Johann-Mattis List DFG Research Fellow Centre des recherches linguistiques sur l’Asie Orientale Team AIRE (Adaptation, Integration, Reticulation, Evolution) at UPMC 2015-02-04 1 / 50
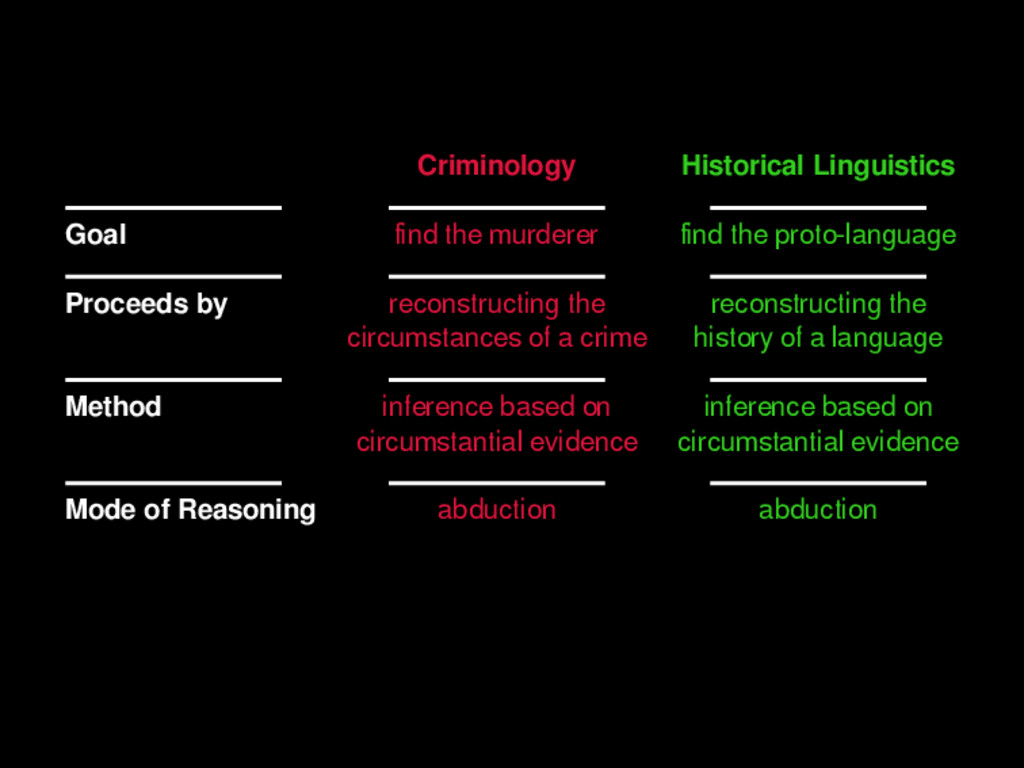
Proceeds by reconstructing the reconstructing the circumstances of a crime history of a language Method inference based on inference based on circumstantial evidence circumstantial evidence Mode of Reasoning abduction abduction 2 / 50
historical linguistics is syn- chronic language data. Based on models of lan- guage and sound change, an inference of relati- ons among different data points is carried out. An analysis of these relations yields historical scena- rios that explain the current structure of the data. 2 / 50
historical linguistics is syn- chronic language data. Based on models of lan- guage and sound change, an inference of relati- ons among different data points is carried out. An analysis of these relations yields historical scena- rios that explain the current structure of the data. 2 / 50
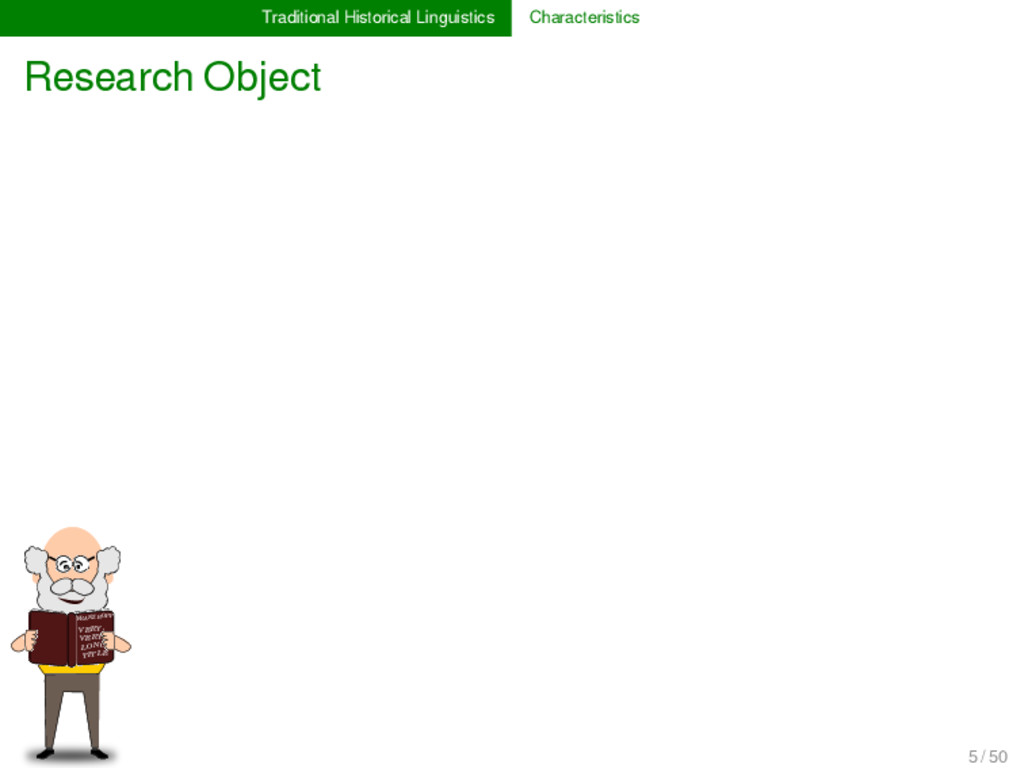
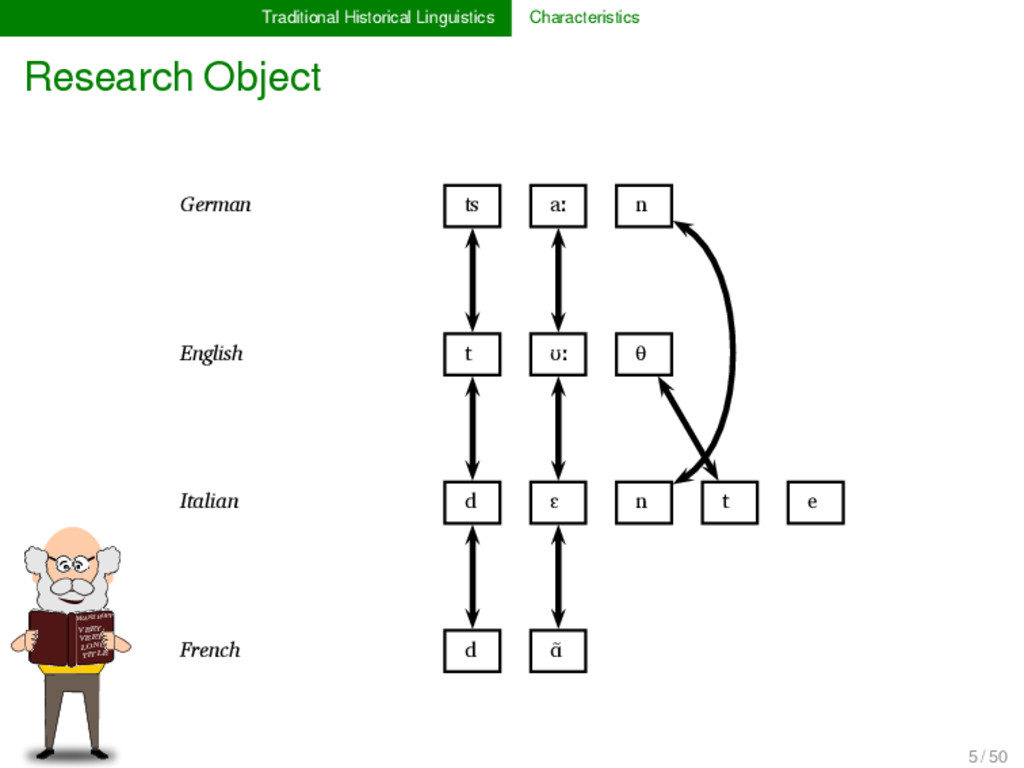
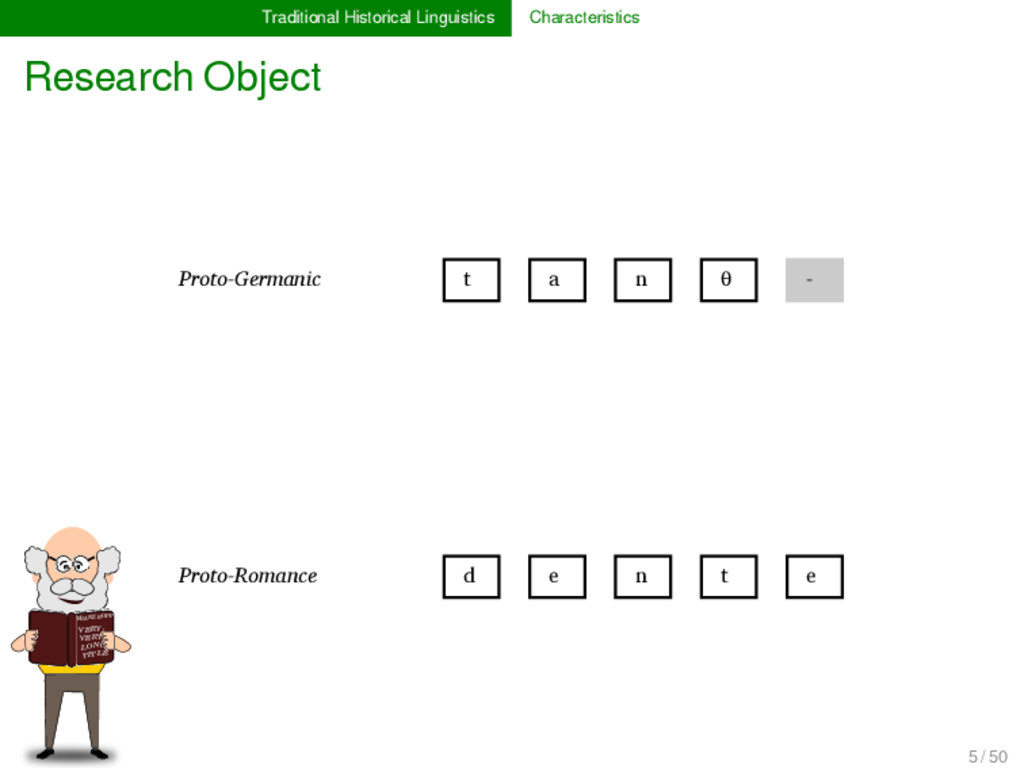
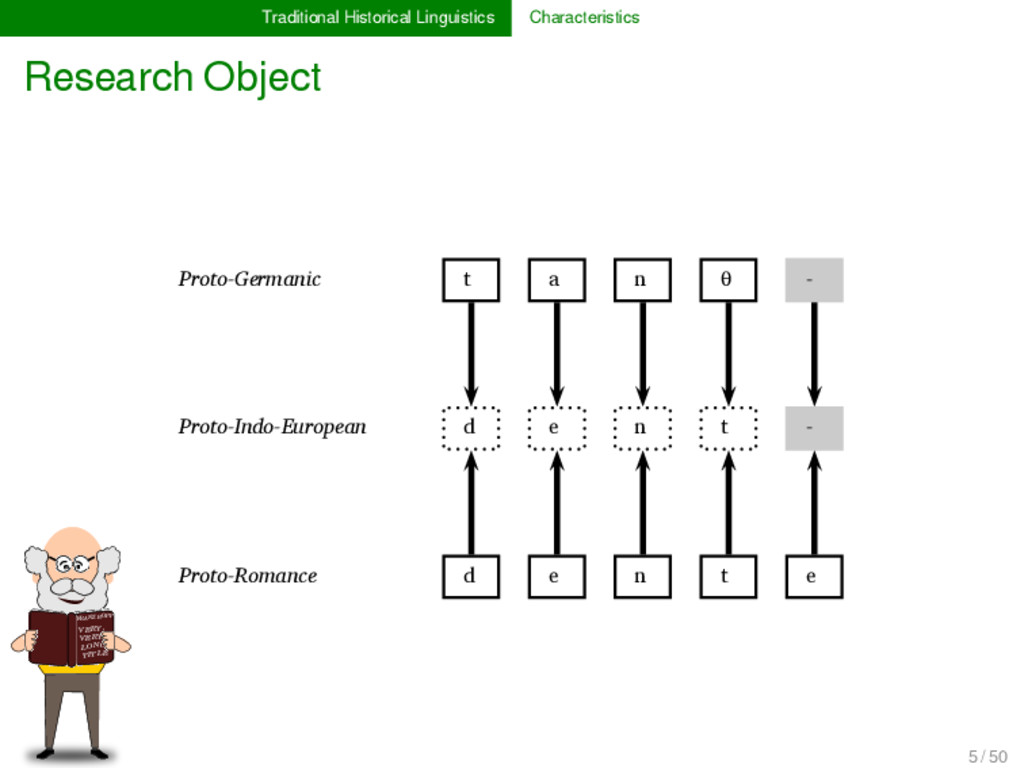
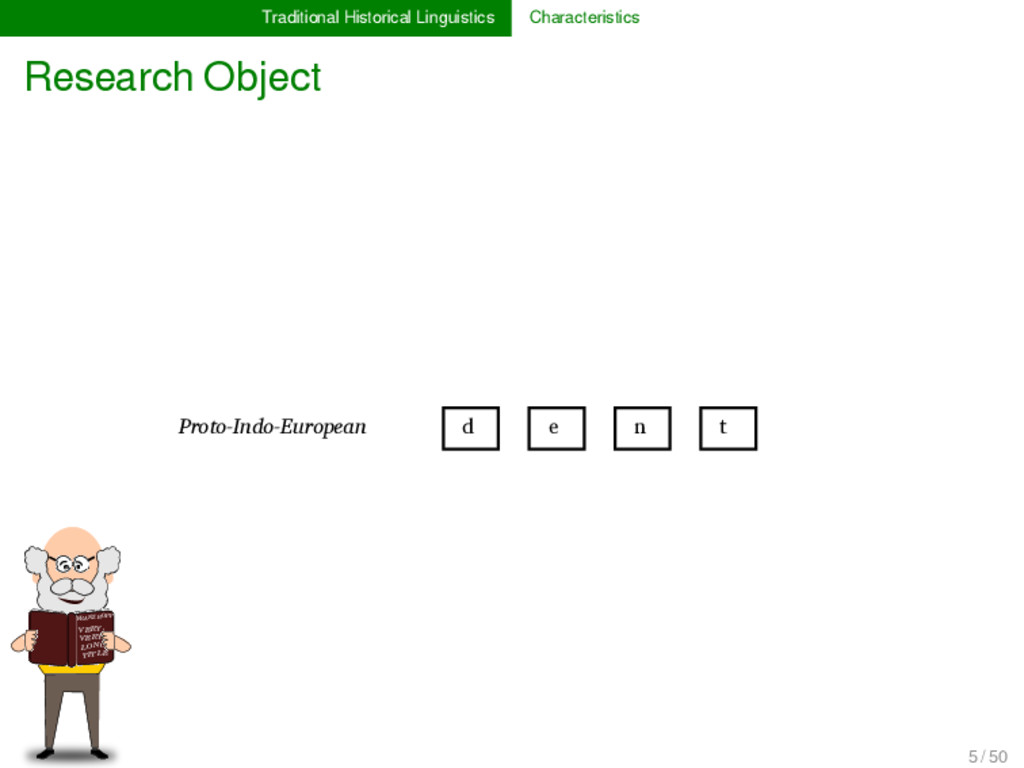
LONG TITLE German ʦ aː n - * Proto-Germanic t a n d English t ʊː θ - ** Proto-Indo-European d o n t Italian d ɛ n t e * Proto-Romance d e n t French d ɑ̃ - - 5 / 50
LONG TITLE German ʦ aː n - * Proto-Germanic t a n d English t ʊː θ - ** Proto-Indo-European d o n t Italian d ɛ n t e * Proto-Romance d e n t French d ɑ̃ - - 5 / 50
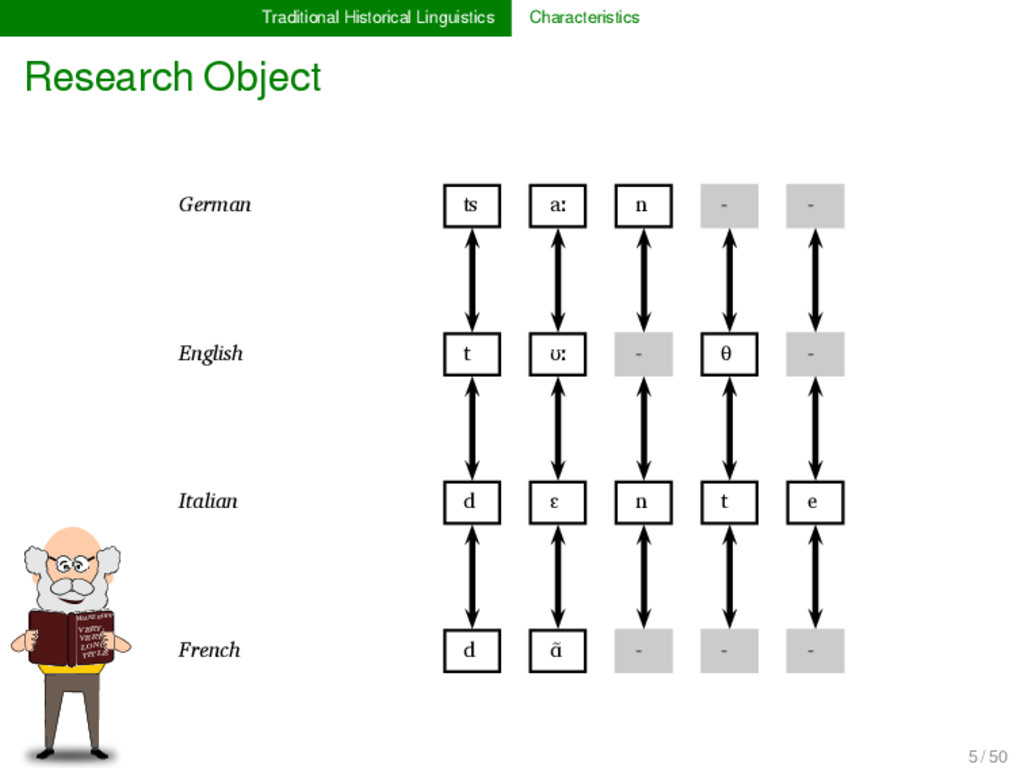
LONG TITLE German ʦ aː n - - * Proto-Germanic t a n d English t ʊː - θ - ** Proto-Indo-European d o n t Italian d ɛ n t e * Proto-Romance d e n t French d ɑ̃ - - - 5 / 50
LONG TITLE German ʦ aː n - - Proto-Germanic t a n θ - English t ʊː - θ - ** Proto-Indo-European d o n t Italian d ɛ n t e Proto-Romance d e n t e French d ɑ̃ - - - 5 / 50
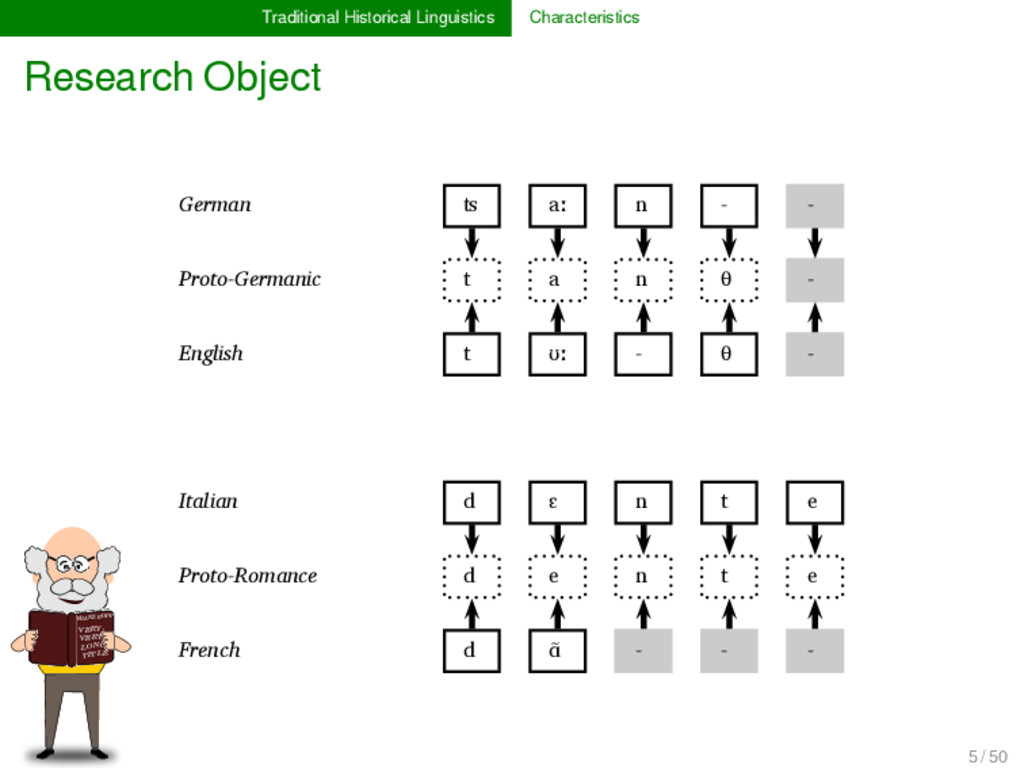
LONG TITLE German ʦ aː n - Proto-Germanic t a n θ - English t ʊː - θ ** Proto-Indo-European d o n t Italian d ɛ n t e Proto-Romance d e n t e French d ɑ̃ - - 5 / 50
LONG TITLE German ʦ aː n - Proto-Germanic t a n θ - English t ʊː - θ Proto-Indo-European d e n t - Italian d ɛ n t ə Proto-Romance d e n t e French d ɑ̃ - - 5 / 50
LONG TITLE German ʦ aː n - * Proto-Germanic t a n d English t ʊː - θ Proto-Indo-European d e n t Italian d ɛ n t ə * Proto-Romance d e n t French d ɑ̃ - - 5 / 50
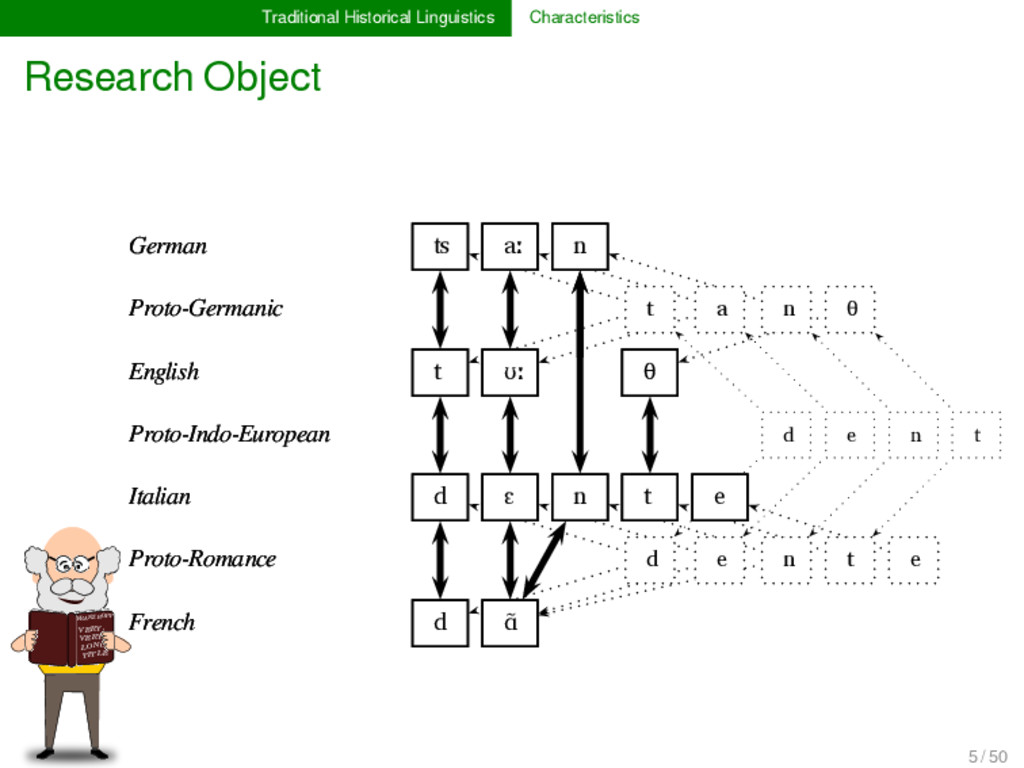
LONG TITLE German ʦ aː n Proto-Germanic t a n θ English t ʊː θ Proto-Indo-European d e n t Italian d ɛ n t e Proto-Romance d e n t e French d ɑ̃ German ʦ aː n Proto-Germanic t a n θ English t ʊː θ Proto-Indo-European d e n t Italian d ɛ n t e Proto-Romance d e n t e French d ɑ̃ 1 5 / 50
LONG TITLE History individual events (description) individual processes (description, inference) general processes (modeling, analysis) Language History individual language states (description of sound system, grammar, lexicon) individual instances of language development (description and inference of sound change patterns, grammaticalization, lexical change) general language development (modeling and analysis of sound change processes, grammaticalization, lexical change) 6 / 50
LONG TITLE Internal Language History (ontogenesis) etymology historical grammar historical phonology External Language History (phylogenesis) linguistic reconstruction (modeling and inference) proof of language relationship (inference) genetic classification (analysis) General Tendencies in Language History processes and mechanisms of sound change grammaticalization lexical change 7 / 50
TITLE Uniformitarianism “universality of change” – change is independent of time and space “graduality of change” – change is neither abrupt nor chaotic “uniformity of change” – change is not heterogeneous, but uniform Founding Fathers Franz Bopp (1791–1867): language comparison (Bopp 1816) Rasmus Rask (1787-1832) and Jacob Grimm (1785-1863): sound law (Rask 1818, Grimm 1822) August Schleicher (1821–1868): family tree and linguistic reconstruction (Schleicher 1853 & 1861) 8 / 50
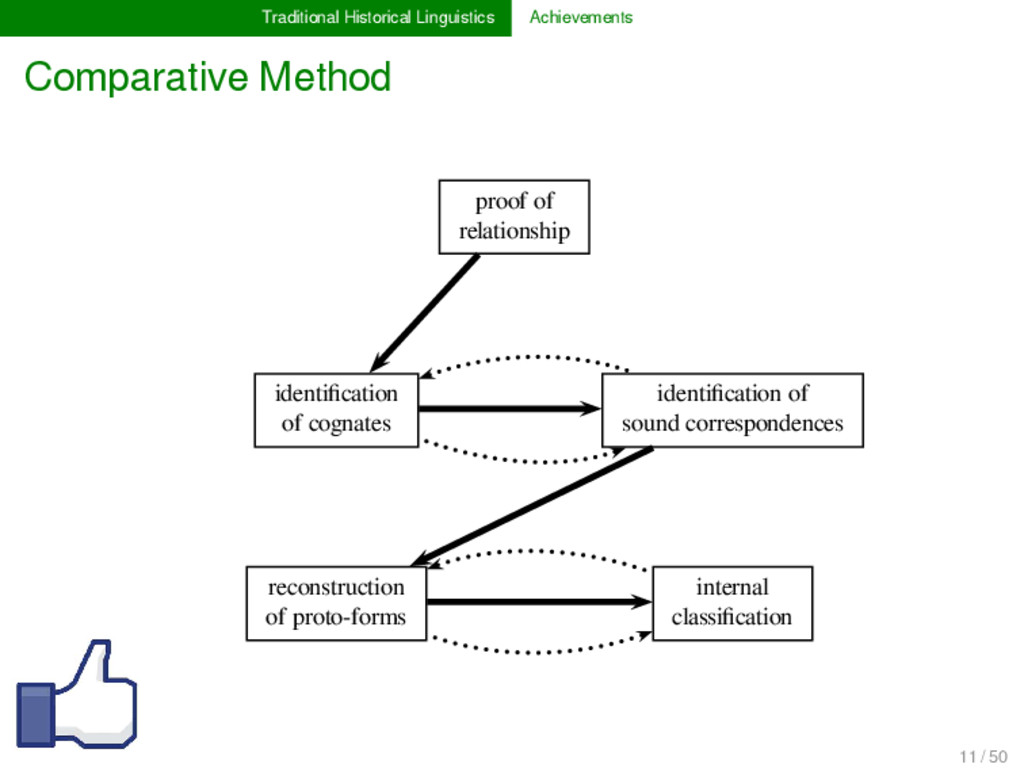
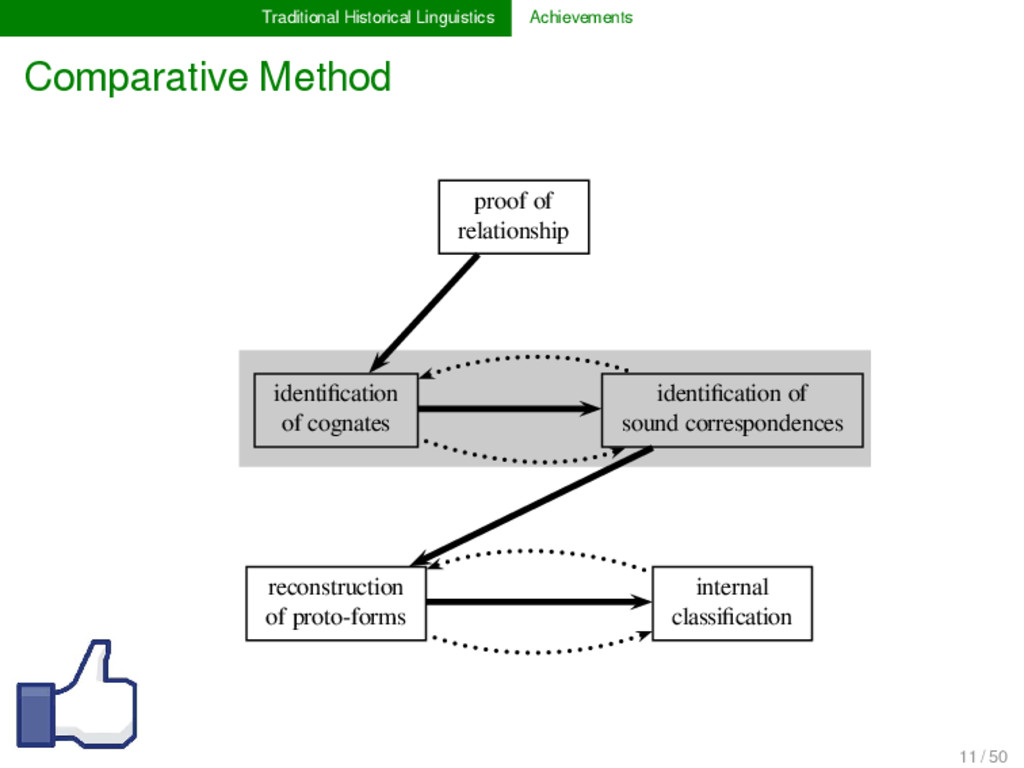
1925) Basic procedure for proving language relationship and reconstructing unattested ancestral language states, etymologies, and genetic classifications. Family Tree Model and Wave Theory (Schleicher 1853, Schmidt 1872) Two partially incompatible models to describe historical language relations. Regularity Hypothesis (Osthoff & Brugmann 1878) Fundamental working hypothesis that states that certain sound change processes proceed regularly (universally, gradually, and in a uniform manner). 10 / 50
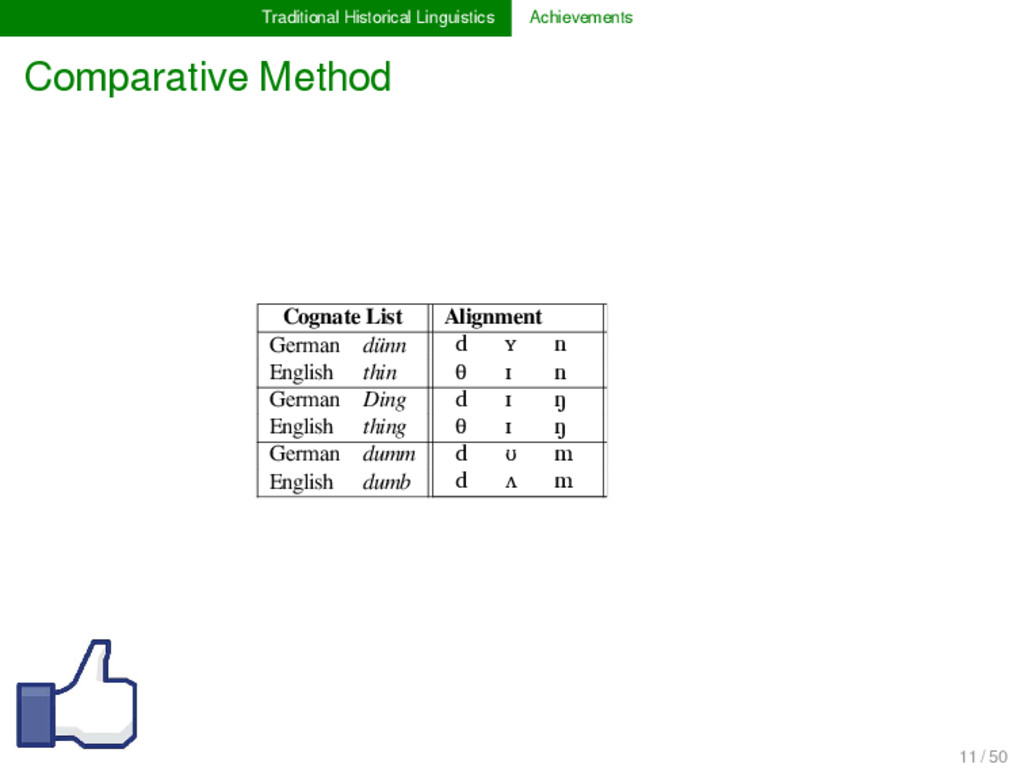
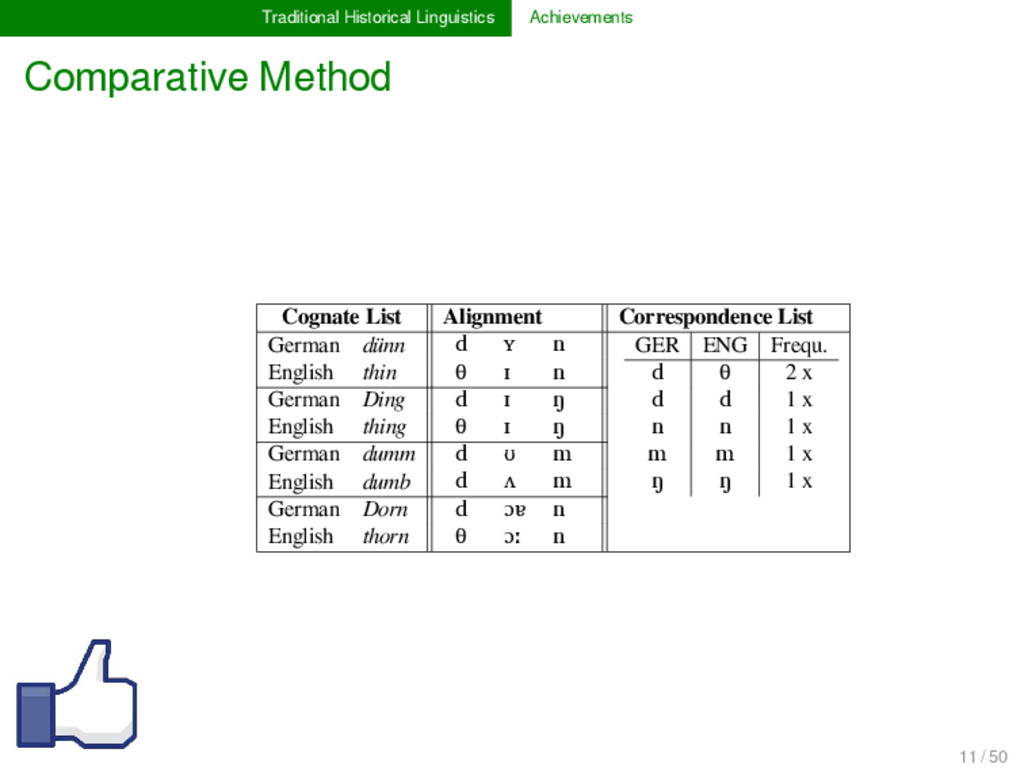
List German dünn d ʏ n GER ENG Frequ. d θ 3 x d d 1 x n n 1 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn d ɔː n 11 / 50
List German dünn d ʏ n GER ENG Frequ. d θ 3 x d d 1 x n n 1 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn d ɔː n 11 / 50
List German dünn d ʏ n GER ENG Frequ. d θ 2 x d d 1 x n n 1 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn d ɔː n 11 / 50
List German dünn d ʏ n GER ENG Frequ. d θ 2 x d d 1 x n n 1 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn θ ɔː n 11 / 50
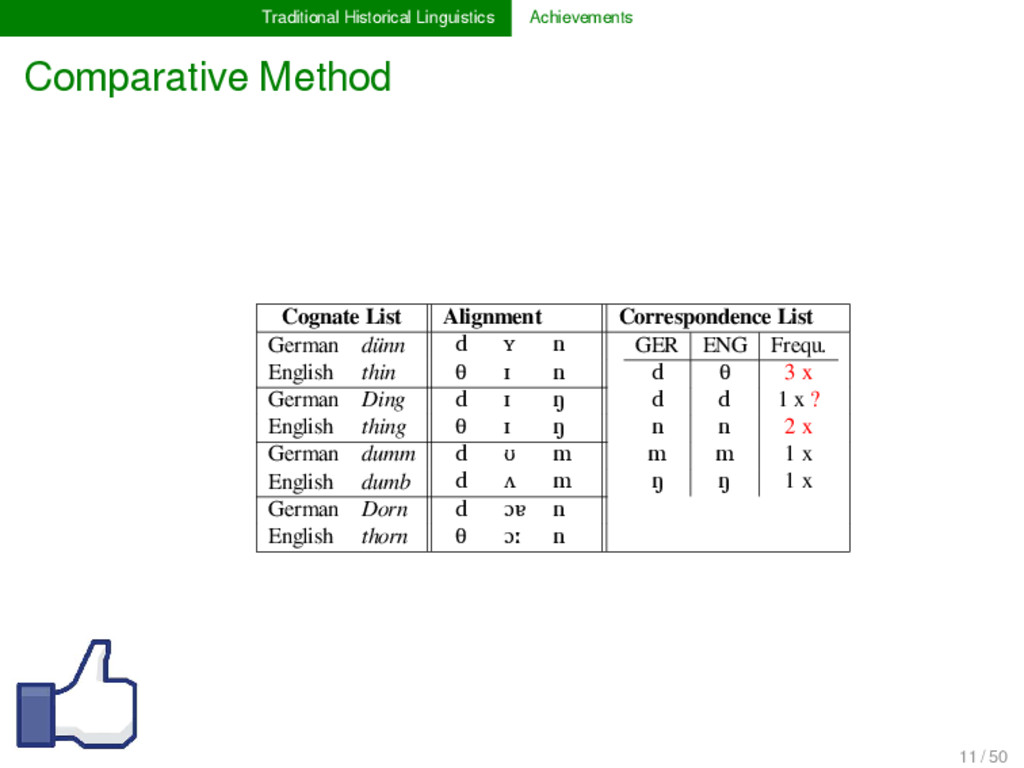
List German dünn d ʏ n GER ENG Frequ. d θ 3 x d d 1 x ? n n 2 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn θ ɔː n 11 / 50
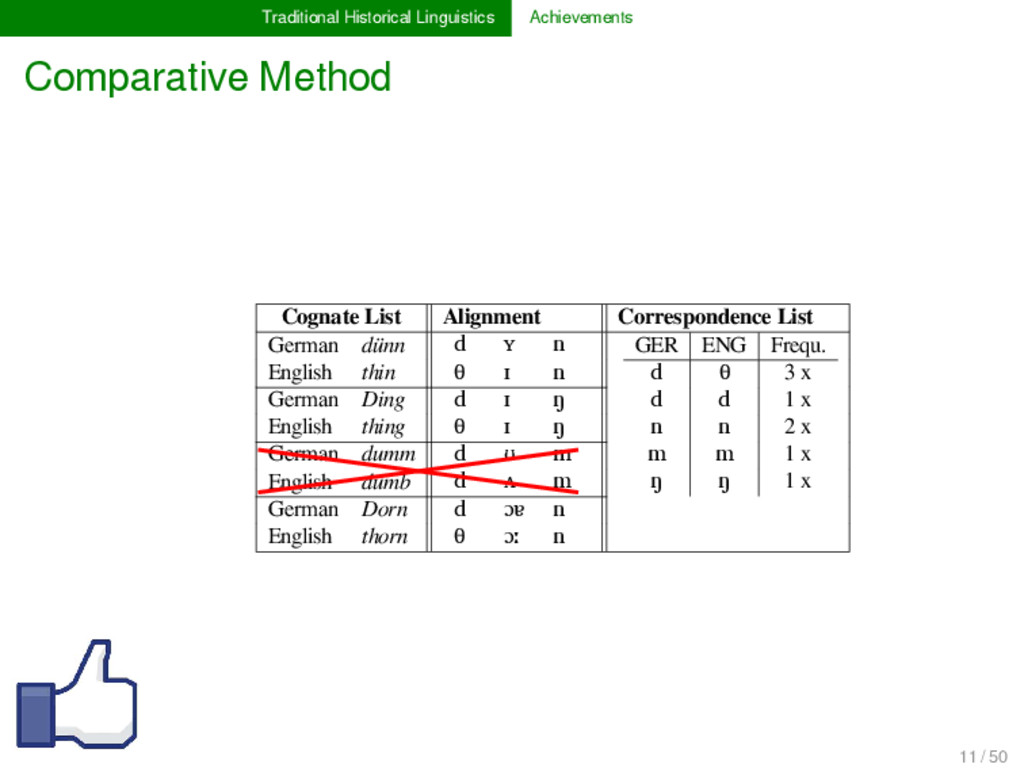
List German dünn d ʏ n GER ENG Frequ. d θ 3 x d d 1 x n n 2 x m m 1 x ŋ ŋ 1 x English thin θ ɪ n German Ding d ɪ ŋ English thing θ ɪ ŋ German dumm d ʊ m English dumb d ʌ m German Dorn d ɔɐ n English thorn θ ɔː n 11 / 50
historical linguistics, the history of a considerable (but still small) amount of languages has been thoroughly investigated. External Language History Thanks to historical linguistics, a considerable amount of the languages in the world has been genetically classified (although there remain many unsolved and controversially discussed questions). General Language History Some work on general processes of language history has been done, yet many questions still remain unsolved or are controversially debated. 12 / 50
“becoming” a competent Indo-Europeanist has always been recognized as coming to grasp “intuitively” concepts and types of changes in language so as to be able to pick and choose between alternative explanations for the history and development of specific features of the reconstructed language and its offspring. Schwink (1994) 14 / 50
data for the lan- guages of the world is growing from day to day, while there are only a few historical linguists who are trained to carry out the comparison of the- se languages. It seems impossible to handle this task when relying only on the traditional, time- consuming manual procedures developed in tra- ditional historical linguistics. 15 / 50
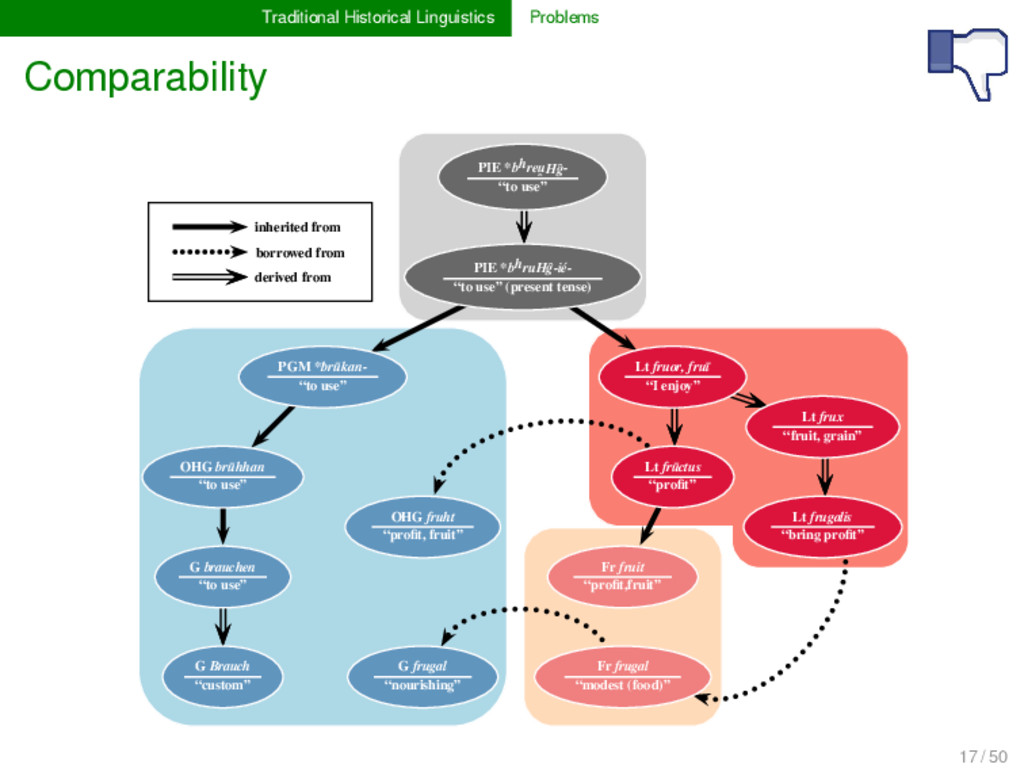
mhd. vruht, ahd. fruht, as. fruht. Ent- lehnt aus l. frūctus m. gleicher Bedeutung (zu l. fruī “genie- ße”). Das deutsche Wort ist Femininum geworden im An- schluß an die ti- Abstrakta wie Flucht² usw. Adjektive: fruch- tig, fruchtbar; Verb: (be-)fruchten. Ebenso nndl. vrucht, ne. fruit, nfrz. fruit, nschw. frukt, nnorw. frukt; frugal. (Kluge und Seebold 2002) 17 / 50
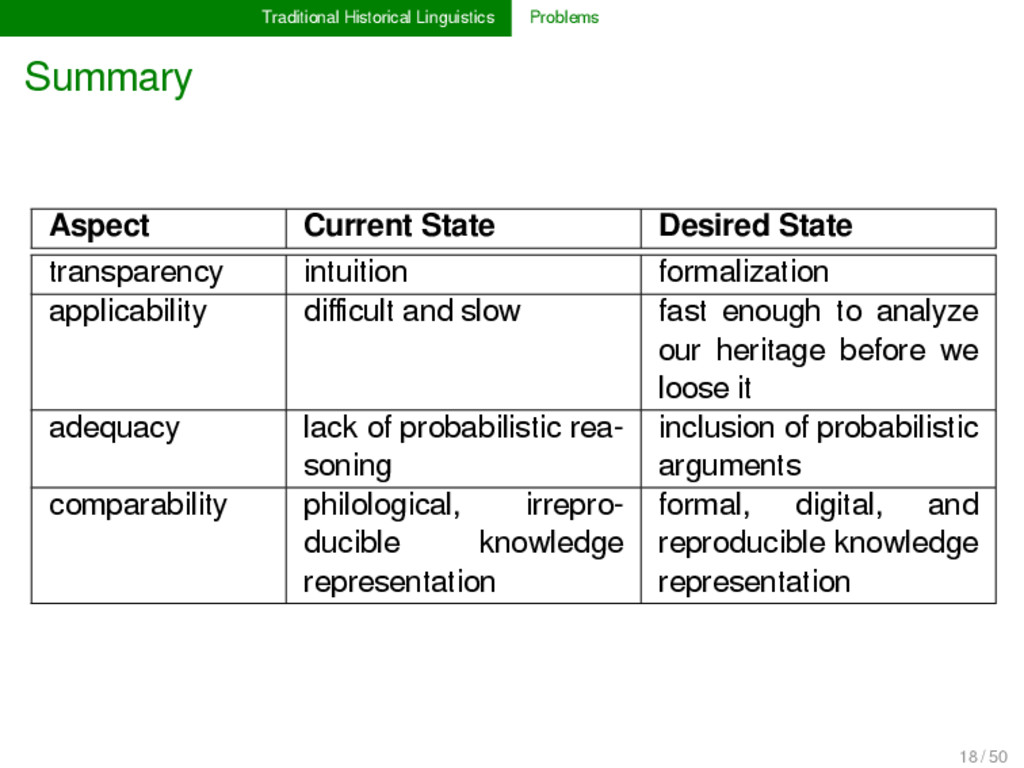
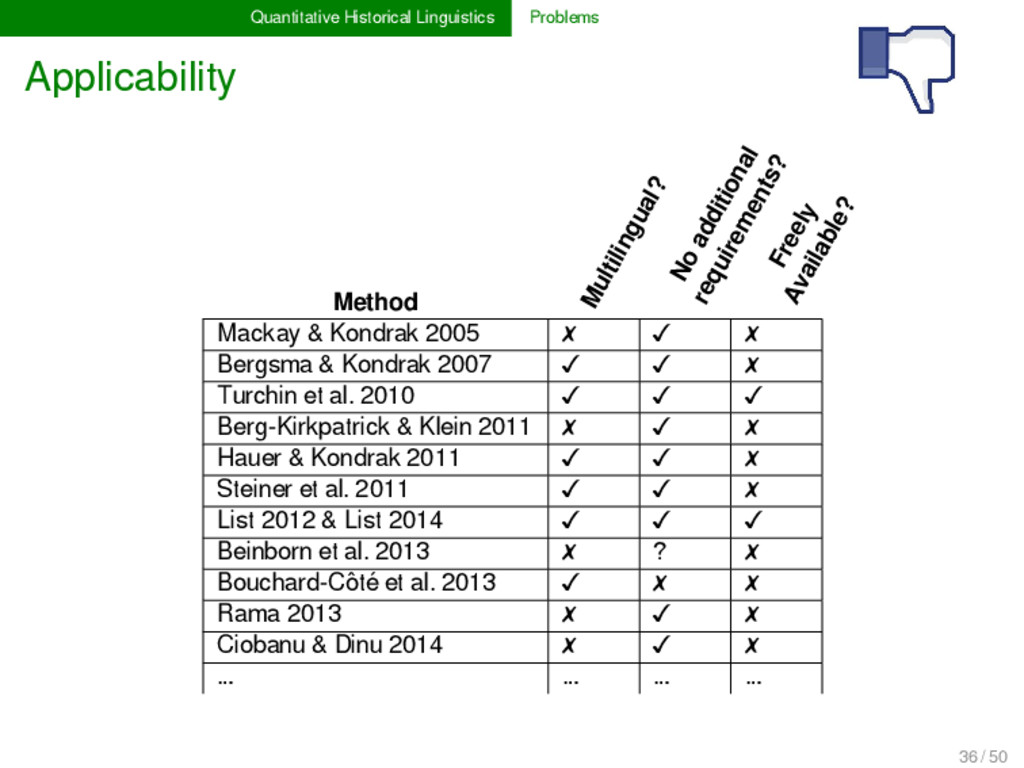
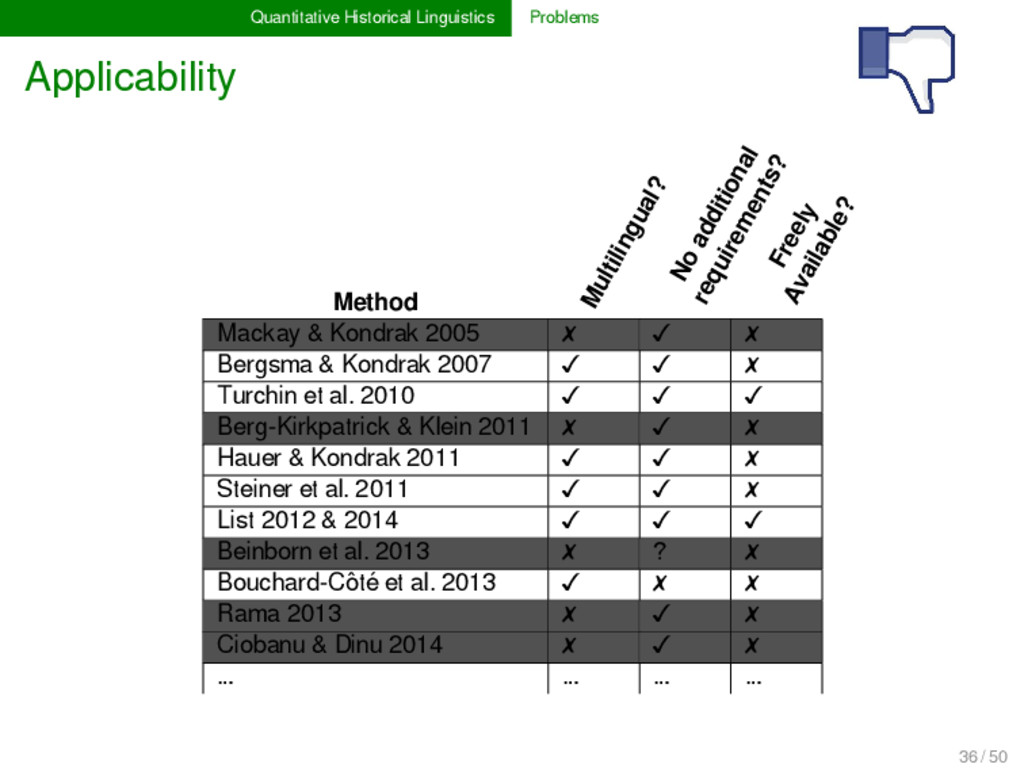
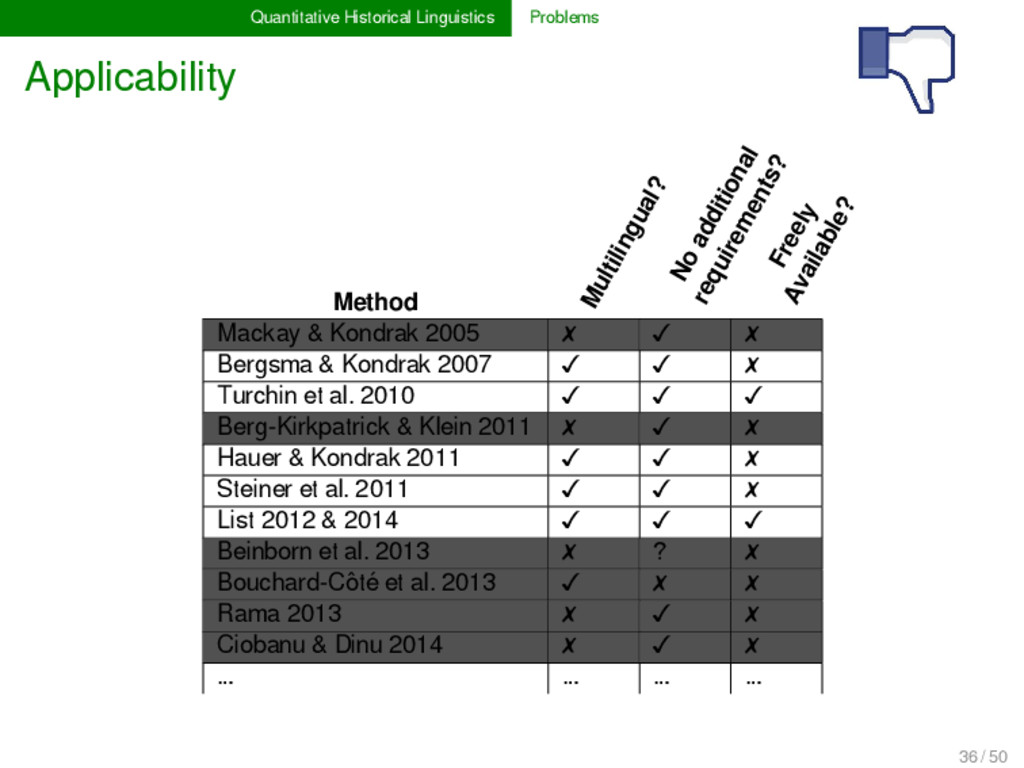
transparency intuition formalization applicability difficult and slow fast enough to analyze our heritage before we loose it adequacy lack of probabilistic rea- soning inclusion of probabilistic arguments comparability philological, irrepro- ducible knowledge representation formal, digital, and reproducible knowledge representation 18 / 50
(Ringe, Warnow and Taylor 2002) “Language-tree divergence times support the Anatolian theory of Indo-European origin” (Gray und Atkinson 2003) “Language classification by numbers” (McMahon und McMahon 2005) “Curious Parallels and Curious Connections: Phylogenetic Thinking in Biology and Historical Linguistics” (Atkinson und Gray 2005) “Automated classification of the world’s languages” (Brown et al. 2008) “Computational Feature-Sensitive Reconstruction of Language Relationships: Developing the ALINE Distance for Comparative Historical Linguistic Reconstruction” (Downey et al. 2008) “Networks uncover hidden lexical borrowing in Indo-European language evolution” (Nelson-Sathi et al. 2011) “A pipeline for computational historical linguistics” (Steiner, Stadler, und Cysouw 2011) 21 / 50
phylogenetic reconstruction sequence comparison general questions of language development Goals If we cannot guarantee getting the same results from the same data considered by different linguists, we jeopardize the essential scientific criterion of repeatability. (McMahon & McMahon 2005) 22 / 50
(cf., among others, Gray & Atkinson 2003 Ringe et al. 2002, Brown et al. 2008) phonetic alignment (cf., among others, Kondrak 2000, Prokić et al. 2009, List 2012a) cognate detection (cf. Steiner et al. 2011, List 2012b) borrowing detection (cf. Nelson-Sathi et al. 2011, List et al. 2014a) 23 / 50
more attention than before “Indo-Euro-Centrism” is replaced by a more cross-linguistic paradigm new questions regarding general language history new proposals to model language history 25 / 50
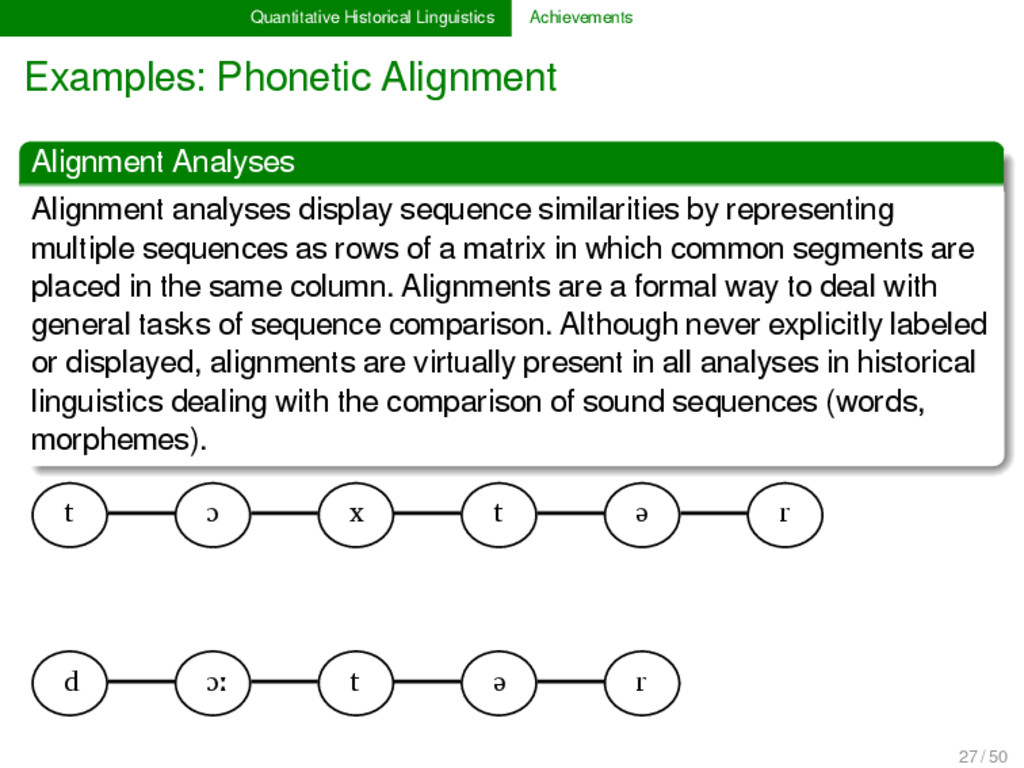
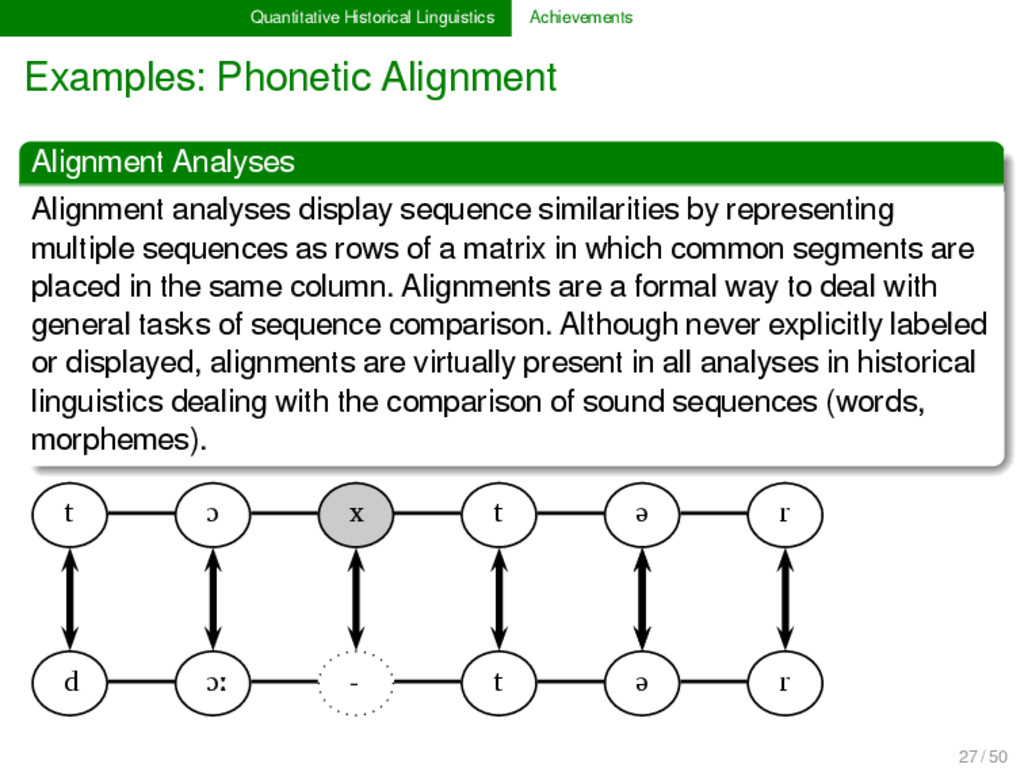
analyses display sequence similarities by representing multiple sequences as rows of a matrix in which common segments are placed in the same column. Alignments are a formal way to deal with general tasks of sequence comparison. Although never explicitly labeled or displayed, alignments are virtually present in all analyses in historical linguistics dealing with the comparison of sound sequences (words, morphemes). 27 / 50
analyses display sequence similarities by representing multiple sequences as rows of a matrix in which common segments are placed in the same column. Alignments are a formal way to deal with general tasks of sequence comparison. Although never explicitly labeled or displayed, alignments are virtually present in all analyses in historical linguistics dealing with the comparison of sound sequences (words, morphemes). t ɔ x t ə r d ɔː t ə r 27 / 50
analyses display sequence similarities by representing multiple sequences as rows of a matrix in which common segments are placed in the same column. Alignments are a formal way to deal with general tasks of sequence comparison. Although never explicitly labeled or displayed, alignments are virtually present in all analyses in historical linguistics dealing with the comparison of sound sequences (words, morphemes). t ɔ x t ə r d ɔː t ə r 27 / 50
analyses display sequence similarities by representing multiple sequences as rows of a matrix in which common segments are placed in the same column. Alignments are a formal way to deal with general tasks of sequence comparison. Although never explicitly labeled or displayed, alignments are virtually present in all analyses in historical linguistics dealing with the comparison of sound sequences (words, morphemes). t ɔ x t ə r d ɔː - t ə r 27 / 50
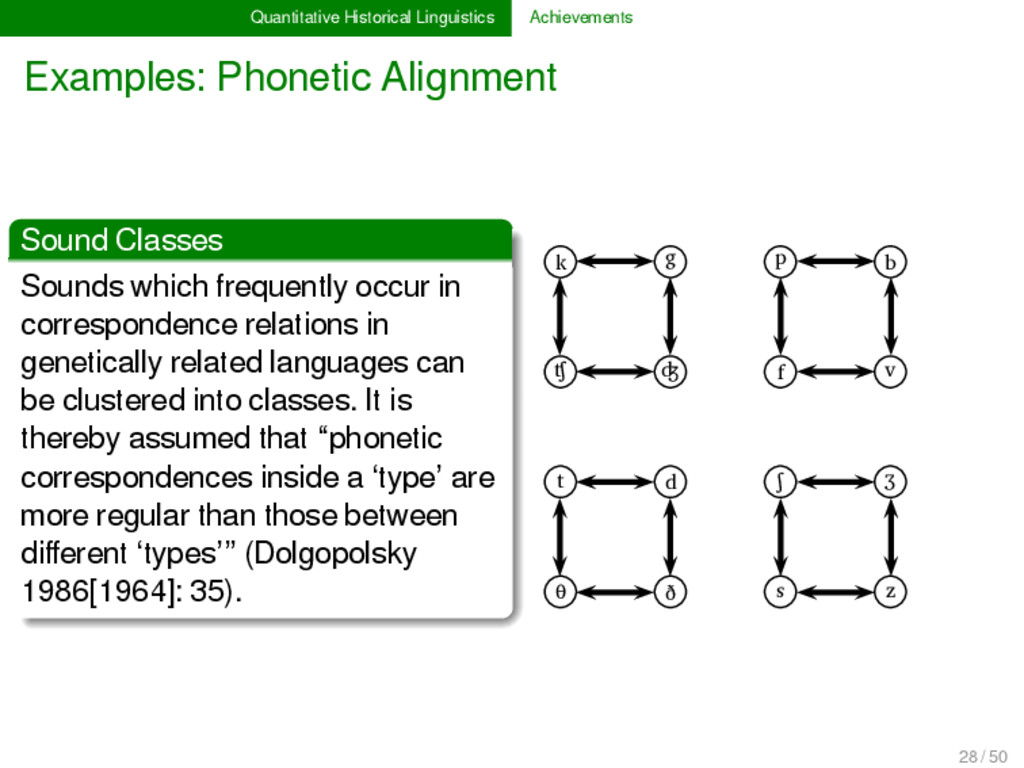
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). 28 / 50
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). k g p b ʧ ʤ f v t d ʃ ʒ θ ð s z 1 28 / 50
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). k g p b ʧ ʤ f v t d ʃ ʒ θ ð s z 1 28 / 50
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). k g p b ʧ ʤ f v t d ʃ ʒ θ ð s z 1 28 / 50
which frequently occur in correspondence relations in genetically related languages can be clustered into classes. It is thereby assumed that “phonetic correspondences inside a ‘type’ are more regular than those between different ‘types’” (Dolgopolsky 1986[1964]: 35). K T P S 1 28 / 50
(SCA, List 2012 a) Sound classes and alignment analyses can be combined. Sound sequences are internally represented as sound classes. Alignments are carried out using standard algorithms developed in evolutionary biology. 29 / 50
(SCA, List 2012 a) Sound classes and alignment analyses can be combined. Sound sequences are internally represented as sound classes. Alignments are carried out using standard algorithms developed in evolutionary biology. INPUT tɔxtər dɔːtər TOKENIZATION t, ɔ, x, t, ə, r d, ɔː, t, ə, r CONVERSION t ɔ x … → T O G … d ɔː t … → T O T … ALIGNMENT T O G T E R T O - T E R CONVERSION T O G … → t ɔ x … T O - … → d oː - … OUTPUT t ɔ x t ə r d ɔː - t ə r 1 29 / 50
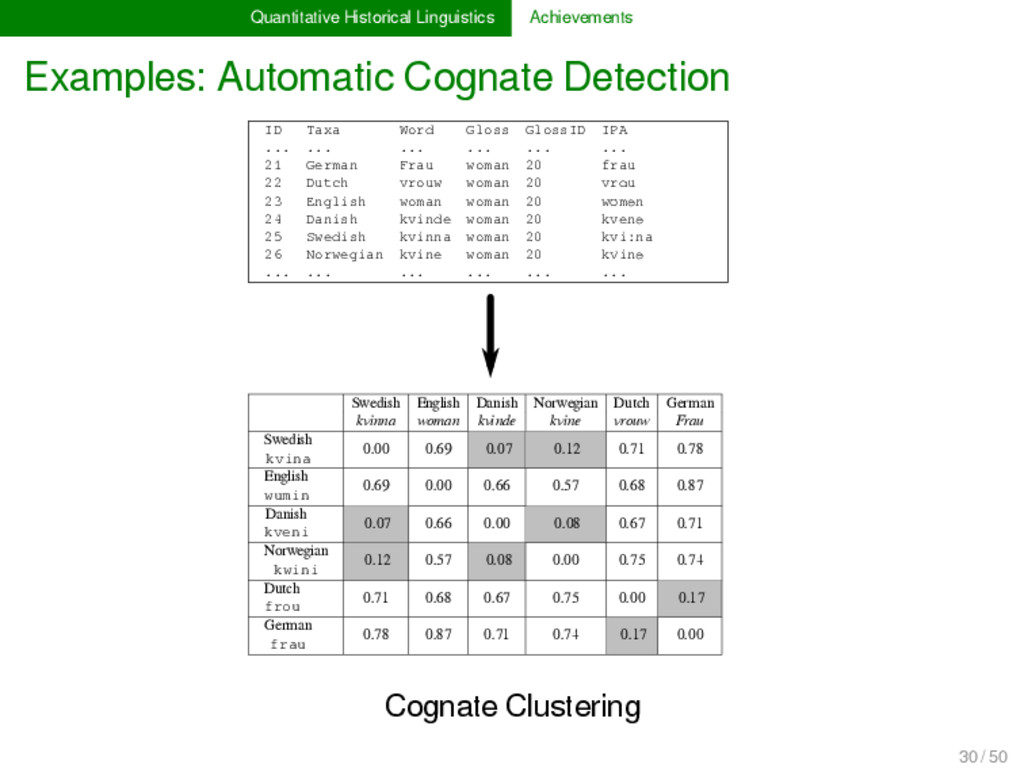
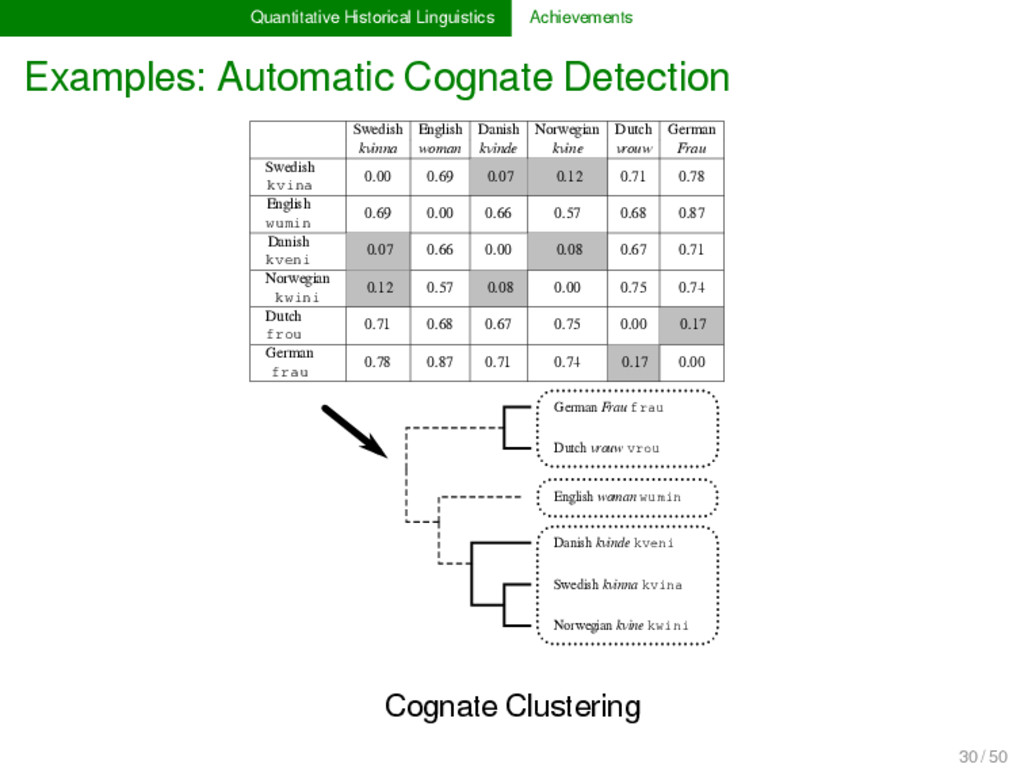
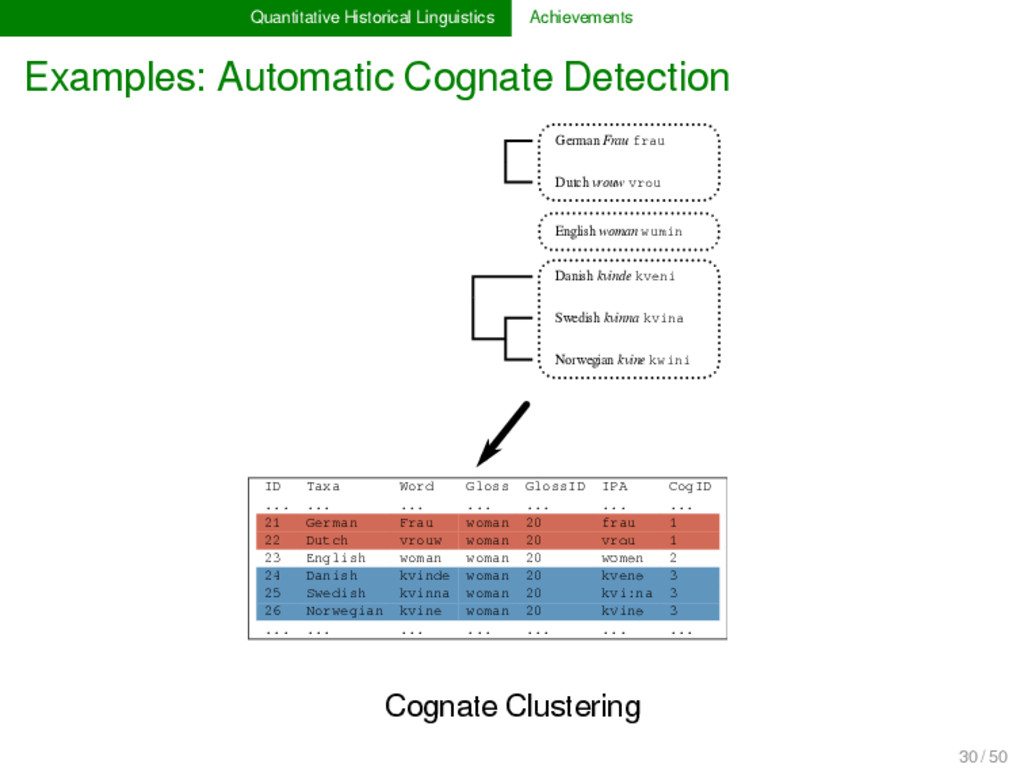
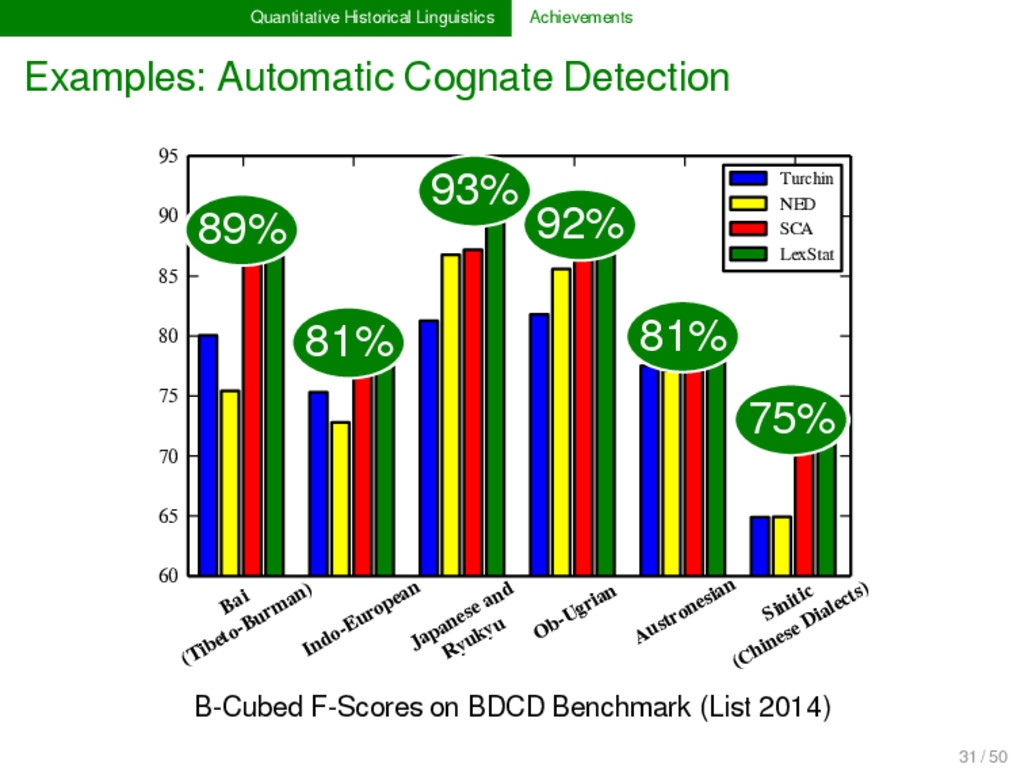
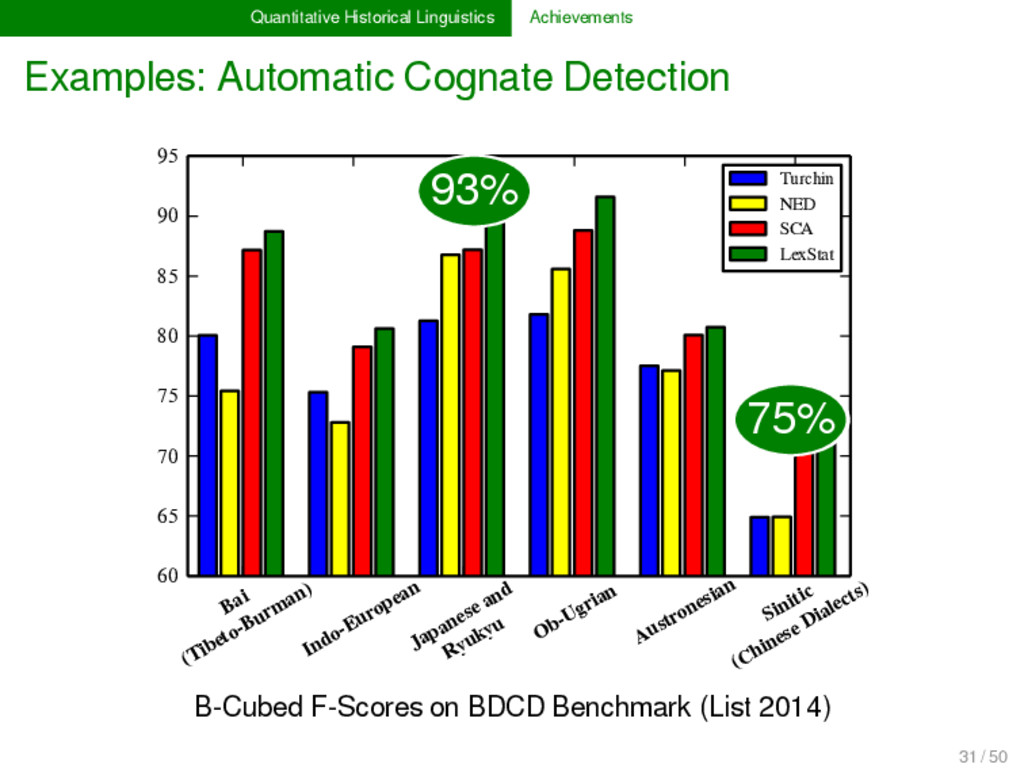
2012, List 2014) LexStat is a method for automatic cognate detection in multilingual wordlists. It uses on sound-class-based sequence alignment (SCA) analyses as a proxy to infer language-specific sound similarities (similar to the notion of sound correspondences in historical linguistics). Using the automatically inferred sound similarities, LexStat partitions words into cognate sets. 30 / 50
presented in a blackbox fashion. This does not mean that the methods are actually blackboxes upon which scholars do not have control, but rather that researchers avo- id the effort of increasing the transparency of their algorithms in such a way that they log all relevant decisions that lead to a certain re- sult. As a result, the majority of research published in quantitative historical linguistics is irreproducible and not falsifiable. 35 / 50
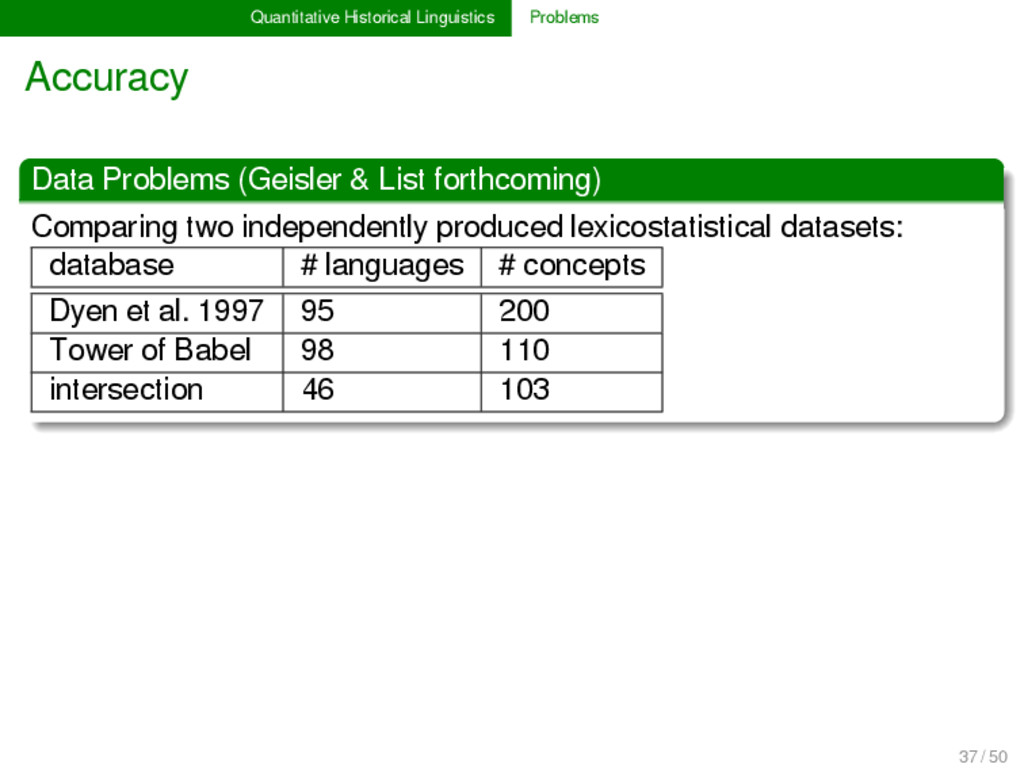
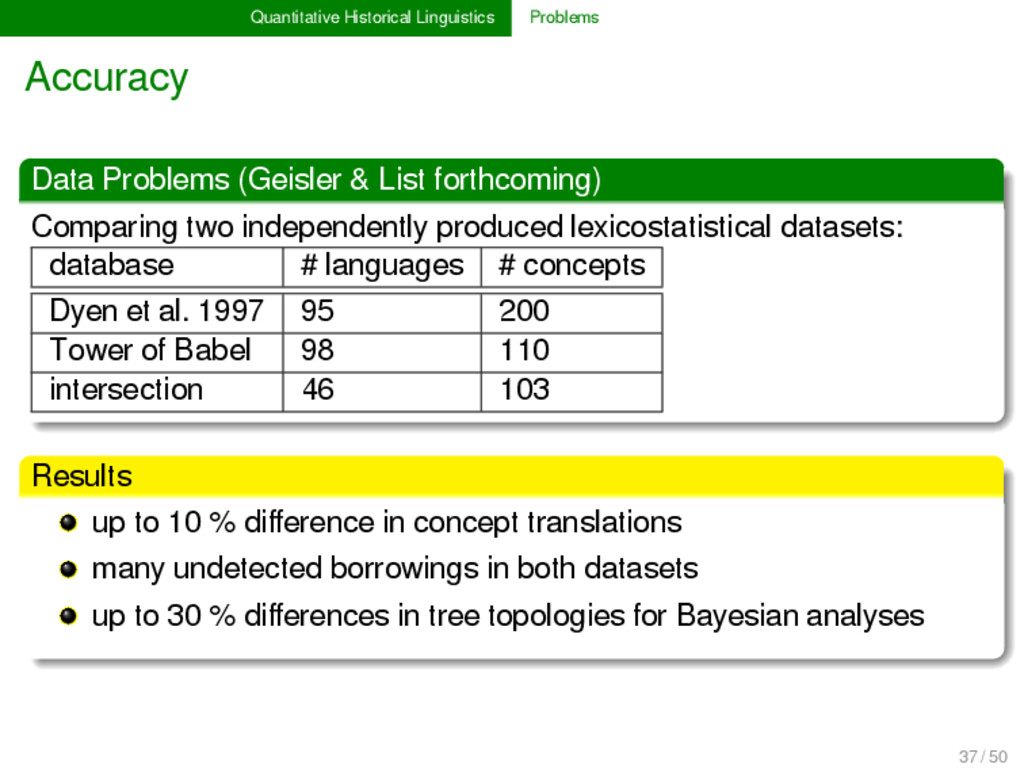
forthcoming) Comparing two independently produced lexicostatistical datasets: database # languages # concepts Dyen et al. 1997 95 200 Tower of Babel 98 110 intersection 46 103 Results up to 10 % difference in concept translations many undetected borrowings in both datasets up to 30 % differences in tree topologies for Bayesian analyses 37 / 50
to test new quantitative methods varies greatly, and there seems to be little interest in standardization. As a result, it is difficult if not impossible to compare the accuracy of dif- ferent methods in quantitative historical linguistics, and it drastically hampers the improvement of existing applications. 38 / 50
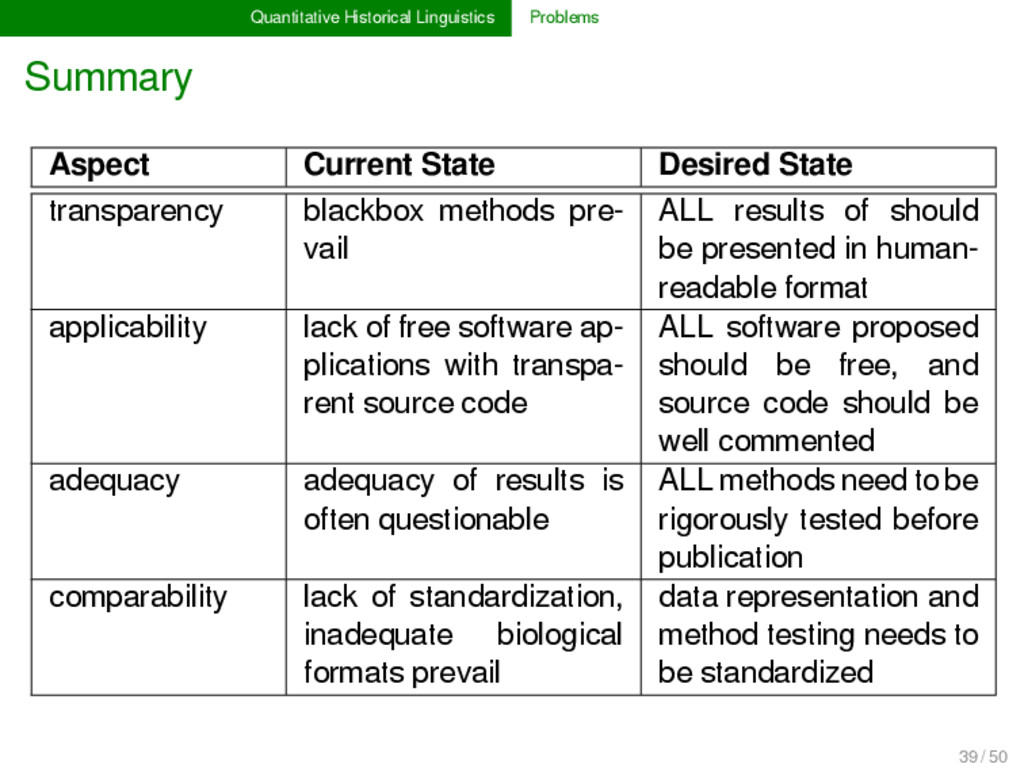
transparency blackbox methods pre- vail ALL results of should be presented in human- readable format applicability lack of free software ap- plications with transpa- rent source code ALL software proposed should be free, and source code should be well commented adequacy adequacy of results is often questionable ALL methods need to be rigorously tested before publication comparability lack of standardization, inadequate biological formats prevail data representation and method testing needs to be standardized 39 / 50
approaches in historical linguistics largely dis- regard the actual needs of historical linguistics. Despite the frequent claims that the algorithms are intended to supple- ment traditional research, many of them are mere attempts to prove the power of modern machine learning approaches. On the other hand, traditional approaches often disregard the fascinating possibilities that the digital age offers, and fail to leave the “realm of intuition”. 41 / 50
FRANZ BOPP VERY, VERY LONG TITLE Apart from “computational historical linguistics”, we need to establish a new discipline of “computer- assisted historical linguistics” (CALC). 41 / 50
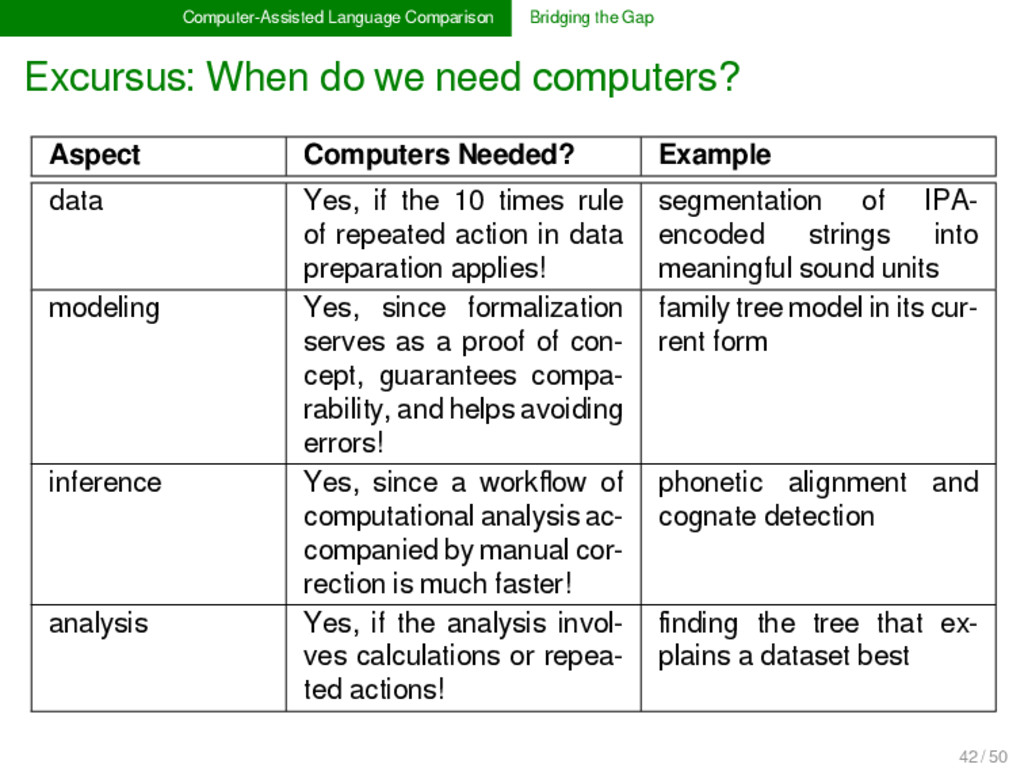
need computers? Aspect Computers Needed? Example data Yes, if the 10 times rule of repeated action in data preparation applies! segmentation of IPA- encoded strings into meaningful sound units modeling Yes, since formalization serves as a proof of con- cept, guarantees compa- rability, and helps avoiding errors! family tree model in its cur- rent form inference Yes, since a workflow of computational analysis ac- companied by manual cor- rection is much faster! phonetic alignment and cognate detection analysis Yes, if the analysis invol- ves calculations or repea- ted actions! finding the tree that ex- plains a dataset best 42 / 50
the EDICTOR data preparation with help of the EDICTOR (List forthcoming, http://tsv.lingpy.org) data modeling (phonetic alignments, cognate judgments) with help of the EDICTOR inference of probable semantic shift patterns with help of CLICS (List et al. 2014, http://clics.lingpy.org) analysis of lexical change patterns with help of the MLN approach (List et al. 2014) 43 / 50
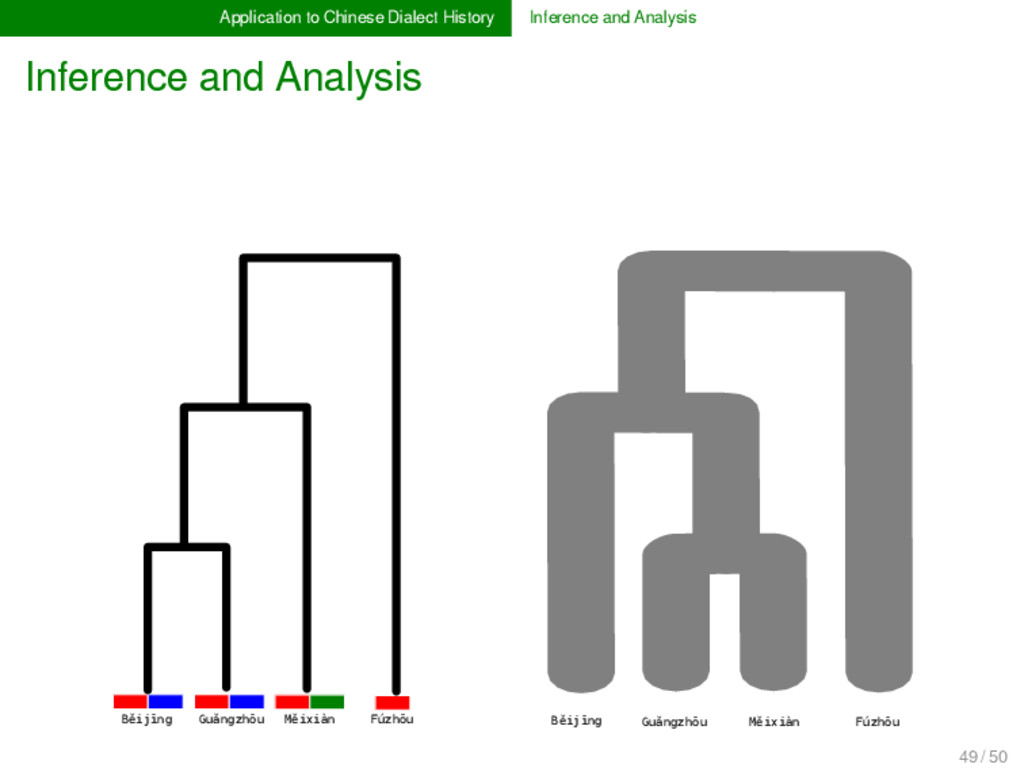
- English m uː n - - Danish m ɔː n - ə Swedish m oː n - e Fúzhōu ŋ u o ʔ ⁵ - - - - - - - - - - Měixiàn ŋ i a t ⁵ - - - - - k u o ŋ ⁴⁴ Guǎngzhōu j - y t ² l - œ ŋ ²² - - - - - Běijīng - y ɛ - ⁵¹ l i ɑ ŋ - - - - - - 44 / 50
- English m uː n - - Danish m ɔː n - ə Swedish m oː n - e Fúzhōu ŋ u o ʔ ⁵ - - - - - - - - - - Měixiàn ŋ i a t ⁵ - - - - - k u o ŋ ⁴⁴ Guǎngzhōu j - y t ² l - œ ŋ ²² - - - - - Běijīng - y ɛ - ⁵¹ l i ɑ ŋ - - - - - - "MOON" "MOON" "SHINE" "LIGHT" 44 / 50
Project on Chinese Dialect History My research project “Vertical and lateral aspects of Chinese dialect history”, funded by the German Research Foundation (DFG), pro- poses an interdisciplinary, data-driven approach to Chinese dialec- tology and has two major goals: 1 Based on the cooperation with sinologists (CLRAO) and biologists (UMPC), quantitative methods originally designed to study lateral gene transfer in evolutionary biology shall be used to explore vertical (inheritance-related) and lateral (contact-related) aspects of Chinese dialect history. 2 In order to bridge the gap between traditional and quantitative approaches in historical linguistics the research will be carried out within the new framework of “computer-assisted language comparison”. 46 / 50
Fāngyán Cíhuì 汉语方言词汇 (Běijīng Dàxué 1964, 904 concepts, translated into 17 dialect varieties) serves as the fundamental data basis, hopefully expanded by further sources provided by colleagues or taken from additional literature digital version of the Cíhuì has already been prepared about 80 percent of all Chinese glosses have already been translated to Chinese during the next two weeks, all data will be systematically extracted, cleaned (segmentation of phonetic entries, e.g. write "thai51jaŋ35" as "tʰ a j ⁵¹ j a ŋ ³⁵"), and uploaded to the EDICTOR tool for further analysis (as part of a larger database on Sino-Tibetan languages) additional sources will be subsequently added (web-based tools for quick identification of identical concepts in new sources have already been written) 47 / 50
will be searched for cognate parts cognate sets will be aligned by first carrying out automatic analyses and correcting them later manually each lexical entry will further be aligned with its Middle Chinese and Old Chinese ancestral forms => In this way, I hope to make sure that a maximal amount of knowledge about Chinese dialect history is represented in a human- and machine-readable way and can later be accessed and analysed by both humans and computers. 48 / 50
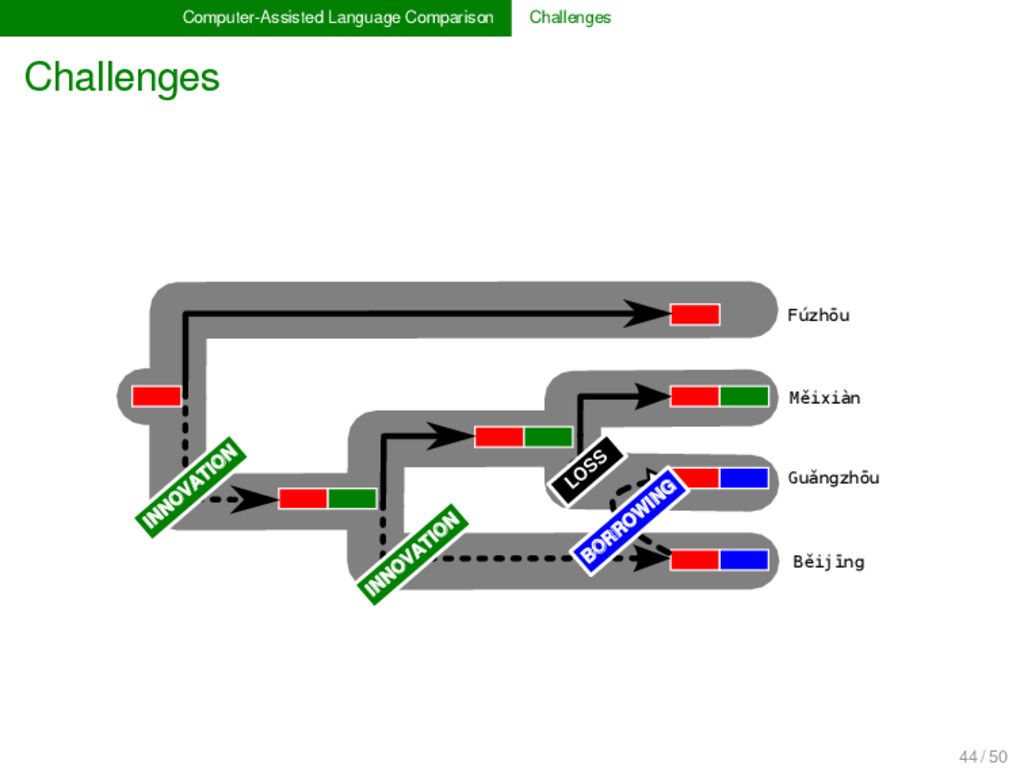
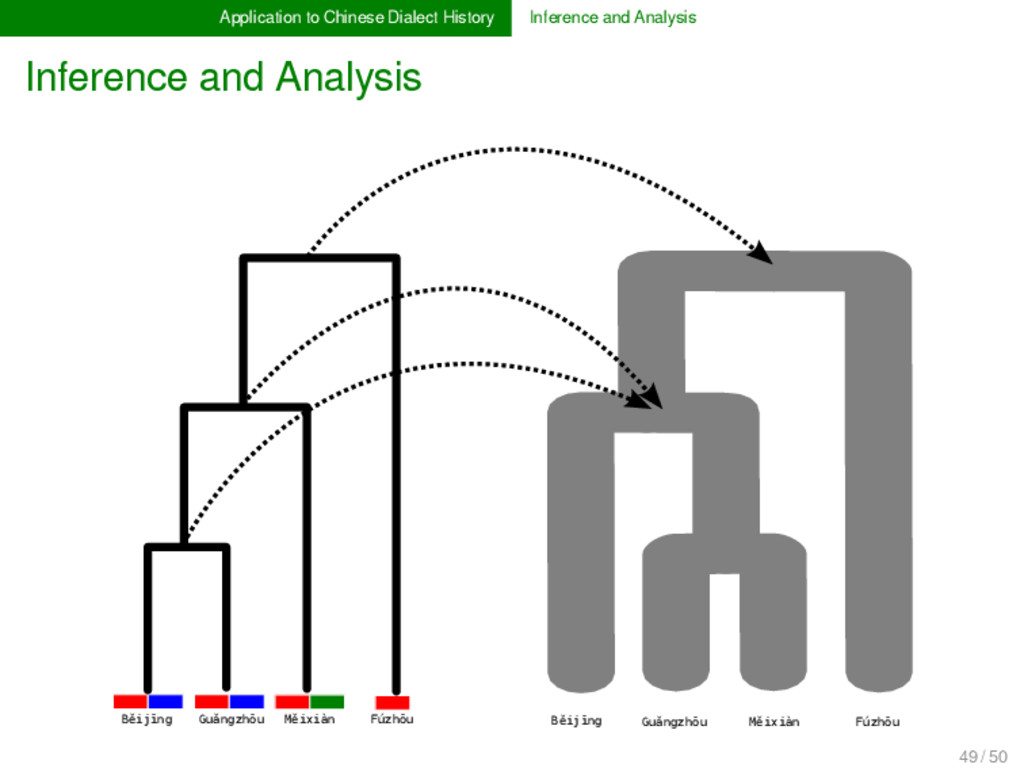
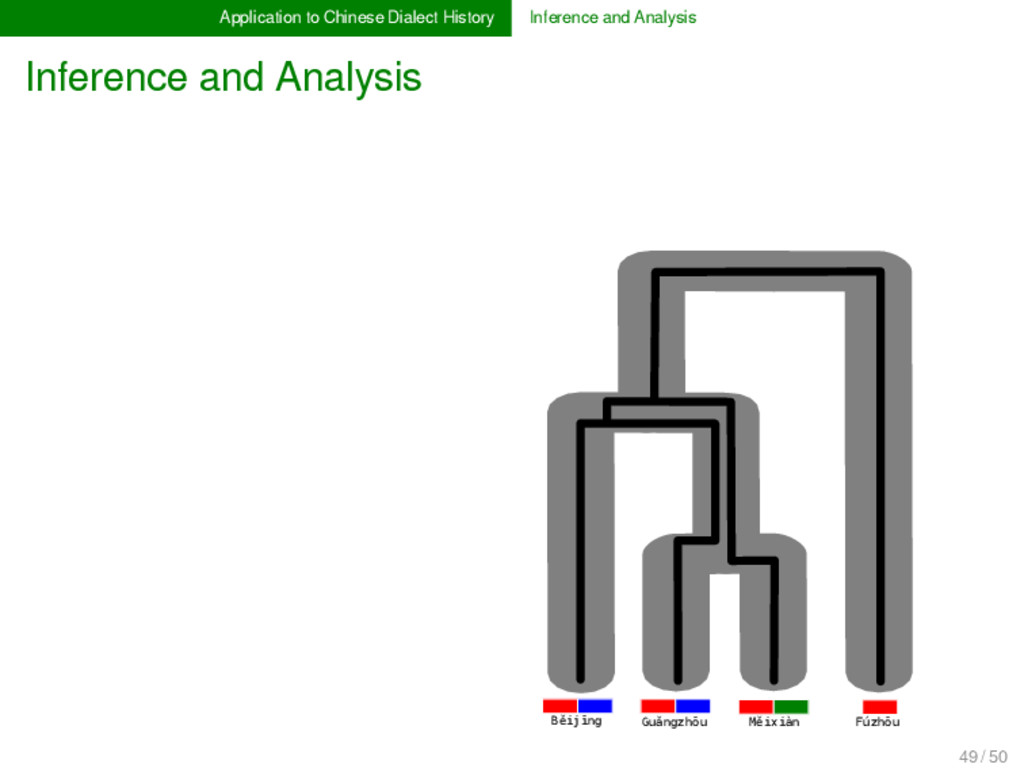
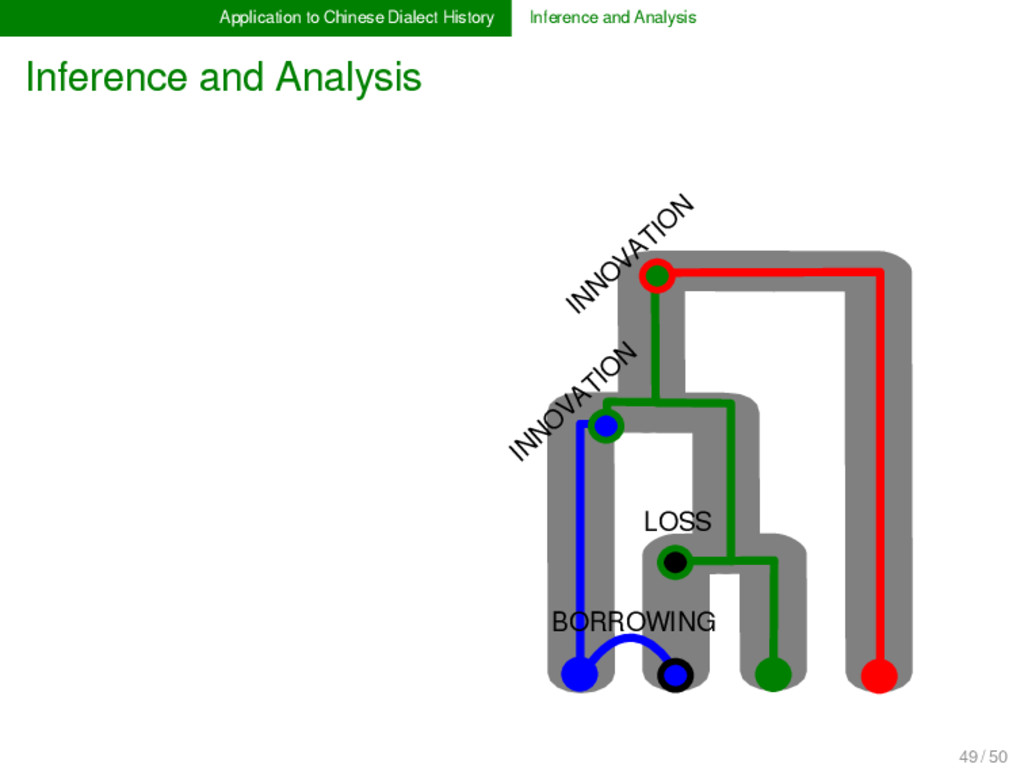
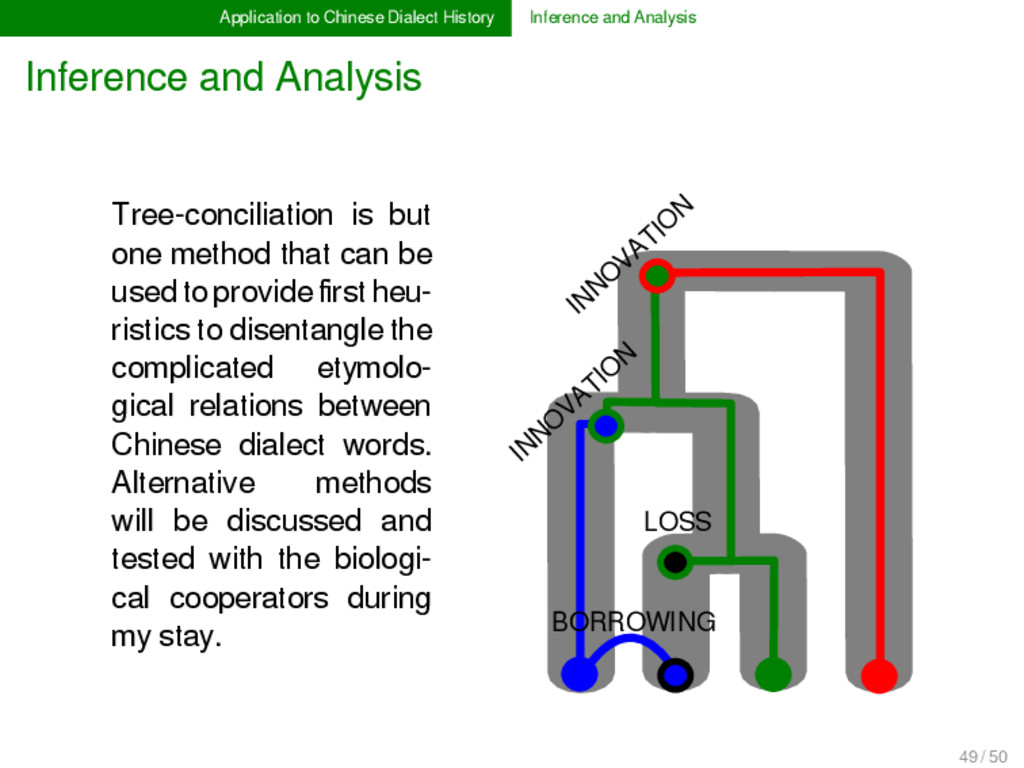
Analysis In Chinese dialectology, it is often not very hard to detect whether two or more words are etymologically related. What is hard, however, is to determine their exact relationship, that is, it is hard to resolve which dimensions of lexical change were involved during their history. In order to cope with the multiple dimensions of lexical change, we need new methods and models in historical linguistics, which explicitly deal with borrowing, partial cognacy, and semantic change. Following the lead of evolutionary biology, these methods could be combined under a unified framework of tree reconciliation (Page & Cotton 2002) in historical linguistics. 49 / 50
Analysis LOSS INNO VATIO N INNO VATIO N BORROWING Tree-conciliation is but one method that can be used to provide first heu- ristics to disentangle the complicated etymolo- gical relations between Chinese dialect words. Alternative methods will be discussed and tested with the biologi- cal cooperators during my stay. 49 / 50
to oppose the Neogrammarian claim that sound change proceeds without exceptions. Under the slogan “chaque mot a son histoire”, they de- manded that linguists should take all available data, especially dialect data, into account when propo- sing their theories on language variation and chan- ge. This triggered some debates in historical lin- guistics, but they were soon forgotten and the me- thods were never changed. 50 / 50
genes may follow very idiosyncratic patterns, so complex indeed, that one could likewi- se claim that each gene has its own history. In order to account for this, they started to develop compu- tational tools that allow them to study what they now sometimes call “mosaic history”, that is, the indivi- dual histories of genes that do not follow a major evolutionary path. 50 / 50
dance of language data that no one person can re- ad in a lifetime. It seems to be time that historical linguists start following the example of evolutiona- ry biology in using computers as a helpful tool to investigate our data and not giving easily up if our theories are threatened by reality. If it is really true, that every word has its own history, then let’s try to assemble all these histories in databases and look which new and interesting patterns we may find! 50 / 50
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}