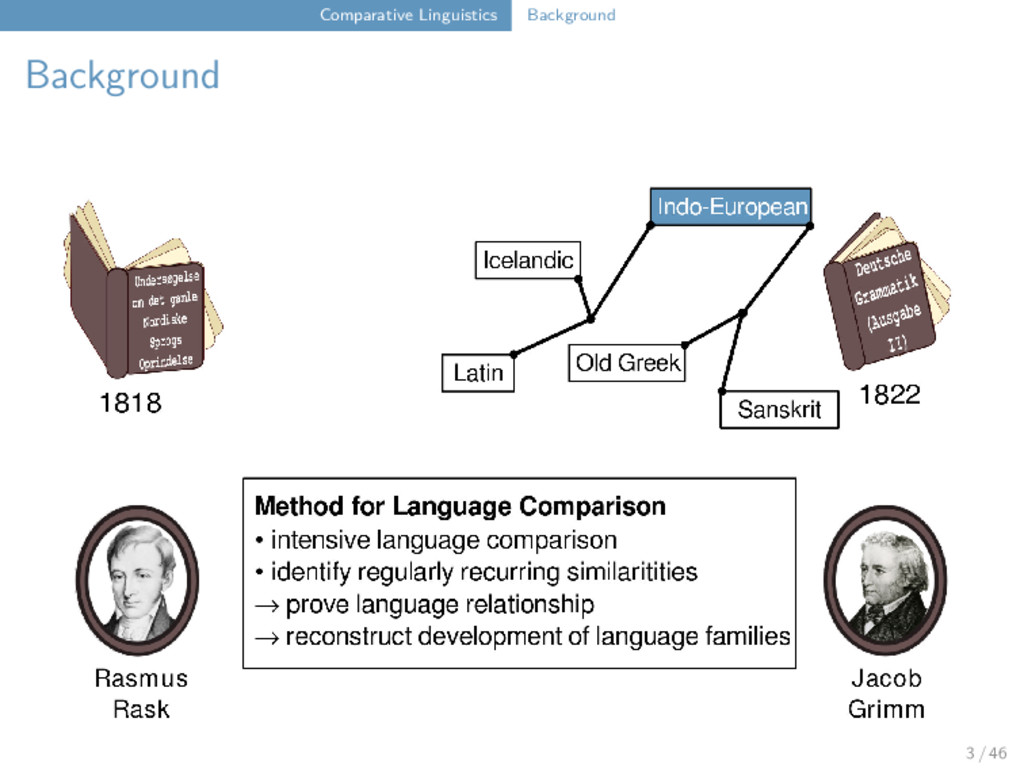
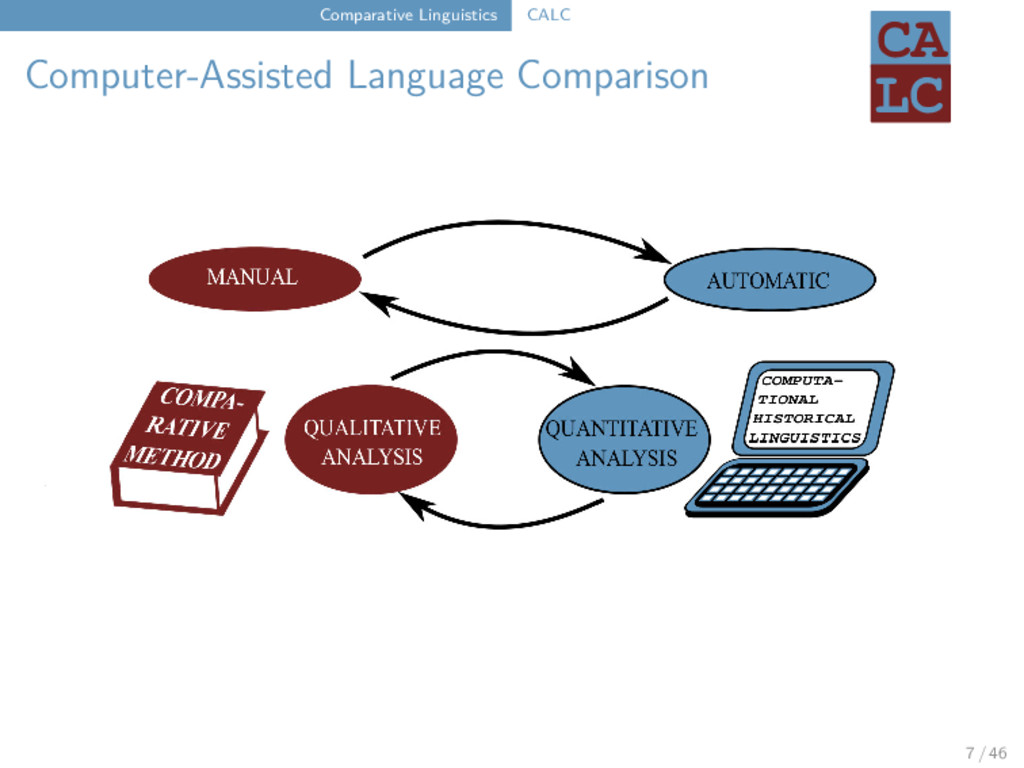
List Research Group “Computer-Assisted Language Comparison” Department of Linguistic and Cultural Evolution Max-Planck Institute for the Science of Human History Jena, Germany 2018-03-23 very long title P(A|B)=P(B|A)... 1 / 46
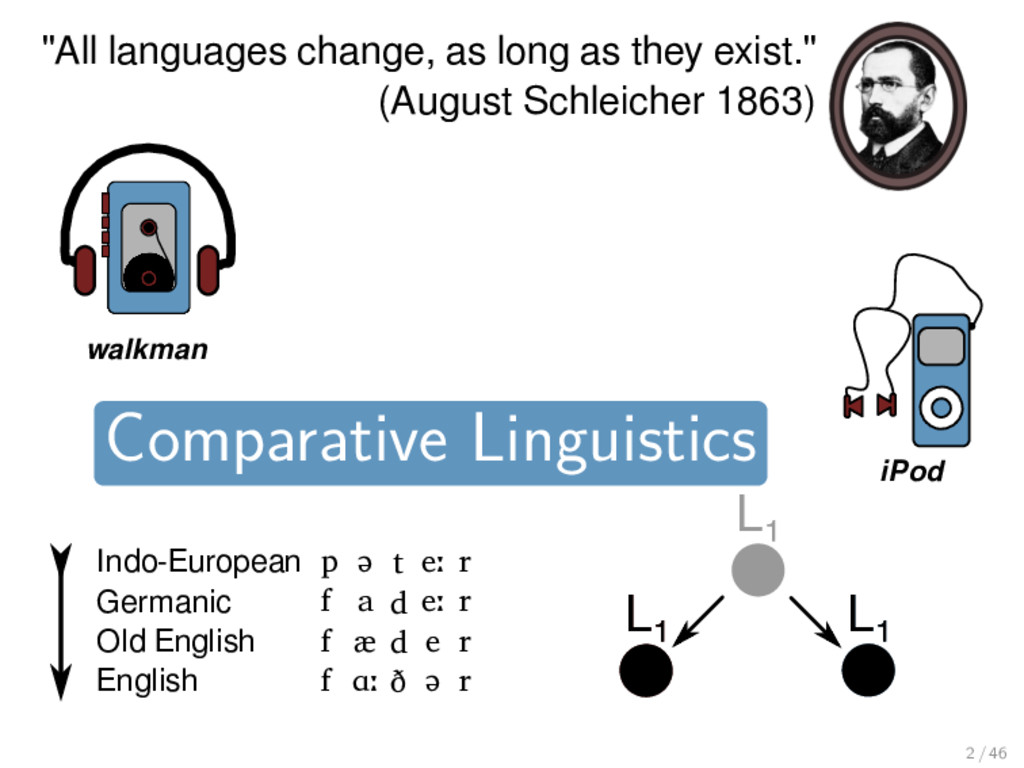
1863) walkman Indo-European Germanic Old English English p f f f ə a æ ɑː t d d ð eː eː e ə r r r r Germanic German English iPod Comparative Linguistics 2 / 46
ə a æ ɑː t d d ð eː eː e ə r r r r Germanic German English walkman "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics 2 / 46
ə a æ ɑː t d d ð eː eː e ə r r r r Germanic German English iPod "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics 2 / 46
ə a æ ɑː t d d ð eː eː e ə r r r r Germanic German English iPod "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics 2 / 46
ə a æ ɑː t d d ð eː eː e ə r r r r walkman L₁ L₁ L₁ L₁ L₁ "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics 2 / 46
ə a æ ɑː t d d ð eː eː e ə r r r r walkman L₁ L₁ L₁ L₁ L₁ "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics 2 / 46
ə a æ ɑː t d d ð eː eː e ə r r r r walkman L₁ L₁ L₁ L₁ L₁ "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics 2 / 46
ə a æ ɑː t d d ð eː eː e ə r r r r walkman L₁ L₁ L₁ "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics 2 / 46
ə a æ ɑː t d d ð eː eː e ə r r r r walkman L₂ L₁ L₃ "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics 2 / 46
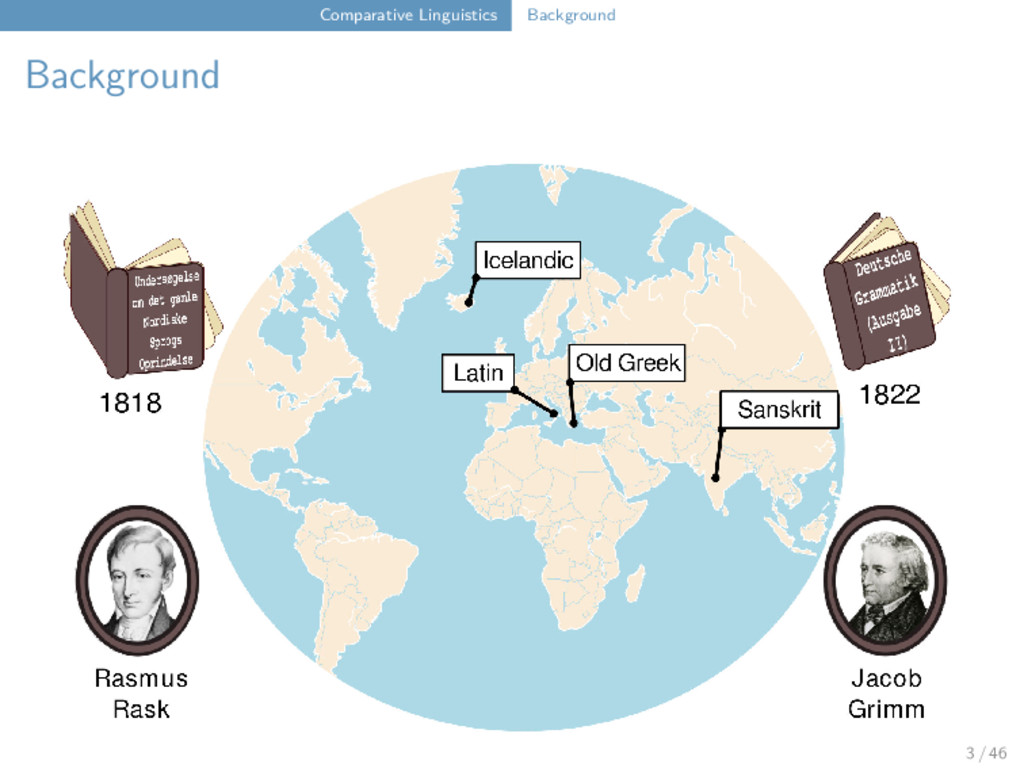
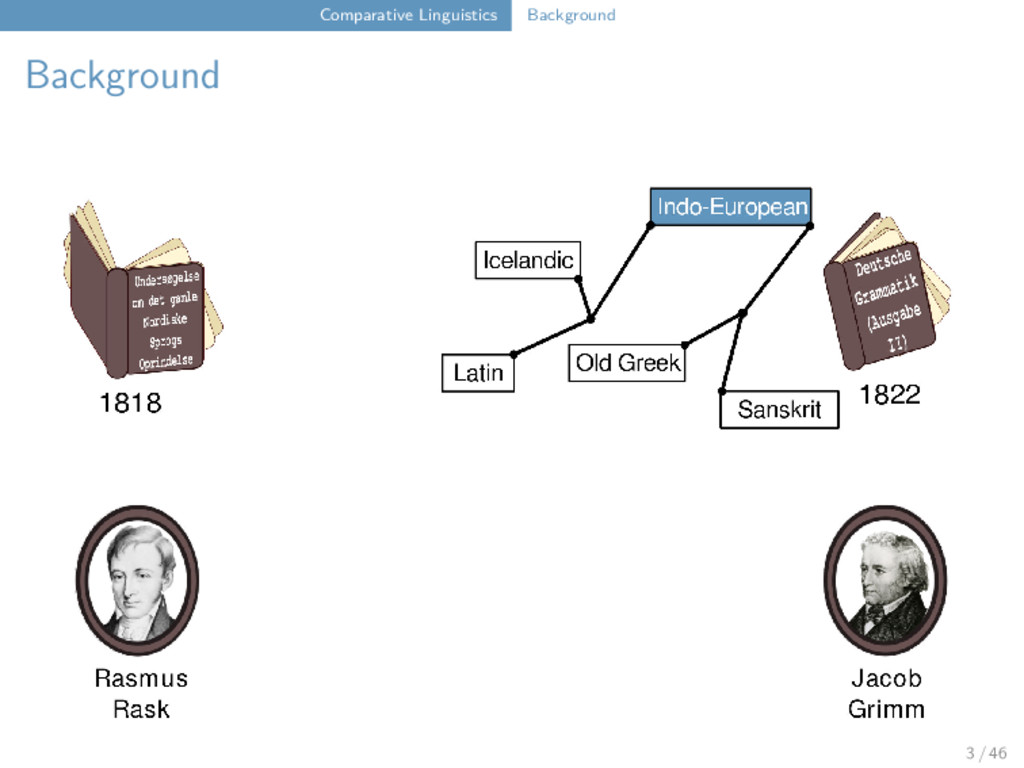
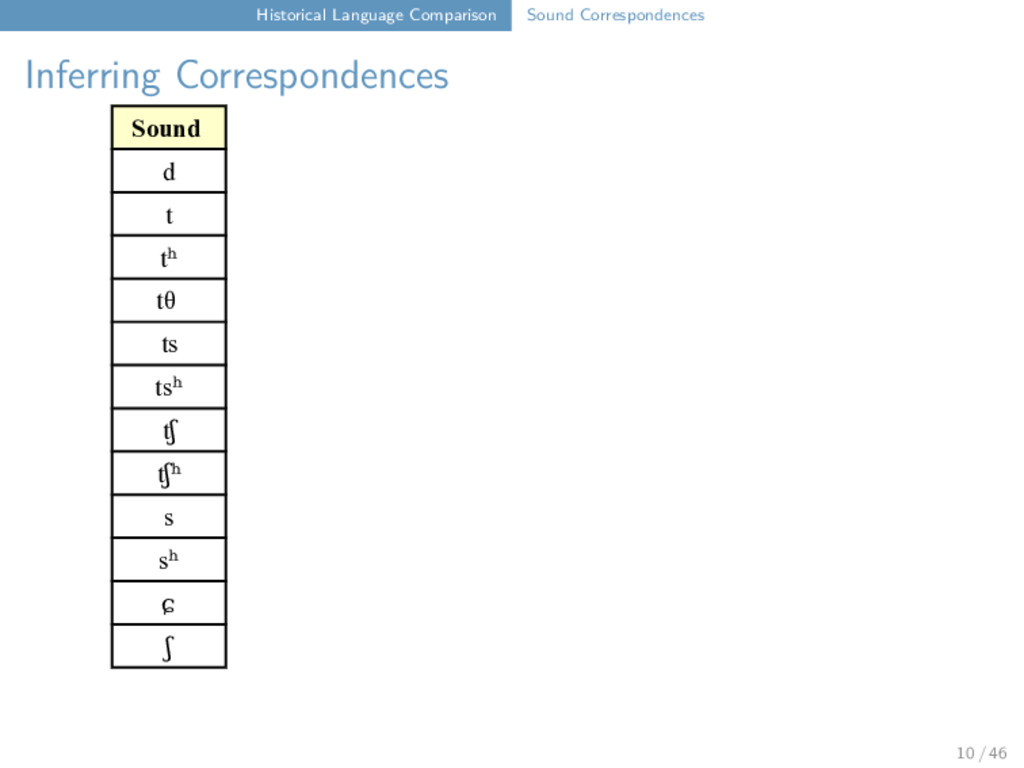
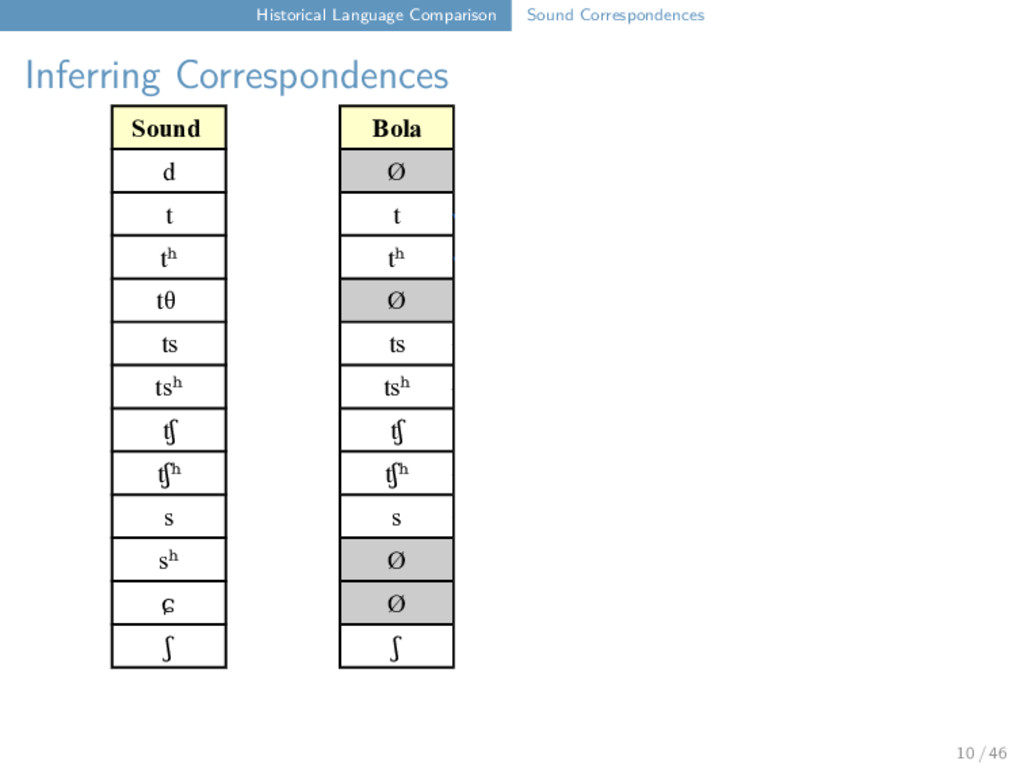
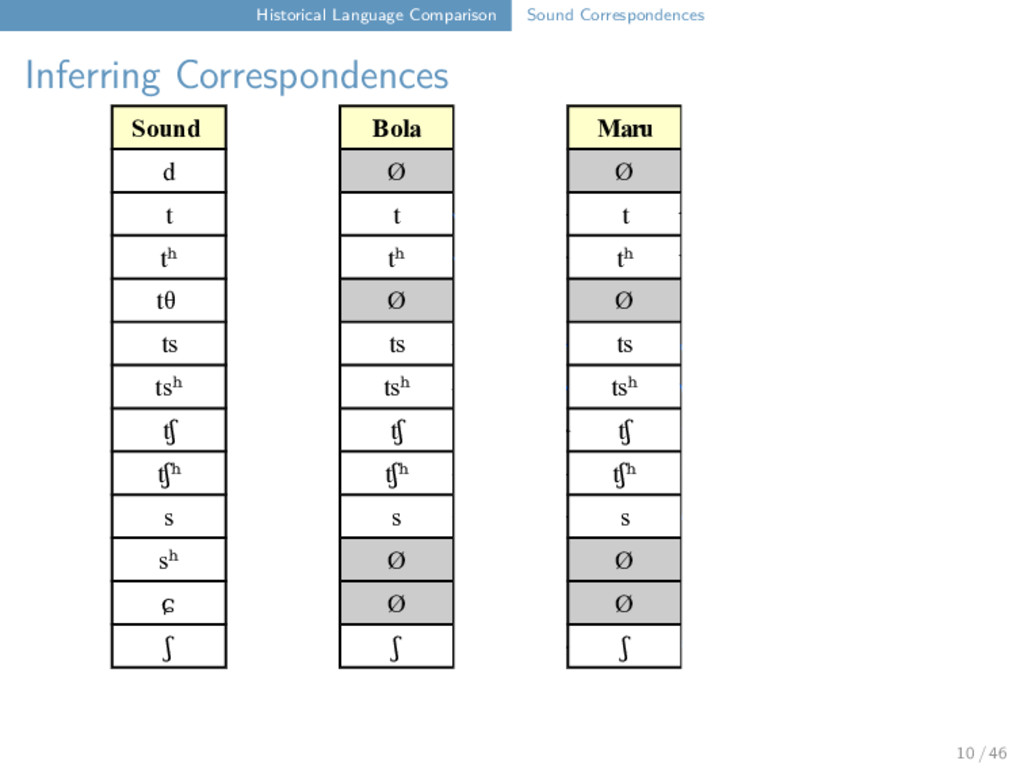
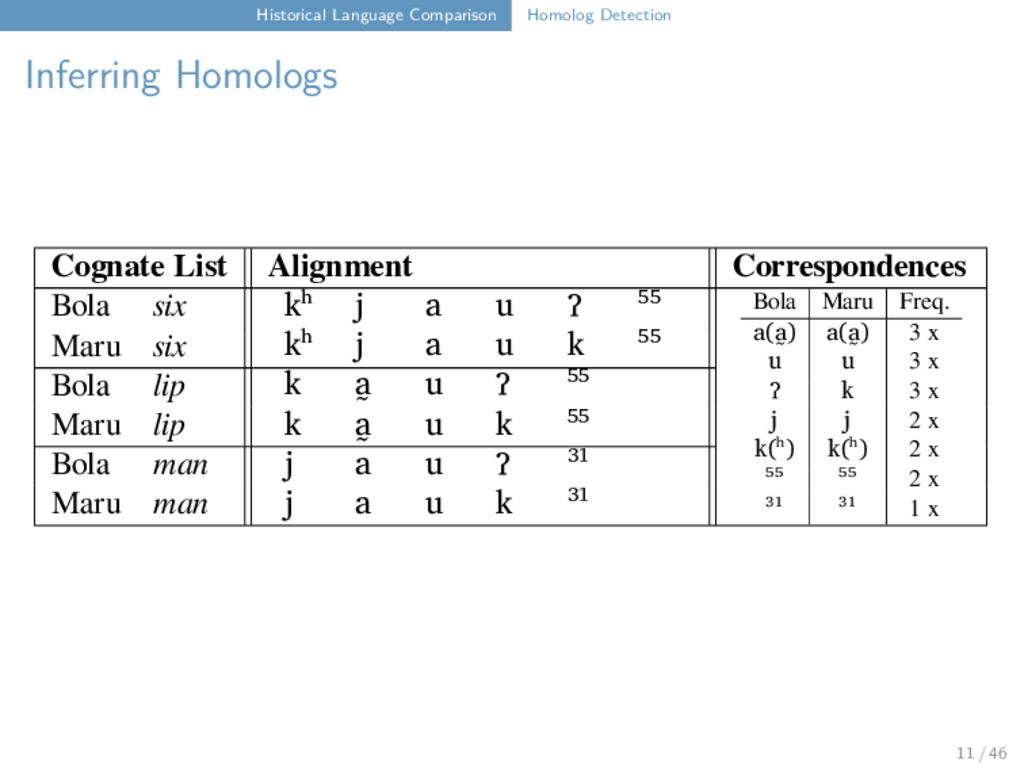
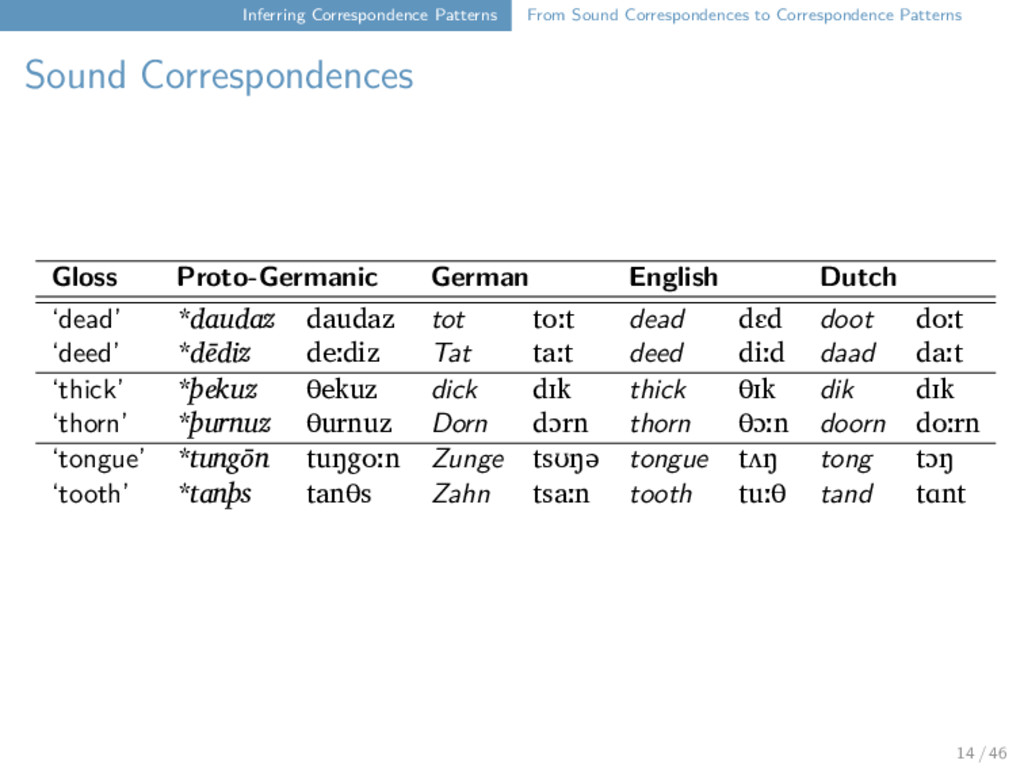
Correspondences Bola six kʰ j a u ʔ ⁵⁵ Bola Maru Freq. a(a̰) a(a̰) 3 x u u 3 x ʔ k 3 x j j 2 x k(ʰ) k(ʰ) 2 x ⁵⁵ ⁵⁵ 2 x ³¹ ³¹ 1 x Maru six kʰ j a u k ⁵⁵ Bola lip k a̰ u ʔ ⁵⁵ Maru lip k a̰ u k ⁵⁵ Bola man j a u ʔ ³¹ Maru man j a u k ³¹ 11 / 46
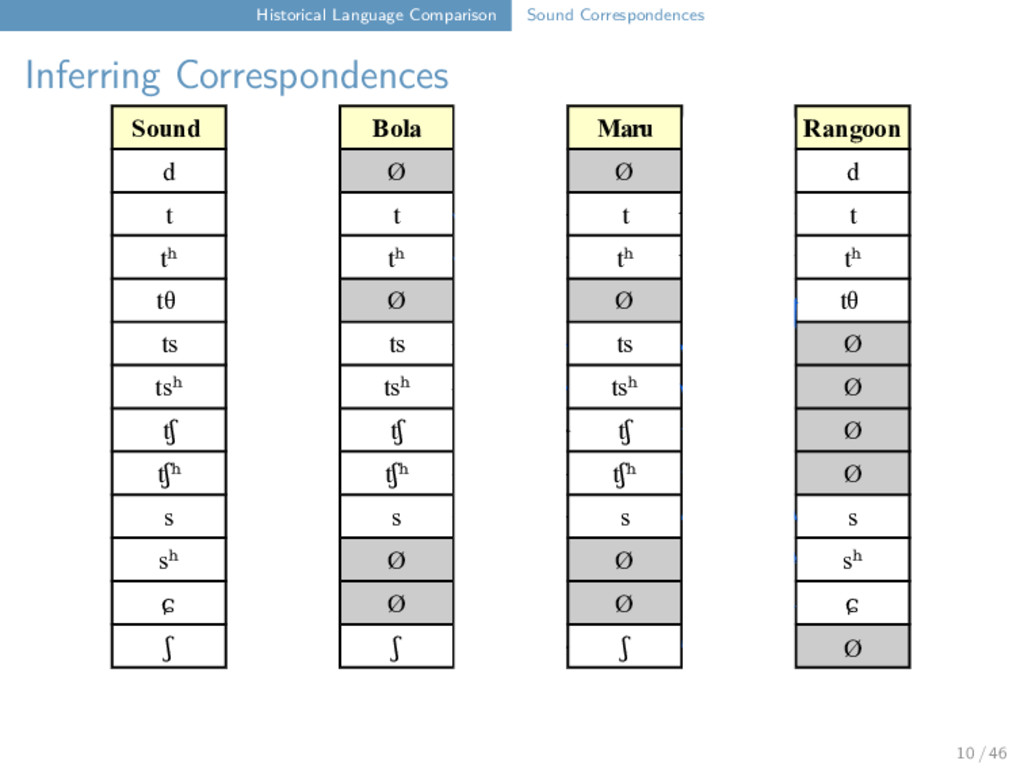
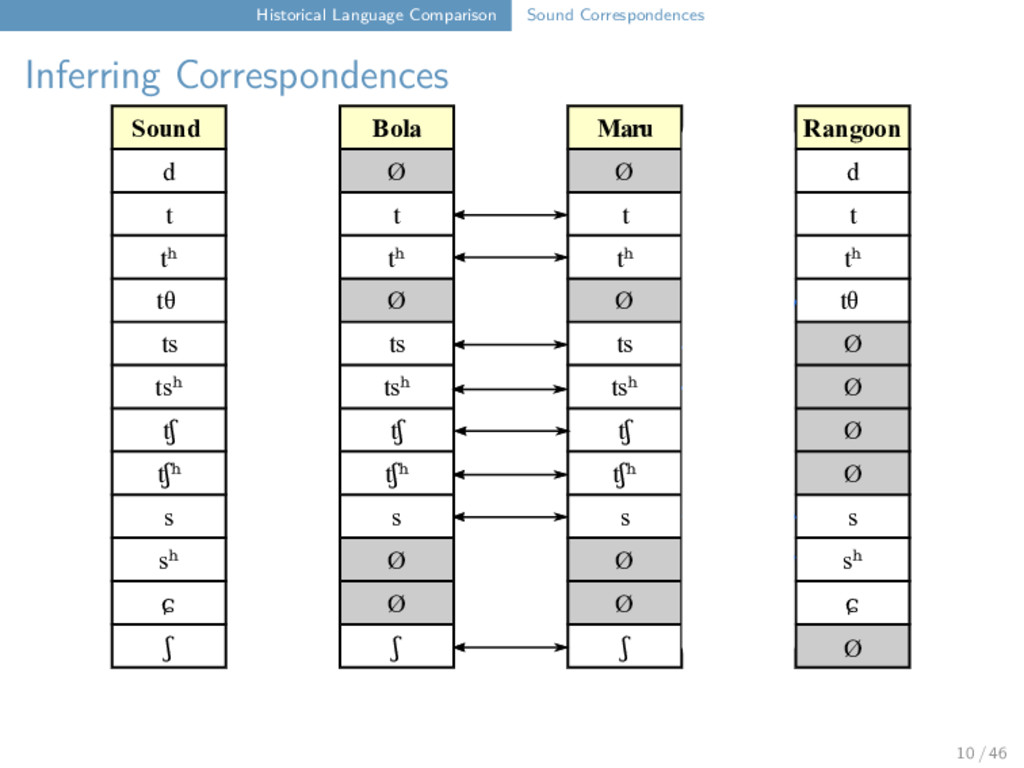
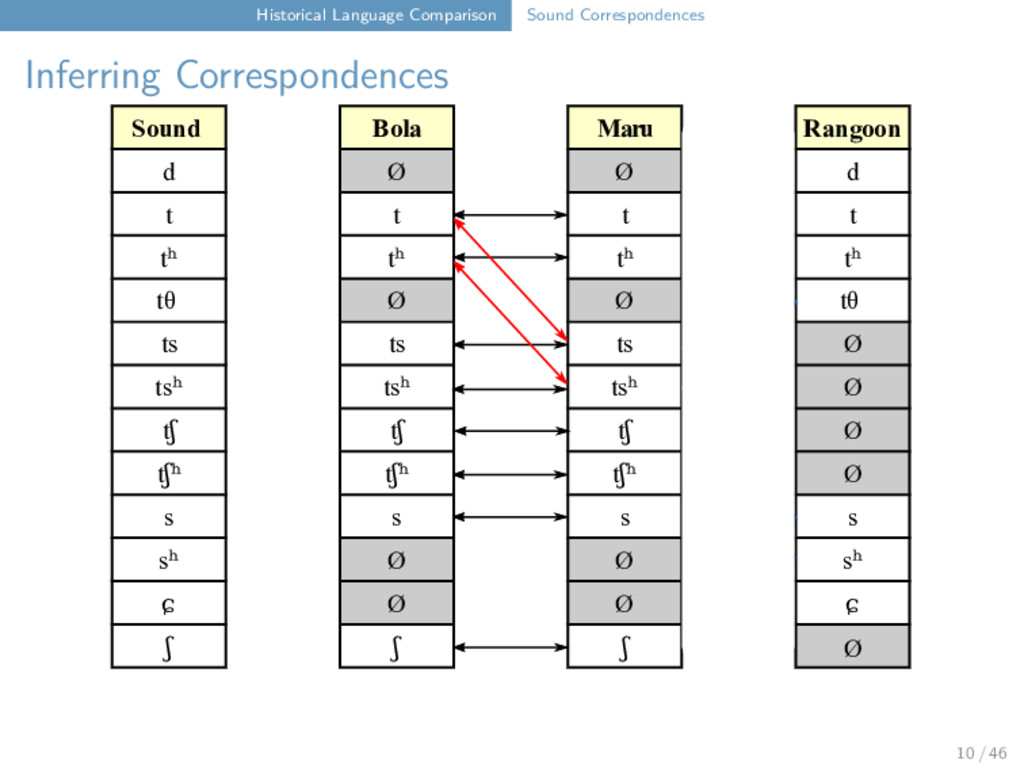
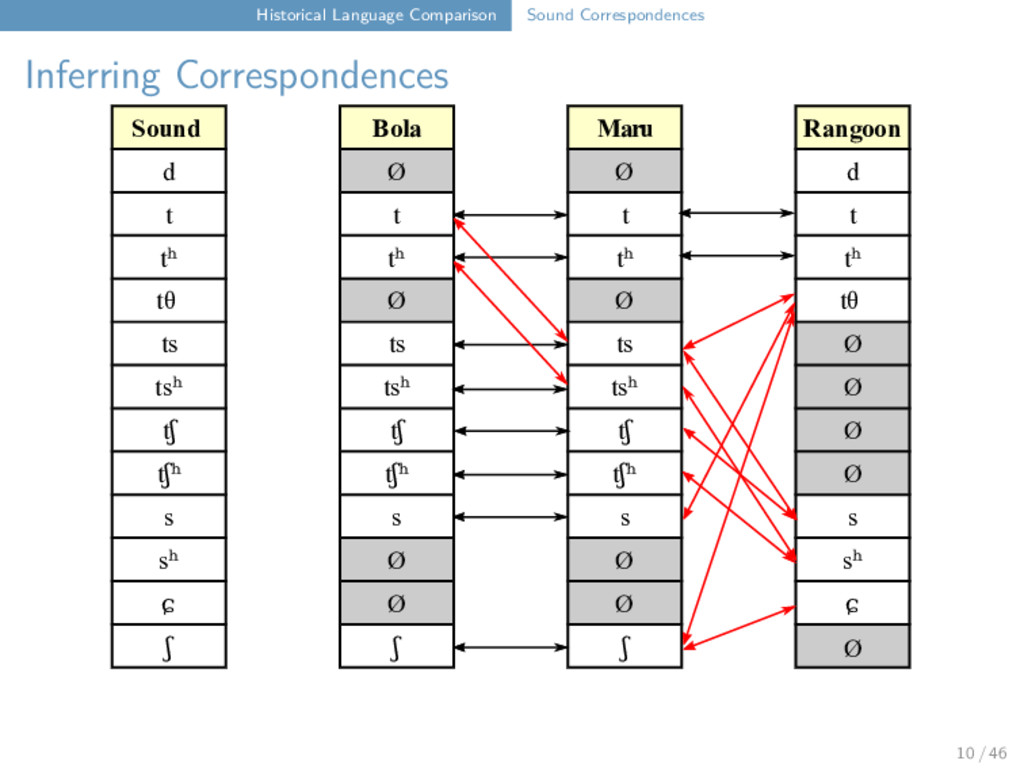
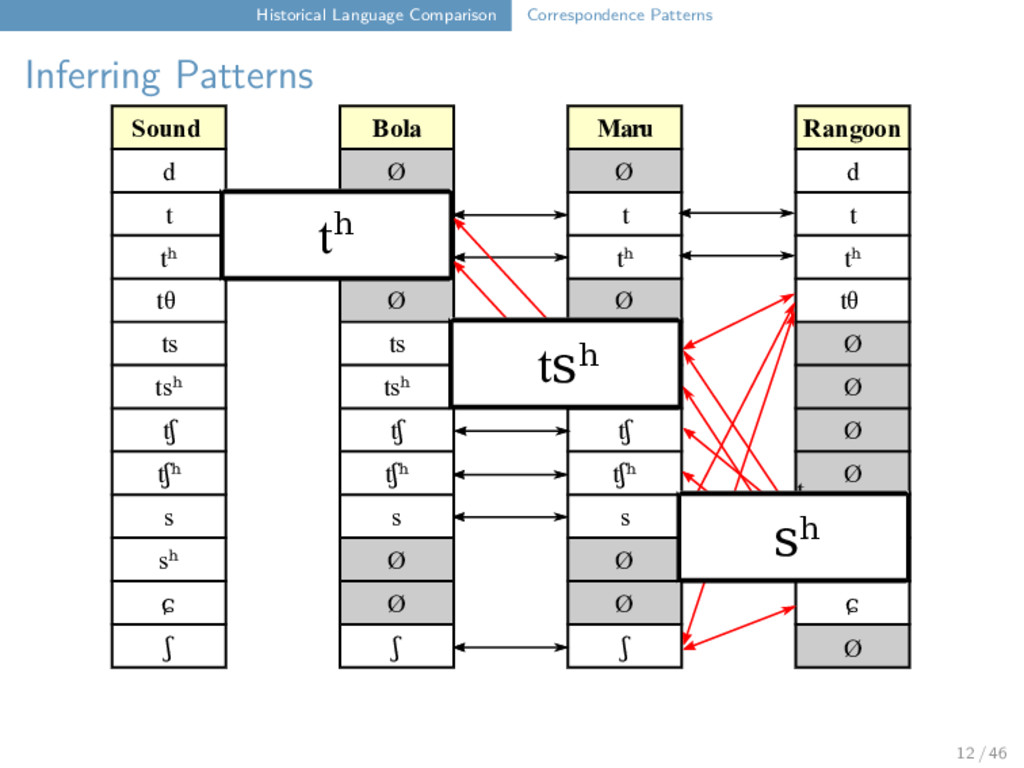
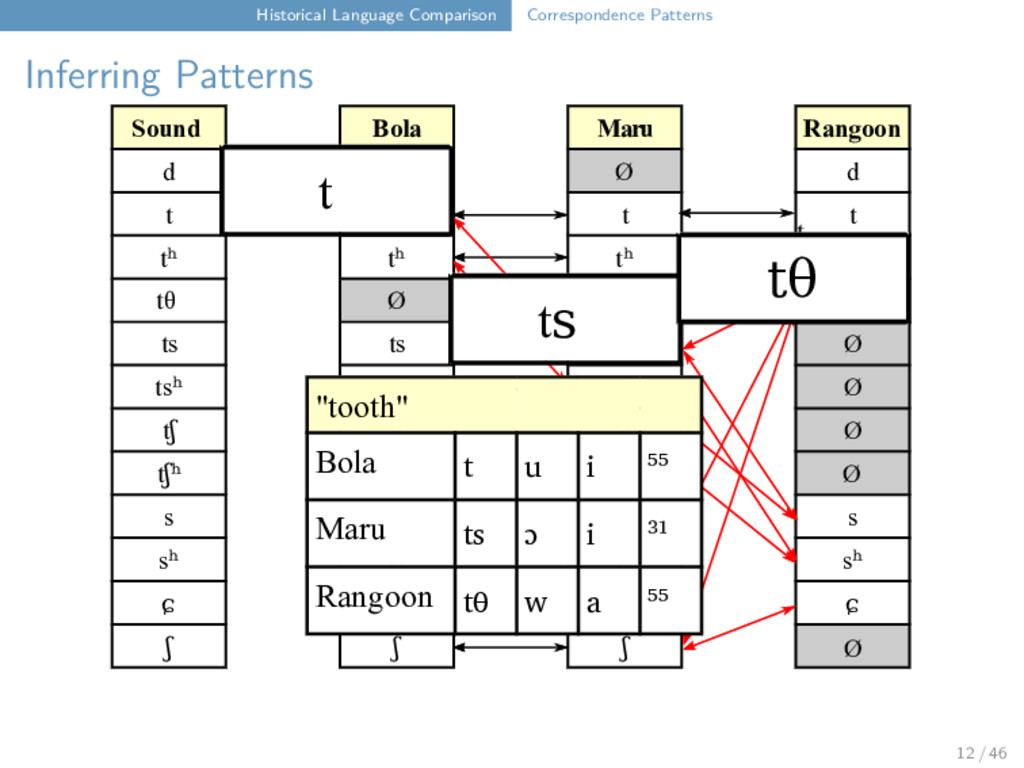
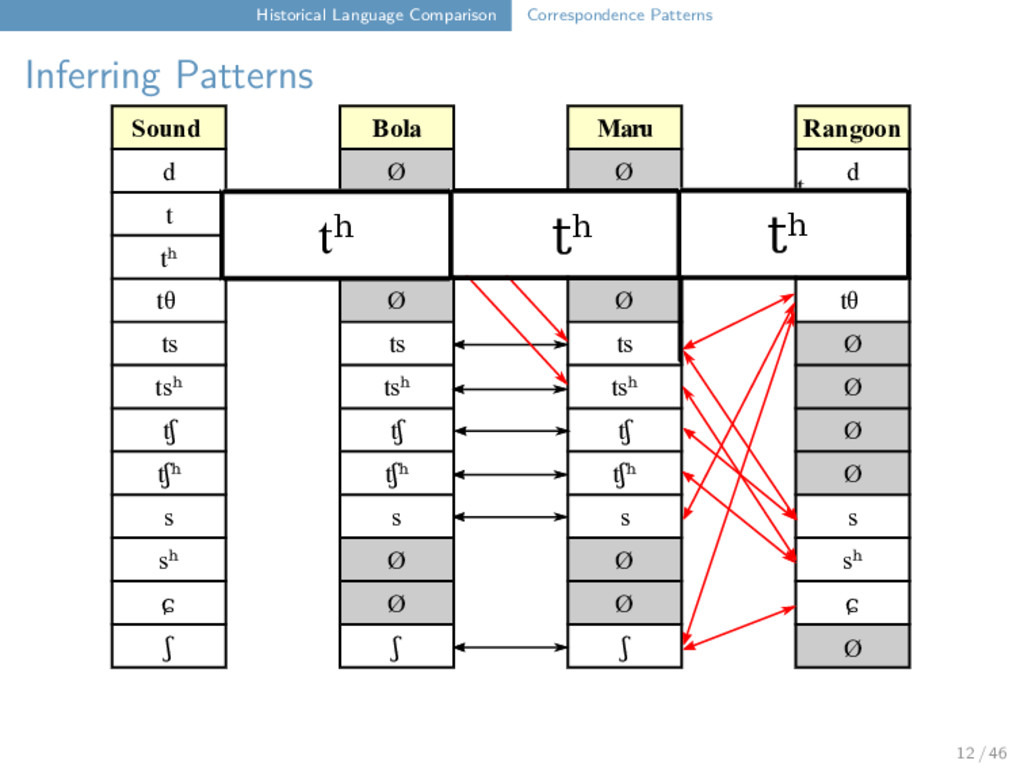
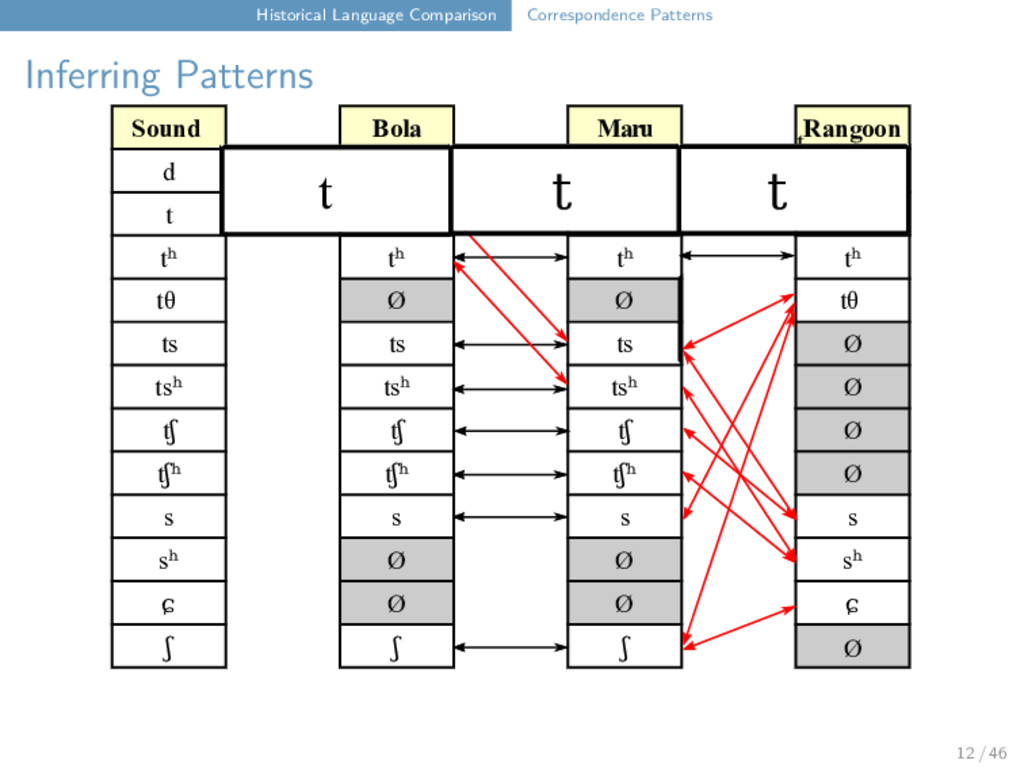
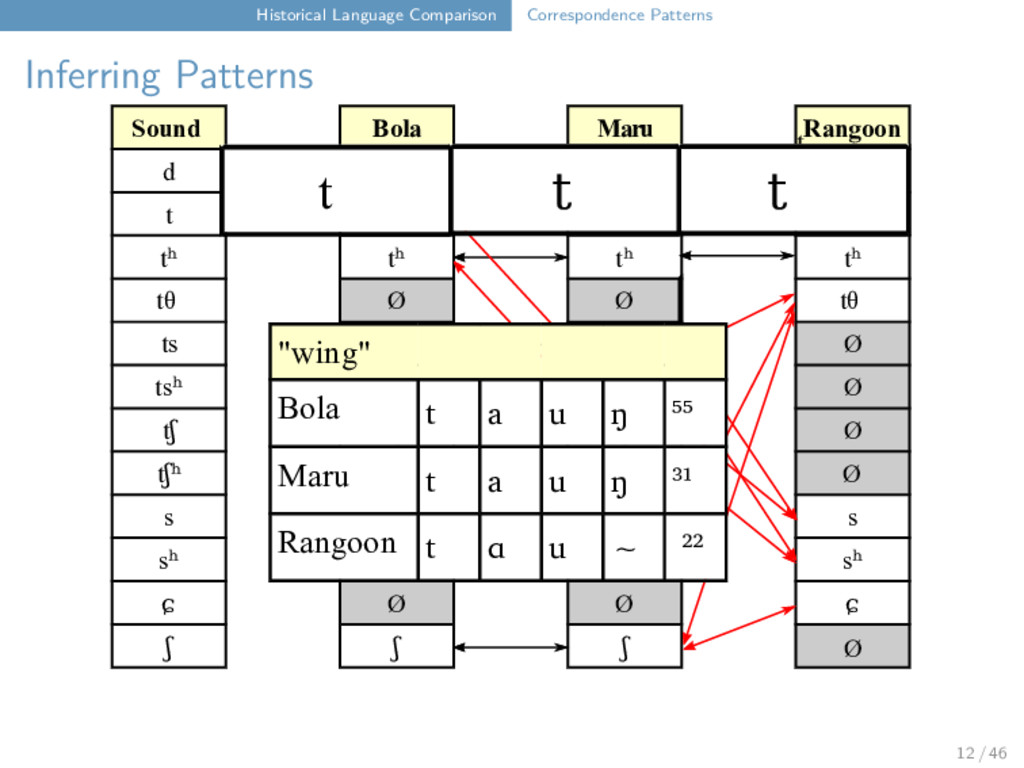
Maru Rangoon d Ø Ø d t t t t tʰ tʰ tʰ tʰ tθ Ø Ø tθ ts ts ts Ø tsʰ tsʰ tsʰ Ø tʃ tʃ tʃ Ø tʃʰ tʃʰ tʃʰ Ø s s s s sʰ Ø Ø sʰ ɕ Ø Ø ɕ ʃ ʃ ʃ t ts t tʰ tθ 12 / 46
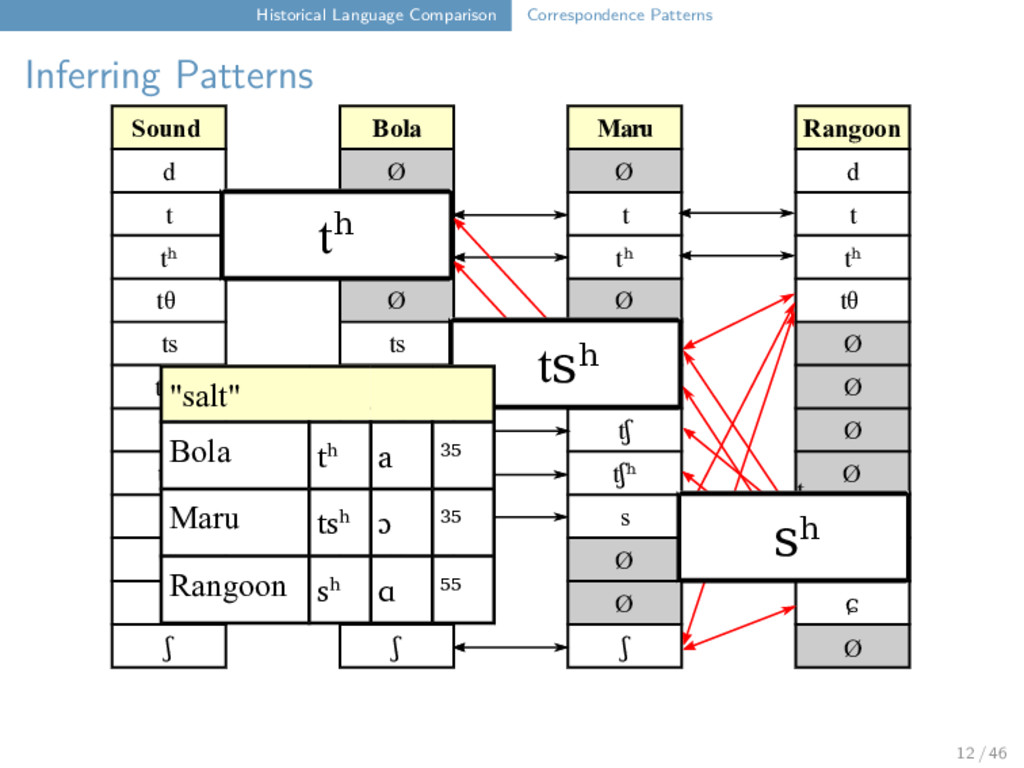
Maru Rangoon d Ø Ø d t t t t tʰ tʰ tʰ tʰ tθ Ø Ø tθ ts ts ts Ø tsʰ tsʰ tsʰ Ø tʃ tʃ tʃ Ø tʃʰ tʃʰ tʃʰ Ø s s s s sʰ Ø Ø sʰ ɕ Ø Ø ɕ ʃ ʃ ʃ t ts t tʰ tθ "tooth" Bola t u i ⁵⁵ Maru ts ɔ i ³¹ Rangoon tθ w a ⁵⁵ 12 / 46
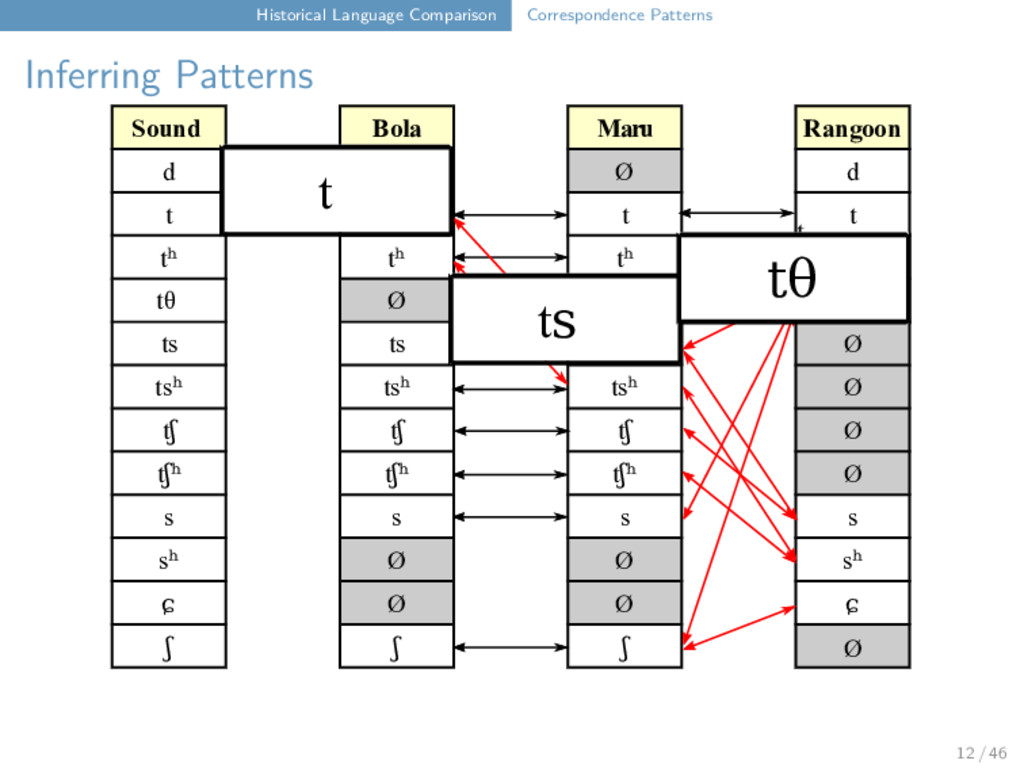
Maru Rangoon d Ø Ø d t t t t tʰ tʰ tʰ tʰ tθ Ø Ø tθ ts ts ts Ø tsʰ tsʰ tsʰ Ø tʃ tʃ tʃ Ø tʃʰ tʃʰ tʃʰ Ø s s s s sʰ Ø Ø sʰ ɕ Ø Ø ɕ ʃ ʃ ʃ t t t tʰ t 12 / 46
Maru Rangoon d Ø Ø d t t t t tʰ tʰ tʰ tʰ tθ Ø Ø tθ ts ts ts Ø tsʰ tsʰ tsʰ Ø tʃ tʃ tʃ Ø tʃʰ tʃʰ tʃʰ Ø s s s s sʰ Ø Ø sʰ ɕ Ø Ø ɕ ʃ ʃ ʃ t t t tʰ t "wing" Bola t a u ŋ ⁵⁵ Maru t a u ŋ ³¹ Rangoon t ɑ u ∼ ²² 12 / 46
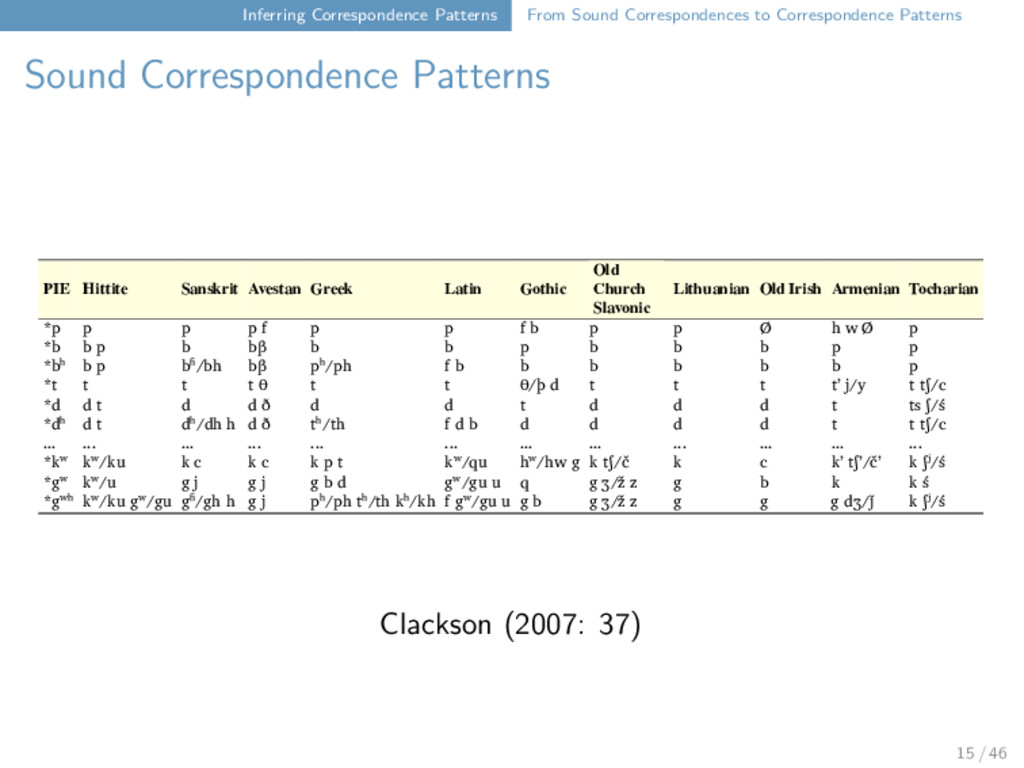
Correspondence Patterns PIE Hittite Sanskrit Avestan Greek Latin Gothic Old Church Slavonic Lithuanian Old Irish Armenian Tocharian *p p p p f p p f b p p Ø h w Ø p *b b p b bβ b b p b b b p p *bʰ b p bʱ/bh bβ pʰ/ph f b b b b b b p *t t t t θ t t θ/þ d t t t tʼ j/y t tʃ/c *d d t d d ð d d t d d d t ts ʃ/ś *dʰ d t dʰ/dh h d ð tʰ/th f d b d d d d t t tʃ/c ... ... ... ... ... ... ... ... ... ... ... ... *kʷ kʷ/ku k c k c k p t kʷ/qu hʷ/hw g k tʃ/č k c kʼ tʃʼ/čʼ k ʃʲ/ś *gʷ kʷ/u g j g j g b d gʷ/gu u q g ʒ/ž z g b k k ś *gʷʰ kʷ/ku gʷ/gu gʱ/gh h g j pʰ/ph tʰ/th kʰ/kh f gʷ/gu u g b g ʒ/ž z g g g dʒ/ǰ k ʃʲ/ś Clackson (2007: 37) 15 / 46
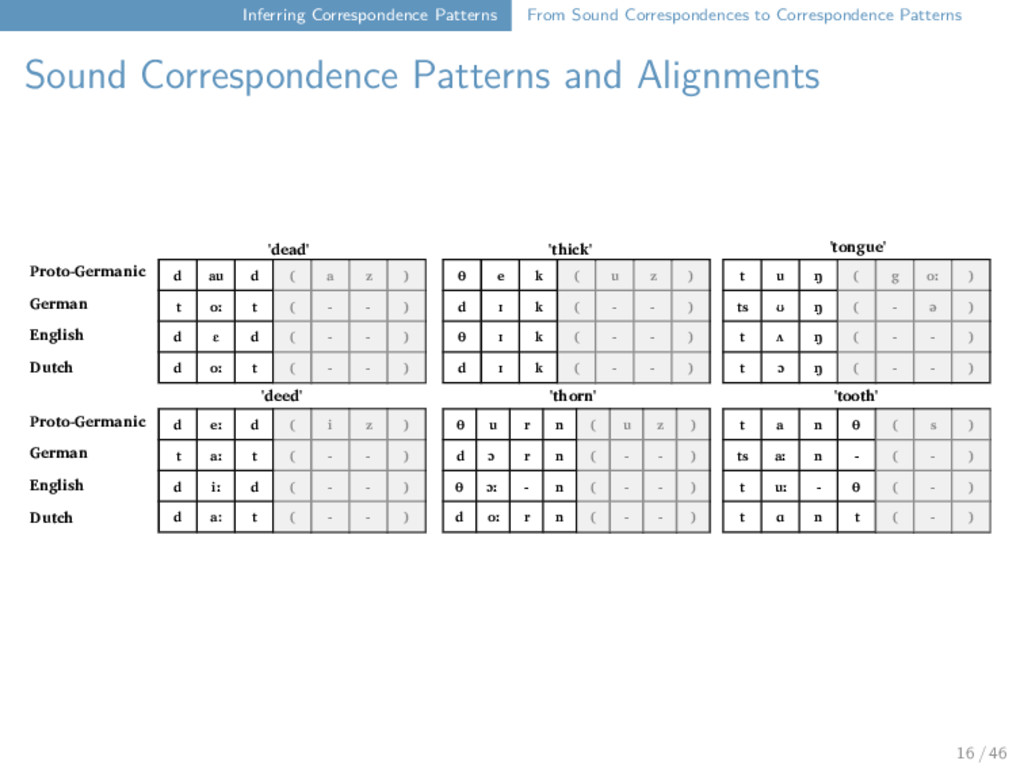
Correspondence Patterns and Alignments d au d ( a z ) t oː t ( - - ) d ɛ d ( - - ) d oː t ( - - ) d eː d ( i z ) t aː t ( - - ) d iː d ( - - ) d a: t ( - - ) θ e k ( u z ) d ɪ k ( - - ) θ ɪ k ( - - ) d ɪ k ( - - ) θ u r n ( u z ) d ɔ r n ( - - ) θ ɔː - n ( - - ) d oː r n ( - - ) t u ŋ ( g oː ) ts ʊ ŋ ( - ə ) t ʌ ŋ ( - - ) t ɔ ŋ ( - - ) t a n θ ( s ) ts aː n - ( - ) t uː - θ ( - ) t ɑ n t ( - ) Proto-Germanic German English Dutch Proto-Germanic German English Dutch 'dead' 'thick' 'tongue' 'deed' 'thorn' 'tooth' 16 / 46
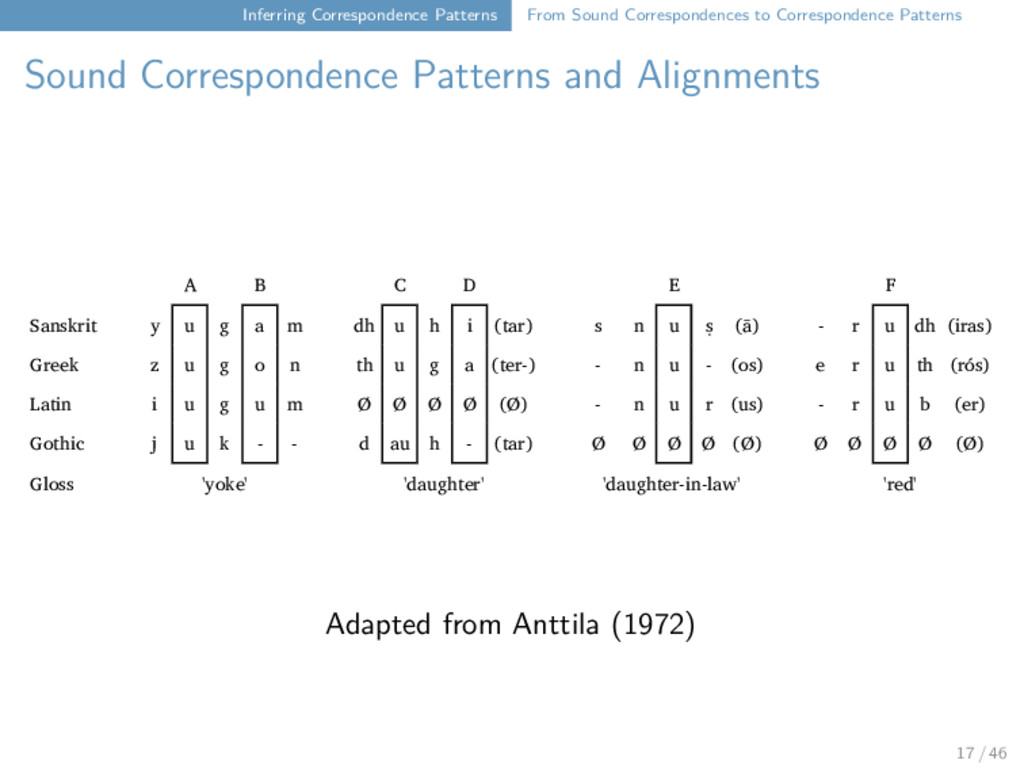
Correspondence Patterns and Alignments A B C D E F Sanskrit y u g a m dh u h i (tar) s n u ṣ (ā) - r u dh (iras) Greek z u g o n th u g a (ter-) - n u - (os) e r u th (rós) Latin i u g u m Ø Ø Ø Ø (Ø) - n u r (us) - r u b (er) Gothic j u k - - d au h - (tar) Ø Ø Ø Ø (Ø) Ø Ø Ø Ø (Ø) Gloss 'yoke' 'daughter' 'daughter-in-law' 'red' Adapted from Anttila (1972) 17 / 46
on Sound Correspondence Patterns correspondence patterns in linguistics are a way to encode mappings across several different alphabets they are usually inferred manually, by inspecting “correspondence sets” (Clackson 2007: 29f) of words (i.e., cognate sets with recurring sounds) 18 / 46
on Sound Correspondence Patterns correspondence patterns in linguistics are a way to encode mappings across several different alphabets they are usually inferred manually, by inspecting “correspondence sets” (Clackson 2007: 29f) of words (i.e., cognate sets with recurring sounds) the main problem of correspondence pattern identification is the handling of missing data, since not all cognate sets will necessarily contain reflexes from each of the languages under investigation 18 / 46
on Sound Correspondence Patterns θ u r n ( u z ) d ɔ r n ( - - ) θ ɔː - n ( - - ) d oː r n ( - - ) 'thorn' alignment site sound correspondence pattern θ e k ( u z ) d ɪ k ( - - ) θ ɪ k ( - - ) d ɪ k ( - - ) 'thick' Proto-Germanic German English Dutch θ d θ d θ u r p ( a ) Ø Ø Ø Ø Ø Ø Ø d ɔ r f ( - ) d ɔ r p ( - ) 'thorp' 19 / 46
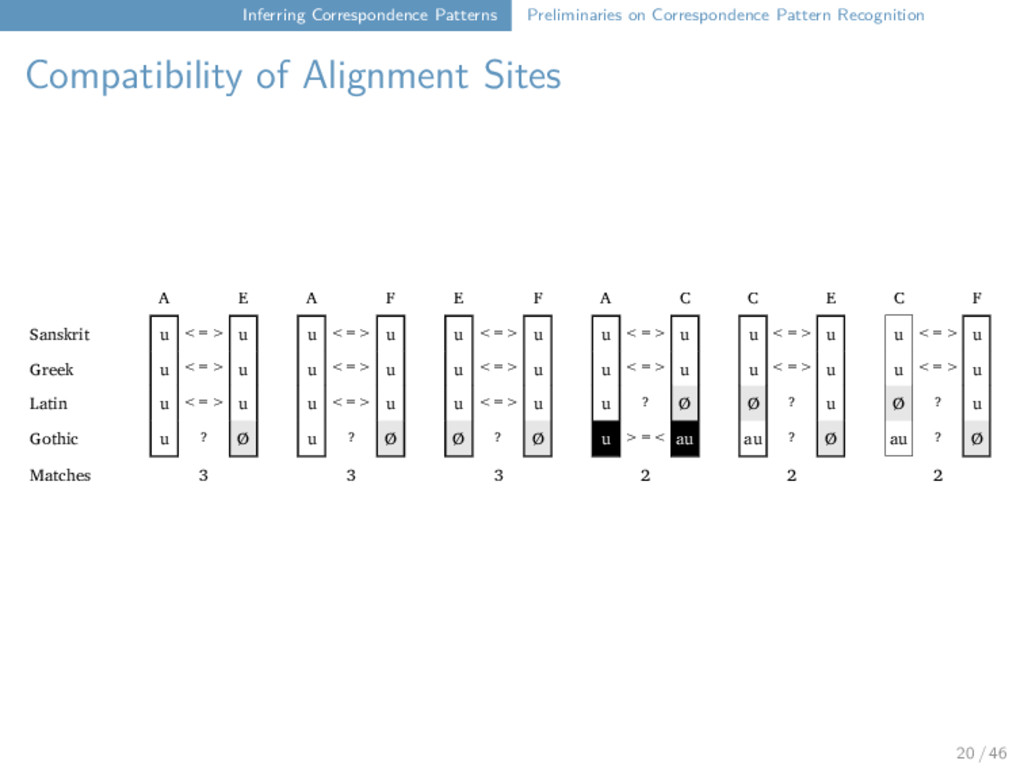
Alignment Sites A E A F E F A C C E C F Sanskrit u <=> u ------ u <=> u ------ u <=> u ------ u <=> u ------ u <=> u ------ u <=> u Greek u <=> u u <=> u u <=> u u <=> u u <=> u u <=> u Latin u <=> u u <=> u u <=> u u ? Ø Ø ? u Ø ? u Gothic u ? Ø u ? Ø Ø ? Ø u >=< au au ? Ø au ? Ø Matches 3 3 3 2 2 2 20 / 46
Alignment Sites Two alignment sites are assumed to be compatible, if they (a) share at least one sound, (b) do not have any conflicting sounds. 21 / 46
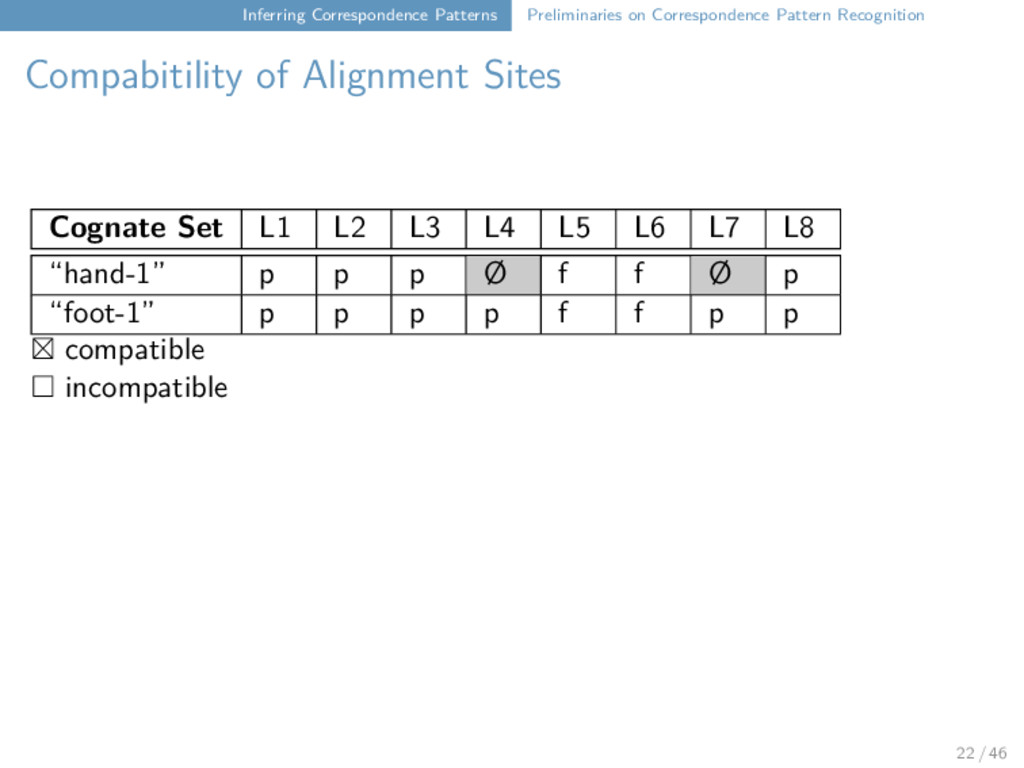
Alignment Sites Cognate Set L1 L2 L3 L4 L5 L6 L7 L8 “hand-1” p p p Ø f f Ø p “foot-1” p p p p f f p p ⊠ compatible □ incompatible Cognate Set L1 L2 L3 L4 L5 L6 L7 L8 “hand-1” p p p Ø f f Ø p “leg-1” p p f pf f f p p □ compatible ⊠ incompatible 22 / 46
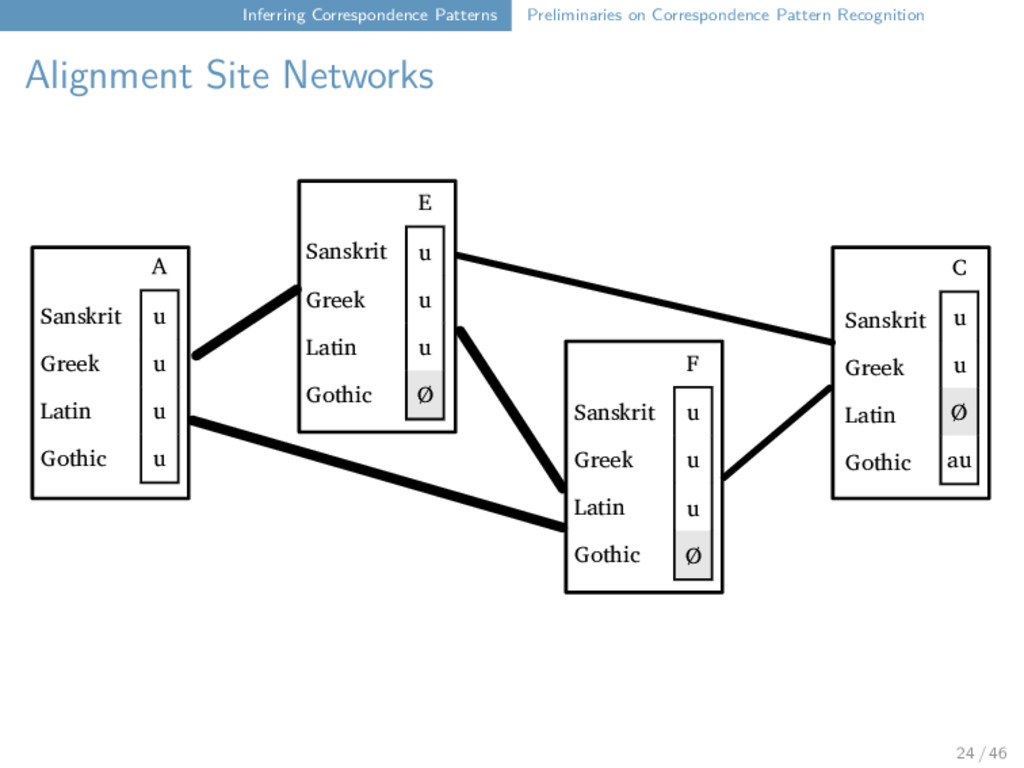
Networks Constructing an alignment site network from a set of alignments: all sites represent a node in the network edges are drawn between compatible sites edges can (in principle) also be weighted by the number of matching sounds (but disregarded in our algorithm so far) 23 / 46
Networks Sanskrit Greek Latin Gothic E u u u Ø Sanskrit Greek Latin Gothic F u u u Ø A u u u Sanskrit Greek Latin Gothic u Sanskrit Greek Latin Gothic C u u Ø au 24 / 46
Inference as Clique Cover Problem The clique cover problem (also called clique partitioning problem, see Bhasker 1991) is the inverse of the famous graph coloring problem and has been shown to be NP-hard. 25 / 46
Inference as Clique Cover Problem The clique cover problem (also called clique partitioning problem, see Bhasker 1991) is the inverse of the famous graph coloring problem and has been shown to be NP-hard. The goal of the problem is to split a graph into the smallest number of cliques in which each node is represented by exactly one clique. 25 / 46
Inference as Clique Cover Problem The clique cover problem (also called clique partitioning problem, see Bhasker 1991) is the inverse of the famous graph coloring problem and has been shown to be NP-hard. The goal of the problem is to split a graph into the smallest number of cliques in which each node is represented by exactly one clique. We assume (but we cannot formally prove it) that the clique cover of our graph of compatible correspondence sets will come close to the best set of sound correspondence patterns in our data. 25 / 46
Inference as Clique Cover Problem The clique cover problem (also called clique partitioning problem, see Bhasker 1991) is the inverse of the famous graph coloring problem and has been shown to be NP-hard. The goal of the problem is to split a graph into the smallest number of cliques in which each node is represented by exactly one clique. We assume (but we cannot formally prove it) that the clique cover of our graph of compatible correspondence sets will come close to the best set of sound correspondence patterns in our data. Partitioning our alignment site network into cliques does not solve the problem of linguistic reconstruction, but it can be seen as its fundamental prerequisite. 25 / 46
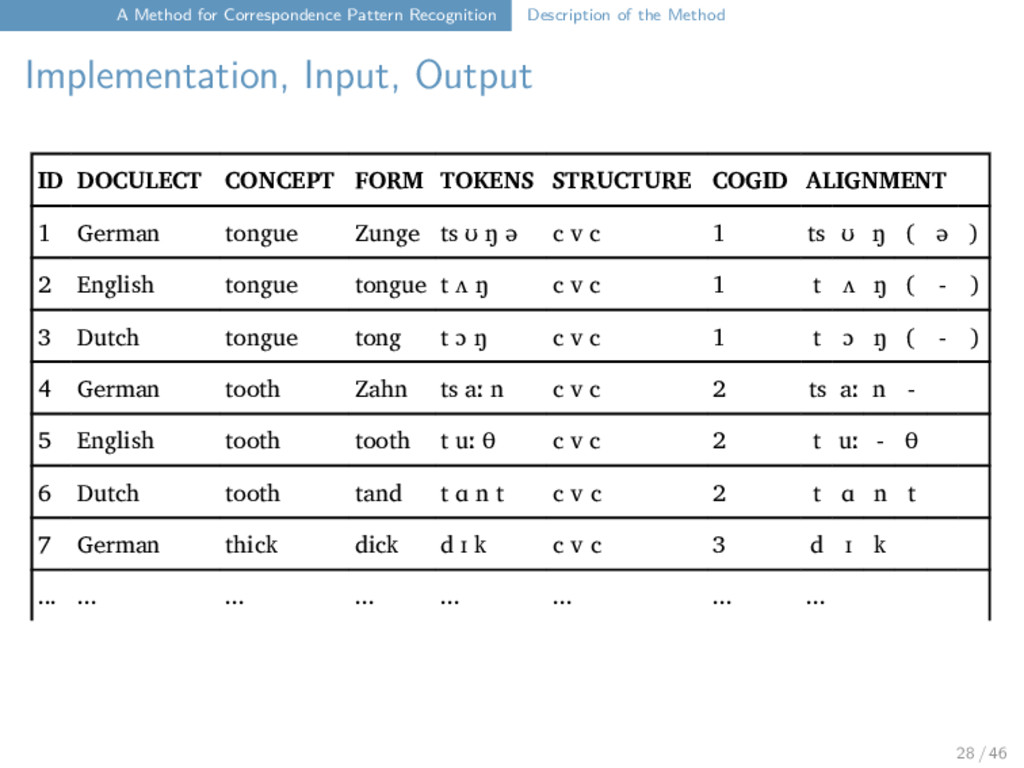
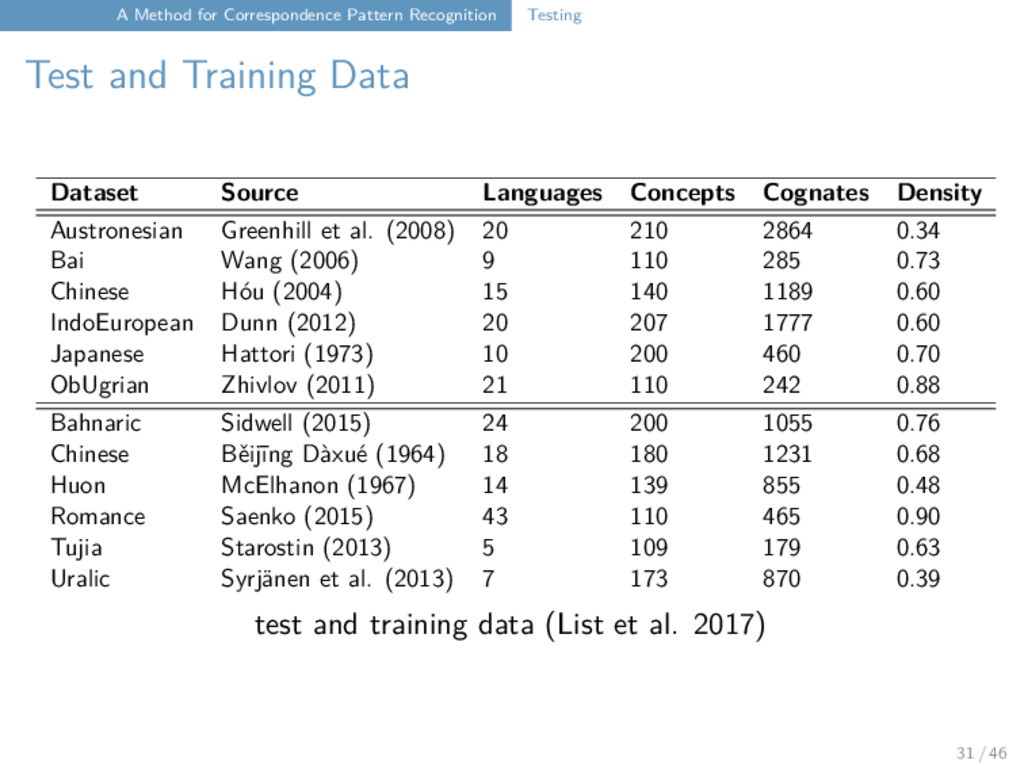
Implementation, Input, Output Full implementation is provided as plugin for LingPy (http://lingpy.org). An approximate version is shipped with the EDICTOR (http://edictor.digling.org). Input format follows the format employed by LingPy with some additional required columns which need to be submitted. Output in form of annotated word lists with assigned patterns for each word form, which can be read in and inspected with help of the EDICTOR, or in form of “normal” text files. 27 / 46
Implementation, Input, Output ID DOCULECT CONCEPT FORM TOKENS STRUCTURE COGID ALIGNMENT 1 German tongue Zunge ts ʊ ŋ ə c v c 1 ts ʊ ŋ ( ə ) 2 English tongue tongue t ʌ ŋ c v c 1 t ʌ ŋ ( - ) 3 Dutch tongue tong t ɔ ŋ c v c 1 t ɔ ŋ ( - ) 4 German tooth Zahn ts aː n c v c 2 ts aː n - 5 English tooth tooth t uː θ c v c 2 t uː - θ 6 Dutch tooth tand t ɑ n t c v c 2 t ɑ n t 7 German thick dick d ɪ k c v c 3 d ɪ k ... ... ... ... ... ... ... ... 28 / 46
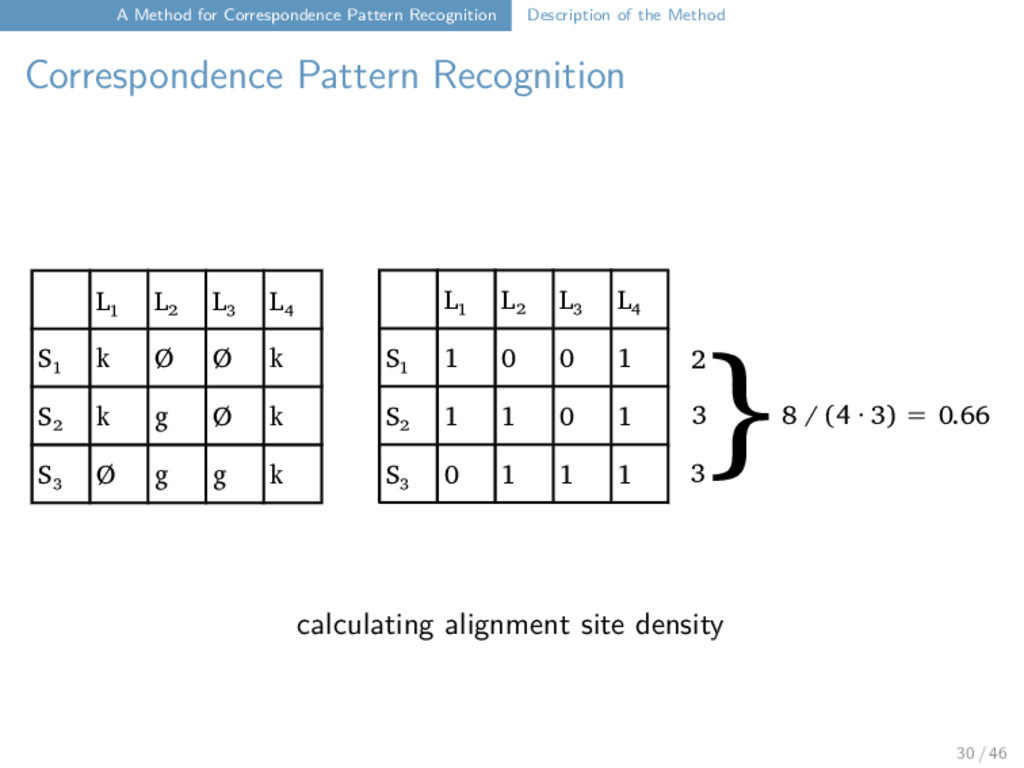
Correspondence Pattern Recognition A three-step algorithm: (A) sort the alignment sites with a customized variant of the Quicksort algorithm (Hoare 1962) which groups compatible alignment sites closely together (sole algorithm used by EDICTOR due to restrictions of JavaScript on memory) (B) inverse version of Welsh-Powell algorithm (Welsh and Powell 1967) for graph coloring (a) sort all partitions according to size and alignment site density (b) pick first partition and compare it against all other partitions, merge with compatible partitions, put incompatible partitions into a queue (c) finish if no more partitions are in the queue (C) compare all alignment sites again with the inferred correspondence patterns and assign each alignment site to all patterns with which it is compatible to yield a fuzzy clustering 29 / 46
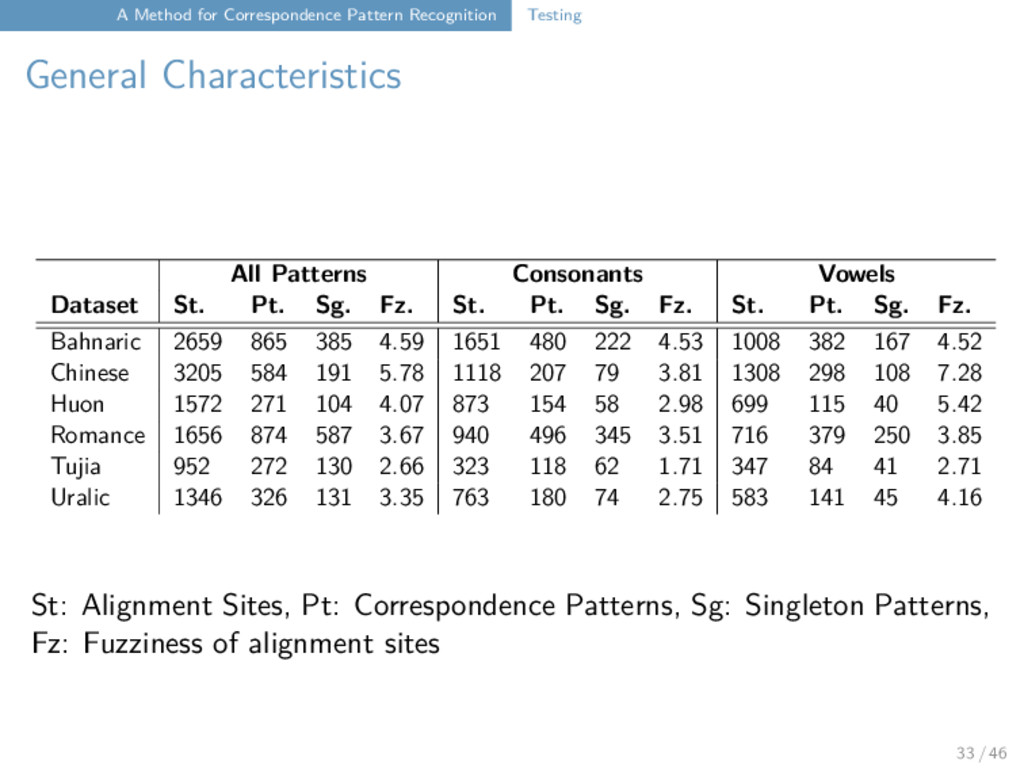
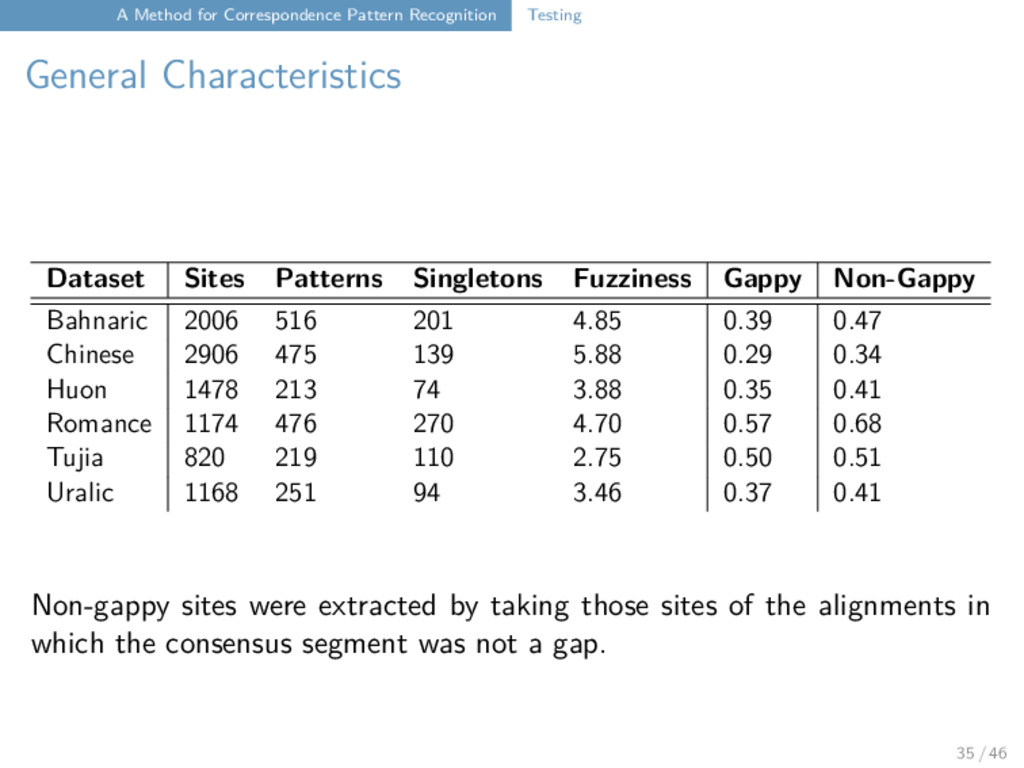
intermediate summary: the method seems to be successful in reducing patterns the number of singleton patterns is still surprising vowels seem to be “fuzzier” than consonants (not against our expectation) automatic cognates may have caused problems 34 / 46
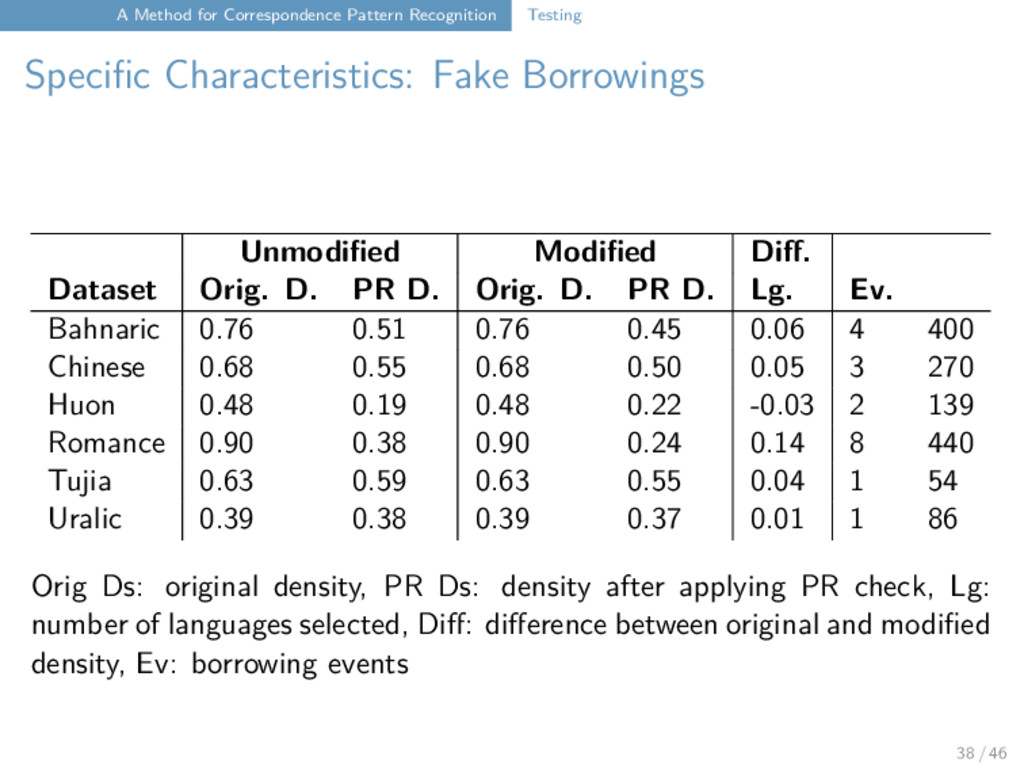
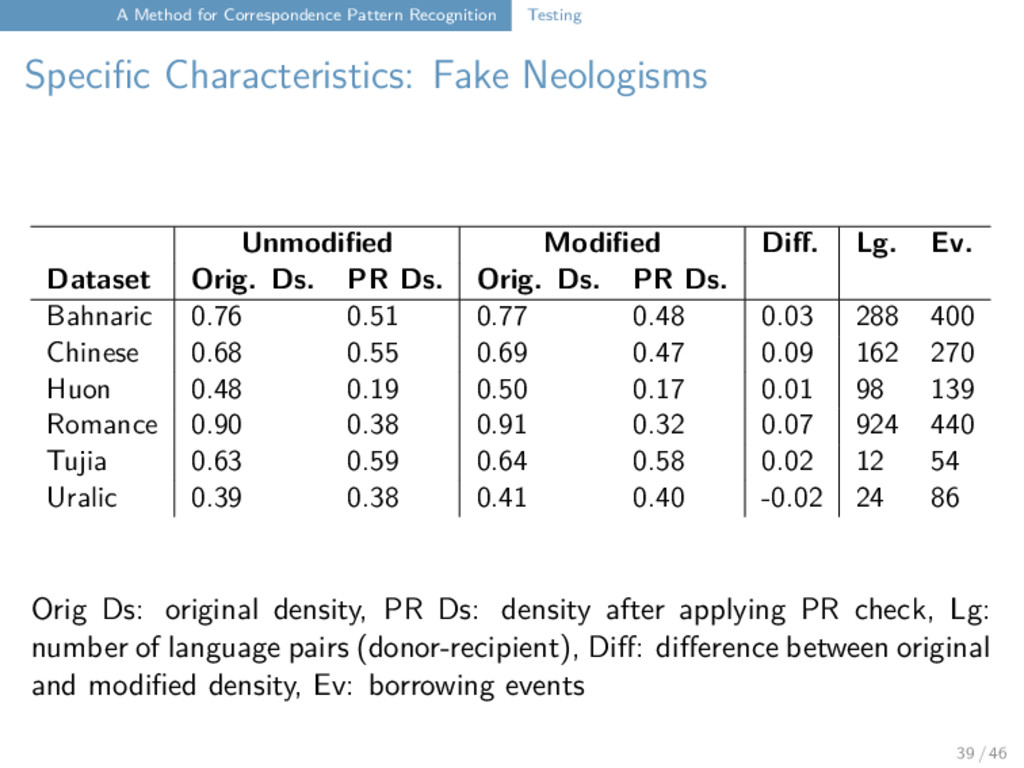
of artificial borrowings or wrong cognates as a method for testing following Dessimoz et al. (2008), for a biological framework, randomly select pairs of languages and have them interchange words building on Dessimoz et al. (2008), create neologisms with LingPy’s built-in word generator (based on Markov Chains), to replace existing words in a given cognate set with a new (possible) word from the same language investigate the pattern regularity (PR) of the cognate sets in the data before and after the operations by (a) setting a user-defined threshold for the regularity of an alignment site derived from the density of its pattern (smoothing of singletons: they are always irregular) (b) accepting a cognate set as regular if half of its alignment sites are regular (c) splitting irregular cognate sets up into independent cognate sets 37 / 46
the fake borrowings lead as expected to a decrease in cognate density the fake neologisms also lead as expected to a decrease in cognate density even pulling out those correspondence patterns which are singletons or marking the cognate sets which have a low density seems like a valuable enterprise as it can help linguists to have another look at their data and check the findings manually 40 / 46
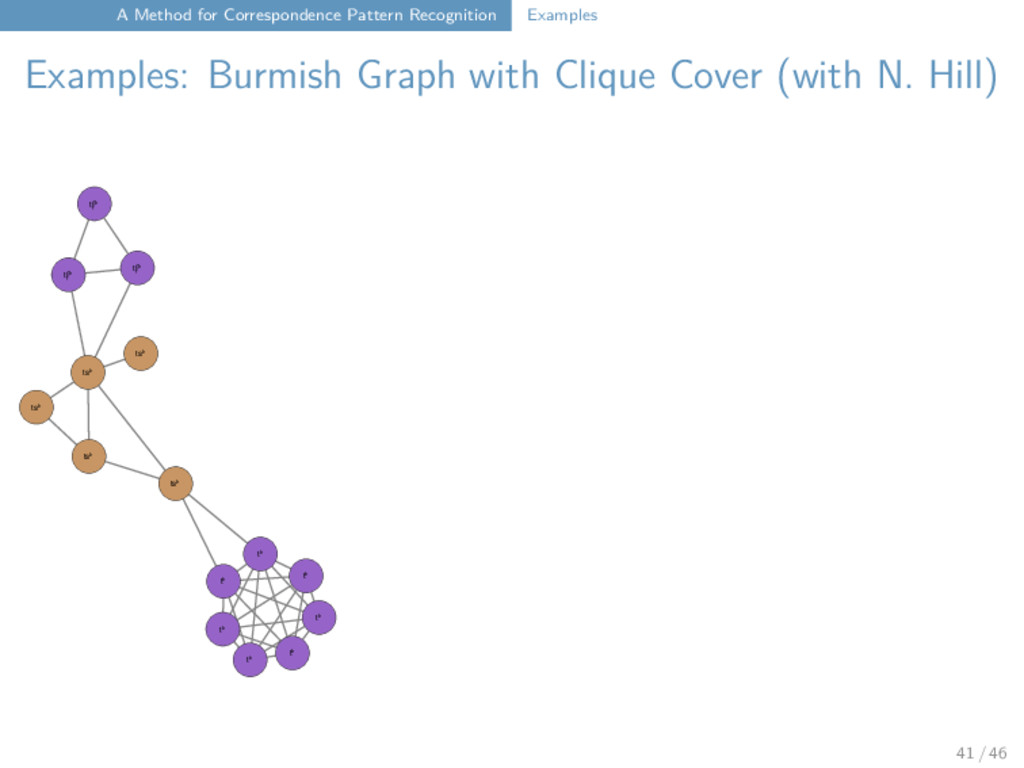
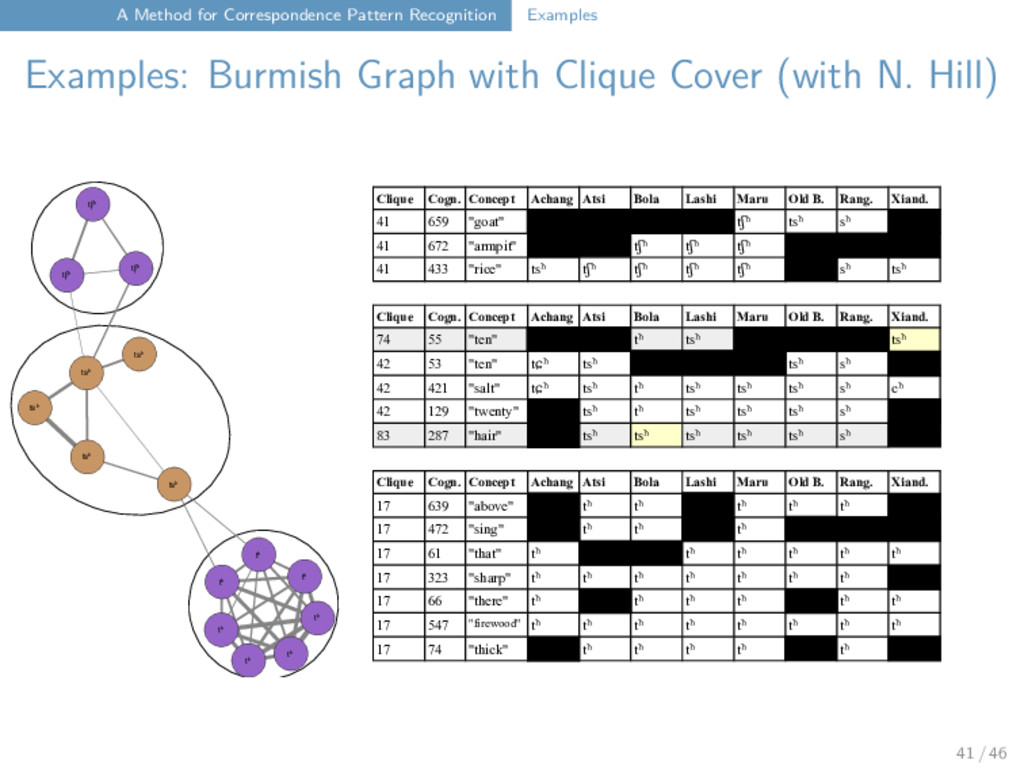
with Clique Cover (with N. Hill) tʃʰ s ʃ tʃʰ x j n◌̥ n n ŋ tsʰ tsʰ tsʰ tʃʰ pʰ pʰ pʰ j w x v x v x j x n n x x x n◌̥ x n m m m n kʰ kʰ kʰ tʰ tʰ tʰ kʰ tʰ tʰ tʰ tʰ - - - pʰ pʰ p j ɣ ɣ ɣ ɣ j j j n n n n m n n n n m m m m m m m m m m l l l p l l l l l l l kʰ kʰ kʰ kʰ kʰ kʰ kʰ kʰ kʰ kʰ ʃ s s s k ʃ ʃ k s s k s ʃ ʃ ʃ t t t t t t t t t t t m m m m m m m m m p p p p p p p p p p p p p p p k k s kʰ kʰ k ʃ ŋ n m l t t l - tsʰ f tʃ k n n l ʃ tsʰ l s m t p k n kʰ m j m v j s tʃ n ts m l ŋ k kʰ v ʃ ʐ ʃ n k j - tʃ pʰ s v m k ŋ ŋ - n n l n◌̥ ŋ ŋ l l l l ʃ ʃ ts ʃ k s k s s s s s ts ts ts ts ts ts j k j ɣ k ŋ ŋ ŋ ŋ ŋ ŋ ŋ s s tʃ tʃ tʃ tʃ tʃ tʃ tʃ k k k k k ts p pʰ ts nʲ ŋ n ŋ k 41 / 46
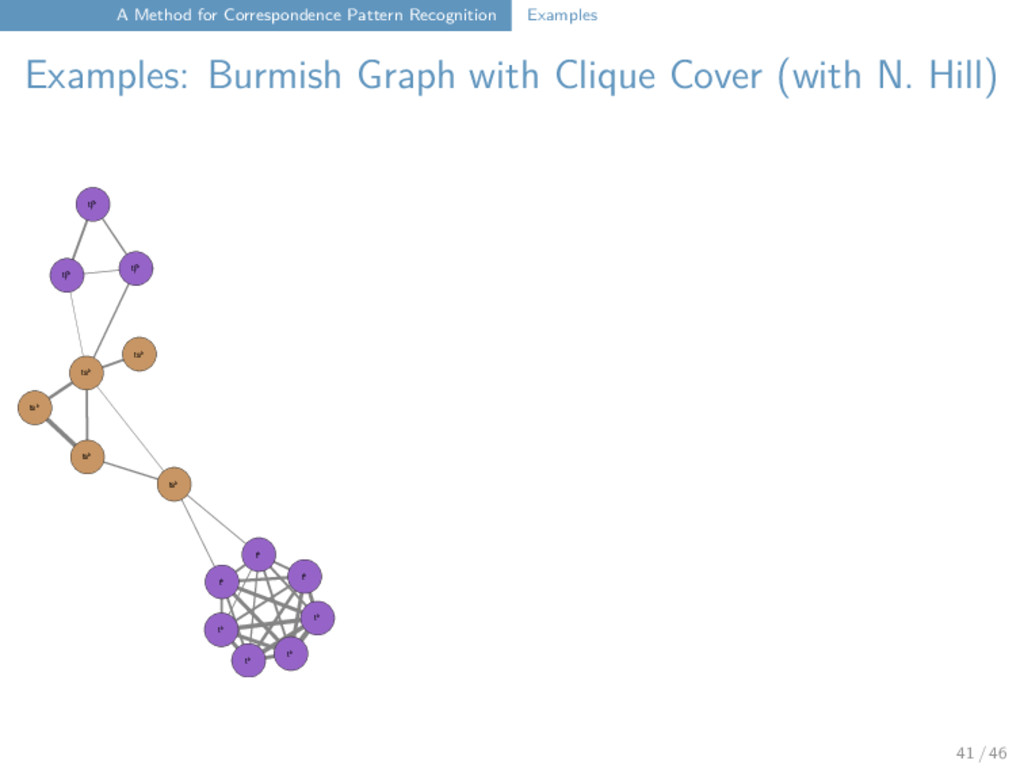
with Clique Cover (with N. Hill) tʰ tʰ tʰ pʰ tʰ tʰ pʰ pʰ tʰ tʰ pʰ ŋ ŋ ŋ ŋ ŋ ŋ ŋ ŋ tsʰ tsʰ tʃʰ tsʰ tsʰ tʃʰ tʃʰ tsʰ j v f j v v ŋ - ŋ n◌̥ ŋ ŋ ŋ ʃ ʃ s ʃ ʃ ʃ ʃ ʃ ʃ s tʃ tʃ tʃ tʃ tʃ s tʃ tʃ tʃ tʃ x x tʃ x x x t t t t t t ʃ ʃ ʃ ʃ ʃ ʃ ts ts ts ts ts ts ts ts ts ts t t t t t t t t m m m pʰ pʰ p p p m m s s s s s s s s s s n l l l l l l l l l l l l s s s s s s p p p p p p p p p p p p p p p pʰ p m m m m m m m l l l l l l l l - - j j j j j - j k ɣ ɣ ɣ ɣ ʐ ɣ w j - v v j j j k k k k k k k k k kʰ kʰ kʰ kʰ kʰ kʰ kʰ k k k k k kʰ kʰ kʰ kʰ kʰ kʰ kʰ kʰ kʰ kʰ kʰ x x x x n n◌̥ n n n n n ŋ n n n n n n n n n n n n k k k k k k m m m m m m m m - n n ŋ ŋ n n◌̥ n nʲ m m m m m m m m m 41 / 46
inference of correspondence patterns is a first attempt to account for systemic aspects of sound change in a rigorous manner in contrast to many approaches proposed so far, it does not require family trees in any form, networks are just enough, but the patterns inferred can be used to study tree-like aspects of evolution (Chacon and List 2015), 44 / 46
inference of correspondence patterns is a first attempt to account for systemic aspects of sound change in a rigorous manner in contrast to many approaches proposed so far, it does not require family trees in any form, networks are just enough, but the patterns inferred can be used to study tree-like aspects of evolution (Chacon and List 2015), the algorithm needs to be further tested we need a deeper discussion in the field about the importance of correspondence patterns for linguistic reconstruction 44 / 46
Hill (essential discussions on the implications of the procedure and further applications, intensive manual inspection of the output of the method) Taraka Rama (testing the method for alignment-based phylogenetic tree reconstruction, comments on draft and code) Eric Bapteste, Philippe Lopez, and their Team AIRE (providing initial inspiration and follow-up discussions on the approach, thanks to a similar approach applied in biology) 45 / 46
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}