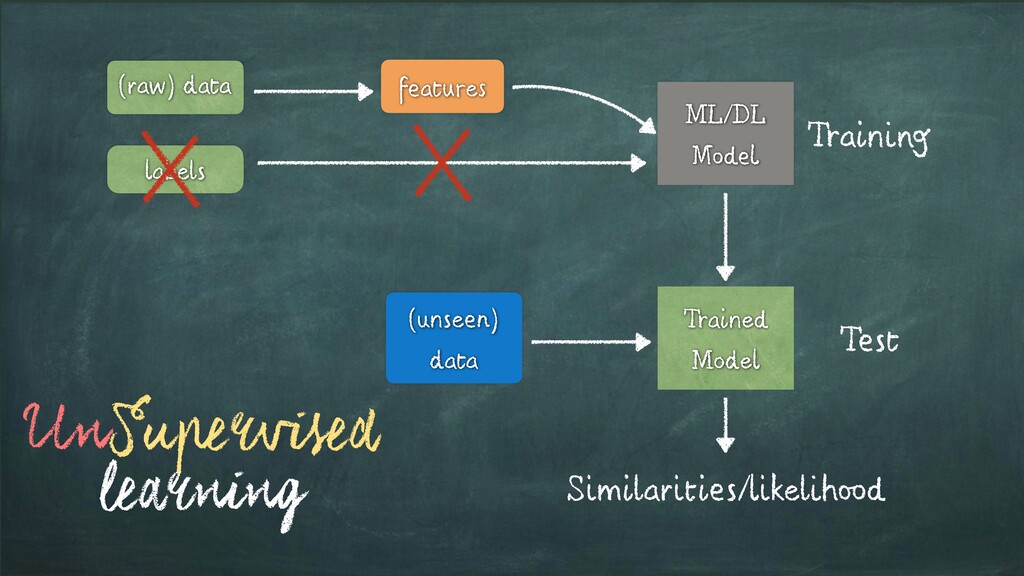
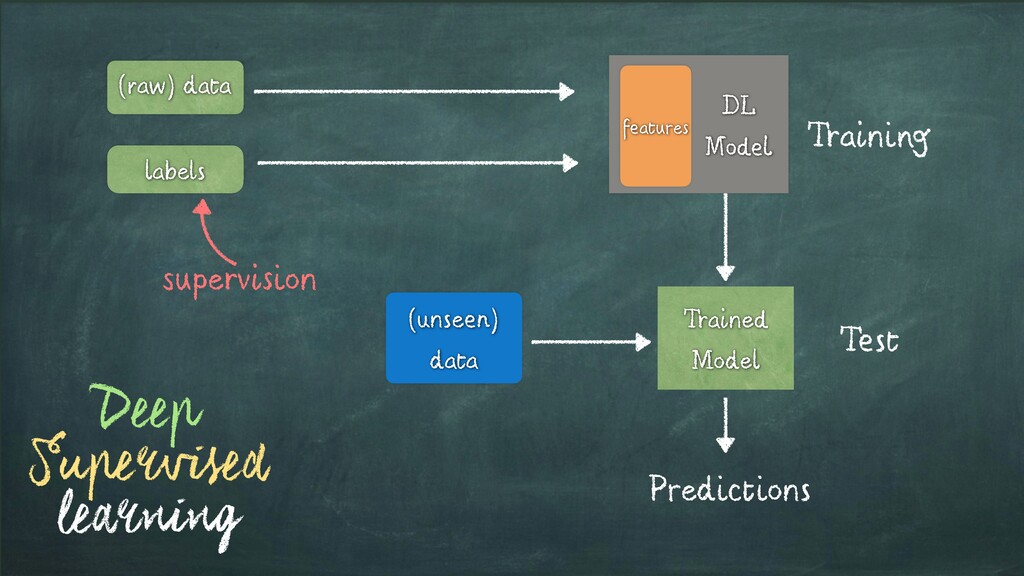
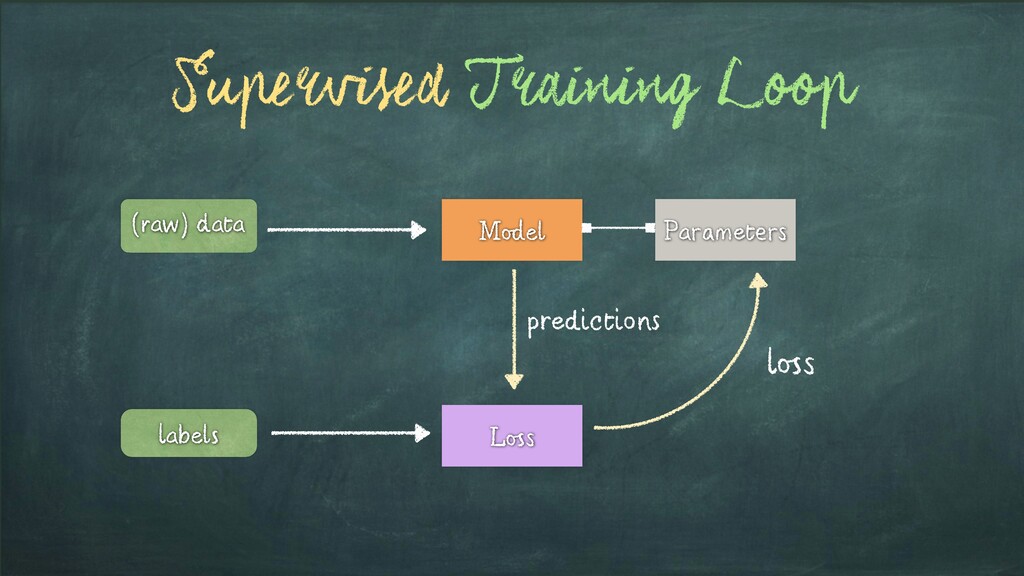
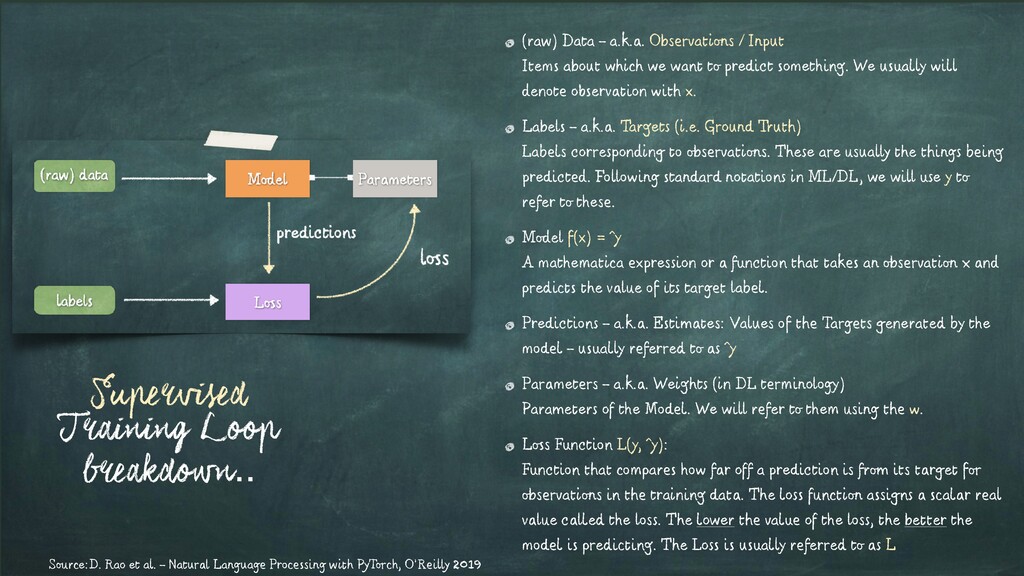
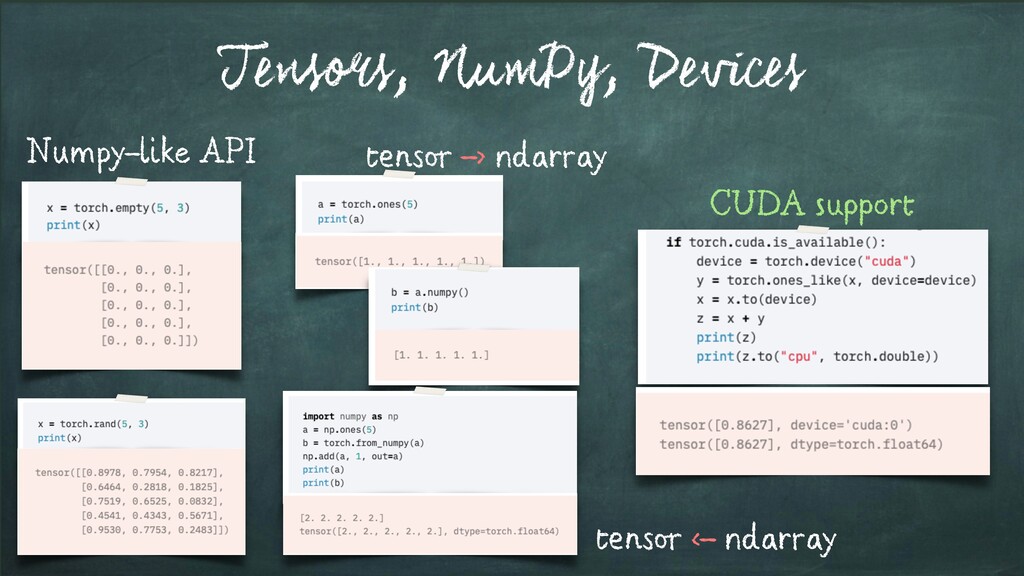
Input Items about which we want to predict something. We usually will denote observation with x. Labels - a.k.a. Targets (i.e. Ground Truth) Labels corresponding to observations. These are usually the things being predicted. Following standard notations in ML/DL, we will use y to refer to these. Model f(x) = ˆy A mathematica expression or a function that takes an observation x and predicts the value of its target label. Predictions - a.k.a. Estimates: Values of the Targets generated by the model - usually referred to as ˆy Parameters - a.k.a. Weights (in DL terminology) Parameters of the Model. We will refer to them using the w. Loss Function L(y, ˆy): Function that compares how far off a prediction is from its target for observations in the training data. The loss function assigns a scalar real value called the loss. The lower the value of the loss, the better the model is predicting. The Loss is usually referred to as L Source:D. Rao et al. - Natural Language Processing with PyTorch, O’Reilly 2019
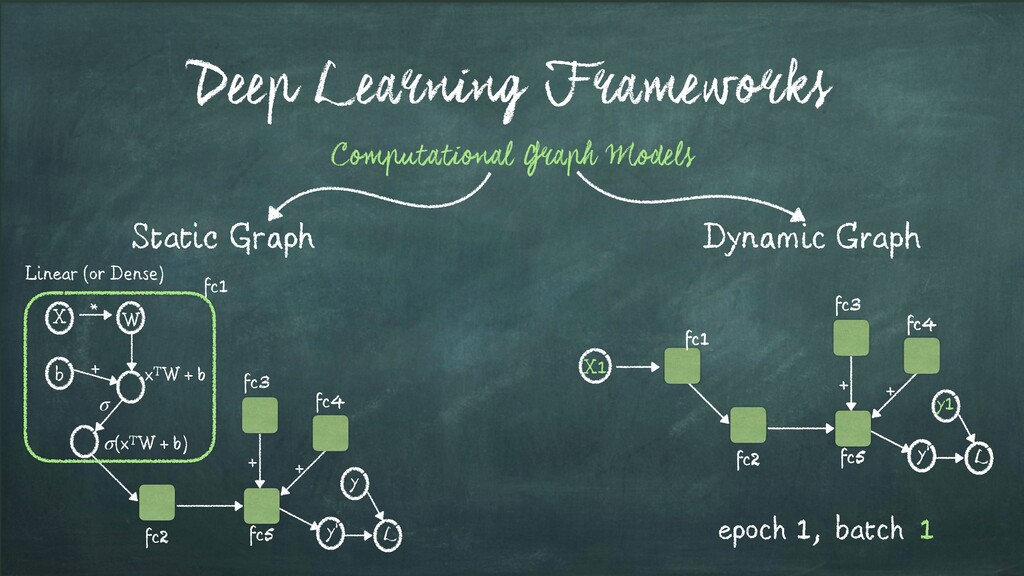
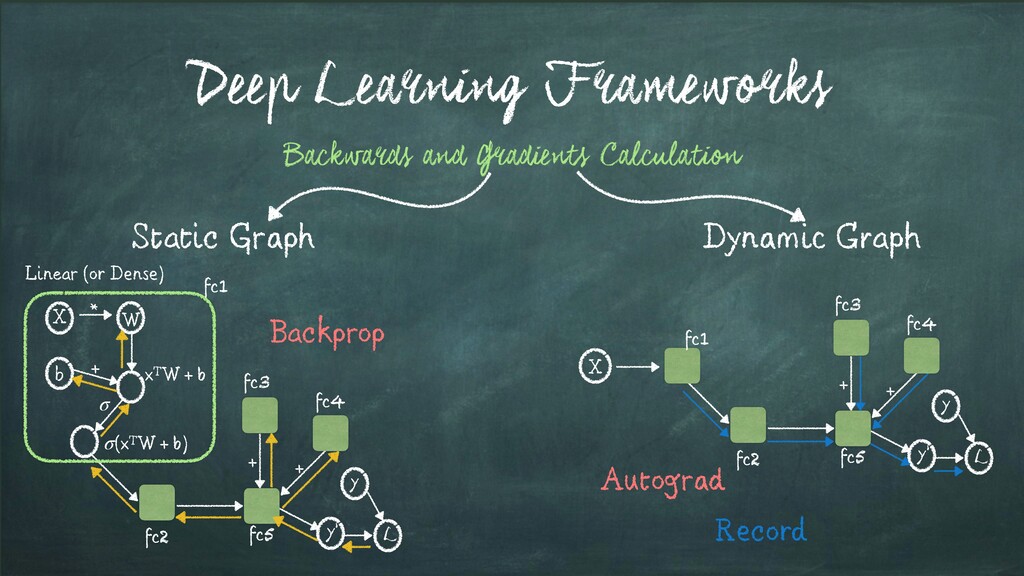
* + σ xTW + b (xTW + b) σ Backwards and Gradients Calculation Linear (or Dense) + + y L y’ fc1 fc2 fc3 fc4 fc5 + + y L y’ fc2 fc3 fc1 X fc5 fc4 Backprop Autograd Record
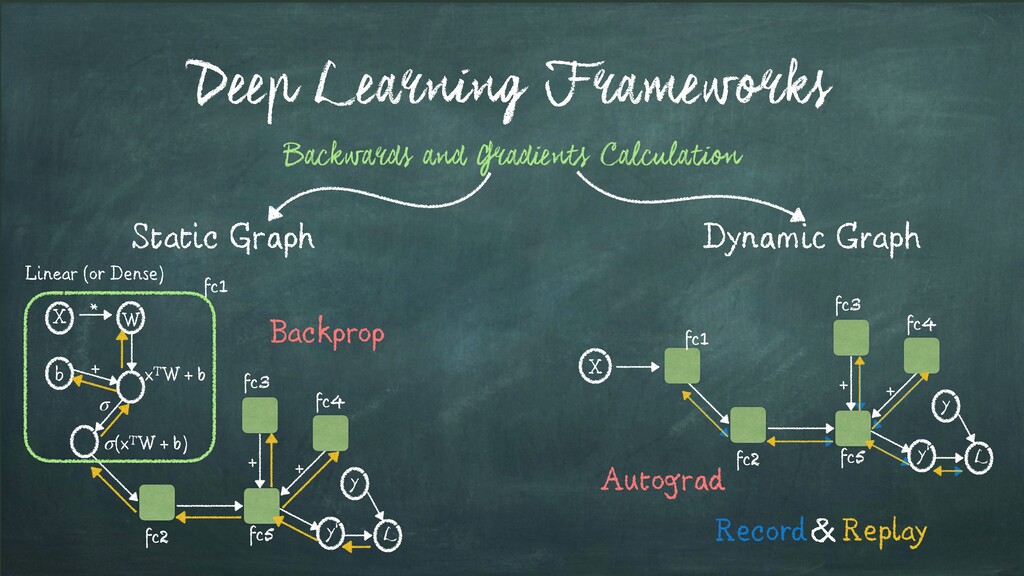
* + σ xTW + b (xTW + b) σ Backwards and Gradients Calculation Linear (or Dense) + + y L y’ fc1 fc2 fc3 fc4 fc5 + + y L y’ fc2 fc3 fc1 X fc5 fc4 Record Replay Backprop Autograd &
(tools & sw) Work on full pipeline (e.g. data preparation) Emphasis on the implementation Perspective: Researcher No off-the-shelf (so no “black-box”) solutions” References and Further Readings to know more features
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}