Privacy is to date one of the major impediment for Machine Learning (ML), when applied to sensitive dataset. One popular example is the case of ML applied to the medical domain, but this generally extends to any data scenario in which sensitive data have or simply cannot be used. Moreover, data anonymisation methods are also not enough to guarantee that privacy will be completely preserved. In fact, it is possible to exploit the _memoisation_ effect of DL models to exploit sensitive information about samples, and the original dataset used for training. However, *privacy-preserving machine learning* (PPML) methods promise to overcome all this issues, allowing to train Machine learning models on "data that cannot be seen".
The workshop will be organised in **two parts**: (1) in the first part, we will work on attacks to Deep Learning models, leveraging on their vulnerabilities to exploit insights on original (sensitive) data. We will then explore potential counter-measures to work around these issues.
Examples will include cases of image data, as well as textual data where attacks and counter-measures highlight different nuances and corner cases.
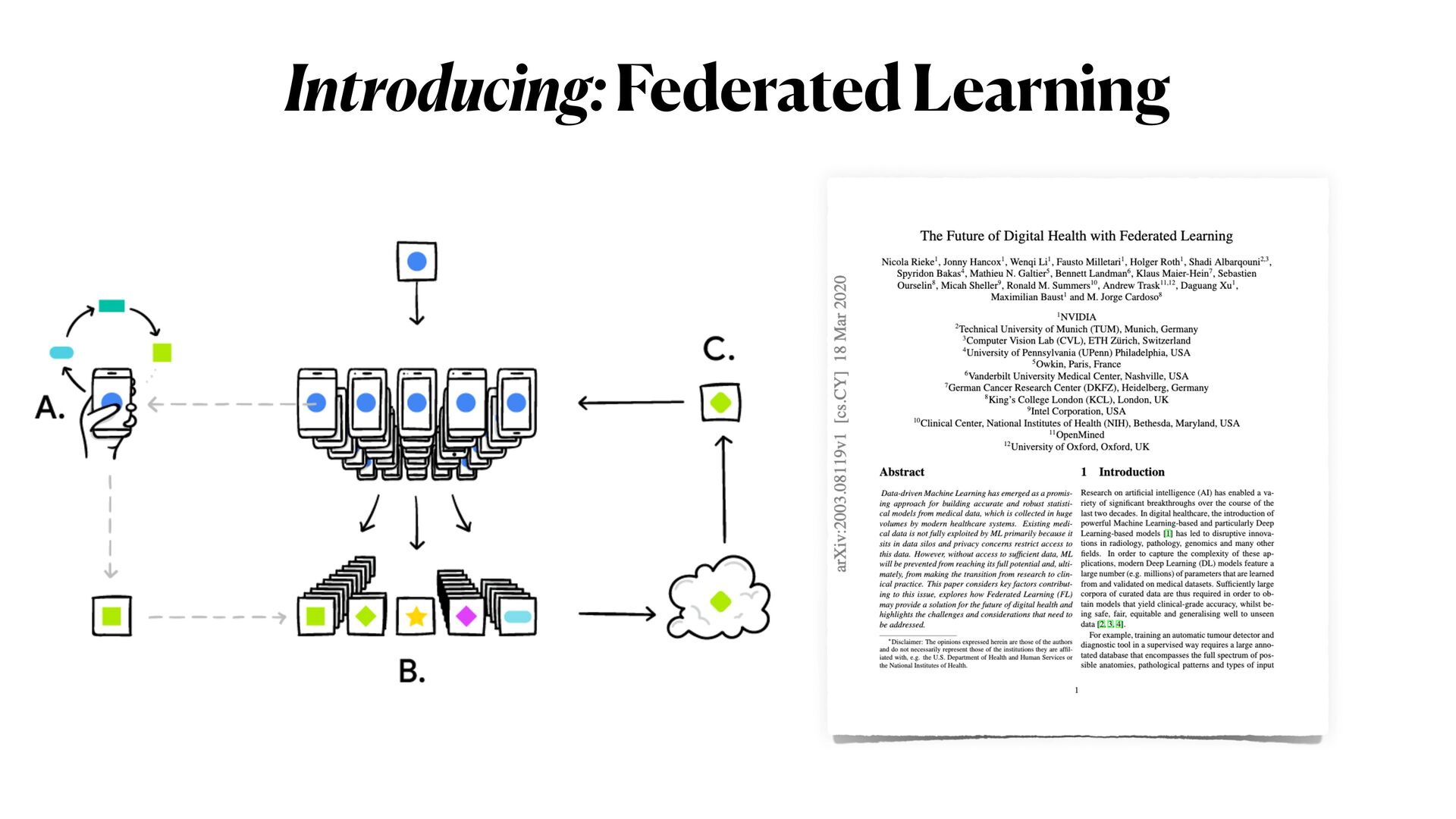
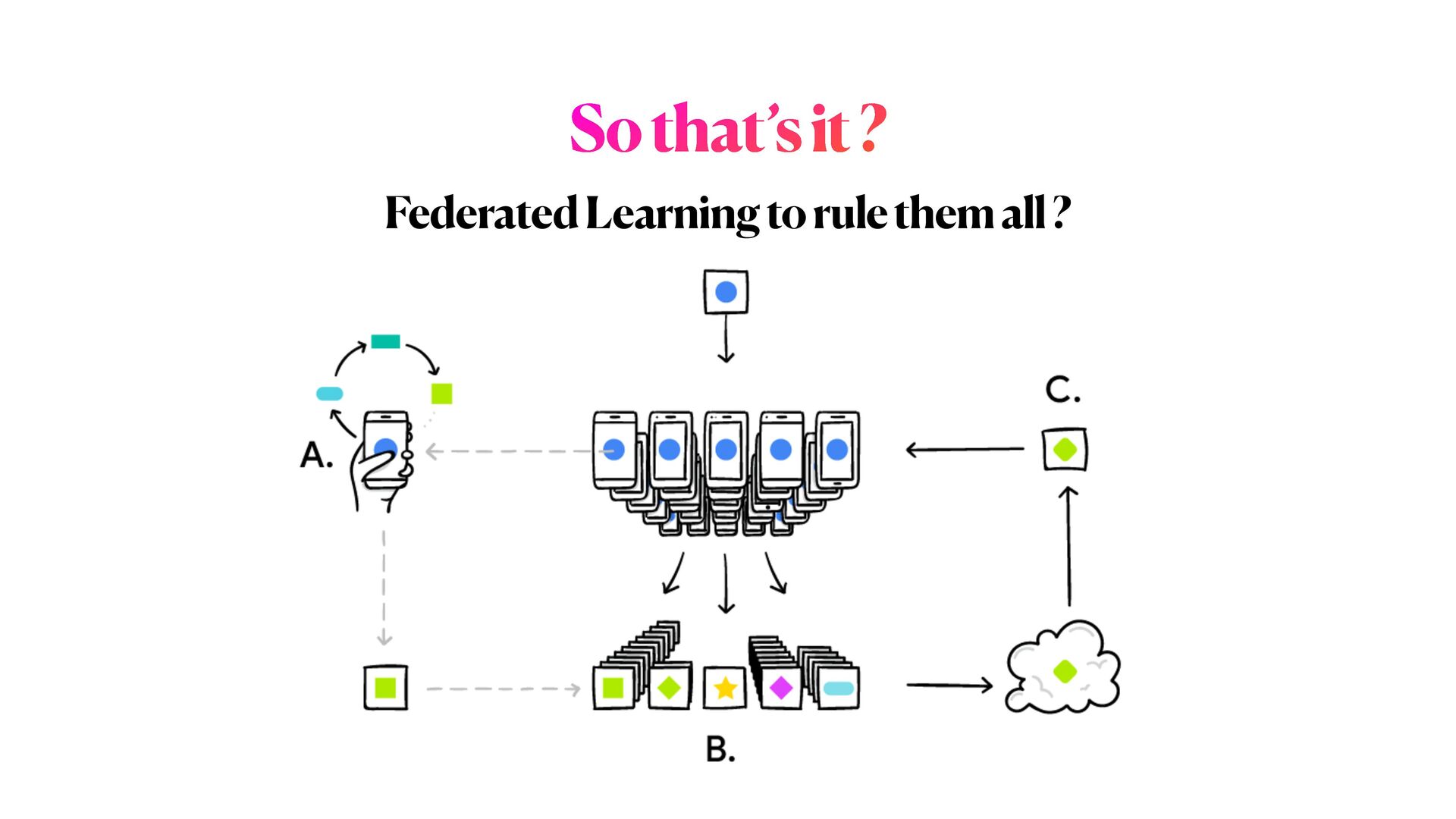
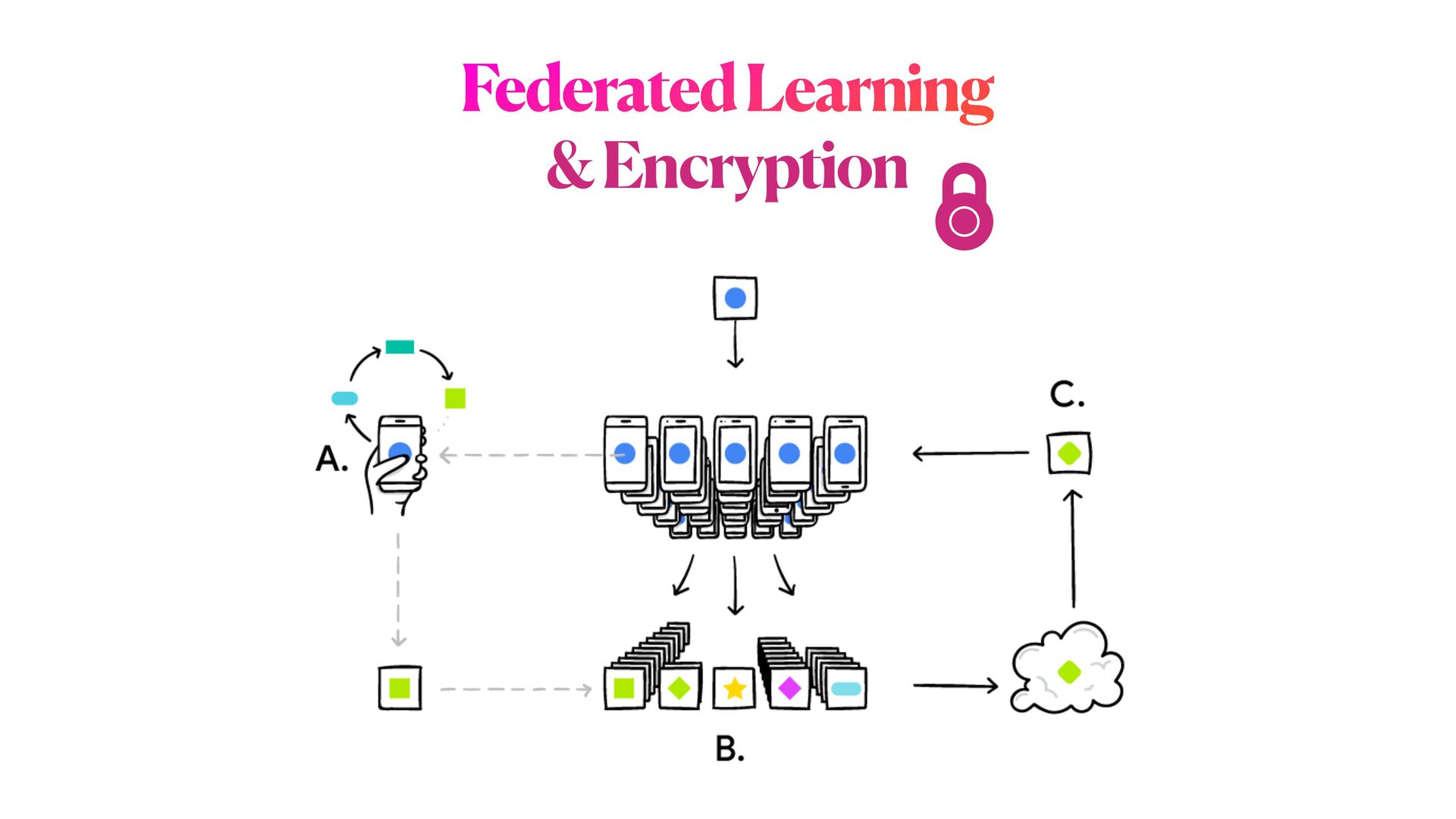
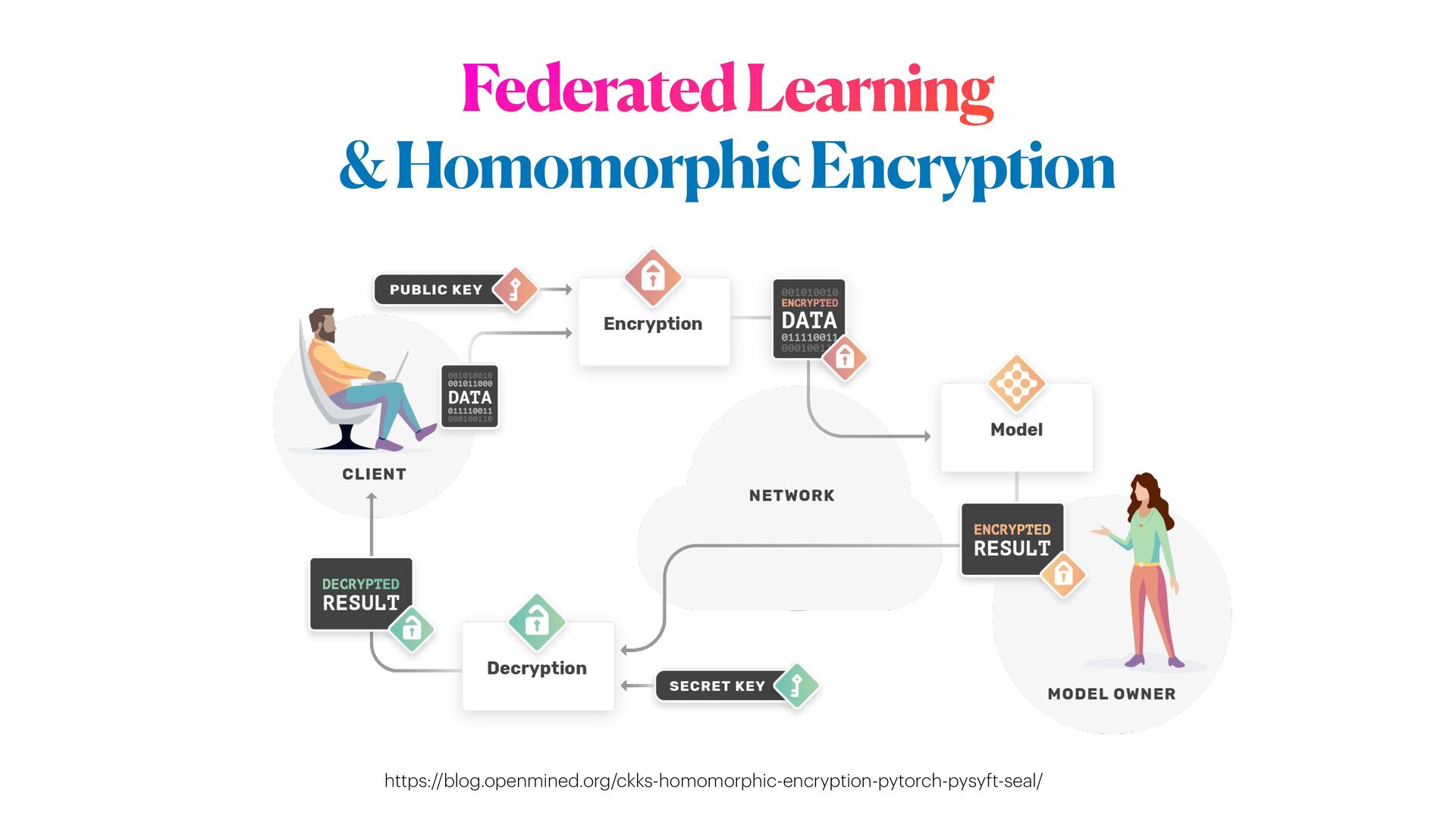
(2) In the second part of the workshop, will delve into PPML methods, focusing on mechanisms to train DL networks on encrypted data, as well as on specialised _distributed federated_ training strategies for multiple _sensitive_ datasets.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
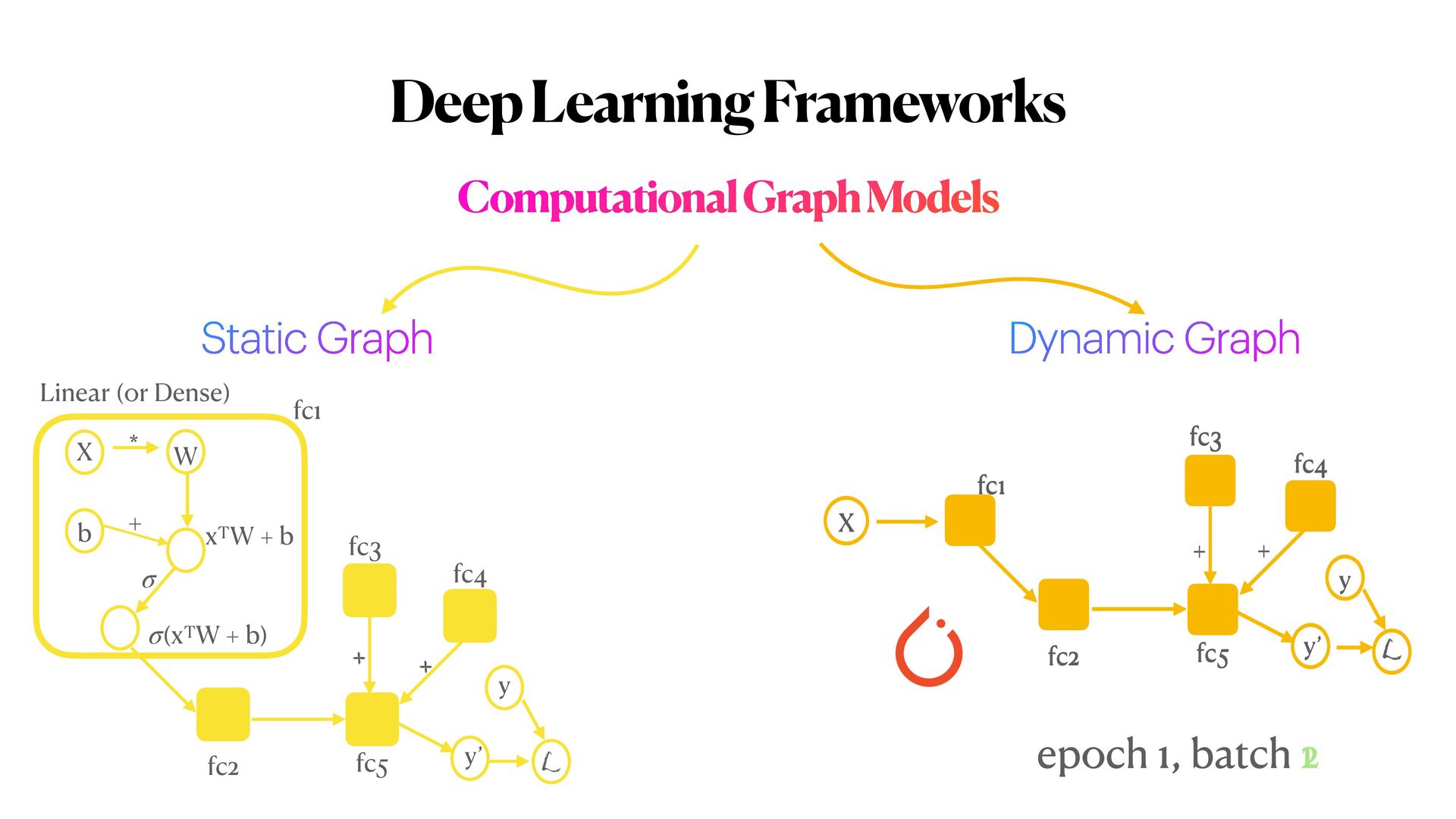{kind=link}
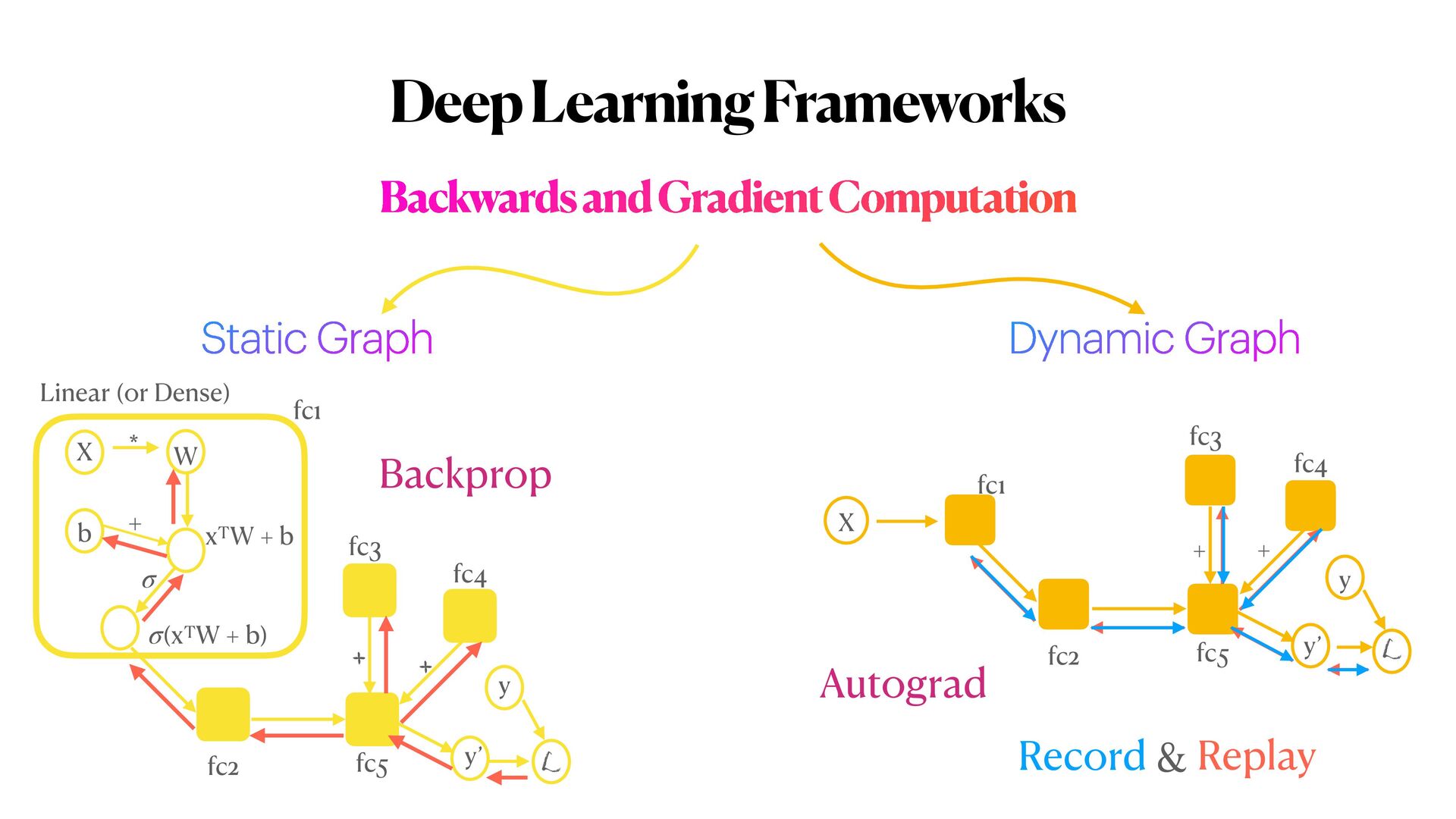{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
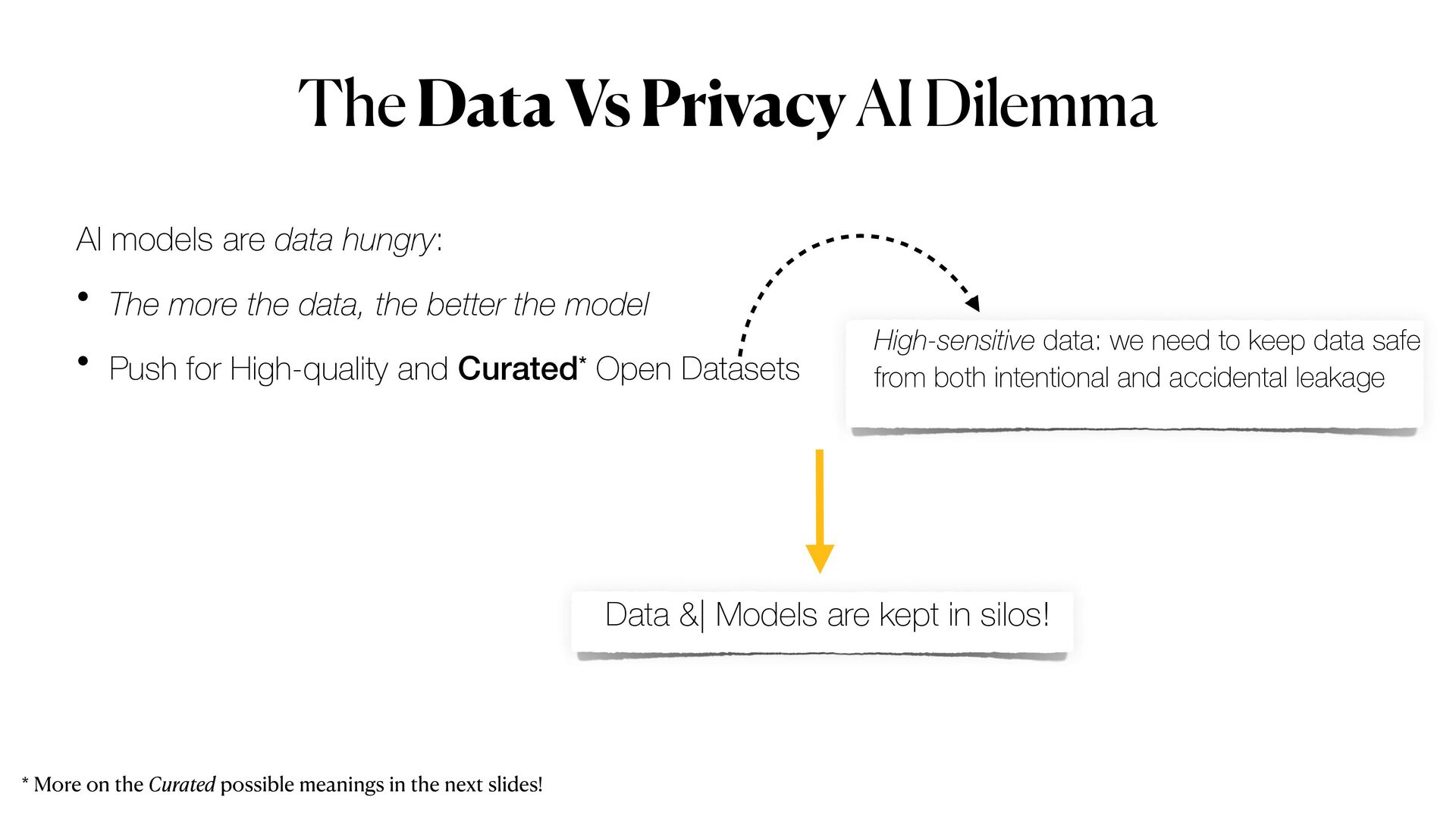{kind=link}
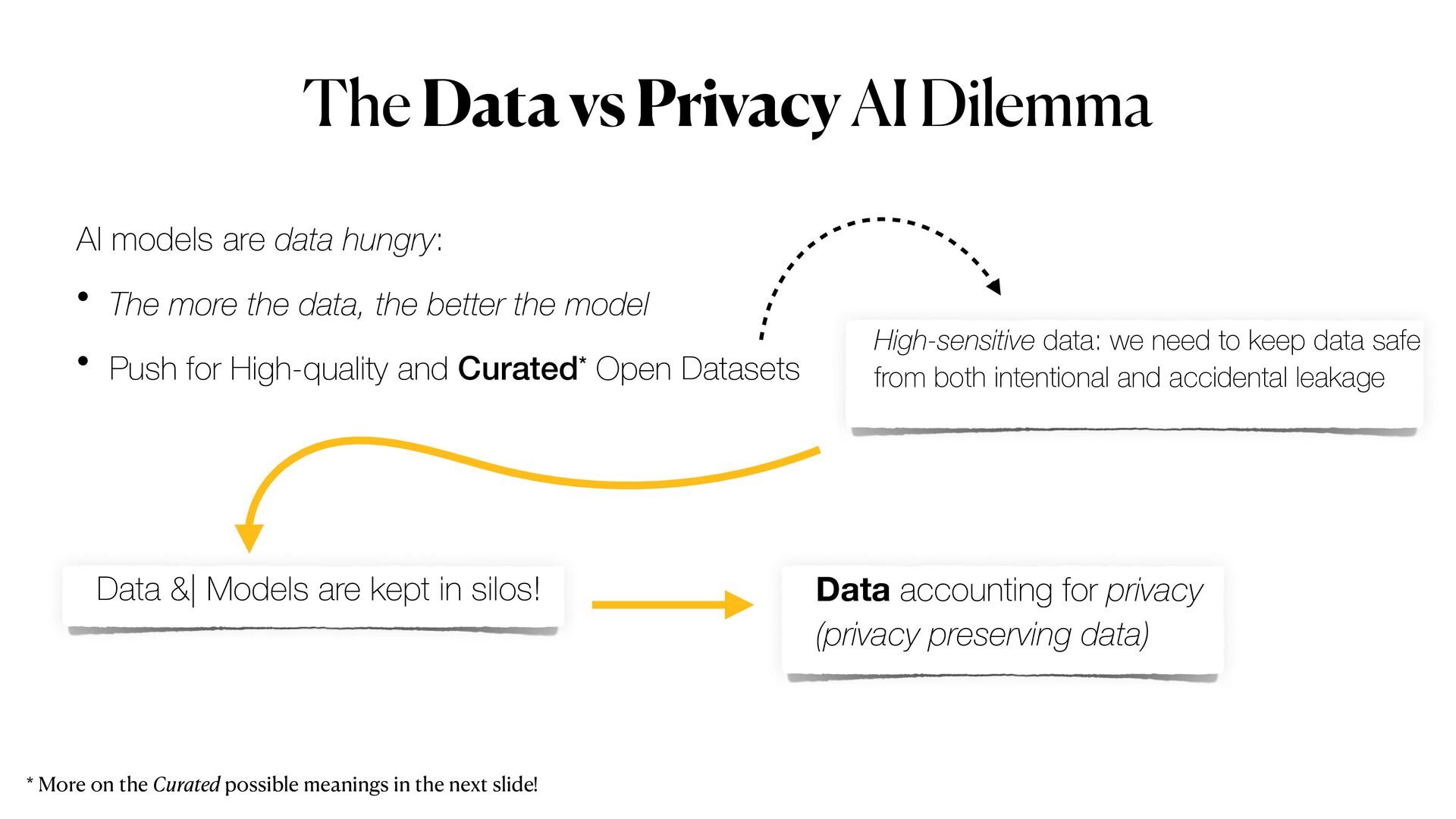{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}