surveillance is needed to enable services and provide security without onboard staff • Pose tracking would be useful as a base for action recognition Context 3
in frames • Linking the poses over time • The first stage is usually performed using a top-down pose detector. • A pose detector first detects human bounding boxes • A pose estimation method is used inside these bounding boxes 4 Related works
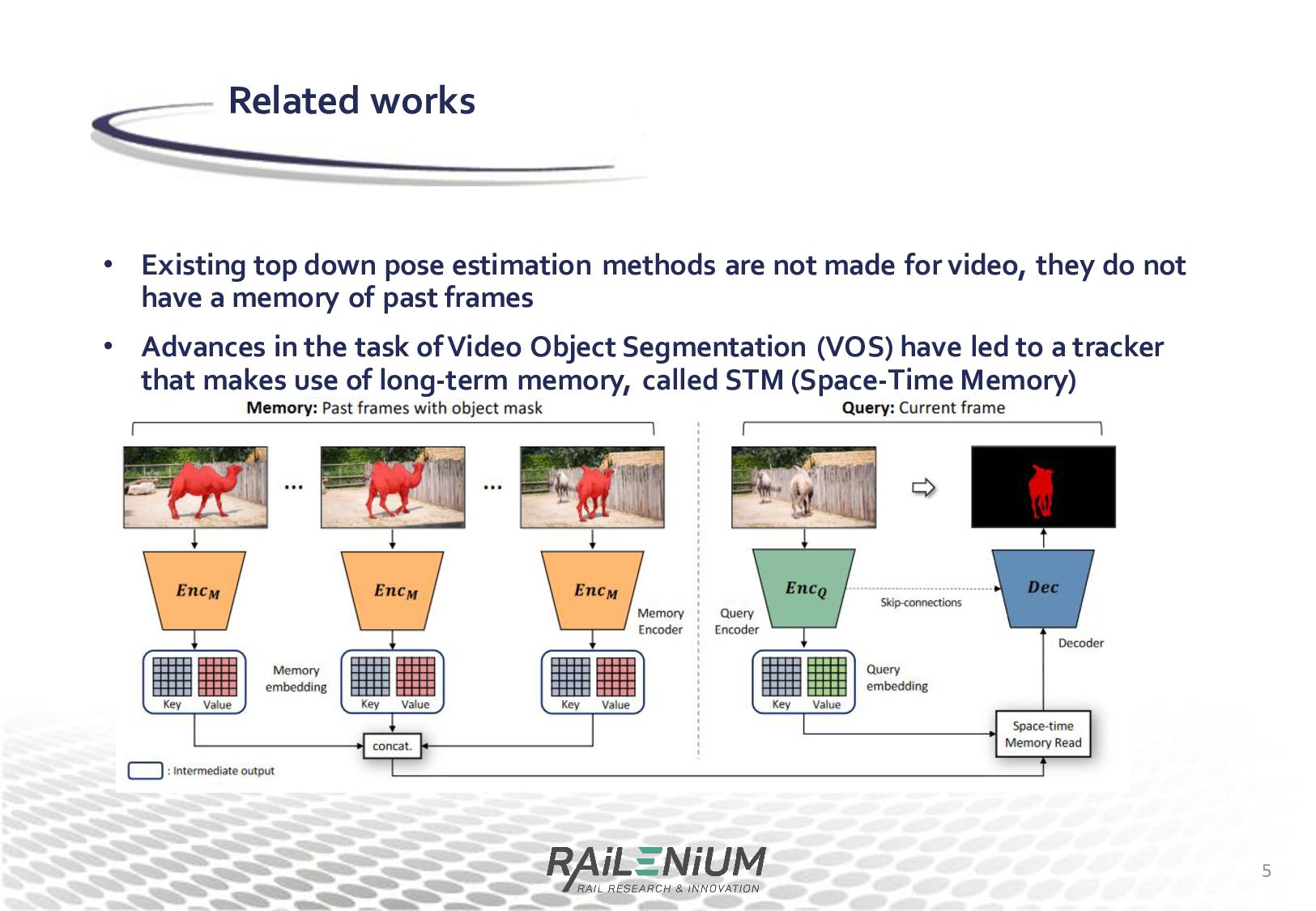
for video, they do not have a memory of past frames • Advances in the task of Video Object Segmentation (VOS) have led to a tracker that makes use of long-term memory, called STM (Space-Time Memory) 5 Related works
segmentation • The original STM weights are finetuned on this new task • First on the MS-COCO[1] image dataset (64114 images annotated with keypoints) • We generate short videos (2 to 4 frames) by translating/rotating individual images 7 Experiments : skeleton confidence map
obtained by initialising with ground truth for the first frame and then tracking for the rest of the video sequence 8 Experiments : skeleton confidence map
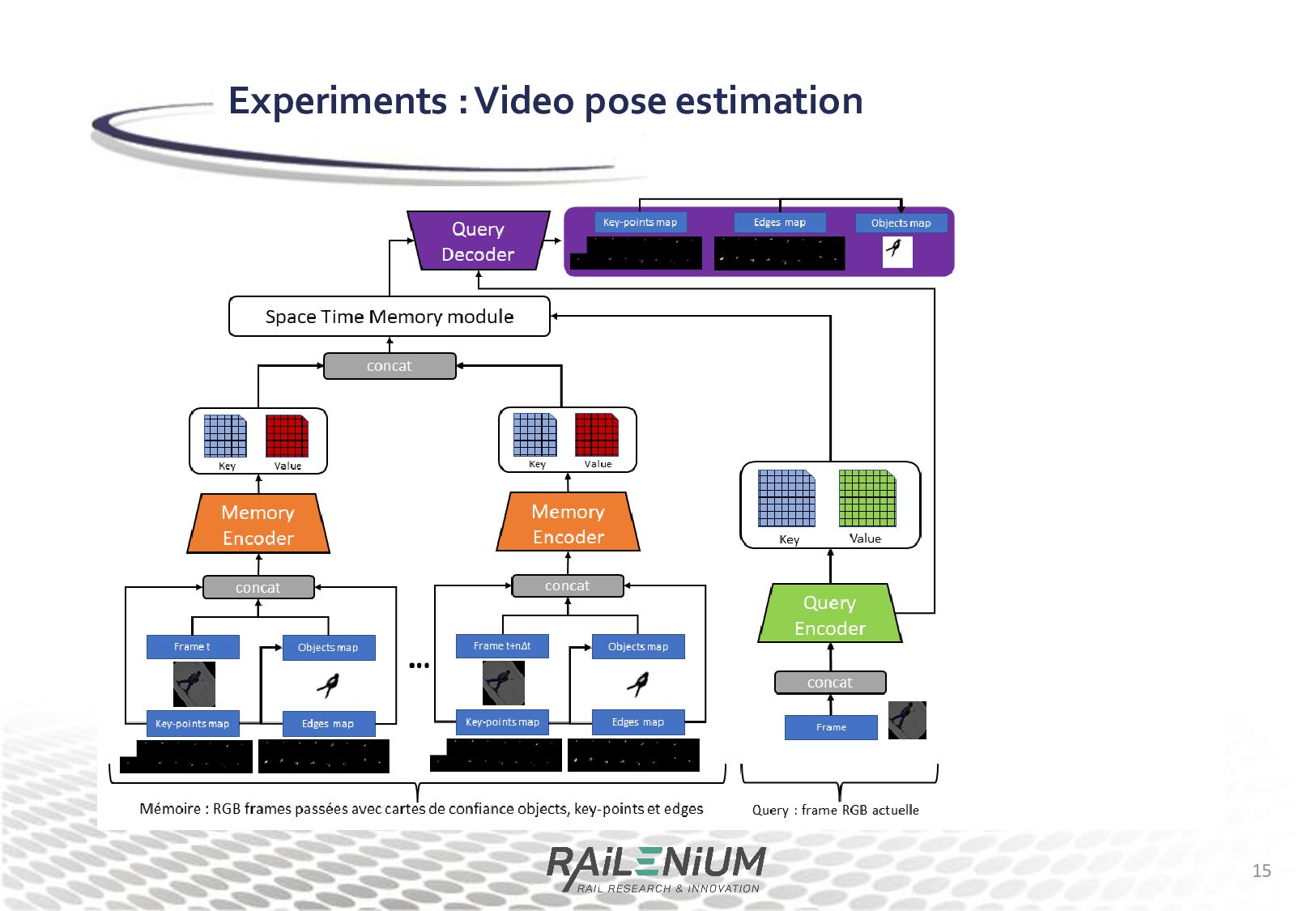
a STM architecture that handles each keypoint and each edge in a particular confidence map. • We try out multiple data augmentation method that aim at improving performance for long term tracking. without augmentations "rand" augmentation "baits" augmentation "jitter" augmentation "dull_clouds" augmentation
a STM architecture that handles each keypoint and each edge in a particular confidence map. • We try out multiple data augmentation method that aim at improving performance for long term tracking. without augmentations "rand" augmentation "baits" augmentation "jitter" augmentation
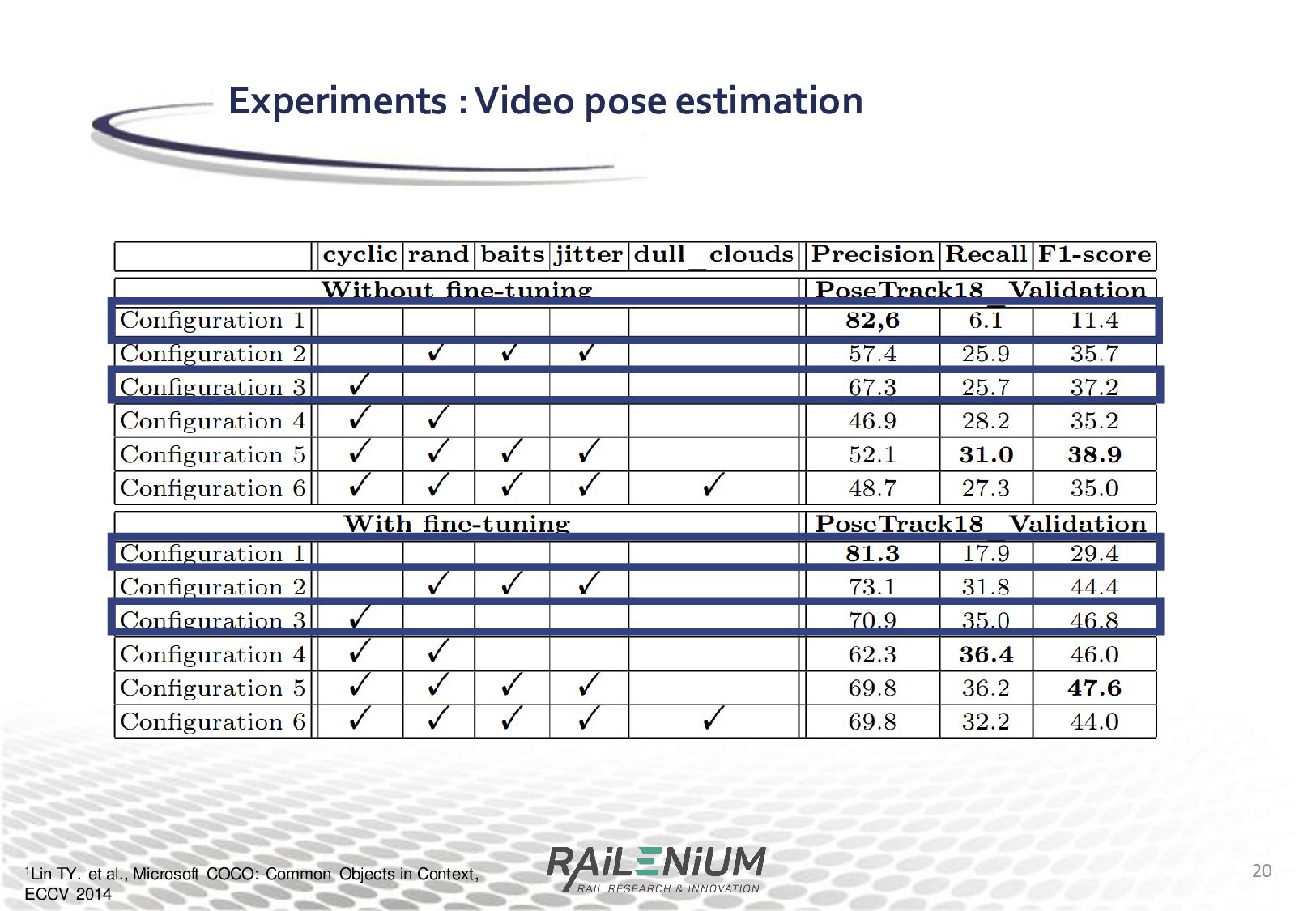
Context, ECCV 2014 Experiments : Video pose estimation • Finally, we use a STM architecture that handles each keypoint and each edge in a particular confidence map. • We try out multiple data augmentation method that aim at improving performance for long term tracking. • Cyclic training : During training, the model is fed back its own prediction for the previous frame, repeatedly
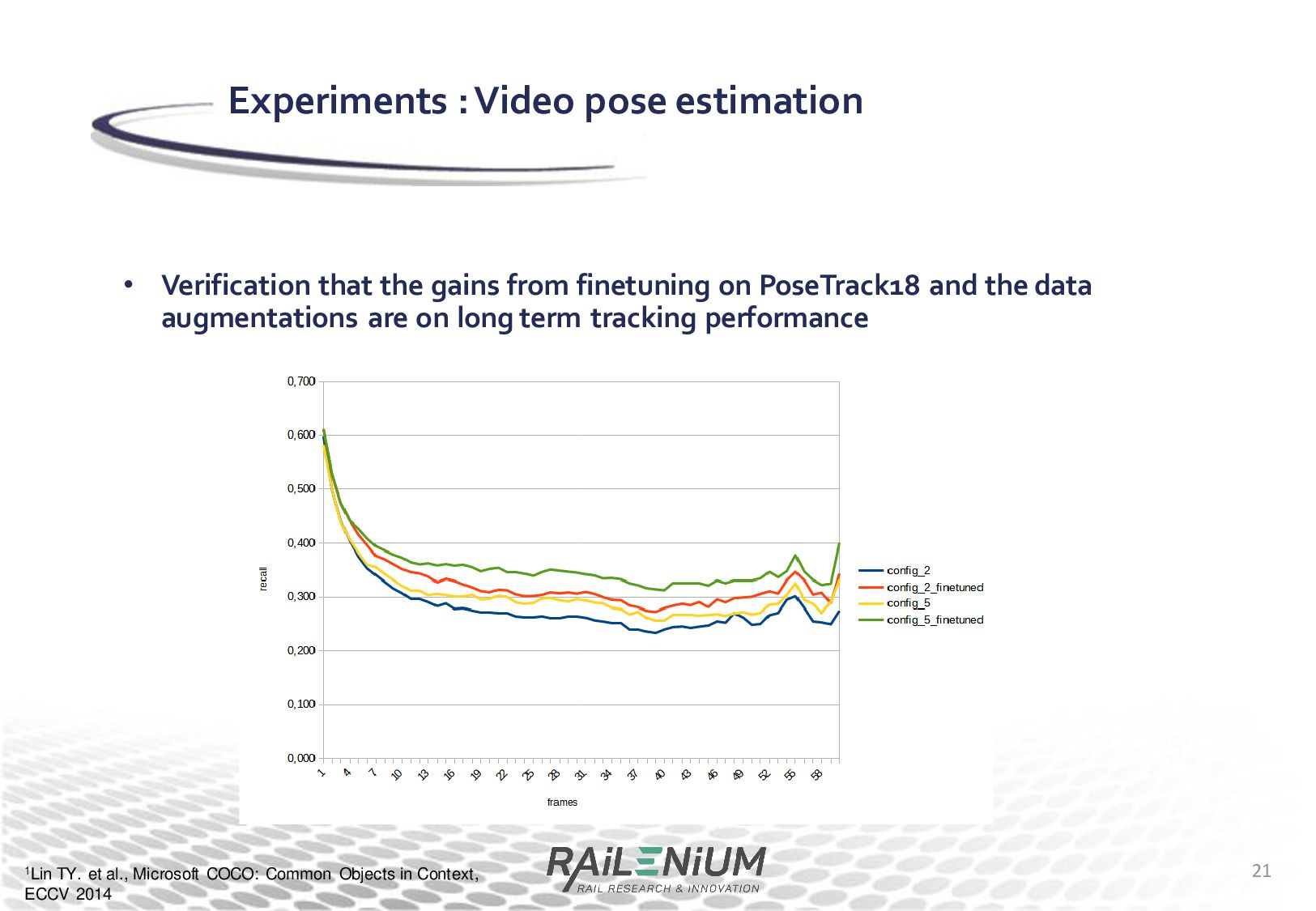
Context, ECCV 2014 Experiments : Video pose estimation • Verification that the gains from finetuning on PoseTrack18 and the data augmentations are on long term tracking performance
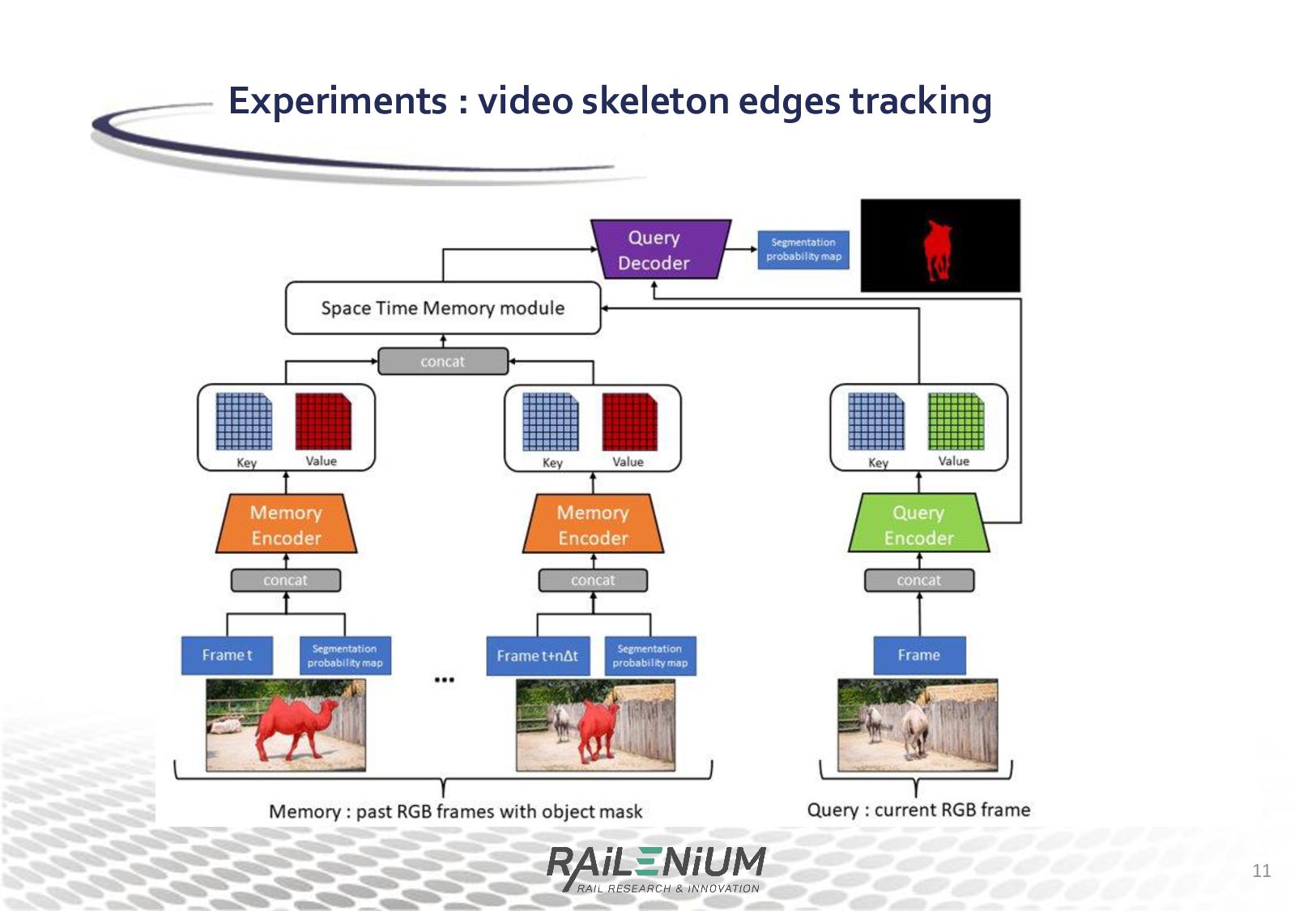
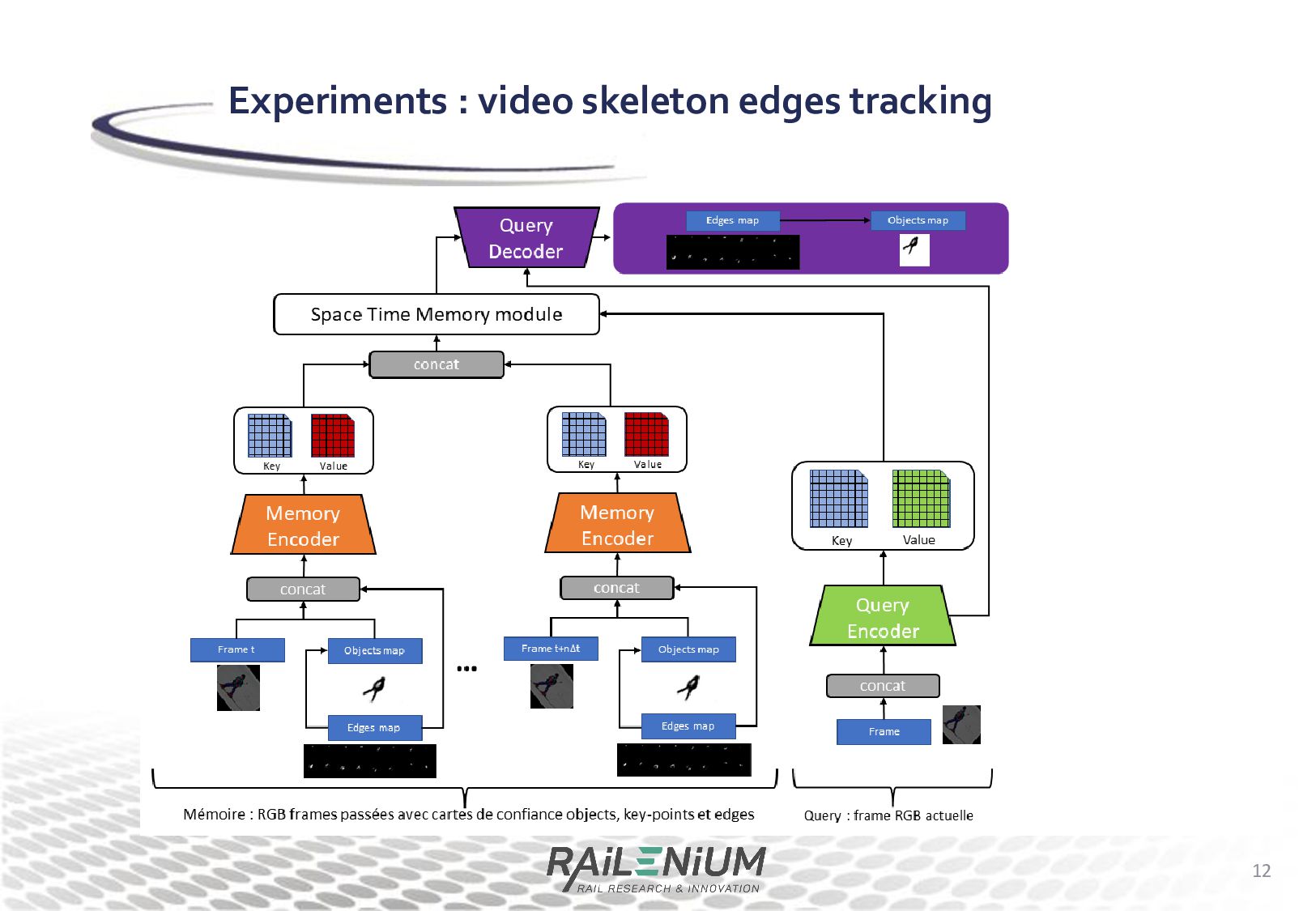
handle skeletons rather than segment the contour of the tracked object • We have then shown that the STM architecture can be modified to track each skeleton edge individually • Finally, we test a new architecture that can track skeleton keypoints and edges, and experiment with different training procedures and data augmentation methods. • Finetuning on the train set of PoseTrack18 • Cyclic training • Data augmentation "baits" and "jitter" shown to help • The next step should be to compare to other pose tracking methods Conclusion 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• Then, we finetune on the PoseTrack[1] dataset for 5](https://files.speakerdeck.com/presentations/a9bace5dc85140cca0b2f91a4fe41778/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}